前言
本人是web后端研发,习惯使用spring boot 相关框架,因此技术选型直接使用的是spring boot,目前并未使用 spring-data-hadoop 依赖,因为这个依赖已经在 2019 年终止了,可以点击查看 ,所以我这里使用的是自己找的依赖,
声明:此依赖可能和你使用的不兼容,我这个适用于我自己的CDH配套环境,如果遇到不兼容情况,自行修改相关版本即可
代码库地址:https://github.com/lcy19930619/cdh-demo
认识Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop 中的HDFS 是CDH数据系统中的核心存储单元,也是学习其他组件的基础
组成
NameNode
- NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责
管理文件系统名称空间和控制外部客户机的访问。 - NameNode 决定是否将文件映射到 DataNode 上的复制块上。对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上
- 实际的 I/O事务并
没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode - NameNode 在一个称为 FsImage 的文件中存储所有关于文件系统名称空间的信息。这个文件和一个包含所有事务的记录文件( EditLog)将存储在 NameNode 的本地文件系统上。FsImage 和 EditLog 文件也需要复制副本,以防文件损坏或 NameNode 系统丢失
- NameNode本身不可避免地具有单点失效的风险,主备模式并不能解决这个问题,通过Hadoop Non-stop namenode才能实现100% uptime可用时间
DataNode
- DataNode 也是一个通常在 HDFS实例中的单独机器上运行的软件。
- Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以
机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度 DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。NameNode 依赖来自每个 DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块文件操作
核心部分
HDFS
- HDFS 是Apache Hadoop Core项目的一部分。它存储 Hadoop 集群中所有存储节点上的文件
- HDFS 是指被设计成适合运行在通用硬件上的分布式文件系统。
- HDFS 是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
- 存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(1.x版本默认为 64MB,2.x版本默认为128MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
- HDFS 并不是一个万能的文件系统。它的主要目的是支持以流的形式访问写入的大型文件
MapReduce 计算引擎
- 该引擎由 JobTrackers 和 TaskTrackers 组成
- 该引擎位于HDFS上层
- MapReduce是一个基于集群的高性能并行计算平台。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
- MapReduce是一个并行计算与运行软件框架。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
- MapReduce是一个并行程序设计模型与方法。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理
