声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站:https://space.bilibili.com/1523287361 点击打开链接
微博地址: https://weibo.com/luoyepiaoxue2014 点击打开链接
title: Spark系列
一、Transformation 高级算子
官网链接: https://spark.apache.org/docs/3.1.2/streaming-programming-guide.html#transformations-on-dstreams
1.1 updateStateByKey

updateStateByKey可以实现累计
package com.aa.sparkscala.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.sparkscala.streaming
*/
object UpdateStateByKeyDemo {
def main(args: Array[String]): Unit = {
/**
* 1、程序入口
*/
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf()
conf.setMaster("local[2]")
conf.setAppName("UpdateStateByKeyDemo")
val ssc = new StreamingContext(conf,Seconds(2))
ssc.checkpoint("D://UpdateStateByKeyDemo_CheckPointDir")
/**
* 2、数据的输入
*/
val myDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop12",9991)
/**
* 3、数据的处理
*/
val wordDStream = myDStream.flatMap(_.split(" "))//hadoop hadoop hadoop
val wordAndOneDStream = wordDStream.map((_,1))
/**
* updateFunc: (Seq[V], Option[S]) => Option[S]
* 参数一:Seq[V]
* hadoop 1
* hadoop 1
* hadoop 1
* 分组:
* {hadoop,(1,1,1)} -> values (1,1,1)
*
* 参数二: Option[S]
* 当前的这个key的上一次的状态(历史的状态)
*
* Option:
* Some 有值
* None 没有值
* 返回值:
* 当前key出现的次数
*
*/
var resultDStream = wordAndOneDStream.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val lastCount = state.getOrElse(0)
Some(currentCount + lastCount)
})
/**
* 4、数据的输出
*/
resultDStream.print()
/**
* 5、启动程序
*/
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
1.2 mapWithState
代码
package com.aa.sparkscala.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming._
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.sparkscala.streaming
*
* MapWithStateAPIDemo 测试
*
* updateStateBykey 官网上能看到
* mapWithState 官方博客上面有,而且说测试过性能更好
*/
object MapWithStateAPIDemo {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(2))
ssc.checkpoint("D://MapWithStateAPIDemo_CheckPointDir")
val lines = ssc.socketTextStream("hadoop12", 9992)
val words = lines.flatMap(_.split(" "))
val wordsDStream = words.map(x => (x, 1))
val initialRDD = sc.parallelize(List(("flink", 100L), ("spark", 50L))) //初始的一些值
/**示例,假如输入 hadoop hadoop hadoop
* 切分之后变成了:
* hadoop 1
* hadoop 1
* hadoop 1
*
* 经过 mapWithState 里面的bykey操作 之后,变成了如下:
* {hadoop,(1,1,1) => 3}
*
* hadoop 3
*
* hadoop 10
*
* key:hadoop 当前的key
* value:3 当前的key出现的次数
* lastState: 当前的这个key的历史的状态
*
* hadoop:3
*
* hadoop,10
*
* hadoop,13
*
*/
// currentBatchTime : 表示当前的Batch的时间
// key: 表示需要更新状态的key
// value: 表示当前batch的对应的key的对应的值
// lastState : 对应key的当前的状态
val stateSpec =StateSpec.function((currentBatchTime: Time, key: String, value: Option[Int], lastState: State[Long]) => {
val sum = value.getOrElse(0).toLong + lastState.getOption.getOrElse(0L) //求和
val output = (key, sum)
//更改状态
//如果你的数据没有超时
if (!lastState.isTimingOut()) {
lastState.update(sum)
}
//最后一行代码是返回值
Some(output) //返回值要求是key-value类型
}).initialState(initialRDD)
.numPartitions(2).timeout(Seconds(15))
//timeout:超时。 当一个key超过这个时间没有接收到数据的时候,这个key以及对应的状态会被移除掉。也就是重新统计。
/**
* reduceByKey
*
* udpateStateByKey
* mapWithState // 里面也有bykey操作 -> 在bykey分组的时候顺带就完成了合并的操作
*/
val result = wordsDStream.mapWithState(stateSpec)
//result.print() //打印出来发生变化的那些数据
result.stateSnapshots().print() //打印出来的是全量的数据
//启动Streaming处理流
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
1.3 Transform实现黑名单过滤
package com.aa.sparkscala.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.sparkscala.streaming
*/
object TransformDemo {
def main(args: Array[String]): Unit = {
//0、打印日志
Logger.getLogger("org").setLevel(Level.WARN)
//1、程序入口
val sparkConf = new SparkConf().setAppName("TransformDemo").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(2))
//2、数据的输入
val lines = ssc.socketTextStream("hadoop12", 9993)
lines.print()
val words = lines.flatMap(_.split(" "))
val wordsDStream = words.map(x => (x, 1))
/**
* 3、数据的处理
*
* 首先要获取到黑名单,企业中可以从Mysql,Redis里面去获取。
* 我们这里 造一个 黑名单的的规则
* 其实也就是一个 过滤的小小的规则
* 比如: "$","?","!"
