Python+大数据-Spark技术栈(三) SparkCore加强
- 重点:RDD的持久化和Checkpoint
- 提高拓展知识:Spark内核调度全流程,Spark的Shuffle
- 练习:热力图统计及电商基础指标统计
- combineByKey作为面试部分重点,可以作为扩展知识点
Spark算子补充
-
关联函数补充
-
join为主基础算子
-
# -*- coding: utf-8 -*- # Program function:演示join操作 from pyspark import SparkConf, SparkContext if __name__ == '__main__': print('PySpark join Function Program') # TODO:1、创建应用程序入口SparkContext实例对象 conf = SparkConf().setAppName("miniProject").setMaster("local[*]") sc = SparkContext.getOrCreate(conf) # TODO: 2、从本地文件系统创建RDD数据集 x = sc.parallelize([(1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhangliu")]) y = sc.parallelize([(1001, "sales"), (1002, "tech")]) # TODO:3、使用join完成联合操作 print(x.join(y).collect()) # [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))] print(x.leftOuterJoin(y).collect()) print(x.rightOuterJoin(y).collect()) # [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))] sc.stop()
[掌握]RDD 持久化
为什么使用缓存
- 缓存可以加速计算,比如在wordcount操作的时候对reduceByKey算子进行cache的缓存操作,这时候后续的操作直接基于缓存后续的计算
- 缓存可以解决容错问题,因为RDD是基于依赖链的Dependency
- 使用经验:一次缓存可以多次使用
如何进行缓存?
-
spark中提供cache方法
-
spark中提供persist方法
-
# -*- coding: utf-8 -*- # Program function:演示join操作 from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel import time if __name__ == '__main__': print('PySpark join Function Program') # TODO:1、创建应用程序入口SparkContext实例对象 conf = SparkConf().setAppName("miniProject").setMaster("local[*]") sc = SparkContext.getOrCreate(conf) # TODO: 2、从本地文件系统创建RDD数据集 x = sc.parallelize([(1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhangliu")]) y = sc.parallelize([(1001, "sales"), (1002, "tech")]) # TODO:3、使用join完成联合操作 join_result_rdd = x.join(y) print(join_result_rdd.collect()) # [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))] print(x.leftOuterJoin(y).collect()) print(x.rightOuterJoin(y).collect()) # [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))] # 缓存--基于内存缓存-cache底层调用的是self.persist(StorageLevel.MEMORY_ONLY) join_result_rdd.cache() # join_result_rdd.persist(StorageLevel.MEMORY_AND_DISK_2) # 如果执行了缓存的操作,需要使用action算子触发,在4040页面上看到绿颜色标识 join_result_rdd.collect() # 如果后续执行任何的操作会直接基于上述缓存的数据执行,比如count print(join_result_rdd.count()) time.sleep(600) sc.stop() -
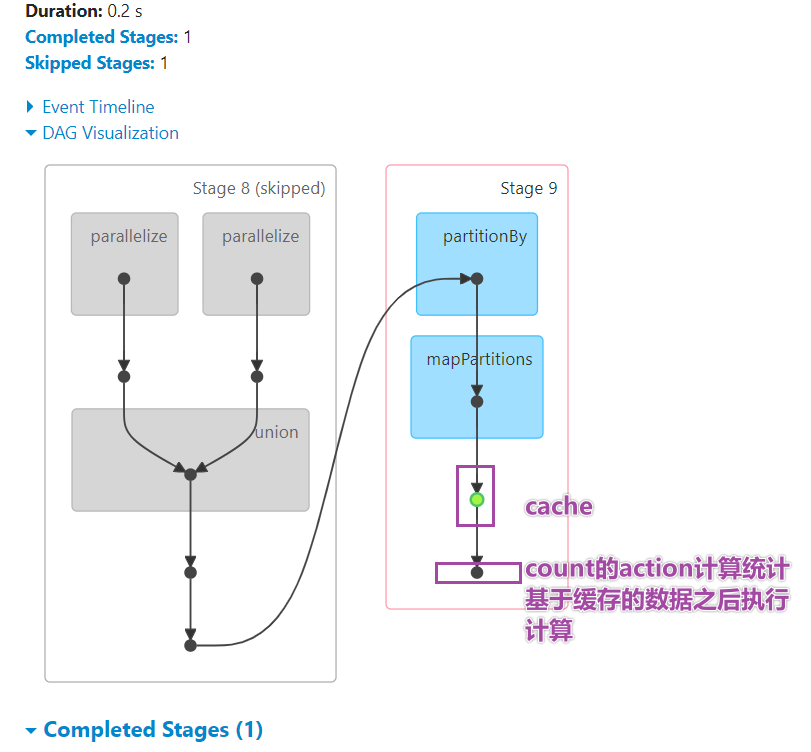
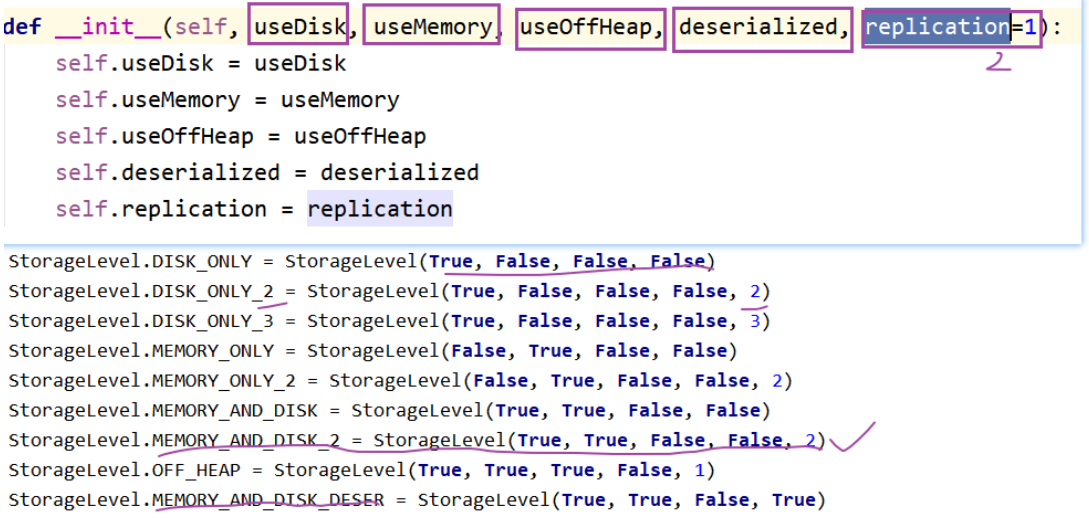
缓存级别
- 如何选:
- 1-首选内存
- 2-内存放不下,尝试序列化
- 3-如果算子比较昂贵可以缓存在磁盘中,否则不要直接放入磁盘
- 4-使用副本机制完成容错性质


释放缓存
后续讲到Spark内存模型中,缓存放在Execution内存模块
如果不在需要缓存的数据,可以释放
最近最少使用(LRU)
print(“释放缓存之后,直接从rdd的依赖链重新读取”)
print(join_result_rdd.count())* 

何时缓存数据
- rdd来之不易
- 经过很长依赖链计算
- 经过shuffle
- rdd被使用多次
- 缓存cache或persist
- 问题:缓存将数据保存在内存或磁盘中,内存或磁盘都属于易失介质
- 内存在重启之后没有数据了,磁盘也会数据丢失
- 注意:缓存会将依赖链进行保存的
- 如何解决基于cache或persist的存储在易失介质的问题?
