文章目录
- 1.transformer介绍
- 1.1 注意力机制
- 1.2 Transformer架构
- 1.2.1编码器
- 1.2.2解码器
- 2. Transformer中的模块
- 2.1 注意模块
- 2.1.1 缩放点积注意事项
- 2.1.2 多头注意
- 2.2 Transformer中的注意事项
- 2.2.1 自注意
- 2.2.2 掩蔽的自注意(自回归或因果注意)
- 2.2.3 交叉注意
1.transformer介绍
- Transformer被认为是一种新型的深度前馈人工神经网络架构,它利用了自注意机制,可以处理输入序列项之间的长期相关性。
- 在大量领域中采用,如自然语言处理(NLP)、计算机视觉(CV)、,音频和语音处理、化学和生命科学;他们可以在前面提到的学科中实现SOTA性能。
- TransformerX库存储库
1.1 注意力机制
- 注意力是一种处理能力有限的认知资源分配方案
- 它同时生成源标记(单词)的翻译,1)这些相关位置的上下文向量和2)先前生成的单词。
- 注意力的特性
1.软 2.硬 3.局部 4.全局 - 输入特征的形式
- Item-wise 2. Location-wise
- 输入表示
1.Co-attention 2. Self-attention 3. Distinctive attention 4. Hierarchical attention - 输出表示
- 多头 2.单输出 3.多维
1.2 Transformer架构
- 基本Transformer架构由两个主要构建块组成,即编码器和解码器块.(与序列到序列模型类似,Transformer使用编码器-解码器架构)
- 编码器从输入表示序列 (𝒙₁ , …, 𝒙ₙ) 生成嵌入向量𝒁 = (𝒛₁ , …, 𝒛ₙ),并将其传递给解码器以生成输出序列 (𝒚₁ , …, 𝒚ₘ).
在每一步生成输出之前,𝒁 向量被送入解码器,因此该模型是自回归的。 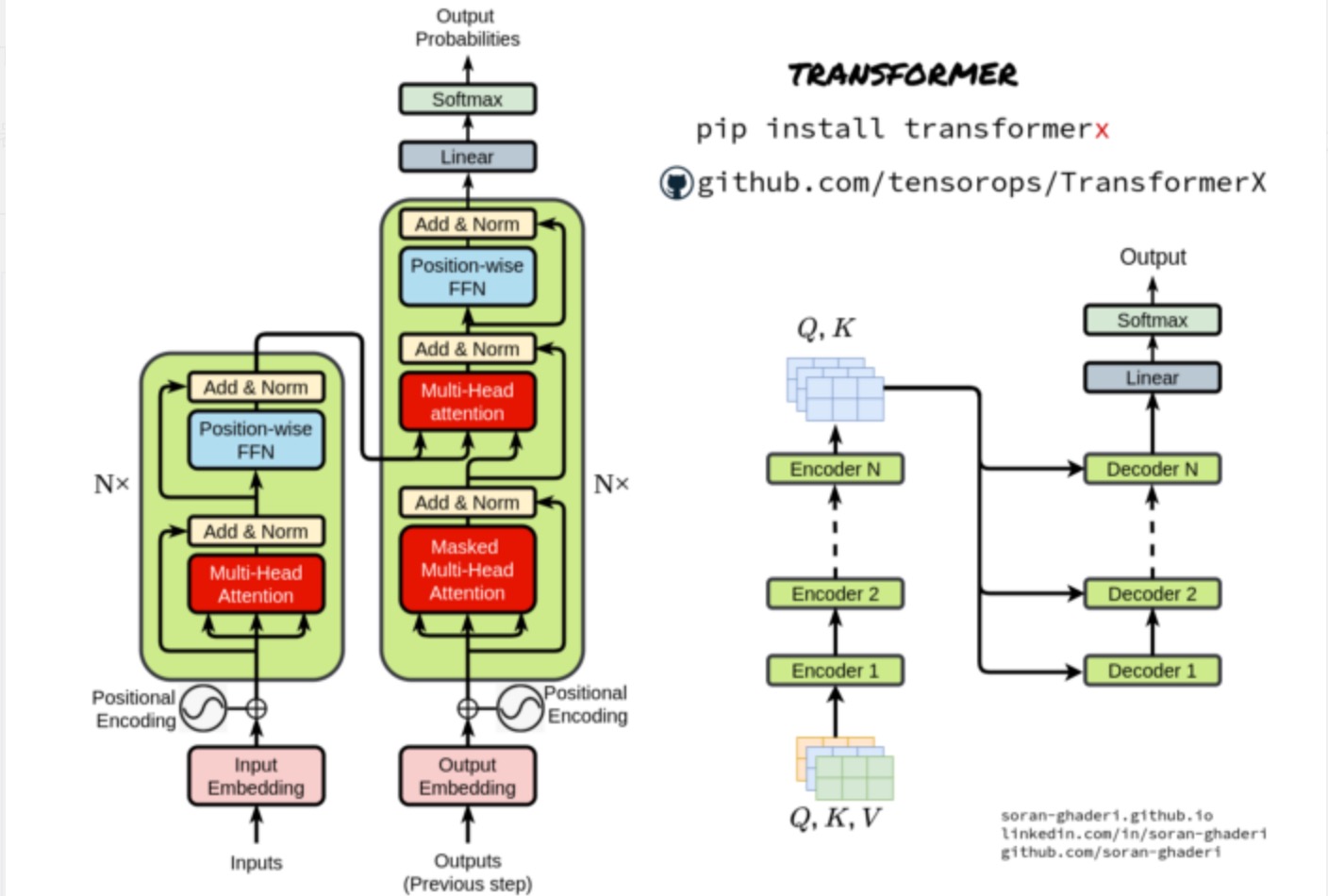
1.2.1编码器
- 编码器只是多个组件或层的堆栈-𝑵 在原始论文中是6。它们本身是两个子层,即多头自注意块和简单FC FFN(全连接的前馈网络)。
- 为了实现更深入的模型,研究人员通过包裹两个子层,然后进行层归一化,并实现残差连接。因此,每个子层的输出都是LayerNorm( 𝒙 + Sublayer( 𝒙 )) ,Sublayer(* 𝒙 *)*是在其内部实现的函数。所有子层以及嵌入的输出维度为𝒅 _model=512。
import tensorflow as tf
from transformerx.layers.positional_encoding import SinePositionalEncoding
from transformerx.layers.transformer_encoder_block import TransformerEncoderBlock
class TransformerEncoder(tf.keras.layers.Layer):
def __init__(self,vocab_size,depth,norm_shape,ffn_num_hiddens,
num_heads,
n_blocks,
dropout,
bias=False,
):
super().__init__()
self.depth = depth
self.n_blocks = n_blocks
self.embedding = tf.keras.layers.Embedding(vocab_size, depth)
self.pos_encoding = SinePositionalEncoding(depth, dropout)
self.blocks = [
TransformerEncoderBlock(
depth,
norm_shape,
ffn_num_hiddens,
num_heads,
dropout,
bias,
)
for _ in range(self.n_blocks)
]
def call(self, X, valid_lens, **kwargs):
X = self.pos_encoding(
self.embedding(X) * tf.math.sqrt(tf.cast(self.depth, dtype=tf.float32)),
**kwargs,
)