使用CDH 创建 HDFS 集群
添加服务
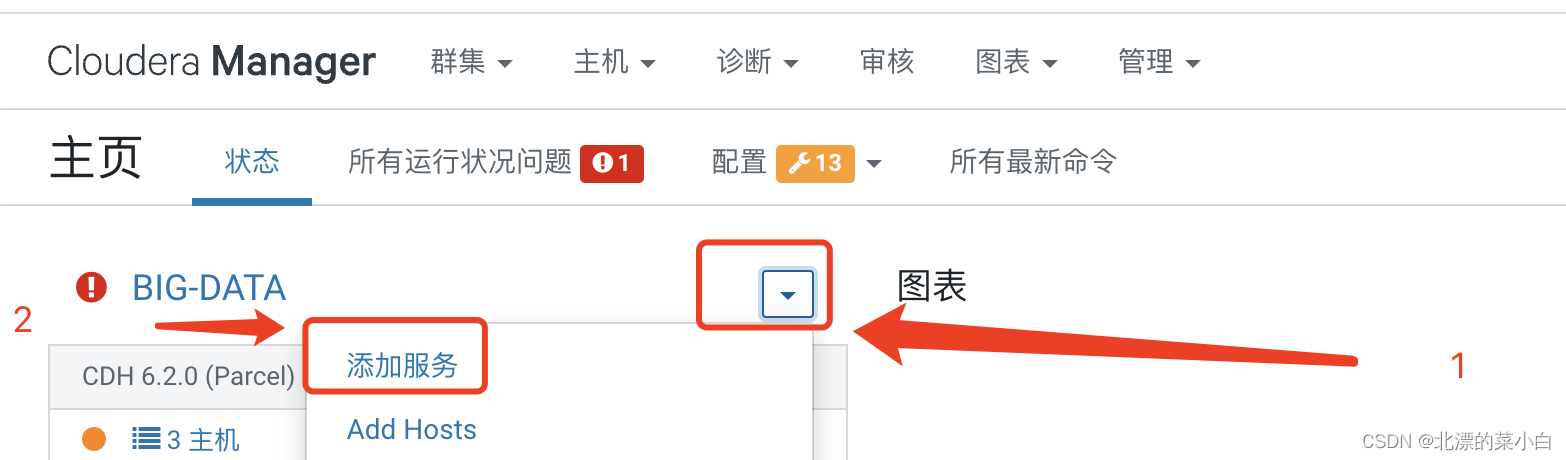
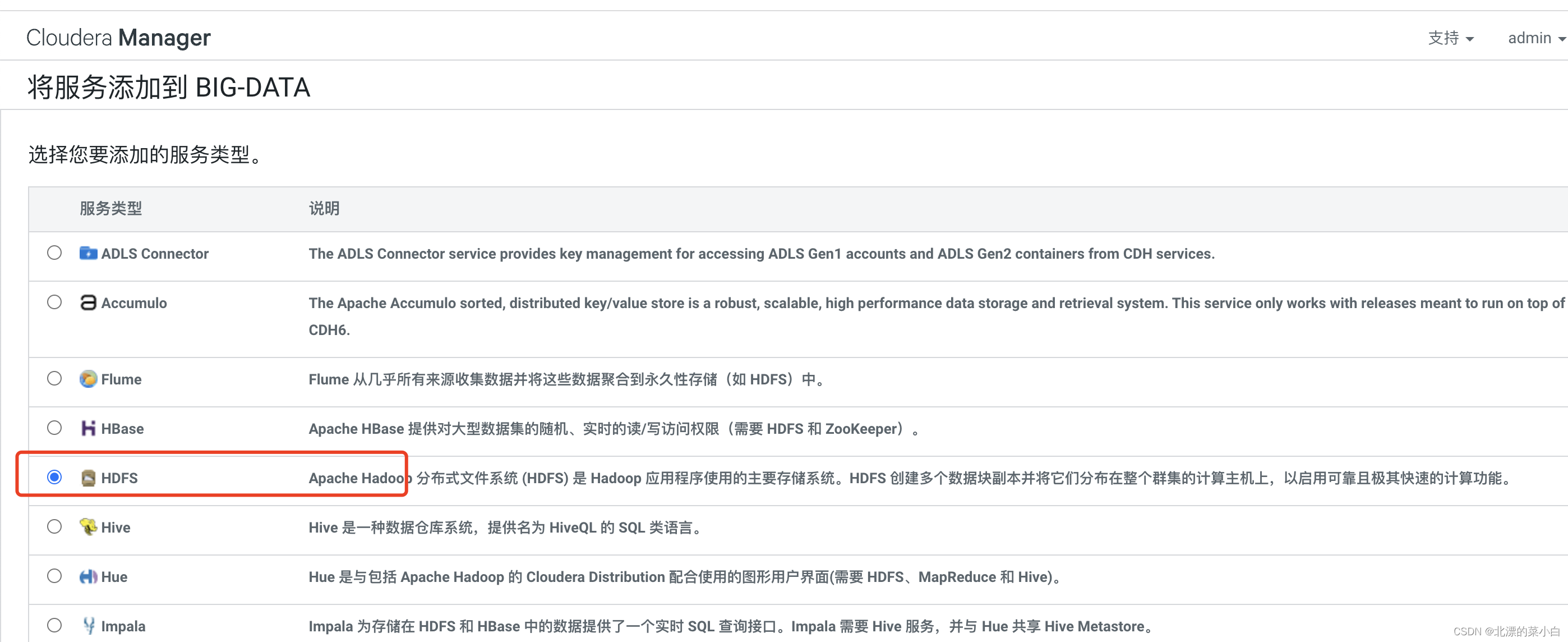
角色分配
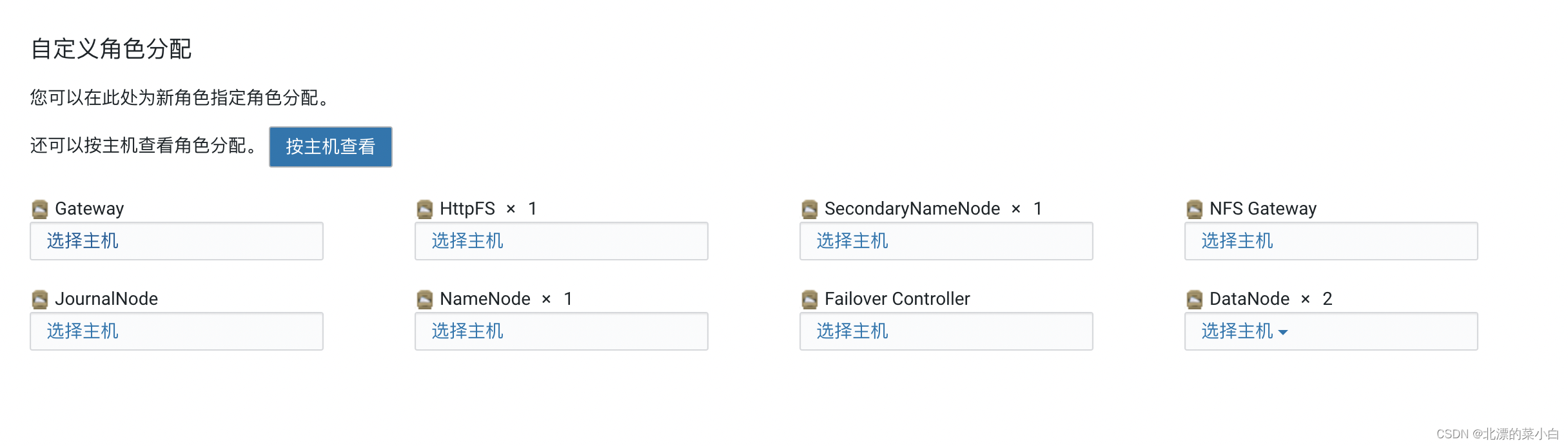
修改HDFS配置,允许外部访问
搜索关键值 ‘绑定到通配符地址’
添加完成
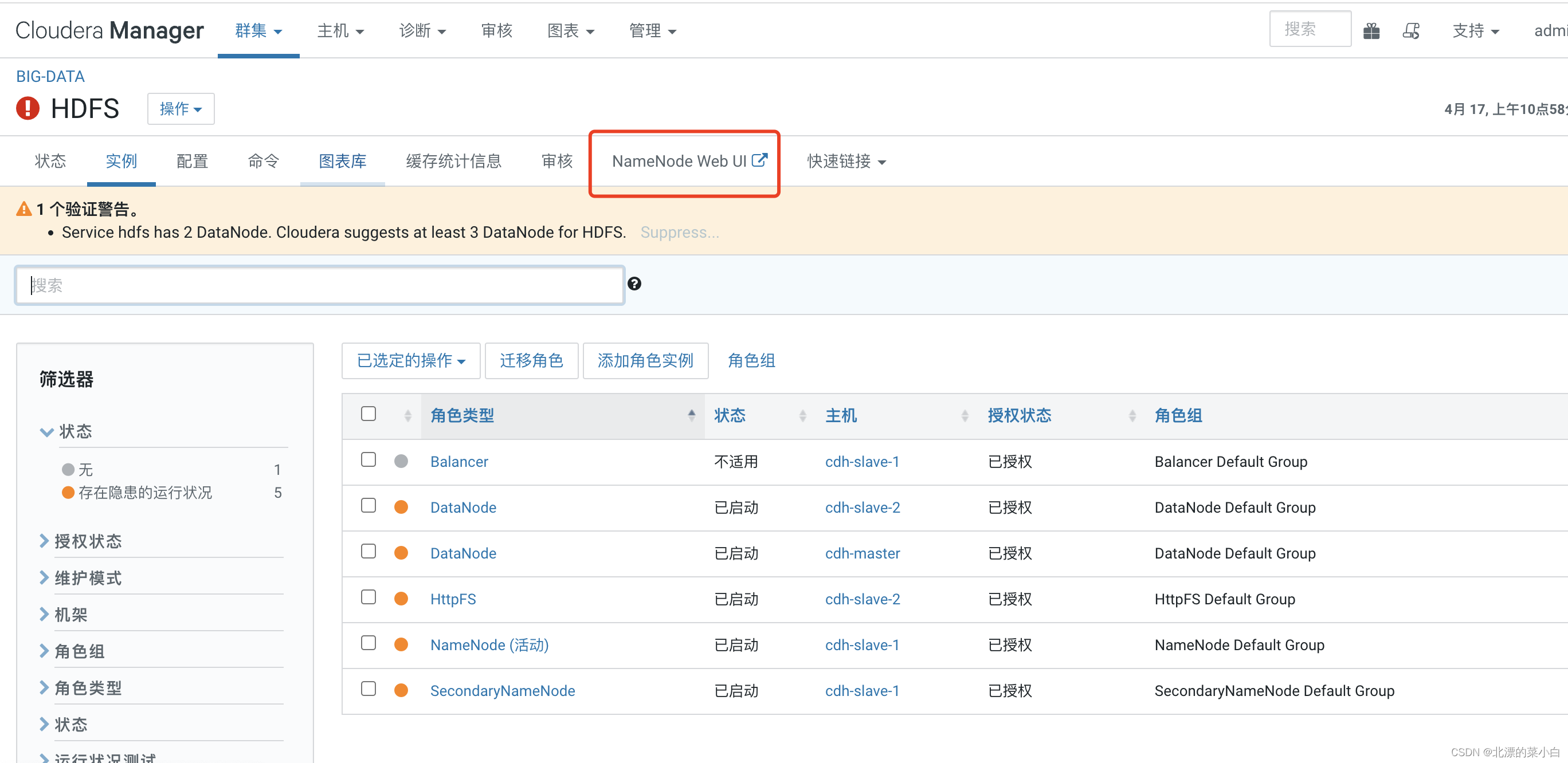
点击红款部分,访问 NameNode 检查集群情况
检查集群
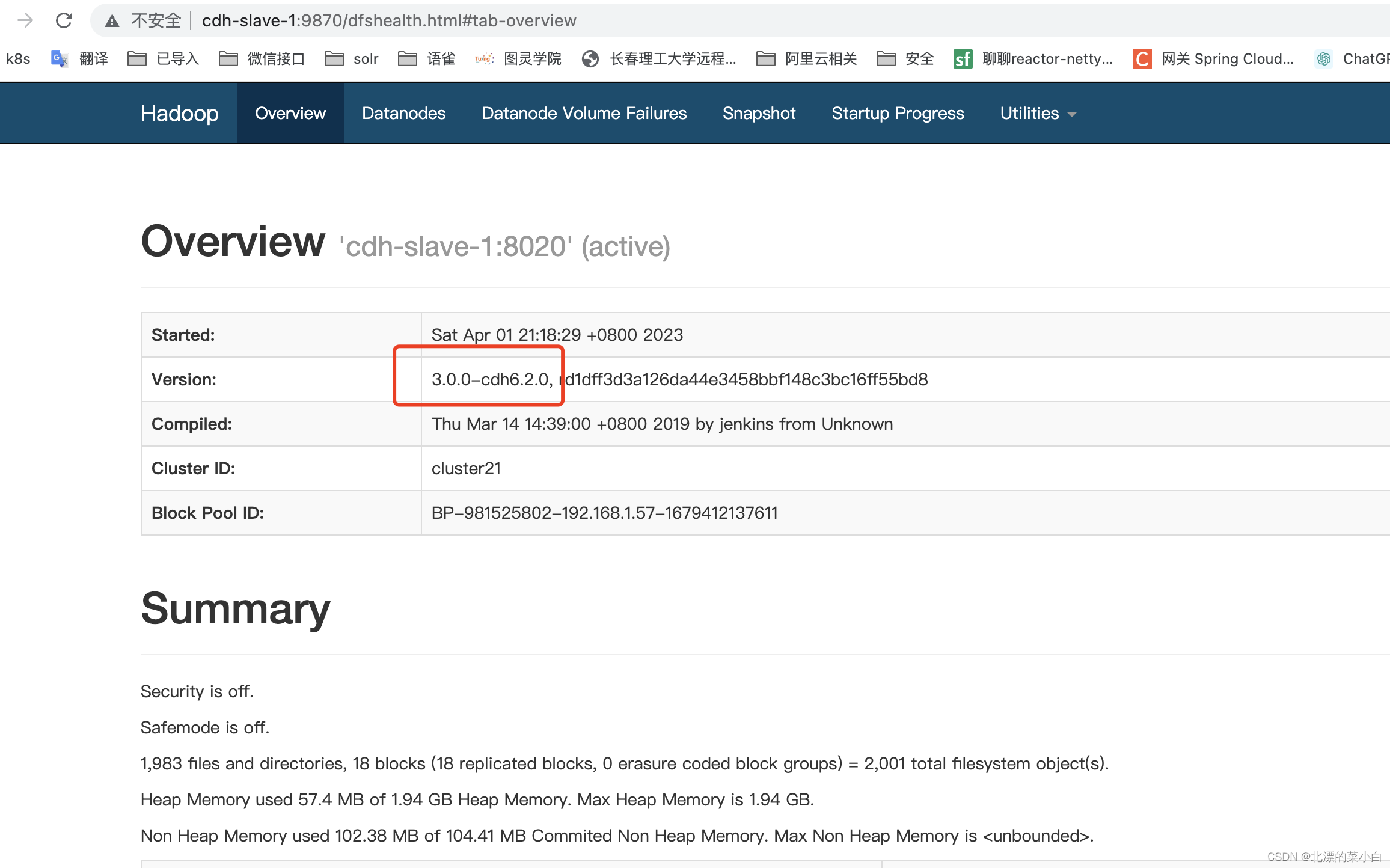
可以看到 hadoop 正常启动,且集群版本为 ``
使用 Spring Boot 操作Hadoop
新建项目
一定要添加 Cloudera仓库
<repositories>
<repository>
<id>cloudera.repo</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
pom文件内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>cdh-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>cdh-demo</name>
<description>cdh-demo</description>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
<hadoop.version>3.0.0-cdh6.2.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-reload4j</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-reload4j</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-reload4j</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<artifactId>slf4j-reload4j</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>cloudera.repo</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<mainClass>com.example.cdh.CdhDemoApplication</mainClass>
<skip>true</skip>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
YML 文件
hadoop:
# 我的 hdfs namenode 在 slave-1这台机器上
url: hdfs://cdh-slave-1:8020
replication: 3
blockSize: 2097152
user: root
Hadoop 属性配置类
package com.example.cdh.properties;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
/**
* @author chunyang.leng
* @date 2023-04-17 10:31
*/
@Configuration
@ConfigurationProperties(prefix = "hadoop")
public class HadoopProperties {
/**
* namenode 地址,示例:hdfs://cdh-master:8020
*/
private String url;
