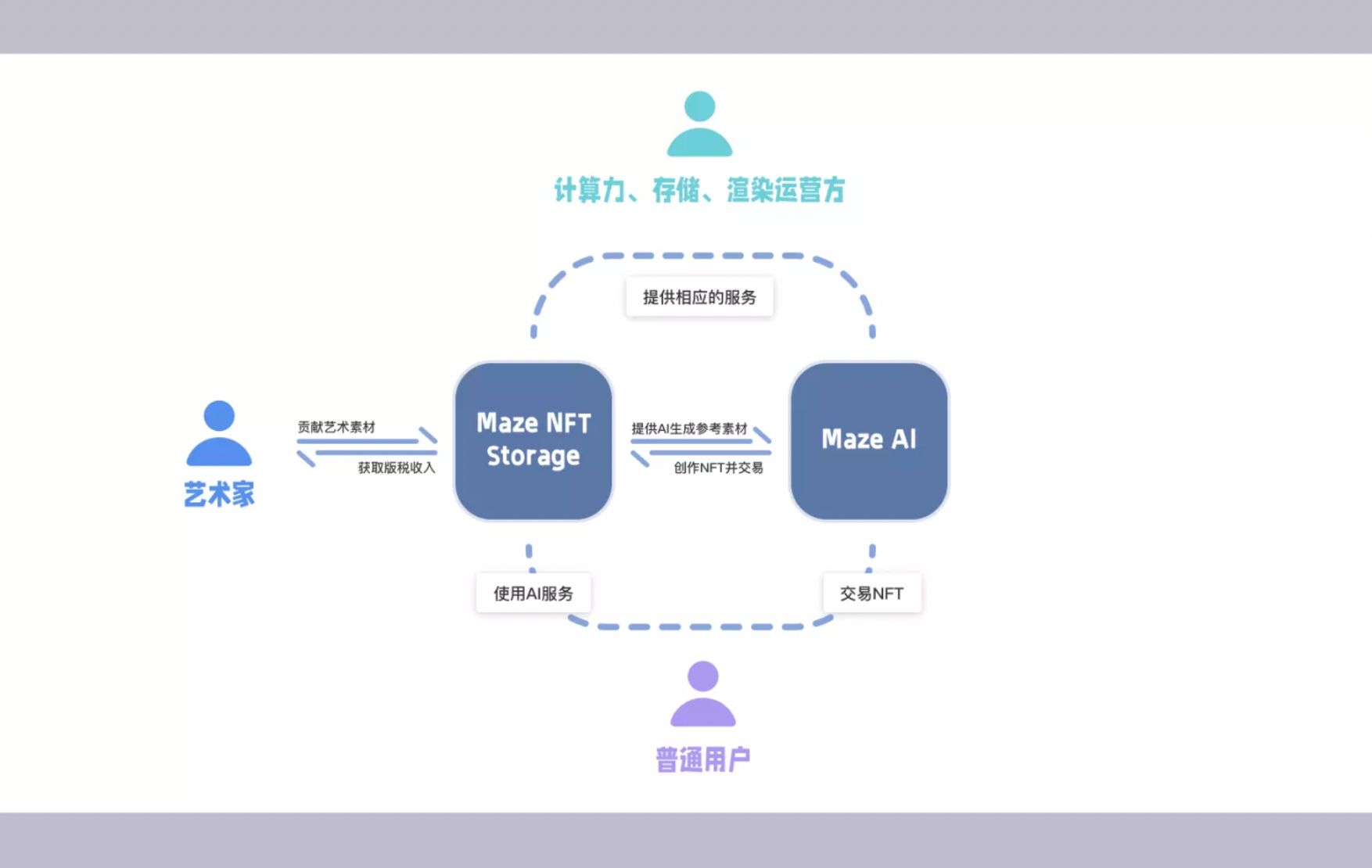
文章目录
- 摘要
- 1 研究背景
- 1.1 主要研究内容
- 1.2 研究背景
- 1.3 启发
- 2 基于改进BORDA投票法的多度量水文时间序列相似性分析
- 2.1 研究方法
- 2.2 BORDA投票法的改进
- 2.2.1 BORDA 的缺点
- 2.2.2 改进的BORDA投票法
- 3 实验验证与分析
- 3.1 实验数据
- 3.2 实验结果分析
- 4 结语
多度量组合可以提高相似性分析的准确性。

摘要
- 多度量组合可以提高相似性分析的准确性
- 本文方法:首先使用多个单一相似度量分别计算相似时间子序列;然后采用改进的BORDA投票法对各度量分析得到的相似子序列进行组合和排序,得到最终的相似时间子序列。
1 研究背景
1.1 主要研究内容
主要是研究水文时间序列相似性;
目前是k个最近邻水文过程发现,特别是洪水过程的相似性。
1.2 研究背景
众多学者结合水文时间序列的特点,进行了水文时间序列相似性的研究。
-
李薇 《水文时间序列相似性查询的分析与研究》
抽取时间序列的模式特征(包括长度和斜率),然后借鉴动态弯曲的思想定义序列之间的动态模式匹配距离(DPM) -
