CKA证书模拟24道题-题解
快捷别名
alias k=kubectl # will already be pre-configured
export do="--dry-run=client -o yaml" # k create deploy nginx --image=nginx $do
export now="--force --grace-period 0" # k delete pod x $now
vim设置
set tabstop=2
set expandtab
set shiftwidth=2
题库1
任务权重:1%
您可以通过上下文从主终端访问多个集群。将所有这些上下文名称写入 。kubectl/opt/course/1/contexts
接下来编写一个命令以将当前上下文显示到 ,该命令应使用 。/opt/course/1/context_default_kubectl.shkubectl
最后在 中编写执行相同操作的第二个命令,但不使用 ./opt/course/1/context_default_no_kubectl.shkubectl
You have access to multiple clusters from your main terminal through kubectl contexts. Write all those context names into /opt/course/1/contexts.
Next write a command to display the current context into /opt/course/1/context_default_kubectl.sh, the command should use kubectl.
Finally write a second command doing the same thing into /opt/course/1/context_default_no_kubectl.sh, but without the use of kubectl.
题解
k config get-contexts
k config get-contexts -o name > /opt/course/1/contexts
或者
Or using jsonpath:
k config view -o yaml # overview
k config view -o jsonpath="{.contexts[*].name}"
k config view -o jsonpath="{.contexts[*].name}" | tr " " "\n" # new lines
k config view -o jsonpath="{.contexts[*].name}" | tr " " "\n" > /opt/course/1/contexts
#/opt/course/1/contexts
k8s-c1-H
k8s-c2-AC
k8s-c3-CCC
接下来创建第一个命令
# /opt/course/1/context_default_kubectl.sh
kubectl config current-context
➜ sh /opt/course/1/context_default_kubectl.sh
k8s-c1-H
第二个
# /opt/course/1/context_default_no_kubectl.sh
cat ~/.kube/config | grep current
➜ sh /opt/course/1/context_default_no_kubectl.sh
current-context: k8s-c1-H
第二个命令也可以改进为
# /opt/course/1/context_default_no_kubectl.sh
cat ~/.kube/config | grep current | sed -e "s/current-context: //"
题库2
任务权重:3%
使用上下文:kubectl config use-context k8s-c1-H
在命名空间中创建单个映像 Pod。应该命名 Pod,容器应该命名。此 Pod 应该只调度在控制平面节点上,不要在任何节点上添加新标签。httpd:2.4.41-alpinedefaultpod1pod1-container
Use context: kubectl config use-context k8s-c1-H
Create a single Pod of image httpd:2.4.41-alpine in Namespace default. The Pod should be named pod1 and the container should be named pod1-container. This Pod should only be scheduled on a controlplane node, do not add new labels any nodes.
题解
答:
首先,我们找到控制平面节点及其污点:
k get node # find controlplane node
k describe node cluster1-controlplane1 | grep Taint -A1 # get controlplane node taints
k get node cluster1-controlplane1 --show-labels # get controlplane node labels
接下来我们创建 Pod 模板:
# check the export on the very top of this document so we can use $do
k run pod1 --image=httpd:2.4.41-alpine $do > 2.yaml #追加为yaml文件
vim 2.yaml
手动执行必要的更改。使用 Kubernetes 文档并搜索例如容忍和 nodeSelector 来查找示例:
# 2.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod1
name: pod1
spec:
containers:
- image: httpd:2.4.41-alpine
name: pod1-container # change
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
tolerations: # add
- effect: NoSchedule # add
key: node-role.kubernetes.io/control-plane # add
nodeSelector: # add
node-role.kubernetes.io/control-plane: "" # add
status: {}
这里重要的是添加在控制平面节点上运行的容差,以及 nodeSelector,以确保它只在控制平面节点上运行。如果我们只指定容忍度,则可以 在控制平面或工作节点上调度 Pod。
现在我们创建它:
k -f 2.yaml create
让我们检查一下 Pod 是否已调度:
➜ k get pod pod1 -o wide
NAME READY STATUS RESTARTS ... NODE NOMINATED NODE
pod1 1/1 Running 0 ... cluster1-controlplane1 <none>
题库3
任务权重:1%
使用上下文:kubectl config use-context k8s-c1-H
命名空间中有两个命名的 Pod。C13 管理层要求您将 Pod 缩减到一个副本以节省资源。o3db-*project-c13
Use context: kubectl config use-context k8s-c1-H
There are two Pods named in Namespace . C13 management asked you to scale the Pods down to one replica to save resources.o3db-*project-c13
题解
答:
如果我们检查 Pod,我们会看到两个副本:
➜ k -n project-c13 get pod | grep o3db
o3db-0 1/1 Running 0 52s
o3db-1 1/1 Running 0 42s
从它们的名字来看,这些似乎由StatefulSet管理。但是,如果我们不确定,我们还可以检查管理 Pod 的最常见资源:
➜ k -n project-c13 get deploy,ds,sts | grep o3db
statefulset.apps/o3db 2/2 2m56s
确认,我们必须使用StatefulSet。要找出这一点,我们还可以查看 Pod 标签:
➜ k -n project-c13 get pod --show-labels | grep o3db
o3db-0 1/1 Running 0 3m29s app=nginx,controller-revision-hash=o3db-5fbd4bb9cc,statefulset.kubernetes.io/pod-name=o3db-0
o3db-1 1/1 Running 0 3m19s app=nginx,controller-revision-hash=o3db-5fbd4bb9cc,statefulset.kubernetes.io/pod-name=o3db-1
为了完成任务,我们只需运行:
➜ k -n project-c13 scale sts o3db --replicas 1
statefulset.apps/o3db scaled
➜ k -n project-c13 get sts o3db
NAME READY AGE
o3db 1/1 4m39s
题库4
任务权重:4%
使用上下文:kubectl config use-context k8s-c1-H
在命名空间中执行以下操作。创建一个以 image 命名的 Pod 。配置一个只执行命令的活体探针。还要配置一个 准备探测 检查 url 是否可访问,您可以为此使用。启动 Pod 并确认由于准备情况探测而未准备就绪。defaultready-if-service-readynginx:1.16.1-alpinetruehttp://service-am-i-ready:80wget -T2 -O- http://service-am-i-ready:80
创建第二个以带有标签的映像命名的 Pod。现有的服务现在应该将第二个 Pod 作为端点。am-i-readynginx:1.16.1-alpineid: cross-server-readyservice-am-i-ready
现在第一个 Pod 应该处于就绪状态,确认这一点。
Use context: kubectl config use-context k8s-c1-H
Do the following in Namespace . Create a single Pod named of image . Configure a LivenessProbe which simply executes command . Also configure a ReadinessProbe which does check if the url is reachable, you can use for this. Start the Pod and confirm it isn't ready because of the ReadinessProbe.defaultready-if-service-readynginx:1.16.1-alpinetruehttp://service-am-i-ready:80wget -T2 -O- http://service-am-i-ready:80
Create a second Pod named of image with label . The already existing Service should now have that second Pod as endpoint.am-i-readynginx:1.16.1-alpineid: cross-server-readyservice-am-i-ready
Now the first Pod should be in ready state, confirm that.
题解
答:
对于一个 Pod 使用探针检查另一个 Pod 是否准备就绪有点反模式,因此通常可用的对 绝对远程 url 不起作用。尽管如此,此任务中请求的解决方法仍应显示探测器和 Pod<-> 服务通信的工作原理。readinessProbe.httpGet
首先,我们创建第一个 Pod:
k run ready-if-service-ready --image=nginx:1.16.1-alpine $do > 4_pod1.yaml
vim 4_pod1.yaml
# 4_pod1.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: ready-if-service-ready
name: ready-if-service-ready
spec:
containers:
- image: nginx:1.16.1-alpine
name: ready-if-service-ready
resources: {}
livenessProbe: # add from here
exec:
command:
- 'true'
readinessProbe:
exec:
command:
- sh
- -c
- 'wget -T2 -O- http://service-am-i-ready:80' # to here
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
然后创建 Pod
k -f 4_pod1.yaml create
并确认它处于未就绪状态:
➜ k get pod ready-if-service-ready
NAME READY STATUS RESTARTS AGE
ready-if-service-ready 0/1 Running 0 7s
我们还可以使用描述来检查其原因:
➜ k describe pod ready-if-service-ready
...
Warning Unhealthy 18s kubelet, cluster1-node1 Readiness probe failed: Connecting to service-am-i-ready:80 (10.109.194.234:80)
wget: download timed out
现在我们创建第二个 Pod:
k run am-i-ready --image=nginx:1.16.1-alpine --labels="id=cross-server-ready"
现有的服务 现在应该有一个终结点:service-am-i-ready
k describe svc service-am-i-ready
k get ep # also possible
这将导致我们的第一个 Pod 准备就绪,只需给它一分钟时间让就绪探测再次检查:
➜ k get pod ready-if-service-ready
NAME READY STATUS RESTARTS AGE
ready-if-service-ready 1/1 Running 0 53s
看看这些 Pod 一起工作!
题库5
任务权重:1%
使用上下文:kubectl config use-context k8s-c1-H
所有命名空间中都有各种 Pod。编写一个命令,其中列出了按 AGE () 排序的所有 Pod。/opt/course/5/find_pods.shmetadata.creationTimestamp
编写第二个命令,其中列出了按字段排序的所有 Pod。对这两个命令都使用排序。/opt/course/5/find_pods_uid.shmetadata.uidkubectl
Use context: kubectl config use-context k8s-c1-H
There are various Pods in all namespaces. Write a command into which lists all Pods sorted by their AGE ()./opt/course/5/find_pods.shmetadata.creationTimestamp
Write a second command into which lists all Pods sorted by field . Use sorting for both commands./opt/course/5/find_pods_uid.shmetadata.uidkubectl
题解
答:
这里的一个很好的资源(以及许多其他事情)是kubectl-cheat-sheet。在 Kubernetes 文档中搜索“备忘单”时,您可以快速访问它。
# /opt/course/5/find_pods.sh
kubectl get pod -A --sort-by=.metadata.creationTimestamp
并执行:
➜ sh /opt/course/5/find_pods.sh
NAMESPACE NAME ... AGE
kube-system kube-scheduler-cluster1-controlplane1 ... 63m
kube-system etcd-cluster1-controlplane1 ... 63m
kube-system kube-apiserver-cluster1-controlplane1 ... 63m
kube-system kube-controller-manager-cluster1-controlplane1 ... 63m
...