/**
* 分片数量
*/
private String replication;
/**
* 块文件大小
*/
private String blockSize;
/**
* 操作的用户
*/
private String user;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getReplication() {
return replication;
}
public void setReplication(String replication) {
this.replication = replication;
}
public String getBlockSize() {
return blockSize;
}
public void setBlockSize(String blockSize) {
this.blockSize = blockSize;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
}
Hadoop 自动装配类
package com.example.cdh.configuration;
import com.example.cdh.properties.HadoopProperties;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.springframework.context.annotation.Bean;
/**
* @author chunyang.leng
* @date 2023-04-17 10:40
*/
@org.springframework.context.annotation.Configuration
public class HadoopAutoConfiguration {
@Bean
public FileSystem fileSystem(
HadoopProperties hadoopProperties) throws URISyntaxException, IOException, InterruptedException {
// 获取连接集群的地址
URI uri = new URI(hadoopProperties.getUrl());
// 创建一个配置文件
Configuration configuration = new Configuration();
// 设置配置文件中副本的数量
configuration.set("dfs.replication", hadoopProperties.getReplication());
// 设置配置文件块大小
configuration.set("dfs.blocksize", hadoopProperties.getBlockSize());
// 获取到了客户端对象
return FileSystem.get(uri, configuration, hadoopProperties.getUser());
}
}
操作HDFS
HDFS 操作类
package com.example.cdh.service;
import java.io.IOException;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* @author chunyang.leng
* @date 2023-04-17 11:06
*/
@Component
public class HdfsService {
@Autowired
private FileSystem fileSystem;
/**
* 上传文件到 HDFS
* @param data 文件数据
* @param url 文件名称和路径
* @param overwrite 是否允许覆盖文件
*/
