虽然 O2OA 数据表高效的表结构以及索引的设计已经极大程度地保障了数据存取操作的性能,但是随着使用时间从增长,数据表存放的数据量也会急剧增长。此时,仍然需要有合适的方案来解决数据量产生的系统性能瓶颈。本文介绍通过 PostgreSQL + Citus 来实现分布式数据方案来进一步提升 QRY_ITEM 表在大数据量数据存储中系统性能。基于 PostgreSQL 数据库,比如 KingBase,OpenGauss 等都可以通过相同的方式实现分布式数据存储。
一、O2OA 数据库支持类型
O2OA 底层依靠 Druid + JPA (OPENJPA) + 自定访问配置 (OPENJPA Dictionary) 实现对各种数据库的支持,目前支持 MySQL, PostgreSQL, Oracle, DB2, SQLServer, Sybase, Firebird 等数据库,也支持 KingBase, 南大通用, opengauss, 达梦, 神舟通用数据库, 对于其他数据库可以通过自定义 dictionary 来实现支持。
二、O2OA 数据库表介绍
O2OA 默认会创建 200 多张数据表来存储数据,其中大部分数据都集中存储在以下表中:
-
PP_C_TASK:流程平台待办
-
PP_C_TASKCOMPLETED:流程平台已办
-
PP_C_READ:流程平台待阅
-
PP_C_READCOMPLETED:流程平台已阅
-
PP_C_REVIEW:流程平台权限
-
PP_C_WORK:流程平台工作实例
-
PP_C_WORKCOMPLETED:流程平台已完成实例
-
CMS_DOCUMENT:内容平台文档实例
-
CMS_REVIEW:内容平台权限
-
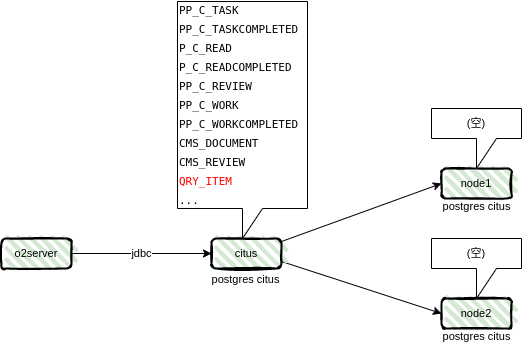
QRY_ITEM:流程平台和内容平台字段
尤其是 QRY_ITEM 表,流程平台以及内容平台中所有的字段值都分行单独存储在这个表中,这张表的数据量将会非常大。
虽然 QRY_ITEM 以及索引的设计已经极大程度地保障了数据存取操作的性能,但是随着使用时间从增长,QRY_ITEM 表存放了数以亿计的数据,仍然需要有合适的方案来解决数据量产生的系统性能瓶颈。
本文介绍通过 PostgreSQL + Citus 来实现分布式数据方案来进一步提升 QRY_ITEM 表在大数据量数据存储中系统性能。基于 PostgreSQL 数据库,比如 KingBase,OpenGauss 等都可以通过相同的方式实现分布式数据存储。
三、Citus 介绍
Citus 是 PostgreSQL 数据库的分布式中间件,用以解决 PostgreSQL 横向扩展问题,旨在帮助应对大规模数据集和高并发负载,以支持更大的数据量、更大的写入和查询性能。
Citus 允许将数据水平分片,并将其分布在多个节点上,从而使查询可以并行执行,以提高查询性能。
Citus 还提供了用于数据分区、复制和故障转移的工具,以确保高可用性和数据安全性。
此外,Citus 支持在 PostgreSQL 上使用常见的 SQL 功能,例如外键约束、触发器和索引等。
Citus 还提供了一些高级功能,例如跨分片的查询和分布式事务等,这些功能可以让开发人员更容易地处理大规模数据集。
四、方案目标介绍
实现分布式数据存储。在安装配置步骤我们将实现以下目标:
在分布式存储配置步骤我们将实现以下目标:
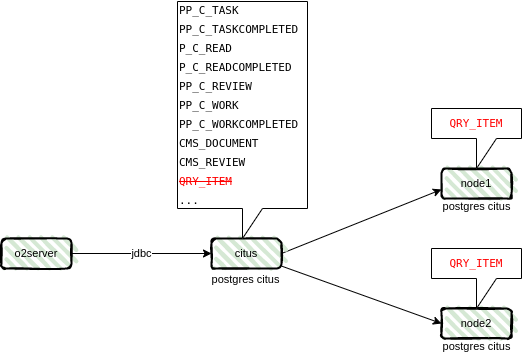
五、安装配置介绍
1、服务器准备
下面我们进行安装演示说明,我们一共准备了 4 台服务器用于安装整个环境,服务器说明如下:
| 服务器 | 地址 | 用途 | 操作系统 |
| O2OA | 172.16.91.59 | O2OA 应用服务器 | Ubuntu 22.04 |
| Citus | 172.16.91.60 | PostgreSQL Citus 服务器 | Ubuntu 22.04 |
| node1 | 172.16.91.61 | PostgreSQL Citus 工作节点 1 | Ubuntu 22.04 |
| node2 | 172.16.91.62 | PostgreSQL Citus 工作节点 2 | Ubuntu 22.04 |
2、安装 Postgresql
这个步骤我们将在 Citus, node1, node2 服务器上安装全新的 PostgreSQL 数据库。