对于第二个命令:
# /opt/course/5/find_pods_uid.sh
kubectl get pod -A --sort-by=.metadata.uid
并执行:
➜ sh /opt/course/5/find_pods_uid.sh
NAMESPACE NAME ... AGE
kube-system coredns-5644d7b6d9-vwm7g ... 68m
project-c13 c13-3cc-runner-heavy-5486d76dd4-ddvlt ... 63m
project-hamster web-hamster-shop-849966f479-278vp ... 63m
project-c13 c13-3cc-web-646b6c8756-qsg4b ... 63m
题库6
任务权重:8%
使用上下文:kubectl config use-context k8s-c1-H
创建一个名为 的新持久卷。它应该具有2Gi的容量,访问模式读写一次,hostPath和未定义存储类名。safari-pv/Volumes/Data
接下来,在命名空间中创建一个名为 的新 PersistentVolumeClaim。它应该请求 2Gi 存储,访问模式 ReadWriteOnce,并且不应该定义 storageClassName。PVC 应正确绑定到 PV。project-tigersafari-pvc
最后,在命名空间中创建一个新的部署,该部署将该卷装载在 。该部署的 Pod 应为映像 。safariproject-tiger/tmp/safari-datahttpd:2.4.41-alpine
Use context: kubectl config use-context k8s-c1-H
Create a new PersistentVolume named . It should have a capacity of 2Gi, accessMode ReadWriteOnce, hostPath and no storageClassName defined.safari-pv/Volumes/Data
Next create a new PersistentVolumeClaim in Namespace named . It should request 2Gi storage, accessMode ReadWriteOnce and should not define a storageClassName. The PVC should bound to the PV correctly.project-tigersafari-pvc
Finally create a new Deployment in Namespace which mounts that volume at . The Pods of that Deployment should be of image .safariproject-tiger/tmp/safari-datahttpd:2.4.41-alpine
题解
答
vim 6_pv.yaml
从 https://kubernetes.io/docs 中找到一个例子 并对其进行更改:
# 6_pv.yaml
kind: PersistentVolume
apiVersion: v1
metadata:
name: safari-pv
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/Volumes/Data"
然后创建它:
k -f 6_pv.yaml create
接下来是 PersistentVolumeClaim:
vim 6_pvc.yaml
从 https://kubernetes.io/docs 中找到一个例子 并对其进行更改:
# 6_pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: safari-pvc
namespace: project-tiger
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
然后创建:
k -f 6_pvc.yaml create
并检查两者的状态是否为“绑定”:
➜ k -n project-tiger get pv,pvc
NAME CAPACITY ... STATUS CLAIM ...
persistentvolume/safari-pv 2Gi ... Bound project-tiger/safari-pvc ...
NAME STATUS VOLUME CAPACITY ...
persistentvolumeclaim/safari-pvc Bound safari-pv 2Gi ...
接下来,我们创建一个部署并挂载该卷:
k -n project-tiger create deploy safari \
--image=httpd:2.4.41-alpine $do > 6_dep.yaml
vim 6_dep.yaml
更改 yaml 以装载卷:
# 6_dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: safari
name: safari
namespace: project-tiger
spec:
replicas: 1
selector:
matchLabels:
app: safari
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: safari
spec:
volumes: # add
- name: data # add
persistentVolumeClaim: # add
claimName: safari-pvc # add
containers:
- image: httpd:2.4.41-alpine
name: container
volumeMounts: # add
- name: data # add
mountPath: /tmp/safari-data # add
k -f 6_dep.yaml create
我们可以确认它是否正确安装:
➜ k -n project-tiger describe pod safari-5cbf46d6d-mjhsb | grep -A2 Mounts:
Mounts:
/tmp/safari-data from data (rw) # there it is
/var/run/secrets/kubernetes.io/serviceaccount from default-token-n2sjj (ro)
题库7
Use context: kubectl config use-context k8s-c1-H
The metrics-server has been installed in the cluster. Your college would like to know the kubectl commands to:
show Nodes resource usage
show Pods and their containers resource usage
Please write the commands into and ./opt/course/7/node.sh/opt/course/7/pod.sh
任务权重:1%
使用上下文:kubectl config use-context k8s-c1-H
指标服务器已安装在群集中。您的大学想知道 kubectl 命令:
显示节点资源使用情况
显示 Pod 及其容器的资源使用情况
请将命令写入 和 。/opt/course/7/node.sh/opt/course/7/pod.sh
题解
答:
我们在这里需要使用的命令是 top:
➜ k top -h
Display Resource (CPU/Memory/Storage) usage.
The top command allows you to see the resource consumption for nodes or pods.
This command requires Metrics Server to be correctly configured and working on the server.
Available Commands:
node Display Resource (CPU/Memory/Storage) usage of nodes
pod Display Resource (CPU/Memory/Storage) usage of pods
我们看到指标服务器提供有关资源使用情况的信息:
➜ k top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cluster1-controlplane1 178m 8% 1091Mi 57%
cluster1-node1 66m 6% 834Mi 44%
cluster1-node2 91m 9% 791Mi 41%
我们创建第一个文件:
# /opt/course/7/node.sh
kubectl top node
对于第二个文件,我们可能需要再次检查文档:
➜ k top pod -h
Display Resource (CPU/Memory/Storage) usage of pods.
...
Namespace in current context is ignored even if specified with --namespace.
--containers=false: If present, print usage of containers within a pod.
--no-headers=false: If present, print output without headers.
...
有了这个,我们可以完成这个任务:
# /opt/course/7/pod.sh
kubectl top pod --containers=true
题库8
Use context: kubectl config use-context k8s-c1-H
Ssh into the controlplane node with . Check how the controlplane components kubelet, kube-apiserver, kube-scheduler, kube-controller-manager and etcd are started/installed on the controlplane node. Also find out the name of the DNS application and how it's started/installed on the controlplane node.ssh cluster1-controlplane1
Write your findings into file . The file should be structured like:/opt/course/8/controlplane-components.txt
任务权重:2%
使用上下文:kubectl config use-context k8s-c1-H
使用 Ssh 进入控制平面节点。检查控制平面组件 kubelet、kube-apiserver、kube-scheduler、kube-controller-manager 和 etcd 是如何在控制平面节点上启动/安装的。还要了解 DNS 应用程序的名称以及它在控制平面节点上的启动/安装方式。ssh cluster1-controlplane1
将您的发现写入文件 。该文件的结构应如下所示:/opt/course/8/controlplane-components.txt
# /opt/course/8/controlplane-components.txt
kubelet: [TYPE]
kube-apiserver: [TYPE]
kube-scheduler: [TYPE]
kube-controller-manager: [TYPE]
etcd: [TYPE]
dns: [TYPE] [NAME]
选项包括:、、、[TYPE]not-installedprocessstatic-podpod
题解
答:
我们可以从查找所请求组件的进程开始,尤其是一开始的 kubelet:
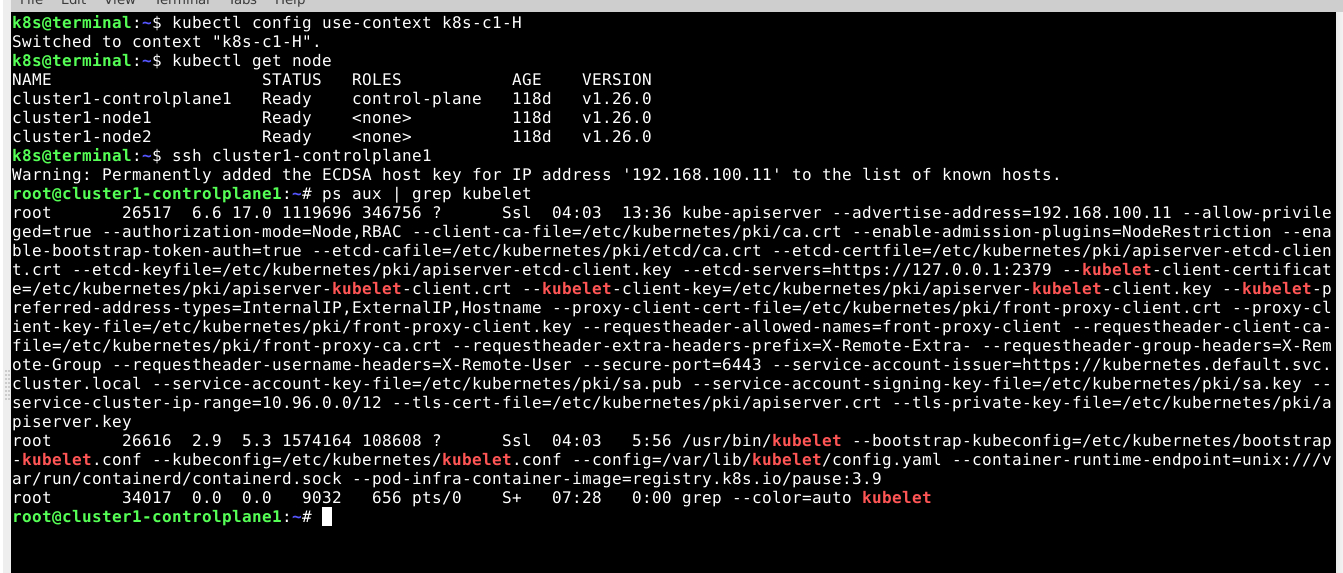
➜ ssh cluster1-controlplane1
root@cluster1-controlplane1:~# ps aux | grep kubelet # shows kubelet process
我们可以看到哪些组件是通过 systemd 控制的,查看 目录:/etc/systemd/system
➜ root@cluster1-controlplane1:~# find /etc/systemd/system/ | grep kube
/etc/systemd/system/kubelet.service.d
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
/etc/systemd/system/multi-user.target.wants/kubelet.service
➜ root@cluster1-controlplane1:~# find /etc/systemd/system/ | grep etcd
这表明 kubelet 是通过 systemd 控制的,但没有其他名为 kube 和 etcd 的服务。似乎这个集群是使用 kubeadm 设置的,所以我们检查默认的清单目录:
➜ root@cluster1-controlplane1:~# find /etc/kubernetes/manifests/
/etc/kubernetes/manifests/
/etc/kubernetes/manifests/kube-controller-manager.yaml
/etc/kubernetes/manifests/etcd.yaml
/etc/kubernetes/manifests/kube-apiserver.yaml
/etc/kubernetes/manifests/kube-scheduler.yaml
(kubelet 也可以有一个不同的清单目录,通过 它的 systemd 启动配置中的参数指定)--pod-manifest-path
这意味着主要的 4 个控制平面服务被设置为静态 Pod。实际上,让我们检查在 控制平面节点上的命名空间中 运行的所有 Pod:kube-system
➜ root@cluster1-controlplane1:~# kubectl -n kube-system get pod -o wide | grep controlplane1
coredns-5644d7b6d9-c4f68 1/1 Running ... cluster1-controlplane1
coredns-5644d7b6d9-t84sc 1/1 Running ... cluster1-controlplane1
etcd-cluster1-controlplane1 1/1 Running ... cluster1-controlplane1
kube-apiserver-cluster1-controlplane1 1/1 Running ... cluster1-controlplane1
kube-controller-manager-cluster1-controlplane1 1/1 Running ... cluster1-controlplane1
kube-proxy-q955p 1/1 Running ... cluster1-controlplane1
kube-scheduler-cluster1-controlplane1 1/1 Running ... cluster1-controlplane1
weave-net-mwj47 2/2 Running ... cluster1-controlplane1
在那里,我们看到 5 个静态 pod,带有 as 后缀。-cluster1-controlplane1
我们还看到 dns 应用程序似乎是 coredns,但它是如何控制的?