public void uploadFile(byte[] data, String url,boolean overwrite) throws IOException {
try (FSDataOutputStream stream = fileSystem.create(new Path(url), overwrite)){
IOUtils.write(data, stream);
}
}
/**
* 下载文件到本地
* @param url
* @return
*/
public void download(String url, OutputStream outputStream) throws IOException {
Path path = new Path(url);
try (FSDataInputStream open = fileSystem.open(path)){
IOUtils.copy(open, outputStream);
}
}
/**
* 遍历全部文件,并返回所有文件路径
* @param url
* @param recursive 是否为递归遍历
* @return
* @throws IOException
*/
public List<Path> listFiles(String url,boolean recursive) throws IOException {
Path path = new Path(url);
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(path, true);
List<Path> list= new ArrayList<Path>();
while (iterator.hasNext()){
LocatedFileStatus file = iterator.next();
Path filePath = file.getPath();
list.add(filePath);
}
return list;
}
/**
* 删除文件
* @param path 文件路径
* @param recursive 是否为递归删除
* @throws IOException
*/
public void delete(String path,boolean recursive) throws IOException{
fileSystem.delete(new Path(path),recursive);
}
}
HDFS 单元测试
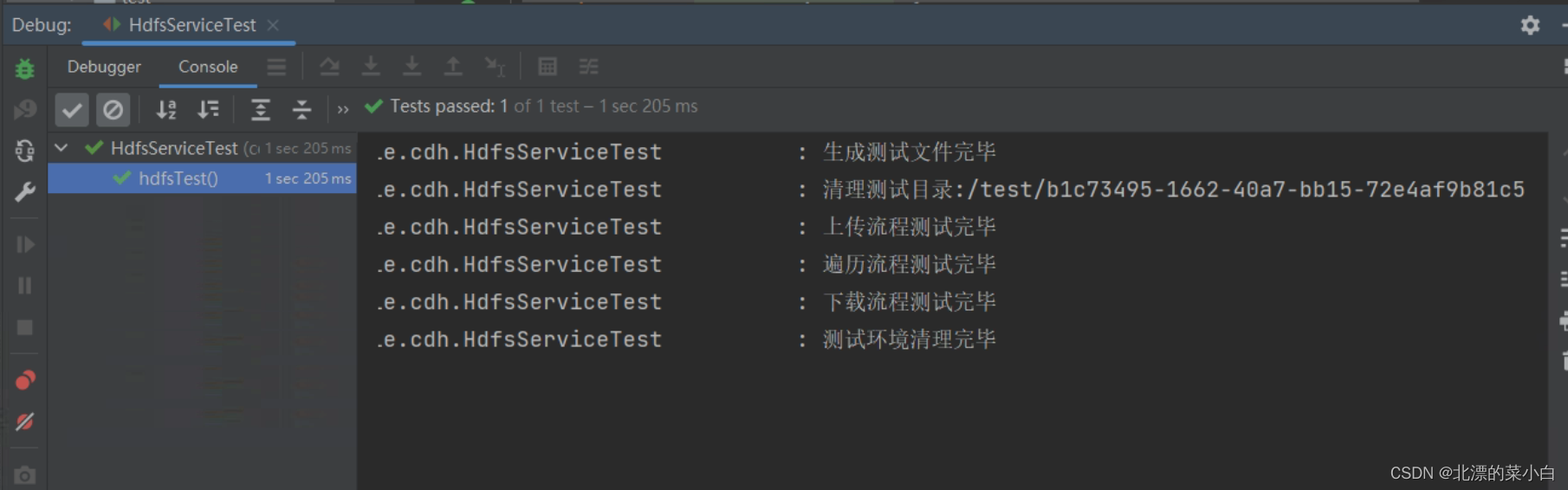
使用单元测试操作hdfs
- 使用UUID,生成简短测试文件内容
- 清理掉HDFS 测试目录内容,防止出现错误目录
- 将测试文件通过HDFS操作类,上传到HDFS中
- 使用遍历封装的接口,确认数据上传成功
- 使用下载接口,下载刚刚上传的文件内容
- 将初始文件内容、下载后的文件内容分别生成MD5摘要
- 计算两个MD5应该相同
- 使用删除接口,清理HDFS测试环境
- 使用删除功能,删除本地测试文件
package com.example.cdh;
import com.example.cdh.service.HdfsService;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.UUID;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.fs.Path;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.Assert;
import org.springframework.util.CollectionUtils;
import org.springframework.util.DigestUtils;
/**
* @author chunyang.leng
* @date 2023-04-17 11:26
*/
@SpringBootTest