- 引入checkpoint检查点机制
- 将元数据和数据统统存储在HDFS的非易失介质,HDFS有副本机制
- checkpoint切断依赖链,直接基于保存在hdfs的中元数据和数据进行后续计算
- 什么是元数据?
- 管理数据的数据
- 比如,数据大小,位置等都是元数据
[掌握]RDD Checkpoint
-
为什么有检查点机制?
- 因为cache或perisist将数据缓存在内存或磁盘中,会有丢失数据情况,引入检查点机制,可以将数据斩断依赖之后存储到HDFS的非易失介质中,解决Spark的容错问题
- Spark的容错问题?
- 有一些rdd出错怎么办?可以借助于cache或Persist,或checkpoint
-
如何使用检查点机制?
- 指定数据保存在哪里?
- sc.setCheckpointDir(“hdfs://node1:9820/chehckpoint/”)
- 对谁缓存?答案算子
- rdd1.checkpoint() 斩断依赖关系进行检查点
- 检查点机制触发方式
- action算子可以触发
- 后续的计算过程
- Spark机制直接从checkpoint中读取数据
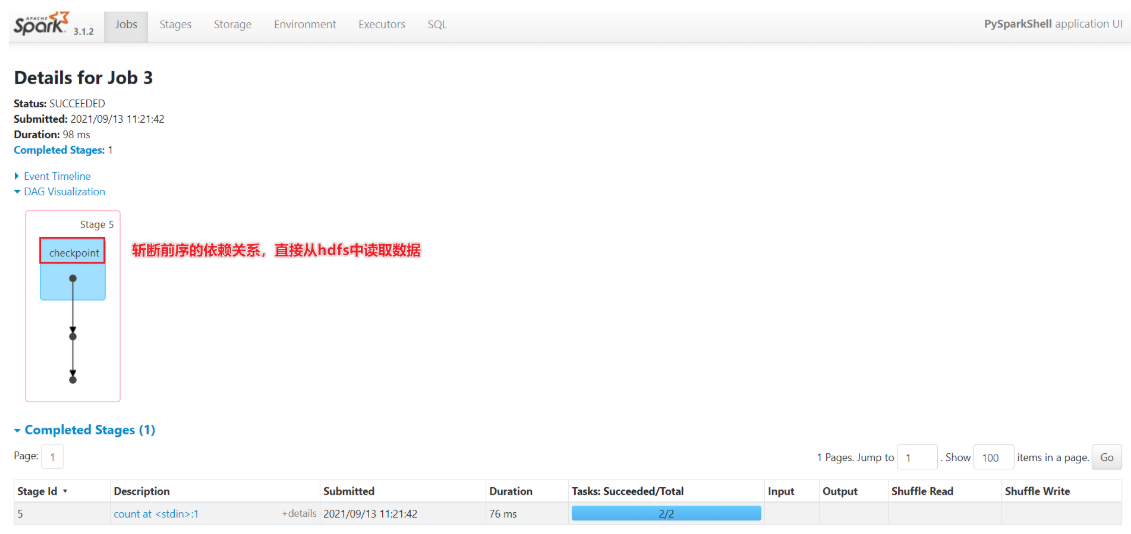
- 实验过程还原:
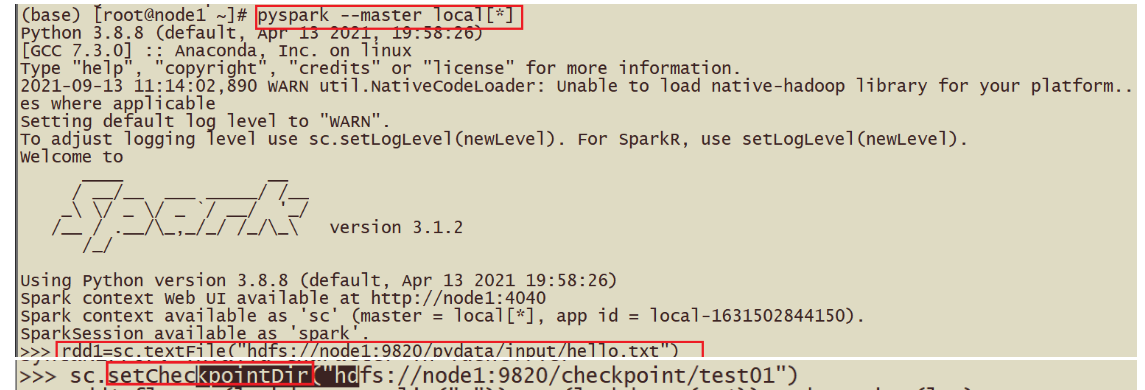

-
检查点机制那些作用?
- 将数据和元数据保存在HDFS中
- 后续执行rdd的计算直接基于checkpoint的rdd
- 起到了容错的作用
-
面试题:如何实现Spark的容错?