➜ root@cluster1-controlplane1$ kubectl -n kube-system get ds
NAME DESIRED CURRENT ... NODE SELECTOR AGE
kube-proxy 3 3 ... kubernetes.io/os=linux 155m
weave-net 3 3 ... <none> 155m
➜ root@cluster1-controlplane1$ kubectl -n kube-system get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
coredns 2/2 2 2 155m
似乎 coredns 是通过部署控制的。我们将我们的发现合并到请求的文件中:
# /opt/course/8/controlplane-components.txt
kubelet: process
kube-apiserver: static-pod
kube-scheduler: static-pod
kube-controller-manager: static-pod
etcd: static-pod
dns: pod coredns
您应该能够轻松调查正在运行的集群,了解如何设置集群及其服务的不同方法,并能够进行故障排除和查找错误源。
题库9
Use context: kubectl config use-context k8s-c2-AC
Ssh into the controlplane node with ssh cluster2-controlplane1. Temporarily stop the kube-scheduler, this means in a way that you can start it again afterwards.
Create a single Pod named manual-schedule of image httpd:2.4-alpine, confirm it's created but not scheduled on any node.
Now you're the scheduler and have all its power, manually schedule that Pod on node cluster2-controlplane1. Make sure it's running.
Start the kube-scheduler again and confirm it's running correctly by creating a second Pod named manual-schedule2 of image httpd:2.4-alpine and check if it's running on cluster2-node1.
任务权重:5%
使用上下文:kubectl config use-context k8s-c2-AC
使用 Ssh 进入控制平面节点。暂时停止 kube-scheduler,这意味着您可以在之后再次启动它。ssh cluster2-controlplane1
创建一个以 image 命名的 Pod,确认它已创建但未在任何节点上调度。manual-schedulehttpd:2.4-alpine
现在你是调度程序并拥有它的所有功能,在节点集群 2-controlplane1 上手动调度该 Pod。确保它正在运行。
再次启动 kube-scheduler,并通过创建第二个名为 image 的 Pod 来确认它是否正常运行,并检查它是否在 cluster2-node1 上运行。manual-schedule2httpd:2.4-alpine
题解
答:
停止调度程序
首先,我们找到控制平面节点:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster2-controlplane1 Ready control-plane 26h v1.26.0
cluster2-node1 Ready <none> 26h v1.26.0
然后我们连接并检查调度程序是否正在运行:
➜ ssh cluster2-controlplane1
➜ root@cluster2-controlplane1:~# kubectl -n kube-system get pod | grep schedule
kube-scheduler-cluster2-controlplane1 1/1 Running 0 6s
终止调度程序(暂时):
➜ root@cluster2-controlplane1:~# cd /etc/kubernetes/manifests/
➜ root@cluster2-controlplane1:~# mv kube-scheduler.yaml ..
并且应该停止:
➜ root@cluster2-controlplane1:~# kubectl -n kube-system get pod | grep schedule
➜ root@cluster2-controlplane1:~#
创建容器
现在我们创建 Pod:
k run manual-schedule --image=httpd:2.4-alpine
并确认它没有分配节点:
➜ k get pod manual-schedule -o wide
NAME READY STATUS ... NODE NOMINATED NODE
manual-schedule 0/1 Pending ... <none> <none>
手动调度 Pod
现在让我们玩调度程序:
k get pod manual-schedule -o yaml > 9.yaml
# 9.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-09-04T15:51:02Z"
labels:
run: manual-schedule
managedFields:
...
manager: kubectl-run
operation: Update
time: "2020-09-04T15:51:02Z"
name: manual-schedule
namespace: default
resourceVersion: "3515"
selfLink: /api/v1/namespaces/default/pods/manual-schedule
uid: 8e9d2532-4779-4e63-b5af-feb82c74a935
spec:
nodeName: cluster2-controlplane1 # add the controlplane node name
containers:
- image: httpd:2.4-alpine
imagePullPolicy: IfNotPresent
name: manual-schedule
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-nxnc7
readOnly: true
dnsPolicy: ClusterFirst
...
调度器唯一要做的就是为 Pod 声明设置 nodeName 。它如何找到正确的节点进行调度,这是一个非常复杂的问题,需要考虑许多变量。
由于我们不能 或 ,在这种情况下,我们需要删除并创建或替换:kubectl apply``kubectl edit
k -f 9.yaml replace --force
它看起来如何?
➜ k get pod manual-schedule -o wide
NAME READY STATUS ... NODE
manual-schedule 1/1 Running ... cluster2-controlplane1
看起来我们的 Pod 现在正在按照要求在控制平面上运行,尽管没有指定容忍度。只有调度程序在查找正确的节点名称时会考虑 tains/toleranceations/affinity。这就是为什么仍然可以手动将 Pod 直接分配给控制平面节点并跳过调度程序的原因。
再次启动调度程序
➜ ssh cluster2-controlplane1
➜ root@cluster2-controlplane1:~# cd /etc/kubernetes/manifests/
➜ root@cluster2-controlplane1:~# mv ../kube-scheduler.yaml .
检查它是否正在运行:
➜ root@cluster2-controlplane1:~# kubectl -n kube-system get pod | grep schedule
kube-scheduler-cluster2-controlplane1 1/1 Running 0 16s
安排第二个测试 Pod:
k run manual-schedule2 --image=httpd:2.4-alpine
➜ k get pod -o wide | grep schedule
manual-schedule 1/1 Running ... cluster2-controlplane1
manual-schedule2 1/1 Running ... cluster2-node1
恢复正常。
题库10
Use context: kubectl config use-context k8s-c1-H
Create a new ServiceAccount processor in Namespace project-hamster. Create a Role and RoleBinding, both named processor as well. These should allow the new SA to only create Secrets and ConfigMaps in that Namespace.
任务权重:6%
使用上下文:kubectl config use-context k8s-c1-H
在命名空间中创建新的服务帐户。创建角色和角色绑定,两者都已命名。这些应该允许新的 SA 仅在该命名空间中创建机密和配置映射。processorproject-hamsterprocessor
题解
答:
让我们谈谈 RBAC 资源
集群角色|角色定义一组权限,以及该权限可用的地方,在整个群集中或仅单个命名空间中。
集群角色绑定|RoleBinding 将一组权限与帐户连接起来,并定义在整个群集或单个命名空间中的应用位置。
因此,有 4 种不同的 RBAC 组合和 3 种有效的组合:
- 角色 + 角色绑定(在单个命名空间中可用,在单个命名空间中应用))
- ClusterRole + ClusterRoleBinding(在群集范围内可用,在群集范围内应用)
- 群集角色 + 角色绑定(在群集范围内可用,在单个命名空间中应用))
- 角色 + 群集角色绑定(**不可能:**在单个命名空间中可用,在群集范围内应用)
跳转至解决方案
我们首先创建服务帐户:
➜ k -n project-hamster create sa processor
serviceaccount/processor created
然后对于角色:
k -n project-hamster create role -h # examples
所以我们执行:
k -n project-hamster create role processor \
--verb=create \
--resource=secret \
--resource=configmap
这将创建一个角色,例如:
# kubectl -n project-hamster create role processor --verb=create --resource=secret --resource=configmap
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: processor
namespace: project-hamster
rules:
- apiGroups:
- ""
resources:
- secrets
- configmaps
verbs:
- create
现在,我们将角色绑定到服务帐户:
k -n project-hamster create rolebinding -h # examples
所以我们创建它:
k -n project-hamster create rolebinding processor \
--role processor \
--serviceaccount project-hamster:processor
这将创建一个角色绑定,如下所示:
# kubectl -n project-hamster create rolebinding processor --role processor --serviceaccount project-hamster:processor
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: processor
namespace: project-hamster
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: processor
subjects:
- kind: ServiceAccount
name: processor
namespace: project-hamster
要测试我们的 RBAC 设置,我们可以使用:kubectl auth can-i
k auth can-i -h # examples
喜欢这个:
➜ k -n project-hamster auth can-i create secret \
--as system:serviceaccount:project-hamster:processor
yes
➜ k -n project-hamster auth can-i create configmap \
--as system:serviceaccount:project-hamster:processor
yes
➜ k -n project-hamster auth can-i create pod \
--as system:serviceaccount:project-hamster:processor
no
➜ k -n project-hamster auth can-i delete secret \
--as system:serviceaccount:project-hamster:processor
no
➜ k -n project-hamster auth can-i get configmap \
--as system:serviceaccount:project-hamster:processor
no
做。
题库11
Use context: kubectl config use-context k8s-c1-H
Use Namespace project-tiger for the following. Create a DaemonSet named ds-important with image httpd:2.4-alpine and labels id=ds-important and uuid=18426a0b-5f59-4e10-923f-c0e078e82462. The Pods it creates should request 10 millicore cpu and 10 mebibyte memory. The Pods of that DaemonSet should run on all nodes, also controlplanes.
任务权重:4%
使用上下文:kubectl config use-context k8s-c1-H
将命名空间用于以下内容。创建一个以图像和标签命名的守护程序集,以及 .它创建的 Pod 应该请求 10 毫核 CPU 和 10 兆字节内存。该守护程序集的 Pod 应该在所有节点上运行,也应该在控制平面上运行。project-tigerds-importanthttpd:2.4-alpineid=ds-importantuuid=18426a0b-5f59-4e10-923f-c0e078e82462
题解
答:
到目前为止,我们无法 直接使用 创建守护程序集,因此我们创建一个部署并对其进行更改:kubectl
k -n project-tiger create deployment --image=httpd:2.4-alpine ds-important $do > 11.yaml
vim 11.yaml
(当然,你也可以在 Kubernetes 文档中搜索 DaemonSet 示例 yaml 并对其进行更改。
然后我们将 yaml 调整为:
# 11.yaml
apiVersion: apps/v1
kind: DaemonSet # change from Deployment to Daemonset
metadata:
creationTimestamp: null
labels: # add
id: ds-important # add
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462 # add
name: ds-important
namespace: project-tiger # important
spec:
#replicas: 1 # remove
selector:
matchLabels:
id: ds-important # add
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462 # add
#strategy: {} # remove
template:
metadata:
creationTimestamp: null
labels:
id: ds-important # add
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462 # add
spec:
containers:
- image: httpd:2.4-alpine
name: ds-important
resources:
requests: # add
cpu: 10m # add
memory: 10Mi # add
tolerations: # add
- effect: NoSchedule # add
key: node-role.kubernetes.io/control-plane # add
#status: {} # remove
请求守护程序集在所有节点上运行,因此我们需要为此指定容忍度。
让我们确认一下:
k -f 11.yaml create
➜ k -n project-tiger get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
ds-important 3 3 3 3 3 <none> 8s
➜ k -n project-tiger get pod -l id=ds-important -o wide
NAME READY STATUS NODE
ds-important-6pvgm 1/1 Running ... cluster1-node1
ds-important-lh5ts 1/1 Running ... cluster1-controlplane1
ds-important-qhjcq 1/1 Running ... cluster1-node2
题库12
Use context: kubectl config use-context k8s-c1-H
Use Namespace project-tiger for the following. Create a Deployment named deploy-important with label id=very-important (the Pods should also have this label) and 3 replicas. It should contain two containers, the first named container1 with image nginx:1.17.6-alpine and the second one named container2 with image kubernetes/pause.
