PyTorch典型函数之gather
- 作用描述
- 函数详解
- 典型应用场景
- (1) 深度强化学习中计算损失函数
- 参考链接
作用描述

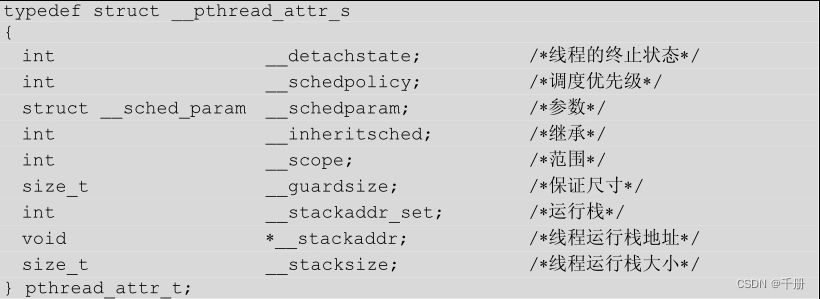
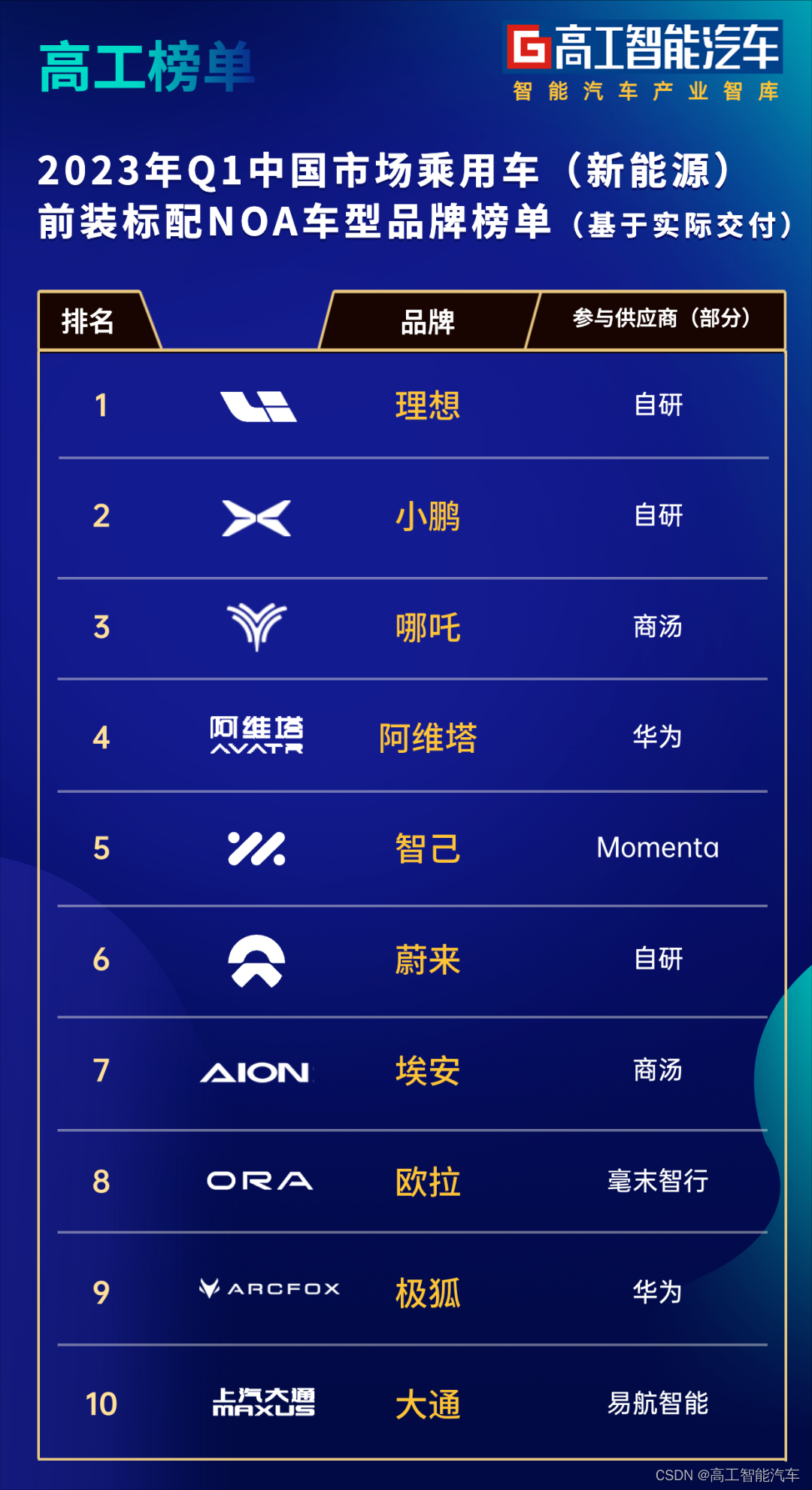
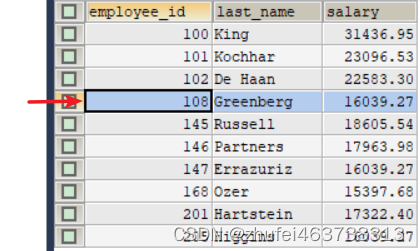
如上图所示,假如我们有一个Tensor A(图左),要从A中提取一部分元素组成Tensor B(图右),这时可以用torch.gather来实现:
>>> import torch
>>> t1 = torch.Tensor([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
>>> t2 = torch.gather(t1, 1, torch.tensor([[3,3],[0,2],[0,1]]))
>>> print(t2)
tensor([[ 4., 4.],
[ 5., 7.],
[ 9., 10.]])
