编译
语义分析
由语义分析器完成,这个步骤只是完成了对表达式的语法层面的分析,它并不了解这个语句是否真的有意义(例如在C语言中两个指针做乘法运算,这个语句在语法上是合法的,但是没有什么意义;还有同样一个指针和一个浮点数做乘法运算是否合法等),这里就要知道编译器所能分析的语义是静态语义(在编译期就可以确定的语义)反之则是动态语义(只有在运行期才能确定的语义)
补充:
静态语义通常包括声明和类型的匹配,类型的转换(例如当一个浮点型的表达式赋值给一个整型的表达式时,其中隐含了一个浮点数到整型的转换过程,在语义分析过程中需要完成这个步骤),比如将一个浮点型赋值给一个指针时,语义分析程序会发现类型不匹配,然后编译器就会报错
动态语义指的是在运行期出现的语义相关的问题,比如将0作为除数就是一个运行期的语义错误
语义分析阶段过后,之前的那个语法树的表达式就都被表示了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应转换节点
补充:
隐式类型转换,也叫做自动类型转换,是编译器根据表达式的上下文自动将某种类型的值转换为另一种类型的过程,隐式转换通常发生在类型不完全一致时,编译器会根据规则自动进行转换(例如上文提到的整型和浮点数),下面举个例子
int a = 5;
float b = a; // 这个就是隐式转换:a 从 int 类型转换为 float 类型
在编译过程中,转换节点是编译器在语法树中插入的节点,用来表示隐式类型转换的过程,通常,编译器会根据类型系统的规则自动插入这样的转换节点,照上文来说,在语法树中,有一个表达式需要将int转换为float,那么在构建语法树时,编译器会插入一个转换节点,表示这个类型的自动转换,这个节点会把 int 类型的值转换为 float 类型,然后继续执行后续的计算或操作,举个例子
int a = 5;
float b = 10.5;
float result = a + b;
上面这段代码中,在语法树里:a 是 int 类型,b 是 float 类型,编译器会检查 a + b 的类型,发现 a 和 b 类型不同,编译器会隐式将 a(int 类型)转换为 float 类型(因为 float 类型能够容纳 int 的值),然后,编译器执行 float + float 的操作,在这个过程中,语法树会被修改,插入一个转换节点,表示a需要被转换成float类型,并在计算之前完成这个过程