欧阳如琳《水文时间序列的相似性搜索研究》
采用DTW距离计算流域内多水文站之间相似性洪水过程,发现流域的洪水过程形态。 -
朱跃龙《基于语义相似的水文时间序列相似性挖掘》
提出基于语义的水文时间序列相似性度量,定义水文时间序列的上升、保持和下降等语义模式,在此基础上,定义序列的语义距离描述序列的相似程度。

- 李士进 《基于BORDA计数法的多元水文时间序列相似性分析》
针对多维水文时间序列相似性,李士进首先逐维进行一元时间序列相似性分析,然后采用BORDA投票法对各维的相似子序列进行组合和排序,获取多维相似子序列。

1.3 启发
目前水文时间序列相似性所示大多采用单一相似度量来评价序列之间的相似性。
[11-12]文献提出多度量相似性分析,采用启发式搜索确定各度量的权重,相似距离为各度量距离的加权和。

2 基于改进BORDA投票法的多度量水文时间序列相似性分析
2.1 研究方法
-
串行组合处理
-
并行组合处理
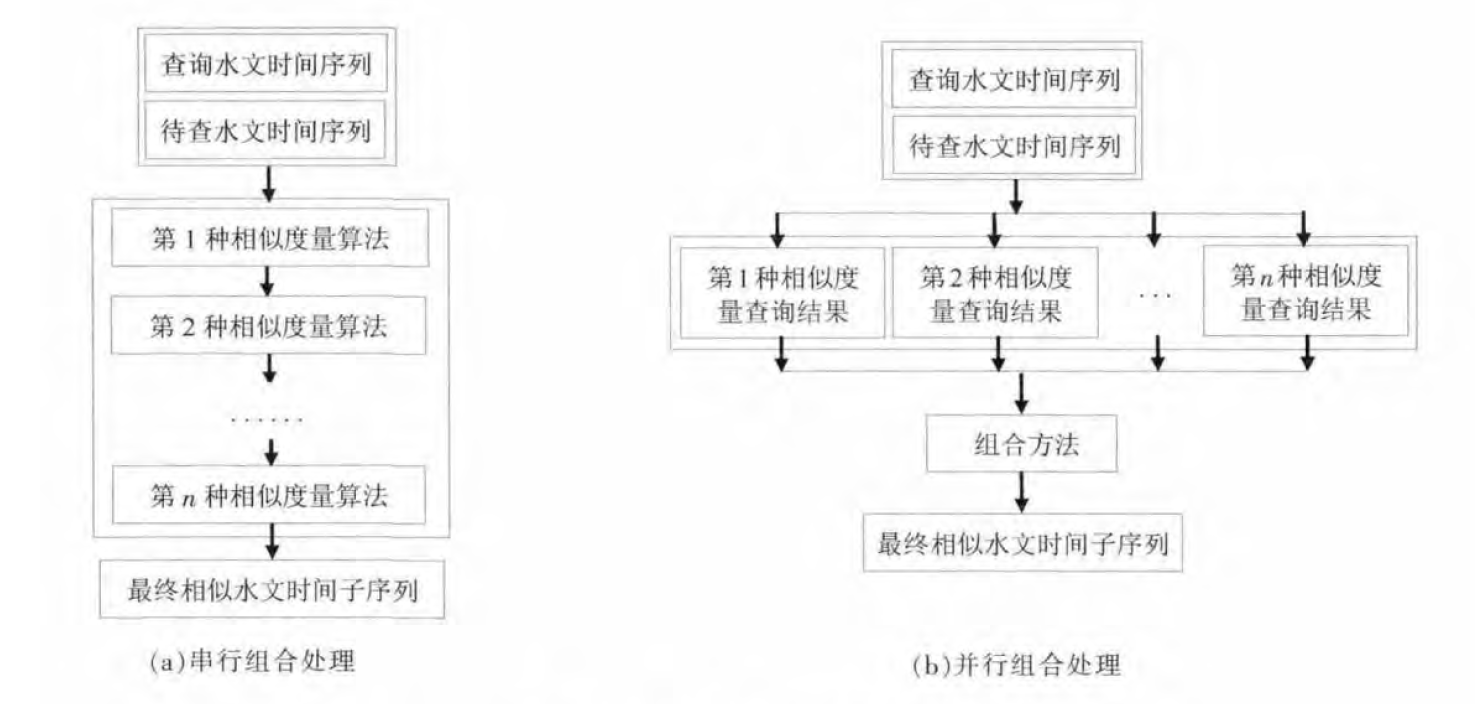
-
本文关注h近邻搜索问题,即查询与指定序列最相似的前k个子序列从分类角度来看,k近邻相似搜索可以视为采用相似度量将时间子序列划分为第1相似子序列、第2相似子序列…,第h相似子序列以及不相似子序列。(也就是说,前k个都是相似的,后面都是不相似的)
