文章目录
- 🌷 1. root 用户登录
- 🌷 2. 数据库的操作
- 🌷 3. 常用数据类型
- 🌷 4. 表的操作
- ⭐ 4.1 创建表
- 🍁 约束类型
- ⭐ 4.2 插入
- ⭐ 4.3 查询
- 🍁 去重:DISTINCT
- 🍁 排序:ORDER BY
- 🍁 条件查询:WHERE
- 🍁 分页查询:LIMIT
- 🍁 聚合函数
- 🍁 GROUP BY子句
- 🍁 HAVING
- 🍁 内连接
- 🍁 外连接
- 🍁 自连接
- 🍁 子查询
- 🍁 合并查询
- ⭐ 4.4 修改
- ⭐ 4.5 删除
- 🌷 5. 索引
- 🌷 6. 事务
🌷 1. root 用户登录
- root 用户登录
mysql -u root -p
- 使用mysql数据库
use mysql;
- 更新用户表的root账户,设置为任意ip都可以访问,密码修改为123456
update user set host="%",authentication_string=password('root') where user="root";
- 刷新权限
flush privileges;
- 退出
quit;
🌷 2. 数据库的操作
- 显示当前的数据库
SHOW DATABASES;
- 创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name CHARACTER SET utf8mb4;
MYSQL中允许用户使用关键字做为数据库名,但是需要用反引号把关键字引起来
- 查看数据库字符集
show variables like '%character%';
- 使用数据库
use 数据库名;
- 查看下当前使用的是哪个数据库:
select database();
- 删除数据库
DROP DATABASE [IF EXISTS] db_name;
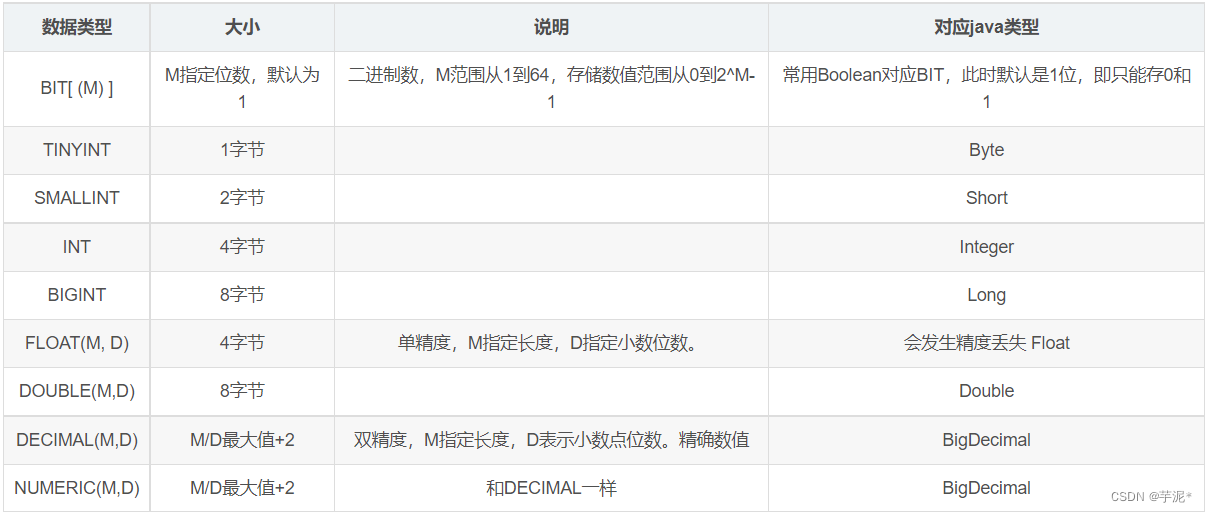
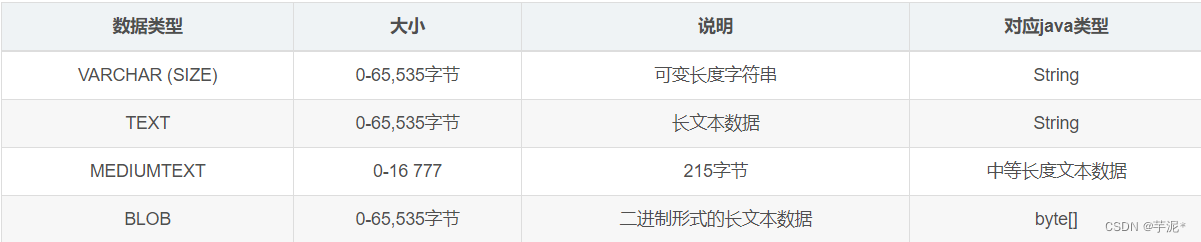
🌷 3. 常用数据类型

🌷 4. 表的操作
- 查看表结构
desc 表名;
⭐ 4.1 创建表
CREATE TABLE table_name (`
`field1 datatype,`
`field2 datatype,`
`field3 datatype);`
-- 可以使用comment增加字段说明
🍁 约束类型
NOT NULL -- 指示某列不能存储 NULL 值。
UNIQUE -- 保证某列的每行必须有唯一的值。
DEFAULT -- 规定没有给列赋值时的默认值。
PRIMARY KEY -- NOT NULL 和 UNIQUE的结合。确保某列(或两个列多个列的结合)有唯一标识,
auto_increment--对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
FOREIGN KEY -- 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK -- 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
- 外键使用语法:
foreign key (字段名) references 主表(列)
案例:
-- 设置学生表结构
create table student (
id int primary key auto_increment,
sn int unique comment '学号',
sex varchar(1),
check (sex ='男' or sex='女'),
name varchar(255) default 'unkown',
qq_mail VARCHAR(20),
classes_id int not null,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
⭐ 4.2 插入
INSERT [INTO] table_name [(column [, column] ...)]
VALUES(value_list) [, (value_list)] ...
