Jindo-Spark 是阿里云智能E-MapReduce 团队在开源的Apache Spark 基础上自主研发的分布式云原生 OLAP 引擎,已经在近千E-MapReduce 客户中大规模部署使用。Jindo Spark 在开源版本基础上做了大量优化和扩展,深度集成和连接了众多阿里云基础服务。凭借该引擎,EMR 成为第一个云上 TPC-DS 成绩提交者。经过持续不断地内核优化,目前基于最新 EMR-Jindo 引擎的 TPC-DS 成绩又有了大幅提高,达到了3615071,成本降低到 0.76 CNY。
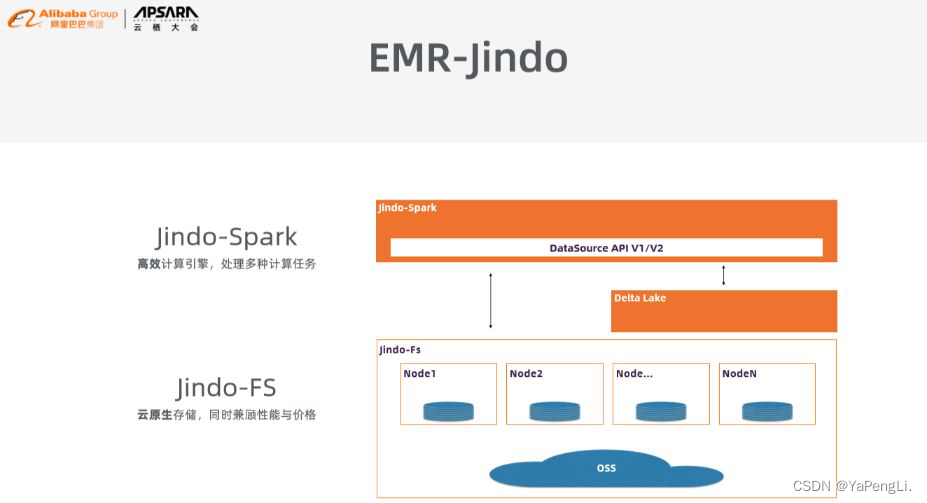
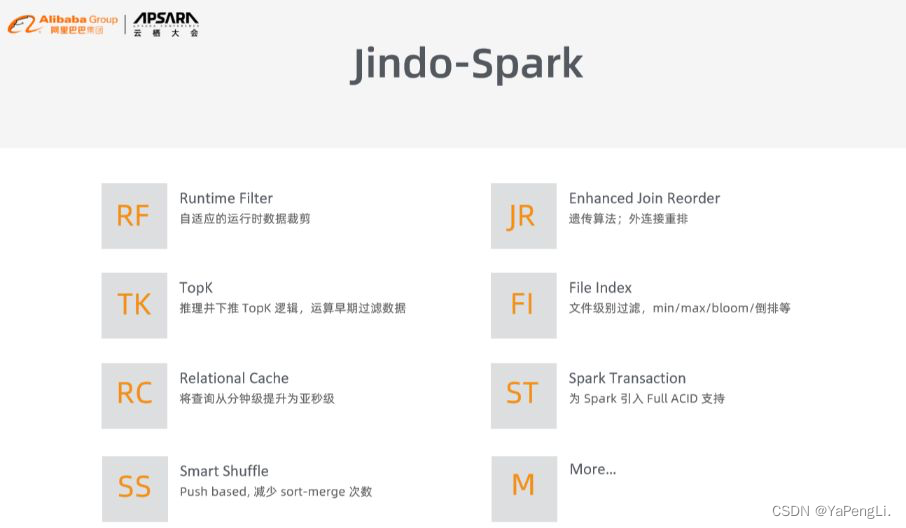
Jindo-Spark高效计算引擎对Spark采起了一系列优化措施,好比Runtime Filter支持自适应的运行时数据裁剪;Enhanced Join Reorder来解决外链接重排等问题;TopK支持推理并下推 TopK 逻辑,帮助尽早地过滤数据;File Index支持文件级别过滤和min/max/bloom/倒排等;自研开发了Relational Cache,实现使用一套引擎就能够将查询从分钟级提高为亚秒级;针对特定的场景推出Spark Transaction功能,为Spark引入Full ACID支持;实现了Smart Shuffle功能,从底层来减小sort-merge 次数,提高Shuffle的效率。