There should be only ever one Pod of that Deployment running on one worker node. We have two worker nodes: cluster1-node1 and cluster1-node2. Because the Deployment has three replicas the result should be that on both nodes one Pod is running. The third Pod won't be scheduled, unless a new worker node will be added.
In a way we kind of simulate the behaviour of a DaemonSet here, but using a Deployment and a fixed number of replicas.
任务权重:6%
使用上下文:kubectl config use-context k8s-c1-H
将命名空间用于以下内容。创建一个以标签命名的部署(也应具有此标签)和 3 个副本。它应该包含两个容器,第一个名为 container1 带有图像,第二个名为 container2 带有图像。project-tigerdeploy-importantid=very-importantPodsnginx:1.17.6-alpinekubernetes/pause
在一个工作节点上应该只有一个该部署的 Pod 运行。我们有两个工作节点:cluster1-node1 和cluster1-node2。因为部署有三个副本,所以结果应该是在两个节点上都有一个 Pod 正在运行。第三个 Pod 不会被调度,除非添加新的工作节点。
在某种程度上,我们在这里模拟了守护程序集的行为,但使用部署和固定数量的副本。
题解
答:
有两种可能的方法,一种使用,一种 使用 .podAntiAffinity``topologySpreadConstraint
豆荚反亲和力
这里的想法是,我们创建了一个“Pod 间反亲和力”,它允许我们说一个 Pod 应该只调度在一个节点上,其中另一个特定标签的 Pod (这里是相同的标签)尚未运行。
让我们从创建部署模板开始:
k -n project-tiger create deployment \
--image=nginx:1.17.6-alpine deploy-important $do > 12.yaml
vim 12.yaml
然后将 yaml 更改为:
# 12.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
id: very-important # change
name: deploy-important
namespace: project-tiger # important
spec:
replicas: 3 # change
selector:
matchLabels:
id: very-important # change
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
id: very-important # change
spec:
containers:
- image: nginx:1.17.6-alpine
name: container1 # change
resources: {}
- image: kubernetes/pause # add
name: container2 # add
affinity: # add
podAntiAffinity: # add
requiredDuringSchedulingIgnoredDuringExecution: # add
- labelSelector: # add
matchExpressions: # add
- key: id # add
operator: In # add
values: # add
- very-important # add
topologyKey: kubernetes.io/hostname # add
status: {}
指定一个拓扑键,这是一个预填充的 Kubernetes 标签,你可以通过描述一个节点来找到它。
拓扑扩展约束
我们可以用. 最好尝试并同时玩两者。topologySpreadConstraints
# 12.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
id: very-important # change
name: deploy-important
namespace: project-tiger # important
spec:
replicas: 3 # change
selector:
matchLabels:
id: very-important # change
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
id: very-important # change
spec:
containers:
- image: nginx:1.17.6-alpine
name: container1 # change
resources: {}
- image: kubernetes/pause # add
name: container2 # add
topologySpreadConstraints: # add
- maxSkew: 1 # add
topologyKey: kubernetes.io/hostname # add
whenUnsatisfiable: DoNotSchedule # add
labelSelector: # add
matchLabels: # add
id: very-important # add
status: {}
应用并运行
让我们运行它:
k -f 12.yaml create
然后我们检查部署状态,其中显示 2/3 就绪计数:
➜ k -n project-tiger get deploy -l id=very-important
NAME READY UP-TO-DATE AVAILABLE AGE
deploy-important 2/3 3 2 2m35s
运行以下命令,我们看到每个工作节点上都有一个 Pod,一个未调度。
➜ k -n project-tiger get pod -o wide -l id=very-important
NAME READY STATUS ... NODE
deploy-important-58db9db6fc-9ljpw 2/2 Running ... cluster1-node1
deploy-important-58db9db6fc-lnxdb 0/2 Pending ... <none>
deploy-important-58db9db6fc-p2rz8 2/2 Running ... cluster1-node2
如果我们 kubectl 描述 Pod,它将向我们展示不调度的原因是我们实现的 podAntiAffinity 规则:deploy-important-58db9db6fc-lnxdb
Warning FailedScheduling 63s (x3 over 65s) default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/control-plane: }, that the pod didn't tolerate, 2 node(s) didn't match pod affinity/anti-affinity, 2 node(s) didn't satisfy existing pods anti-affinity rules.
或者我们的拓扑扩展约束:
Warning FailedScheduling 16s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/control-plane: }, that the pod didn't tolerate, 2 node(s) didn't match pod topology spread constraints.
题库13
Use context: kubectl config use-context k8s-c1-H
Create a Pod named multi-container-playground in Namespace default with three containers, named c1, c2 and c3. There should be a volume attached to that Pod and mounted into every container, but the volume shouldn't be persisted or shared with other Pods.
Container c1 should be of image nginx:1.17.6-alpine and have the name of the node where its Pod is running available as environment variable MY_NODE_NAME.
Container c2 should be of image busybox:1.31.1 and write the output of the date command every second in the shared volume into file date.log. You can use while true; do date >> /your/vol/path/date.log; sleep 1; done for this.
Container c3 should be of image busybox:1.31.1 and constantly send the content of file date.log from the shared volume to stdout. You can use tail -f /your/vol/path/date.log for this.
Check the logs of container c3 to confirm correct setup.
任务权重:4%
使用上下文:kubectl config use-context k8s-c1-H
创建一个在命名空间中命名的 Pod,其中包含三个容器,分别名为 和 。应该有一个卷附加到该 Pod 并挂载到每个容器中,但该卷不应持久化或与其他 Pod 共享。multi-container-playgrounddefaultc1c2c3
容器应该是镜像的,并且具有运行其 Pod 的节点的名称,可用作环境变量MY_NODE_NAME。c1nginx:1.17.6-alpine
容器应该是映像的,并且每秒将共享卷中命令的输出写入文件。你可以为此使用。c2busybox:1.31.1datedate.logwhile true; do date >> /your/vol/path/date.log; sleep 1; done
容器应该是图像的,并不断将文件的内容从共享卷发送到标准输出。你可以为此使用。c3busybox:1.31.1date.logtail -f /your/vol/path/date.log
检查容器的日志以确认设置正确。c3
题解
答:
首先,我们创建 Pod 模板:
k run multi-container-playground --image=nginx:1.17.6-alpine $do > 13.yaml
vim 13.yaml
并添加其他容器和它们应执行的命令:
# 13.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: multi-container-playground
name: multi-container-playground
spec:
containers:
- image: nginx:1.17.6-alpine
name: c1 # change
resources: {}
env: # add
- name: MY_NODE_NAME # add
valueFrom: # add
fieldRef: # add
fieldPath: spec.nodeName # add
volumeMounts: # add
- name: vol # add
mountPath: /vol # add
- image: busybox:1.31.1 # add
name: c2 # add
command: ["sh", "-c", "while true; do date >> /vol/date.log; sleep 1; done"] # add
volumeMounts: # add
- name: vol # add
mountPath: /vol # add
- image: busybox:1.31.1 # add
name: c3 # add
command: ["sh", "-c", "tail -f /vol/date.log"] # add
volumeMounts: # add
- name: vol # add
mountPath: /vol # add
dnsPolicy: ClusterFirst
restartPolicy: Always
volumes: # add
- name: vol # add
emptyDir: {} # add
status: {}
k -f 13.yaml create
哦,天哪,很多要求的东西。我们检查 Pod 是否一切正常:
➜ k get pod multi-container-playground
NAME READY STATUS RESTARTS AGE
multi-container-playground 3/3 Running 0 95s
很好,然后我们检查容器 c1 是否将请求的节点名称作为 env 变量:
➜ k exec multi-container-playground -c c1 -- env | grep MY
MY_NODE_NAME=cluster1-node2
最后我们检查日志记录:
➜ k logs multi-container-playground -c c3
Sat Dec 7 16:05:10 UTC 2077
Sat Dec 7 16:05:11 UTC 2077
Sat Dec 7 16:05:12 UTC 2077
Sat Dec 7 16:05:13 UTC 2077
Sat Dec 7 16:05:14 UTC 2077
Sat Dec 7 16:05:15 UTC 2077
Sat Dec 7 16:05:16 UTC 2077
题库14
Use context: kubectl config use-context k8s-c1-H
You're ask to find out following information about the cluster k8s-c1-H:
How many controlplane nodes are available?
How many worker nodes are available?
What is the Service CIDR?
Which Networking (or CNI Plugin) is configured and where is its config file?
Which suffix will static pods have that run on cluster1-node1?
Write your answers into file /opt/course/14/cluster-info, structured like this:
任务权重:2%
使用上下文:kubectl config use-context k8s-c1-H
系统会要求您了解有关群集的以下信息:k8s-c1-H
有多少个控制平面节点可用?
有多少个工作器节点可用?
什么是服务网段?
配置了哪个网络(或CNI插件),其配置文件在哪里?
静态 Pod 将具有哪个后缀在 cluster1-node1 上运行?
将您的答案写入文件,结构如下:/opt/course/14/cluster-info
# /opt/course/14/cluster-info
1: [ANSWER]
2: [ANSWER]
3: [ANSWER]
4: [ANSWER]
5: [ANSWER]
题解
答:
有多少个控制平面和工作器节点可用?
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster1-controlplane1 Ready control-plane 27h v1.26.0
cluster1-node1 Ready <none> 27h v1.26.0
cluster1-node2 Ready <none> 27h v1.26.0
我们看到一个控制平面和两个工作线程。
什么是服务网段?
