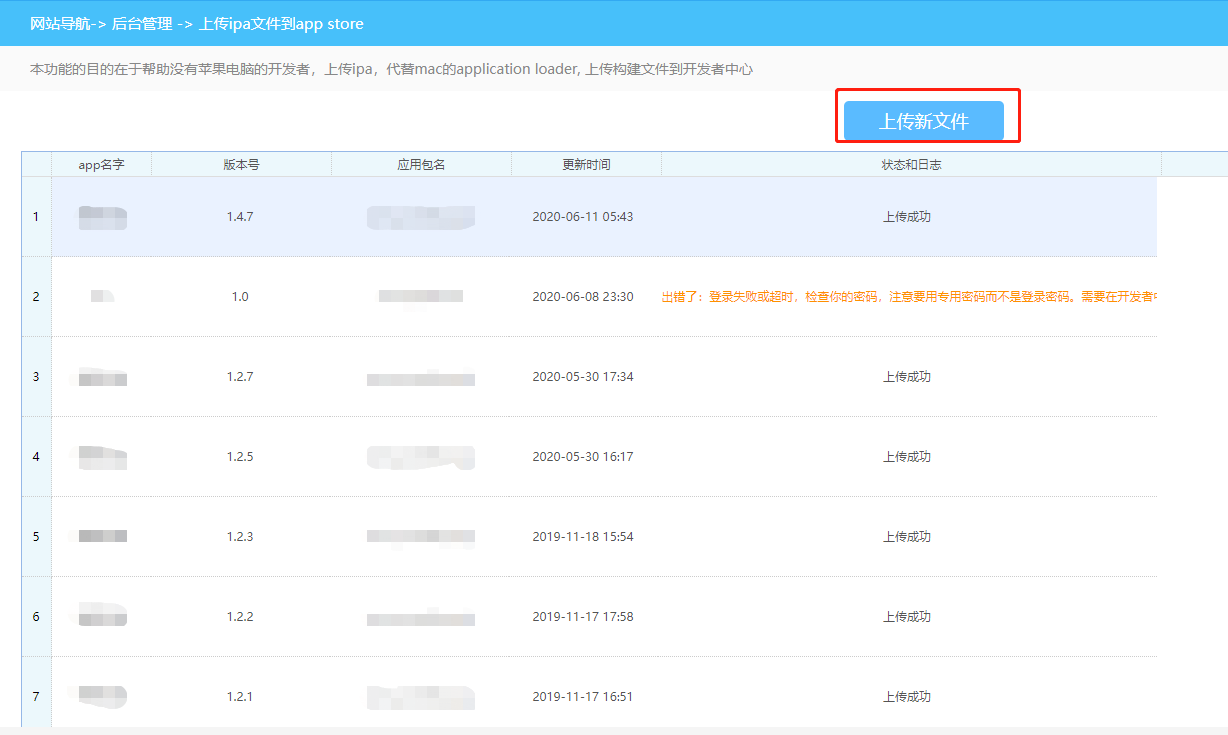
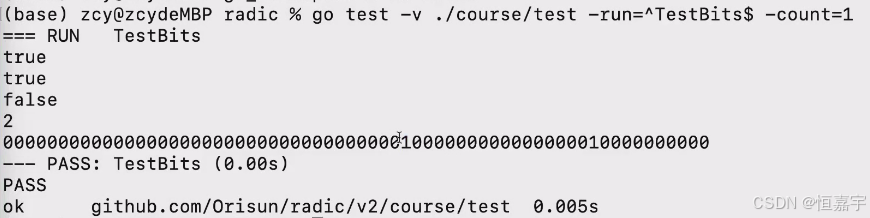
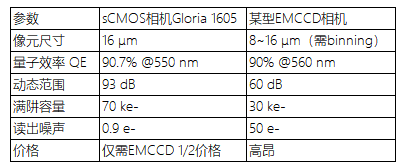
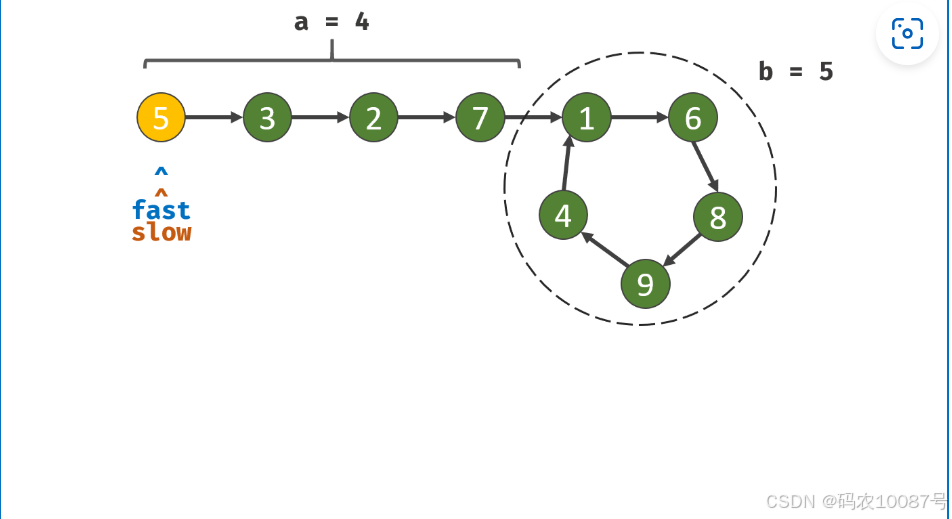
A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models
➡️ 论文标题:A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models
➡️ 论文作者:Jie Liu, Wenxuan Wang, Yihang Su, Jingyuan Huan, Wenting Chen, Yudi Zhang, Cheng-Yi Li, Kao-Jung Chang, Xiaohan Xin, Linlin Shen, Michael R. Lyu
➡️ 研究机构: The City University of Hong Kong、The Chinese University of Hong Kong、Shenzhen University、National Yang Ming Chiao Tung University、Taipei Veterans General Hospital、Stanford University
➡️ 问题背景:当前的医疗多模态大语言模型(Med-MLLMs)在现代医疗中展现出强大的信息综合和医疗决策支持能力。然而,这些模型的评估通常依赖于不适用于Med-MLLMs的有限样本,导致对其能力的评估不全面。现有的医疗基准测试方法往往无法准确衡量Med-MLLMs的复杂能力,尤其是在不同专科和诊断能力方面。
➡️ 研究动机:为了填补这一空白,研究团队提出了Asclepius,这是一个新的Med-MLLMs基准测试,旨在全面评估这些模型在不同医疗专科和诊断能力方面的表现。Asclepius基于三个核心原则设计:多专科覆盖、多维度能力评估和原创性与盲测。通过这些原则,Asclepius确保了对Med-MLLMs的全面、系统和公正的评估。
➡️ 方法简介:研究团队构建了一个系统化的数据集,包含3,232个原创的多模态问题,涵盖了15个医疗专科和8个能力评估维度。数据集的构建采用了两种策略:一是从现有的医学图像数据集中生成问题-答案对;二是从美国医学执照考试(USMLE)和当前的医学教科书中提取问题-答案对。所有问题都经过了医学学生的改写和审查,并由资深医生验证,确保了数据的质量和准确性。
➡️ 实验设计:实验在四个通用的多模态大语言模型(GPT-4V、GPT-4o、Gemini、Claude 3.5 Sonnet)和五个专门的Med-MLLMs(CheX-agent、RadFM、Med-Flamingo、XrayGPT、BiomedGPT-B)上进行。实验设计了不同的评估指标,包括多项选择题、是非题、开放式问题和报告生成任务。此外,研究还邀请了三位临床专科医生参与评估,以建立人类专家的性能基准。实验结果表明,GPT-4V在大多数专科和能力评估中表现最佳,接近人类医生的水平,而其他模型的表现则相对较低。