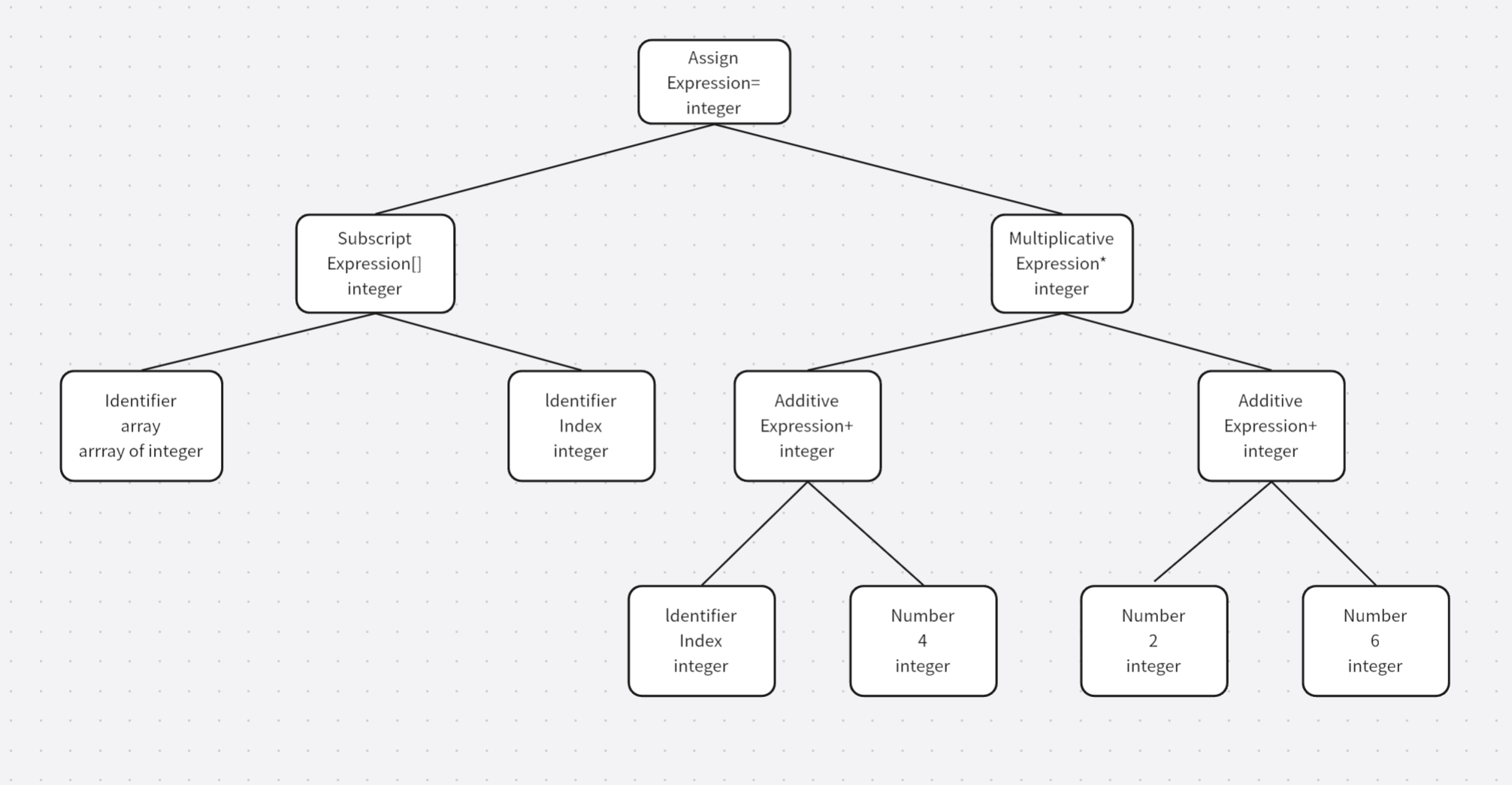
在这个语法树中可以看到每个表达式(包括符号和数字)都被标识了类型,另外符号分析器还对符号表中的符号类型进行了更新
总结来说就是在编译器的语义分析阶段,主要的任务是检查程序的语义正确性,并为表达式、变量、函数等绑定相关类型信息,确保类型之间的匹配符合语言的语法规则
中间语言生成
现代的编译器具备很多层次的优化,往往在源码级别会有一个优化过程,这里说到的源码级优化器在不同编译器中会有不同的定义或其他差异,比如说在上面的那个例子中(2+6)这个表达式是可以被优化掉的(值在编译期已确定),下面是优化后的语法树
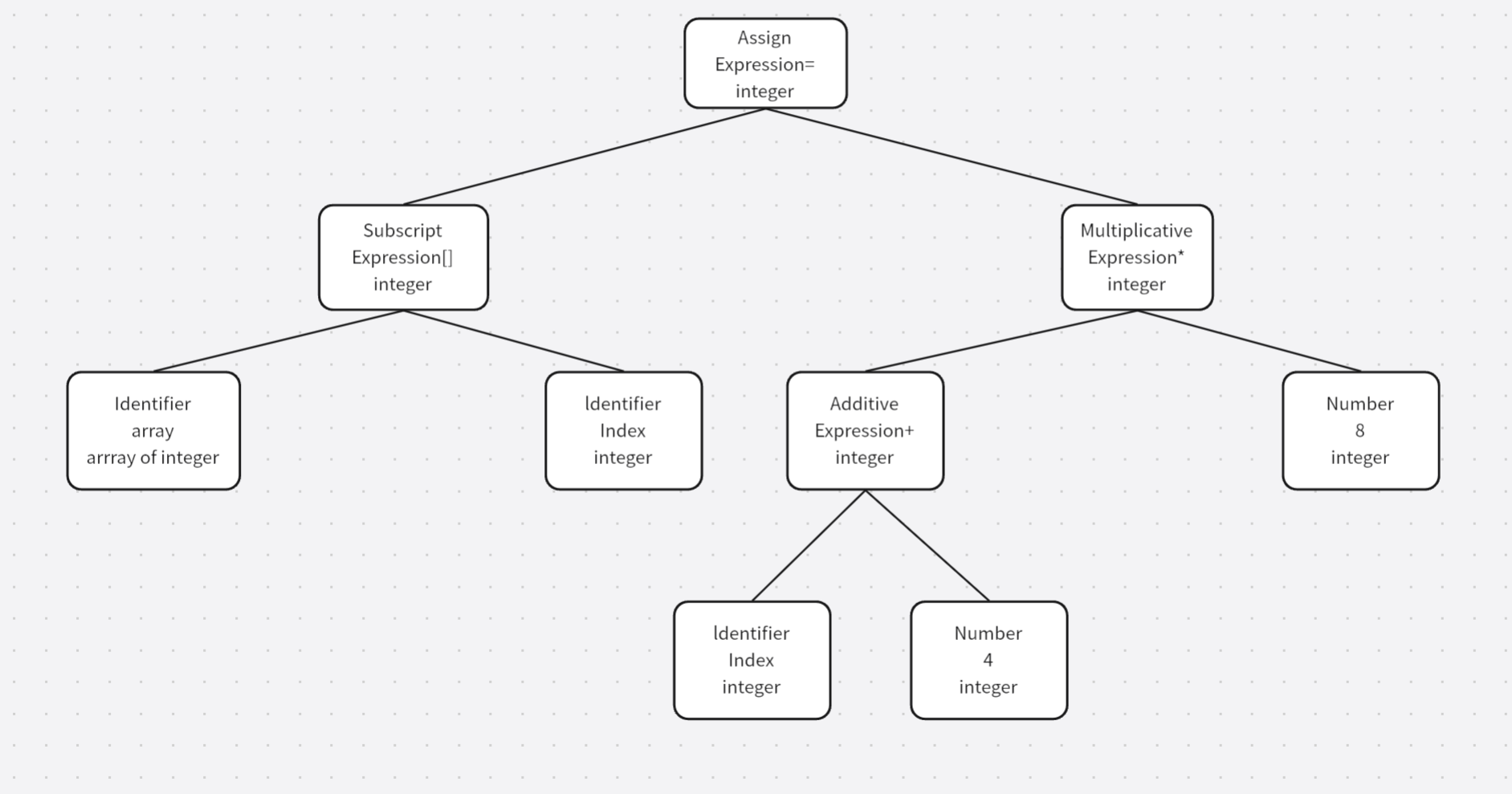
可以看到相较上面的语法树优化后直接变成8了,这里要注意直接在语法树上作优化比较困难,那么这里就引出了中间语言这一说法,源代码优化器往往会将整个语法树转换成中间代码(语法树的顺序表示),在编译过程中,中间代码是源代码和目标代码之间的桥梁,其实已经非常接近目标代码了,但是一般与目标机器和运行环境是无关的(比如不包含数据的尺寸、变量地址和寄存器的名字等),中间代码比较常见的类型有三地址和P-代码,除此之外还有很多不同的类型,在不同的编码器中有不同的形式
补充:
三地址码:一个三地址码语句中有三个变量地址,因此得名,每条指令最多包含三个操作数(通常是两个源操作数和一个目标操作数),每条指令执行一个基本操作(如算术运算、赋值、跳转等),使用临时变量存储中间结果,便于优化
常见指令形式
x = y op z # 二元运算(如加法、乘法)
x = op y # 一元运算(如取负)
x = y # 直接赋值
goto L # 无条件跳转
if x relop y goto L # 条件跳转(relop 为比较运算符)
例如
a = b + c * d;
这是源码
t1 = c * d
t2 = b + t1
a = t2
这是三地址码
可以看到结构更为简单,更易于理解和优化,而且更接近实际机器的指令格式,便于转换为目标代码。为了使所有操作符合三地址码形式,利用到了t1、t2、t3三个临时变量(由编译器自动生成的、用于存储中间计算结果的变量,没有对应的源代码变量名,仅在编译阶段或中间代码执行过程中临时存在)
