目录
一、环境配置
1. 通过SSH连接服务器
2. 查看服务器已安装模块
3. 调用Anaconda模块
4. 创建Python3.7的虚拟环境(不是必须。不需要的话可以使用默认安装的环境)
5. 虚拟环境下安装CUDA11.6+Pytorch1.12.1
二、使用方法
1、提交作业
2、其他命令
3、注意事项
一、环境配置
1. 通过SSH连接服务器
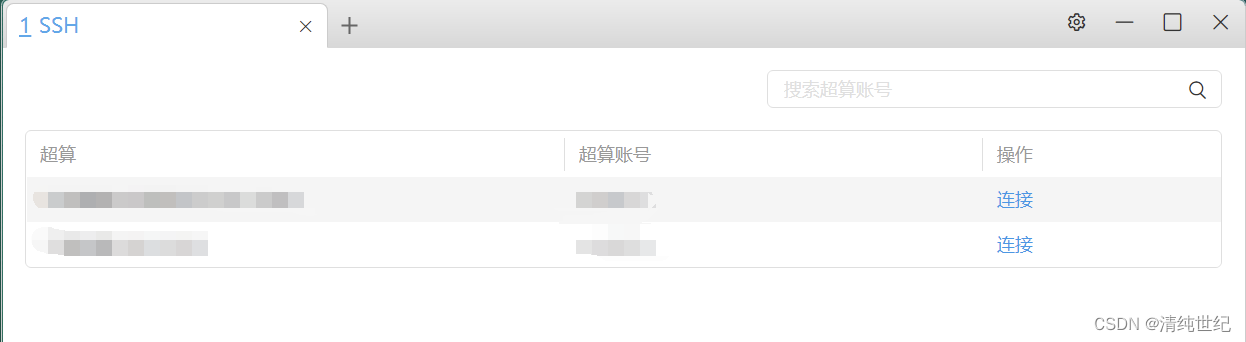
点击桌面SSH图标,显示当前账号可访问的云服务器,点击想要连接的服务器。
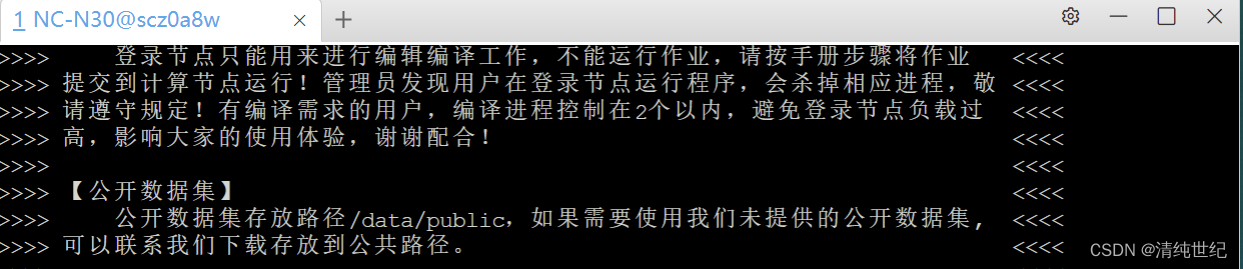
显示当前页面表明服务器连接成功。
2. 查看服务器已安装模块
在SSH终端输入命令 module avail
踩过的坑:如果输入module avail显示command module not found,则先输入source path/path/module.sh(一般这里路径会在连接服务器时有提示),再输入module avail。通常服务器已经预先装好anaconda,cuda等常用环境。
3. 调用Anaconda模块
module load anaconda/2021.054. 创建Python3.7的虚拟环境(不是必须。不需要的话可以使用默认安装的环境)
conda create -n my_name python=3.7 # my_name 是虚拟环境名字5. 虚拟环境下安装CUDA11.6+Pytorch1.12.1
sources activate my_name # 如果创建了虚拟环境,先激活虚拟环境。没创建则跳过
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
# 安装成功,但通过print(torch.cuda.is_available())返回False,主要是未向云服务器请求分配GPU的原因
# 则需要申请GPU分配后才可以使用GPUGPU分配申请:
1、salloc --gpus=1 抢占一个计算节点
2、squeue 查看节点名,最后一列
3、ssh gxxx 登录计算节点此时,配置Pytorch环境完成!
二、使用方法
1、提交作业
提交作业,需要先向服务器上传 模型 和设置好的 .sh 文件。使用桌面上的 快传


.sh 文件的配置模板如下:(编辑器,编辑脚本中第三行,将xxx改为实际用conda创建的虚拟环境名,最后一行python命令后xxx.py修改为自己的代码文件或完整命令即可)
#!/bin/bash
module load anaconda/2021.05
source activate xxx
export PYTHONUNBUFFERED=1
python xxx.py然后在服务器中,进入到该文件夹,利用如下命令提交作业。
sbatch --gpus=卡数 ./run.sh2、其他命令
-
查看作业情况
squeue- 结束作业
scancel 作业号(作业号执行squeue即可查看到)- 实时查看输出文件
tail -f 文件名(文件夹下的.out文件)- 查看详细历史作业
sacct -u $USER -S 2023-01-01-00:00 -E now --field=jobid,partition,jobname,user,nnodes,ncpus,nodelist,submit,start,end,elapsed,state,time-u paratera是指查看paratera账号的历史作业,
-S是开始查询时间,
-E是截止查询时间,
–format定义了输出的格式,
jobid是指作业号,
partition是指提交队列,
user是指超算账号名,
nnodes是节点数,
nodelist是节点列表,
start是开始运行时间,
end是作业退出时间,
elapsed是运行时间,
state是作业结束状态。
sacct --helpformat可以查看支持的输出格式。
sacct的其他参数选项可通过sacct --help查看。
- 查看作业及查看每个作业的GPU利用率
parajobs3、注意事项
我们提交作业用的是sbatch,而不是salloc。
主要是因为salloc这样的方式,会受到本地网络的影响,而sbatch提交的不会,即便您本地电脑关机,这样提交到计算节点的作业也不会受影响。另外,通过salloc抢占的节点,建议通过 :scancel JOBID 这个命令取消作业,如果不采用该命令取消,有一种情况就是,退出的时候可能刚好本地网络波动导致作业没有取消成功,就一直挂着计费,导致浪费。因此,退出后最好执行squeue命令查看下是否成功退出了,没有退出的话,就执行scancel命令取消。