在后面的步骤里,我们还要在这 3 台服务器上安装 Citus,所以需要安装和 Citus 版本所匹配的 PostgreSQL 版本。
由于 Ubuntu 仓库中默认的 PostgreSQL 版本比较老,所以我们通过 Postgresql 仓库安装 PostgreSQL 15。
需要在 3 台服务器上都安装同样版本的 PostgreSQL,我们在 3 台服务器上分别进行以下操作。
1)导入 PostgreSQL 仓库配置:
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
2)导入仓库签名密钥:
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
3)更新软件包列表:
sudo apt-get update
4)安装 Postgresql 15:
sudo apt-get -y install postgresql
3、安装 Citus
我们先跳过 Postgresql 初始化配置,先在 3 台数据库服务器上分别安装 Citus,后面在统一进行配置.
Citus 没有在 Ubuntu 默认仓库中,我们需要先把仓库地址加入进来再安装 Citus。
1) 下载仓库安装脚本,在当前用户的 home 目录下执行:
curl https://install.citusdata.com/community/deb.sh > add-citus-repo.sh
2) 执行脚本将仓库加入,执行后会自动执行 apt update:
sudo bash add-citus-repo.sh
3) 执行安装操作,这里需要保持版本对应 postgresql-15-citus-11.3 指 PostgreSQL 15 版本 citus 11.3 版本
sudo apt-get -y install postgresql-15-citus-11.3
至此我们就完成了安装的步骤了,后续的步骤我们将进行一些必要的配置。
4、数据库服务器配置
我们需要在 3 台数据库服务器上分别执行命令以完成数据库配置。
1) 编辑 PostgreSQL 配置文件,设置允许远程访问,使用 Citus 插件:
sudo nano /etc/postgresql/15/main/postgresql.conf
在文件的最后加入三行配置:
shared_preload_libraries = 'citus' # 启用 citus
listen_addresses = '*' #允许远程访问
citus.shard_count = 256 # 默认分片数量设置为 256,这里需要注意的是一个工作节点对应多个 shared,shared 应该远大于最大分片数量,所以直接把 shared_count 设置为 256。
shared_preload_libraries = 'citus' listen_addresses = '*' citus.shard_count = 256
2) 设置客户认证文件 (pg_hba.conf),允许远程访问
sudo nano /etc/postgresql/15/main/pg_hba.conf
在文件最后加入两行,请注意两行的顺序,先匹配生效。
host all all 172.16.91.1/24 trust #3 台数据库服务器之间相互信任访问。
host all all 0.0.0.0/0 scram-sha-256 #允许用户通过用户名密码访问。
host all all 172.16.91.1/24 trust host all all 0.0.0.0/0 scram-sha-256
3) 配置完成后重启 PostgreSQL 服务,并将 PostgreSQL 加入到启动任务
sudo systemctl restart postgresql sudo systemctl enable postgresql
5、设置服务器管理员密码,并创建 citus 表
需要在 3 台数据库服务器上执行数据库命令来修改管理员口令以及执行 citus 创建。
需要注意的是 citus 数据库是独立的,不同的数据库需要单独运行创建命令。默认情况下都是在 PostgreSQL 数据库下执行。
1) 进入到 psql 命令行模式:
sudo -u postgres psql
2) 在进入到 psql 命令行模式后在 psql 命令行模式下执行修改密码的命令:
ALTER USER postgres PASSWORD 'password';