- 1-首先会查看Spark是否对数据缓存,cache或perisist,直接从缓存中提取数据
- 2-否则查看checkpoint是否保存数据
- 3-否则根据依赖关系重建RDD
-
检查点机制案例
持久化和Checkpoint的区别
- 存储位置:缓存放在内存或本地磁盘,检查点机制在hdfs
- 生命周期:缓存通过LRU或unpersist释放,检查点机制会根据文件一直存在
- 依赖关系:缓存保存依赖关系,检查点斩断依赖关系链
案例测试:
先cache在checkpoint测试
- 1-读取数据文件
- 2-设置检查点目录
- 3-rdd.checkpoint() 和rdd.cache()
- 4-执行action操作,根据spark容错选择首先从cache中读取数据,时间更少,速度更快
- 5-如果对rdd实现unpersist
- 6-从checkpoint中读取rdd的数据
- 7-通过action可以查看时间
[代码实战]SparkCore案例
PySpark实现IP地址查询统计分析
数据认知:
- 日志信息:
- 城市Ip段信息:
- 查看用户在哪个Ip端里面:
需求:
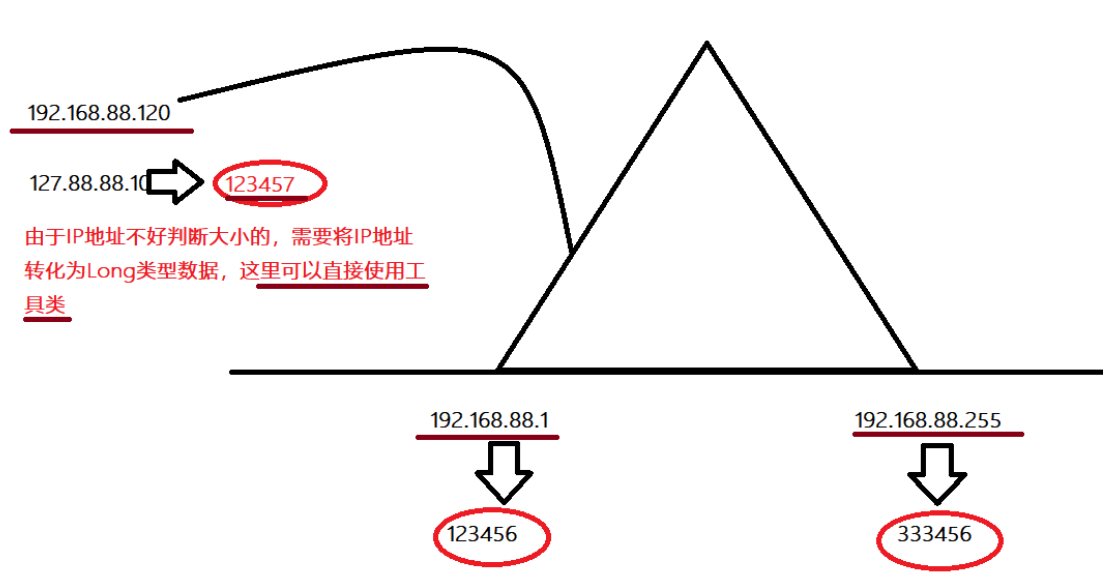
- 需要将ip地址转化为long类型数据,可以直接使用工具类
- 需要使用long类型ip进行对比查找–折半查找方法
步骤:
- 1-准备Spark的上下文环境
- 2-读取用户所在ip信息的文件,切分后选择下标为1字段就是用户ip
- 3-读取城市ip段信息,需要获取起始ip的long类型(下标2),结束ip的long类型(下标3),经度(下标13),维度(下标14)
- 4-通过ip地址转化为long类型IP
- 5-采用折半查找方法寻找ip对应的经纬度
- 6-根据相同经纬度的数据进行累加统计在进行排序
- 7-画个图
代码:
# -*- coding: utf-8 -*- # Program function:实现用户ip的地址查询,实现相同经纬度范围统计 ''' * 1-准备Spark的上下文环境 * 2-读取用户所在ip信息的文件,切分后选择下标为1字段就是用户ip * 3-读取城市ip段信息,需要获取起始ip的long类型(下标2),结束ip的long类型(下标3),经度(下标13),维度(下标14) * 4-通过ip地址转化为long类型IP * 5-采用折半查找方法寻找ip对应的经纬度 * 6-根据相同经纬度的数据进行累加统计在进行排序 * 7-画个图 ''' from pyspark import SparkConf, SparkContext from pyspark.sql import SparkSession # 需要拿到用户ip转化为long类型,然后通过二分查找方法在city_ip_rdd查找对应的经度和维度 def ip_transform(ip): ips = ip.split(".") # [223,243,0,0] 32位二进制数 ip_num = 0 for i in ips: ip_num = int(i) | ip_num << 8 return ip_num def binary_search(ip_num, city_rdd_broadcast_value): start = 0 end = len(city_rdd_broadcast_value) - 1 # (1)起始ip的long(2)结束ip的long(3)经度(4)维度的信息 # city_rdd_broadcast_value while (start <= end): mid = int((start + end) / 2) # 首先判断是否位于middle的[0]和[1]下标之间 if (ip_num >= int(city_rdd_broadcast_value[mid][0]) and ip_num <= int(city_rdd_broadcast_value[mid][1])): # 指导找到中间位置,返回mid位置=后面的index return mid # 如果是小于middle[0]起始ip, end=mid if (ip_num < int(city_rdd_broadcast_value[mid][0])): end = mid # 如果是大于middle[1]结束ip, start=mid if (ip_num > int(city_rdd_broadcast_value[mid][1])): start = mid def main(): global city_ip_rdd_broadcast # *1 - 准备Spark的上下文环境 spark = SparkSession.builder.appName("ipCheck").master("local[*]").getOrCreate() sc = spark.sparkContext sc.setLogLevel("WARN") # 直接将log4j放入文件夹中 # *2 - 读取用户所在ip信息的文件,切分后选择下标为1字段就是用户ip # user_rdd读取的是包含有user的ip地址的信息 user_rdd = sc.textFile( "/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ip/20190121000132394251.http.format") dest_ip_rdd = user_rdd \ .map(lambda x: x.split("|")) \ .map(lambda x: x[1]) # print(dest_ip_rdd.take(4))#['125.213.100.123', '117.101.215.133', '117.101.222.68', '115.120.36.118'] # *3 - 读取城市ip段信息,需要获取起始ip的long类型(下标2),结束ip的long类型(下标3),经度(下标13),维度(下标14) # .map(lambda x:(x[2],x[3],x[len(x)-2],x[len(x)-1])) ip_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ip/ip.txt") city_ip_rdd = ip_rdd \ .map(lambda x: x.split("|")) \ .map(lambda x: (x[2], x[3], x[13], x[14])) # Broadcast a read-only variable to the cluster,下面的代码中使用city.collect将rdd转化为list在进行广播 city_ip_rdd_broadcast = sc.broadcast(city_ip_rdd.collect()) # city_ip_rdd是包含有城市的(1)起始ip的long(2)结束ip的long(3)经度(4)维度的信息 # print(city_ip_rdd.take(5)) def GetPos(x): city_rdd_broadcast_value = city_ip_rdd_broadcast.value def getResult(ip): # *4 - 通过ip地址转化为long类型IP ip_num = ip_transform(ip) # *5 - 采用折半查找方法寻找ip对应的经纬度 # index 获取 (1)起始ip的long(2)结束ip的long(3)经度(4)维度的信息 index = binary_search(ip_num, city_rdd_broadcast_value) return ((city_rdd_broadcast_value[index][2], city_rdd_broadcast_value[index][3]), 1) # 得到的是((经度,维度),1),下面是python的map函数 re = map(tuple, [getResult(ip) for ip in x]) return re # *6 - 根据相同经纬度的数据进行累加统计在进行排序 ip_rdd_map_partitions = dest_ip_rdd.mapPartitions(GetPos) result = ip_rdd_map_partitions.reduceByKey(lambda x, y: x + y).sortBy(lambda x: x[1], False) print("final sorted result is:") print(result.take(5)) # [(('108.948024', '34.263161'), 1824), (('116.405285', '39.904989'), 1535), (('106.504962', '29.533155'), 400), (('114.502461', '38.045474'), 383), (('106.57434', '29.60658'), 177)] # *7 - 画个图 sc.stop() if __name__ == '__main__': main()总结:
- 掌握数据开发的思路,通过ip去城市ip段查找
- ip的类型转化为ip_long类型,寻找工具类
- index=binarySearch(ipnum,广播变量)
- 根据索引得到经度和维度
- 获取相同经纬度的信息的累加,在排序
反思:
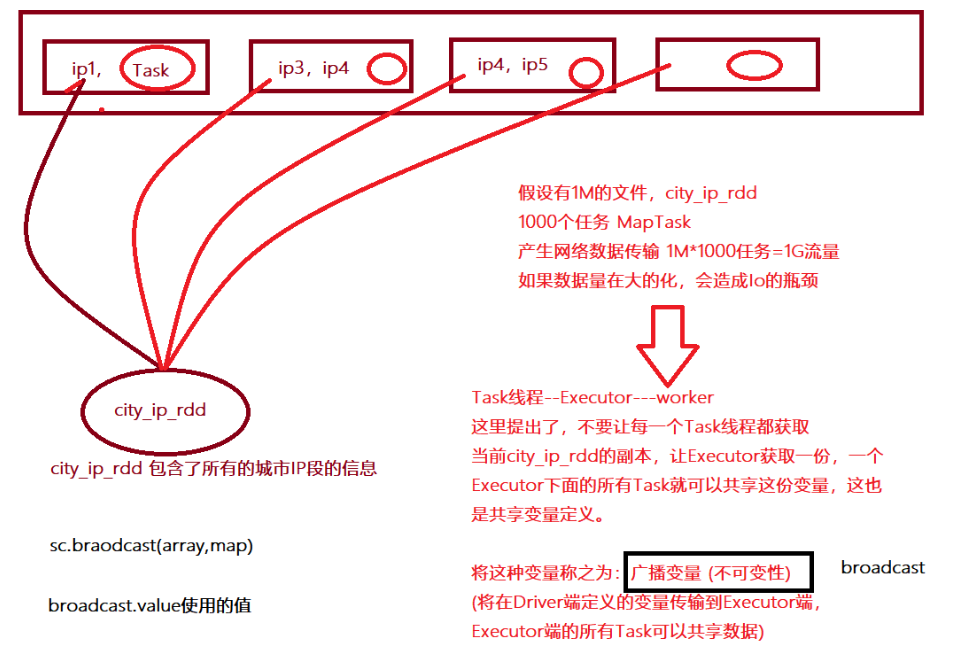
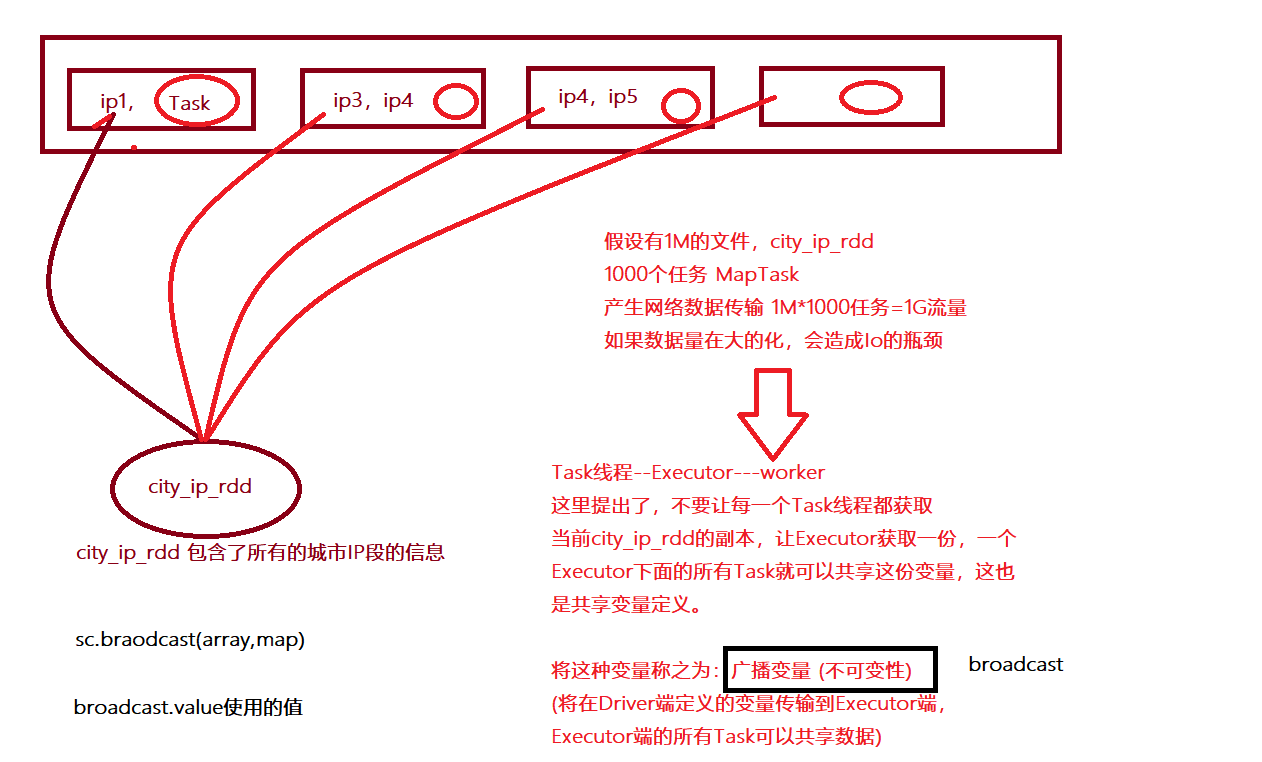
- 对于一直使用的数据,可以使用广播变量可以避免任务个数较多的时候造成大量网络的传输
- 可以将之前每个Task会获取一个变量的副本转变为一个executor获取一个变量副本,当前executor的所有task可以共享
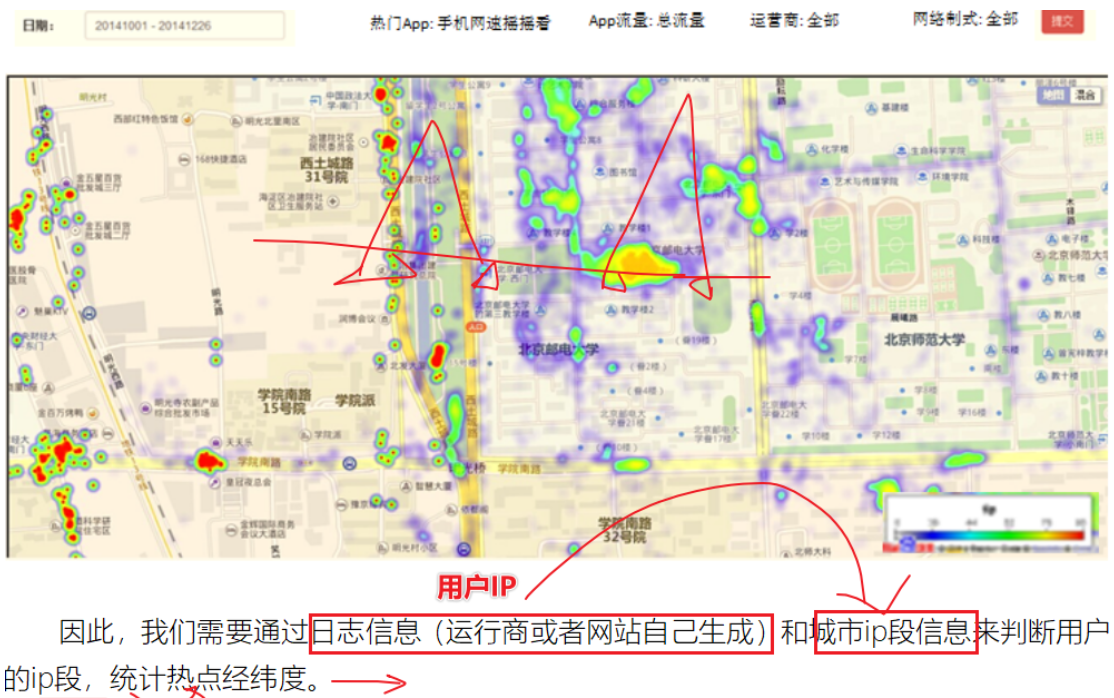

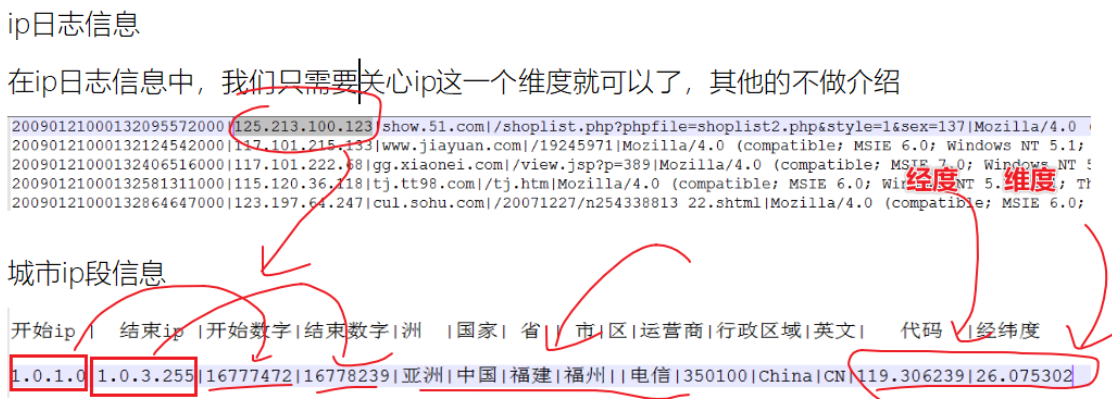
通过PySpark实现点击流日志分析
数据认知:
网站点击流,一个用户上网产生用户行为日志,Pv(Page View) Uv(User View) 互联网Pv5:1Uv
#每条数据代表一次访问记录 包含了ip 访问时间 访问的请求方式 访问的地址…信息