-
本文采用改进的BORDA投票法,对多个单一相似度量算法计算得到的相似子序列进行并行组合,得到最终的k近邻子序列。
2.2 BORDA投票法的改进
2.2.1 BORDA 的缺点
本文指定:针对每个投票人的排序,给每个候选人设定一个排序分数,规定排在最后的候选人的排序分数为1分,倒数第2位的候选人为2分,依次类推,排在第1位为p分,候选人的排序分数的累积称为BORDA分数,BORDA分数进入前m名的候选称作BORDA胜者。
BORDA投票法只考虑所有候选人排序先后,没有考虑前后候选人差距的大小,这样可能造成无法计算出真实的排序。【啥意思啊,看不懂啊,候选人差距的大小?感觉根据例子是投票人差距大小吧阿巴阿巴】
如假设,有A、B.C、D四匹马进行四场比赛,四场比赛名次排序分别为:A、B C、D,B、A、D、C,D、C、A、B和C、D、B、A。四匹赛马BORDA分数都为10分,出现了四匹赛马并列第一名的情况,因为BOR-DA投票法仅考虑四匹马的名次排序,而没有考虑各匹马在比赛时成绩的具体差异。
2.2.2 改进的BORDA投票法


- 那么我就自然地提出我的问题了:第一d1 、d2、d3等等是如何确定的?第二 候选人差距是否可以量化是如何确定的?