public class HdfsServiceTest {
private static final Logger logger = LoggerFactory.getLogger(HdfsServiceTest.class);
String fileContent = UUID.randomUUID().toString();
@Autowired
private HdfsService hdfsService;
@Test
public void hdfsTest() throws IOException {
File testFile = new File("./test", "hdfs-test.txt");
FileUtils.writeStringToFile(testFile,fileContent,"utf-8");
logger.info("生成测试文件完毕");
byte[] before = FileUtils.readFileToByteArray(testFile);
String testPath = "/test/" +UUID.randomUUID().toString();
hdfsService.delete(testPath,true);
logger.info("清理测试目录:{}",testPath);
String hdfsFilePath = testPath +"/test.txt";
hdfsService.uploadFile(before,hdfsFilePath,true);
logger.info("上传流程测试完毕");
List<Path> paths = hdfsService.listFiles(testPath, true);
Assert.isTrue(!CollectionUtils.isEmpty(paths),"测试目录不应该为空");
logger.info("遍历流程测试完毕");
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
hdfsService.download(hdfsFilePath,outputStream);
byte[] after = outputStream.toByteArray();
String beforeMd5 = DigestUtils.md5DigestAsHex(before);
String afterMd5 = DigestUtils.md5DigestAsHex(after);
Assert.isTrue(beforeMd5.equals(afterMd5),"上传与下载的文件内容应该一致");
logger.info("下载流程测试完毕");
hdfsService.delete(testPath,true);
testFile.delete();
logger.info("测试环境清理完毕");
}
}
HDFS 测试结果
MapReduce
执行流程
-
切分输入数据:MapReduce会将输入数据切分成若干个小块,让不同的Map任务来处理这些小块。
-
执行Map任务:对于每一个Map任务,MapReduce框架会调用Map函数来处理该任务所负责的输入数据块。Map函数可以根据输入数据生成若干个键值对,这些键值对可以是简单的数据类型(如整数、字符串等),也可以是自定义的数据类型。Map函数执行完毕后,会将生成的键值对按照键的哈希值分发给不同的Reduce任务。
-
执行Shuffle过程:MapReduce框架会将所有Map任务生成的键值对按照键的哈希值发送到不同的Reduce任务。这个过程被称为Shuffle过程。Shuffle过程是MapReduce框架中最耗时的操作之一。
-
执行Reduce任务:每一个Reduce任务会收到多个Map任务发来的键值对,并根据键将这些键值对进行合并,并执行Reduce函数来生成最终的输出结果。Reduce函数的输入和输出可以是简单的数据类型(如整数、字符串等),也可以是自定义的数据类型。