➜ ssh cluster1-controlplane1
➜ root@cluster1-controlplane1:~# cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep range
- --service-cluster-ip-range=10.96.0.0/12
配置了哪个网络(或CNI插件),其配置文件在哪里?
➜ root@cluster1-controlplane1:~# find /etc/cni/net.d/
/etc/cni/net.d/
/etc/cni/net.d/10-weave.conflist
➜ root@cluster1-controlplane1:~# cat /etc/cni/net.d/10-weave.conflist
{
"cniVersion": "0.3.0",
"name": "weave",
...
默认情况下,kubelet 会查看 以发现 CNI 插件。这在每个控制平面和工作器节点上都是相同的。/etc/cni/net.d
静态 Pod 将具有哪个后缀在 cluster1-node1 上运行?
后缀是带有前导连字符的节点主机名。它曾经在 早期的 Kubernetes 版本中。-static
结果
结果 可能如下所示:/opt/course/14/cluster-info
# /opt/course/14/cluster-info
# How many controlplane nodes are available?
1: 1
# How many worker nodes are available?
2: 2
# What is the Service CIDR?
3: 10.96.0.0/12
# Which Networking (or CNI Plugin) is configured and where is its config file?
4: Weave, /etc/cni/net.d/10-weave.conflist
# Which suffix will static pods have that run on cluster1-node1?
5: -cluster1-node1
题库15
Use context: kubectl config use-context k8s-c2-AC
Write a command into /opt/course/15/cluster_events.sh which shows the latest events in the whole cluster, ordered by time (metadata.creationTimestamp). Use kubectl for it.
Now kill the kube-proxy Pod running on node cluster2-node1 and write the events this caused into /opt/course/15/pod_kill.log.
Finally kill the containerd container of the kube-proxy Pod on node cluster2-node1 and write the events into /opt/course/15/container_kill.log.
Do you notice differences in the events both actions caused?
任务权重:3%
使用上下文:kubectl config use-context k8s-c2-AC
编写一个命令,在其中显示整个群集中的最新事件,按时间排序 ()。用于它。/opt/course/15/cluster_events.shmetadata.creationTimestampkubectl
现在杀死在节点集群 2-node1 上运行的 kube-proxy Pod,并将由此引起的事件写入 ./opt/course/15/pod_kill.log
最后在节点集群 2-node1 上杀死 kube-proxy Pod 的容器,并将事件写入 ./opt/course/15/container_kill.log
您是否注意到两种行为引起的事件存在差异?
题解
答:
# /opt/course/15/cluster_events.sh
kubectl get events -A --sort-by=.metadata.creationTimestamp
现在我们杀死 kube-proxy Pod:
k -n kube-system get pod -o wide | grep proxy # find pod running on cluster2-node1
k -n kube-system delete pod kube-proxy-z64cg
现在检查事件:
sh /opt/course/15/cluster_events.sh
将杀戮造成的事件写成:/opt/course/15/pod_kill.log
# /opt/course/15/pod_kill.log
kube-system 9s Normal Killing pod/kube-proxy-jsv7t ...
kube-system 3s Normal SuccessfulCreate daemonset/kube-proxy ...
kube-system <unknown> Normal Scheduled pod/kube-proxy-m52sx ...
default 2s Normal Starting node/cluster2-node1 ...
kube-system 2s Normal Created pod/kube-proxy-m52sx ...
kube-system 2s Normal Pulled pod/kube-proxy-m52sx ...
kube-system 2s Normal Started pod/kube-proxy-m52sx ...
最后,我们将尝试通过杀死属于 kube-proxy Pod 容器的容器来引发事件:
➜ ssh cluster2-node1
➜ root@cluster2-node1:~# crictl ps | grep kube-proxy
1e020b43c4423 36c4ebbc9d979 About an hour ago Running kube-proxy ...
➜ root@cluster2-node1:~# crictl rm 1e020b43c4423
1e020b43c4423
➜ root@cluster2-node1:~# crictl ps | grep kube-proxy
0ae4245707910 36c4ebbc9d979 17 seconds ago Running kube-proxy ...
我们杀死了主容器(1e020b43c4423),但也注意到直接创建了一个新容器(0ae4245707910)。谢谢 Kubernetes!
现在我们看看这是否再次导致事件,并将其写入第二个文件:
sh /opt/course/15/cluster_events.sh
# /opt/course/15/container_kill.log
kube-system 13s Normal Created pod/kube-proxy-m52sx ...
kube-system 13s Normal Pulled pod/kube-proxy-m52sx ...
kube-system 13s Normal Started pod/kube-proxy-m52sx ...
比较事件,我们看到当我们删除整个 Pod 时,有更多的事情要做,因此有更多的事件。例如,游戏中的守护程序集用于重新创建丢失的 Pod。当我们手动杀死 Pod 的主容器时,Pod 仍然存在,但只需要重新创建它的容器,因此事件更少。
题库16
Use context: kubectl config use-context k8s-c1-H
Write the names of all namespaced Kubernetes resources (like Pod, Secret, ConfigMap...) into /opt/course/16/resources.txt.
Find the project-* Namespace with the highest number of Roles defined in it and write its name and amount of Roles into /opt/course/16/crowded-namespace.txt.
任务权重:2%
使用上下文:kubectl config use-context k8s-c1-H
将所有命名空间的 Kubernetes 资源(如 Pod、Secret、ConfigMap...)的名称写入 ./opt/course/16/resources.txt
找到其中定义的命名空间数量最多,并将其名称和角色数量写入 。project-*Roles/opt/course/16/crowded-namespace.txt
题解
答:
命名空间和命名空间资源
现在我们可以得到所有资源的列表,例如:
k api-resources # shows all
k api-resources -h # help always good
k api-resources --namespaced -o name > /opt/course/16/resources.txt
这将导致文件:
# /opt/course/16/resources.txt
bindings
configmaps
endpoints
events
limitranges
persistentvolumeclaims
pods
podtemplates
replicationcontrollers
resourcequotas
secrets
serviceaccounts
services
controllerrevisions.apps
daemonsets.apps
deployments.apps
replicasets.apps
statefulsets.apps
localsubjectaccessreviews.authorization.k8s.io
horizontalpodautoscalers.autoscaling
cronjobs.batch
jobs.batch
leases.coordination.k8s.io
events.events.k8s.io
ingresses.extensions
ingresses.networking.k8s.io
networkpolicies.networking.k8s.io
poddisruptionbudgets.policy
rolebindings.rbac.authorization.k8s.io
roles.rbac.authorization.k8s.io
具有大多数角色的命名空间
➜ k -n project-c13 get role --no-headers | wc -l
No resources found in project-c13 namespace.
0
➜ k -n project-c14 get role --no-headers | wc -l
300
➜ k -n project-hamster get role --no-headers | wc -l
No resources found in project-hamster namespace.
0
➜ k -n project-snake get role --no-headers | wc -l
No resources found in project-snake namespace.
0
➜ k -n project-tiger get role --no-headers | wc -l
No resources found in project-tiger namespace.
0
最后,我们将名称和金额写入文件:
# /opt/course/16/crowded-namespace.txt
project-c14 with 300 resources
题库17
Use context: kubectl config use-context k8s-c1-H
In Namespace project-tiger create a Pod named tigers-reunite of image httpd:2.4.41-alpine with labels pod=container and container=pod. Find out on which node the Pod is scheduled. Ssh into that node and find the containerd container belonging to that Pod.
Using command crictl:
Write the ID of the container and the info.runtimeType into /opt/course/17/pod-container.txt
Write the logs of the container into /opt/course/17/pod-container.log
任务权重:3%
使用上下文:kubectl config use-context k8s-c1-H
在命名空间中,创建一个以图像命名的 Pod,并带有标签和 .找出 Pod 调度在哪个节点上。Ssh 进入该节点并找到属于该 Pod 的容器。project-tigertigers-reunitehttpd:2.4.41-alpinepod=containercontainer=pod
使用命令 :crictl
将容器的 ID 写入info.runtimeType/opt/course/17/pod-container.txt
将容器的日志写入/opt/course/17/pod-container.log
题解
答:
首先,我们创建 Pod:
k -n project-tiger run tigers-reunite \
--image=httpd:2.4.41-alpine \
--labels "pod=container,container=pod"
接下来,我们找出它被调度的节点:
k -n project-tiger get pod -o wide
# or fancy:
k -n project-tiger get pod tigers-reunite -o jsonpath="{.spec.nodeName}"
然后我们 ssh 到该节点并检查容器信息:
➜ ssh cluster1-node2
➜ root@cluster1-node2:~# crictl ps | grep tigers-reunite
b01edbe6f89ed 54b0995a63052 5 seconds ago Running tigers-reunite ...
➜ root@cluster1-node2:~# crictl inspect b01edbe6f89ed | grep runtimeType
"runtimeType": "io.containerd.runc.v2",
然后我们填写请求的文件(在主终端上):
# /opt/course/17/pod-container.txt
b01edbe6f89ed io.containerd.runc.v2
最后,我们将容器日志写入第二个文件中:
ssh cluster1-node2 'crictl logs b01edbe6f89ed' &> /opt/course/17/pod-container.log
上面的 in 命令重定向标准输出和标准错误。&>
您也可以简单地在 节点上运行并手动复制内容,如果不是很多。该文件应如下所示:crictl logs
# /opt/course/17/pod-container.log
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.44.0.37. Set the 'ServerName' directive globally to suppress this message
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.44.0.37. Set the 'ServerName' directive globally to suppress this message
[Mon Sep 13 13:32:18.555280 2021] [mpm_event:notice] [pid 1:tid 139929534545224] AH00489: Apache/2.4.41 (Unix) configured -- resuming normal operations
[Mon Sep 13 13:32:18.555610 2021] [core:notice] [pid 1:tid 139929534545224] AH00094: Command line: 'httpd -D FOREGROUND'
题库18
Use context: kubectl config use-context k8s-c3-CCC
There seems to be an issue with the kubelet not running on cluster3-node1. Fix it and confirm that cluster has node cluster3-node1 available in Ready state afterwards. You should be able to schedule a Pod on cluster3-node1 afterwards.
Write the reason of the issue into /opt/course/18/reason.txt.
任务权重:8%
使用上下文:kubectl config use-context k8s-c3-CCC
似乎有一个问题 kubelet 无法运行.修复此问题,并在之后确认群集的节点处于“就绪”状态。之后你应该能够安排一个 Pod。cluster3-node1cluster3-node1cluster3-node1
将问题的原因写到 中。/opt/course/18/reason.txt
题解
答:
此类任务的过程应该是检查 kubelet 是否正在运行,如果没有启动它,则检查其日志并纠正错误(如果有)。
检查其他集群是否已经定义并运行了一些组件总是有帮助的,因此您可以复制和使用现有的配置文件。尽管在这种情况下可能不需要。
检查节点状态:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-controlplane1 Ready control-plane 14d v1.26.0
cluster3-node1 NotReady <none> 14d v1.26.0
首先,我们检查 kubelet 是否正在运行:
➜ ssh cluster3-node1
➜ root@cluster3-node1:~# ps aux | grep kubelet
root 29294 0.0 0.2 14856 1016 pts/0 S+ 11:30 0:00 grep --color=auto kubelet
不,所以我们检查它是否使用 systemd 作为服务进行配置:
➜ root@cluster3-node1:~# service kubelet status
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: inactive (dead) since Sun 2019-12-08 11:30:06 UTC; 50min 52s ago
...