Efficient Multimodal Learning from Data-centric Perspective
➡️ 论文标题:Efficient Multimodal Learning from Data-centric Perspective
➡️ 论文作者:Muyang He, Yexin Liu, Boya Wu, Jianhao Yuan, Yueze Wang, Tiejun Huang, Bo Zhao
➡️ 研究机构: 北京人工智能研究院、北京大学、香港科技大学(广州)、牛津大学、上海交通大学
➡️ 问题背景:多模态大型语言模型(MLLMs)在视觉理解和推理任务中表现出显著的能力。然而,这些模型的部署受到训练和推理阶段巨大计算成本的限制,这阻碍了它们在更广泛的研究和用户社区中的普及。尽管使用较小的预训练视觉和语言模型可以降低成本,但这通常会导致性能显著下降。
➡️ 研究动机:为了克服性能下降的问题,研究团队提出了一种通过优化高质量训练数据来训练更小但性能更好的MLLMs的方法。具体来说,研究团队引入了Bunny,一个轻量级MLLMs家族,通过精选的训练数据实现高效的多模态学习。实验结果表明,Bunny-4B/8B在多个基准测试中超越了现有的大型MLLMs。
➡️ 方法简介:研究团队通过数据集浓缩技术构建了高质量的训练数据集,包括Bunny-pretrain-LAION-2M和Bunny-695K。这些数据集用于模型的预训练和指令调优。Bunny模型包括三个主要模块:语言模型主干、视觉编码器和跨模态投影器。研究团队还探索了LoRA微调、高分辨率图像处理、权重合并等技术,以进一步提升模型性能。
➡️ 实验设计:研究团队在11个流行的基准测试上评估了Bunny模型的性能,包括MME感知、MME认知、MMBench测试集和开发集、SEED-Bench-1、MMMU验证集和测试集、VQA-v2测试开发集、GQA测试开发平衡集、ScienceQA-IMG测试集和POPE。实验结果表明,Bunny-4B/8B在大多数基准测试中均优于现有的大型MLLMs。
CoCo-Agent: A Comprehensive Cognitive MLLM Agent for Smartphone GUI Automation
➡️ 论文标题:CoCo-Agent: A Comprehensive Cognitive MLLM Agent for Smartphone GUI Automation
➡️ 论文作者:Xinbei Ma, Zhuosheng Zhang, Hai Zhao
➡️ 研究机构: 上海交通大学电子信息技术与电气工程学院、计算机科学与工程系、智能交互与认知工程上海市教委重点实验室、Web3可信数据流通与治理上海市重点实验室
