目录
- 1 常规的队列构建
- 2 加入一些限制
- 2-1形式化说明
- 附录
- 0 双数组或双链表实现队列
- 1 单链表与循环缓冲区实现队列
- 3 参考资料
1 常规的队列构建
到火车站办理退票,排队的人构成队列。注意到有两个关键动作:
- 入队,即自觉站到队伍的末尾。
- 出队,从柜台离开。

单链表:先建立一个漂亮的柜员姐姐(哨兵或额外的头结点),记忆当前队列的第一个人,再来个尾指针,用于添加下一个人。
循环数组,也叫循环缓冲区,如图灰色部分就是队列的内容。

2 加入一些限制
现先引入新情境:考虑一种情况在函数式环境不能用变量来记录末尾,怎么办?
- 如果只能用链表实现(如Haskell语言),这时候入队必须遍历到末尾,时间复杂度
O(N) - 如果只能用数组实现(如BASIC语言),入队必须把所有元素往后移动,时间复杂度又是
O(N)
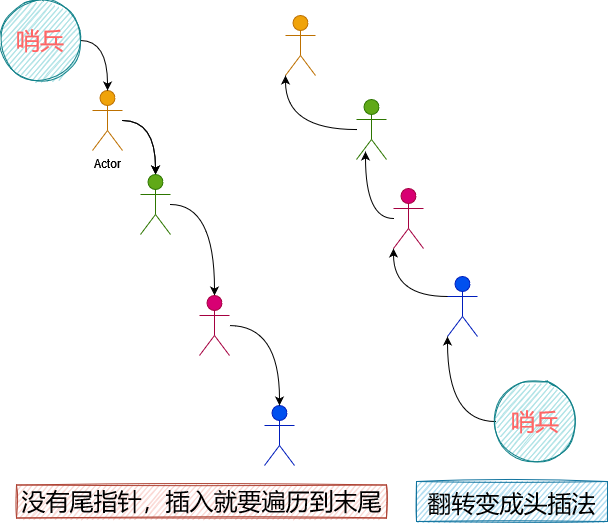
如上图所示,左边是原来的队列,右边是翻转后的队列。然后会出现几个问题:
- 在队伍末尾直接插入,是O(N)复杂度,虽然翻转后插入是O(1),但翻转不也是O(N)吗?
- 翻转后入队是O(N),那出队呢?再翻转回来吗?不是更麻烦了吗?
两个问题其实一个纠结在一个队列怎么能来回翻转呢?然而,我们可以用两个链表(或数组结构),一个只管出队,一个只管入队,只有在出队的队列为空,才把入队的队列翻转并放到出队(修改指针O(1)),可以看到本质是延时处理,翻转并不针对每次入队操作,其分摊性能可以降低为常数O(1)。
2-1形式化说明
说明:记入队的列表为F(Front),出队的队列为R(Rear),那完整的队列 Q ( F , R ) Q(F,R) Q(F,R),此外定义两个操作,设列表 X = { x 1 , x 2 , x 3 . . . } X=\{x_1,x_2,x_3...\} X={x1,x2,x3...},则
- 函数 t a i l ( X ) = { x 2 , x 3 , x 4 . . . } tail(X)=\{x_2,x_3,x_4...\} tail(X)={x2,x3,x4...}即去掉首个元素的剩余部分;
- 函数 b a l a n c e ( F , R ) = Q ( r e v e r s e ( R ) , ∅ ) : F = ∅ balance(F,R)=Q(reverse(R),\emptyset):F=\emptyset balance(F,R)=Q(reverse(R),∅):F=∅,此外当出队队列F不空,什么也不做。
此时,入队和出队操作定义如下:
p
u
s
h
(
Q
,
x
)
=
b
a
l
a
n
c
e
(
F
,
x
∪
R
)
p
o
p
(
Q
)
=
b
a
l
a
n
c
e
(
t
a
i
l
(
F
)
,
R
)
push(Q,x)=balance(F,{x} \cup R) \\ \\[2ex] pop(Q)=balance(tail(F),R)
push(Q,x)=balance(F,x∪R)pop(Q)=balance(tail(F),R) 实现是容易的代码放在附录,现在先点这里平摊分析,证明一下两个链表(或数组)的分摊性能的确是常数级别。只有出队操作可能引发翻转,尽管翻转的总复杂度是O(N),可只有几次,但O(1)出队操作却有N个,即均摊到每次出队操作上只有
O
(
1
)
=
O
(
N
)
/
N
O(1)=O(N)/N
O(1)=O(N)/N。
p
o
p
(
Q
)
=
{
O
(
N
)
,
L为空集
1
,
其他
pop(Q) = \begin{cases} O(N), & \text{L为空集} \\ 1, & \text{其他} \end{cases}
pop(Q)={O(N),1,L为空集其他
附录
队列的基本的方法说明:
- 判断是否非空? empty(
is_empty) - 入队 push 、(append、
push_back) - 出队 pop 、(tail、
pop_front) - 查看头部元素
front(head)
0 双数组或双链表实现队列
#include<iostream>
#include<vector>// 代替数组
#include<algorithm>// 翻转vector
using namespace std;
#define ERROR -1
using Key=int;
//定义节点
struct Node
{
Key key;
struct Node *nxt;
Node(Key k, struct Node *ptr = nullptr) : key(k), nxt(ptr) {}
};
using Nptr = struct Node *;
//定义链表
struct List{
Nptr sentry;//哨兵节点
List(){
sentry=new Node(-1);
}
};
class dualListQ
{
private:
List m_front;
List m_rear;
int balance();
Nptr reverse_list(Nptr head);//递归翻转链表
public:
bool is_empty() const;
void push_back(const Key &k) ;
void pop_front();
Key front();
};