self.attention_weights = [None] * len(self.blocks)
for i, blk in enumerate(self.blocks):
X = blk(X, valid_lens, **kwargs)
self.attention_weights[i] = blk.attention.attention.attention_weights
return X
1.2.2解码器
- 除了编码器中使用的子层之外,解码器对编码器组件的输出应用多头注意。与编码器一样,残差连接连接到子层,然后进行层规范化。保证对该位置的预测𝒊 可以仅依赖于先前已知的位置,对自注意子层应用另一种修改以防止位置伴随着将输出嵌入偏移一个位置而注意其他位置。
import tensorflow as tf
from transformerx.layers.positional_encoding import SinePositionalEncoding
from transformerx.layers.transformer_decoder_block import TransformerDecoderBlock
class TransformerDecoder(tf.keras.layers.Layer):
def __init__(self,vocab_size,depth,norm_shape,ffn_num_hiddens,num_heads,n_blocks,dropout,):
super().__init__()
self.depth = depth
self.n_blocks = n_blocks
self.embedding = tf.keras.layers.Embedding(vocab_size, depth)
self.pos_encoding = SinePositionalEncoding(depth, dropout)
self.blocks = [
TransformerDecoderBlock(
depth,
norm_shape,
ffn_num_hiddens,
num_heads,
dropout,
i,
)
for i in range(n_blocks)
]
self.dense = tf.keras.layers.Dense(vocab_size)
def init_state(self, enc_outputs, enc_valid_lens):
return [enc_outputs, enc_valid_lens, [None] * self.n_blocks]
def call(self, X, state, **kwargs):
X = self.pos_encoding(
self.embedding(X) * tf.math.sqrt(tf.cast(self.depth, dtype=tf.float32)),
**kwargs,
)
# 2 attention layers in decoder
self._attention_weights = [[None] * len(self.blocks) for _ in range(2)]
for i, blk in enumerate(self.blocks):
X, state = blk(X, state, **kwargs)
# Decoder self-attention weights
self._attention_weights[0][i] = blk.attention1.attention.attention_weights
# Encoder-decoder attention weights
self._attention_weights[1][i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
2. Transformer中的模块
2.1 注意模块
该Transformer将信息检索中的查询键值(QKV)概念与注意力机制相结合
- 缩放的点积注意
- 多头注意力
2.1.1 缩放点积注意事项
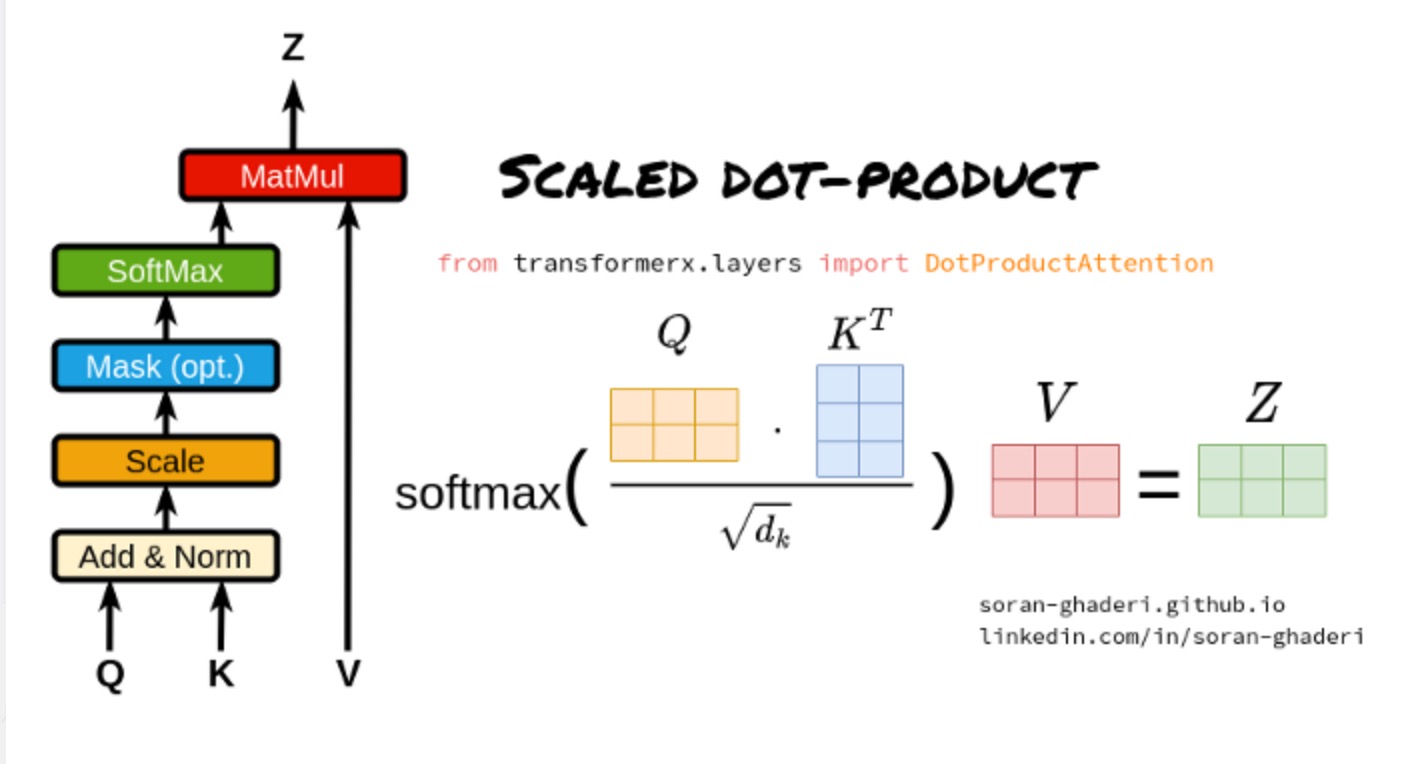
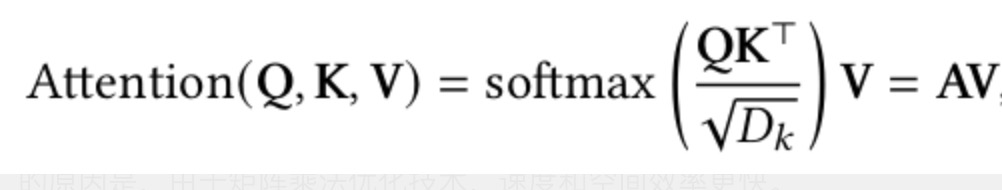
矩阵𝑨 在等式1中,通常称为注意力矩阵。他们使用点积注意力而不是加法注意力(使用具有单个隐藏层的前馈网络来计算兼容性函数)的原因是,由于矩阵乘法优化技术,速度和空间效率更快。
