Scala中的数据结构和Java中一样,都有数组,列表,集合,映射。在Scala中与Java不同的是数组可以有可变数组,而不是一旦定义就不可以进行更改。我们来认识数组,并使用相应的代码去查看具体的实现效果。
目录
数组
1,不可变数组
1)静态声明
2)动态声明
2,可变数组
1)动态声明一个可变数组
2)使用append函数向可变数组的末尾添加元素
3)使用insert函数在可变数组的指定位置添加元素
一次只插入一个元素:
一次插入多个元素:
编辑 4)使用 +=函数在可变数组的末尾追加一个或多个元素
5)使用++=函数在可变数组中添加同类型的数组
6)使用-=函数去指定删除数组中的元素(可以一次性删除多个元素)
7)使用remove函数删除指定索引下标的元素(一次性删除多个)
删除一个元素:
删除多个元素:
3,数组的相关方法
1)获取数组元素个数:size/获取数组长度:length
2)修改数组元素【给数组元素赋值】array[index]=value
3)静态数组转换成动态数组array.toBuffer
4)将Any类型类型的数组进行强转并取出里面的元素array.asInstanceOf[type]
5)获取数组中的最大数max
6)获取数组中的最小数min
7)数组翻转reverse
8)数组排序sorted
9)遍历数组
10)使用yield关键字对数组元素进行处理(全部)
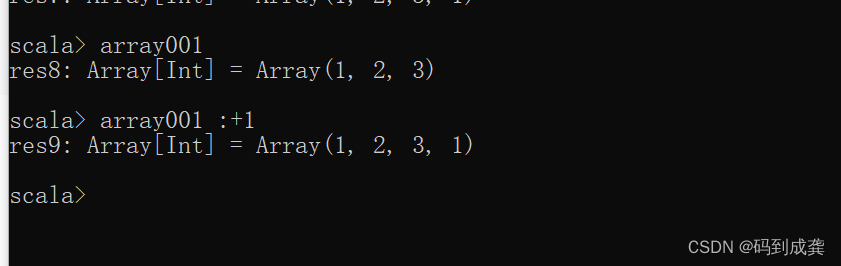
11)给定长数组添加元素并返回新的数组 :+
数组
数组类型默认不可变,一旦声明定义好,数组的长度就不会更改。如果想要在里面插入或者是删除元素都是实现不了的。但是可变数组可以进行这些更改操作。
1,不可变数组
Scala中的集合在进行动态声明和定义的时候可以不适用new关键字创建一个对象才能够进行相应的操作,我们只需要使用集合的类名即可。
1)静态声明
格式为:val 变量名【对象名】 =Array[Int](元素1,元素2,元素3)
代码:
scala> val array2=Array[Int](1,5,7)结果:

2)动态声明
但是在进行动态声明和定义一个数组的时候就使用new关键字,因为如果不使用的话,虚拟机就会默认后面的小括号里面的参数为数组里面的元素。即我们在进行数组的动态声明时,需要使用到new关键字来调用类的构造方法进行创建,并且,我们只能够传入一个参数,就是数组的长度,但是之前我们的不可变数组【定长数组】调用的是Array的静态数组对象,可以向里面传入多个参数即多个数组的元素。
错误的动态声明【声明成了静态数组】:
scala> val array3=Array[Int](3)
array3: Array[Int] = Array(3)