案例:
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO student VALUES (100, 10000, '唐三藏', NULL);
INSERT INTO student VALUES (101, 10001, '孙悟空', '11111');
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO student (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
从另一张表中复制:
-- 将学生表中的所有数据复制到用户表
insert test_user(name,email) select name,qq_mail from student;
⭐ 4.3 查询
MYSQL语句的执行顺序:from -> where -> select -> group by
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
案例:
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。
SELECT * FROM exam;
-- 指定列的顺序不需要按定义表的顺序来
SELECT id, name, english FROM exam;
-- 表达式不包含字段
SELECT id, name, 10 FROM exam;
-- 表达式包含一个字段
SELECT id, name, english + 10 FROM exam;
-- 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam;
-- 结果集中,表头的列名=别名
SELECT id, name, chinese + math + english 总分 FROM exam;
🍁 去重:DISTINCT
-- 去重结果
SELECT DISTINCT math FROM exam;
🍁 排序:ORDER BY
– ASC 为升序(从小到大)
– DESC 为降序(从大到小)
默认为 ASC
--查询同学姓名和 qq_mail,按 qq_mail 排序显示
SELECT name, qq_mail FROM student ORDER BY qq_mail;
SELECT name, qq_mail FROM student ORDER BY qq_mail DESC;
🍁 条件查询:WHERE
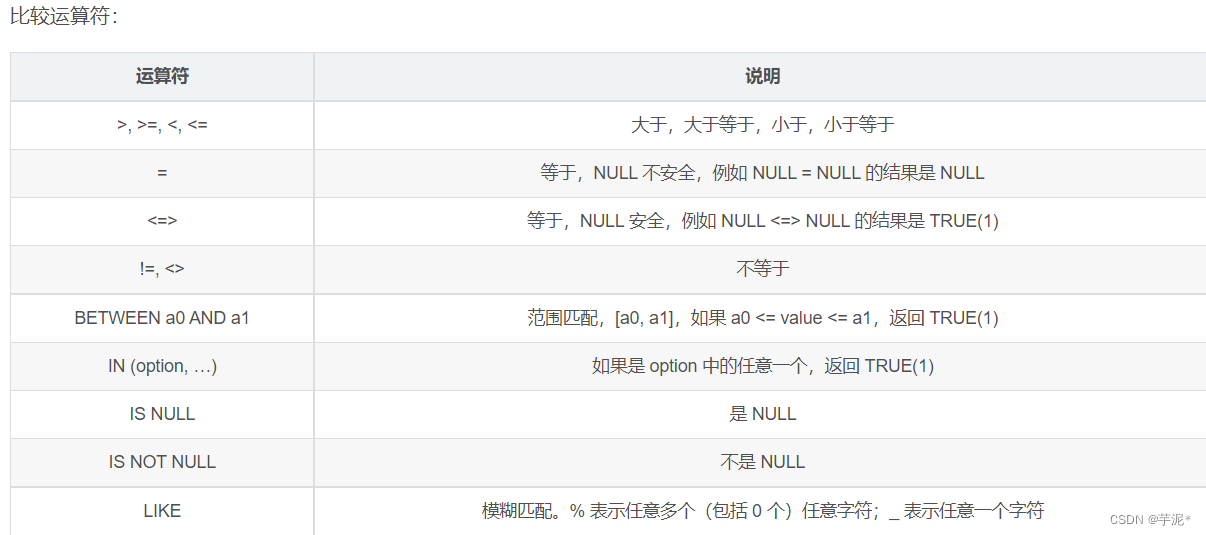
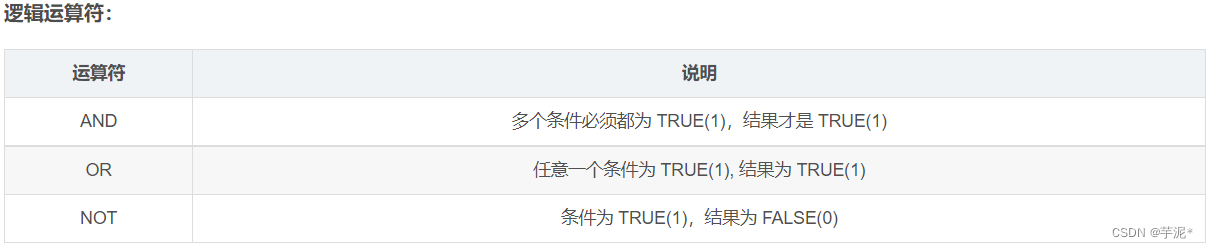
案例:
-- 查询语文成绩在 [80, 90] 分的同学及语文成绩
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
-- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
-- % 匹配任意多个(包括 0 个)字符
SELECT name FROM exam_result WHERE name LIKE '孙%';-- 匹配到孙悟空、孙权
-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到孙权
查询 qq_mail 已知的同学姓名
SELECT name, qq_mail FROM student WHERE qq_mail IS NOT NULL;
🍁 分页查询:LIMIT
– 起始下标为 0
– 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
– 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
– 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
案例:
-- 第 1 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3 OFFSET 0;