P-代码:一种面向虚拟机的栈式中间代码,常用于解释型语言或早期编译器(如Pascal的编译器),指令通过操作栈完成计算,无需显式临时变量
常见指令形式
LOD x # 将变量x压栈
LIT 5 # 将常量5压栈
ADD # 弹出栈顶两个值相加,结果压栈
STO y # 弹出栈顶值并存储到变量y
例如
a = b + c * d;
这是源代码
LOD c
LOD d
MUL # 计算 c * d,结果压栈
LOD b
ADD # 计算 b + (c*d),结果压栈
STO a # 存储到a
这是P-代码
可以看到换为P-代码后指令变得紧凑,无需临时变量名,更适合解释执行
这里举例用的是最常见的三地址码
x = y op z
也就是上面补充中提到的二元运算的三地址码,表示的是将变量y和z进行op(二元运算符,可以是几件乘除,也可以是任何可以应用到y和z的操作)后赋值给x,那么上面那个语法树就可以被翻译为下面这样
t1 = 2+6
t2 = index + 4
t3 = t2 * t1
array[index] = t3
这里使用了几个临时变量:t1、t2、t3,接下来进行优化时,优化程序会计算2+6,也就是将t1的结果计算出来,得到8,然后后面的t1就会全部替换成8,那么t3也就不需要了,因为t2可以重复利用(t3现在只是t2 * 8的结果,而t2仍然有效,也就是说在t3 = t2 * 8时,t2的值没有被其他计算覆盖,所以可以直接复用t2),那么优化后代码就长这样
t2 = index + 4
t2 = t2 * 8
array[index] = t2
中间代码使得编译器可以被分为前端和后端(前端负责产生机器无关的中间代码,后端用来将中间代码转换成目标机器代码),那么对于一些可跨平台的编译器而言可以针对不同的平台使用同一个前端和针对不同机器平台的无数个后端
目标代码生成与优化
源代码级优化器产生中间代码标志着下面的过程都属于编译器后端,主要包括代码生成器和目标代码优化器
接下来详细讲一下代码生成器和目标代码优化器
代码生成器:
将编译器前端生成的中间代码,如三地址码、抽象语法树等,转换为目标机器的低级代码,通常是汇编代码或机器码,整个过程依赖于目标机器,因为不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等,上面的例子中的中间代码代码生成器可能会生成下面这个代码序列(这里用的是x86汇编表示,假设index类型是int,array类型是int型数组),可以看到确实有冗余加载等问题