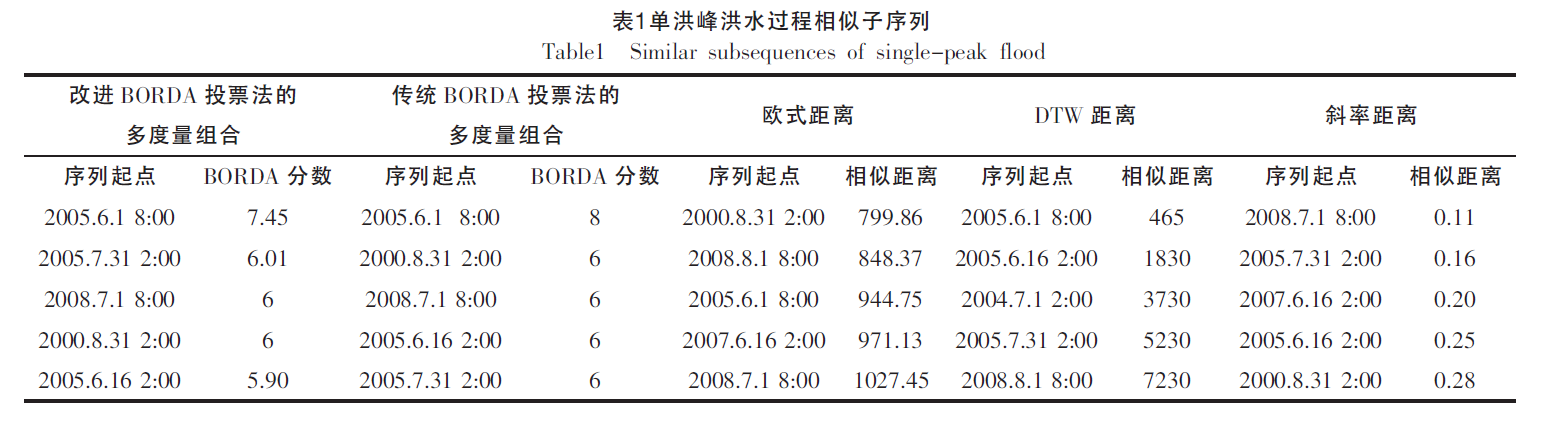
在各单一相似度量的查询结果中,出现次数越多,说明其被越多的相似度量认可为相似子序列,其改进BORDA分数将可能越高;若只是在单一相似度量的查询结果靠前,说明可能只是被单一的度量认为是相似子序列,其改进BORDA分数可能不高。
因此,相比于单一相似度量,多度量组合可以在结果中包含参与组合的多个单一相似度量结果中的优秀结果,从而提高相似搜索的准确性。
3 实验验证与分析
- 为什么选择这一流域的这一个水文站?

3.1 实验数据
- 这里的实验数据介绍的还是很清楚的。

