Zookeeper
- 1、工作中 Zookeeper 有什么用途吗
- 2、zookeeper 数据模型是什么样的
- 3、那你知道 znode 有几种类型呢
- 4、你知道 znode 节点里面存储什么吗
- 5、每个节点数据最大不能超过多少呢
- 6、你知道 znode 节点上监听机制嘛
- 7、那你讲下 Zookeeper 特性吧
- 8、你刚提到顺序一致性,那 zookeeper 如何保证事务顺序一致性呢
- 9、你知道 Zookeeper 服务器有几种角色嘛
- 10、Zookeeper 下 Server 工作状态又有几种
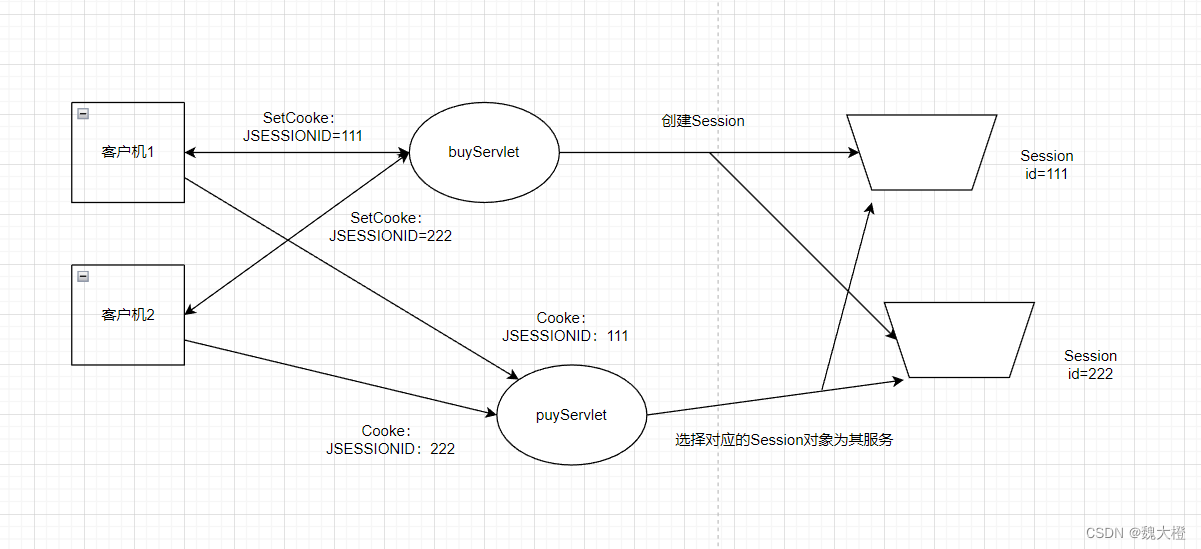
- 11、ZooKeeper 集群部署图
- 12、ZooKeeper 如何保证主从节点数据一致性
- 13、你讲一下 ZooKeeper 选举机制吧
- 14、讲一下 zk 分布式锁实现原理吧
- 15、ZooKeeper 集群为啥最好奇数台
1、工作中 Zookeeper 有什么用途吗
- 注册中心
- 什么是注册中心
- 注册中心是只有在分布式架构中才有的概念,注册中心是分布式架构中所有服务器注册信息等相关功能的专用服务器,注册的地址是服务器的名称与对应IP地址。分布式环境下的应用在启动时候都会向这个地方来注册自己的网络地址和名称。用一句话来概括,注册中心的作用就是存放和调度服务,实现服务和注册中心,服务与服务之间的通信。
- 在分布式架构中,服务会注册到注册中心,应用 a 访问应用 b 时,则应用 a 首先通过应用 b 的应用名称向注册中心获取最新的 ip 地址,再根据 ip 地址访问应用 b。
- 为什么需要注册中心
- ① 在不用服务注册之前,去维护这种关系网络呢就是写死 IP 地址。将其他模块的 ip 和 port 写死在自己的配置文件里,甚至写死在代码里,每次要去新增或者移除1个服务的实例的时候,就得去通知其他所有相关联的服务去修改。随之而来的就是各个项目的配置文件的反复更新、每隔一段时间大规模的 ip 修改和机器裁撤,非常的痛苦。
- ② 有了注册中心之后,每个服务在调用别人的时候只需要服务的名称就好,调用时会通过注册中心根据服务编码进行具体服务地址进行调用。
- 什么是注册中心
- 分布式锁
- 分布式锁的实现方式有很多种,比如 Redis 、数据库 、zookeeper 等。个人认为 zookeeper 在实现分布式锁这方面是非常非常简单的。
- 命名服务
- 命名服务指通过指定名字来获取资源或者服务地址。Zookeeper 可以创一个全局唯一路径,这个路径就可以作为一个名字。被命名实体可以集群中机器,服务地址,或者远程对象等。
- 集群管理