4.1 Runtime Filter
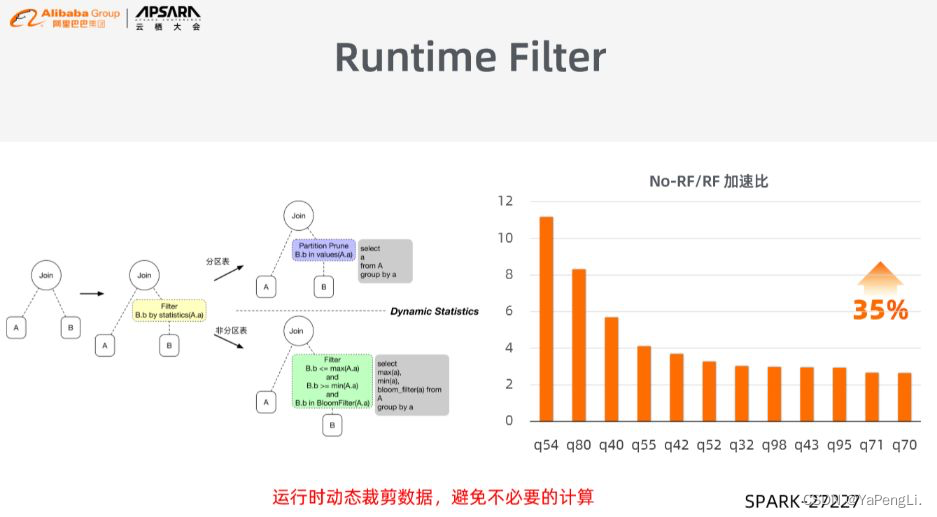
相似于Spark中的Dynamic Partition Pruning(DPP),可是其比DPP功能更强大。除了DPP能处理的分析表以外,Runtime Filter还能够处理非分析表。其基本原理是运行时动态裁剪数据,避免没必要要的计算。好比,面对一个join查询,没法经过value下推到存储层而将数据过滤,逻辑推算的时候没法预知最后的数据量级。这种状况下若是是分析表,Runtime Filter首先会估计其中一个表中参与join操做的数据量,若是数据量较小,则提早进行数据筛选,再推送到另外一侧作数据过滤;而对于非分析表,会引入Filter,如BloomFilter得到Min或Max的统计信息,根据这些统计信息,将备选数据比较少的一侧提取出来,推到另外一侧进行过滤。Runtime Filter的成本很小,只须要在优化器中进行简单评估,却能够带来显著的性能提高。以下图所示,Runtime Filter实现了35%左右的总体性能提高。该特性已经在Spark提交了PR(SPARK-27227)。
4.2 Enhanced Join Recorde
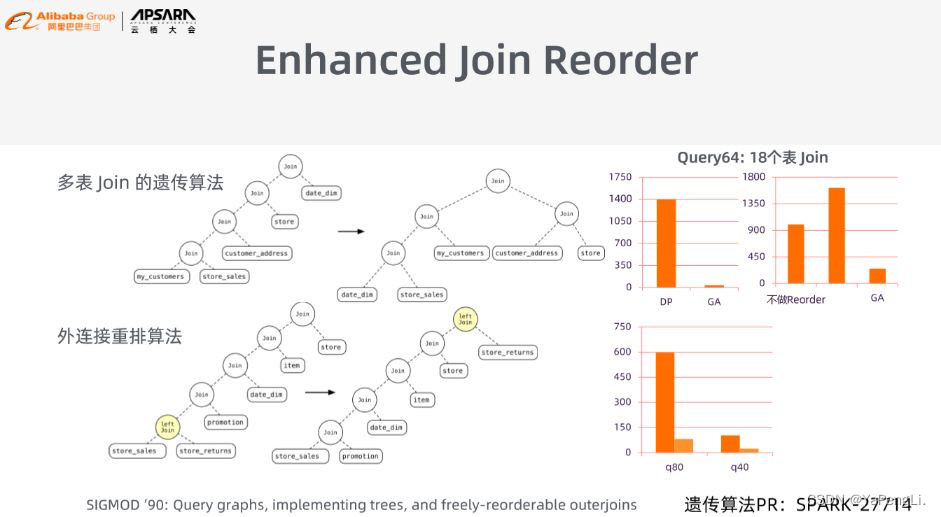