-
输出结果:所有Reduce任务执行完毕后,MapReduce框架会将最终的输出结果写入输出文件或输出数据库中,然后输出结果。
编程模型
用户编程的程序分成三个部分:Mapper、Reducer、Driver。
- Mapper:
- 用户自定义的Mapper要继承自己的父类
- Mapper的输入数据是KV对的形式(KV的类型可自定义)
- Mapper中的业务逻辑写在map()方法中
- Mapper的输出数据是KV对的形式(KV的类型可自定义)
- map()方法(MapTask进程)对每一个<K,V>调用一次
- Reduce
- 用户自定义的Reduce要继承自己的父类
- Reduce的输入数据类型对应Mapper的输出数据类型,也是KV
- Reducer的业务逻辑写在reduce()方法中
- Reduce Task进程对每一组相同的<K,V>组调用一次reduce()方法
- Driver : Driver是对本次Job相关参数内容的一层封装
JAVA 类型 与Hadoop writable 类型 映射
| Java类型 | Hadoop writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
测试用例
- 编写测试 Mapper、Reduce、Driver
- 统计 HDFS 一段数据中,每个非空白字符的使用数量
- 将结果写入到HDFS中,并将结果打印到控制台
测试Mapper
package com.example.cdh.service.mapreduce.wordcount;
import java.io.IOException;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author chunyang.leng
* @date 2023-04-17 13:26
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final Text outK = new Text();
private final IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key,
Text value,
Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
char[] chars = line.toCharArray();
for (char aChar : chars) {
String str = Character.toString(aChar);
if (StringUtils.isBlank(str)){
continue;
}
outK.set(str);
context.write(outK, outV);
}
}
}
测试Reduce
package com.example.cdh.service.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author chunyang.leng
* @date 2023-04-17 13:27
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
测试Driver
package com.example.cdh.service.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author chunyang.leng
* @date 2023-04-17 13:27
*/
public class WordCountDriver {
private final Job instance;
public WordCountDriver(String inputPath, String outputPath) throws IOException {