- 集群管理包括集群监控和集群控制,其实就监控集群机器状态,剔除机器和加入机器。zookeeper 可以方便集群机器管理,它可以实时监控 znode 节点变化,一旦发现有机器挂了,该机器就会与 zk 断开连接,对用临时目录节点会被删除,其他所有机器都收到通知。
2、zookeeper 数据模型是什么样的
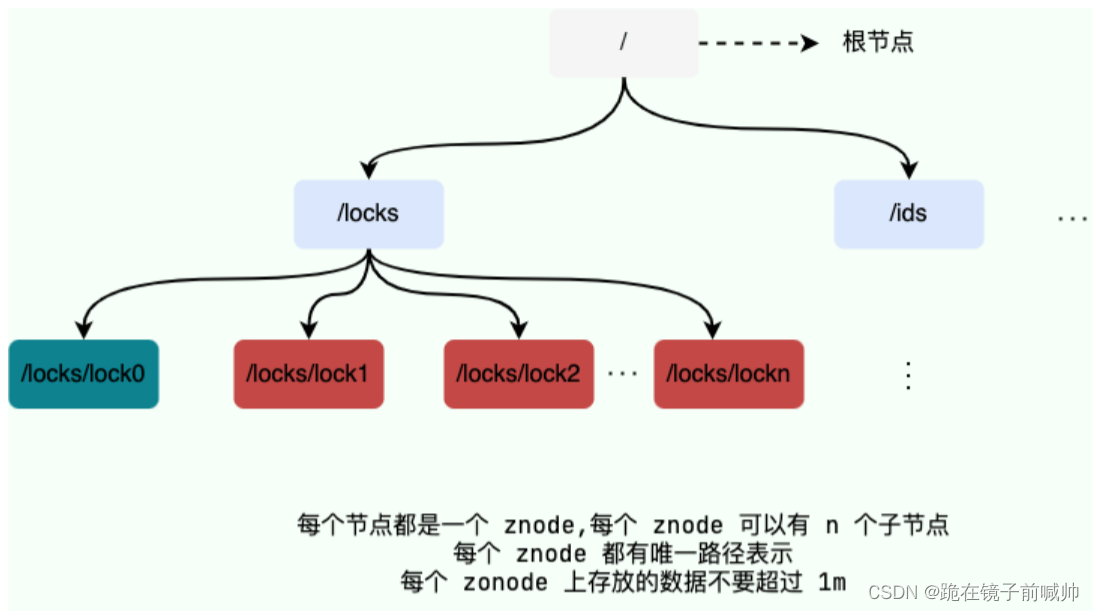
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都一个唯一的路径标识。
从下图可以更直观地看出:ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
3、那你知道 znode 有几种类型呢
我们通常是将 znode 分为 4 大类:
- 持久(PERSISTENT)节点 :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
- 临时(EPHEMERAL)节点 :临时节点的生命周期是与 客户端会话(session) 绑定的,会话消失则节点消失 。并且,临时节点只能做叶子节点 ,不能创建子节点。
- 持久顺序(PERSISTENT_SEQUENTIAL)节点 :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 /node1/app0000000001 、/node1/app0000000002 。
- 临时顺序(EPHEMERAL_SEQUENTIAL)节点 :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
4、你知道 znode 节点里面存储什么吗
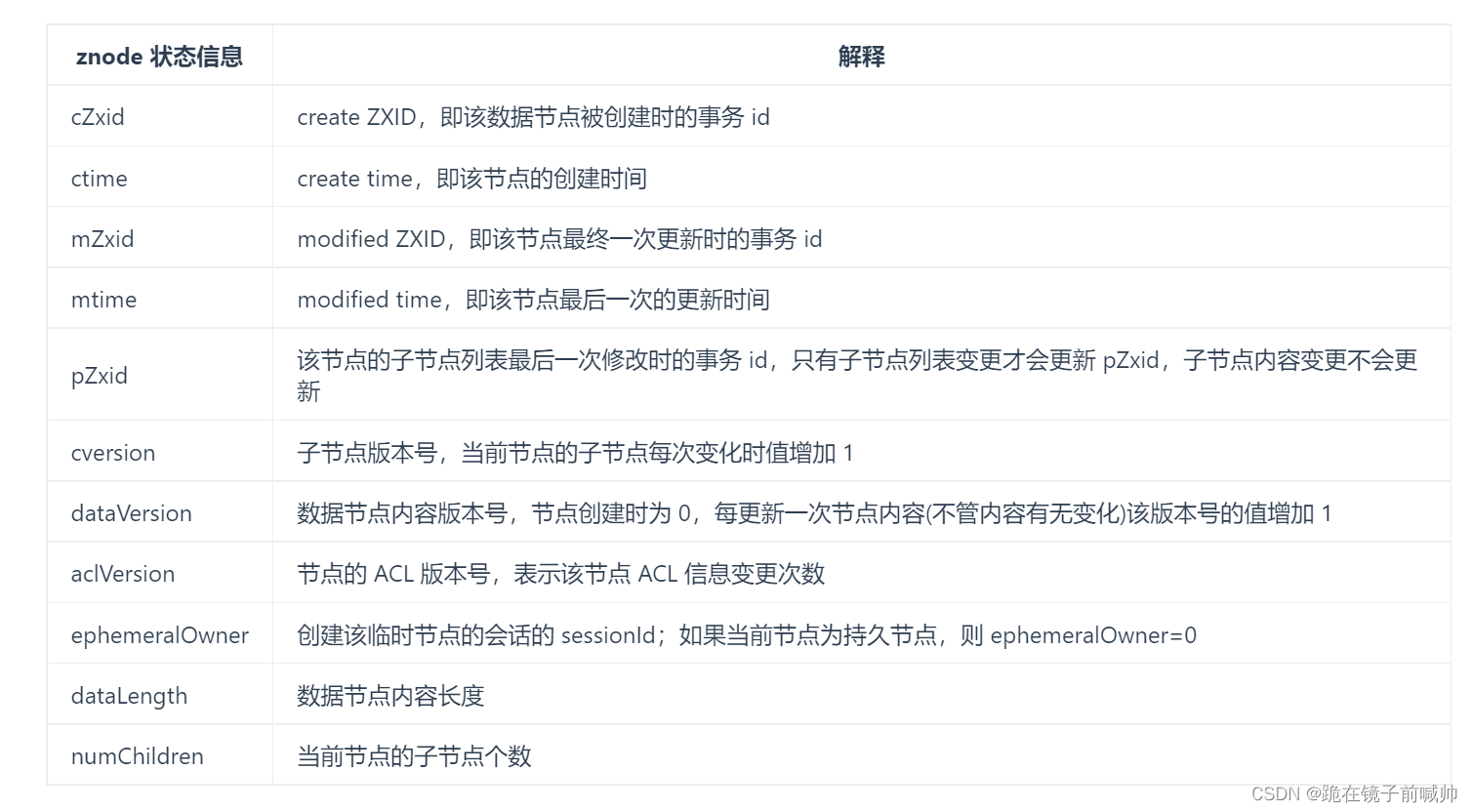
- stat :状态信息。
Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务 ID(cZxid)、节点创建时间(ctime) 和子节点个数(numChildren) 等等,如下:
- data : znode 存储业务数据信息。
- acl : 记录客户端对 znode 节点访问权限,如 IP 等。
- ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
- CREATE : 能创建子节点
- READ :能获取节点数据和列出其子节点
- WRITE : 能设置/更新节点数据
- DELETE : 能删除子节点
- ADMIN : 能设置节点 ACL 的权限
- 其中尤其需要注意的是,CREATE 和 DELETE 这两种权限都是针对 子节点 的权限控制。对于身份认证,提供了以下几种方式:
- world : 默认方式,所有用户都可无条件访问。
- auth :不使用任何 id,代表任何已认证的用户。
- digest :用户名:密码认证方式: username:password 。
- ip : 对指定 ip 进行限制
- ZooKeeper 采用 ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
- child : 当前节点子节点引用。
5、每个节点数据最大不能超过多少呢
为了保证高吞吐和低延迟,以及数据一致性,znode 只适合存储非常小数据,不能超过 1M,最好都小于 1K。
6、你知道 znode 节点上监听机制嘛
Watcher 为事件监听器,是 zk 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端注册指定的 watcher ,当服务端符合了 watcher 的某些事件或要求则会向客户端发送事件通知 ,客户端收到通知后找到自己定义的 Watcher 然后执行相应的回调方法 。

可以把 Watcher 理解成客户端注册在某个 Znode 上触发器,当这个 Znode 节点发生变化时(增删改查),就会触发 Znode 对应注册事件,注册客户端就会收到异步通知,然后做出业务改变。
zookeeper 监听原理
zookeeper的监听事件有四种
- nodedatachanged 节点数据改变
- nodecreate 节点创建事件
- nodedelete 节点删除事件
- nodechildrenchanged 子节点改变事件
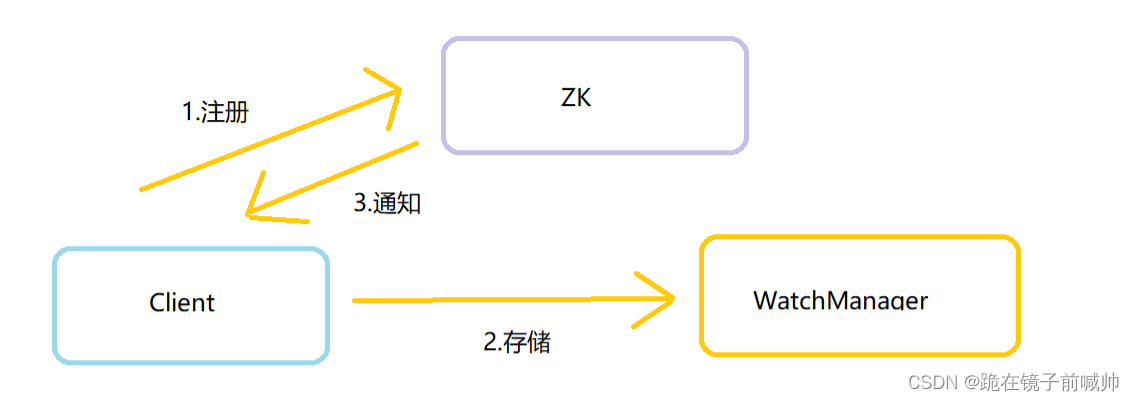
ZooKeeper Watcher 机制主要包括客户端线程、客户端WatcherManager、Zookeeper 服务器三部分。
- 客户端向 ZooKeeper 服务器注册 Watcher 同时,会将 Watcher 对象存储在客户端 WatchManager 中。
- 当 zookeeper 服务器触发 watcher 事件后,会向客户端发送通知, 客户端线程从 WatcherManager 中取出对应Watcher 对象来执行回调逻辑。
7、那你讲下 Zookeeper 特性吧
- 全局数据一致:集群中每个服务器保存一份相同的数据副本,client无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征。
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
