Memcached是一种内存中的键值存储,最初是用Perl编写的,后来重写为C语言。它受到Facebook、Netflix和Wikipedia等公司的欢迎,因为它简单易用。
虽然当谈论到软件描述时,“简单”这个词已经失去了意义,但我认为Memcached是少数真正简单的软件之一。Memcached没有像持久性或丰富的数据类型这样的花哨特性。甚至分布式缓存也是客户端的责任,而不是Memcached服务器的责任。
Memcached的后端只有一个任务,即内存中的键值存储。
缓存是逃避行为
Memcached被用作缓存来存储耗时的数据库查询或昂贵的HTTP响应。虽然缓存对于可扩展性至关重要,但它应该被视为最后的选择,让我来解释一下。
我认为为每个遇到的耗时查询都运行一个缓存是一种逃避行为。我相信理解性能下降的原因才是关键,否则缓存只是一个权宜之计。如果是数据库查询,看看执行计划,是否需要索引?是否有很多逻辑读取,你是否可以重写查询或包含额外的预测性过滤器以最小化搜索空间?
如果是RPC调用,考虑一下为什么调用本来就是冗余的,你是否可以在客户端消除这些调用。经常情况下,当使用不当时,库和框架会发出一系列查询。这也是为什么黑盒子必须被理解的原因。
在尝试了所有的调优选项后,可能需要使用缓存,这时候Memcached是最适合的选择。
Memcached架构
在本文中,我将深入探讨Memcached的架构以及开发人员为保持其简单性和功能削减所做的努力。我将对某些组件发表自己的观点,认为它们应该是可选的。
本文将涵盖以下主题:
内存管理
线程
最近最少使用(LRU)
读/写
冲突
分布式缓存
演示
什么是Memcached?
Memcached是一个用作缓存的键值存储。它被设计为简单,因此在某些方面有一些限制。这些限制也可以看作是特性,因为它们使Memcached变得透明。
在Memcached中,键是字符串,长度限制为250个字符。值可以是任意类型,但默认情况下,值的大小限制为1 MB。键还具有过期日期或存活时间(TTL)。然而,不应依赖于此,因为最近最少使用(LRU)算法可能在访问之前删除过期的键。Memcached适用于缓存昂贵的查询,但不应依赖于其作为持久性或可靠存储。在构建应用程序时,始终假设Memcached不具备你所需的功能。为最坏情况做计划,希望发生最好的情况。
内存管理
当分配诸如数组、字符串或整数等项目时,它们通常会随机分配到进程内存中的某些位置。这会在物理内存中留下一些未使用的小内存间隙,这个问题被称为碎片化。
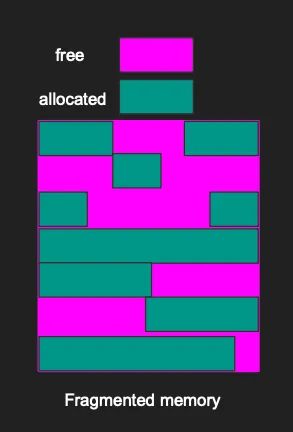
当已分配项目之间的间隙继续增加时,就会发生碎片化。这使得很难找到足够大的连续内存块来存储新项目。从技术上讲,可能有足够的内存来存储项目,但内存分散在物理空间的各个位置。
这是否意味着如果没有连续内存块存在,项目无法存储?实际上并非如此,借助虚拟内存的帮助,操作系统给出了应用程序正在使用连续内存块的错觉。在幕后,该块被映射到物理内存中的小区域。
碎片化会导致程序运行变慢,因为系统需要组装内存碎片。虚拟内存映射的开销以及获取本应是单个内存块的多次I/O操作的成本相对较高。这就是为什么我们要尽量避免内存碎片化。
Memcached通过预分配1 MB大小的内存页面来避免碎片化,这也是为什么默认情况下值被限制为1 MB。
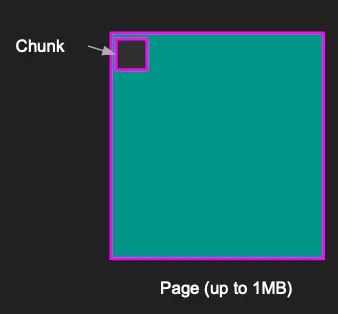