movl index,%ecx ; value of index to ecx
addl $4,%ecx ; ecx = ecx + 4
mull $8,%ecx ; ecx = ecx * 8
movl index,%eax ; value of index to eax
movl %ecx,array(,eax,4) ; array[index] = ecx
接下来讲的是目标代码优化器
目标代码优化器:
对代码生成器输出的目标代码进行窥孔优化(扫描短指令序列,替换为更高效的指令(如用 INC eax 代替 ADD eax, 1))、分支优化(调整跳转指令布局以减少流水线冲刷(如将高频分支放在前面))、机器特有的优化(利用特定CPU的指令集(如SIMD指令)或硬件特性(如多发射流水线))、冗余指令删除(消除不必要的加载/存储操作)等优化,现在对上述代码进行优化,惩罚由一条相对复杂的基址比例变址寻址的lea指令完成,随后由一条mov指令完成最后的赋值操作,这条mov指令的寻址方式与lea一致
movl index,%edx
leal 32(,%edx,8),%eax
movl %eax,array(,%edx,4)
补充:
基址比例变址寻址:
变址寻址指的是基址寄存器 + 变址寄存器 * 比例因子,例如
movl array(,%ecx,4), %eax ;
访问array + ecx*4地址处的值,适用于数组遍历(如 array[i],其中 i 是变量),比例因子(1, 2, 4, 8)用于支持不同数据类型(如 int 是 4 字节)
基址比例变址寻址:
基址比例变址寻址(也称为带比例的变址寻址)是一种 高级内存寻址模式,常用于访问数组、结构体等数据结构,结合了 基址寄存器、变址寄存器和比例因子来计算最终的内存地址,基本语法如下
displacement(base_reg, index_reg, scale_factor)
displacement:常量偏移量(可选,通常用于结构体成员访问)
base_reg:基址寄存器(如 %ebx),存放数组的起始地址
index_reg:变址寄存器(如 %ecx),存放数组下标