大家都知道,算子执行顺序可能会极大地影响sql的执行效率,这种状况下优化的核心原则是改变算子的执行顺序,尽早地过滤数据。运维好比下图左上角的例子中,若是最底层两个表很是大的话,则这两张表join的开销会很是大,join后的大数据再去join小表,大数据一层一层地传递下去,就会影响整个流程的执行效率。此时,优化的思想是先将大表中一些无关的数据过滤掉,减小往下游传递的数据量。针对该问题,Spark使用的是动态规划算法,但其只适用于表的数量比较少的状况,若是表的数量大于12,该算法就一筹莫展。面对表的数量比较多的状况,EMR提供了多表join的遗传算法,其能够将原来的动态规划算法的2n的复杂度降到线性的量级,能完成成百上千张表的join。
下图右上角能够看到,Query64有18个表参与join,动态规划算法优化时间就须要耗费1400秒,而多表join的遗传算法仅须要20秒左右就可完成。Join Recorder另一个重要的功能是外链接重排算法,你们都知道sql中外链接不能随意交换顺序的,但这并不表明不能交换顺序,好比A left join B, 而后再left join C,事实上在某种条件下其顺序是可交换的。在Spark中,外链接的优化是直接被放弃掉,而EMR则根据现有研究找到了顺序可交换的充分必要条件,实现了外链接重排算法(以下图左下角所示),对外链接的执行效率有了质的提高(下图右下角)
4.3 Relational Cache