- 数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态。
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
8、你刚提到顺序一致性,那 zookeeper 如何保证事务顺序一致性呢
9、你知道 Zookeeper 服务器有几种角色嘛
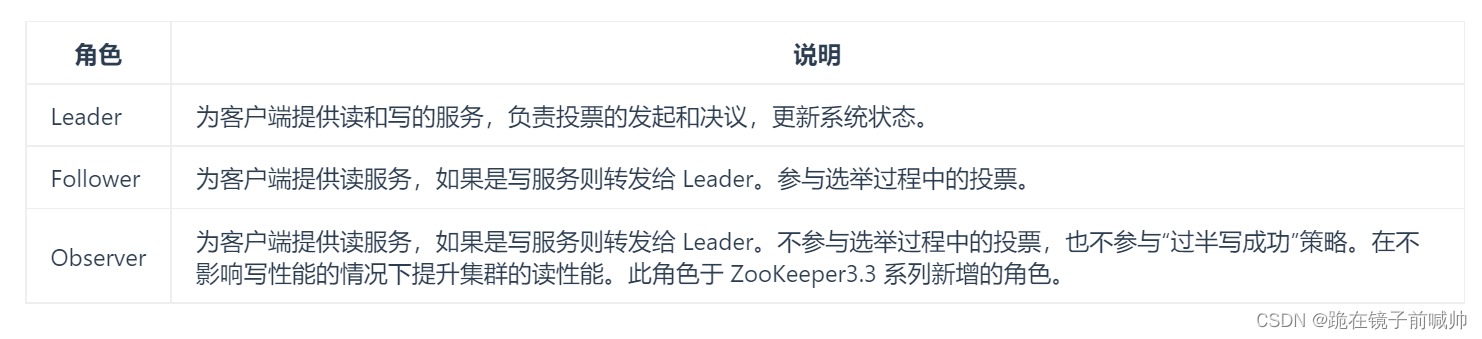
10、Zookeeper 下 Server 工作状态又有几种
- LOOKING:寻找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态。
- FOLLOWING:跟随者状态。表明当前服务器角色✁ Follower。
- LEADING:领导者状态。表明当前服务器角色✁ Leader。
- OBSERVING:观察者状态。表明当前服务器角色✁ Observer。
11、ZooKeeper 集群部署图
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构图就是一个 ZooKeeper 集群整体对外提供服务。
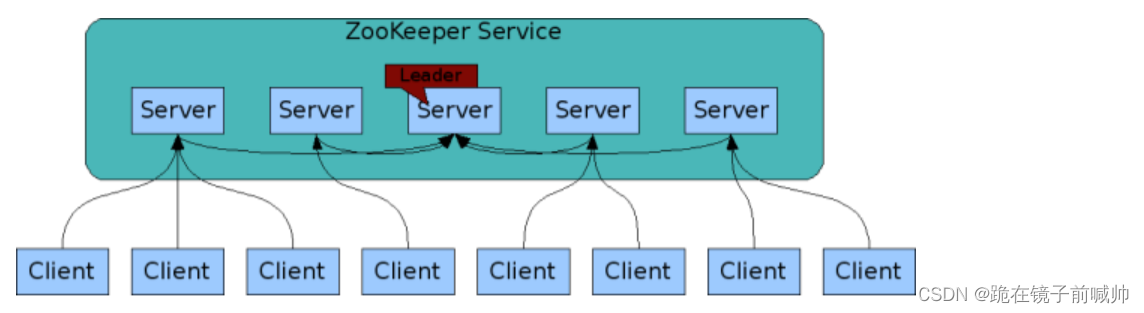
上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
最典型集群模式: Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
12、ZooKeeper 如何保证主从节点数据一致性
ZooKeeper 主要提供数据的一致性服务,其实现分布式系统的状态一致性依赖一个叫 Paxos 的算法。Paxos 算法在多台服务器通过内部的投票表决机制决定一个数据的更新与写入。
但Paxos 算法有点过于复杂、实现难度也比较高,所以 ZooKeeper 在编程实现的时候将其简化成了一种叫做 ZAB 的算法(Zookeeper Atomic Broadcast, Zookeeper 原子广播)。
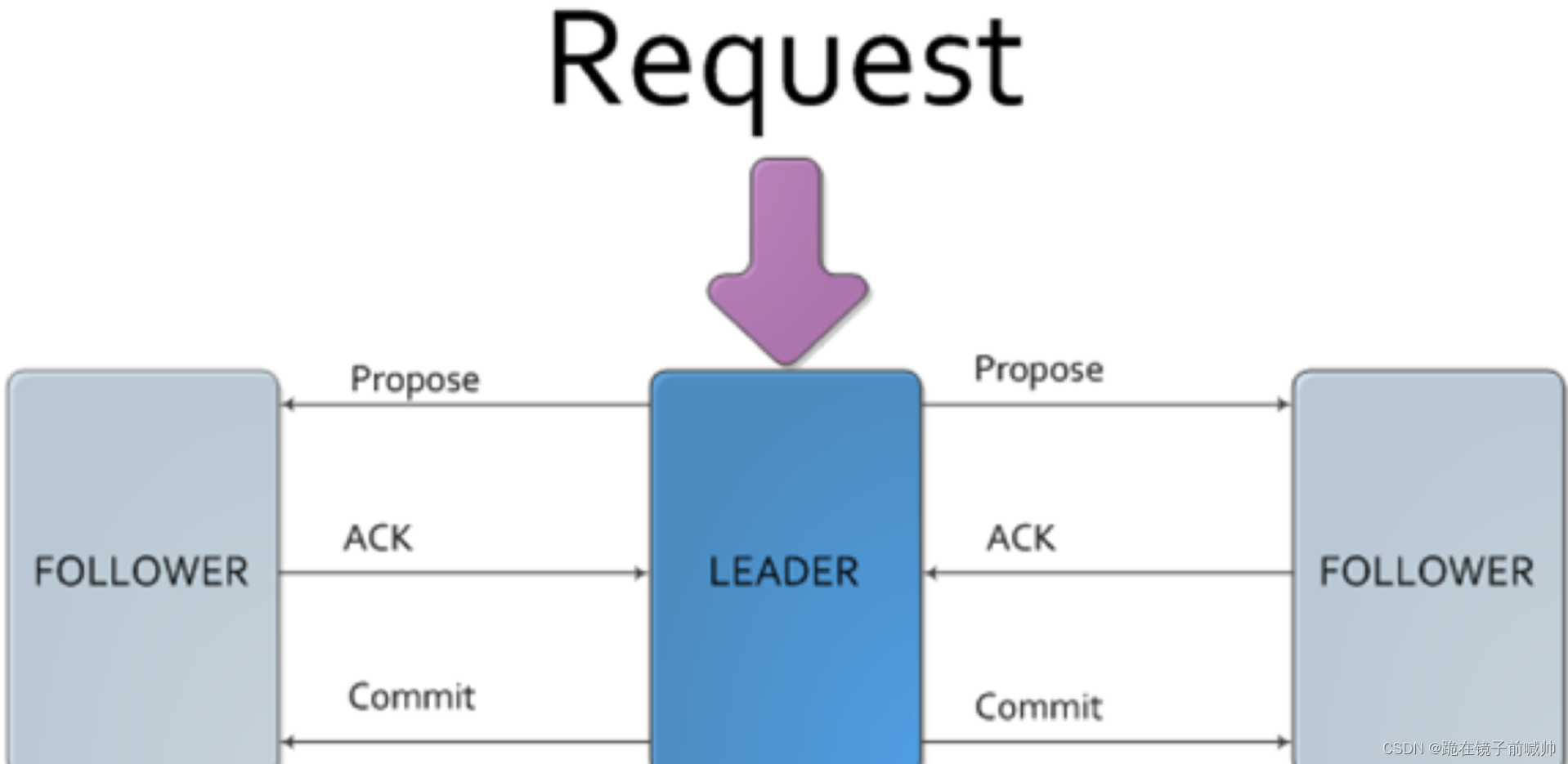
ZAB 算法的目的,同样是在多台服务器之间达成一致,保证这些服务器上存储的数据是一致的。ZAB 算法的主要特点在于:需要在这些服务器中选举一个 Leader,所有的写请求都必须提交给 Leader。由 Leader 服务器向其他服务器(Follower)发起 Propose,通知所有服务器:我们要完成一个写操作请求,大家检查自己的数据状态,是否有问题。
