目录
- 1 Mask R-CNN 原理(简单版)
- 2 ROI Align
- 3 PyTorch 加载预训练模型
1 Mask R-CNN 原理(简单版)
Mask R-CNN 是一个实例分割(Instance segmentation)算法,主要是在目标检测的基础上再进行分割。 Mask R-CNN 算法主要是 Faster R-CNN + FCN,更具体一点就是 ResNet/VGGNet + RPN + RoI Align + Fast R-CNN + FCN,如下图所示。

Mask R-CNN 的主要创新点有两点:
- Backbone: ResNet-101 + FPN,这是考虑到图片的多尺度特征,金字塔特征有利于小物体的检测;
- RoI Align 替换 RoI Pooling.
- 在 Faster R-CNN 的基础上增加了实例分割分支.
Mask R-CNN 的算法步骤如下:
- 输入一张图片,进行数据预处理(尺寸,归一化等等);
- 将处理好的图片传入预训练的神经网络中(ResNet 等,优秀的主干特征提取网络)获得相应的 feature map,这里的 feature map 是金字塔特征图;
- 通过 feature map 中的每一点设定 RoI,获得多个 RoI 候选框,这里与 Faster R-CNN 相同;
- 对这些多个 RoI 候选框送到 RPN 中进行二值分类(前景或后景)和预测框回归(Bounding-box regression),并过滤掉一部分候选的 RoI;
- 对剩下的 RoI 进行 RoI Align 操作(即先将原图和 feature map 的 pixel 对应起来,然后将 feature map 和固定的 feature 对应起来);
- 对这些 RoI 进行分类(N 类别分类),预测框回归和 Mask 生成。
Mask R-CNN 一大创新点是使用了 ROI Align,下面介绍其流程。
2 ROI Align
首先假设 RoI 在原图上的大小为 x,原图到特征图缩小了 k 倍,则 RoI 对应到特征图大小就是 x / k,这里不对坐标进行取整,这意味着网格中没有确定的像素可以取,因为新坐标是浮点值。

假设我们最终需要的特征图大小为 2 × 2,我们需要将 RoI 的特征图平均等分成 4 份,然后再将每个方格分成 4 小块,取每个小块的中心作为黑点,然后对这 4 个黑点的值选择最大值或者均值,作为这个方格最终的特征,如上图。RoI Align 使用了双线性插值的方法。小黑点周围会有特征图上的 4 个特征点,利用这 4 个特征点双线性插值出该黑点的值。 计算方式举例如下:


双线性差值公式如下:
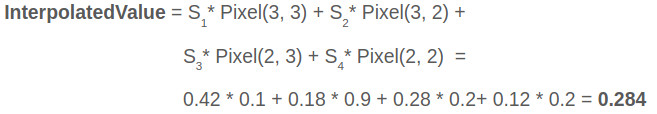
3 PyTorch 加载预训练模型
代码结构如下:
../MaskRCNN
├── checkpoint
│ └── mask_rcnn_with_10epochs.pth
├── LabPicsMedical
│ ├── Categories
│ ├── EvaluationScripts
│ ├── ReaderScriptsPython
│ ├── Test
│ └── Train
├── result.jpg
├── dataset.py
├── test.py
└── train.py
本次任务我加载了 pytorch 的 mask r-cnn 的预训练模型,并在该模型基础上进行 fine-tuning 10 个 epochs,并保存 fine-tuning 后的模型,最终进行测试。 下面是代码中各个部分实现的具体情况和文件说明:
- checkpoint:保存 fine-tuning 后的模型参数;
- LabPicsMedical:数据集,本次实验使用的数据集是用于视觉理解医学的 LabPics 数据集,该数据集主要是对医学容器和容器内的物体进行实例分割,本次实验我只对图片的容器进行实例分割;下载地址请参考:https://zenodo.org/record/4736111
- result.jpg:测试图片;
- dataset.py:该模块用于模型数据的生成。我在其中编写了 MedicalDataset 类,继承了 Dataset 类,类中的 data_load 方法用于图片数据和注释数据的读取,注释数据包括 boxes、 labels 和 masks;
- train.py:该模块用于模型训练;
- test.py:该模块用于模型测试。
下面对每份代码进行详细注释,不再另外说明,张贴如下:
dataset.py
import torch
import numpy as np
import cv2
import argparse
from pathlib import Path
from torch.utils.data import DataLoader, Dataset
class MedicalDataset(Dataset) :
def __init__(self, args):
super(MedicalDataset, self).__init__()
# args 是传入的所有参数集合
self.args = args
# 加载图片和图片的注释数据,也即分割对象的 masks、labels、boxes
self.images, self.targets = self.data_load()
def data_load(self):
imgs = []
