目录
0 体验
1 摘要
2 十个问题
参考文献
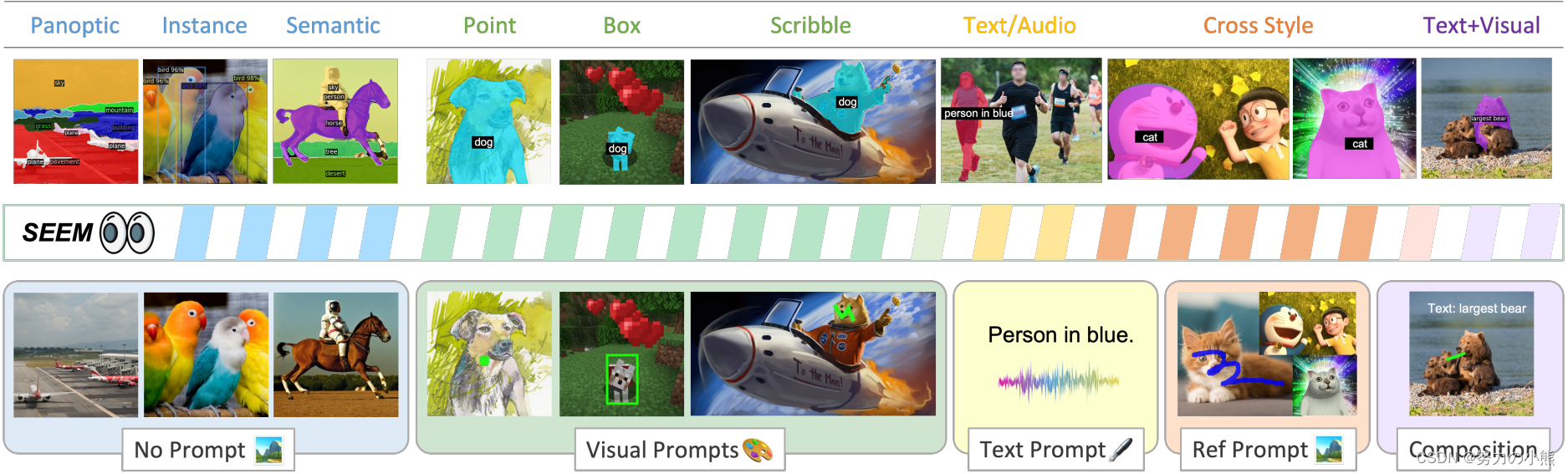
0 体验
体验地址:SEEM - a Hugging Face Space by xdecoder
体验结果:
将哈士奇和汽车人从图片中分割出来。

1 摘要
尽管对于交互式人工智能系统的需求不断增长,但在视觉理解(例如分割)中的人工智能交互方面,很少有全面的研究。本文受到基于提示的通用界面发展的启发,介绍了SEEM,一种可提示、交互式模型,用于在图像中一次性分割所有内容。SEEM具有四个期望目标:多样化、组合性、交互性和语义感知。我们通过引入多功能提示引擎实现多样化、通过学习联合视觉-语义空间为视觉和文本提示组合查询提供即时推理支持的组合性、通过允许用户使用额外提示交互地改进分割结果实现交互性、以及利用联合嵌入空间实现对未见过提示的零样本泛化的语义感知。广泛的实验表明,我们的模型在几个开放词汇和交互式分割基准测试中具有竞争性的性能。
2 十个问题
Q1:论文试图解决什么问题?
A1:本文试图解决在视觉理解中的人工智能交互方面的全面研究问题,特别是在分割任务中。作者提出了一种可提示、交互式模型SEEM,用于在图像中一次性分割所有内容。
Q2:这是否是一个新的问题?
A2:这不是一个新的问题,但是本文提出了一种新的方法来解决这个问题。
Q3:这篇文章要验证一个什么科学假设?
A3:本文要验证SEEM模型是否能够实现多样化、组合性、交互性和语义感知,并且在几个开放词汇和交互式分割基准测试中具有竞争性的性能。
Q4:有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
A4:与本文相关的研究包括视觉理解、分割任务和人工智能交互等领域。本文提出了一种新方法来解决这个问题。值得关注的研究员包括Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida等人。
Q5:论文中提到的解决方案之关键是什么?
A5:论文中提到的解决方案的关键是SEEM模型,它具有多样化、组合性、交互性和语义感知等特点。
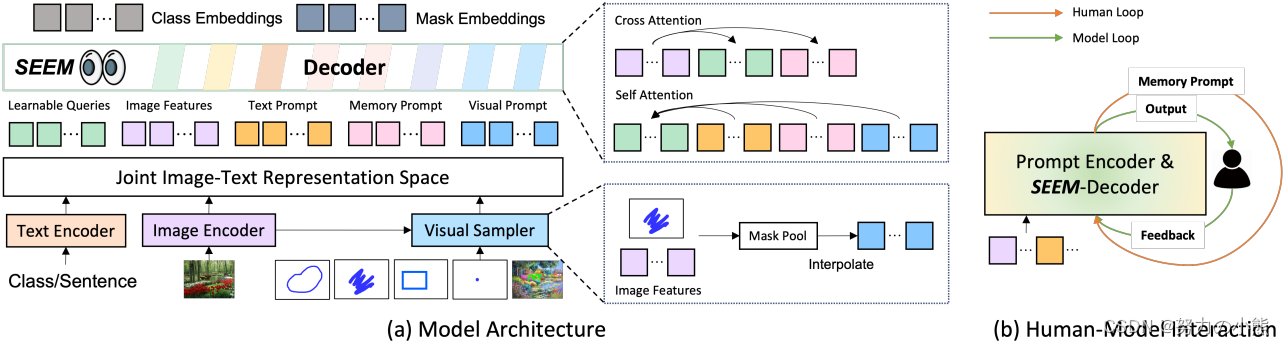
Q6:论文中的实验是如何设计的?