是的,它配置为 config at 的服务,但我们看到它处于非活动状态。让我们尝试启动它:/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
➜ root@cluster3-node1:~# service kubelet start
➜ root@cluster3-node1:~# service kubelet status
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: activating (auto-restart) (Result: exit-code) since Thu 2020-04-30 22:03:10 UTC; 3s ago
Docs: https://kubernetes.io/docs/home/
Process: 5989 ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=203/EXEC)
Main PID: 5989 (code=exited, status=203/EXEC)
Apr 30 22:03:10 cluster3-node1 systemd[5989]: kubelet.service: Failed at step EXEC spawning /usr/local/bin/kubelet: No such file or directory
Apr 30 22:03:10 cluster3-node1 systemd[1]: kubelet.service: Main process exited, code=exited, status=203/EXEC
Apr 30 22:03:10 cluster3-node1 systemd[1]: kubelet.service: Failed with result 'exit-code'.
我们看到它正在尝试 使用其服务配置文件中定义的一些参数来执行。查找错误并获取更多日志的一个好方法是手动运行命令(通常也使用其参数)。/usr/local/bin/kubelet
➜ root@cluster3-node1:~# /usr/local/bin/kubelet
-bash: /usr/local/bin/kubelet: No such file or directory
➜ root@cluster3-node1:~# whereis kubelet
kubelet: /usr/bin/kubelet
另一种方法是查看服务的扩展日志记录,例如使用 .journalctl -u kubelet
好吧,我们有它,指定了错误的路径。更正文件中的路径并运行:/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf # fix
systemctl daemon-reload && systemctl restart kubelet
systemctl status kubelet # should now show running
此外,该节点应该可用于 api 服务器,不过要给它一点时间:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-controlplane1 Ready control-plane 14d v1.26.0
cluster3-node1 Ready <none> 14d v1.26.0
最后,我们将原因写入文件:
# /opt/course/18/reason.txt
wrong path to kubelet binary specified in service config
题库19
NOTE: This task can only be solved if questions 18 or 20 have been successfully implemented and the k8s-c3-CCC cluster has a functioning worker node
Use context: kubectl config use-context k8s-c3-CCC
Do the following in a new Namespace secret. Create a Pod named secret-pod of image busybox:1.31.1 which should keep running for some time.
There is an existing Secret located at /opt/course/19/secret1.yaml, create it in the Namespace secret and mount it readonly into the Pod at /tmp/secret1.
Create a new Secret in Namespace secret called secret2 which should contain user=user1 and pass=1234. These entries should be available inside the Pod's container as environment variables APP_USER and APP_PASS.
Confirm everything is working.
任务权重:3%
注意:仅当问题 18 或 20 已成功实现并且 k8s-c3-CCC 集群具有正常运行的工作节点时,才能解决此任务
使用上下文:kubectl config use-context k8s-c3-CCC
在新的命名空间中执行以下操作。创建一个以 image 命名的 Pod,它应该会持续运行一段时间。secretsecret-podbusybox:1.31.1
有一个现有的密钥位于 ,在命名空间中创建它并将其只读地挂载到 Pod 中。/opt/course/19/secret1.yamlsecret/tmp/secret1
在名为 的命名空间中创建一个新的密钥,该密钥应包含 和 。这些条目应该在 Pod 的容器中作为环境变量APP_USER和APP_PASS提供。secretsecret2user=user1pass=1234
确认一切正常。
题解
答
首先,我们在其中创建命名空间和请求的机密:
k create ns secret
cp /opt/course/19/secret1.yaml 19_secret1.yaml
vim 19_secret1.yaml
我们需要调整 该密钥的命名空间:
# 19_secret1.yaml
apiVersion: v1
data:
halt: IyEgL2Jpbi9zaAo...
kind: Secret
metadata:
creationTimestamp: null
name: secret1
namespace: secret # change
k -f 19_secret1.yaml create
接下来,我们创建第二个密钥:
k -n secret create secret generic secret2 --from-literal=user=user1 --from-literal=pass=1234
现在我们创建 Pod 模板:
k -n secret run secret-pod --image=busybox:1.31.1 $do -- sh -c "sleep 5d" > 19.yaml
vim 19.yaml
然后进行必要的更改:
# 19.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: secret-pod
name: secret-pod
namespace: secret # add
spec:
containers:
- args:
- sh
- -c
- sleep 1d
image: busybox:1.31.1
name: secret-pod
resources: {}
env: # add
- name: APP_USER # add
valueFrom: # add
secretKeyRef: # add
name: secret2 # add
key: user # add
- name: APP_PASS # add
valueFrom: # add
secretKeyRef: # add
name: secret2 # add
key: pass # add
volumeMounts: # add
- name: secret1 # add
mountPath: /tmp/secret1 # add
readOnly: true # add
dnsPolicy: ClusterFirst
restartPolicy: Always
volumes: # add
- name: secret1 # add
secret: # add
secretName: secret1 # add
status: {}
在当前的 K8s 版本中可能不需要指定 , 因为它无论如何都是默认设置。readOnly: true
并执行:
k -f 19.yaml create
最后,我们检查一切是否正确:
➜ k -n secret exec secret-pod -- env | grep APP
APP_PASS=1234
APP_USER=user1
➜ k -n secret exec secret-pod -- find /tmp/secret1
/tmp/secret1
/tmp/secret1/..data
/tmp/secret1/halt
/tmp/secret1/..2019_12_08_12_15_39.463036797
/tmp/secret1/..2019_12_08_12_15_39.463036797/halt
➜ k -n secret exec secret-pod -- cat /tmp/secret1/halt
#! /bin/sh
### BEGIN INIT INFO
# Provides: halt
# Required-Start:
# Required-Stop:
# Default-Start:
# Default-Stop: 0
# Short-Description: Execute the halt command.
# Description:
...
题库20
Use context: kubectl config use-context k8s-c3-CCC
Your coworker said node cluster3-node2 is running an older Kubernetes version and is not even part of the cluster. Update Kubernetes on that node to the exact version that's running on cluster3-controlplane1. Then add this node to the cluster. Use kubeadm for this.
任务权重:10%
使用上下文:kubectl config use-context k8s-c3-CCC
你的同事说节点运行的是较旧的 Kubernetes 版本,甚至不是集群的一部分。将该节点上的 Kubernetes 更新为在 上运行的确切版本。然后将此节点添加到群集。为此使用 kubeadm。cluster3-node2cluster3-controlplane1
题解
答:
将 Kubernetes 升级到 cluster3-controlplane1 版本
在文档中搜索 kubeadm 升级: https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-controlplane1 Ready control-plane 22h v1.26.0
cluster3-node1 Ready <none> 22h v1.26.0
控制平面节点似乎正在运行 Kubernetes 1.26.0,并且还不是集群的一部分。cluster3-node2
➜ ssh cluster3-node2
➜ root@cluster3-node2:~# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"26", GitVersion:"v1.26.0", GitCommit:"b46a3f887ca979b1a5d14fd39cb1af43e7e5d12d", GitTreeState:"clean", BuildDate:"2022-12-08T19:57:06Z", GoVersion:"go1.19.4", Compiler:"gc", Platform:"linux/amd64"}
➜ root@cluster3-node2:~# kubectl version --short
Client Version: v1.25.5
Kustomize Version: v4.5.7
➜ root@cluster3-node2:~# kubelet --version
Kubernetes v1.25.5
这里 kubeadm 已经安装在想要的版本中,所以我们不需要安装它。因此,我们可以运行:
➜ root@cluster3-node2:~# kubeadm upgrade node
couldn't create a Kubernetes client from file "/etc/kubernetes/kubelet.conf": failed to load admin kubeconfig: open /etc/kubernetes/kubelet.conf: no such file or directory
To see the stack trace of this error execute with --v=5 or higher
这通常是升级节点的正确命令。但是这个错误意味着这个节点甚至从未初始化过,所以这里没有什么可更新的。稍后将使用 完成此操作。现在我们可以继续使用 kubelet 和 kubectl:kubeadm join
➜ root@cluster3-node2:~# apt update
...
Fetched 5,775 kB in 2s (2,313 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
90 packages can be upgraded. Run 'apt list --upgradable' to see them.
➜ root@cluster3-node2:~# apt show kubectl -a | grep 1.26
Version: 1.26.0-00
➜ root@cluster3-node2:~# apt install kubectl=1.26.0-00 kubelet=1.26.0-00
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages will be upgraded:
kubectl kubelet
2 upgraded, 0 newly installed, 0 to remove and 135 not upgraded.
Need to get 30.5 MB of archives.
After this operation, 9,996 kB of additional disk space will be used.
Get:1 https://packages.cloud.google.com/apt kubernetes-xenial/main amd64 kubectl amd64 1.26.0-00 [10.1 MB]
Get:2 https://packages.cloud.google.com/apt kubernetes-xenial/main amd64 kubelet amd64 1.26.0-00 [20.5 MB]
Fetched 30.5 MB in 1s (29.7 MB/s)
(Reading database ... 112508 files and directories currently installed.)
Preparing to unpack .../kubectl_1.26.0-00_amd64.deb ...
Unpacking kubectl (1.26.0-00) over (1.25.5-00) ...
Preparing to unpack .../kubelet_1.26.0-00_amd64.deb ...
Unpacking kubelet (1.26.0-00) over (1.25.5-00) ...
Setting up kubectl (1.26.0-00) ...
Setting up kubelet (1.26.0-00) ...
➜ root@cluster3-node2:~# kubelet --version
Kubernetes v1.26.0
现在我们了解了 kubeadm、kubectl 和 kubelet。重新启动 kubelet:
➜ root@cluster3-node2:~# service kubelet restart
➜ root@cluster3-node2:~# service kubelet status
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: activating (auto-restart) (Result: exit-code) since Wed 2022-12-21 16:29:26 UTC; 5s ago
Docs: https://kubernetes.io/docs/home/
Process: 32111 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=1/FAILURE)
Main PID: 32111 (code=exited, status=1/FAILURE)
Dec 21 16:29:26 cluster3-node2 systemd[1]: kubelet.service: Main process exited, code=exited, status=1/FAILURE
Dec 21 16:29:26 cluster3-node2 systemd[1]: kubelet.service: Failed with result 'exit-code'.