JobConf jobConf = new JobConf();
// 设置要计算的文件读取路径
jobConf.set(FileInputFormat.INPUT_DIR,inputPath);
// 设置计算结果存储路径
jobConf.set(FileOutputFormat.OUTDIR,outputPath);
// 1.创建job实例
instance = Job.getInstance(jobConf);
// 2.设置jar
instance.setJarByClass(WordCountDriver.class);
// 3.设置Mapper和Reducer
instance.setMapperClass(WordCountMapper.class);
instance.setReducerClass(WordCountReducer.class);
// 4.设置map输出的kv类型
instance.setMapOutputKeyClass(Text.class);
instance.setMapOutputValueClass(IntWritable.class);
// 5.设置最终输出的kv类型
instance.setOutputKeyClass(Text.class);
instance.setOutputValueClass(IntWritable.class);
}
/**
* 提交 job 运行
* @throws IOException
* @throws InterruptedException
* @throws ClassNotFoundException
*/
public void run() throws IOException, InterruptedException, ClassNotFoundException {
instance.waitForCompletion(true);
}
}
测试类
package com.example.cdh;
import com.example.cdh.service.HdfsService;
import com.example.cdh.service.mapreduce.WordCountJob;
import java.io.ByteArrayOutputStream;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.UUID;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.jupiter.api.Test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
/**
* @author chunyang.leng
* @date 2023-04-17 15:28
*/
@SpringBootTest
public class MapReduceTest {
private static final Logger logger = LoggerFactory.getLogger(MapReduceTest.class);
String context = "Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can \"just run\". " +
"We take an opinionated view of the Spring platform and third-party libraries so you can get started with minimum fuss. Most Spring Boot applications need minimal Spring configuration. " +