3) 继续在 psql 命令行模式下执行创建扩展 citus 的命令:
CREATE EXTENSION citus;

这里需要注意的是 citus 是在数据库层面的设置,不同的数据库需要单独执行创建。
当前是在默认数据库 postgres 下。如果创建了新数据库需要在切换到新数据库再去执行创建命令。可以用 c 命令切换数据库。
c database
6、配置 Citus 节点
下面的操作仅在 Citus 服务器上执行,设置协作节点,并把 node1 和 node2 服务器作为工作节点加入进来。
1) 在加入工作节点 node1 和 node2 之前先设置 citus 服务器为协调服务器:
SELECT citus_set_coordinator_host('172.16.91.60', 5432);
2) 将两个工作节点加入到集群中:
SELECT citus_add_node('172.16.91.61', 5432);
SELECT citus_add_node('172.16.92.62', 5432);
3) 运行以下命令可以看到两个工作节点:
SELECT * FROM citus_get_active_worker_nodes();
如果添加错误可以执行进行删除:
SELECT citus_remove_node('172.16.91.61', 5432);

至此我们所有的数据安装及配置已经全部完成,后面我们将测试分布式数据库。
六、测试分布式存储方案
1、创建数据库
我们先使用数据库客户端软件来创建到 3 个数据库 o2oa 的连接,以便后续步骤观察数据变化:

使用自己熟悉的工具就可以了,使用 JDBC 连接。
依上图所示,现在可以看到 3 个数据库都可以正常连接上了。
2、配置并启动 O2OA 服务器
在前面准备的应用服务器上启动一个 O2OA。
具体配置 O2OA 外部数据源以及启动 O2OA 的步骤就不再赘述,请参考相应的技术文档。
配置使用外部数据源配置 externalDataSources.json:
[
{
"url": "jdbc:postgresql://172.16.91.60:5432/postgres",
"schema": "public",
"username": "postgres",
"password": "password",
"includes": [],
"excludes": [],
"enable": true,
"statEnable": false
}
]
这样我们就使用了 Citus 服务器作为数据库服务器。
启动 O2OA 服务器,启动完成后我们应该可以看到在 Citus 服务器上已经创建了使用到的表。

到这里 O2OA 服务器已经正常启动了,这里要特别说明的是现在所有数据都是存放在 Citus 服务器上的,就和单独只有一个 Citus 服务器没有区别,两个 work 节点都处于空跑状态并没有集群效果,没有装载任何数据。
3、在 O2OA 中生成一些数据
我们以 QRY_ITEM 表为例来演示。
先在服务器上创建一个流程,并创建一个实例,这样在 QRY_ITEM 表中就有数据了,大家也可以使用其他方式自行验证。
1) 创建人员和组织
2) 创建表单
3) 创建流程

4) 创建流程实例并流转
这样我们就可以看到在 Citus 数据库服务器的表里已经有了完整的数据

4、对 QRY_ITEM 表进行分布式存储设置
我们再次进入到 Citus 数据库服务器的命令行中运行以下命令:
sudo -u postgres psql
进入到 psql 命令行界面,执行 c o2oa 切换到 o2oa 数据库
c o2oa
执行创建分布表命令:其中地 1 个参数是表名,第 2 个参数是计算分布的字段,这里我们取 xid,最后是使用 hash 方式进行计算。
SELECT create_distributed_table('qry_item', 'xid', 'hash');

