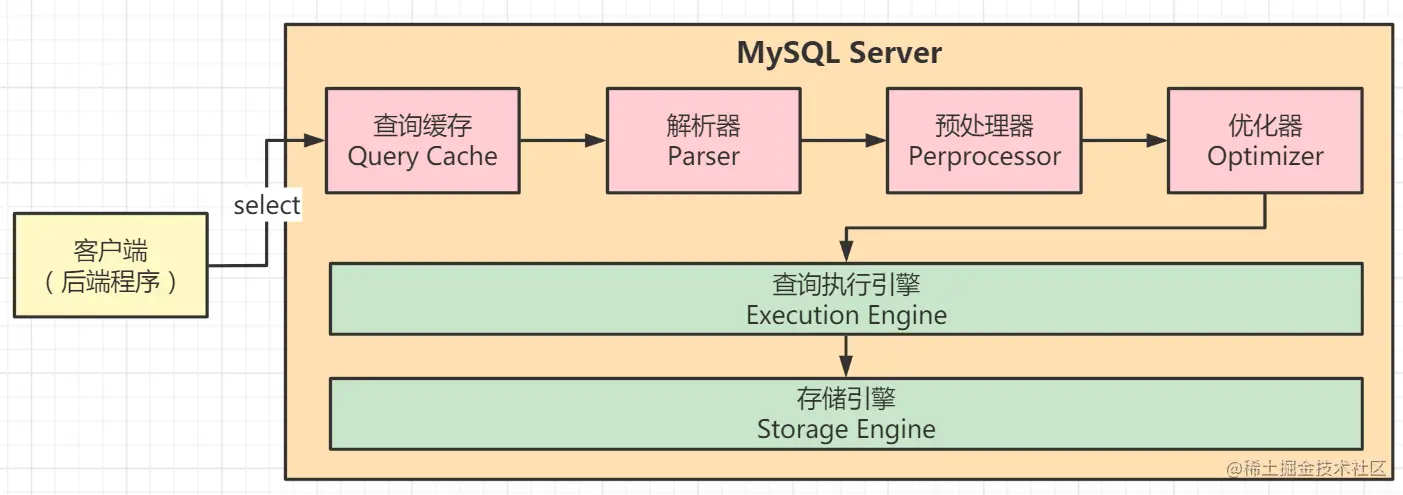
我们学习的HTTP协议,是应用层里面最广泛使用的协议~
我们主要是学习HTTP的请求响应的报文格式
我们可以借助抓包工具来学习,抓包抓到的是文本格式~~
根据上节内容
我们大概了解了请求和响应的格式
请求有4部分:
(1)首行 :方法 URL 版本号
(2)请求头header: 键值对,每一行是一个键值对,键和值使用:和空格来分割
(3)空行:结束标志
(4)正文body:承载一些具体的数据,可能是josn格式(键值对)也可以是其他格式
响应同样也有4部分组成
(1)首行:版本号 状态码 状态码描述
(2)响应头header:同样也是一行一个键值对,同样使用:和空格来分割
(3)空行:结束标志
(4)承载一些具体的数据,可以是json格式,html格式,还可以是css,js,图片等等格式
接下来我们来了解一下HTTP中的一些细节
本章我们主要介绍的是 请求中 的 首行 中的 URL 和 方法 这两个内容~
首先我们先来认识URL
URL:唯一资源定位符(用这个来找网络上的资源)
URI:唯一资源标识符(用这个来区分一个网络上的资源)
URL和URI的概念非常相似,我们一般不会做显示区分~
我们平时在浏览器中搜索的内容,都是一个URL
比如我们搜索一下,搜狗官网 csdm官网 不孕不育关键字
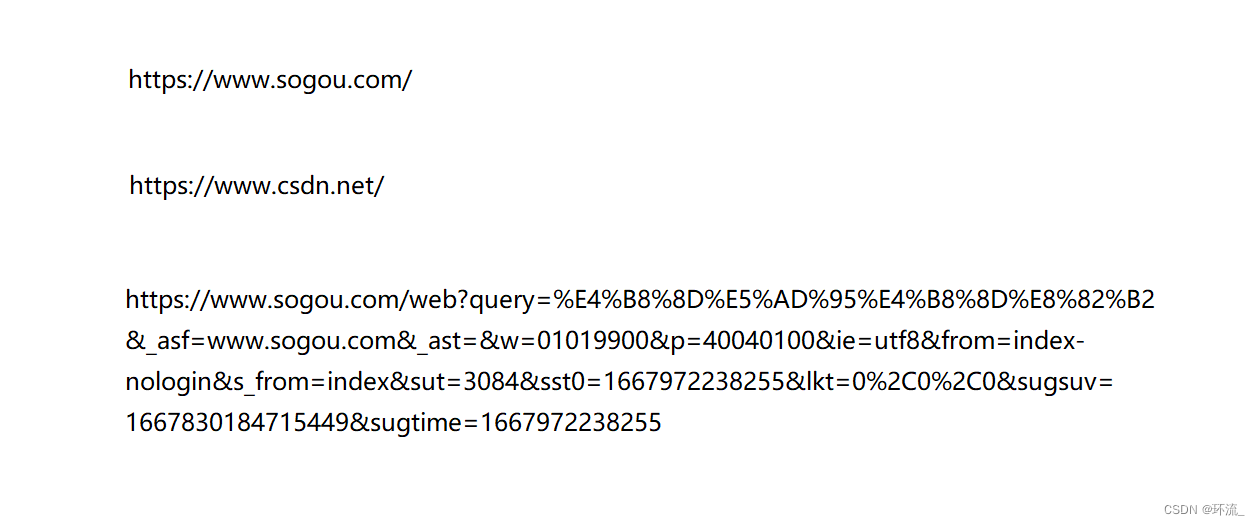
这些都是URL
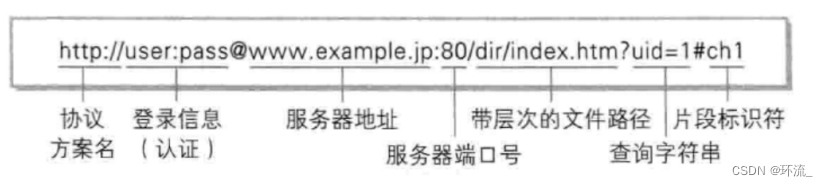
为什么我们现在的URL基本都是https?http其实和https没有太大的区别,唯一的区别就是https对数据进行了加密,https也就比http多了这个加密功能罢了