A6:本文中的实验设计包括使用不同类型的提示进行交互式分割,并在几个开放词汇和交互式分割基准测试中进行了评估。
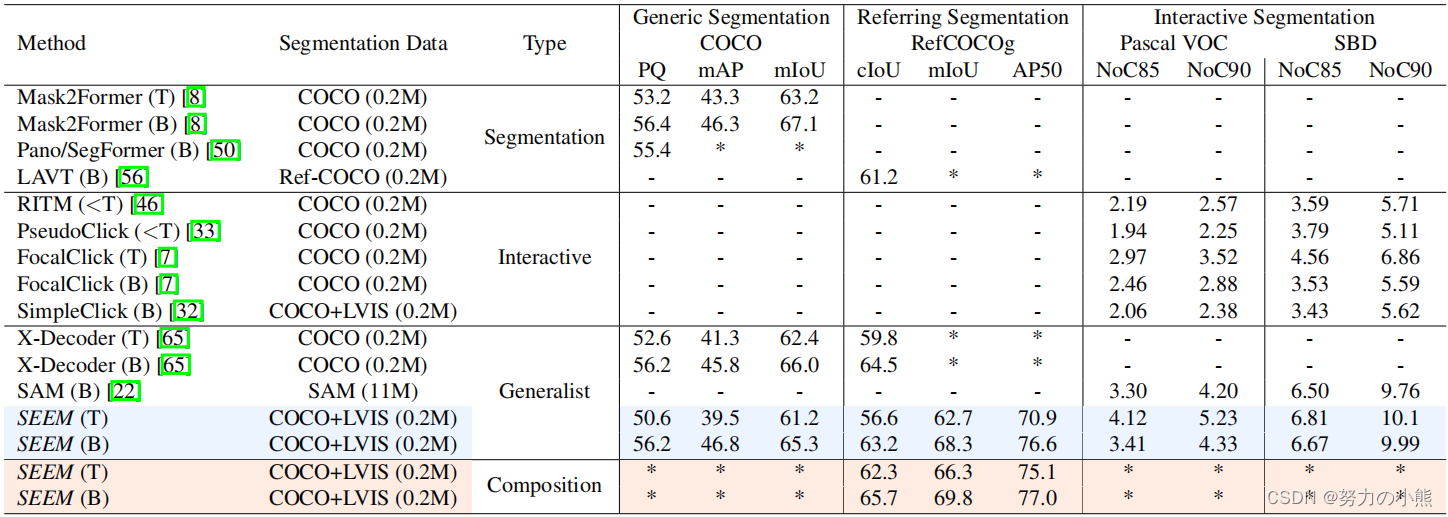
Q7:用于定量评估的数据集是什么?代码有没有开源?
A7:本文使用了几个开放词汇和交互式分割基准测试数据集进行定量评估,包括COCO-Stuff, ADE20K, ScribbleSup, and ReferItGame。作者已经公开了SEEM模型的代码。
GitHub - UX-Decoder/Segment-Everything-Everywhere-All-At-Once: Official implementation of the paper "Segment Everything Everywhere All at Once"Official implementation of the paper "Segment Everything Everywhere All at Once" - GitHub - UX-Decoder/Segment-Everything-Everywhere-All-At-Once: Official implementation of the paper "Segment Everything Everywhere All at Once" https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-OnceQ8:论文中的实验及结果有没有很好地支持需要验证的科学假设?
https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-OnceQ8:论文中的实验及结果有没有很好地支持需要验证的科学假设?
A8:是的,本文中的实验及结果很好地支持了需要验证的科学假设。SEEM模型在多样化、组合性、交互性和语义感知等方面表现出色,并在几个开放词汇和交互式分割基准测试中具有竞争性的性能。
Q9:这篇论文到底有什么贡献?
A9:本文提出了一种新方法来解决视觉理解中人工智能交互方面的全面研究问题,特别是在分割任务中。作者提出了一种可提示、交互式模型SEEM,用于在图像中一次性分割所有内容,并且在几个开放词汇和交互式分割基准测试中具有竞争性的性能。
Q10:下一步呢?有什么工作可以继续深入?
A10:下一步,可以进一步探索SEEM模型在其他视觉理解任务中的应用,例如目标检测和图像分类。此外,可以进一步改进SEEM模型的性能和效率,并将其应用于实际场景中。
参考文献
https://arxiv.org/pdf/2304.06718.pdf![]() https://arxiv.org/pdf/2304.06718.pdf
https://arxiv.org/pdf/2304.06718.pdf