依上图所示,提示分布表已经创建。
打开数据库链接可以看到数据已经分布式存放在了 node1 和 node2 节点中。
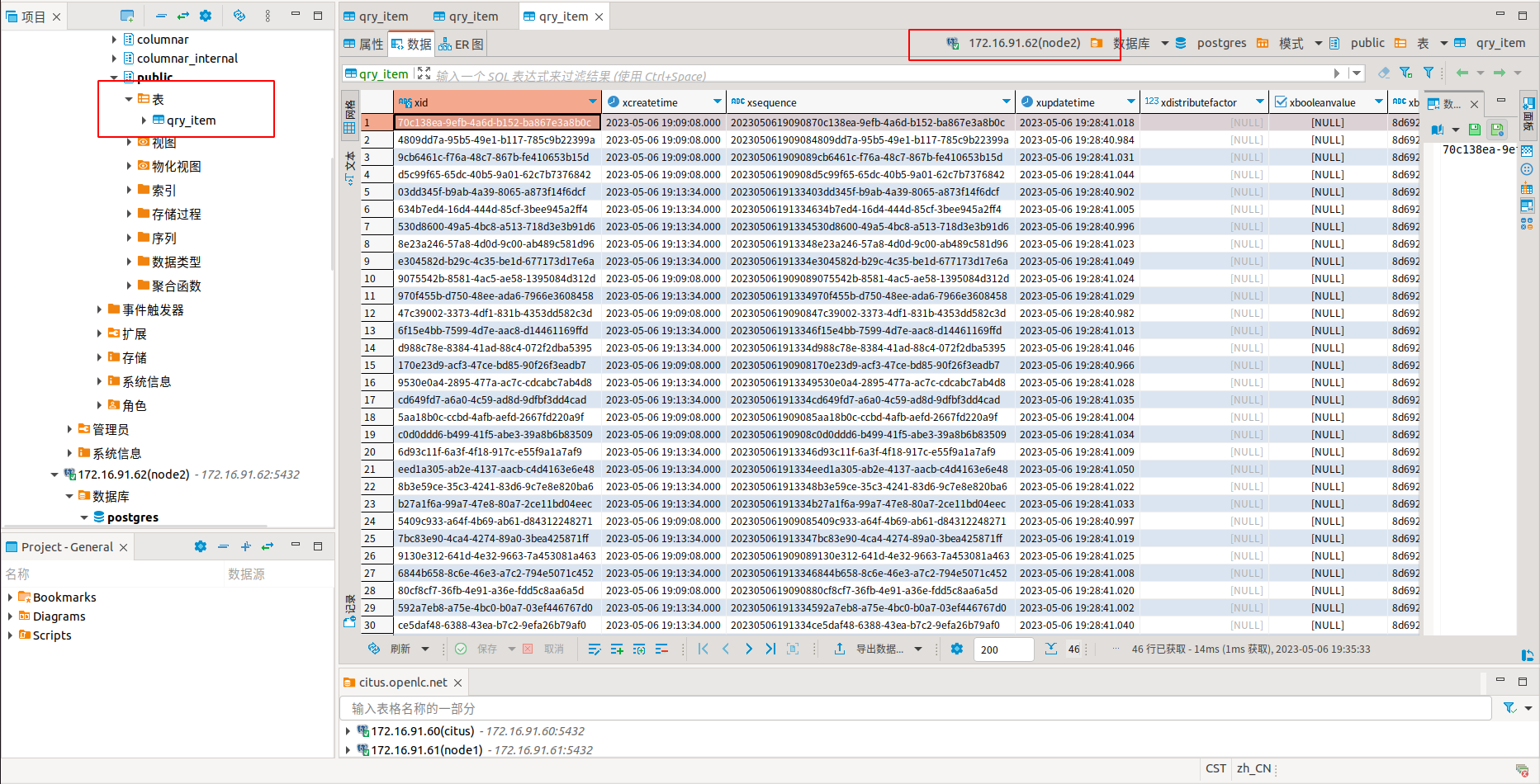
通过命令可以查看到表的 shared 分布
select * from pg_dist_shard;

我们再次进入到业务流程并不影响数据访问和存储。
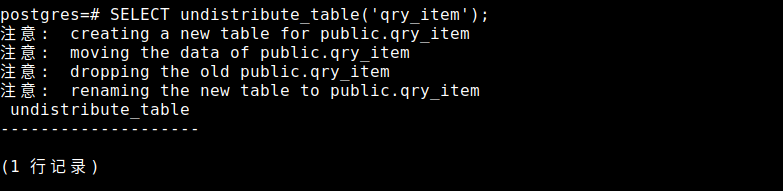
5、回退已分布式存储的 QRY_ITEM 表
对于已经进行了分布式存储的表,如果需要回退可以执行以下操作:
SELECT undistribute_table('qry_item');

至此我们完成了数据库表的分布以及回退,大家可以在实际环境中灵活的根据数据表的数据规模来进行分布式收缩策略希望以上内容对大家有帮助,谢谢关注!