Spark Relational Cache希望能够达到秒级响应或者亚秒级响应,能够在提交SQL之后很快地看到结果。并且也支持很大的数据量,将其存储在持久化的存储上面,同时通过一些匹配手段,增加了匹配的场景。此外,下层存储也使用了高效的存储格式,比如离线分析都会使用的列式存储,并且对于列式存储进行了大量优化。此外,Relational Cache也是用户透明的特性,用户上来进行查询不需要知道几个表之间的关系,这些都是已经有过缓存的,不需要根据已有的缓存重写Query,可以直接判断是否有可以使用的Relational Cache,对于一个厂商而言只需要几个管理员进行维护即可。Spark Relational Cache支持自动更新,用户不需要担心因为插入了新的数据就使得Cache过时导致查询到错误的数据,这里面为用户提供了一些设置的规则,帮助用户去进行更新。此外,Spark Relational Cache还在研发方面,比如智能推荐方面进行了大量探索,比如根据用户SQL的历史可以推荐用户基于怎样的关系去建立Relational Cache。

阿里云EMR具有很多核心技术,如数据预计算、查询自动匹配以及数据预组织

数据预计算
数据在很多情况下都有一个模型,雪花模型是传统数据库中非常常见的模型,阿里云EMR添加了Primary Key/Foreign Key的支持,允许用户通过Primary Key/Foreign Key明确表之间的关系,提高匹配成功率。在数据预计算方面,充分利用EMR Spark加强的计算能力。此外,还通过Data Cube数据立方来支持多维数据分析。

执行计划重写