尽管如此,对于较大值的𝐷𝑘 这将softmax函数的梯度推到极小的梯度。为了抑制softmax函数的梯度消失问题,将键和查询的点积除以𝐷𝑘, 由于这个事实,它被称为缩放点积。
import os
import numpy as np
import tensorflow as tf
from transformerx.utils import masked_softmax
class DotProductAttention(tf.keras.layers.Layer):
def __init__(
self,
dropout_rate: float = 0,
scaled: bool = True,
normalize: bool = False,
kernel_initializer: str = "ones",
kernel_regularizer: str = None,
**kwargs
):
super().__init__(**kwargs)
self.dropout_rate = dropout_rate
self.dropout = tf.keras.layers.Dropout(self.dropout_rate)
self.scaled = scaled
self.normalize = normalize
self.attention_weights = None
self.kernel_initializer = kernel_initializer
self.kernel_regularizer = kernel_regularizer
def build(self, input_shape):
super().build(input_shape)
# Shape of queries: (batch_size, no. of queries, d)
# Shape of keys: (batch_size, no. of key-value pairs, d)
# Shape of values: (batch_size, no. of key-value pairs, value dimension)
# Shape of attention_mask: (batch_size,) or (batch_size, no. of queries)
def call(
self,
queries: tf.Tensor,
keys: tf.Tensor,
values: tf.Tensor,
attention_mask: tf.Tensor = None,
causal_mask: bool = None,
training=None,
**kwargs
) -> tf.Tensor:
scores = tf.matmul(queries, keys, transpose_b=True)
if self.scaled:
# self.scale = self.add_weight(
# name="scale",
# shape=(scores.shape),
# initializer=self.kernel_initializer,
# regularizer=self.kernel_regularizer,
# trainable=True,
# )
depth = queries.shape[-1]
# print(self.scale, scores.shape)
# self.scale = tf.broadcast_to(scores.shape)
# self.scale = tf.broadcast_to(
# tf.expand_dims(tf.expand_dims(self.scale, -1), -1), scores.shape
# )
scores = (
scores
/ tf.math.sqrt(tf.cast(depth, dtype=tf.float32))
# * self.scale
)
# apply causal mask
if causal_mask:
seq_len = tf.shape(queries)[2]
heads = tf.shape(queries)[1]
causal_mask = tf.ones((heads, seq_len)) * -1e9