➡️ 问题背景:当前的多模态大语言模型(MLLMs)在图形用户界面(GUI)自动化任务中展现出显著的潜力,但这些模型在实际应用中面临两大挑战:一是对强大的(M)LLMs的依赖,二是GUI环境建模的不足。这些问题限制了模型在实际场景中的表现,尤其是在生成准确的GUI命令和处理隐私与安全问题方面。
➡️ 研究动机:为了克服上述挑战,研究团队提出了一个全面认知的MLLM代理(CoCo-Agent),旨在通过增强环境感知和条件动作预测,系统地提升GUI自动化性能。研究旨在通过改进模型的感知和响应能力,提高其在实际应用中的可靠性和安全性。
➡️ 方法简介:CoCo-Agent采用了LLaVA作为多模态骨干,并提出了两种新方法:全面环境感知(CEP)和条件动作预测(CAP)。CEP通过整合文本目标、历史动作和视觉通道的高、低层次描述,增强GUI感知。CAP将复杂的GUI动作命令分解为子问题,按照自上而下的顺序进行预测,从而提高动作预测的准确性和效率。
➡️ 实验设计:研究在AITW和META-GUI两个基准数据集上进行了实验,涵盖了应用操作、网页操作和对话等多种任务。实验设计了不同的感知元素(如文本目标、历史动作)和视觉模块选择,以及未来动作预测的分析,以全面评估CoCo-Agent的性能和潜力。实验结果表明,CoCo-Agent在这些任务上达到了新的最先进水平,展示了其在实际场景中的应用潜力。
Model Tailor: Mitigating Catastrophic Forgetting in Multi-modal Large Language Models
➡️ 论文标题:Model Tailor: Mitigating Catastrophic Forgetting in Multi-modal Large Language Models
➡️ 论文作者:Didi Zhu, Zhongyi Sun, Zexi Li, Tao Shen, Ke Yan, Shouhong Ding, Kun Kuang, Chao Wu
➡️ 研究机构: 浙江大学、腾讯优图实验室
➡️ 问题背景:多模态大型语言模型(MLLMs)在处理未见过的任务时,通常会导致在原始任务上的性能显著下降,这种现象被称为灾难性遗忘(Catastrophic Forgetting)。这种现象在多模态生成和理解任务中尤为突出,如图像描述和视觉问答。
➡️ 研究动机:现有的缓解灾难性遗忘的方法主要针对小型模型,且依赖于全模型微调,这在MLLMs中不仅计算成本高昂,而且效果有限。研究团队旨在提出一种参数高效的后训练调整方法,以在提升新任务性能的同时,保持模型在原始任务上的性能。
➡️ 方法简介:研究团队提出了Model Tailor方法,该方法通过保留预训练参数,仅替换少量(≤10%)微调参数,来有效缓解灾难性遗忘。具体而言,Model Tailor通过融合显著性和敏感性分析,生成稀疏掩码来识别“模型补丁”,并引入补偿机制来“装饰补丁”,以增强模型在目标任务和原始任务上的性能。