scale_factor:比例因子(1, 2, 4, 8),用于调整数据类型大小(如 int 是 4 字节)
计算最终内存地址:
address = base_reg + index_reg * scale_factor + displacement基址比例变址寻址 = 基址寄存器 + 变址寄存器 × 比例因子 + 偏移量
可以更高效的访问数组,并且支持不同的数据类型,还能减少指令数量
总结
经过上述扫描、语法分析、语义分析等过程后源代码就会被编译为目标代码,但是可以发现index和array的地址还未确定,如果二者定义在跟上面源代码同一个编译单元里面,那么编译器可为index和array分配空间从而确定地址,但是分配到其他模块就不知道了,也就是说目标代码中有变量定义在其他模块时该怎么办?
那么可以知道定义其他模块的全局变量和函数在最终运行时的绝对地址都要在最终链接时才能确定,所以现代编译器可以将一个源代码文件编译成一个未链接的目标文件,然后由链接器最终将这些目标文件链接起来形成一个可执行文件
链接
这个比较费解,关键点在于汇编器为什么不直接输出可执行文件,反而是生成一个目标文件,链接有什么用?过程包含了什么内容?为什么要链接?
其实了解完上面的编译过程至少能知道问题一链接有什么用:链接可以将各个模块连接到一起,变成一个可执行文件,问题三:因为定义的模块不相同,为了将代码中的各个模块连接起来,将各个模块互相引用的部分处理好才需要用到链接(这里是因为我看书的时候发现链接放到后面可能会比较容易理解一点,这些问题其实是在详细讲编译之前作者提出的,但很明显现在在了解了编译之后来看链接会更好)
先看看怎样调用链接器ld才可以产生一个能够正常运行的helloword:
ld -static crt1.o crti.o crtbeginT.o hello.o --start-group -lgcc -lgcc_eh -lc --end-group crtend.o crtn.o
ps:这里有一个问题啊,看书的时候发现的,长指令应该都是--,不知道为什么这里把路径省略了以后就成了-了,可能书印错了
接着上面讲,要得到可执行文件就需要把那么一大堆的文件链接起来,那么这些文件到底是什么呢
--start-group和--end-group