causal_mask = tf.linalg.LinearOperatorLowerTriangular(
causal_mask
).to_dense()
causal_mask = tf.expand_dims(causal_mask, axis=0) # add batch dimension
scores += tf.broadcast_to(
tf.expand_dims(causal_mask, -1), scores.shape
) # broadcast across batch dimension
self.attention_weights = masked_softmax(scores, attention_mask)
# self.attention_weights = tf.nn.softmax(scores, axis=-1, mask=attention_mask)
scores = tf.matmul(self.dropout(self.attention_weights, **kwargs), values)
if self.normalize:
depth = tf.cast(tf.shape(keys)[-1], tf.float32)
scores /= tf.sqrt(depth)
return scores
def get_attention_weights(self):
return self.attention_weights
2.1.2 多头注意
- 引入多个注意力头而不是单个注意力函数,Transformer 将 𝐷𝑚 维的原始查询、键和值线性投影到 𝐷𝑘、𝐷𝑘 和 𝐷𝑣 维度,分别使用不同的线性投影 h次;通过它,可以并行计算这些投影上的注意力函数(等式 1),产生 𝐷𝑣 维输出值。然后该模型将它们连接起来并生成 𝐷𝑚 维表示。
import numpy as np
import tensorflow as tf
from einops import rearrange
from transformerx.layers.dot_product_attention import DotProductAttention
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(
self,
d_model: int = 512,
num_heads: int = 8,
dropout_rate: float = 0,
bias: bool = False,
attention: str = "scaled_dotproduct",
**kwargs,
):
super(MultiHeadAttention, self).__init__(**kwargs)
self.d_model = d_model
self.num_heads = num_heads
self.dropout_rate = dropout_rate
self.bias = bias
if attention == "scaled_dotproduct" or attention == None:
self.attention = DotProductAttention(self.dropout_rate, scaled=True)
elif attention == "dotproduct":
self.attention = DotProductAttention(self.dropout_rate, scaled=False)
self.W_q = tf.keras.layers.Dense(self.d_model, use_bias=self.bias)
self.W_k = tf.keras.layers.Dense(self.d_model, use_bias=self.bias)
self.W_v = tf.keras.layers.Dense(self.d_model, use_bias=self.bias)
self.W_o = tf.keras.layers.Dense(self.d_model, use_bias=self.bias)
def split_heads(self, X: tf.Tensor) -> tf.Tensor:
# x = tf.reshape(x, shape=(x.shape[0], x.shape[1], self.num_heads, -1))
X = rearrange(X, "b l (h dk) -> b l h dk", h=self.num_heads)
