他们各自的概念看以下链接就可以了:https://blog.csdn.net/weixin_43135178/category_11543123.html
这里主要谈一下他们的区别?
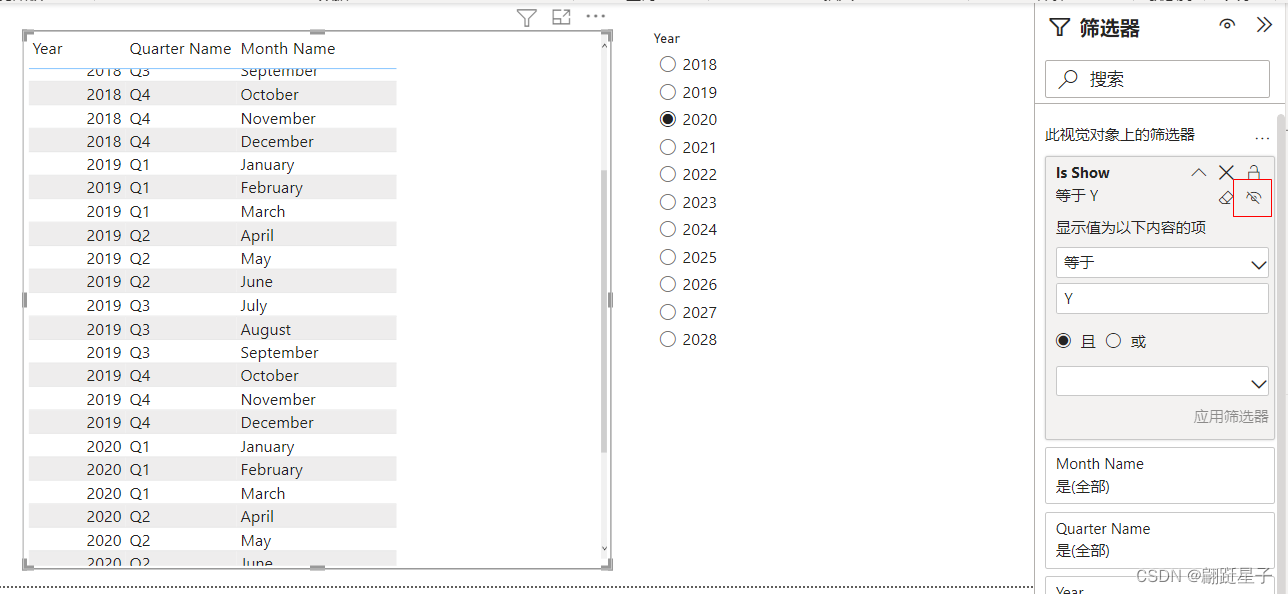
先说结论:
- VAE是AE的升级版,VAE也可以被看作是一种特殊的AE
- AE主要用于数据的压缩与还原,VAE主要用于生成。
- AE是将数据映直接映射为数值code(确定的数值),而VAE是先将数据映射为分布,再从分布中采样得到数值code。
- 损失函数和优化目标不同
AE(Auto Encoder, 自动编码器)
AE的结构
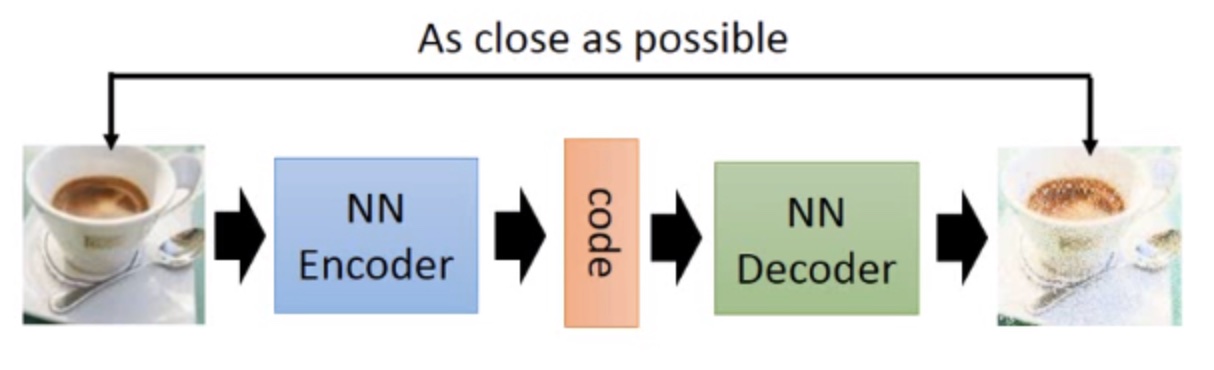
如上图所示,自动编码器主要由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器和解码器可以看作是两个函数,一个用于将高维输入(如图片)映射为低维编码(code),另一个用于将低维编码(code)映射为高维输出(如生成的图片)。这两个函数可以是任意形式,但在深度学习中,我们用神经网络去学习这两个函数。
这时候我们只要拿出Decoder部分,随机生成一个code然后输入,就可以得到一张生成的图像。但实际上这样的生成效果并不好(下面解释原因),因此AE多用于数据压缩,而数据生成则使用下面所介绍的VAE更好。
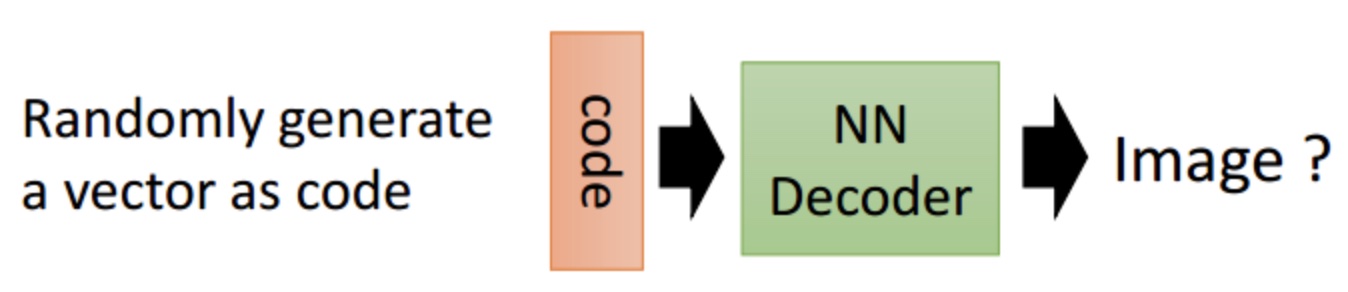
AE的缺陷