操作系统认为Memcached正在使用分配的内存,但实际上Memcached尚未在其中存储任何内容。当创建新项目时,Memcached会将项目写入分配的页面,强制使项目彼此相邻。这通过将内存管理移至Memcached而不是操作系统来避免碎片化。
页面被分割成相等大小的块(Chunk)。每个块的大小由slab class确定。slab class定义了块的大小,例如Slab class 1的块大小为72字节,而slab class 43的块大小为1MB。
项目由键、值和一些元数据组成,并存储在块中。例如,如果项目的大小为40字节,将使用整个块来存储该项目。最接近40字节项目的块大小为72字节,即slab class 1,在块中会有32字节的未使用空间。因此,客户端应该聪明地选择适合块的大小的项目,以尽量减少未使用空间。
Memcached试图通过将项目放入最合适的slab class来尽量减少未使用空间。每个slab class都有多个页面。例如,对于slab class 1,每页有14,563个块,因为每个块的大小为72字节。如果一个项目小于等于72字节,它将完美地适应该块。但如果项目更大,比如900KB,它不适合slab class 1。因此,Memcached会寻找适合该项目的slab class。最接近1MB块大小的是slab class 43,项目将放在该块中。整个项目适应单个页面。
注意我们不需要为项目分配内存,因为内存已经预先分配好了。
我们来看一个新的例子,假设有一个大小为40字节的新项目,但为该slab class分配的所有页面都已满,因此无法插入该项目。
Memcached通过分配一个新页面并将项目存储在空闲块中来处理这种情况。
线程
Memcached接受远程客户端连接,因此必须具备网络功能。Memcached使用TCP作为其主要的传输协议。虽然也支持UDP,但默认情况下已禁用,因为在2018年发生过一次称为反射攻击的攻击事件。
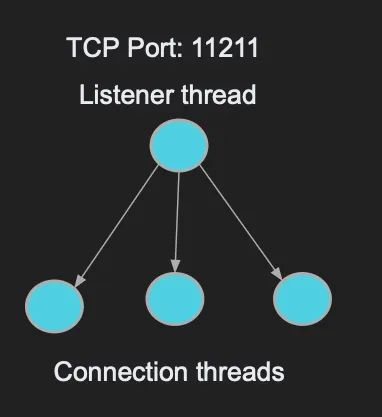
Memcached监听线程创建一个TCP套接字来监听11211端口。它有一个线程旋转并监听传入的连接。该线程创建套接字并接受传入的连接。
然后,Memcached将连接分配给线程池中的一个线程。当建立新连接时,Memcached从池中分配一个线程,并将连接的文件描述符分配给该线程。该工作线程现在负责从连接中读取数据。
如果向连接发送数据流或请求获取一个键,则该线程轮询文件描述符以读取请求。每个线程可以承载一个或多个连接,并且线程池中的线程数量可以进行配置。
多年前,线程管理更为关键,因为异步工作负载在2002年并不像2022年那样丰富。您看,当线程从连接中读取数据时,这个操作在2000年代初曾是阻塞的。线程在获取数据之前无法执行其他任何操作。工程师们意识到这是不可扩展的,于是异步I/O应运而生。几乎所有的读取调用现在都是异步的,这意味着线程可以在一个连接上调用读取操作,然后继续处理其他连接。
然而,在Memcached中,线程管理仍然很重要,因为读取/写入涉及到一些CPU时间,例如哈希和LRU计算。如果一个线程为所有连接执行这些工作,可能无法扩展。
LRU(最近最少使用)
内存的问题在于它是有限的。即使你设置了合理的过期时间,如果存储了大量的键,内存最终会被填满。当内存已满时,你会怎么做呢?