这部分首先通过数据预计算生成预计算的结果,并将结果存储在外部存储上,比如OSS、HDFS以及其他第三方存储中,对于Spark DataSource等数据格式都支持,对于DataLake等热门的存储格式后续也会添加支持。在传统数据库中有类似的优化方案,比如物化视图方式,而在Spark中使用这样的方式就不合适了,将逻辑匹配放在了Catalyst逻辑优化器内部来重写逻辑执行计划,判断Query能否通过Relational Cache实现查询,并基于Relational Cache实现进一步的Join或者组合。将简化后的逻辑计划转化成为物理计划在物理引擎上执行。依托EMR Spark其他的优化方向可以实现非常快速的执行结果,并且通过开关控制执行计划的重写。
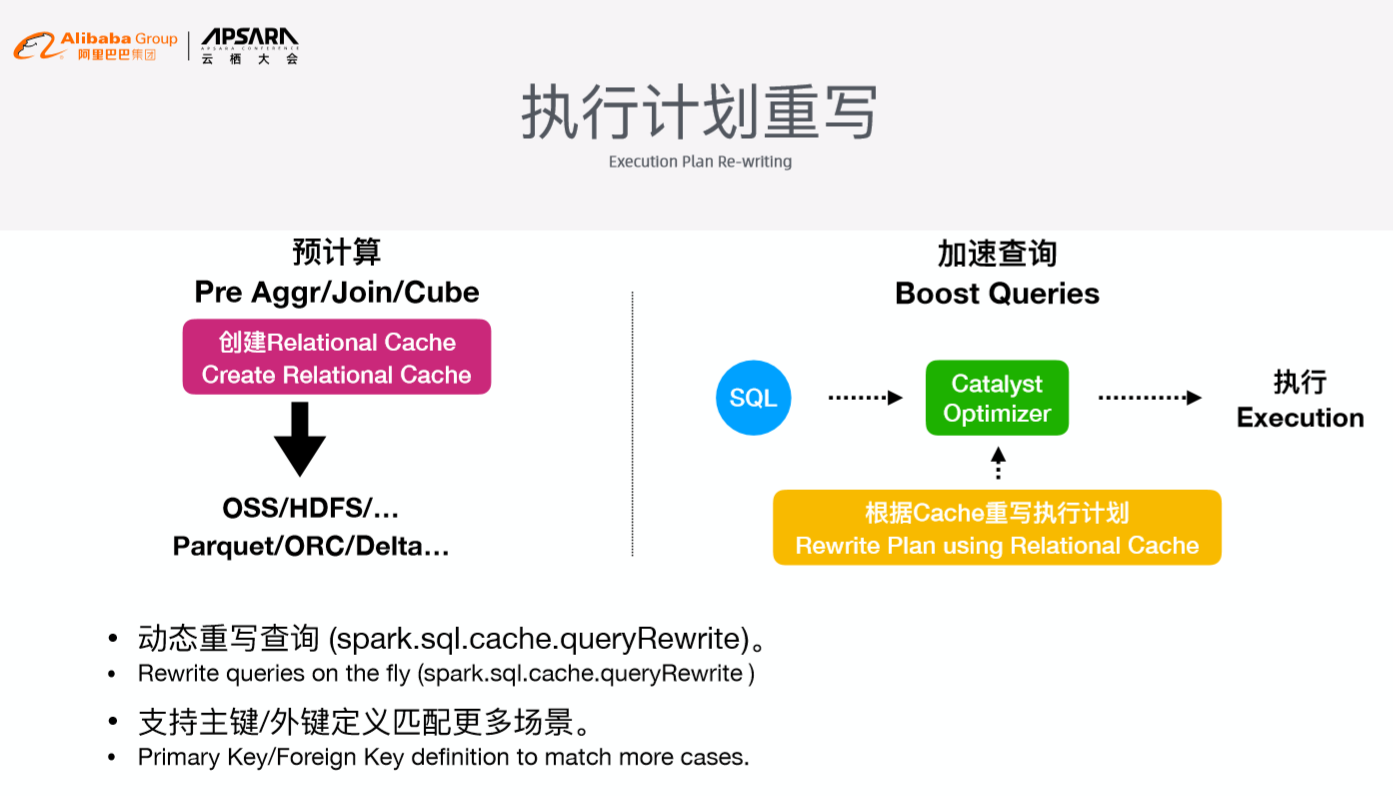
自动查询匹配
这里有一个简单的例子,将三个表简单地Join在一起,经过过滤条件获得最终的结果。当Query过来之后先判断Spark Relational Cache是否能够符合需求,进而实现对于预先计算好的结果进行过滤,进而得到最终想要的结果。

数据预组织
如果将数十T的数据存在存储里面,那么从这个关系中获取最终的结果还需要不少的时间,因为需要启动不少的Task节点,而这些Task的调度也需要不少的开销,通过文件索引的方式将时间开销压缩到秒级水平,可以在执行时过滤所需要读取的文件总量,这样大大减少了任务的数量,这样执行的速度就会快很多。