如果所有 Follower 服务器都回复 Leader 服务器 ACK,即没有问题,那么 Leader 服务器会向所有 Follower 发送 Commit 命令,要求所有服务器完成写操作。这样包括 Leader 服务器在内的所有 ZooKeeper 集群服务器的数据,就都更新并保持一致了。如果有两个客户端程序同时请求修改同一个数据,因为必须要经过 Leader 的审核,而 Leader 只接受其中一个请求,数据也会保持一致。
在实际应用中,客户端程序可以连接任意一个 Follower,进行数据读写操作。如果是写操作,那么这个请求会被这个 Follower 发送给 Leader,进行如上所述的处理;如果是读操作,因为所有服务器的数据都是一致的,那么这个 Follower 直接返回自己本地的数据给客户端就可以了。
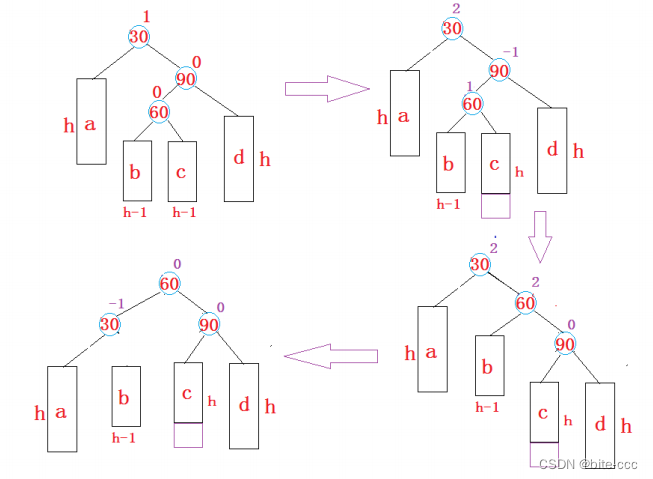
13、你讲一下 ZooKeeper 选举机制吧
服务器启动或者服务器运行期间(Leader 挂了),都会进入 Leader 选举,我们来看一下~假设现在 ZooKeeper 集群有五台服务器。
服务器启动 Leader 选举
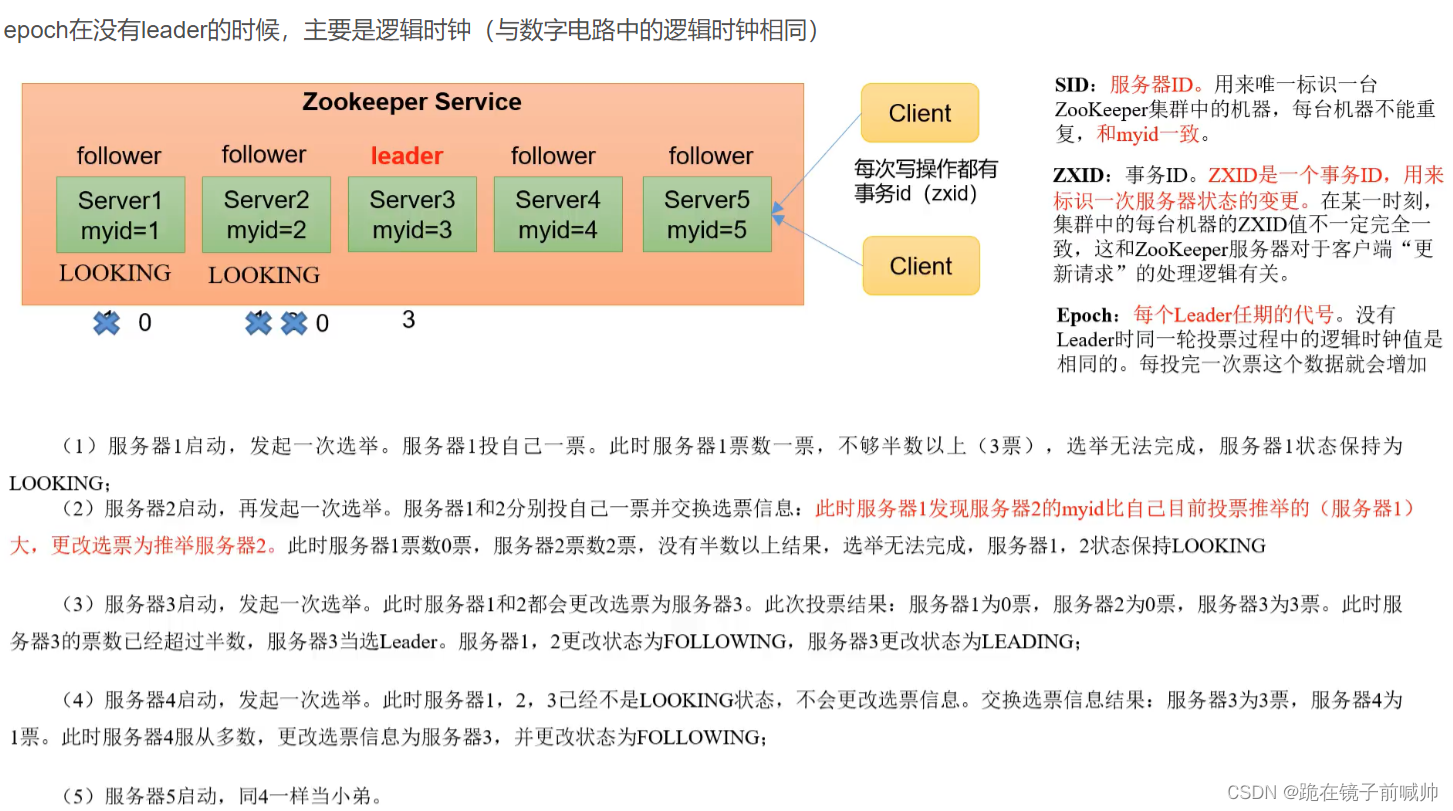
服务器运行期间 Leader 选举
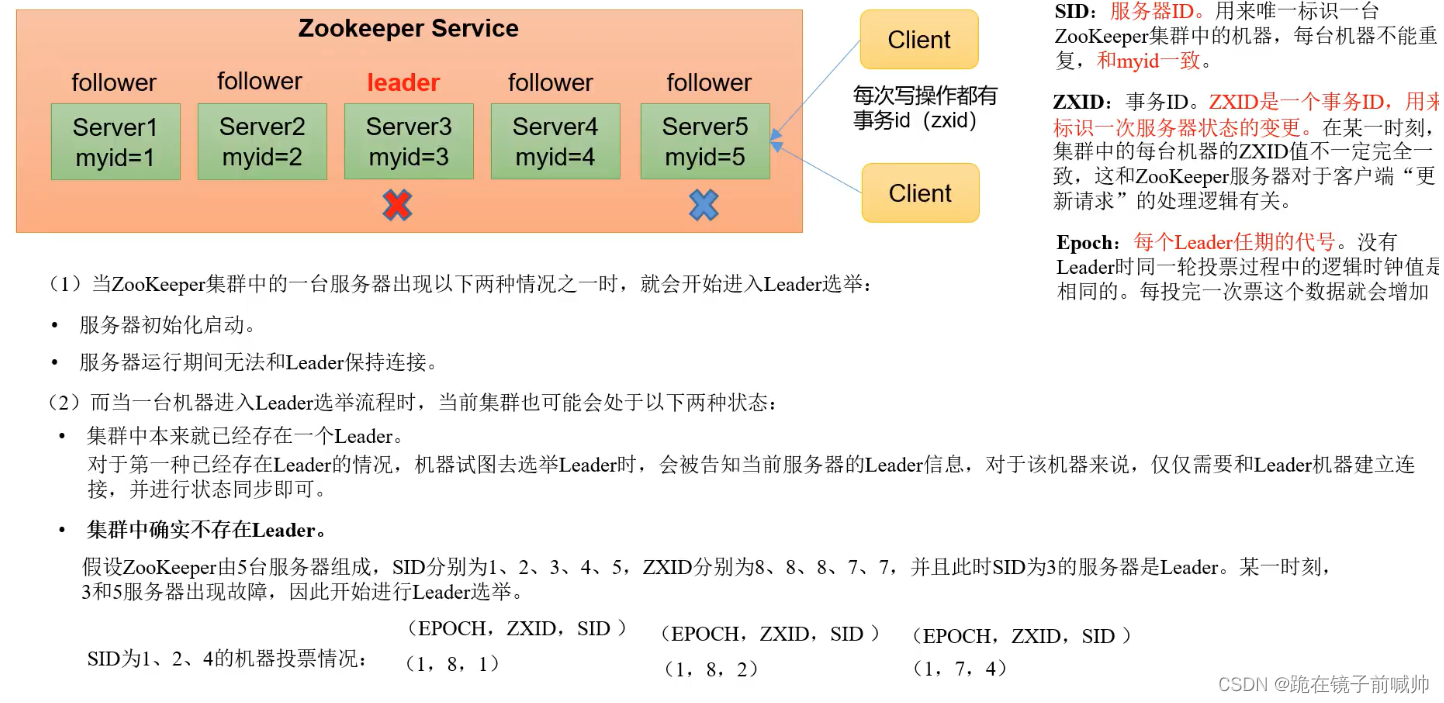
选举Leader规则:①EPOCH大的直接胜出 ②EPOCH相同,事务id大的胜出 ③事务id相同,服务器id大的胜出
总结:择优选取,保证leader是zk集群中数据最完整、最可靠的一台服务器。
14、讲一下 zk 分布式锁实现原理吧
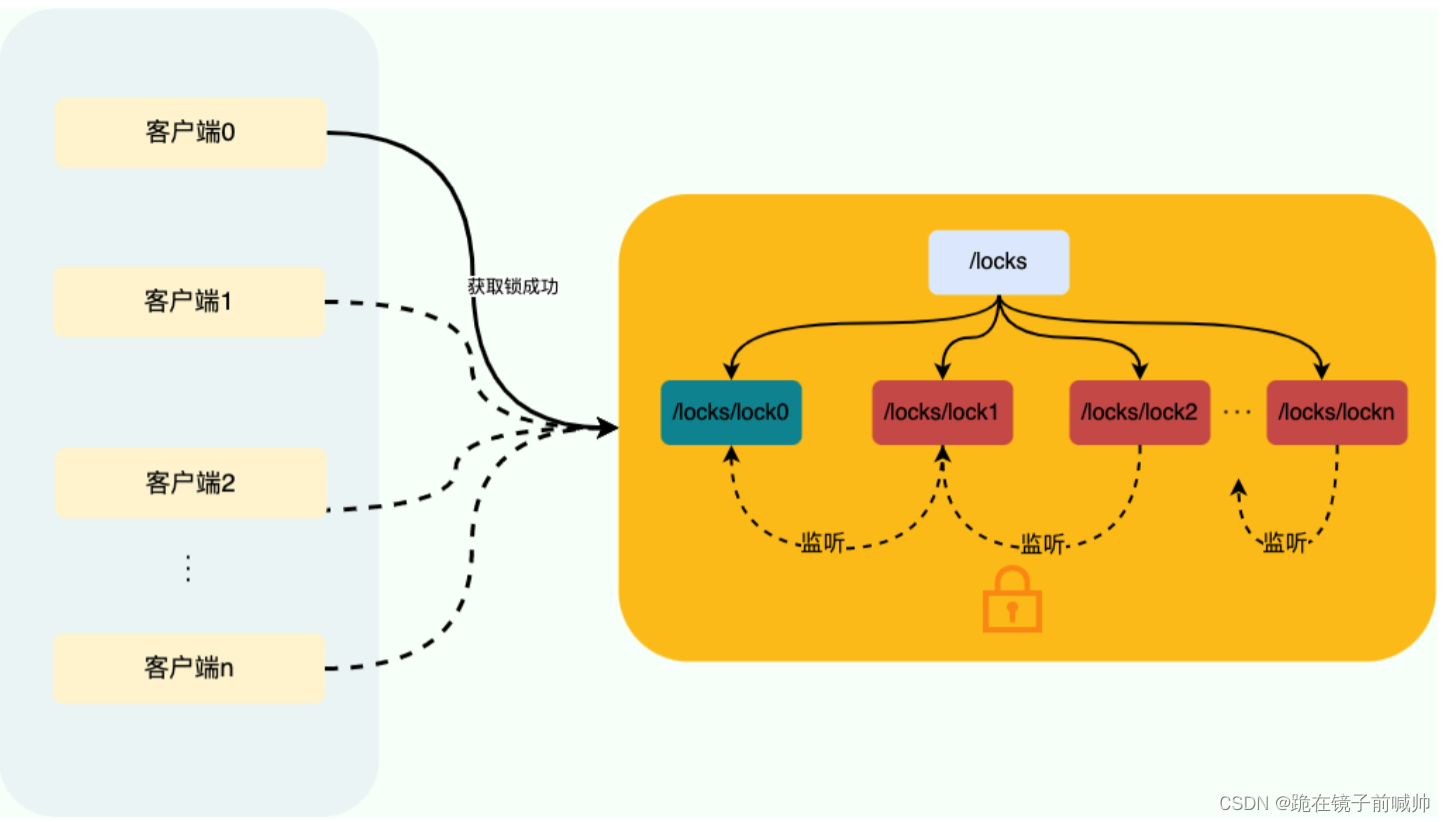
ZooKeeper 分布式锁是基于临时顺序节点和Watcher(事件监听器) 实现的。
获取锁:
- 首先我们要有一个持久节点/locks,客户端获取锁就是在locks下创建临时顺序节点。
- 假设客户端 1 创建了/locks/lock1节点,创建成功之后,会判断 lock1是否是 /locks 下最小的子节点。
- 如果 lock1是最小的子节点,则获取锁成功。否则,获取锁失败。
- 如果获取锁失败,则说明有其他的客户端已经成功获取锁。客户端 1 并不会不停地循环去尝试加锁,而是在前一个节点比如/locks/lock0上注册一个事件监听器。这个监听器的作用是当前一个节点释放锁之后通知客户端 1(避免无效自旋),这样客户端 1 就加锁成功了。
释放锁:
- 成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
- 成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