上图第二部分登录信息,这种用法现在基本上是不用了
第三部分,服务器地址:也就是服务器的IP地址,当然,也可以写成域名,域名和IP地址是一个等价关系,DNS域名解析系统,能够帮助我们自动的把域名转换成IP地址
第四部分服务器端口号:标识了要访问目标服务器的哪个进程(第三和第四部分就能够确定,是互联网上的哪个主机的哪个进程)在浏览器的url里面端口号经常会省略不写,省略的时候用的是当前协议的默认端口,http的默认端口为 80,https的默认端口为 443
第五部分带层次的文件路径:服务器进程可能会提供很多的资源,这些资源会放在一个具体的目录中,在URL中写的路径,不一定是真的对应到服务器上的某个硬盘的目录,服务器提供的资源,可能是真实存在的文件,也可能是一个“虚拟出来的文件”(静态资源/动态资源)
第六部分:有一个问号?,这个问号后面的也是键值对结构,称为query string(查询字符串),相当于浏览器给服务器传递一些必要的参数;header里面也有很多键值对,但这些键值对大多数的根据标准来定义的,而URL中的查询字符串中的键值对是完全自定义的,所以,查询字符串就是前后端交互数据的重要桥梁~
第七部分片段标识符:用来区分一个网页中的哪部分,常见于 小说网站,或者文档网站,借助片段标识符快速跳转到网页的某个部分(所以你在浏览文档网页的时候,你往下滑动鼠标,你会发现URL是跟着变化的,那是因为网页中的不同片段都对应一个片段标识符)
在URL中的重要部分
1.IP地址+端口号【基础】
2.带层次的路径【开发中常用】
3.查询字符串【开发中常用】