如上只是声明了一个静态的数组,并且,第一个元素就是我们传进去的参数3。
正确的动态声明:
scala> val array001=new Array[Int](2)
如上,我们可以看到,使用动态声明的数组里面的元素由虚拟机默认指定的数值。例如:
Int :默认为0
String:默认为null
Bolean:默认为false
Float[Double]:默认为0.0
2,可变数组
可变数组和不可变数组的区别在于可变数组可以对数组的长度进行更改。需要注意的是,可变数组在使用的时候需要导入相关的包import scala.collection.mutable.ArrayBuffer。不然就无法识别到我们声明的ArrayBuffer类型的数组。之前我们已经知道了数组的动态和静态声明,接下来我们直接去动态声明一个可变数组,并对该数组进行改变,如:向数组中添加元素,达到改变数组长度的作用。
1)动态声明一个可变数组
在声明定义可变数组时,一定要记得导包: import scala.collection.mutable.ArrayBuffer
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> var array001=ArrayBuffer(1,2,3,4)
array001: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4)
创建好可变数组之后我们就可以使用append,insert函数向可变数组中添加数组元素。也可以使用+=函数进行添加多个元素。
2)使用append函数向可变数组的末尾添加元素
append函数只能向可变数组的末尾追加元素,并且可以一次性追加多个元素。
scala> var array001=ArrayBuffer(1,2,3,4)
array001: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4)
scala> array001.append(22,22)
scala> array001
res1: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4, 22, 22)
3)使用insert函数在可变数组的指定位置添加元素
insert函数可以实现在指定的数组索引位置插入元素,也可以一次性插入多个元素
一次只插入一个元素:
scala> array001
res1: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4, 22, 22)
scala> array001.insert(0,1) // 在可变数组的第一个位置插入一个元素:1
scala> array001
res3: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 1, 2, 3, 4, 22, 22)
一次插入多个元素:
scala> array001.insert(0,77,88) // 在可变数组的第一个位置插入两个元素:77,88
scala> array001
res9: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(77, 88, 99, 100, 1, 2, 1, 1, 2, 3, 4, 22, 22)
scala>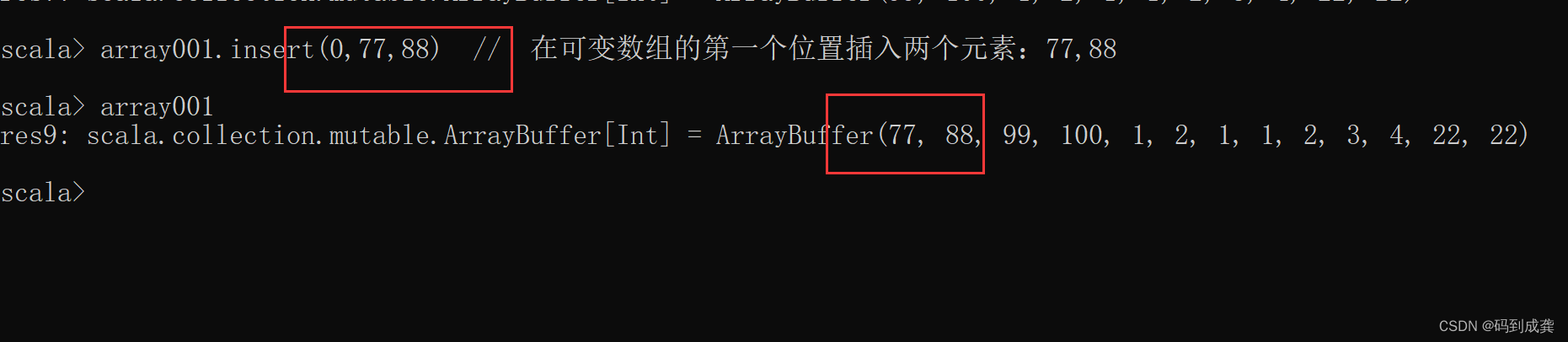 4)使用 +=函数在可变数组的末尾追加一个或多个元素
4)使用 +=函数在可变数组的末尾追加一个或多个元素
scala> array001 +=(44,55) // 在可变数组中添加两个元素44,55
res10: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(77, 88, 99, 100, 1, 2, 1, 1, 2, 3, 4, 22, 22, 44, 55)
5)使用++=函数在可变数组中添加同类型的数组
之前我们使用的+=函数只是向可变数组中添加多个参数而已,无法实现向数组中添加同类型数组:
scala> var array002 =new ArrayBuffer[Int](5) // 动态声明定义一个长度为5的可变数组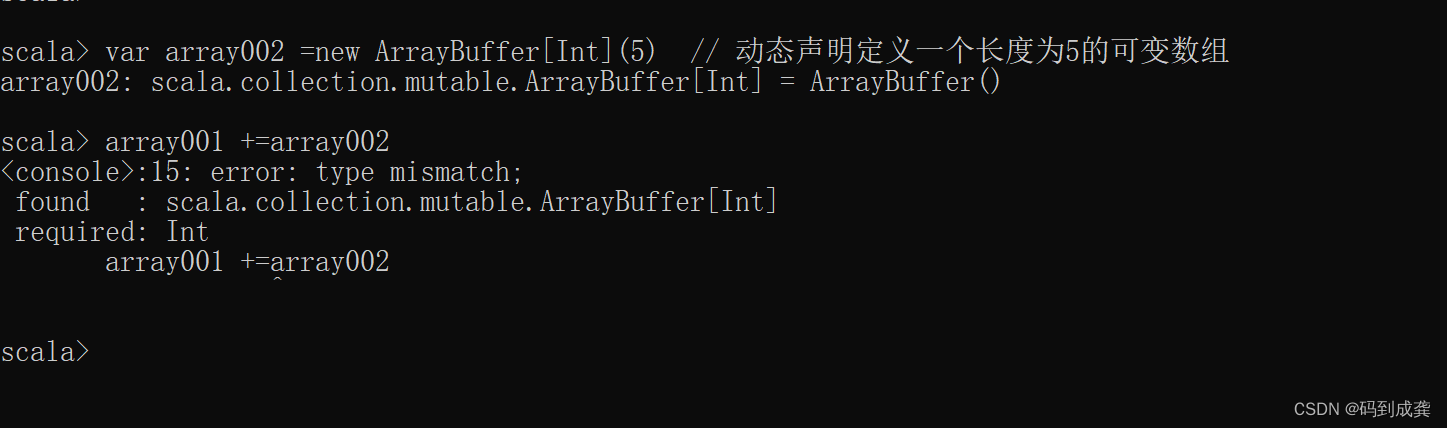
如上,我们可以看到,当我们还是使用之前的+=函数去往数组中添加数组类型的元素时,是行不通的。
现在我们使用++=函数去试试,它可以完成向数组中添加同类(序列)的作用吗?