发生这些错误是因为我们仍然需要运行 才能将节点加入群集。让我们在下一步中执行此操作。kubeadm join
将群集 3-节点 2 添加到群集
首先,我们登录到控制平面 1 并生成一个新的 TLS 引导令牌,同时打印出 join 命令:
➜ ssh cluster3-controlplane1
➜ root@cluster3-controlplane1:~# kubeadm token create --print-join-command
kubeadm join 192.168.100.31:6443 --token rbhrjh.4o93r31o18an6dll --discovery-token-ca-cert-hash sha256:d94524f9ab1eed84417414c7def5c1608f84dbf04437d9f5f73eb6255dafdb18
➜ root@cluster3-controlplane1:~# kubeadm token list
TOKEN TTL EXPIRES ...
44dz0t.2lgmone0i1o5z9fe <forever> <never>
4u477f.nmpq48xmpjt6weje 1h 2022-12-21T18:14:30Z
rbhrjh.4o93r31o18an6dll 23h 2022-12-22T16:29:58Z
我们看到我们的令牌到期了 23 小时,我们可以通过传递 ttl 参数来调整它。
接下来,我们再次连接到 并简单地执行 join 命令:cluster3-node2
➜ ssh cluster3-node2
➜ root@cluster3-node2:~# kubeadm join 192.168.100.31:6443 --token rbhrjh.4o93r31o18an6dll --discovery-token-ca-cert-hash sha256:d94524f9ab1eed84417414c7def5c1608f84dbf04437d9f5f73eb6255dafdb18
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
➜ root@cluster3-node2:~# service kubelet status
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Wed 2022-12-21 16:32:19 UTC; 1min 4s ago
Docs: https://kubernetes.io/docs/home/
Main PID: 32510 (kubelet)
Tasks: 11 (limit: 462)
Memory: 55.2M
CGroup: /system.slice/kubelet.service
└─32510 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runti>
如果您有问题,您可能需要 运行 .kubeadm join``kubeadm reset
这对我们来说看起来很棒。最后我们回到主终端并检查节点状态:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-controlplane1 Ready control-plane 22h v1.26.0
cluster3-node1 Ready <none> 22h v1.26.0
cluster3-node2 NotReady <none> 22h v1.26.0
给它一点时间,直到节点准备就绪。
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-controlplane1 Ready control-plane 22h v1.26.0
cluster3-node1 Ready <none> 22h v1.26.0
cluster3-node2 Ready <none> 22h v1.26.0
我们看到 现在可用且是最新的。cluster3-node2
题库21
Use context: kubectl config use-context k8s-c3-CCC
Create a Static Pod named my-static-pod in Namespace default on cluster3-controlplane1. It should be of image nginx:1.16-alpine and have resource requests for 10m CPU and 20Mi memory.
Then create a NodePort Service named static-pod-service which exposes that static Pod on port 80 and check if it has Endpoints and if it's reachable through the cluster3-controlplane1 internal IP address. You can connect to the internal node IPs from your main terminal.
任务权重:2%
使用上下文:kubectl config use-context k8s-c3-CCC
在群集 3-控制平面 1 上的命名空间中创建一个命名。它应该是映像的,并且具有对 CPU 和内存的资源请求。Static Podmy-static-poddefaultnginx:1.16-alpine10m20Mi
然后创建一个名为的 NodePort 服务,该服务在端口 80 上公开该静态 Pod,并检查它是否有端点以及是否可以通过内部 IP 地址访问它。您可以从主终端连接到内部节点 IP。static-pod-servicecluster3-controlplane1
题解
答:
➜ ssh cluster3-controlplane1
➜ root@cluster1-controlplane1:~# cd /etc/kubernetes/manifests/
➜ root@cluster1-controlplane1:~# kubectl run my-static-pod \
--image=nginx:1.16-alpine \
-o yaml --dry-run=client > my-static-pod.yaml
然后编辑 以 添加请求的资源请求:my-static-pod.yaml
# /etc/kubernetes/manifests/my-static-pod.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: my-static-pod
name: my-static-pod
spec:
containers:
- image: nginx:1.16-alpine
name: my-static-pod
resources:
requests:
cpu: 10m
memory: 20Mi
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
并确保它正在运行:
➜ k get pod -A | grep my-static
NAMESPACE NAME READY STATUS ... AGE
default my-static-pod-cluster3-controlplane1 1/1 Running ... 22s
现在我们公开静态 Pod:
k expose pod my-static-pod-cluster3-controlplane1 \
--name static-pod-service \
--type=NodePort \
--port 80
这将生成如下服务:
# kubectl expose pod my-static-pod-cluster3-controlplane1 --name static-pod-service --type=NodePort --port 80
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
run: my-static-pod
name: static-pod-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: my-static-pod
type: NodePort
status:
loadBalancer: {}
然后运行并测试:
➜ k get svc,ep -l run=my-static-pod
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/static-pod-service NodePort 10.99.168.252 <none> 80:30352/TCP 30s
NAME ENDPOINTS AGE
endpoints/static-pod-service 10.32.0.4:80 30s
看起来不错。
题库22
Use context: kubectl config use-context k8s-c2-AC
Check how long the kube-apiserver server certificate is valid on cluster2-controlplane1. Do this with openssl or cfssl. Write the exipiration date into /opt/course/22/expiration.
Also run the correct kubeadm command to list the expiration dates and confirm both methods show the same date.
Write the correct kubeadm command that would renew the apiserver server certificate into /opt/course/22/kubeadm-renew-certs.sh.
任务权重:2%
使用上下文:kubectl config use-context k8s-c2-AC
检查 kube-apiserver 服务器证书在 上的有效期。使用 openssl 或 cfssl。将过期日期写入 。cluster2-controlplane1/opt/course/22/expiration
还要运行正确的命令以列出到期日期,并确认两种方法显示相同的日期。kubeadm
将续订 apiserver 服务器证书的正确命令写入 。kubeadm/opt/course/22/kubeadm-renew-certs.sh
题解
答:
首先,让我们找到该证书:
➜ ssh cluster2-controlplane1
➜ root@cluster2-controlplane1:~# find /etc/kubernetes/pki | grep apiserver
/etc/kubernetes/pki/apiserver.crt
/etc/kubernetes/pki/apiserver-etcd-client.crt
/etc/kubernetes/pki/apiserver-etcd-client.key
/etc/kubernetes/pki/apiserver-kubelet-client.crt
/etc/kubernetes/pki/apiserver.key
/etc/kubernetes/pki/apiserver-kubelet-client.key
接下来我们使用openssl找出到期日期:
➜ root@cluster2-controlplane1:~# openssl x509 -noout -text -in /etc/kubernetes/pki/apiserver.crt | grep Validity -A2
Validity
Not Before: Dec 20 18:05:20 2022 GMT
Not After : Dec 20 18:05:20 2023 GMT
我们有它,所以我们把它写在主终端上的所需位置:
# /opt/course/22/expiration
Dec 20 18:05:20 2023 GMT
我们也使用 kubeadm 的功能来获取到期时间:
➜ root@cluster2-controlplane1:~# kubeadm certs check-expiration | grep apiserver
apiserver Jan 14, 2022 18:49 UTC 363d ca no
apiserver-etcd-client Jan 14, 2022 18:49 UTC 363d etcd-ca no
apiserver-kubelet-client Jan 14, 2022 18:49 UTC 363d ca no
看起来不错。最后,我们编写命令,将所有证书续订到请求的位置:
# /opt/course/22/kubeadm-renew-certs.sh
kubeadm certs renew apiserver
题库23
Use context: kubectl config use-context k8s-c2-AC
Node cluster2-node1 has been added to the cluster using kubeadm and TLS bootstrapping.
Find the "Issuer" and "Extended Key Usage" values of the cluster2-node1:
kubelet client certificate, the one used for outgoing connections to the kube-apiserver.
kubelet server certificate, the one used for incoming connections from the kube-apiserver.
Write the information into file /opt/course/23/certificate-info.txt.
Compare the "Issuer" and "Extended Key Usage" fields of both certificates and make sense of these.
任务权重:2%
使用上下文:kubectl config use-context k8s-c2-AC
节点群集 2-节点 1 已使用 和 TLS 引导添加到群集中。kubeadm
查找 cluster2-node1 的“颁发者”和“扩展密钥用法”值:
kubelet 客户端证书,用于与 kube-apiserver 的传出连接。
kubelet 服务器证书,用于从 kube-apiserver 传入连接的证书。
将信息写入文件 。/opt/course/23/certificate-info.txt
比较两个证书的“颁发者”和“扩展密钥用法”字段并理解这些字段。
题解
答:
要找到正确的 kubelet 证书目录,我们可以查找 kubelet 参数的默认值 。对于在 Kubernetes 文档中搜索“kubelet”,这将导致:https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet。我们可以检查是否已使用 或 在 中配置了另一个证书目录。--cert-dir``ps aux``/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
首先我们检查 kubelet 客户端证书:
➜ ssh cluster2-node1
➜ root@cluster2-node1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet-client-current.pem | grep Issuer
Issuer: CN = kubernetes
➜ root@cluster2-node1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet-client-current.pem | grep "Extended Key Usage" -A1
X509v3 Extended Key Usage:
TLS Web Client Authentication
接下来我们检查 kubelet 服务器证书:
➜ root@cluster2-node1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet.crt | grep Issuer
Issuer: CN = cluster2-node1-ca@1588186506
➜ root@cluster2-node1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet.crt | grep "Extended Key Usage" -A1
X509v3 Extended Key Usage:
TLS Web Server Authentication
我们看到服务器证书是在工作节点本身上生成的,客户端证书是由 Kubernetes API 颁发的。“扩展密钥用法”还显示它是用于客户端还是服务器身份验证。
更多关于这个: https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet-tls-bootstrapping
题库24
Use context: kubectl config use-context k8s-c1-H
There was a security incident where an intruder was able to access the whole cluster from a single hacked backend Pod.
To prevent this create a NetworkPolicy called np-backend in Namespace project-snake. It should allow the backend-* Pods only to:
connect to db1-* Pods on port 1111
connect to db2-* Pods on port 2222
Use the app label of Pods in your policy.
After implementation, connections from backend-* Pods to vault-* Pods on port 3333 should for example no longer work.
