一、循环
1.range() 函数
用于生成一个整数序列,返回的是一个迭代对象,可用 in / not in查看。
(1)range(stop)
创建一个 [0,stop) 的整数序列,步长为1。
(2)range(start, stop)
创建一个 [start, stop) 的整数序列,步长为1。
(3)range(start, stop, step)
创建一个 [start, stop) 的整数序列,步长为step。
a = range(10)
print(a) #range(0, 10)
print(list(a)) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
b = range(1,10)
print(b) #range(1, 10)
print(list(b)) #[1, 2, 3, 4, 5, 6, 7, 8, 9]
c = range(1,10,2)
print(c) #range(1, 10, 2)
print(list(c)) #[1, 3, 5, 7, 9]
2.循环结构
反复做同一件是的情况。选择结构中的 if 与循环结构的 while 区别:if 是判断一次,条件为 True 执行一行;while 是判断 N+1 次,条件为 True 执行 N 次。
(1)while 循环
四步循环法:初始化变量 -> 条件判断 -> 条件执行体 -> 改变变量
# 初始化变量
a = 1
# 条件判断
while a<3:
# 条件执行体
print("Hello World")
# 改变变量
a += 1
'''
Hello World
Hello World
'''(2)for-in 循环体(for循环)
in 表达从(字符串、序列)中依次取值,又称为遍历。for-in 的循环对象必须是可迭代对象。语法结构:
for 自定义变量 in 可迭代对象:
循环体
若循环体中不需要访问自定义变量,可将自定义变量替代为下划线。
for i in range(5):
print(i)
'''
0
1
2
3
4
'''
for _ in range(3):
print("Hello World")
'''
Hello World
Hello World
Hello World
'''3.break 语句
用于结构循环结构,通常与分支结构 if 一起使用。
for i in range(3):
pwd = input("请输入密码:")
if pwd == '666':
print("密码正确!")
break;
else:
print("密码错误")
# while循环四部循环法
i = 1
while i<4:
pwd = input("请输入密码:")
if pwd == '666':
print("密码正确!")
break;
print("密码错误")
i += 14.continue 语句
用于结束当前循环结构,进入下一次循环,通常与分支结构 if 一起使用。
# 输入 1-50 之间 5 的倍数
for i in range(1,51):
if i % 5 == 0:
print(i)
# 使用 continue 后
for i in range(1,51):
if i % 5 != 0:
continue
print(i)5.else 语句
一般搭配以下三种情况:

6.嵌套循环
循环结构体中又 嵌套另外的完整的循环结构,其中内层循环作为外层的循环体执行。其中,二重及多重循环中的 break 和 continue 用于控制本层循环。
二、列表
变量可以存储一个元素,而列表是一个“大容器”,可存储多个变量,相对于数组。
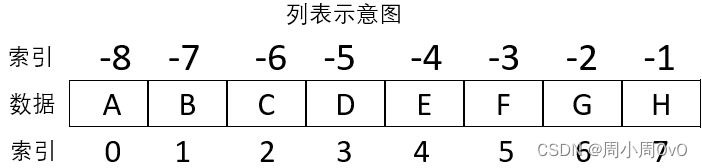
1.列表的创建
(1)语法格式:列表对象名 = [..., ..., ..., .....] (使用英文中括号)
(2)语法格式:列表对象名 = list( [..., ..., ..., .....] )(使用 list() 函数 )
2.列表的特点
(1)列表对象按顺序有序排列;
(2)索引映射唯一数据;
(3)列表可以存储重复数据;
(4)任何数据类型混存;
(5)需动态分配和回收内存。
# 列表的创建及特点
lst1 = ['姓名','年龄',18]
lst2 = list(['班级','学号',101,101])
print(lst1[0]) # 姓名
print(lst2) # ['班级', '学号', 101, 101]
print(lst2[2],lst2[3]) # 101 1013.列表的常规操作
(1)查询操作
a.获取列表中指定元素的索引(即给元素值求索引值)