194.237.142.21 - - [18/Sep/2013:06:49:18 +0000] “GET /wp-content/uploads/2013/07/rstudio-git3.png HTTP/1.1” 304 0 “-” “Mozilla/4.0 (compatible;)”需求: * 求出Pv:页面访问量,用户每点击一次都会产生一条点击日志,一共计算有多少行的点击日志数据 * 求出Uv:用户访问量,针对Ip地址去重之后得到结果 * 求出TopK:访问的网站求解出用户访问网站的前几名 步骤: * 1-准备SparkContext的环境 * 2-读取网站日志数据,通过空格分隔符进行分割 * 3-计算Pv,统计有多少行,一行就算做1次Pv * 4-计算Uv,筛选出ip,统计去重后Ip * 5-计算topk,筛选出对应业务的topk 代码: * ```python# -*- coding: utf-8 -*- # Program function:完成网站访问指标的统计,Pv,Uv,TopK ''' * 1-准备SparkContext的环境 * 2-读取网站日志数据,通过空格分隔符进行分割 * 3-计算Pv,统计有多少行,一行就算做1次Pv * 4-计算Uv,筛选出ip,统计去重后Ip * 5-计算topk,筛选出对应业务的topk ''' from pyspark import SparkConf, SparkContext if __name__ == '__main__': # *1 - 准备SparkContext的环境 conf = SparkConf().setAppName("click").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 直接将log4j放入文件夹中 # *2 - 读取网站日志数据,通过空格分隔符进行分割 file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/click/access.log") # *3 - 计算Pv,统计有多少行,一行就算做1次Pv rdd_map_rdd = file_rdd.map(lambda line: ("pv", 1)) print("pv result is:", rdd_map_rdd.reduceByKey(lambda x, y: x + y).collect()) # pv result is: [('pv', 14619)] # *4 - 计算Uv,筛选出ip,统计去重后Ip # file_rdd_map = file_rdd.map(lambda line: line.split(" ")[0]) file_rdd_map = file_rdd \ .map(lambda line: line.split(" ")) \ .map(lambda x: x[0]) # print(file_rdd_map.take(5)) uv_num = file_rdd_map \ .distinct() \ .map(lambda line: ("uv", 1)) print("uvCount:", uv_num.reduceByKey(lambda x, y: x + y).collect()) # uvCount: [('uv', 1051)] # *5 - 计算topk,筛选出对应业务的topk,访问网站【10下标】的Topk,"需要使用\"-\" re = file_rdd \ .map(lambda x: x.split(" ")) \ .filter(lambda line: len(line) > 10) \ .map(lambda line: (line[10], 1)) \ .reduceByKey(lambda x, y: x + y) \ .sortBy(lambda x: x[1], False) \ .filter(lambda x: x[0] != "\"-\"") print(re.take(10)) re1 = file_rdd \ .map(lambda x: x.split(" ")) \ .filter(lambda line: len(line) > 10) \ .map(lambda line: (line[10], 1)) \ .groupByKey()\ .mapValues(sum) \ .sortBy(lambda x: x[1], False) \ .filter(lambda x: x[0] != "\"-\"") print(re1.take(10))
- 完毕
总结:
- 步骤中关键的步骤,对数据的理解,根据数据进行切分,过滤
反思:
- 作为数据开发工程师,需要对数据有基础的认知,比如age字段如果大于100或小于0过滤
[掌握]共享变量
-
两种共享变量:累加器,广播变量,就是在driver和executor中变量共享的,在driver定义,在exector执行计算
-
累加器
-
原理
- 在Driver端和exeutor端可以共享Executor执行计算的结果
-
不使用累加器
- python本地集合可以直接得到结果
- 但是在分布式集合中得不到累加的
-
使用累加器
- acc=sc.accumulate(10),10是初始值
- acc.add(num)
- print(acc.value)通过value获取累加器的值
-
代码
-