➡️ 实验设计:研究团队在InstructBLIP和LLaVA-1.5两个模型上进行了实验,涵盖了图像描述和视觉问答任务。实验设计了不同任务的组合,以评估模型在多任务场景下的性能。实验结果表明,Model Tailor在保持原始任务性能的同时,显著提升了新任务的性能,且在多任务场景下表现出色。
Browse and Concentrate: Comprehending Multimodal Content via prior-LLM Context Fusion
➡️ 论文标题:Browse and Concentrate: Comprehending Multimodal Content via prior-LLM Context Fusion
➡️ 论文作者:Ziyue Wang, Chi Chen, Yiqi Zhu, Fuwen Luo, Peng Li, Ming Yan, Ji Zhang, Fei Huang, Maosong Sun, Yang Liu
➡️ 研究机构: 清华大学、阿里巴巴集团、上海人工智能实验室、江苏协同创新语言能力中心
➡️ 问题背景:多模态大语言模型(MLLMs)在多种视觉-语言任务中表现出色,但它们在处理涉及多张图像的上下文时存在局限性。主要原因是每个图像的视觉特征在被送入大语言模型(LLMs)之前,由冻结的编码器单独编码,缺乏对其他图像和多模态指令的感知。这种现象被称为先验LLM模态隔离,包括图像-文本隔离和图像间隔离。
➡️ 研究动机:现有的研究已经揭示了模态隔离问题对MLLMs性能的影响。为了进一步理解这些问题,并探索解决方案,研究团队提出了一种新的范式——浏览-集中(Browse-and-Concentrate, Brote),旨在通过两阶段的方法,先对输入进行初步浏览,生成条件上下文向量,再在该向量的指导下深入理解多模态输入,从而提高模型对多图像输入的理解能力。
➡️ 方法简介:研究团队提出了浏览-集中(Brote)范式,该范式包括两个阶段:浏览阶段和集中阶段。在浏览阶段,模型对输入进行初步浏览,生成条件上下文向量;在集中阶段,模型在该向量的指导下深入理解多模态输入。此外,研究团队还开发了训练策略,以增强模型对浏览阶段生成的条件上下文向量的利用能力。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括视觉-语言理解(NLVR2)、图像问答(VQAv2、A-OKVQA)、视频问答(MSVD QA、MSRVTT QA)等任务。实验设计了不同的训练策略,如上下文丢弃(context dropping),以评估模型在不同条件下的表现。实验结果表明,Brote范式显著提高了模型在多图像场景下的性能,平均准确率分别提高了2.13%和7.60%。



![[C]基础13.深入理解指针(5)](https://i-blog.csdnimg.cn/img_convert/fdec36001df774bf9ccaa70641292453.png#pic_center)