- 我们前面说的事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
分布式锁
package com.example.canal.zk;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributedLock {
private final String connectionString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
private final int sessionTimeout = 2000;
private final ZooKeeper zk;
private CountDownLatch countDownLatch = new CountDownLatch(1);
private CountDownLatch waitLatch = new CountDownLatch(1);
private String waitPath;
private String currentMode;
public DistributedLock() throws IOException, InterruptedException, KeeperException {
// 获取连接
zk = new ZooKeeper(connectionString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// connectLatch 如果连接上zk 可以释放
if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {
countDownLatch.countDown();
}
// waitLatch 需要释放
if (watchedEvent.getType() == Event.EventType.NodeDeleted && watchedEvent.getPath().equals(waitPath)) {
waitLatch.countDown();
}
}
});
// 等待zk正常连接后,往下走程序
countDownLatch.await();
// 判断根节点/locks是否存在
Stat stat = zk.exists("/locks", false);
if (stat == null) {
// 创建根节点,这是⼀个完全开放的ACL,持久节点
zk.create("/locks", "locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
// 对zk加锁
public void zkLock() {
try {
// 创建对应的临时顺序节点
currentMode =
zk.create("/locks/" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 判断创建的节点是否是序号最小的节点,如果是获取到锁,如果不是,监听他序号前一个节点
List<String> children = zk.getChildren("/locks", false);
if (children.size() == 1) {
return;
} else {
//[seq-0000000016, seq-0000000017]
Collections.sort(children);
// 获取节点名称 /locks/seq-0000000017 -> seq-0000000017
String thisNode = currentMode.substring("/locks/".length());
// 通过seq-0000000017获取该节点在children集合的位置
int index = children.indexOf(thisNode);
// 判断
if (index == -1) {
System.out.println("数据异常");
} else if (index == 0) {
// 就一个节点,可以获取锁了
return;
} else {
// 需要监听 他前一个结点的变化
waitPath = "/locks/" + children.get(index - 1);
zk.getData(waitPath, true, null);
// 等待监听
waitLatch.await();
}
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 解锁
public void unZkLock() {
// 删除节点
try {
zk.delete(currentMode, -1);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}
测试类
package com.example.canal.zk;
import org.apache.zookeeper.KeeperException;
import java.io.IOException;
public class DistributedLockTest {
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