任务权重:9%
使用上下文:kubectl config use-context k8s-c1-H
发生了一起安全事件,入侵者能够从单个被黑客入侵的后端 Pod 访问整个集群。
为了防止这种情况,请创建一个在命名空间中调用的网络策略。它应该只允许 Pod 执行以下操作:np-backendproject-snakebackend-*
连接到端口 1111 上的 Podsdb1-*
连接到端口 2222 上的 Podsdb2-*
在策略中使用 Pod 标签。app
例如,实现后,端口 3333 上从 Pod 到 Pod 的连接应该不再有效。backend-*vault-*
题解
答:
首先,我们看一下现有的 Pod 及其标签:
➜ k -n project-snake get pod
NAME READY STATUS RESTARTS AGE
backend-0 1/1 Running 0 8s
db1-0 1/1 Running 0 8s
db2-0 1/1 Running 0 10s
vault-0 1/1 Running 0 10s
➜ k -n project-snake get pod -L app
NAME READY STATUS RESTARTS AGE APP
backend-0 1/1 Running 0 3m15s backend
db1-0 1/1 Running 0 3m15s db1
db2-0 1/1 Running 0 3m17s db2
vault-0 1/1 Running 0 3m17s vault
我们测试了当前的连接情况,发现没有任何限制:
➜ k -n project-snake get pod -o wide
NAME READY STATUS RESTARTS AGE IP ...
backend-0 1/1 Running 0 4m14s 10.44.0.24 ...
db1-0 1/1 Running 0 4m14s 10.44.0.25 ...
db2-0 1/1 Running 0 4m16s 10.44.0.23 ...
vault-0 1/1 Running 0 4m16s 10.44.0.22 ...
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.25:1111
database one
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.23:2222
database two
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.22:3333
vault secret storage
现在我们通过 从 k8s 文档中复制和追踪一个示例来创建 NP:
vim 24_np.yaml
# 24_np.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: np-backend
namespace: project-snake
spec:
podSelector:
matchLabels:
app: backend
policyTypes:
- Egress # policy is only about Egress
egress:
- # first rule
to: # first condition "to"
- podSelector:
matchLabels:
app: db1
ports: # second condition "port"
- protocol: TCP
port: 1111
- # second rule
to: # first condition "to"
- podSelector:
matchLabels:
app: db2
ports: # second condition "port"
- protocol: TCP
port: 2222
上面的NP有两个规则,每个规则有两个条件,可以理解为:
allow outgoing traffic if:
(destination pod has label app=db1 AND port is 1111)
OR
(destination pod has label app=db2 AND port is 2222)
错误的例子
现在让我们看一个错误的例子:
# WRONG
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: np-backend
namespace: project-snake
spec:
podSelector:
matchLabels:
app: backend
policyTypes:
- Egress
egress:
- # first rule
to: # first condition "to"
- podSelector: # first "to" possibility
matchLabels:
app: db1
- podSelector: # second "to" possibility
matchLabels:
app: db2
ports: # second condition "ports"
- protocol: TCP # first "ports" possibility
port: 1111
- protocol: TCP # second "ports" possibility
port: 2222
上面的NP有一个规则,有两个条件,每个规则有两个条件条目,可以读作:
allow outgoing traffic if:
(destination pod has label app=db1 OR destination pod has label app=db2)
AND
(destination port is 1111 OR destination port is 2222)
使用此 NP,Pod 仍然可以 连接到 端口 1111 上的 Pod,例如应该禁止的端口。backend-*``db2-*
创建网络策略
我们创建正确的NP:
k -f 24_np.yaml create
并再次测试:
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.25:1111
database one
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.23:2222
database two
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.22:3333
^C
在NP上使用 也有助于了解k8s如何解释政策。kubectl describe
太好了,看起来更安全。任务完成。
题库25
Use context: kubectl config use-context k8s-c3-CCC
Make a backup of etcd running on cluster3-controlplane1 and save it on the controlplane node at /tmp/etcd-backup.db.
Then create a Pod of your kind in the cluster.
Finally restore the backup, confirm the cluster is still working and that the created Pod is no longer with us.
任务权重:8%
使用上下文:kubectl config use-context k8s-c3-CCC
备份在集群 3-控制平面 1 上运行的 etcd,并将其保存在控制平面节点上。/tmp/etcd-backup.db
然后在集群中创建同类 Pod。
最后恢复备份,确认集群仍在工作,并且创建的 Pod 不再与我们在一起。
题解
答:
蚀刻备份
首先,我们登录控制平面并尝试创建 etcd 的快照:
➜ ssh cluster3-controlplane1
➜ root@cluster3-controlplane1:~# ETCDCTL_API=3 etcdctl snapshot save /tmp/etcd-backup.db
Error: rpc error: code = Unavailable desc = transport is closing
但它失败了,因为我们需要验证自己。有关必要的信息,我们可以检查 etc 清单:
➜ root@cluster3-controlplane1:~# vim /etc/kubernetes/manifests/etcd.yaml
我们只检查 必要的信息,我们不会更改它。etcd.yaml
# /etc/kubernetes/manifests/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.100.31:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt # use
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --initial-advertise-peer-urls=https://192.168.100.31:2380
- --initial-cluster=cluster3-controlplane1=https://192.168.100.31:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key # use
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.100.31:2379 # use
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.100.31:2380
- --name=cluster3-controlplane1
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt # use
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: k8s.gcr.io/etcd:3.3.15-0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health
port: 2381
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 15
name: etcd
resources: {}
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd # important
type: DirectoryOrCreate
name: etcd-data
status: {}
但我们也知道 API 服务器正在连接到 etcd,因此我们可以检查其清单是如何配置的:
➜ root@cluster3-controlplane1:~# cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379
我们使用身份验证信息并将其传递给 etcdctl:
➜ root@cluster3-controlplane1:~# ETCDCTL_API=3 etcdctl snapshot save /tmp/etcd-backup.db \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.key
Snapshot saved at /tmp/etcd-backup.db
**注意:**请勿使用 ,因为它可能会更改快照文件并使其无效
snapshot status
蚀刻恢复
现在在集群中创建一个 Pod 并等待它运行:
➜ root@cluster3-controlplane1:~# kubectl run test --image=nginx
pod/test created
➜ root@cluster3-controlplane1:~# kubectl get pod -l run=test -w
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 60s
**注意:**如果您没有解决问题 18 或 20,并且 cluster3 没有就绪的工作节点,则创建的 Pod 可能会保持“挂起”状态。对于此任务,这仍然可以。
接下来,我们停止所有控制平面组件:
root@cluster3-controlplane1:~# cd /etc/kubernetes/manifests/
root@cluster3-controlplane1:/etc/kubernetes/manifests# mv * ..
root@cluster3-controlplane1:/etc/kubernetes/manifests# watch crictl ps
现在我们将快照还原到特定目录中:
➜ root@cluster3-controlplane1:~# ETCDCTL_API=3 etcdctl snapshot restore /tmp/etcd-backup.db \
--data-dir /var/lib/etcd-backup \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.key
2020-09-04 16:50:19.650804 I | mvcc: restore compact to 9935
2020-09-04 16:50:19.659095 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
我们可以指定另一个主机来使用 进行备份,但这里我们只使用默认值:。 etcdctl --endpoints http://IP``http://127.0.0.1:2379,http://127.0.0.1:4001
恢复的文件位于 新文件夹 ,现在我们必须告诉 etcd 使用该目录:/var/lib/etcd-backup
➜ root@cluster3-controlplane1:~# vim /etc/kubernetes/etcd.yaml
# /etc/kubernetes/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
...
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd-backup # change
type: DirectoryOrCreate
name: etcd-data
status: {}
现在,我们将所有控制平面 yaml 再次移动到清单目录中。给它一些时间(最多几分钟)让 etcd 重新启动并再次访问 API 服务器:
root@cluster3-controlplane1:/etc/kubernetes/manifests# mv ../*.yaml .
root@cluster3-controlplane1:/etc/kubernetes/manifests# watch crictl ps
然后我们再次检查 Pod :
➜ root@cluster3-controlplane1:~# kubectl get pod -l run=test
No resources found in default namespace.
太棒了,备份和还原在我们的 pod 消失时工作。
@cluster3-controlplane1:~# cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379
我们使用身份验证信息并将其传递给 etcdctl:
➜ root@cluster3-controlplane1:~# ETCDCTL_API=3 etcdctl snapshot save /tmp/etcd-backup.db
–cacert /etc/kubernetes/pki/etcd/ca.crt
–cert /etc/kubernetes/pki/etcd/server.crt
–key /etc/kubernetes/pki/etcd/server.key
Snapshot saved at /tmp/etcd-backup.db
> **注意:**请勿使用 ,因为它可能会更改快照文件并使其无效`snapshot status`
###### 蚀刻恢复
现在在集群中创建一个 *Pod* 并等待它运行:
➜ root@cluster3-controlplane1:~# kubectl run test --image=nginx
pod/test created
➜ root@cluster3-controlplane1:~# kubectl get pod -l run=test -w
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 60s
> **注意:**如果您没有解决问题 18 或 20,并且 cluster3 没有就绪的工作节点,则创建的 Pod 可能会保持“挂起”状态。对于此任务,这仍然可以。
接下来,我们停止所有控制平面组件:
root@cluster3-controlplane1:~# cd /etc/kubernetes/manifests/
root@cluster3-controlplane1:/etc/kubernetes/manifests# mv * …
root@cluster3-controlplane1:/etc/kubernetes/manifests# watch crictl ps
现在我们将快照还原到特定目录中:
➜ root@cluster3-controlplane1:~# ETCDCTL_API=3 etcdctl snapshot restore /tmp/etcd-backup.db
–data-dir /var/lib/etcd-backup
–cacert /etc/kubernetes/pki/etcd/ca.crt
–cert /etc/kubernetes/pki/etcd/server.crt
–key /etc/kubernetes/pki/etcd/server.key
2020-09-04 16:50:19.650804 I | mvcc: restore compact to 9935
2020-09-04 16:50:19.659095 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
我们可以指定另一个主机来使用 进行备份,但这里我们只使用默认值:。 `etcdctl --endpoints http://IP``http://127.0.0.1:2379,http://127.0.0.1:4001`
恢复的文件位于 新文件夹 ,现在我们必须告诉 etcd 使用该目录:`/var/lib/etcd-backup`
➜ root@cluster3-controlplane1:~# vim /etc/kubernetes/etcd.yaml
/etc/kubernetes/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
…
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs - hostPath:
path: /var/lib/etcd-backup # change
type: DirectoryOrCreate
name: etcd-data
status: {}
现在,我们将所有控制平面 yaml 再次移动到清单目录中。给它一些时间(最多几分钟)让 etcd 重新启动并再次访问 API 服务器:
root@cluster3-controlplane1:/etc/kubernetes/manifests# mv …/*.yaml .
root@cluster3-controlplane1:/etc/kubernetes/manifests# watch crictl ps
然后我们再次检查 *Pod* :
➜ root@cluster3-controlplane1:~# kubectl get pod -l run=test
No resources found in default namespace.
太棒了,备份和还原在我们的 pod 消失时工作。