用于解决静态库之间的循环依赖问题,链接器默认按顺序扫描库,如果库A依赖库B,而库B又依赖库A,直接链接会报错(符号未找到),--start-group和--end-group之间的库会被反复扫描,直到所有符号解析完成。
这些文件是程序启动和退出时的关键代码,由编译器和操作系统提供:
1.crt1.o/crti.o/crtn.o
crt1.o(或crt0.o):程序的入口点(_start),负责初始化栈、加载argc/argv,最后调用main,如果没有的话程序就无法从main开始执行
2.crti.o和crtn.o:处理全局构造/析构(如 C++ 的全局对象构造函数、atexit 注册的函数),crti.o 包含.init和.fini段的开头,crtn.o包含结尾
3.crtbeginT.o和crtend.o
crtbeginT.o:用于静态链接的特殊版本,处理C++的全局构造函数和异常表初始化
crtend.o:与crtbeginT.o配对,清理全局对象和异常表
模块拼装——静态链接
当一个系统十分复杂时,为了达到各个突破的目的不得不将一个复杂的系统逐步分割成小的系统,一个复杂的软件也是一样的,所以会把每个源代码模块独立的编译,然后按需组装,也就是链接,链接的主要内容就是将各个模块建的相互引用部分处理好,使得各个模块间能够正确衔接,链接器所做的工作其实就是“程序员人工调整地址”(很久之前是用指代打孔操作的,打孔代表0,不打孔代表1,是机器语言,如果原先的指令中插入了新的指令就需要人工重新计算每个子程序或跳转的目标地址),区别就在于现代的高级语言有很多特性和功能,使得编译器、链接更加复杂,功能当然也更加强大,但是原理是一样的,都是把一些指令对其他符号地址的引用加以修正
链接的过程包括地址和空间分配、符号决议、重定位
地址和空间分配
为程序中的各个段(如代码段 .text、数据段 .data、未初始化数据段 .bss)分配最终的内存布局(虚拟地址空间)
合并相同类型的段:将所有输入目标文件的 .text段合并到输出文件的 .text段,.data段同理,举个例子
目标文件1.o: .text (代码A) + .data (数据X)
目标文件2.o: .text (代码B) + .data (数据Y)
可执行文件: .text (代码A+代码B) + .data (数据X+数据Y) //合并后
分配虚拟地址:确定每个段在进程虚拟地址空间中的起始位置
