大数据技术基础实验十三:Kafka实验——订阅推送示例
文章目录
- 大数据技术基础实验十三:Kafka实验——订阅推送示例
- 一、前言
- 二、实验目的
- 三、实验要求
- 四、实验原理
- 1、Kafka简介
- 2、Kafka使用场景
- 五、实验步骤
- 1、配置各服务器之间的免密登录
- 2、安装ZooKeeper集群
- 3、安装Kafka集群
- 4、验证消息推送
- 六、最后我想说
一、前言
其实我们的大数据技术基础课已经没有实验了,目前来说我正在更新学校平台上面我们没时间去做的实验,Kafka目前并没有学,所以需要我们自己去了解学习。
废话不多说,直接开始实验!
二、实验目的
- 掌握Kafka的安装部署
- 掌握Kafka的topic创建及如何生成消息和消费消息
- 掌握Kafka和Zookeeper之间的关系
- 了解Kafka如何保存数据及加深对Kafka相关概念的理解
三、实验要求
在两台机器上(以slave1,slave2为例),分别部署一个broker,Zookeeper使用的是单独的集群,然后创建一个topic,启动模拟的生产者和消费者脚本,在生产者端向topic里写数据,在消费者端观察读取到的数据。
四、实验原理
1、Kafka简介
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。如图下所示:

一个Topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性。
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可…由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定。
生产者:Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等。
消费者:本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费。
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡。
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者。
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的。
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
Guarantees
(1)发送到partitions中的消息将会按照它接收的顺序追加到日志中。
(2)对于消费者而言,它们消费消息的顺序和日志中消息顺序一致。
(3)如果Topic的"replicationfactor"为N,那么允许N-1个kafka实例失效。
2、Kafka使用场景
1)Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.不过到目前为止,我们应该很清楚认识到,kafka并没有提供JMS中的"事务性"“消息传输担保(消息确认机制)”"消息分组"等企业级特性;kafka只能使用作为"常规"的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)。
(2)Websit activity tracking
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等。
(3)Log Aggregation
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统。
五、实验步骤
1、配置各服务器之间的免密登录
首先配置master,slave1和slave2之间的免密登录和各虚拟机的/etc/hosts文件,这个步骤请参考我之前的一篇博客,里面有详细过程:
大数据技术基础实验一:配置SSH免密登录
2、安装ZooKeeper集群
配置完免密登录之后我们还需要安装Zookeeper集群,这个步骤可以参考我之前的博客,里面有详细的步骤:大数据技术基础实验五:Zookeeper实验——部署ZooKeeper
在这里我就不再赘述了。
3、安装Kafka集群
首先我们将Kafka安装包解压到slave1的/usr/cstor目录:
tar -zxvf kafka_2.10-0.9.0.1.tar.gz -c /usr/cstor
并将kafka目录所属用户改成root:root:
chown -R root:root /usr/cstor/kafka
然后将kafka目录传到其他机器上:
scp -r /usr/cstor/kafka hadoop@slave2:/usr/cstor
两台机器上分别进入解压目录下,在config目录修改server.properties文件:
cd /usr/cstor/kafka/config/
vim server.properties
然后修改其中的内容,首先是slave1配置:
#broker.id
broker.id=1
#broker.port
port=9092
#host.name
host.name=slave1
#本地日志文件位置
log.dirs=/usr/cstor/kafka/logs
#Zookeeper地址
zookeeper.connect=slave1:2181,slave2:2181,master:2181



然后修改slave2的配置:
#broker.id
broker.id=2
#broker.port
port=9092
#host.name
host.name=slave2
#本地日志文件位置
log.dirs=/usr/cstor/kafka/logs
#Zookeeper地址
zookeeper.connect=slave1:2181,slave2:2181,master:2181



然后,启动Kafka,并验证Kafka功能,进入安装目录下的bin目录,两台机器上分别执行以下命令启动各自的Kafka服务:
cd /usr/cstor/kafka/bin
nohup ./kafka-server-start.sh ../config/server.properties &
在任意一台机器上,执行以下命令(以下三行命令不要换行,是一整行)创建topic:
./kafka-topics.sh --create \
--zookeeper slave1:2181,slave2:2181,master:2181 \
--replication-factor 2 --partitions 2 --topic test

在任意一台机器上(这里我选择的是slave1),执行以下命令(以下三行命令不要换行,是一整行)启动模拟producer:
./kafka-console-producer.sh \
--broker-list slave1:9092,slave2:9092,master:9092 \
--topic test
在另一台机器上(slave2),执行以下命令(以下三行命令不要换行,是一整行)启动模拟consumer:
./kafka-console-consumer.sh \
--zookeeper slave1:2181,slave2:2181,master:2181 \
--topic test --from-beginning
4、验证消息推送
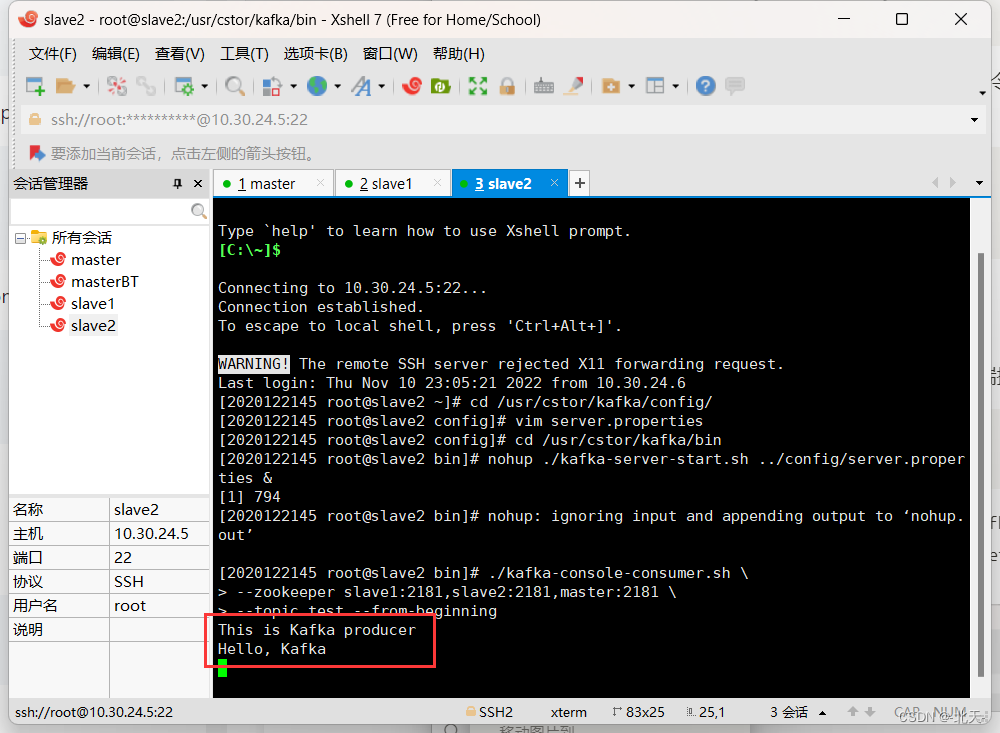
我们在producer端输入任意信息,然后观察consumer端接收到的数据:
This is Kafka producer
Hello, Kafka
在slave1上输入信息:

然后slave2上也收到了信息:
六、最后我想说
本次实验结束,我们只是通过本次实验简单的演示了一下Kafka的基础功能,还有很多更高级的用法,后续有时间的话我会去网上找一下进阶的大数据综合实验做一下。