*/
val filterRDD: RDD[(String, Boolean)] = ssc.sparkContext.parallelize(List("$","?","!")).map((_,true))
//1、给过滤的规则数据广播出去
val filterBroadBast = ssc.sparkContext.broadcast(filterRDD.collect())
//mapRDD
val filterResultRDD: DStream[(String, Int)] = wordsDStream.transform(rdd => {
val filterRDD = ssc.sparkContext.parallelize(filterBroadBast.value)
//左连接 join,如果join不上的数据 大家可以想一下是不是需要的数据
/**
* (String(key), (Int(1), Option[Boolean]))
* 通过这个option没值 来进行判断
*/
val result: RDD[(String, (Int, Option[Boolean]))] = rdd.leftOuterJoin(filterRDD)
val joinResult = result.filter(tuple => {
tuple._2._2.isEmpty //过滤出来我们需要的数据
})
//在Scala里面最后一行就是方法的返回值 这个都是小知识 大家应该知道
//hadoop,1
joinResult.map(tuple => (tuple._1, tuple._2._1))
})
//4、数据的输出
val result = filterResultRDD.reduceByKey(_+_)
result.print()
//5、启动 程序
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
1.4 Window操作
1.4.1 代码
package com.aa.sparkscala.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.sparkscala.streaming
*/
object WindowDemo {
def main(args: Array[String]): Unit = {
//0、打印日志
Logger.getLogger("org").setLevel(Level.WARN)
//1、程序入口
val sparkConf = new SparkConf().setAppName("WindowDemo").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(2))
//2、数据的输入
val lines = ssc.socketTextStream("hadoop12", 9994)
//3、数据的处理
val words = lines.flatMap(_.split(" "))
val wordsDStream = words.map(x => (x, 1))
/**
* reduceFunc: (V, V) => V,
* windowDuration: Duration,
* slideDuration: Duration 滑动窗口的单位
*
* 请注意:窗口大小和滑动间隔必须是间隔的整数倍
* 间隔: val ssc = new StreamingContext(sc, Seconds(2))
* 窗口大小: Seconds(6)
* 滑动间隔: Seconds(4)
*
* 下面的代码的意思是 每隔2秒计算一下,最近6秒的单词出现的次数。
* reduceByKeyAndWindow((x:Int,y:Int) => x+y,Seconds(6),Seconds(1))
*/
val result = wordsDStream.reduceByKeyAndWindow((x:Int,y:Int) => x+y,Seconds(6),Seconds(4))
//4、数据的输出
result.print()
//5、程序的启动
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
1.4.2 可能遇到的错误及解决方案
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Exception in thread "main" java.lang.Exception: The slide duration of windowed DStream (3000 ms) must be a multiple of the slide duration of parent DStream (2000 ms)
at org.apache.spark.streaming.dstream.WindowedDStream.<init>(WindowedDStream.scala:41)
at org.apache.spark.streaming.dstream.DStream.$anonfun$window$1(DStream.scala:768)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.SparkContext.withScope(SparkContext.scala:786)
at org.apache.spark.streaming.StreamingContext.withScope(StreamingContext.scala:264)
at org.apache.spark.streaming.dstream.DStream.window(DStream.scala:768)
at org.apache.spark.streaming.dstream.PairDStreamFunctions.$anonfun$reduceByKeyAndWindow$4(PairDStreamFunctions.scala:277)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.SparkContext.withScope(SparkContext.scala:786)
at org.apache.spark.streaming.StreamingContext.withScope(StreamingContext.scala:264)
at org.apache.spark.streaming.dstream.PairDStreamFunctions.reduceByKeyAndWindow(PairDStreamFunctions.scala:278)
at org.apache.spark.streaming.dstream.PairDStreamFunctions.$anonfun$reduceByKeyAndWindow$2(PairDStreamFunctions.scala:233)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.SparkContext.withScope(SparkContext.scala:786)
at org.apache.spark.streaming.StreamingContext.withScope(StreamingContext.scala:264)
at org.apache.spark.streaming.dstream.PairDStreamFunctions.reduceByKeyAndWindow(PairDStreamFunctions.scala:233)
at com.aa.sparkscala.streaming.WindowDemo$.main(WindowDemo.scala:36)
at com.aa.sparkscala.streaming.WindowDemo.main(WindowDemo.scala)
Process finished with exit code 1
出现上面的错误的原因是因为窗口大小和滑动间隔必须是间隔的整数倍
例如:
* 间隔: val ssc = new StreamingContext(sc, Seconds(2))
* 窗口大小: Seconds(6)
* 滑动间隔: Seconds(4)
1.5 关于测试nc -lk的说明
在测试的时候可以在linux中使用nc -lk进行模拟数据的输入
[root@hadoop12 ~]# nc -lk 9992
flink
hbase
hadoop
....