地址和空间分配解决多个目标文件中段的冲突问题(避免地址重叠),为后续的符号决议和重定位提供基础
符号决议
有时也叫做符号绑定或名称绑定或名称决议,甚至还有叫地址绑定、指令绑定的,大致是一样的,但是也有细节上的区分,‘决议’倾向于静态链接,‘绑定’则是倾向于动态链接,也就是说适用范围不一样,在静态链接中统一称为符号决议
用于将符号(函数名、变量名)的引用与其定义关联起来,确保所有符号都能找到唯一实现
解析符号引用:例如,main.o调用了printf,链接器需要找到printf在libc.a或libc.so中的定义
处理重复符号:如果多个目标文件定义了同名符号(如全局变量int global),链接器会报错或按规则选择其一(如强符号优先)。
举个例子
// main.c
extern void foo(); // 声明(未定义)
int main() { foo(); return 0; }// utils.c
void foo() {} // 定义
链接时,main.o中对foo的引用会被绑定到utils.o中的定义
补充:
main.c文件编译成main.o时,编译器看到extern void foo(),知道foo不是当前文件定义的,就会生成一条未绑定的调用指令(如 call 0x00000000),地址暂时填0,在符号表中标记foo为未解决(UND)
utils.c文件编译成utils.o时,编译器生成foo函数的机器码,在符号表中标记foo为已定义(DEF),并记录它的段内偏移地址(如 0x100)
当运行链接器ld main.o utils.o时:扫描所有目标文件,发现main.o需要foo(UND状态),发现utils.o提供了foo(DEF状态),然后就会绑定关系,也就是将main.o中对foo的引用绑定到utils.o中foo的实际地址,接着重定位修正,将main.o中原本的call 0x00000000修正为call <foo的真实地址>
符号决议是为了避免运行时因未定义符号导致崩溃
重定位
简单来说就是将各个目标的地址重新计算
重定位是链接器和加载器在程序链接或加载时,调整代码和数据的内存地址的过程,核心目的是解决程序在不同内存位置正确运行的问题
程序在编译时,编译器生成的代码和数据地址通常是 基于假设的起始地址(如 0x00000000),但实际运行时,操作系统会将程序加载到 随机的内存位置(如 0x8048000),因此需要调整所有地址引用