-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3 OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3 OFFSET 6;
🍁 聚合函数
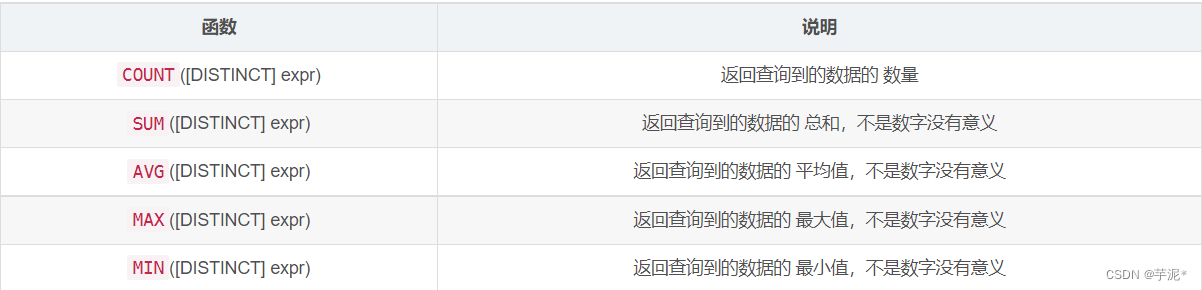
案例:
-- 统计班级共有多少同学
select count(*)from student;
-- 统计班级收集的 qq_mail 有多少个,qq_mail 为 NULL 的数据不会计入结果
select count(qq_mail) from student where qq_mail != null;
-- 统计数学成绩总分
select sum(math) from exam;
-- 不及格同学的数学成绩,没有结果,返回 NULL
select sum(math) from exam where math < 60;
-- 统计平均总分
select avg(chinese + math + english) from exam;
-- 返回英语最高分
select max(english) from exam;
-- 返回 > 70 分以上的数学最低分
select min(math) from exam where math > 70;
🍁 GROUP BY子句
select column1, sum(column2), .. from table group by column1;
按group by 中的字段分组查询
-- 查询每个角色的最高工资、最低工资和平均工资:
select role,max(salary),min(salary),avg(salary) from emp group by role;
🍁 HAVING
--显示平均工资低于1500的角色和它的平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role having avg(salary) < 1500;
select role,avg(salary) from emp where salary < 1500 group by role;
🍁 内连接
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
案例:
select sco.score from student stu inner join score sco on stu.id=sco.student_id
and stu.name='许仙';
-- 或者
select sco.score from student stu, score sco where stu.id=sco.student_id and
stu.name='许仙';
🍁 外连接
– 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
– 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
-- “老外学中文”同学 没有考试成绩,也显示出来了
select * from student stu left join score sco on stu.id=sco.student_id;
-- 对应的右外连接为:
select * from score sco right join student stu on stu.id=sco.student_id;
🍁 自连接
自连接是指在同一张表连接自身进行查询。
案例:
-- 显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
SELECT s1.* FROM score s1,score s2
WHERE
s1.student_id = s2.student_id
AND s1.score < s2.score
AND s1.course_id = 1
AND s2.course_id = 3;