# 得到训练数据的路径
for path in Path(self.args.train_dir).iterdir() :
imgs.append(path)
Imgs = [] # 图片数据
Annos = [] # 注释数据
for idx in range(len(imgs)) :
# 图片读取
img = cv2.imread(imgs[idx].joinpath("Image.jpg").__str__(), cv2.IMREAD_COLOR)
# BGR 图片转成 RGB 图片
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 图片 resize 至固定大小
img = cv2.resize(img, self.args.image_size)
# 得到分割目标也就是图片中容器的路径,本次任务只分割容器
maskdir = imgs[idx].joinpath('Vessels')
masks = []
# 判断该图片是否有容器
if not maskdir.exists() :
continue
for maskname in maskdir.iterdir() :
# 读取图片
vesmask = cv2.imread(maskname.__str__(), cv2.IMREAD_GRAYSCALE)
# 制作标签,令容器所在位置的像素等于 1,其余部分作为背景,赋 0
vesmask = (vesmask > 0).astype(np.uint8)
vesmask = cv2.resize(vesmask, self.args.image_size)
masks.append(vesmask)
# 查看有多少个容器,也即分割对象的数量
num_objs = len(masks)
if num_objs == 0 :
continue
# 制作真正预测框,维度是 [N, 4]
boxxes = torch.zeros([num_objs, 4], dtype = torch.float32)
for i in range(num_objs) :
# 得到 mask 的最小外接矩阵
x, y, w, h = cv2.boundingRect(masks[i])
# 存储左上角和右下角坐标
boxxes[i] = torch.tensor([x, y, x + w, y + h])
masks = torch.as_tensor(masks, dtype = torch.uint8)
img = torch.as_tensor(img, dtype = torch.float32)
# 将 3 个注释信息存到字典里面
annotations = {}
annotations['boxes'] = boxxes
# 这次像素分割只是二分类,也即容器和背景
annotations['labels'] = torch.ones((num_objs, ), dtype = torch.int64)
annotations['masks'] = masks
Imgs.append(img)
Annos.append(annotations)
# 将图片信息拼接
Imgs = torch.stack([torch.as_tensor(image) for image in Imgs], dim = 0)
# 将 (H, W, C) 转成 (C, H, W)
Imgs = Imgs.permute(0, 3, 1, 2)
return Imgs, Annos
def __getitem__(self, item):
return self.images[item], self.targets[item]
def __len__(self):
return len(self.images)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--image_size', type=tuple, default=(600, 600))
parser.add_argument('--batch_size', type=int, default=16)
parser.add_argument('--train_dir', type=str, default='LabPicsMedical/Train')
parser.add_argument('--num_classes', type=int, default=2)
parser.add_argument('--device', type=str, default="cuda:8" if torch.cuda.is_available() else "cpu")
parser.add_argument('--max_epoch', type=int, default=200)
args = parser.parse_args()
data = MedicalDataset(args)
train.py
import torch
import torch.optim as optim
import argparse
from pathlib import Path
from torch.utils.data import DataLoader
from torchvision.models.detection import maskrcnn_resnet50_fpn