要注意这里的是静态重定位发生在程序链接时(由链接器完成),直接修改目标文件中的地址,生成绝对地址的可执行文件,程序加载后地址固定,无法再改变
静态链接过程
最基本的静态链接过程如下所示
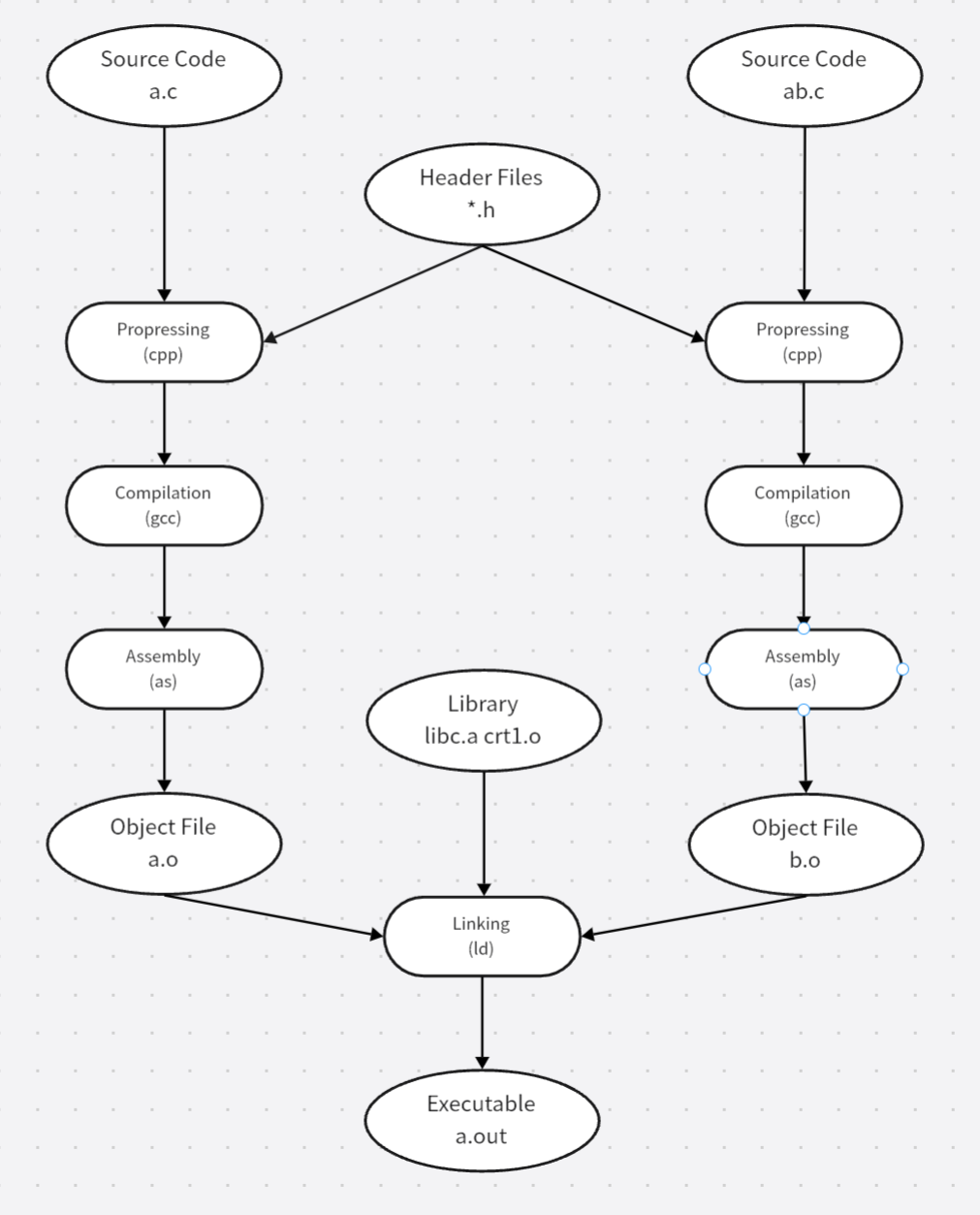
每个模块的源代码文件(如.c)文件经过编译器编译为目标文件(也就是Object File,一般为.o或.obj),目标文件和库一起链接形成可执行文件,而最常见的就是运行时库(支持程序运行的基本函数的合集),而库其实就是一组目标文件的包,也就是一些常用的代码编译成目标文件后打包存放
小结
对于Object文件没有适合的中文名称,叫做中间目标文件比较合适,简称目标文件,也会把目标文件称作模块
静态链接最基本的过程和作用:举个比较容易听懂的例子,加入现在在程序模块的main.c中使用另外一个模块func.c中的函数foo,在main.c中调用foo都必须知道确切的地址,但由于每个模块都是单独编译,所以main.c并不知道foo地址,然后就会暂时把调用了foo的指令目标地址搁置,等到最后链接时由链接器去修正地址,如果没有链接器就需要进行手动修正,填入正确的foo函数地址,当func.c模块重新编译时,foo地址就有可能改变,那么main.c中调用到foo的全部地方都要调整,很麻烦,使用链接器的话就会在引用其他模块的函数时自动去相应的模块查找地址,然后修正
在链接过程中,对其他定义在目标文件中的函数调用的指令须要重新调整,对使用其他定义在其他目标文件的变量来说,也是一样的接下来可以结合CPU指令了解一下过程,现在假设有一全局变量var在目标文件A中,在目标文件B中要访问这个全局变量,比如在目标文件B里有这样一条指令
movl $0x2a, var
给这个var变量赋值0x2a,相当于c语言中的语句var = 42,然后编译目标文件B,得到指令机器码
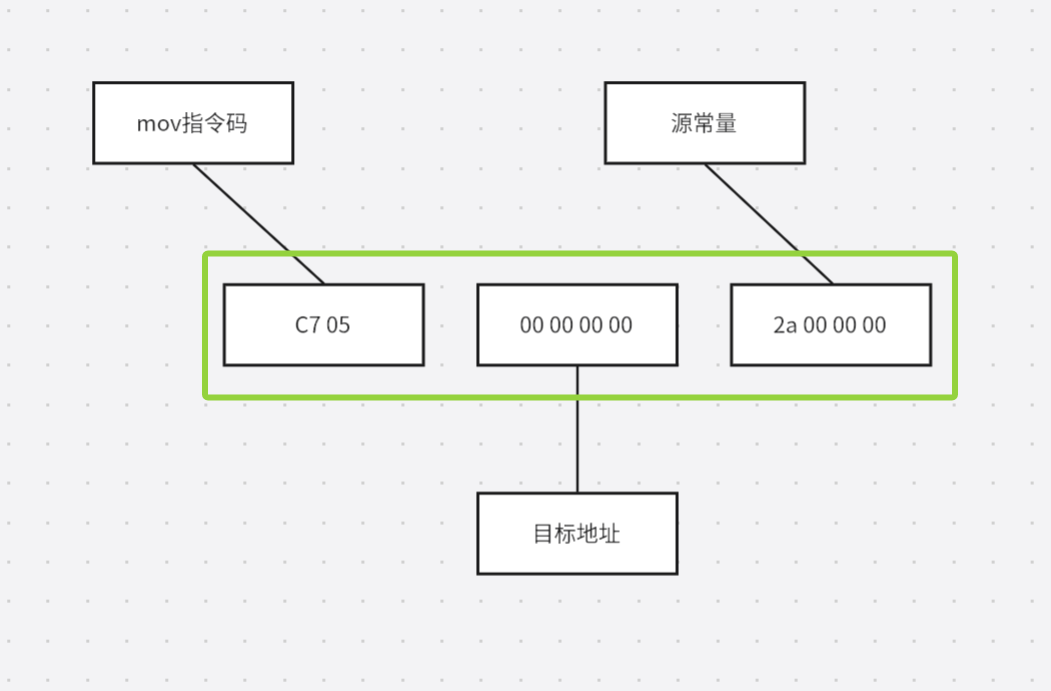
由于在编译目标文件B时,编译器不知道变量var的目标地址,所以编译器在无法确定地址的情况下将这条mov指令目标地址置为0,等待链接器在将目标文件A和B链接起来的时候会进行修正,假设链接后,变量var地址确定为0x10000,地址修正过程就叫做重定位,每一个要被修正的地方叫重定位入口