嗯,作为架构师,你有两个选择。
阻止新插入并向客户端返回错误以释放一些项目
释放旧的未使用项目
Memcached选择了后者。这就是我希望他们将其作为一个选项的地方。就好像我在与设计师们争论该怎么做。使用LRU使Memcached变得复杂,并剥夺了其纯粹的简洁性。理智的声音已经失去了,取而代之的是客户端的便利性。唉,事实就是这样。
当内存已满时,Memcached释放所有长时间未使用的内存中的项目。这也是为什么Memcached被称为瞬态内存的另一个原因。即使你将某个键的过期时间设置为一小时,你也不能指望在一小时过期之前该键一直存在。它可以在任何时候释放,这是Memcached的另一个限制(或特性!)。
Memcached使用一种称为链表LRU(最近最少使用)的数据结构,在内存已满时释放项目。Memcached键值存储中的每个项目都在链表中,每个slab class都有自己的LRU。
如果访问了一个项目,它会从当前位置移动到链表的头部。每次访问项目时都会重复这个过程。结果是,不经常使用的项目将被推到链表尾部,并在内存已满时最终被删除。
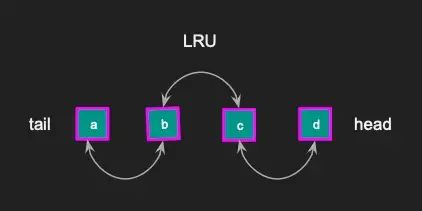
这是LRU缓存的整体图示。我从阅读源代码和Memcached文档中推导出来的。在图示中,我们有页面和块。每个块都包含在一个LRU缓存中,具有头指针和尾指针,头部和尾部之间的每个项目都彼此链接。
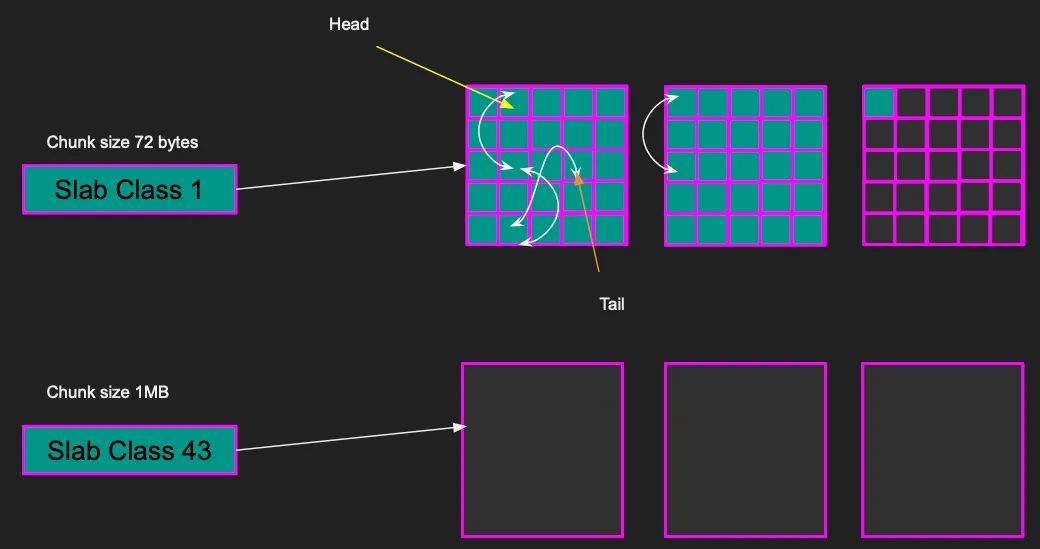
虽然LRU是有用的,但从性能上来说,它也可能非常昂贵。为了维护LRU所必需的锁可能会降低吞吐量并增加应用程序的复杂性。如果LRU可以选择禁用,Memcached可以保持简单。这将允许用户分配一定数量的内存给Memcached,而无需担心管理LRU的开销。释放项目的责任将变为客户端的责任。
LRU锁定
没有两个线程可以同时更新相同的数据结构。为了解决这个问题,需要更新内存中任何数据结构的线程必须获得互斥锁,而其他线程则等待该互斥锁释放。这是基本的锁定模型,适用于所有应用程序。Memcached与LRU数据结构一样,也使用了这种模型。
最初的Memcached设计中有一个全局锁,所有操作和LRU管理都是串行的,使得多线程效果不佳。因此,客户端不能同时访问两个不同的项目,所有读取操作都是串行的。
Memcached通过更新锁定模型,针对每个slab class引入了LRU,从而解决了这个问题。这意味着客户端可以同时访问来自不同slab class的两个项目,而无需等待。然而,当访问来自同一个slab class的两个项目时,它们仍然是串行的,因为需要更新LRU。后来,通过将LRU更新最小化为每60秒一次,改进了这个问题,允许访问多个项目。然而,这还不够好。
在2018年,Memcached彻底重新设计了LRU,通过按温度将其分解为每个slab class的子LRU,从而显著减少了锁定并改善了性能,但在同一温度下,锁定仍然存在。
