函数调用约定简介

参数的传递方式:使用后栈来保存。
每个进程都有自己的栈,这就是每个内存自己的专用内存空间;保存参数的内存地址不用再花精力维护,已经有栈机制来维护地址变化了,参数在栈中的位置可以通过栈顶的偏移量来得到。
C语言 由调用者压入栈,由调用者清理栈空间,函数参数是从右到左的顺序入栈。


汇编语言和C语言混合编程
浅析C库函数与系统调用
汇编语言和C语言混合编码可分为两类:
单独的汇编代码文件与单独的C语言文件分别编译目标文件后,一起链接成可执行文件。(本文使用方法)
在C语言中嵌入汇编代码,直接编译生成可执行程序。
系统调用是用来实现一系列在用户态不能或不易实现的功能,比如最常见的读写硬盘文件,只有操作系统有权限去访问硬件,用户程序是没有权限的,所以系统调用是供用户程序来使用的。
系统调用类似BIOS中断,不过它只需要一个入口0x80启动中断,子功能用eax寄存器来指定。可以使用man命令查看某个系统调用的用法。
调用“系统调用”有两种方式:
将系统调用指令封装在C库函数,通过库函数进行系统调用;(直接使用库函数)
不依赖任何库函数,直接通过汇编指令int 与操作系统通信。
跨过库函数,使用汇编语言:

(每次需要操作系统就int 0x80,提前在eax上写入需要操作的子功能)
汇编语言和C语言共同协作
C语言文件使用汇编语言的函数,汇编语言使用C语言中的函数。C语言使用汇编函数时,直接将函数参数按照规范压入栈中。汇编函数需要用global进行外部引用。


实现自己的打印函数
显卡的端口控制
端口实际上就是IO接口电路上的寄存器,为了能访问到这些CPU外部的寄存器(端口),计算机系统为这些寄存器统一编址,一个寄存器被赋予一个地址。寄存器的地址范围为0~65535(不是内存地址,只是寄存器编号),这些地址就是端口号,用专门的IO指令in和out来读写这些寄存器。
显卡中的寄存器
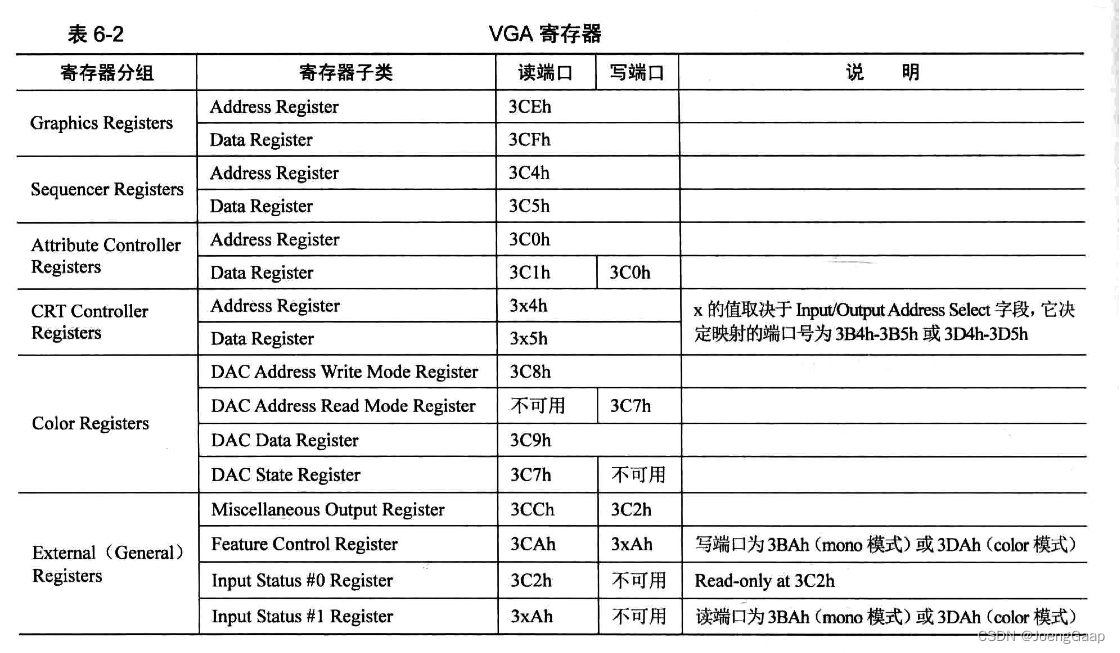
前四组寄存器属于分组,被分成了Address Register和Data Register寄存器两类。给显卡的寄存器分组是因为它的数量太多了。把一个寄存器分组视为一个寄存器数组,提供一个寄存器用于指定数组下标,再提供一个寄存器用于对索引所指向的数组元素进行输入输出操作,这样两个寄存器就能够定位寄存器数组中的任何寄存器了。(把一堆寄存器看出一个寄存器数组,只有一个端口用于输入输出,再提供一个端口用来表示索引)。这两个寄存器就是各组中的Address Register和Data Register。Address Register作为数组的索引,Data Register作为寄存器数组中该索引对应的寄存器,它相当于所对应的寄存器的窗口,往此窗口读写的数据都作用在索引所对应的寄存器上。
CRT Controller Register:


实现单个字符打印
实现字符打印(实验)
实现自己的打印函数
内联汇编
什么是内联汇编
内联汇编:在C语言中直接嵌入汇编语言,内联汇编所用的汇编语言其语法是AT&T。
汇编语言AT&T语法简介
AT&T是汇编语言的一种语法风格、格式。
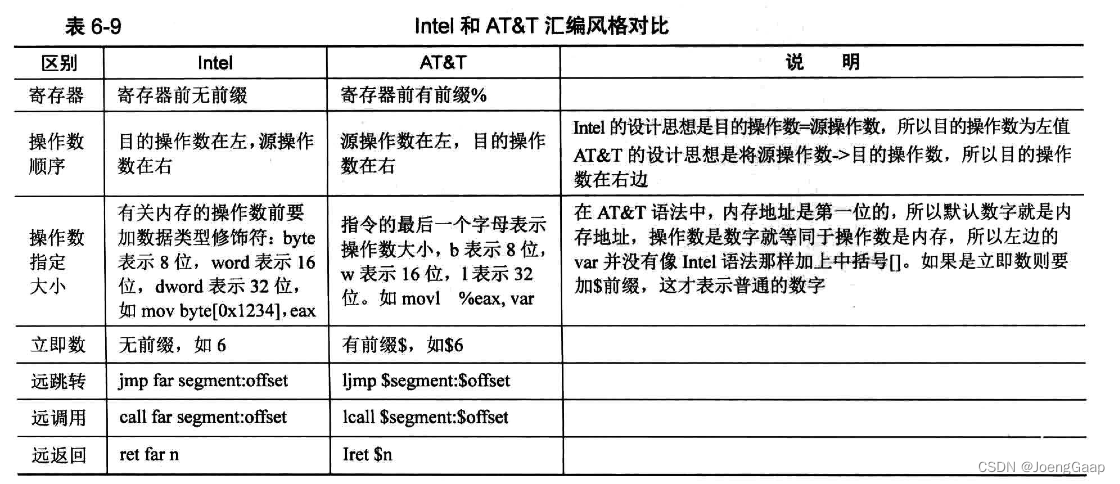
AT&T的内存寻址:


内存寻址的不同方式表达:


基本内联汇编
基本内联汇编最简单的内联形式:(也就是在C语言编程中使用汇编语言的格式)
asm [volatile] ("assembly code")
各关键字之间可以用空格或制表符分隔,也可以紧凑挨在一起不分隔。
关键词asm用于声明内联表达式,这是内联汇编固定的部分,不可少。
asm和__asm__是一样的,是由gcc定义的宏:#define __asm__asm。
因为gcc有个优化选项-O,可以指定优化级别。当用-O来编译时,gcc按照自己的意图优化代码,说不定就会把自己所写的代码修改了。关键字volatile是可选项,它告诉gcc不能修改所写代码。volatile和__volatile__是一样的,是由gcc定义的宏:#define valatile volatile。
"assembly code"是所写的汇编代码,它必须位于圆括号中,而且必须用双引号引起来。


(在内联汇编中,若要引用C变量,只能将它定义为全局变量)
扩展内联汇编

如何将C代码中的变量变成汇编代码中的操作数?
编译器采取的做法是它提供一个模板,让用户在模板中提出要求,其余工作由它负责实现。
asm [volatile] ("assembly code":output : input : clobber/modeify)
圆括号中的每一部分都可以省略,省略的部分要保留冒号分隔符来占位,如果省略的是后面的一个或多个连续部分,分隔符也不用保留。input和output是C为汇编提供输入参数和存储其输出的部分。



约束的作用是把C代码中的操作数(变量、立即数)映射为汇编中所使用的操作数,实际就是描述C中的操作数如何变成汇编操作数。


基本内联汇编和扩展内联汇编的区别:
基本内联汇编的操作数需要在汇编语言编写中手动输入,而扩展内联汇编在格式中就输入了,用约束名a为C变量指定了寄存器eax,用约束名b指定了寄存器ebx。


内存约束就是直接对当前输入变量地址操作,不需要把变量的值复制到寄存器中。





C操作数通过约束(C变量在汇编中的映射)后,在汇编中的操作数是约束所指定的那个操作数载体,即内存或寄存器,如果是寄存器约束,汇编中操作的并不是C变量本身,而是C变量通过值传递到汇编的副本。

占位符的作用是代表约束的操作数,使用占位符来引用操作数。无论哪种占位符,它都是指代C变量经过约束后、由gcc分配的对应于汇编代码中的操作数,和C变量本身无关。
占位符分为序号占位符和名称占位符。
序号占位符根据出现次序直接用%n指代操作数。
序号占位符:

占位符在默认情况下为32位数据。但指令的操作数大小并不一致,有32位,16位(默认用低16位),8位(默认用低8位)。
gcc为我们提供了改变默认操作数的机会,对于8位,可以在%和序号之间插入字符‘h’来表示操作数为ah(8-15位),或者插入字符’b’来表示操作数为al(0-7位)。
名称占位符:

操作数类型修饰符,用来修饰所约束的操作数:内存、寄存器,分别在output和input中有以下几种。

扩展内联汇编之机器模式简介
机器模式用来在机器层面上指定数据的大小及格式。由于各种约束均不能确切地表达具体的操作数对象,所以引用了机器模式,用来从更细的粒度上描述数据对象的大小及其指定部分。
机器模式名称的结构:数据大小+数据类型+mode。