# x = tf.transpose(x, perm=(0, 2, 1, 3))
X = rearrange(X, "b l h dk -> b h l dk")
# return tf.reshape(x, shape=(-1, x.shape[2], x.shape[3]))
# X = rearrange(X, "b h l dk -> (b h) l dk")
return X
def inverse_transpose_qkv(self, X: tf.Tensor) -> tf.Tensor:
# transpose back to original shape: (batch_size, seq_len, num_heads, head_dim)
X = rearrange(X, "b h l d -> b l h d")
# concatenate num_heads dimension with head_dim dimension:
X = rearrange(X, "b l h d -> b l (h d)")
return X
def call(
self,
queries: tf.Tensor,
values: tf.Tensor,
keys: tf.Tensor,
attention_mask: tf.Tensor = None,
causal_mask: bool = False,
**kwargs,
) -> tf.Tensor:
queries = self.split_heads(self.W_q(queries))
keys = self.split_heads(self.W_k(keys))
values = self.split_heads(self.W_v(values))
if attention_mask is not None:
# On axis 0, copy the first item (scalar or vector) for num_heads
# times, then copy the next item, and so on
attention_mask = tf.repeat(attention_mask, repeats=self.num_heads, axis=0)
# Shape of output: (batch_size * num_heads, no. of queries,
# depth / num_heads)
output = self.attention(
queries, keys, values, attention_mask, causal_mask, **kwargs
)
# Shape of output_concat: (batch_size, no. of queries, depth)
output_concat = self.inverse_transpose_qkv(output)
return self.W_o(output_concat)
2.2 Transformer中的注意事项
- Transformer论文中采用了三种不同的使用注意力的方法,它们在键、查询和值被输入注意力函数的方式方面是不同的。
2.2.1 自注意
- 所有键、查询和值向量来自相同的序列,在Transformer的情况下,编码器的前一步输出,允许编码器同时注意其自身前一层中的所有位置,即。𝑸 = 𝑲 = 𝑽 = 𝑿 (以前的编码器输出)。
2.2.2 掩蔽的自注意(自回归或因果注意)
- 尽管有编码器层,但在解码器的自注意中,查询被限制在它们之前的键值对位置以及它们的当前位置,以便保持自回归特性。这可以通过屏蔽无效位置并将其设置为负无限来实现,即𝑨 𝒊𝒋 = −∞ 如果𝒊 < 𝒋.
2.2.3 交叉注意
- 这种类型的注意力从先前的解码器层获得其查询,而键和值是从编码器产量获得的。这基本上是在序列到序列模型中的编码器-解码器注意机制中使用的注意。换句话说,交叉注意力将两个不同的嵌入序列相结合,这些维度从一个序列中导出其查询,从另一个序列导出其键和值。
- 假设S1和S2是两个嵌入序列,交叉注意力从S1获得其键和值,从S2获得其查询,然后计算注意力得分并生成长度为S2的结果序列。在Transformer的情况下,键和值是从编码器和前一步解码器输出的查询中导出的。