"If you’re looking for information about a specific version, or instructions about how to upgrade from an earlier release, check out the project release notes section on our wiki.";
@Autowired
private HdfsService hdfsService;
@Autowired
private WordCountJob wordCountJob;
@Autowired
private FileSystem fileSystem;
@Test
public void testMapReduce() throws Exception {
String fileName = "mapreduce.txt";
String path = "/test/" + UUID.randomUUID().toString();
String inputHdfsFilePath = path + "/" + fileName;
String outPutHdfsFile = path + "/result/";
hdfsService.delete(inputHdfsFilePath, true);
logger.info("测试环境数据清理完毕");
hdfsService.uploadFile(context.getBytes(StandardCharsets.UTF_8), inputHdfsFilePath, true);
logger.info("MapReduce 测试文本上传完毕,开始执行 word count job");
wordCountJob.runJob("hdfs://cdh-slave-1:8020" + inputHdfsFilePath, "hdfs://cdh-slave-1:8020" + outPutHdfsFile);
logger.info("MapReduce 测试job执行完毕");
List<Path> paths = hdfsService.listFiles(outPutHdfsFile, true);
for (Path resultPath : paths) {
FileStatus status = fileSystem.getFileStatus(resultPath);
if (status.isDirectory()){
continue;
}
if (status.isFile() && !resultPath.getName().startsWith("_SUCCESS")){
// 是文件,并且不是成功标识文件
try (FSDataInputStream open = fileSystem.open(resultPath);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream()){
IOUtils.copy(open, outputStream);
byte[] bytes = outputStream.toByteArray();
logger.info("任务执行完毕,获取结果:{}", new String(bytes, StandardCharsets.UTF_8));
}
}
}
hdfsService.delete(path, true);
logger.info("测试结束,清理空间完毕");
}
}
测试结果
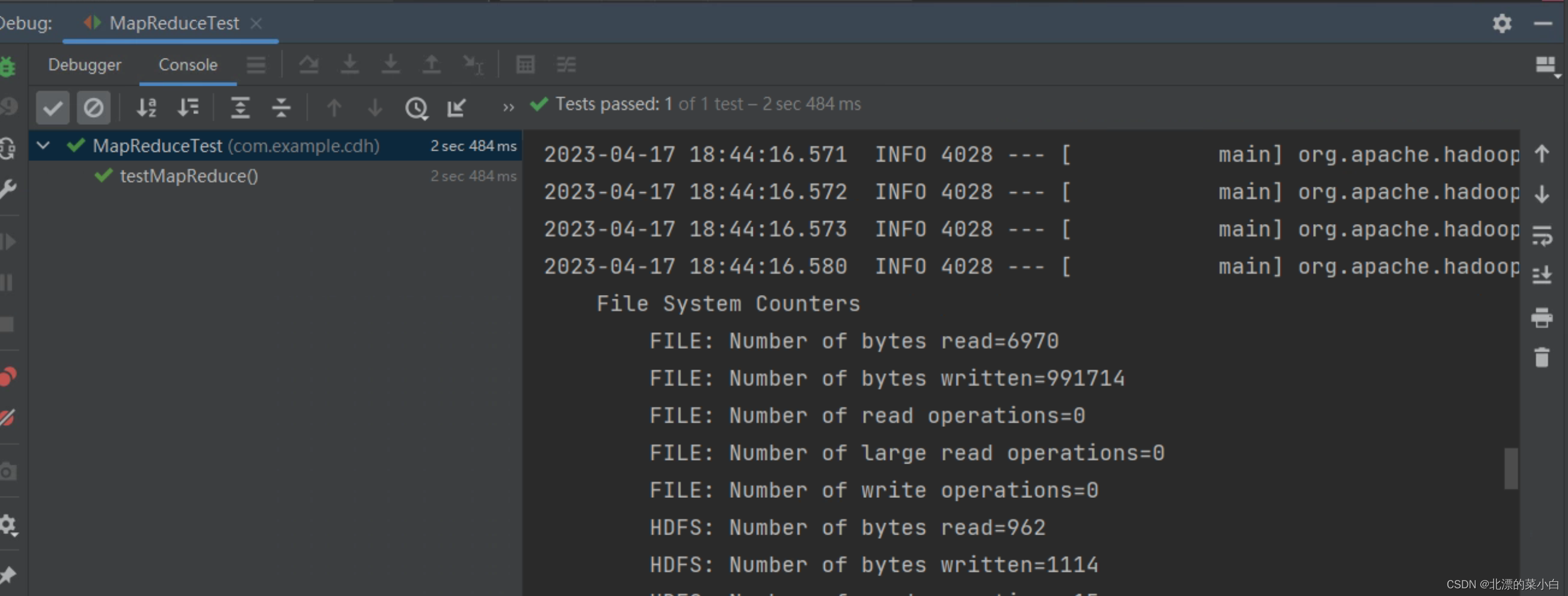
![[oeasy]python0133_[趣味拓展]好玩的unicode字符_另类字符_上下颠倒英文字符](https://img-blog.csdnimg.cn/img_convert/ff5b4f4c839700b1f5a22934ea8da0aa.png)







![[2021 东华杯]bg3](https://img-blog.csdnimg.cn/c814fb80016745fc97880bf949568051.png)