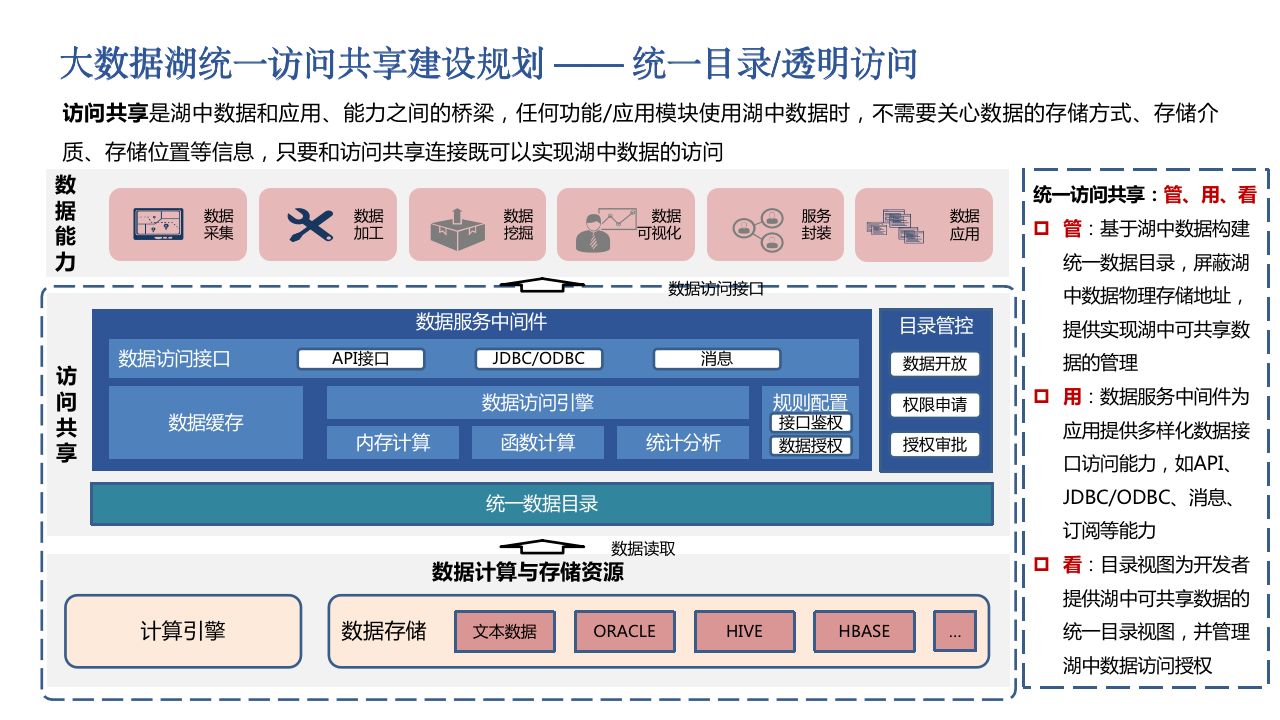
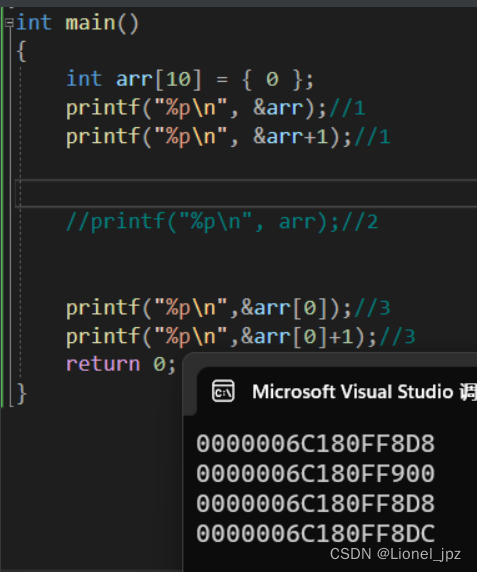
hi,各位大佬,今天尝试下diffusion大模型,也是CV领域的GPT,但需要prompt,我给了prompt结果并不咋滴,如下示例,并附代码及参考link
1、img2img
代码实现:
import torch
from PIL import Image
from diffusers import StableDiffusionImg2ImgPipeline
device = "cuda"
model_id_or_path = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe = pipe.to(device)
img_path="girl.jpeg"
init_image = Image.open(img_path).convert("RGB")
init_image = init_image.resize(( 512,768))
#init_image.resize((int(init_image.size[0]*0.6),int(init_image.size[1]*0.6) ))
prompt = "A beautiful hair "
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
images[0].save("beauty.png")原图及生成的新图对比如下:侵删


woc 网上搜的图,结果搞成这样子,也是服气了。
2、text2img
代码如下:
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a beautiful girl with blue eyes and long legs and little dress"
#"three girl,chesty"
image = pipe(prompt).images[0]
image.save("generator.png")

眼睛都有问题啊,这生成魔鬼可以,生成正常人有点难。
3、带有负向提示词的depth2img
据说哈,提示词越多越好,画得就越好,不然它就比较“自我”,比较随意画了。
import torch
import requests
from PIL import Image
from diffusers import StableDiffusionDepth2ImgPipeline
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
)
pipe.to("cuda")
img_path="seg1.jpeg"#仍旧是第一个网图
init_image = Image.open(img_path)
prompt = "handsome, beautiful, long hair, big eyes, white face"
n_propmt = "bad, deformed, ugly, bad anotomy"
image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]效果不错,除了手指有问题,这个需要加入负向提示词。


负向改为如下,生成上面右图,勉强吧,虽说不上好看,但也没畸形吧。
n_propmt="lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,bad, cartoon, ugly, deformed"
>>> init_image = Image.open(img_path)
>>> init_image=init_image.resize((int(init_image.size[0]*0.6),int(init_image.size[1]*0.6) ))
>>> image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 35/35 [00:39<00:00, 1.14s/it]
>>> image.save("seg1_d.png")
因此,对上面的text2img及img2img进行增加上述负向词再次试验,如下:正向词不变


text2img(上面右图),必须指明五官方面的词,不能有任何畸形,包括脚,腿,不然太吓人了。
负向提示词改为如下:头都没有了。。。
n_propmt="lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,bad, cartoon, ugly, deformed,bad face,bad fingers,bad leg,bad shoes, bad feet, bad arm"

上边右图相对正常了,但牙齿不太好,负向词增加“bad teeth”再次尝试,下面的图截断了。

这也太差劲了吧👎,我勒个去。这要是给客户看到立马滚蛋了。
4、高分辨率的Super-Resolution
import requests
from PIL import Image
from io import BytesIO
from diffusers import StableDiffusionUpscalePipeline
import torch
# load model and scheduler
model_id = "stabilityai/stable-diffusion-x4-upscaler"
pipeline = StableDiffusionUpscalePipeline.from_pretrained(
model_id, revision="fp16", torch_dtype=torch.float16
)
pipeline = pipeline.to("cuda")
# let's download an image
url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-
init_image = Image.open("seg1.jpeg")
init_image=init_image.resize((int(init_image.size[0]*0.1),int(init_image.size[1]*0.1) ))
prompt = "a white cat"
upscaled_image = pipeline(prompt="a beautiful Chinese girl", image=init_image).images[0]
upscaled_image.save("upsampled_cat.png")
压缩后再高分辨率的,为啥到我这里都是翻车呢?



![[2021 东华杯]bg3](https://img-blog.csdnimg.cn/c814fb80016745fc97880bf949568051.png)