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from dataset import MedicalDataset
class Solver :
def __init__(self, args):
self.args = args
# 制作训练集,要注意输出的数据状态,分割任务中因为每张图片的目标数量可能不一样,因此无法进行张量拼接
# 因此,对于图片或者标注信息我们要获取列表型数据,由参数 collate_fn 决定,可以查查该参数的用法
self.train_loader = DataLoader(MedicalDataset(args), batch_size = args.batch_size, shuffle = True,
collate_fn = lambda x: tuple(zip(*x)))
def train(self):
# 具有 ResNet-50-FPN 主干的 maskrcnn 的预训练模型
model = maskrcnn_resnet50_fpn(pretrained = True)
# 更换分类器
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes = self.args.num_classes)
model = model.to(self.args.device)
# 优化器
optimizer = optim.AdamW(model.parameters(), lr = 1e-5)
model.train()
losses = []
min_loss = 100000
# 训练
for epoch in range(self.args.max_epoch) :
train_loss = 0.0
for images, targets in self.train_loader :
images = list(image.to(self.args.device) for image in images)
targets = [{k : v.to(self.args.device) for k, v in t.items()} for t in targets]
# 损失,如果输入了 target 则输出损失,否则输出的是预测分数、框、分割等等信息
output = model(images, targets)
loss = sum(loss for loss in output.values())
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
print(f'[{epoch + 1:02d}/{self.args.max_epoch:02d}], train_loss:{train_loss / len(self.train_loader):.5f}')
losses.append(round(float(train_loss) / len(self.train_loader), 5))
# 保存 fine-tuning 后的模型
model_save_path = Path(self.args.model_save_path)
if not model_save_path.exists() :
model_save_path.mkdir(parents = True, exist_ok = True)
if train_loss < min_loss :
min_loss = train_loss
torch.save(model.state_dict(), model_save_path.joinpath(f'mask_rcnn_with_{self.args.max_epoch}epochs.pth'))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--image_size', type = tuple, default = (600, 600))
parser.add_argument('--batch_size', type = int, default = 16)
parser.add_argument('--train_dir', type = str, default = 'LabPicsMedical/Train')
parser.add_argument('--num_classes', type = int, default = 2)
parser.add_argument('--device', type = str, default = "cuda:5" if torch.cuda.is_available() else "cpu")
parser.add_argument('--max_epoch', type = int, default = 10)
parser.add_argument('--model_save_path', type = str, default = 'checkpoint')
args = parser.parse_args()
solver = Solver(args)
solver.train()
test.py
import torch
import cv2
import argparse
import numpy as np
import random
from pathlib import Path