带层次的路径:选择的时候,根据实际情况来,服务器的哪些资源是可以通过网络访问,哪些资源是不允许访问,是要根据选择的路径来的
查询字符串:要注意的是解码和编码,写代码的时候要经常考虑这个事情,虽然一般不用咱们自己实现解码编码,但要有这个意识
URL encode【编码】/ decode【解码】
我们知道,URL中已经包含了一些特殊含义的符号了,比如@ / ? ……
万一query string 的value中,也包含了这些特殊符号,很可能会有问题!!(浏览器可能会错误的识别URL,服务器也可能会错误的解析URL)非常类似与,编程中的变量名不能是 “关键字”~
我们要用编码的方式来转义这些要用的符号,,本质上就是把特殊符号进行转义了,这里的转义范围不仅仅是这些特殊符号,还可以是汉字
(1)咱们现在浏览器中搜索一下 C++ 这个关键词

复制URL,我们看到在query string中的value里面,出现了C%2B%2B,这难道是为了骂C++的程序员都是一群2B吗?并不是,当我们打开ASCII编码查看 加号+ 的转移字符,而转义的规则,就是把转义的字符串,每个字符的十六进制表示,每个字节前边加上一个%
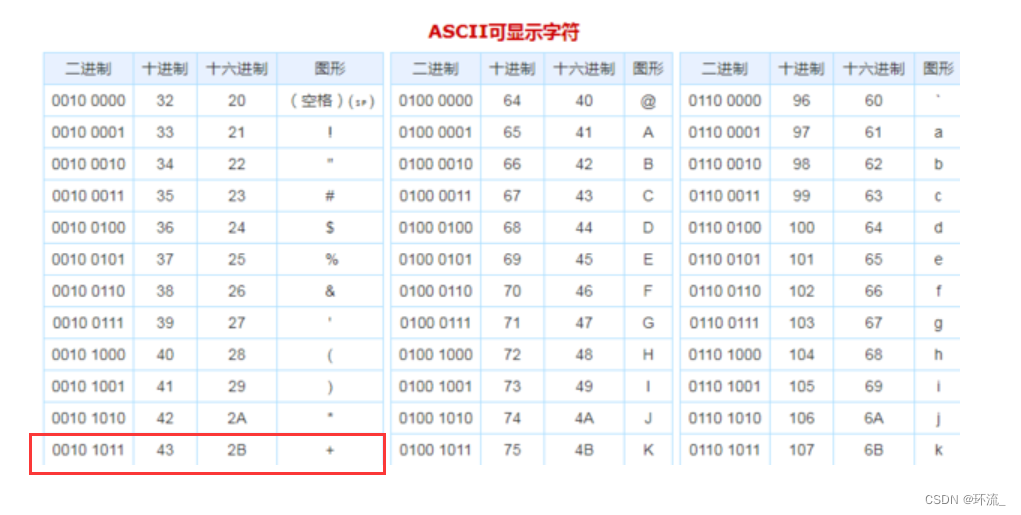
+十六进制 =》ascii就是 2B
而转义汉字就是借用UTF-8
比如说我们搜索 不孕不育 这个词作为关键字

![]()
不孕不育搜索的关键词就会在url中的query string 中以utf8编码的形式显示
一个汉字是3个字节,每个字节前边都会加一个%
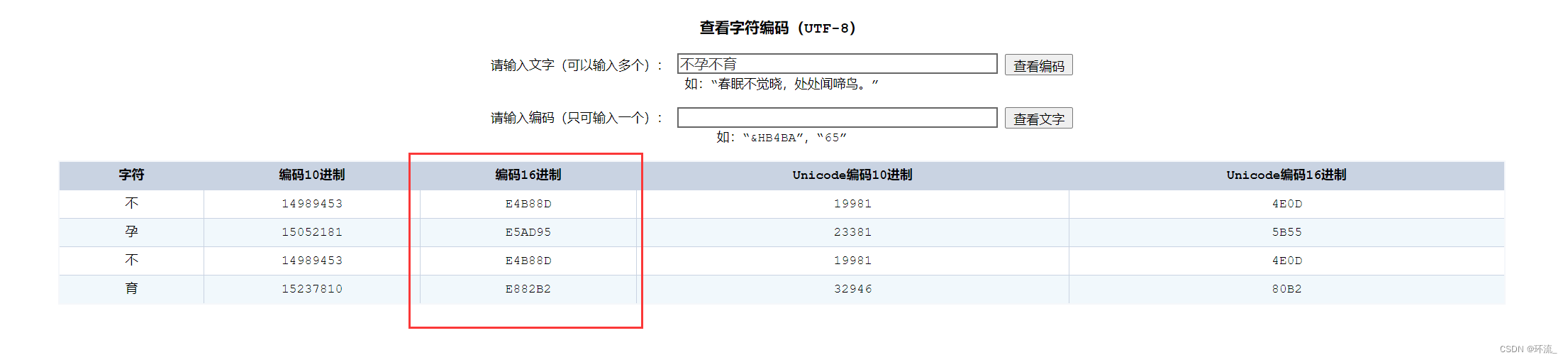