int dualListQ::balance()
{
if(m_front.sentry->nxt!=nullptr) return 0;
if(m_rear.sentry->nxt==nullptr){
cerr<<"balance()-> queue is empty!"<<endl;
return ERROR;
}
m_front.sentry->nxt=reverse_list(m_rear.sentry->nxt);
m_rear.sentry->nxt=nullptr;
return 0;
}
//haed 指向哨兵的下一个节点
Nptr dualListQ::reverse_list(Nptr head){
//递归的出口:空链或只有一个结点,直接返回头指针
if (head == nullptr || head->nxt == nullptr)
{
return head;
}
else
{
//一直递归,找到链表中最后一个节点
Nptr new_head = reverse_list(head->nxt);
//当逐层退出时,new_head 的指向都不变,一直指向原链表中最后一个节点;
//递归每退出一层,函数中 head 指针的指向都会发生改变,都指向上一个节点。
//每退出一层,都需要改变 head->next 节点指针域的指向,同时令 head 所指节点的指针域为 NULL。
head->nxt->nxt = head;
head->nxt = nullptr;
//每一层递归结束,都要将新的头指针返回给上一层。由此,即可保证整个递归过程中,能够一直找得到新链表的表头。
return new_head;
}
}
bool dualListQ::is_empty() const
{
return m_front.sentry->nxt==nullptr&&nullptr==m_rear.sentry->nxt;
}
void dualListQ::push_back(const Key &k)
{
Nptr old_=m_rear.sentry->nxt;
Nptr new_=new Node(k);
m_rear.sentry->nxt=new_;
new_->nxt=old_;
if(ERROR==balance()) return;
}
void dualListQ::pop_front()
{
if(ERROR==balance()) return;
Nptr tmp=m_front.sentry->nxt;
m_front.sentry->nxt=tmp->nxt;
delete tmp;
}
Key dualListQ::front()
{
if(is_empty()){
cerr<<"front()-> queue is empty!"<<endl;
return ERROR;
}
if(m_front.sentry->nxt==nullptr){
balance();
}
return m_front.sentry->nxt->key;
}
class dualVectorQ
{
private:
vector<Key> m_front,m_rear;
int balance();
public:
bool is_empty() const;
int push_back(const Key &k) ;
void pop_front();
Key front();
};
int dualVectorQ::balance()
{
if(m_front.empty()){
if(m_rear.empty()){
cerr<<"balance()-> queue is empty."<<endl;
return ERROR;
}
reverse(m_rear.begin(),m_rear.end());
for(auto &k:m_rear){
m_front.push_back(k);
}
m_rear.clear();
}
return 0;
}
bool dualVectorQ::is_empty() const
{
return m_front.size()+m_rear.size()==0;
}
int dualVectorQ::push_back(const Key &k)
{
m_rear.push_back(k);
return 0;
}
void dualVectorQ::pop_front(){
balance();
m_front.pop_back();// 翻转后,队尾即对头
}
Key dualVectorQ::front(){
if(is_empty()){
cerr<<"front()-> Queue is empty..."<<endl;
return ERROR;
}
balance();
return m_front.back();// 翻转后,队尾即对头
}
#define see(x) cout<<x<<endl
void test(){
// dualListQ que;//创建空的队列
dualVectorQ que;
int arr[]={1,3,5,7,9};
for (size_t i = 0; i < 5; i++)
{
que.push_back(arr[i]);
}
see(que.front());//1
que.pop_front();
see(que.front());//3