# -*- coding: utf-8 -*- # Program function:测试累加器 # 测试1:python集合的累加器,作为单机版本没有问题 # 测试2:spark的rdd的集合,直接进行累加操作,不会触发结果到driver的 # 原因;Driver端定义的变量,在executor执行完毕后没有将结果传递到driver # 引出共享变量,Driver和Executor共享变量的改变 from pyspark import SparkContext, SparkConf if __name__ == '__main__': conf = SparkConf().setAppName("miniPy").setMaster("local[*]") sc = SparkContext(conf=conf) # 下面是rdd的集合 l1 = [1, 2, 3, 4, 5] l1_textFile = sc.parallelize(l1) # 定义累加器 acc_num = sc.accumulator(10) # 执行函数 def add_num(x): global acc_num # acc_num+=x,这里了累加器提供的默认的方法是add方法 acc_num.add(x) # 执行foreach l1_textFile.foreach(add_num) # 输出累加器的值 print(acc_num) # 25 print(acc_num.value) # 获取累加器的值,25
-
-
广播变量
- 原理
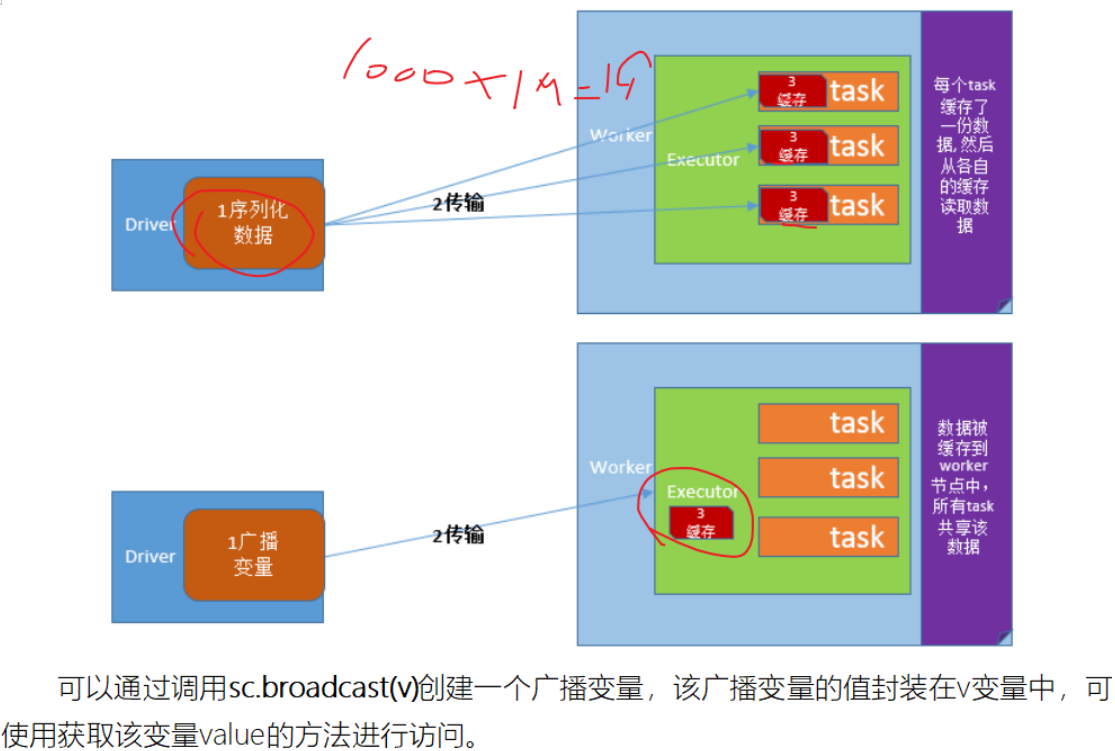
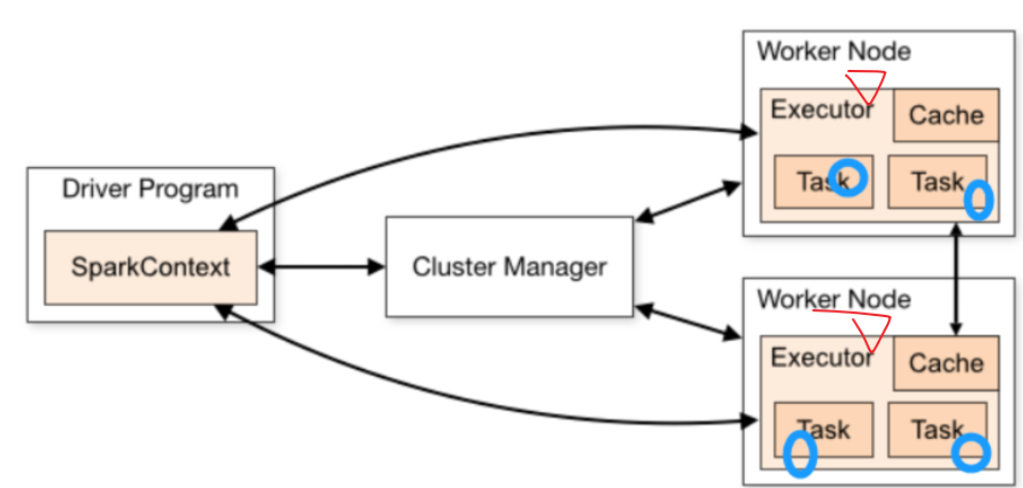
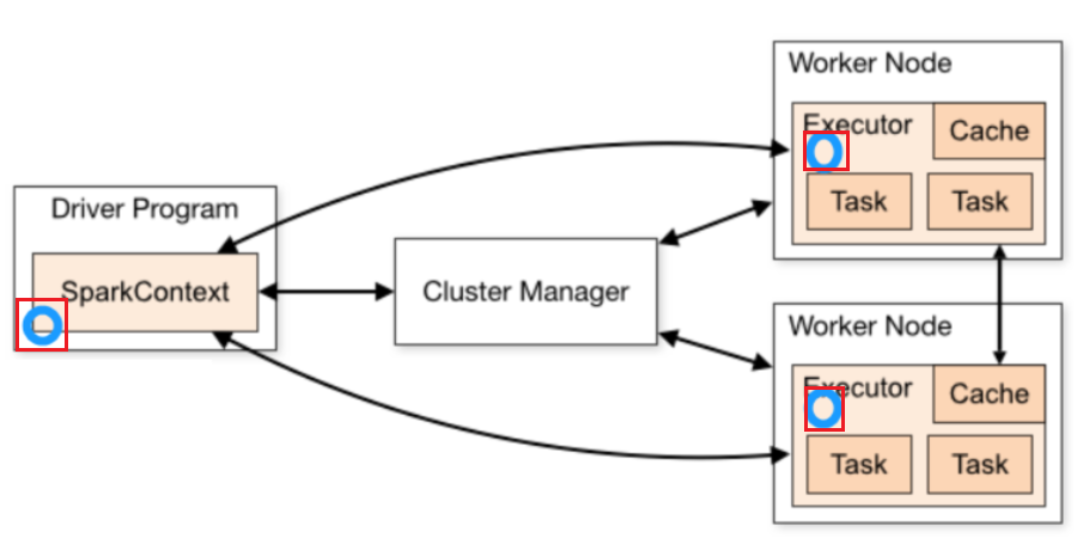
- 不使用广播变量
- 使用广播变量

- 1-广播变量不是在每个Task拥有一份变量,而是每个节点的executor一份副本
- 2-广播变量通过本地的executor从blockmanager中过去driver上面变量的副本(计算资源+计算程序)
- 代码
实战案例演示:
这里对应的fruit_collect_as_map如果后面的水果种类比较多,
每次的访问量比较大的时候,尽可能将fruit_collect_as_map转化为广播变量,通过广播变量让executor获取driver端定义变量的副本信息
# -*- coding: utf-8 -*- # Program function: from pyspark import SparkContext, SparkConf if __name__ == '__main__': conf = SparkConf().setAppName("miniPy").setMaster("local[*]") sc = SparkContext(conf=conf) # 这里定义rdd kvFruit = sc.parallelize([(1, "apple"), (2, "orange"), (3, "banana"), (4, "grape")]) print(kvFruit.collect()) fruit_collect_as_map = kvFruit.collectAsMap() # 声明广播变量 broadcast_value = sc.broadcast(fruit_collect_as_map) # print(fruit_collect_as_map)#{1: 'apple', 2: 'orange', 3: 'banana', 4: 'grape'} # 通过指定索引来查询对应水果名称 friut_ids = sc.parallelize([2, 1, 4, 3]) # 执行查询 print("执行查询后的结果") # ['orange', 'apple', 'grape', 'banana'] print(friut_ids.map(lambda fruit: fruit_collect_as_map[fruit]).collect()) print("执行广播变量之后查询后的结果") # 使用广播变量的取值 print(friut_ids.map(lambda fruit: broadcast_value.value[fruit]).collect())
完毕
整合案例:
需求:利用广播变量和累加器完成非字母的表示统计

步骤:
1-读取数据
2-切割字符串
3-定义累加器,这里累加器可以计算非字母个数
4-定义广播变量-------------[# !,@,#,]
5-利用自定义函数累加非字母的表示
6-执行统计
7-停止sparkcontext
代码:
-- coding: utf-8 --
Program function:
from pyspark import SparkConf, SparkContext
import re‘’’
- 1-读取数据
- 2-切割字符串
- 3-定义累加器,这里累加器可以计算非字母个数
- 4-定义广播变量-------------[# !,@,#,]
- 5-利用自定义函数累加非字母的表示
- 6-执行统计
- 7-停止sparkcontext
‘’’
if name == ‘main’:*1 - 准备SparkContext的环境
conf = SparkConf().setAppName(“click”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”) # 直接将log4j放入文件夹中*1 - 读取数据