- 首先可以看到是11年间的,6-9这四个月的流量数据(标题中的水文序列就是指的是流量序列,水文数据包括了流量数据、水文数据、降水量数据等等),每天是四个检测时间点,也就是说(这里是大概算了一下数据量)
11年 * 4个月 * 30天 * 4个时间点 = 5280个数据点这些数据都是连续的记录型数据,但是要注意的是,这里是洪水过程相似性分析,应该是要对5千个数据点按照一场洪水为单位去划分的,每场洪水大概持续多少天然后大概几十到一百多的流量数据能刻画出一场洪水。
3.2 实验结果分析
- 这里介绍了查询序列,任务就是在数据库中查询出与之相似的序列。
- 可以看到这个洪水是7月31日到8月29日,
30天*4个数据点,流量序列的长度就是120

- 看表1,这里可以看出洪水的流量序列是被等长切分的,也就是说没有按照单场洪水来划分,而是简单处理成30天的长度,应该是作者想要方便实现和方便计算。
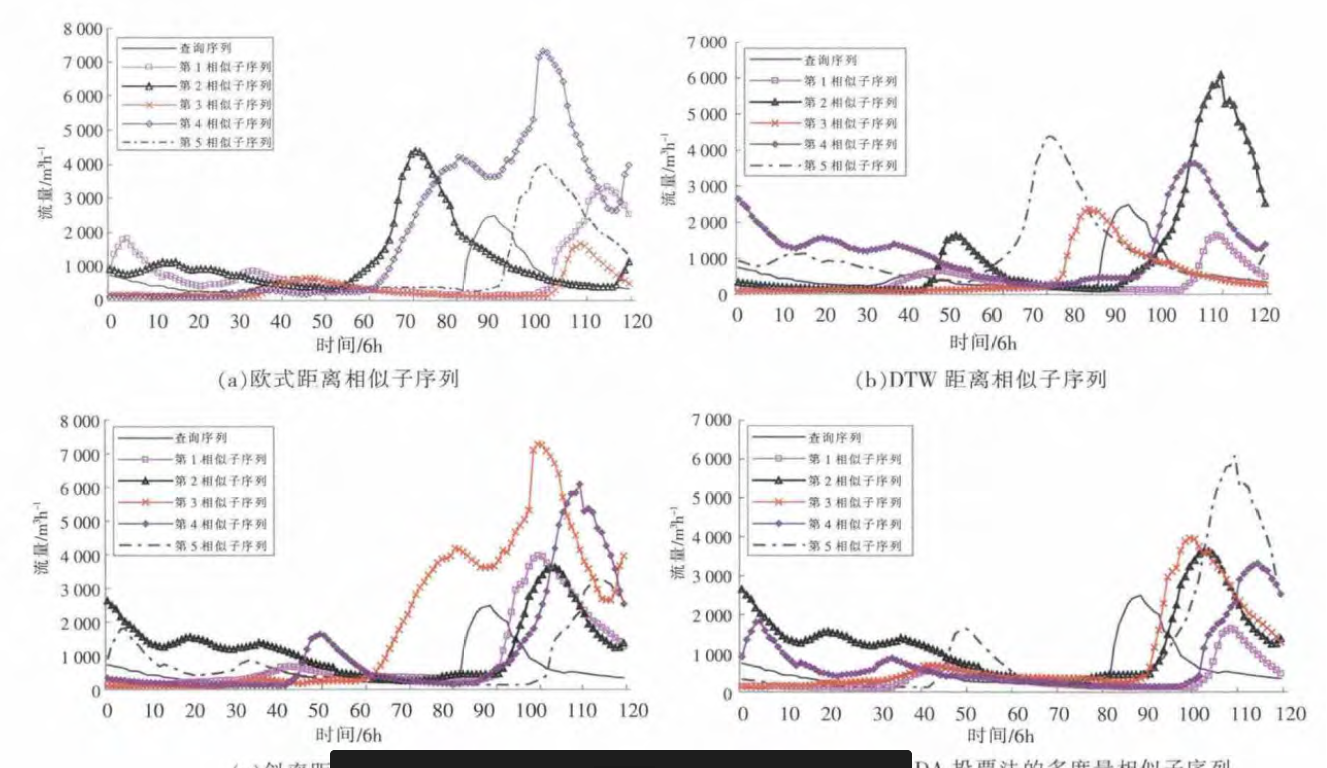
- 实验二:双洪峰M型洪水相似性分析
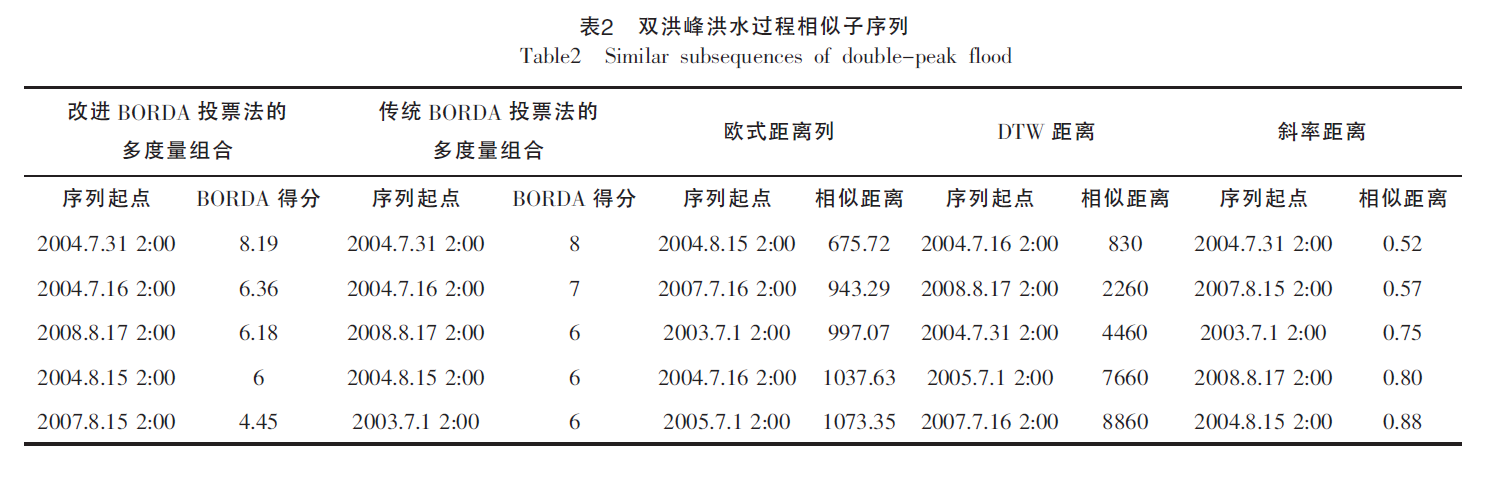
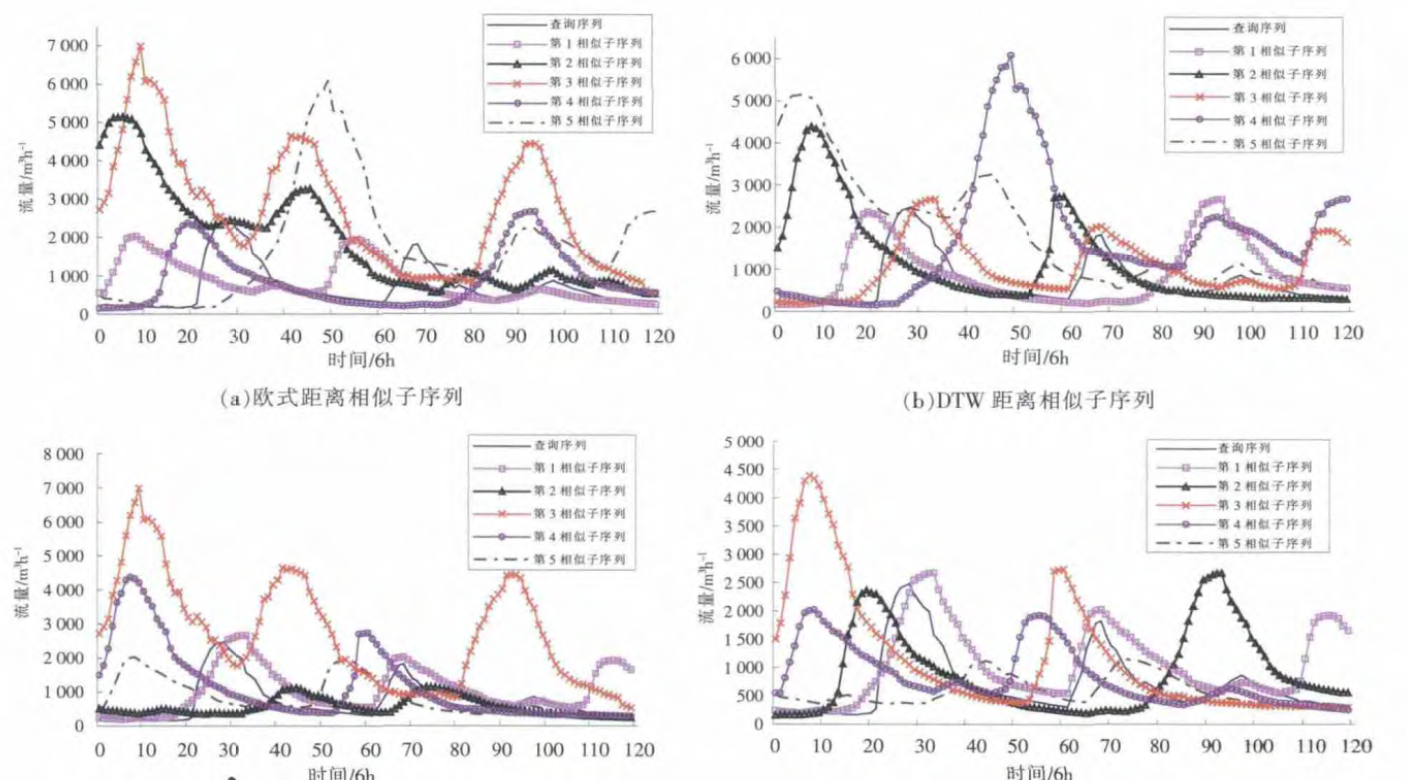
- 分析就不放上来了,无非就是这四种方法不好,然后自己提出的改进BORDA方法好。
4 结语