index() :①若被查列表中存在 N 个相同元素。则返回该元素的第一个索引值;②若查询的元素不存在,则抛出 ValueError 异常;③可以在指定的 start 和 stop 之间查找。
b.获取列表中的单个元素(即给索引值获取元素值)
①正向索引:从 0 到 N-1;②逆向索引:从 -N 到 -1;③若指定索引不存在时,则抛出 IndexError 异常。
c.获取列表中的多个元素
语法格式:列表名 [ start: stop: step ]
切片操作:
①切片结果:原列表片段的拷贝;②切片范围:[ start: stop );③step 默认为1,可以简写为:列表名 [ start: stop ];④step 为正数时,⑤⑥⑦⑧⑨
d.判断指定元素在列表中是否存在
语法格式:元素 in 列表名 / 元素 not in 列表名
e.列表元素遍历
语法格式:for 可迭代变量 in 列表名: 操作
# 列表的查询操作1 —— 获取列表中指定元素的索引
lst3 = ['Hello',985,211,'Hello']
print(lst3.index(985)) # 1
print(lst3.index('Hello')) # 0
# print(lst3.index('985')) # ValueError: '985' is not in list
print(lst3.index('Hello',1,4)) # 3
# 列表的查询操作2 —— 获取列表中的单个元素
lst4 = [985,'World',211,'World',123]
print(lst4[0]) # 985
print(lst4[-5]) # 985
# print(lst4[10]) # IndexError: list index out of range
# 列表的查询操作3 —— 获取列表中的多个元素
lst5 = [10,20,30,40,50,60,70,80]
lst6 = lst5[1:6:1]
print(lst5,id(lst5)) # [10, 20, 30, 40, 50, 60, 70, 80] 2120896680192
print(lst6,id(lst6)) # [20, 30, 40, 50, 60] 2120896681408
print(lst5[1:6]) # [20, 30, 40, 50, 60]
print(lst5[1:6:]) # [20, 30, 40, 50, 60]
# 列表的查询操作4 —— 判断指定元素在列表中是否存在
print('p' in 'python') # True
print('p' not in 'python') # False
lst7 = ['P',123,456,'Python']
print('P' in lst7) # True
print('789' not in lst7) # False
# 列表的查询操作5 —— 列表元素遍历
for i in lst7:
print(i)
'''
P
123
456
Python
'''(2)添加操作
a.append() 函数:在列表末尾添加一个元素;
b.extend() 函数:在列表末尾至少添加一个元素;
c.insert() 函数:在列表任意位置添加一个元素;
d.切片:在列表任意位置至少添加一个元素。
# 列表的添加操作1 —— append() 函数
lst8 = [10,20,30,40,'python','Hello World']
lst9 = ['Just Do Yourself!']
lst8.append(10)
print(lst8) # [10, 20, 30, 40, 'python', 'Hello World', 10]
lst8.append(lst9)
print(lst8) # [10, 20, 30, 40, 'python', 'Hello World', 10, ['Just Do Yourself!']]
# 列表的添加操作2 —— extend() 函数
lst8.extend(lst9)
print(lst8) #[10, 20, 30, 40, 'python', 'Hello World', 10, ['Just Do Yourself!'], 'Just Do Yourself!']
# 列表的添加操作3 —— insert() 函数
lst8.insert(1,'99')
print(lst8)
[10, '99', 20, 30, 40, 'python', 'Hello World', 10, ['Just Do Yourself!'], 'Just Do Yourself!']