file_rdd = sc.textFile(“/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/wordnon.txt”)*2 - 切割字符串
split_rdd = file_rdd
.filter(lambda line: (len(line) > 0))
.flatMap(lambda line: re.split(“\s+”, line))
print(split_rdd.collect())print(split_rdd.collect())
*3 - 定义累加器,这里累加器可以计算非字母个数
acc_count = sc.accumulator(0)*4 - 定义广播变量 - ------------[ # !,@,#,]
list = [“,”, “.”, “!”, “#”, “$”, “%”]
list_broadcast = sc.broadcast(list)# *5 - 利用自定义函数累加非字母的表示 def f(x): global acc_count listValue = list_broadcast.value if x in listValue: # acc_count.add(1) acc_count += 1 return 1 else: return 0 # *6 - 执行统计 line__filter = file_rdd \ .filter(lambda line: (len(line.strip()) > 0)) \ .flatMap(lambda line: re.split("\s+", line)) \ .filter(f) print(line__filter.count()) # 8 print("list broadcast value is:", acc_count.value) # 8 # *6 - 执行各个非单词过滤统计 line__filter_alpha = file_rdd \ .filter(lambda line: (len(line.strip()) > 0)) \ .flatMap(lambda line: re.split("\s+", line)) \ .filter(f)\ .map(lambda word: (word, 1)) \ .reduceByKey(lambda x, y: x + y) print(line__filter_alpha.collect())#[('#', 2), ('!', 2), ('$', 2), ('%', 2)] # *7 - 停止sparkcontext
总结:
累加器和广播变量
累加器注意事项:
如果执行多次action操作的化,如果没有缓存会执行多次累加
这里需要在执行累加的action操作之前最好做缓存,不至于累加器的数据是错误的

代码
# -*- coding: utf-8 -*- # Program function:累加器的注意事项 accumulate from pyspark import SparkConf, SparkContext if __name__ == '__main__': # *1 - 准备SparkContext的环境 conf = SparkConf().setAppName("click").setMaster("local[*]") sc = SparkContext.getOrCreate(conf=conf) sc.setLogLevel("WARN") # 直接将log4j放入文件夹中 acc = sc.accumulator(0) def judge_even(row_data): """ 过滤奇数,计数偶数个数 """ global acc if row_data % 2 == 0: acc += 1 return 1 else: return 0 a_list = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) even_num = a_list.filter(judge_even) even_num.cache() # 上述结果需要一个action触发 print("count value is:", even_num.count()) # 再次执行输出的时候,得到正确的结果 5 print("acc value is:{}".format(acc)) # acc value is:5 # 坑:如果再次执行action操作,会发生什么现象? # 解析:由于第二次执行action的操作会重新计算所有rdd的算子,会再次累加5,得到10结果 print("count value is:", even_num.count()) print("acc value is:{}".format(acc)) # acc value is:10
完毕
[提高扩展]Spark 内核调度
RDD依赖
为什么设计依赖?
- 1-为了实现Spark的容错,rdd1-rdd2-rdd3-rdd4
- 2-并行计算,划分依赖、
为什么划分宽窄依赖?
为了加速并行计算
窄依赖可以并行计算,如果是宽依赖无法并行计算
依赖的划分
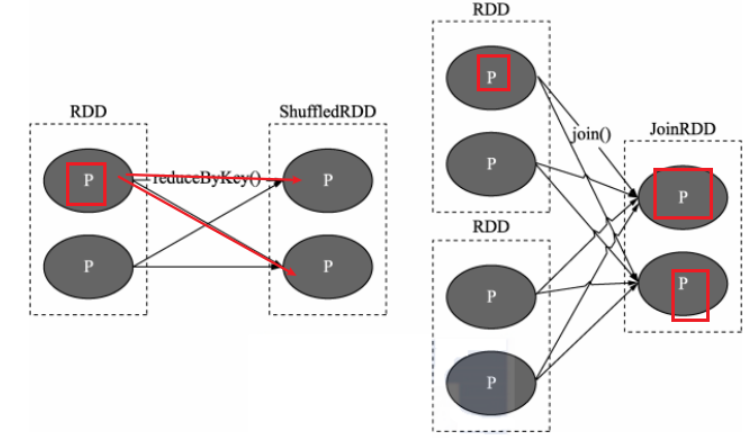
窄依赖:*父 RDD 与子 RDD 间的分区是一对一的*
宽依赖:划分Stage
- *父 RDD 中的分区可能会被多个子 RDD 分区使用*
如何区分宽窄依赖?