可以看到,这样的方法是可行的。但是因为array002数组是使用动态创建的,所以现在的效果不明显,我们可以使用++=函数,让array002可变数组添加array001数组中的所有元素:
scala> array002 ++= array001
如上我们可以看到,之前动态创建的数组里面不是空的,而是有了其他的元素存在。
6)使用-=函数去指定删除数组中的元素(可以一次性删除多个元素)
我们可以向可变数组中添加元素,那么我们可以从可变数组中删除元素吗?当然可以。
我们可以使用 或者是-=函数,--=函数去删除想要删除的元素(不管该元素是位于元组中的哪一位置)
scala> array002 -=(99,22,44)
如上,我们可以看到,我们可以删除数组中指定的元素,不管是它位于哪一个位置。
7)使用remove函数删除指定索引下标的元素(一次性删除多个)
现在我们有这么一个数组,接下来我们对里面的元素使用remove函数来删除:
ArrayBuffer(1, 2, 1, 1, 2, 3, 4, 22, 22, 44, 55)
删除一个元素:
scala> array003
res41: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 1, 1, 2, 3, 4, 22, 22, 44, 55)
scala> array003.remove(1)
res42: Int = 2如上,我们可以看到,当我们使用remove函数只删除一个元素的话,会顺道将我们删除的元素在数组中的索引位置。
删除多个元素:
当我们使用remove函数去删除多个元素的时候,我们需要向里面传入两个参数,一个是起始删除的索引位置,第二个是要删除的元素个数,格式:remove(start_indext Int,count Int)
接下来我们使用remove函数去删除多个元素:
原始数组:ArrayBuffer(1, 2, 1, 1, 2, 3, 4, 22, 22, 44, 55)
现在我们如果想要删除索引从2开始,长度为4所包含的元素,就可以如下编写代码:

scala> var array003=ArrayBuffer(1, 2, 1, 1, 2, 3, 4, 22, 22, 44, 55)
array003: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 1, 1, 2, 3, 4, 22, 22, 44, 55)
scala> array003.remove(2,4)
scala> array003
res1: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 4, 22, 22, 44, 55)