# 列表的添加操作4 —— 切片
lst10 = [10,20,30,40,'python','Hello World']
print(id(lst10)) # 2257809121152
lst11 = [1,2,'3']
lst10[1:] = lst11
print(lst10) # [10, 1, 2, '3']
print(id(lst10)) # 2257809121152(3)删除操作
a.remove() 函数
一次删除一个元素;重复元素只删除第一个;元素不存在,则抛出 ValueError 异常。
b.pop() 函数
删除一个指定索引位置上的元素;指定索引不存在,则抛出 IndexError 异常;不指定索引,则删除最后一个元素。
c.切片
一次至少删除一个元素。
d.clear() 函数
清空列表。
e.del
删除列表。
# 列表的删除操作1 —— remove() 函数
lst1 = ['123',123,'456',456,'456']
lst1.remove('456')
print(lst1) # ['123', 123, 456, '456']
# lst1.remove(1234) # ValueError: list.remove(x): x not in list
print(lst1)
# 列表的删除操作2 —— pop() 函数
lst2 = ['123',123,'456',456,'456']
# lst2.pop(10) # IndexError: pop index out of range
lst2.pop(0)
print(lst2) # [123, '456', 456, '456']
lst2.pop()
print(lst2) # [123, '456', 456]
# 列表的删除操作3 —— 切片
lst3 = [10,20,30,40,50]
new_list = lst3[1:3]
print('原列表:',lst3,id(lst3)) # 原列表: [10, 20, 30, 40, 50] 2443498232512
print('切片后的列表:',new_list,id(new_list)) # 切片后的列表: [20, 30] 2443498361408
# 列表的删除操作4 —— clear() 函数
lst4 = [10,20,30,40,50]
lst4.clear()
print(lst4) # []
# 列表的删除操作5 —— del
lst5 = [10,20,30,40,50]
del lst5
# print(lst5) # ameError: name 'lst5' is not defined(4)修改操作
a.为指定索引的元素赋予一个新值;
b.为指定切片赋予一个新值。
# 列表的修改操作1 —— 为指定索引的元素赋予一个新值
lst1 = [10,20,30,40]
lst1[2] = 20
print(lst1) # [10, 20, 20, 40]
# 列表的修改操作2 —— 为指定切片赋予一个新值
lst2 = [10,20,30,40]
lst2[1:3] = [1,2]
print(lst2) # [10, 1, 2, 40](5)排序操作
a.sort() 函数
默认按从小到大的序列排序;可指定 reverse = True,即进行降序排序。原列表发生改变。
b.sorted() 函数
默认按从小到大的序列排序;可指定 reverse = True,即进行降序排序。原列表不发生改变。即产生一个新的列表对象。
# 列表的排序操作1 —— sort() 函数
lst1 = [8,9,795,29418,7263,336,456,985]
print('排序前的列表',lst1,id(lst1)) # 排序前的列表 [8, 9, 795, 29418, 7263, 336, 456, 985] 1330168607744
lst1.sort()
print('排序后的列表',lst1,id(lst1)) # 排序后的列表 [8, 9, 336, 456, 795, 985, 7263, 29418] 1330168607744
lst1.sort(reverse=True)
print(lst1) # [29418, 7263, 985, 795, 456, 336, 9, 8]
# 列表的排序操作2 —— sorted() 函数
lst2 = [8,9,795,29418,7263,336,456,985]
new_list1 = sorted(lst2)
new_list2 = sorted(lst2,reverse=True)
print('排序前的列表',lst2,id(lst2)) # 排序前的列表 [8, 9, 795, 29418, 7263, 336, 456, 985] 2882593888832
print('排序后的列表',new_list1,id(new_list1)) # 排序后的列表 [8, 9, 336, 456, 795, 985, 7263, 29418] 2882593888768
print(new_list2,id(new_list2)) # [29418, 7263, 985, 795, 456, 336, 9, 8] 28825940058884.列表生成式
简称 “生成列表的公式”,语法格式:[ 表示列表元素的表达式 for 自定义变量 in 可迭代对象 ]。注意:“表示列表元素的表达式” 中通常包含自定义变量。
lst1 = [i*i for i in range(1,10)]
print(lst1) # [1, 4, 9, 16, 25, 36, 49, 64, 81]