- 比如map。filter,flatMap 窄依赖
- 比如reduceByKey,groupByKey,宽依赖(shuffle)
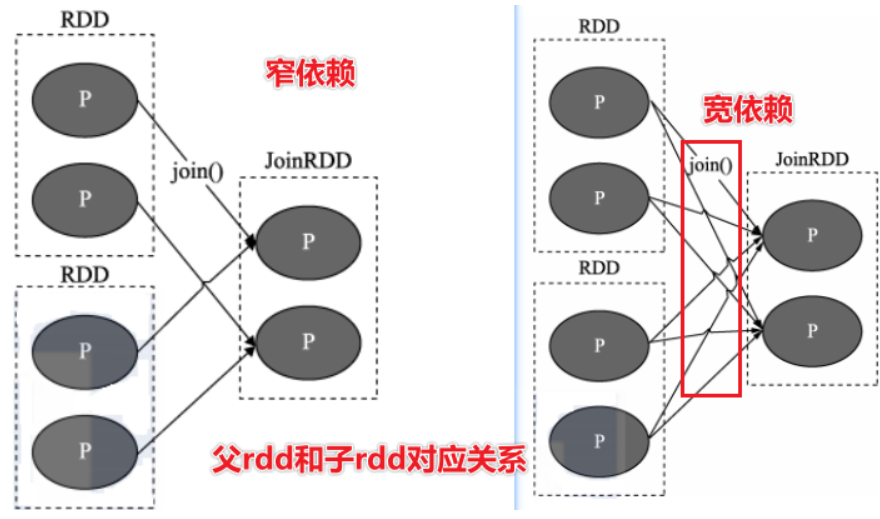
- 不能说:一个子RDD依赖于多个父rdd,该种情况无法判断
DAG和Stage
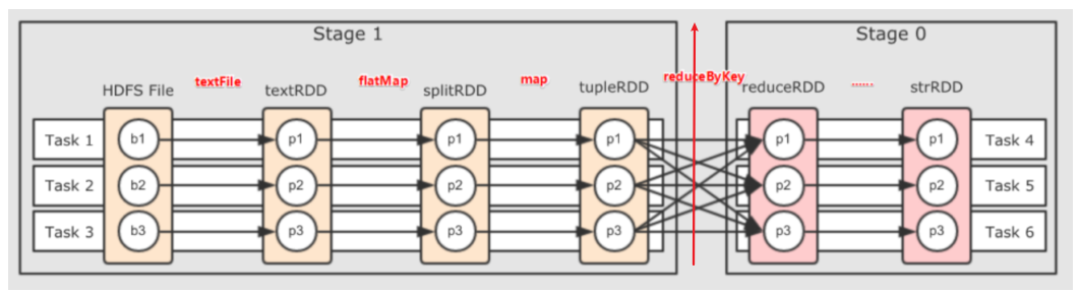
如何划分Stage?
根据Shuffle依赖,划分Stage?因为Shuffle前后都以执行并行计算
什么是DAG?
- 有向无环图
DAG如何划分Stage?
- 一个Dag就是一个Job,一个Dag是由Action算子进行划分
- 一个Job下面有很多Stage,根据宽依赖Shuffle依赖划分Stage
Job调度流程
一个Spark应用程序包括Job、Stage及Task:
l 第一:Job是以Action方法为界,遇到一个Action方法则触发一个Job;一个Job就是dag
l 第二:Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
l 第三:Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
结合资源获取,以onyarn为例
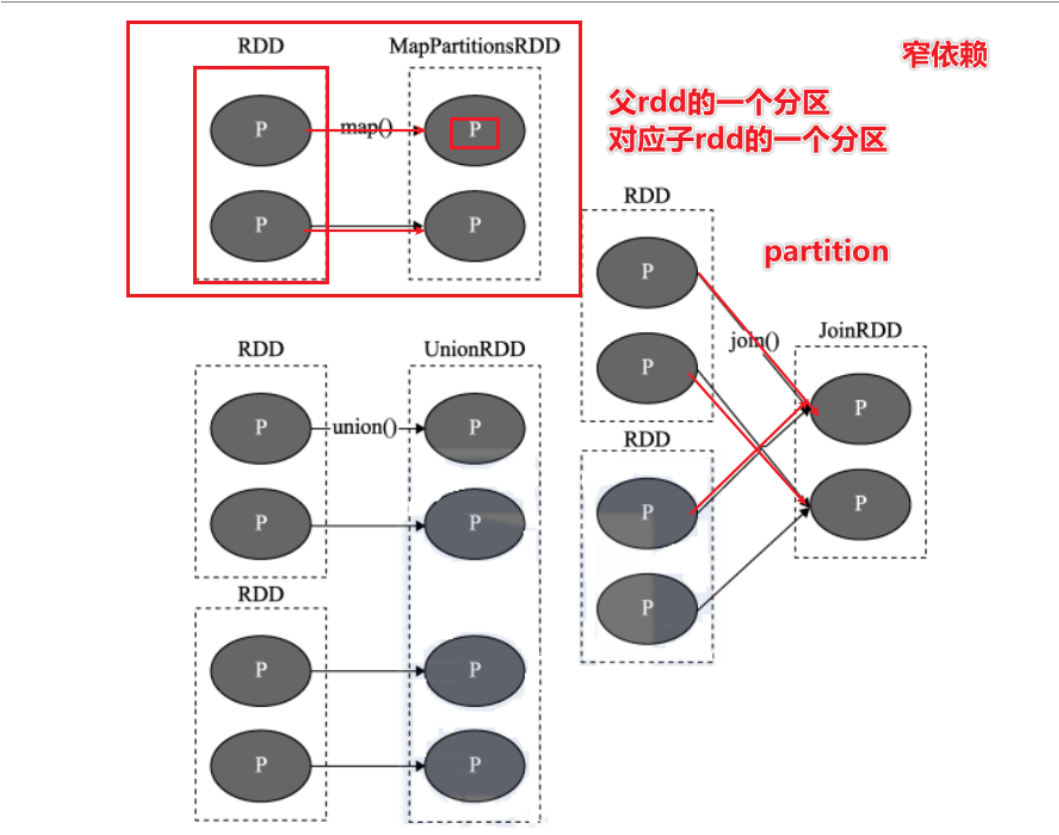
- 作业:
- ip地址查询理清楚,写1遍
- Job调度流程–只需要在宏观层面理解Job调度,更多借助ppt
- 思考几个问题:
- 是什么,为什么,怎么用
- 缓存
- checkpoint
- dag
- 依赖关系