3,数组的相关方法
1)获取数组元素个数:size/获取数组长度:length
scala> array001.size // size方法用于获取数组中的元素有几个res0: Int = 3
scala> array001.lengthlength方法和size方法一样,都可以用于返回数组中的元素个数或数组的长度。

2)修改数组元素【给数组元素赋值】array[index]=value
如下,我们可以通过,数组变量加中括号,并且在小括号里面指定要进行赋值或者是修改的元素的索引即可,实现修改或赋值,如果是在Java中的话数组的赋值和修改是需要数组变量加上中括号才行。在下面我们的将array001数组的第一个元素赋值(修改)为2003,并将这个数组进行返回,可以看到,在数组的第一个元素就是我们修改后的结果。
scala> array001(0)=2003
3)静态数组转换成动态数组array.toBuffer
如果想要将不可变的数组转换成可变数组的话可以使用toBuffer方法,该方法也可以在不想要使用循环语句的条件下进行查看数组:
scala> val array002=array001.toBuffer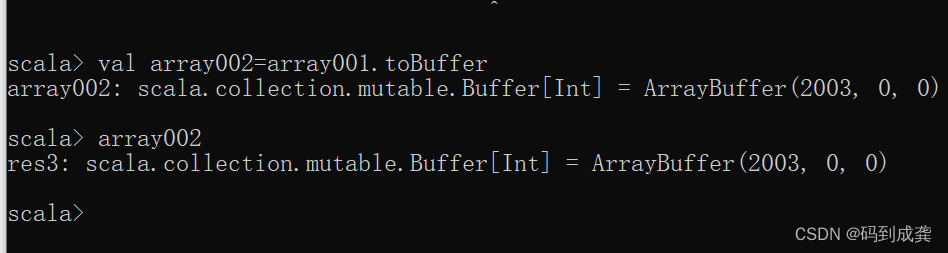
如上,我们可以看到使用另外一个变量接收转换后的数组为可变数组。
4)将Any类型类型的数组进行强转并取出里面的元素array.asInstanceOf[type]
首先需要创建包含有多种数据类型的Array数组:
scala> val array004=Array(1,"张三",Array[Int](1,2,3))现在我们去遍历数组的各个元素:

例如想要取出Array[Int](1,2,3)中的第二个元素就会报错:
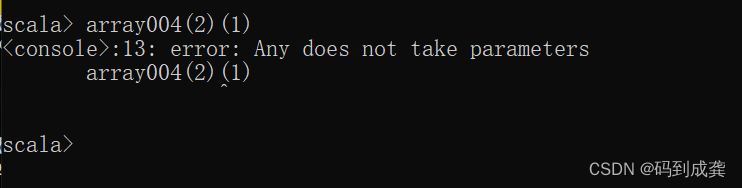
但是如果我们使用强转,将Any类型的Array数组转换成Int类型的话就可以进行操作。需要使用的关键字为asInstanceOf:
scala> array004(2).asInstanceOf[Array[Int]]
如上,我们可以看到,转换之后的数组返回的结果没有带有Any类型的表示,而是返回对应的元素。所以在类型为泛型的数组中如果想要对里面的元素进行处理,就需要进行强转处理。
5)获取数组中的最大数max
使用max函数就可以获取到数组中值最大的元素,并返回该元素:

scala> array002
res8: Array[Int] = Array(1, 4, 2, 5, 6, 7)
scala> array002.max
res9: Int = 7
6)获取数组中的最小数min
使用min函数就可以获取到数组中值最小的元素,并返回该元素:

scala> array002
res10: Array[Int] = Array(1, 4, 2, 5, 6, 7)
scala> array002.min
res11: Int = 1
7)数组翻转reverse
reserve方法可以用来翻转我们的数组,一般是该数组使用了sorted或者是sorteWith函数升序排序之后去调用,实现返回一个降序排序的数组的效果。如下我是直接返回该翻转后的数组:
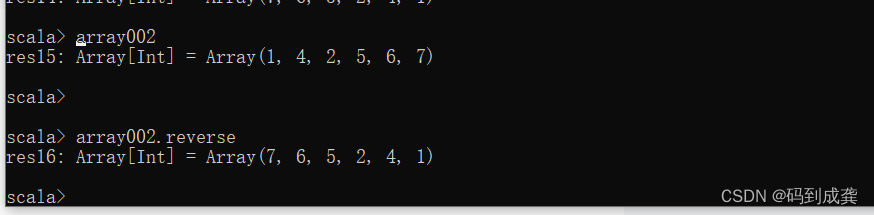
scala> array002
res15: Array[Int] = Array(1, 4, 2, 5, 6, 7)
scala>
scala> array002.reverse
res16: Array[Int] = Array(7, 6, 5, 2, 4, 1)8)数组排序sorted
sorted方法可以用于对数组进行升序排序,得到一个元素是从小到大排序的数组:
scala> array002
res4: Array[Int] = Array(1, 4, 2, 5, 6, 7)
scala> array002.sorted
res5: Array[Int] = Array(1, 2, 4, 5, 6, 7)
9)遍历数组
我们在遍历数组的时候可以使用两种方式进行遍历,一种是直接取出数组中的元素并返回,另外一种是通过索引获取到元素之后再返回:
scala> for(i <-0 until array002.size)print(s"${array002(i)} ") // 通过索引遍历数组
1 4 2 5 6 7
scala> for(i <- array002)print(s"${i} ") // 直接获取到数组元素
1 4 2 5 6 7
scala> array002
res22: Array[Int] = Array(1, 4, 2, 5, 6, 7) // 原数组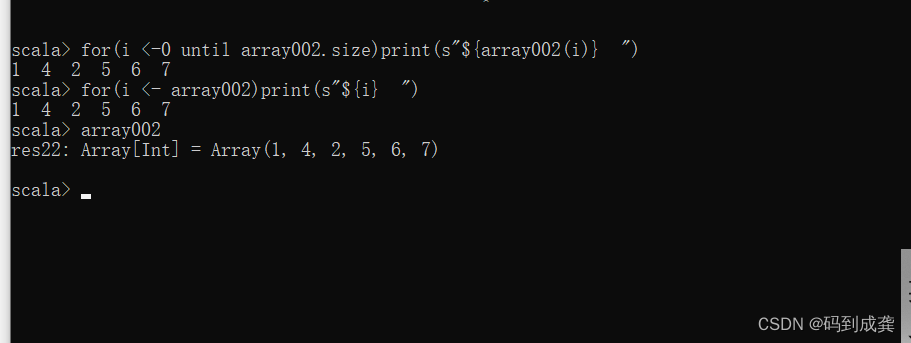
10)使用yield关键字对数组元素进行处理(全部)
在遍历数组元素的时候对元素进行自定义的处理(会对数组里面的全部数组进行一样的操作)并将处理后的元素放到一个新的数组中并返回该数组,如下,我们将遍历出来的数组元素都乘以10,并使用一个变量来存储新的数组:
scala> val array003=for(i <- array002) yield i * 10
array003: Array[Int] = Array(10, 40, 20, 50, 60, 70)
11)给定长数组添加元素并返回新的数组 :+
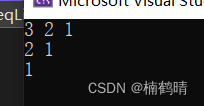
scala> array001
res8: Array[Int] = Array(1, 2, 3)
scala> array001 :+1
res9: Array[Int] = Array(1, 2, 3, 1)