参考:
- 各种生成模型:VAE、GAN、flow、DDPM、autoregressive models
https://blog.csdn.net/zephyr_wang/article/details/126588478 - 李沐GAN精度
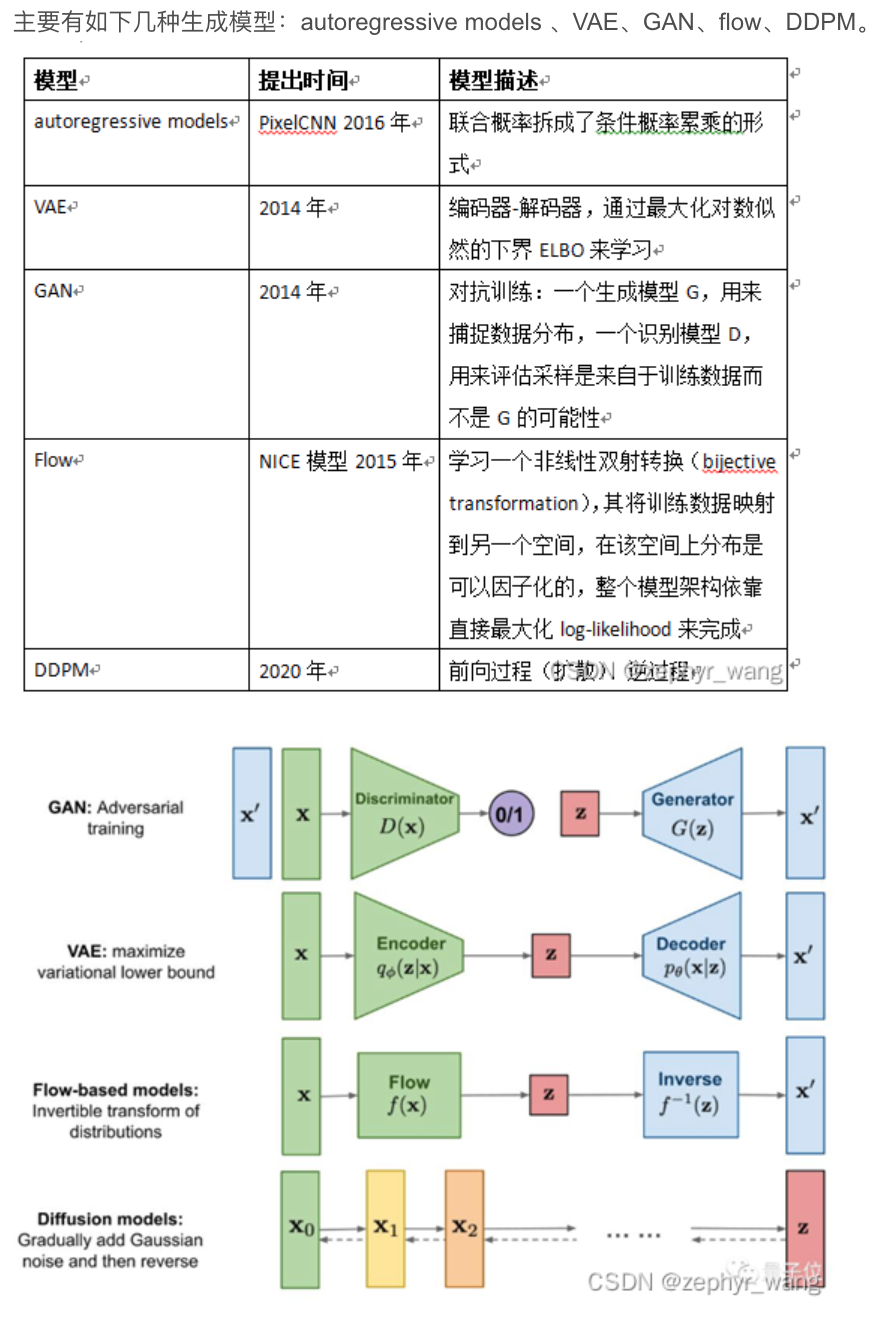
x.1 生成模型家族
DGMs(Deep Generatitve Models)家族主要有:GAN(Generative Adversarial Network),VAE(Variational autoencoder),flow,DDPM,Autoregressive models。
x.2 GANs简介
今天主要讲一下GANs。
GANs作为生成模型的一员,它分为两部分Discriminator判别器和Generator生成器。其中Discriminator用于区分真实样本与生成样本;Generator用于生成假样本来欺骗Discriminator。两者要达到nash equilibrium。
x.3 GANs痛点
GANs的主要难点如下:
- 高质量图像的生成
- 生成图像的多样化
- 训练的不稳定性
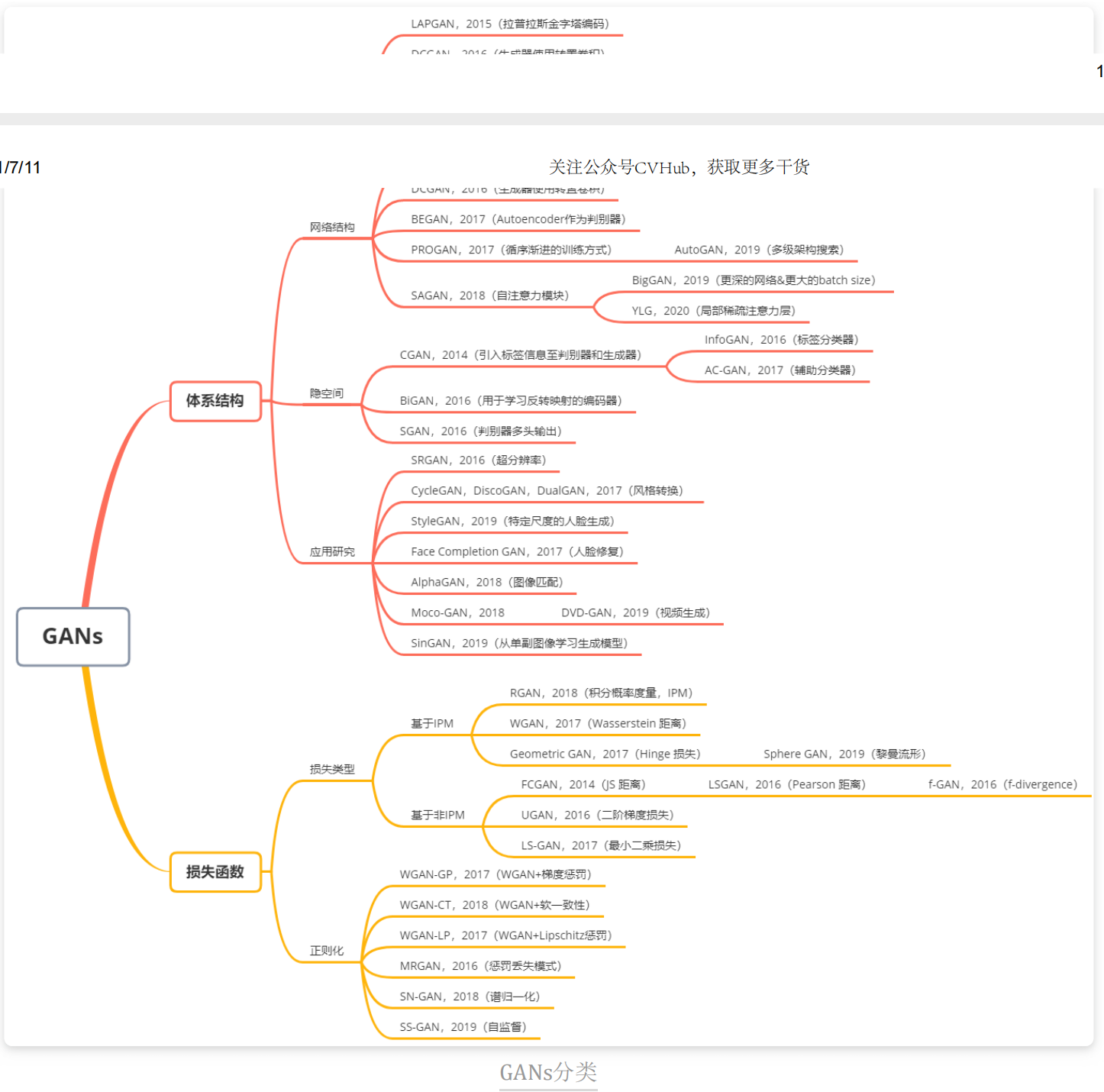
x.4 GANs分类
GANs有很多变体形式,我们主要根据以下几点对GANs的变体进行分类:体系结构变体(architecture-variant)和 损失变体(loss-variant)。其中,在体系结构变体中,我们分为三类,分别为网络结构(network architecture)、隐空间(latent space) 以及 应用研究(application-focus);对于损失变体,我们将其分成两类,损失类型和正则化。
