系列文章目录
Flink第一章:环境搭建
Flink第二章:基本操作
文章目录
- 系列文章目录
- 前言
- 一、Source
- 1.读取无界数据流
- 2.读取无界流数据
- 3.从Kafka读取数据
- 二、Transform
- 1.map(映射)
- 2.filter(过滤)
- 3.flatmap(扁平映射)
- 4.keyBy(按键聚合)
- 5.reduce(归约聚合)
- 6.UDF(用户自定义函数)
- 7.Rich Function Classes(富函数类)
- 总结
前言
Flink的基本操作分为三类,Source,Transform,sink,分别负责数据的读取,转换和写入,现在来学习一些常用的api.
一、Source
添加需要的pom依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1.0-1.17</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
创建文件
1.读取无界数据流
SourceBoundedTest.scala
package com.atguigu.chapter02.Source
import org.apache.flink.streaming.api.scala._
case class Event(user:String,url:String,timestamp:Long)
object SourceBoundedTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//1.从元素中读取数据
val stream: DataStream[Int] = env.fromElements(1, 2, 3, 4, 5)
val stream1: DataStream[Event] = env.fromElements(Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L)
)
//2.从集合中读取数据
val clicks: List[Event] =List(Event("Mary", "./home", 1000L),Event("Bob", "./cart", 2000L))
val stream2: DataStream[Event] = env.fromCollection(clicks)
//3.从文本文件中读取
val stream3: DataStream[String] = env.readTextFile("input/clicks.txt")
//打印输出
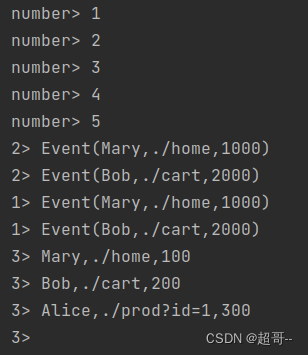
stream.print("number")
stream1.print("1")
stream2.print("2")
stream3.print("3")
env.execute()
}
}
2.读取无界流数据
自定义数据源
ClickSource.scala
package com.atguigu.chapter02.Source
import org.apache.flink.streaming.api.functions.source.SourceFunction
import java.util.Calendar
import scala.util.Random
class ClickSource extends SourceFunction[Event] {
//标志位
var running = true
override def run(sourceContext: SourceFunction.SourceContext[Event]): Unit = {
//随机生成器
val random = new Random()
val users: Array[String] = Array("Mary", "Alice", "Cary")
val urls: Array[String] = Array("./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2", "./prod?id=3")
//标志位结束循环
while (running) {
val event: Event = Event(user = users(random.nextInt(users.length)), url = urls(random.nextInt(users.length)), timestamp = Calendar.getInstance.getTimeInMillis)
sourceContext.collect(event)
//休眠1s
Thread.sleep(1000)
}
}
override def cancel(): Unit = running = false
}
读取数据
SourceCustomTest.scala
package com.atguigu.chapter02.Source
import org.apache.flink.streaming.api.scala._
object SourceCustomTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.addSource(new ClickSource)
stream.print()
env.execute()
}
}
程序会实时打印收到的数据

3.从Kafka读取数据
package com.atguigu.chapter02.Source
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.streaming.api.scala._
object SourceKafkaTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val source: KafkaSource[String] = KafkaSource.builder()
.setBootstrapServers("hadoop102:9092")
.setGroupId("consumer-group")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setTopics("clicks")
.build()
val stream: DataStream[String] = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source")
stream.print()
env.execute()
}
}
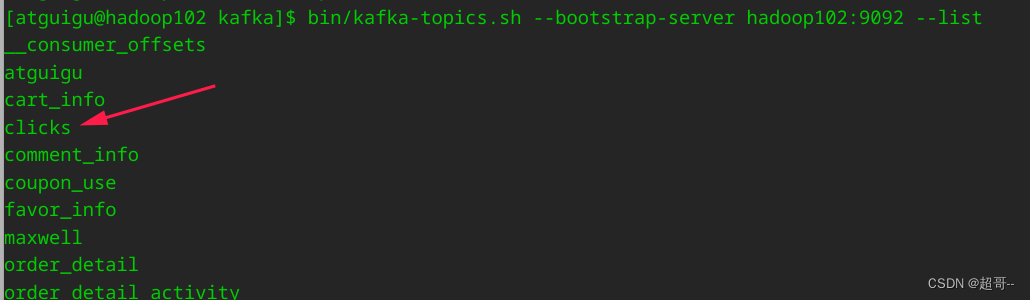
运行程序然后生产数据
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic clicks

Flink的支持的读取源有很多,这里只是随便举个例子,具体信息可以看官方文档.