图中每个方块代表一个值,图中数字代表这个值在该行中的序号,这里以dim=1,即按行提取为例。
对于二维Tensor而言,dim=0为按列提取,dim=1为按行提取。
函数详解
官网描述:
torch.gather(input, dim, index, *, sparse_grad=False, out=None) → Tensor
根据dim参数指定的轴来收集值。对于一个三维Tensor:
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
- 输入Tensor(input)和索引Tensor(index)必须维数一样。比如input给一个矩阵,index给个一维向量PyTorch就不知道要怎么办了。
- 对于所有
d != dim的维数d,需要满足index.size(d) <= input.size(d)。(原文It is also required thatindex.size(d) <= input.size(d)for all dimensionsd != dim.) - 输出Tensor和索引Tensor具有相同的形状。
- 输入Tensor(input)和索引张量不会互相广播。(原文Note that
inputandindexdo not broadcast against each other.)
参数:
input (Tensor)- the source tensordim (int)- the axis along which to indexindex (LongTensor)- the indices of elements to gather
参数名传参
sparse_grad (bool, optional)- IfTrue, gradient w.r.t.inputwill be a sparse tensor.out (Tensor, optional)- the destination tensor
此外,下面两种用法等价:
input_tensor = torch.Tensor([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
index_tensor = torch.tensor([[3,3],[0,2],[0,1]])
# 方法1
t1 = torch.gather(input_tensor , 1, index_tensor)
# 方法2
t2 = input_tensor.gather(1, index_tensor)
典型应用场景
(1) 深度强化学习中计算损失函数
在深度Q-network方法中,需要构建Q-network,并从经验区进行采样,根据采样计算损失函数并更新Q-network。
采样信息包括当前环境观测值(当前状态)和当前实际采取的行动。
之后根据当前环境观测值,通过Q-network计算各行为对应的Q值。
接下来用gather函数从各行为对应的Q值根据实际采取的行动提取其对应的Q值。
最后结合(1)根据实际行为计算出的当前状态Q值和(2)根据下一个环境观测值计算出的Q值进行MSELoss计算。
对应代码如下:
def calc_loss(batch, net, tgt_net, device='cpu'):
states, actions, rewards, dones, next_states = batch
states_v = torch.tensor(np.array(states, copy=False)).to(device) # 当前环境观察
next_states_v = torch.tensor(np.array(next_states, copy=False)).to(device) # 下一刻环境观察
actions_v = torch.tensor(actions, dtype=torch.int64).to(device) # 当前采取的行动
rewards_v = torch.tensor(rewards).to(device) # 采取当前行动后的奖励值
done_mask = torch.BoolTensor(dones).to(device)
# net(states_v)产生在输入环境为states_v情况下,各行动对应的Q值
# 从net(states_v)中提取实际选择的行动对应的Q值,用于后面和Q值公式计算出的Q值期望计算MSELoss
state_action_values = net(states_v).gather(1, actions_v.unsqueeze(-1)).squeeze(-1)
next_state_values = tgt_net(next_states_v).max(1)[0]
next_state_values[done_mask] = 0.0
next_state_values = next_state_values.detach()
expected_state_action_values = next_state_values * GAMMA + rewards_v
return nn.MSELoss()(state_action_values, expected_state_action_values)
参考链接
- torch.gather — PyTorch 2.0 documentation
- Deep-Reinforcement-Learning-Hands-On-Second-Edition