🍁 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
案例:查询“语文”或“英文”课程的成绩信息
- [NOT] IN关键字
-- 使用IN
select * from score where course_id in (select id from course where
name='语文' or name='英文');
-- 使用 NOT IN
select * from score where course_id not in (select id from course where
name!='语文' and name!='英文');
- [NOT] EXISTS关键字
-- 使用 EXISTS
select * from score sco where exists (select sco.id from course cou
where (name='语文' or name='英文') and cou.id = sco.course_id);
-- 使用 NOT EXISTS
select * from score sco where not exists (select sco.id from course cou
where (name!='语文' and name!='英文') and cou.id = sco.course_id);
🍁 合并查询
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
案例:查询id小于3,或者名字为“英文”的课程:
select * from course where id < 3
union
select * from course where name='英文';
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
案例:查询id小于3,或者名字为“Java”的课程
- 可以看到结果集中出现重复数据Java
select * from course where id<3
union all
select * from course where name='英文';
⭐ 4.4 修改
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...]
[ORDER BY ...] [LIMIT ...]
案例:
-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
-- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT 3;
-- 将所有同学的语文成绩更新为原来的 2 倍
UPDATE exam_result SET chinese = chinese * 2;
⭐ 4.5 删除
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
-- 删除孙悟空同学的考试成绩
DELETE FROM exam_result WHERE name = '孙悟空';
-- 删除整表数据
DELETE FROM for_delete;
🌷 5. 索引
- 查看索引
show index from 表名;
- 创建索引
create index 索引名 on 表名(字段名);
create index 索引名 on 表名(字段名1,字段名2...);
- 删除索引
drop index 索引名 on 表名;
🌷 6. 事务
- 使用
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
- 查看当前事务的隔离级别
show variables like '%tx_isolation';
- 修改事务的隔离级别
set @@global.tx_isolation = 'READ-UNCOMMITTED'; //全局
set @@session.tx_isolation = 'READ-UNCOMMITTED'; //当前session
set @@tx_isolation = 'READ-UNCOMMITTED'; //仅对下⼀个事务⽣效