二、Transform
1.map(映射)
TransformMapTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
object TransformMapTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L)
)
//Map函数
//1.匿名函数
stream.map(_.user).print("1")
//2.MapFunction接口
stream.map(new UserExtractor).print("2")
env.execute()
}
class UserExtractor extends MapFunction[Event, String] {
override def map(t: Event): String = t.user
}
}

package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala._
object TransformFilterTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L)
)
//Filter
stream.filter(_.user == "Mary").print("1")
stream.filter(new UserFilter).print("2")
env.execute()
}
class UserFilter extends FilterFunction[Event] {
override def filter(t: Event): Boolean = t.user == "Bob"
}
}

3.flatmap(扁平映射)
TransformFlatmapTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object TransformFlatmapTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L)
)
stream.flatMap(new MyFlastMap).print()
env.execute()
}
class MyFlastMap extends FlatMapFunction[Event, String] {
override def flatMap(t: Event, collector: Collector[String]): Unit = {
if (t.user == "Mary") {
collector.collect(t.user)
}
else if (t.user == "Bob") {
collector.collect(t.user)
collector.collect(t.url)
}
}
}
}
4.keyBy(按键聚合)
TransformAggTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala._
object TransformAggTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Alice", "./cart", 7000L),
Event("Bob", "./prod?id=1", 4000L),
Event("Bob", "./prod?id=2", 8000L),
Event("Bob", "./prod?id=4", 4000L),
Event("Bob", "./prod?id=6", 3000L),
)
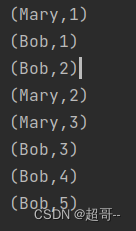
stream.keyBy(_.user).max("timestamp").print("1")
stream.keyBy(new MyKeySelector()).max("timestamp")
.print("2")
env.execute()
}
class MyKeySelector() extends KeySelector[Event, String] {
override def getKey(in: Event): String = in.user
}
}

5.reduce(归约聚合)
TransformReduceTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
object TransformReduceTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Bob", "./cart", 3000L),
Event("Mary", "./cart", 7000L),
Event("Mary", "./prod?id=1", 4000L),
Event("Bob", "./prod?id=2", 8000L),
Event("Bob", "./prod?id=4", 4000L),
Event("Bob", "./prod?id=6", 3000L),
)
// reduce 聚合
stream.map(data => (data.user, 1L))
.keyBy(_._1)
.reduce(new Mysum()) //统计用户活跃度
.keyBy(data => true) //将所有数据合并到同一个组
.reduce((state, data) => if (data._2 >= state._2) data else state)
.print()
env.execute()
}
class Mysum() extends ReduceFunction[(String, Long)] {
override def reduce(t: (String, Long), t1: (String, Long)): (String, Long) = (t._1, t._2 + t1._2)
}
}
6.UDF(用户自定义函数)
TransformUDFTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala._
object TransformUDFTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
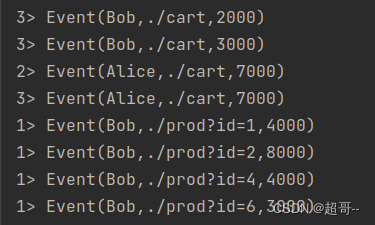
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Bob", "./cart", 3000L),
Event("Alice", "./cart", 7000L),
Event("Bob", "./prod?id=1", 4000L),
Event("Bob", "./prod?id=2", 8000L),
Event("Bob", "./prod?id=4", 4000L),
Event("Bob", "./prod?id=6", 3000L),
)
//测试UDF的用法,筛选url中包含摸个关键字 /home
//1.实现自定义函数类
stream.filter(new MyFilterFunction()).print("1")
//2.使用匿名类
stream.filter(new FilterFunction[Event] {
override def filter(t: Event): Boolean = t.user.contains("Alice")
}).print("2")
//3.使用lambda表达式
stream.filter(_.url.contains("cart")).print("3")
env.execute()
}
class MyFilterFunction extends FilterFunction[Event] {
override def filter(t: Event): Boolean = t.url.contains("prod")
}
}
7.Rich Function Classes(富函数类)
可以理解为自定义函数的升级版,可以在线程开始之前和结束之后做更多的工作,常用于链接数据库.
TransformRichFunctionTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object TransformRichFunctionTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Bob", "./cart", 3000L),
Event("Alice", "./cart", 7000L),
Event("Bob", "./prod?id=1", 4000L),
Event("Bob", "./prod?id=2", 8000L),
Event("Bob", "./prod?id=4", 4000L),
Event("Bob", "./prod?id=6", 3000L),
)
//自定义RichMapFunction
stream.map(new MyRich).print("1")
env.execute()
}
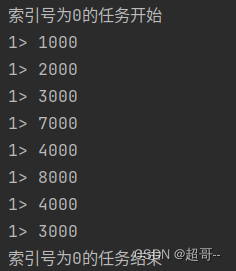
class MyRich extends RichMapFunction[Event,Long]{
override def open(parameters: Configuration): Unit = {
println("索引号为"+getRuntimeContext.getIndexOfThisSubtask+"的任务开始")
}
override def map(in: Event): Long = in.timestamp
override def close(): Unit = {
println("索引号为"+getRuntimeContext.getIndexOfThisSubtask+"的任务结束")
}
}
}
总结
这里的内容比较多,下次博客继续写.






![PMP项目管理-[第十三章]相关方管理](https://img-blog.csdnimg.cn/7db9ede0975841a588bc11853a625727.png)