因为需要让全局索引变得更加有效,因此最好让数据是排过序的,如果对于结构化数据进行排序就会知道只是对于排列在第一位的Key有一个非常好的优化效果,对于排列在后面的Key比较困难,因此引入了ZOrder排序,使得列举出来的每个列都具有同等的效果。同时将数据存储在分区表里,使用GroupID作为分区列。

如何使用
对于简单的Query,可以指定自动更新的开关,并起一个名字方便后续管理。还可以规定数据Layout的形式,并最终通过SQL语句来描述关系,后续提供给用户WebUI一样的东西,方便用户管理Relational Cache。

数据更新
Relational Cache的数据更新主要有两种策略,一种是On Commit,比如当依赖的数据发生更新的时候,可以将所有需要添加的数据都追加写进去。还有一种默认的On Demand形式,用户通过Refresh命令手动触发更新,可以在创建的时候指定,也可以在创建之后手工调整。Relational Cache增量的更新是基于分区实现的,后续会考虑集成一些更加智能的存储格式,来支持行级别的更新。

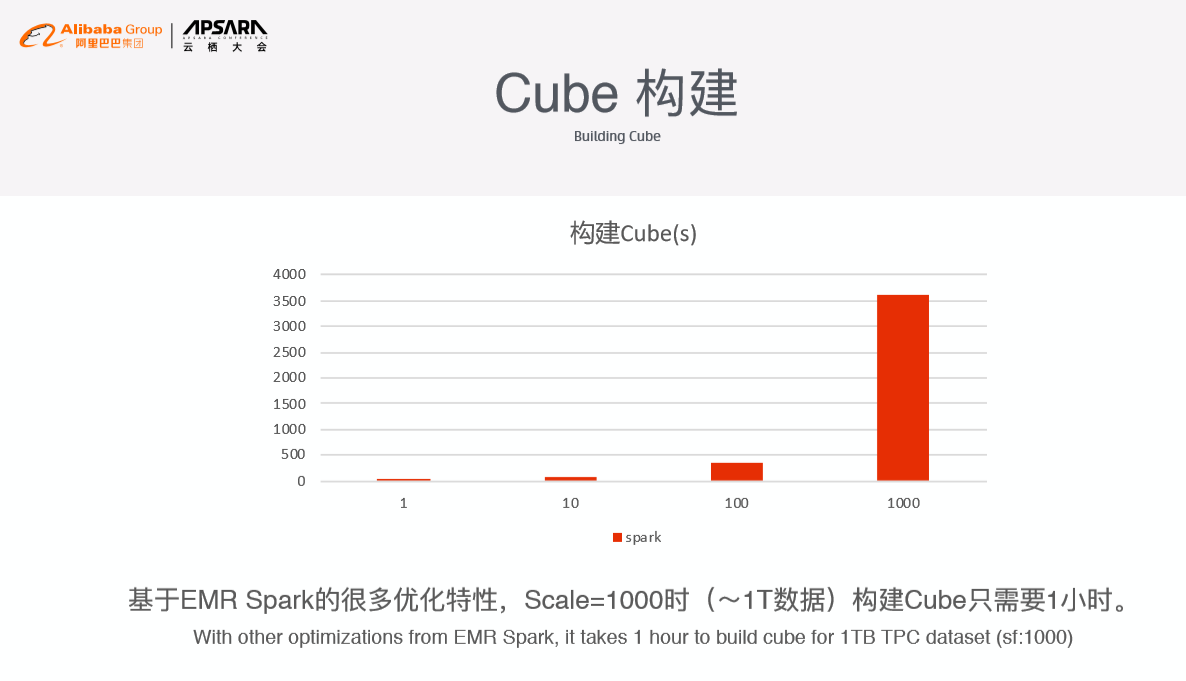
性能分析
阿里巴巴的EMR Spark对于1T数据的构建时间只需要1小时。
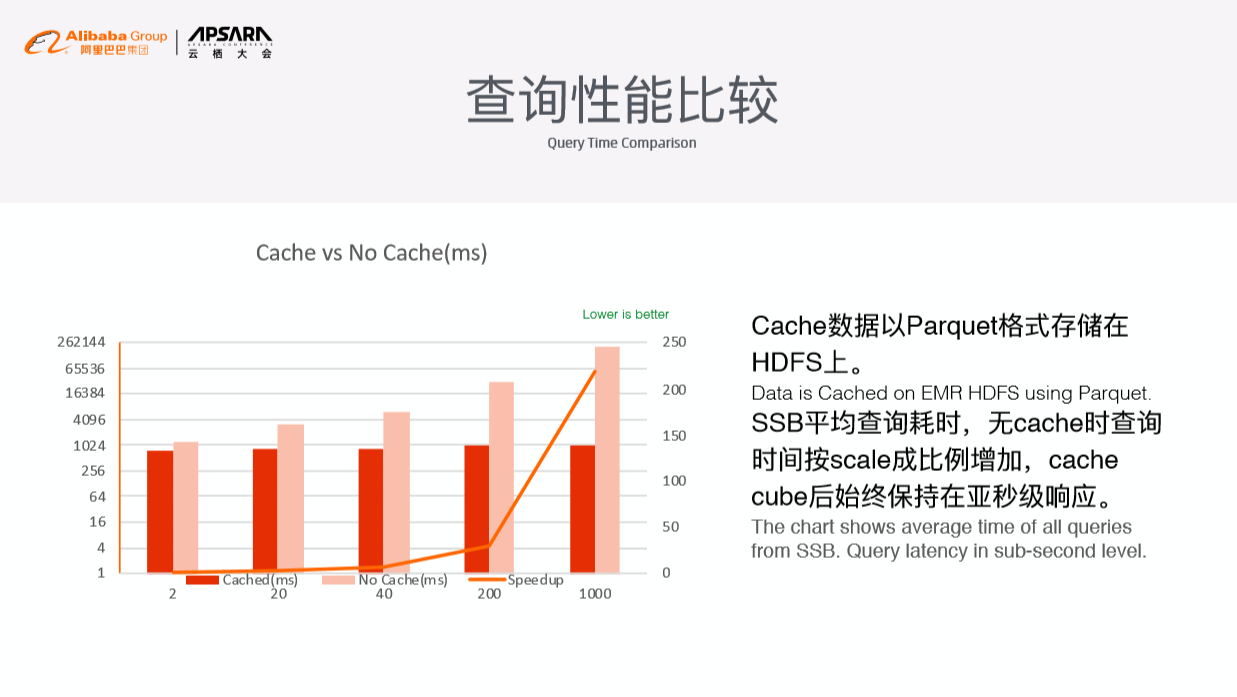
查询性能
在查询性能方面,SSB平均查询耗时,无Cache时查询 时间按Scale成比例增加,Cache Cube后始终保持在亚秒级响应。