final DistributedLock lock1 = new DistributedLock();
final DistributedLock lock2 = new DistributedLock();
new Thread(new Runnable() {
@Override
public void run() {
try {
lock1.zkLock();
System.out.println("线程1 启动,获取到锁");
Thread.sleep(5 * 1000);
lock1.unZkLock();
System.out.println("线程1 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
lock2.zkLock();
System.out.println("线程2 启动,获取到锁");
Thread.sleep(5 * 1000);
lock2.unZkLock();
System.out.println("线程2 释放锁");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
为什么要用临时顺序节点
临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,临时节点会话消失则对应的节点消失。这样的话,如果客户端发生异常导致没来得及释放锁也没关系,会话失效节点自动被删除,不会发生死锁的问题。
使用 Redis 实现分布式锁的时候,我们是通过过期时间来避免锁无法被释放导致死锁问题的,而 ZooKeeper 直接利用临时节点的特性即可。
假设不适用顺序节点的话,所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好。
为什么要设置对前一个节点的监听
同一时间段内,可能会有很多客户端同时获取锁,但只有一个可以获取成功。如果获取锁失败,则说明有其他的客户端已经成功获取锁。获取锁失败的客户端并不会不停地循环去尝试加锁,而是在前一个节点注册一个事件监听器。
这个事件监听器的作用是: 当前一个节点对应的客户端释放锁之后(也就是前一个节点被删除之后,监听的是删除事件),通知获取锁失败的客户端(唤醒等待的线程,Java 中的 wait/notifyAll ),让它尝试去获取锁,然后就成功获取锁了。
15、ZooKeeper 集群为啥最好奇数台
ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。 假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
综上,何必增加那一个不必要的 ZooKeeper 呢?