x.5 Generative Adversarial Nets
x.5.1 GAN的创新
改文章由花书作者Ian J. Goodfellow于2014年提出。GAN提出了一个新的framework框架,并影响了后续好几万份的工作。GAN做出的贡献主要包括两点:
- 他是unsupervised-learning无监督学习,未引入标号。
- 他将supervised-learning监督学习的cost function引入无监督学习,cost func所需要的标号来自采样(training data)或者生成(generate data)。
x.5.2 GAN的网络架构
GAN的网络架构由两个模型组成,generative model G生成模型G和discriminative model D判别模型D,G和D都是由multilayer perceptrons(MLP)多层感知机构成。为了方便理解,可以将G类比为counterfeiters造假者,将D类比为police警察,两者要相互博弈,且要达到一个均衡。
DL的本质是要学习一个分布。
- 输入signal的分布,通过网络模型,使得最终的输出的分布趋近于target的分布。这便是第一种学习分布的方式,即构造出target的分布。(解析解)
- GAN并不需要学习target的分布,GAN通过随机噪声z生成一个分布,使得这个分布近似于target的分布。(逼近)
生成器
一个像素对应一个随机变量x,很多随机变量组成一个随机向量,不妨设这组随机变量独立同分布于总体的分布,即对于随机变量 x x x它的分布为 p g p_g pg。(这里的分布是指概率分布,而不是分布函数,你可是理解为分布律[离散]/概率密度函数[连续])。
同时我们具有一组随机噪声 z z z,他的分布为 p z p_z pz。
我们的生成模型为 G ( z ; θ g ) G(z; \theta_g) G(z;θg)其中 θ g \theta_g θg为可学习参数。即我们将噪声z生成了G_z。
生成器要尽量生成趋近于真实的数据,来迷惑判别器。
判别器
我们的判别模型为 D ( x ; θ d ) D(x; \theta_d) D(x;θd)其中 θ d \theta_d θd为可学习参数。
我们通过将随机变量 z z z或者 x x x输入判别器,判别器输出一个标量0或1。其中0表示假,1表示真。
判别器要尽量区分生成器生成的假图和真实的图片。
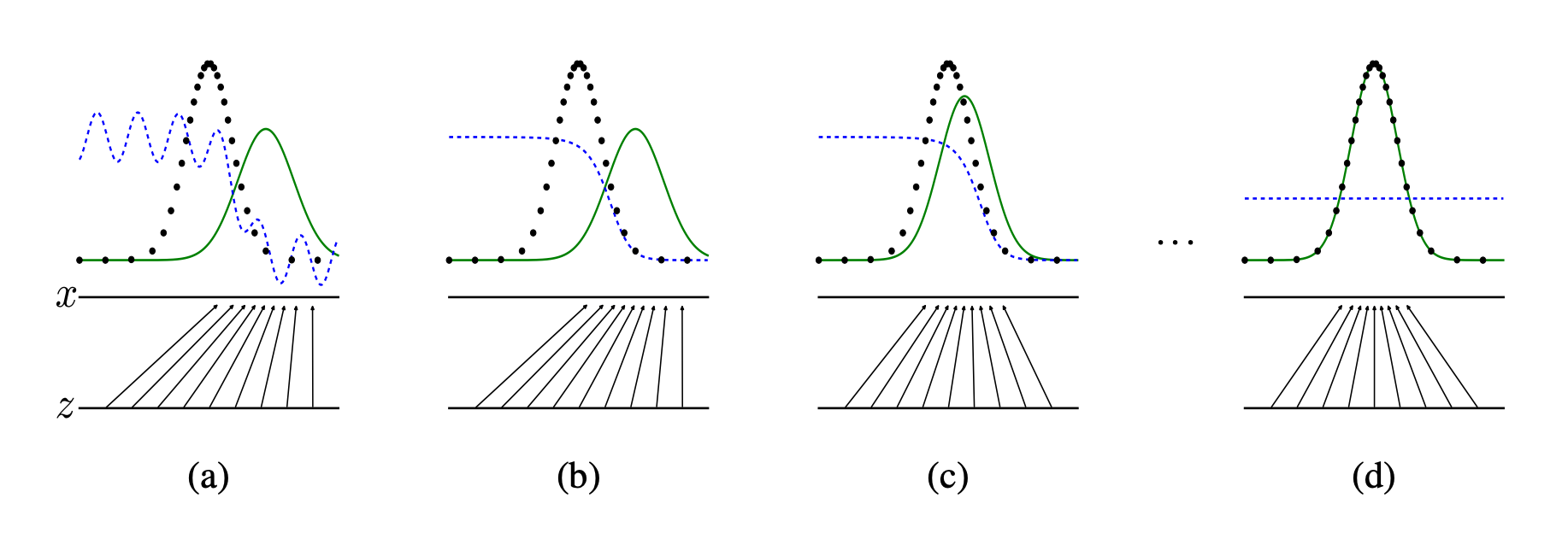
x.5.3 GAN的损失函数
GAN的损失函数是这样一个函数:对于D来说要让cost尽可能大;对于G来说要让cost可能小。
最终我们需要让G,D达到均衡——nash equilibrium。
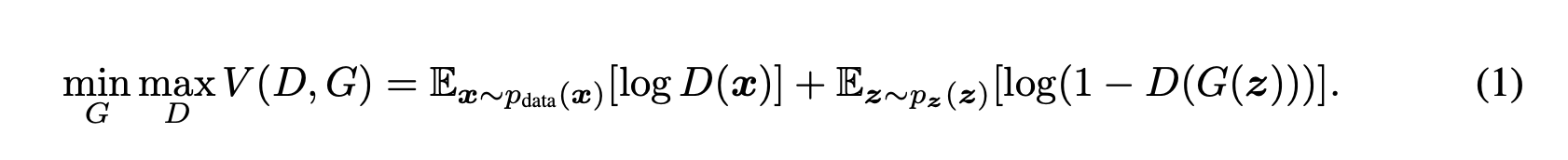
x.6 Vox2Vox
这是一个3DGan,生成器为3DUNet,判别器为3D卷积。


![[2021 东华杯]bg3](https://img-blog.csdnimg.cn/c814fb80016745fc97880bf949568051.png)