que.pop_front();
que.pop_front();
que.pop_front();
if(que.is_empty())
see("queue is empty");//无
see(que.front());//9
que.pop_front();
if(que.is_empty())
see("queue is empty");//有
see(que.front());
}
int main(){
test();
return 0;
}
1 单链表与循环缓冲区实现队列
#include<iostream>
using namespace std;
#define ERROR -1
using Key=int;
class listQ
{
private:
struct Node
{
Key key;
struct Node* nxt;
Node(Key k,struct Node* ptr=nullptr):key(k),nxt(ptr){}
};
using Nptr=struct Node*;
Nptr m_sentry=nullptr;//头结点,指向真实的头一个数据
Nptr m_tail=nullptr;//指向尾节点
public:
listQ();//创建空队列
~listQ();
bool is_empty() const;
void push_back(const Key &k) ;
void pop_front();
Key front();
};
listQ::listQ()
{
m_sentry=new Node(-1);
m_tail=m_sentry;
}
listQ::~listQ()
{
while(!is_empty()){
pop_front();
}
delete m_sentry;
cout<<"over ..."<<endl;
}
bool listQ::is_empty() const
{
if(m_sentry->nxt==nullptr) return true;
return false;
}
void listQ::push_back(const Key &k)
{
Nptr new_node=new Node(k);
m_tail->nxt=new_node;
m_tail=new_node;
}
void listQ::pop_front()
{
Nptr tmp=m_sentry->nxt;
m_sentry->nxt=tmp->nxt;
delete tmp;
}
Key listQ::front()
{
if(is_empty()){
cerr<<"queue is empty!"<<endl;
return ERROR;
}
return m_sentry->nxt->key;
}
//循环缓冲区
class arrayQ
{
private:
static const size_t QSIZE=5;
Key m_buf[100];
int m_head=0;
int m_tail=0;//指向队列末尾下一个空位
int m_length=0;
public:
bool is_empty() const{ return 0==m_length;}
int push_back(const Key &k) ;
void pop_front();
Key front();
};
void arrayQ::pop_front(){
--m_length;
++m_head;
m_head -= (m_head < QSIZE) ? 0 : QSIZE;//模拟取余数,因为某些机器取余很慢
}
int arrayQ::push_back(const Key &k){
if(m_length==QSIZE){
cerr<<"push-> Queue is full!!"<<endl;
return ERROR;
}
m_buf[m_tail++]=k;
m_tail -=(m_tail < QSIZE) ? 0 : QSIZE;
++m_length;
return 0;
}
Key arrayQ::front(){
if(is_empty()){
cerr<<"front()-> Queue is empty..."<<endl;
return ERROR;
}
return m_buf[m_head];
}
#define see(x) cout<<x<<endl
void test(){
// listQ que;//创建空的队列
arrayQ que;
int arr[]={1,3,5,7,9};
for (size_t i = 0; i < 5; i++)
{
que.push_back(arr[i]);
}
// que.push_back(11);
see(que.front());//1
que.pop_front();
see(que.front());//3
que.pop_front();
que.pop_front();
que.pop_front();
see(que.is_empty());
see(que.front());//9
que.pop_front();
see(que.is_empty());
see(que.front());
}
int main(){
test();
return 0;
}
3 参考资料
刘新宇 《算法新解》