from torchvision.models.detection import maskrcnn_resnet50_fpn
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
class Solver :
def __init__(self, args):
self.args = args
def test(self):
# 这部分与训练一样
model = maskrcnn_resnet50_fpn(pretrained = True)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes = self.args.num_classes)
model = model.to(self.args.device)
model.eval()
# 加载已经保存的 fine-tuning 模型
ckpt = torch.load(Path(self.args.model_save_path).joinpath(f'mask_rcnn_with_{self.args.max_epoch}epochs.pth').__str__())
model.load_state_dict(ckpt)
# 读入图片数据并进行维度转换等操作
imgs = cv2.imread(self.args.test_img_path)
imgs = cv2.resize(imgs, self.args.image_size)
imgs = cv2.cvtColor(imgs, cv2.COLOR_BGR2RGB)
imgs = torch.as_tensor(imgs, dtype = torch.float32).unsqueeze(0)
imgs = imgs.permute(0, 3, 1, 2)
imgs = [img.to(self.args.device) for img in imgs]
with torch.no_grad() :
# 预测
pred = model(imgs)
im = imgs[0].permute(1, 2, 0).detach().cpu().numpy().astype(np.uint8)
im = cv2.cvtColor(im, cv2.COLOR_RGB2BGR)
im2 = im.copy()
showed = 0
for i in range(len(pred[0]['masks'])):
# mask,[i, 0] 之所以要有 0,是因为 mask 输出维度为 [N, 1, H, W]
msk = pred[0]['masks'][i, 0].detach().cpu().numpy()
# 置信度
showed = pred[0]['scores'][i].detach().cpu().numpy()
# 置信分数超过 0.5 则接受该 mask
if showed > 0.5:
# 得到最终的分割掩膜,对软掩膜进行阈值处理,一般取值为 0.5
im2[:, :, 0][msk > 0.5] = random.randint(0, 255)
im2[:, :, 1][msk > 0.5] = random.randint(0, 255)
im2[:, :, 2][msk > 0.5] = random.randint(0, 255)
cv2.imwrite(f'{str(showed)}.jpg', np.hstack([im, im2]))
# cv2.imshow(str(showed), np.hstack([im, im2]))
# cv2.waitKey()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--image_size', type = tuple, default = (600, 600))
parser.add_argument('--test_img_path', type = str, default = 'LabPicsMedical/Test/9Eval_IVbags/Image.jpg')
parser.add_argument('--num_classes', type = int, default = 2)
parser.add_argument('--device', type = str, default = "cuda:5" if torch.cuda.is_available() else "cpu")
parser.add_argument('--max_epoch', type = int, default = 10)
parser.add_argument('--model_save_path', type = str, default = 'checkpoint')
args = parser.parse_args()
solver = Solver(args)
solver.test()
分割结果:
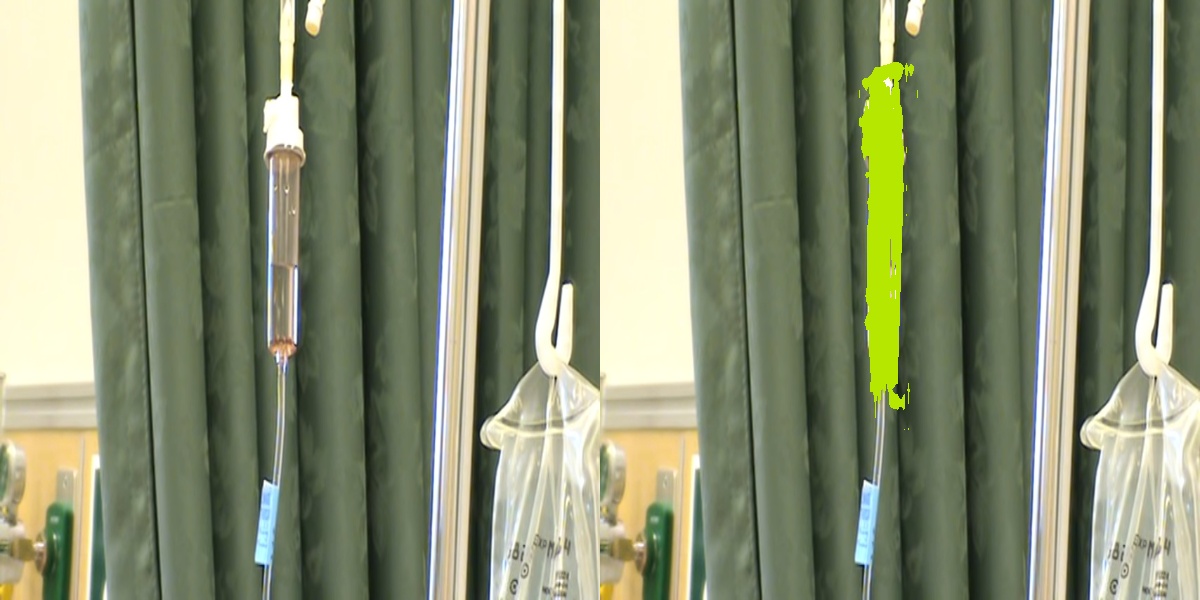
如果单看对针管的分割,效果还是很不错的。但是模型只分割出了针管,右下方的医疗袋没分割出来,需要调一下参数。
参数可在此处下载 https://drive.google.com/file/d/1oERLJzAel8CB2iBWfDJNqy5KwXpJhVvU/view?usp=sharing