由上面介绍可以看出,AE的Encoder是将图片映射成“数值编码”,Decoder是将“数值编码”映射成图片。这样存在的问题是,在训练过程中,随着不断降低输入图片与输出图片之间的误差,模型会过拟合,泛化性能不好。也就是说对于一个训练好的AE,输入某个图片,就只会将其编码为某个确定的code,输入某个确定的code就只会输出某个确定的图片,并且如果这个code来自于没见过的图片,那么生成的图片也不会好。下面举个例子来说明:
假设我们训练好的AE将“新月”图片encode成code=1(这里假设code只有1维),将其decode能得到“新月”的图片;将“满月”encode成code=10,同样将其decode能得到“满月”图片。这时候如果我们给AE一个code=5,我们希望是能得到“半月”的图片,但由于之前训练时并没有将“半月”的图片编码,或者将一张非月亮的图片编码为5,那么我们就不太可能得到“半月”的图片。因此AE多用于数据的压缩和恢复,用于数据生成时效果并不理想。

如何解决AE的问题呢?
这时候我们转变思路,不将图片映射成“数值编码”,而将其映射成“分布”。还是刚刚的例子,我们将“新月”图片映射成μ=1的正态分布,那么就相当于在1附近加了噪声,此时不仅1表示“新月”,1附近的数值也表示“新月”,只是1的时候最像“新月”。将"满月"映射成μ=10的正态分布,10的附近也都表示“满月”。那么code=5时,就同时拥有了“新月”和“满月”的特点,那么这时候decode出来的大概率就是“半月”了。这就是VAE的思想。

VAE(Variational Auto-Encoder, 变分自动编码器)
VAE的结构

小结
- AE主要用于数据的压缩与还原,在生成数据上使用VAE。
- AE是将数据映直接映射为数值code,而VAE是先将数据映射为分布,再从分布中采样得到数值code。