网络拓扑及机架感知
网络拓扑
节点距离:两个节点到达共同父节点的距离和

机架感知 ( 副本节点的选择 )
例如:500个节点,上传数据my.tar.gz,副本数为3,
根据机架感知,副本数据存储节点的选择。

上传流程(重点记)

Block
HDFS中的文件在物理上是分块存储的,即分成Block;
block在Hadoop不同版本大小不同:
Hadoop1.x:64M
Hadoop2.x:128M
Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。ACK (Acknowledge character )即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
Packet
Packet是Client端向Datanode,或者DataNode的PipLine之间传输数据的基本单位,默认64kB.
Chunk
Chunk是最小的Hadoop中最小的单位,是Client向DataNode或DataNode的PipLne之间进行数据校验的基本单位,默认512Byte,因为用作校验(自己校验自己),故每个chunk需要带有4Byte的校验位。
所以世纪每个chunk写入packet的大小为516Byte,真实数据与校验值数据的比值为128:1。
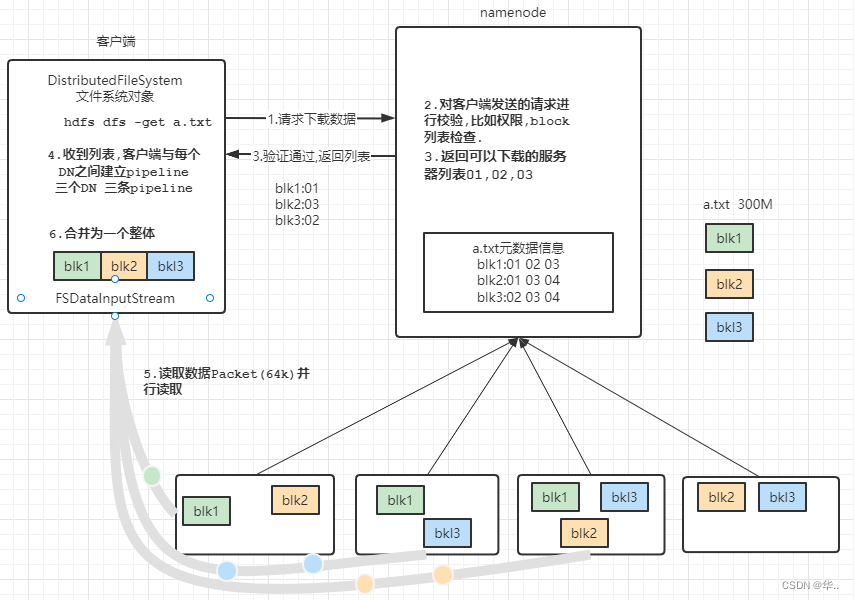
下载数据流程
IO操作过程中难免会出现数据丢失或脏数据,数据传输得量越大出错得几率越高。校验错误最常用得办法就是传输前计算一个校验和,传输后计算一个校验和,两个校验和如果不相同就说明数据存在错误,比较常用得错误校验码是CRC32.
hdfs写入的时候计算出校验和,然后每次读的时候再计算校验和。要注意的一点是,hdfs每固定长度就会计算一次校验和,这个值由io.bytes.per.checksum指定,默认是512字节。
DataNode节点如何保证数据的完整性
1.当datanode读取Block的时候,会计算CheckSum
2.如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏
3.客户端读取其他DataNode上的Block
4.常见的校验算法crc,md5等
5.DataNode在其文件创建后周期验证CheckSum(DataNode后台进程(DataBlockScanner))
如果客户端发现有block坏掉呢,恢复这个坏的块,主要分几步:
1.客户端在抛出ChecksumException之前会把坏的block和block所在的datanode报告给namenode
2.namenode把这个block标记为已损坏,这样namenode就不会把客户端指向这个block,也不会复制这个block到其他的datanode。
3.namenode会把一个好的block复制到另外一个datanode
4.namenode把坏的block删除掉