目录
Apache Hadoop生态-目录汇总-持续更新
1:taildir source
2:kafka source
3:exec source(tail -F)
4:netcat source(采集端口)
5:spoolDir读取目录文件(文件更新不同步)
Apache Hadoop生态-目录汇总-持续更新
系统环境:centos7
Java环境:Java8
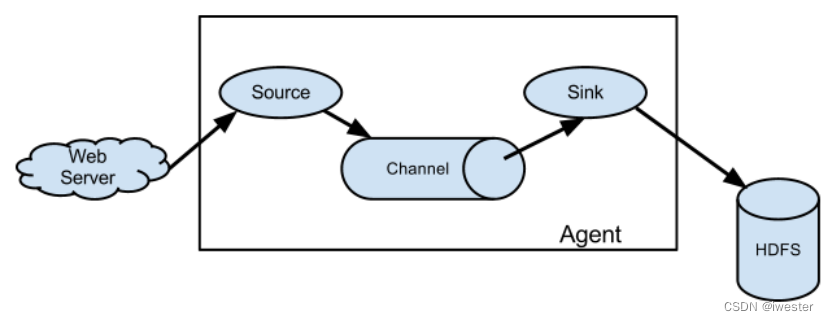
1:taildir source
# 1:定义组件
file_flume_kafka.sources = r1
file_flume_kafka.channels = c1
file_flume_kafka.sinks = k1
# 2:定义source
file_flume_kafka.sources.r1.type = TAILDIR
file_flume_kafka.sources.r1.positionFile = /usr/local/flume-1.9.0/project_v4/tail_dir.json
file_flume_kafka.sources.r1.fileSuffix = .COMPLETED
file_flume_kafka.sources.r1.filegroups = f1
file_flume_kafka.sources.r1.filegroups.f1 = /log/app.*.log
### 多个文件夹写法
#file_flume_kafka.sources.r1.filegroups = f1 f2
#file_flume_kafka.sources.r1.filegroups.f1 = /log/app.*.log
#file_flume_kafka.sources.r1.filegroups.f2 = /log2/app.*.log.*
## 定义source拦截器(ETL数据清洗,判断数据是否完整)
file_flume_kafka.sources.r1.interceptors = i1
file_flume_kafka.sources.r1.interceptors.i1.type = com.wester.flume.interceptor.ETLInterceptor$Builder
# 3:定义channel
....
这里主要介绍sources顾这里省略,到channel模块查看写法
# 4:定义sink
....
这里主要介绍sources顾这里省略,到sink模块查看写法
# 5:定义关联关系
file_flume_kafka.sources.r1.channels = c1
file_flume_kafka.sinks.k1.channel = c12:kafka source
# 1:定义组件
kafka_flume_hdfs.sources = r1
kafka_flume_hdfs.channels = c1
kafka_flume_hdfs.sinks = k1
# 2:定义source
kafka_flume_hdfs.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
kafka_flume_hdfs.sources.r1.kafka.bootstrap.servers = 192.168.5.103:9092,192.168.5.87:9092,192.168.5.114:9092
kafka_flume_hdfs.sources.r1.kafka.topics = project_v4_topic_log
kafka_flume_hdfs.sources.r1.batchSize = 5000
kafka_flume_hdfs.sources.r1.batchDurationMillis = 2000
#从头开始消费-非实时场景常使用
kafka_flume_hdfs.sources.r1.kafka.consumer.auto.offset.reset = earliest
## 配置时间连接器(解决零点漂移问题)
kafka_flume_hdfs.sources.r1.interceptors = i1
kafka_flume_hdfs.sources.r1.interceptors.i1.type = com.wester.flume.interceptor.TimeStampInterceptor$Builder
# 3:定义channel
....
这里主要介绍sources顾这里省略,到channel模块查看写法
# 4:定义sink
....
这里主要介绍sources顾这里省略,到sink模块查看写法
# 5:定义关联关系
kafka_flume_hdfs.sources.r1.channels = c1
kafka_flume_hdfs.sinks.k1.channel = c13:exec source(tail -F)
exec 即 execute 执行的意思。表示执行Linux 命令来读取文件
# 1:定义组件
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# 2:定义source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /logs/app.log
# 3:定义channel
....
这里主要介绍sources顾这里省略,到channel模块查看写法
# 4:定义sink
....
这里主要介绍sources顾这里省略,到sink模块查看写法
# 5:定义关联关系
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c24:netcat source(采集端口)
# 1:定义组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2:定义source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.1.100
a1.sources.r1.port = 44444
# 3:定义channel
....
这里主要介绍sources顾这里省略,到channel模块查看写法
# 4:定义sink
....
这里主要介绍sources顾这里省略,到sink模块查看写法
# 5:定义关联关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1netcat使用
(1)安装 netcat 工具
$ sudo yum install -y nc
(2)判断 44444 端口是否被占用
$ sudo netstat -nlp | grep 44444
(3)使用 netcat 工具向本机的 44444 端口发送内容
$ nc localhost 44444
abcd
这边输入内容5:spoolDir读取目录文件(文件更新不同步)
# 1:定义组件
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# 2:定义source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /upload # 同步的文件夹
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp 结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# 3:定义channel
....
这里主要介绍sources顾这里省略,到channel模块查看写法
# 4:定义sink
....
这里主要介绍sources顾这里省略,到sink模块查看写法
# 5:定义关联关系
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3