二、Output 高级算子
拿核心算子讲解
2.1 foreachRDD
2.1.1 添加pom依赖
这是因为我们要给测试的输出的结果添加到mysql中去。所以要添加mysql的相关依赖。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
2.1.2 代码
package com.aa.sparkscala.streaming
import org.apache.log4j.{Level, Logger}
import java.sql.DriverManager
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.sparkscala.streaming
*
* ForeachDemo 多种案例
*/
object ForeachDemo {
def main(args: Array[String]) {
//0、打印日志
Logger.getLogger("org").setLevel(Level.WARN)
//1、程序入口
val sparkConf = new SparkConf().setAppName("ForeachDemo").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(4))
//2、数据的输入
val lines = ssc.socketTextStream("hadoop12", 9995)
//3、数据的处理
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
//4、数据的输出 将结果保存到Mysql 代码可以运行。
wordCounts.foreachRDD { (rdd, time) =>
rdd.foreach { record =>
//为每一条数据都创建了一个连接。
//连接使用完了以后就关闭。 频繁的创建和关闭连接。其实对数据性能影响很大。 这个就是可以优化的点 同学们自己考虑,自己动手解决
//executor,worker
Class.forName("com.mysql.jdbc.Driver")
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/spark", "root", "111111")
val statement = conn.prepareStatement(s"insert into wordcount(ts, word, count) values (?, ?, ?)")
statement.setLong(1, time.milliseconds.toLong)
statement.setString(2, record._1)
statement.setInt(3, record._2)
statement.execute()
statement.close()
conn.close()
}
}
//启动Streaming处理流
ssc.start()
//等待Streaming程序终止
ssc.awaitTermination()
ssc.stop()
}
}
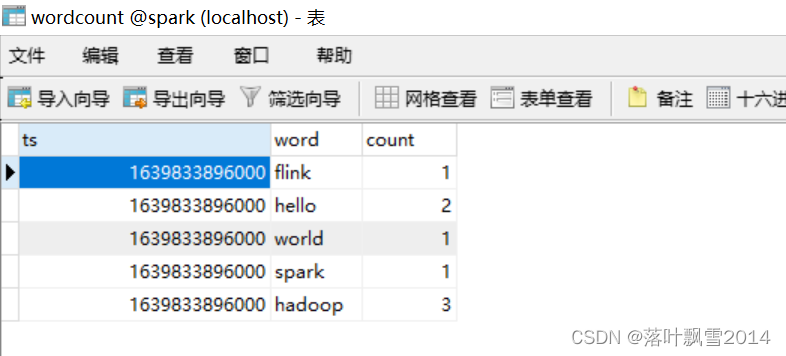
2.1.3 测试结果
在shell窗口中输入对应的数据
[root@hadoop12 ~]# nc -lk 9995
hello hadoop world spark flink hadoop hello hadoop

查看mysql中的结果
三、Checkpoint
package com.aa.sparkscala.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.sparkscala.streaming
* 为了保证 Driver 的 HA
*/
object UpdateStateByKeyDemo {
def main(args: Array[String]): Unit = {
/**
* 1、程序入口
*/
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf()
conf.setMaster("local[2]")
conf.setAppName("UpdateStateByKeyDemo")
val ssc = new StreamingContext(conf,Seconds(2))
ssc.checkpoint("D://UpdateStateByKeyDemo_CheckPointDir")
/**
* 2、数据的输入
*/
val myDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop12",9996)
/**
* 3、数据的处理
*/
val wordDStream = myDStream.flatMap(_.split(" "))//hadoop hadoop hadoop
val wordAndOneDStream = wordDStream.map((_,1))
/**
* updateFunc: (Seq[V], Option[S]) => Option[S]
* 参数一:Seq[V]
* hadoop 1
* hadoop 1
* hadoop 1
* 分组:
* {hadoop,(1,1,1)} -> values (1,1,1)
*
* 参数二: Option[S]
* 当前的这个key的上一次的状态(历史的状态)0
*
* Option:
* Some 有值
* None 没有值
* 返回值:
* 当前key出现的次数
*
*/
var resultDStream = wordAndOneDStream.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val lastCount = state.getOrElse(0)
Some(currentCount + lastCount)
})
/**
* 4、数据的输出
*/
resultDStream.print()
/**
* 5、启动程序
*/
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
四、SparkStreaming和SparkSQL整合
SparkStreaming和SparkSQL整合之后,就非常的方便,可以使用SQL的方式操作相应的数据。很方便。
package com.aa.sparkscala.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.sparkscala.streaming
*/
object StreamAndSQLDemo {
def main(args: Array[String]): Unit = {
//0、打印日志
Logger.getLogger("org").setLevel(Level.WARN)
//1、程序入口
val sparkConf = new SparkConf().setAppName("StreamAndSQLDemo").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(5)) //SS其实是准实时 flink是真正的实时
//2、数据的输入
val lines = ssc.socketTextStream("hadoop12", 9997)
//3、数据的处理
val words = lines.flatMap(_.split(" "))
// 获取到一个一个的单词
words.foreachRDD( rdd =>{
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// 隐式转换
val wordDataFrame = rdd.toDF("word")
// 注册一个临时视图
wordDataFrame.createOrReplaceTempView("words")
//4、数据的输出
spark.sql("select word,count(*) as totalCount from words group by word")
.show()
})
//5、程序的启动
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}