我们如果在代码的时候不进行编码的话,有的浏览器可以访问我们的网页,而有的浏览器假如没有自动编码,可能就访问不了,因此我们要有编码解码的意识~
把原始的字符,转成转义后的字符 => URL encode(编码)
把转义后的字符还原成原始的字符 => URL decode(解码)
认识请求首行中的 “方法”(method)
这也是HTTP中非常重要的部分
可以把这个方法理解成,你的这个请求想要做啥
谢灵运说过,天下文采十斗,曹子剑独占八斗,他自己一斗,剩下的其他文人共享一斗
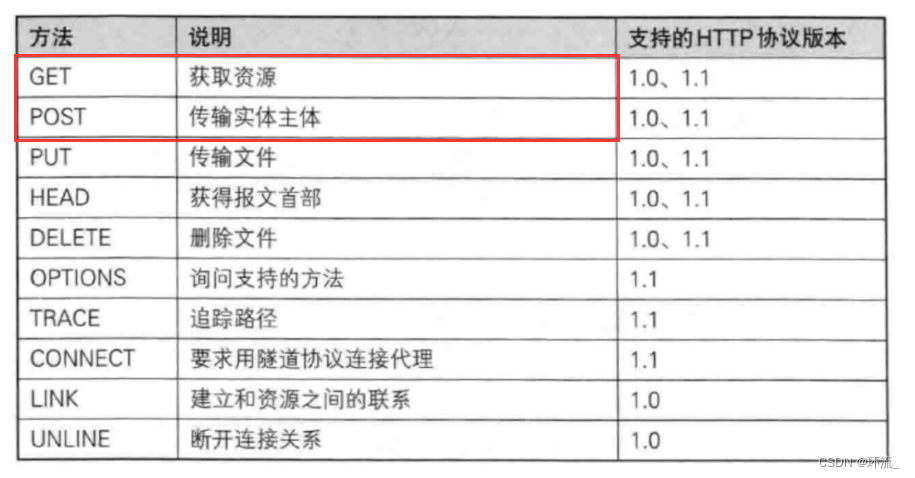
在HTTP中的方法重要性也是如此,GET方法独占8斗(最常用)POST独占一斗(常用)剩下的方法共享一斗,所以我们这里只重点介绍 GET 和 POST
GET
GET是HTTP中最常用的请求方法,一般下面4种情况会触发GET
(1)浏览器地址栏直接输入 URL,此时就会出发GET
(2)html里面的link ,a, img, script 也会触发GET请求
(3)form表单
(4)ajax
GET请求的特点
1.URL的query string 可以为空,也可以不为空
2.有若干个header键值对
3.body部分为空
GET请求长度在标准里面是不限制的

标准中没有限制长度上限,但浏览器和HTTP服务器实现的时候,可能有长度上限,这取决于具体实现
POST
产生POST途径
1.form
2.ajax
POST请求的特点
1.方法叫做POST
2.URL里面通常没有query string
3.也有若干个header键值对
4.body这里通常是有的,body的格式有很多种
POST在传递信息给服务器的时候,通常会把信息放到body中