现在你知道为什么我希望LRU是一个可选项了。
读取和写入
读取
让我们通过一个在Memcached中的读取示例来说明。为了确定给定键的项在内存中的位置,Memcached使用哈希表。哈希表是一种关联数组。关联数组的优点是它是连续的,这意味着如果你有一个包含1000个元素的数组,访问元素7、12、24、33或1的速度是一样的,因为你知道索引。一旦你知道了索引,你就可以立即跳转到内存中的那个位置。
在哈希表中,我们没有索引,而是有一个键。关键的技巧是将键转换为索引,然后访问元素。我们取键并计算其哈希值,然后对哈希表大小取模。让我们举个例子。
要读取键“test”,我们对“test”进行哈希计算,然后对哈希表数组的大小进行模运算。这将给我们一个介于0和N-1之间的数字。这个数字可以用来索引哈希表,并获取键的值。所有这些操作的时间复杂度为O(1)。
键的值将带您到特定slab class上的页面。当我们读取值时,我们通过将项推送到LRU链表的头部来更新slab class的LRU。这需要对LRU数据结构进行互斥锁定,以防止多个线程破坏LRU。
注意,如果尝试读取相同slab class上的两个项,则读取操作是串行的,因为需要锁定LRU。
当读取键“test”并获取到项“d”时,LRU被更新,使得“d”现在位于链表的头部。
那么如果我们读取键"buzz",指向项"c"呢?LRU被更新,使得"c"现在紧随"d"之后成为新的头部。
写入
如果我们需要写入一个新值为44字节的键,首先需要计算哈希值,并找到其在哈希表中的索引。如果索引位置为空,将创建一个新的指针,并分配一个slab class和一个chunk。然后,将项放置在内存中,并将该chunk适应于相应的slab class。
冲突
由于哈希将键映射到固定大小,两个键可能会哈希到相同的索引位置,从而引发冲突。假设我要写入一个名为“Nani”的新键。“Nani”的哈希值与另一个已存在的键发生了冲突。
为了解决这个问题,Memcached使哈希表中的每个索引映射到一个项目链,而不是直接映射到项目。我们将键“Nani”添加到该链中,该链现在有两个项目。当读取键时,需要查找链中的所有项目来确定哪个与所需键匹配,这在最坏情况下的时间复杂度为O(N)。以下是一个示例:
Memcached测量这些链的增长情况。如果增长过于剧烈,读取性能可能会受到影响。要读取一个键,必须查找整个冲突链以找到实际的键。冲突链越长,读取速度越慢。
如果读取性能开始下降,Memcached会进行哈希调整并重新分配所有项,以使结构扁平化。
分布式缓存
Memcached服务器是隔离的,服务器之间不会互相通信。我非常喜欢这种设计的简洁和优雅之处。如果要分发你的键,客户端必须自行处理,你可以构建自己的Memcached客户端来实现这一点。
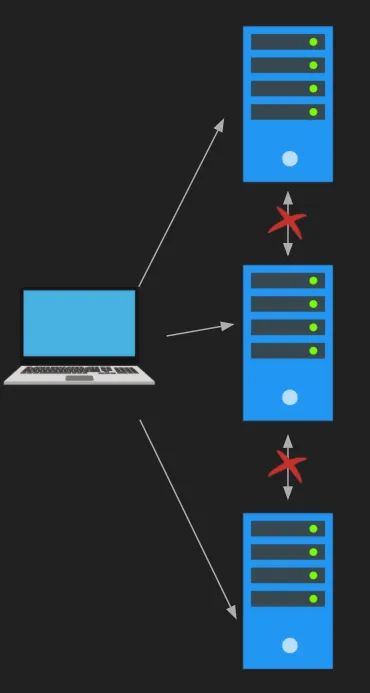
服务器之间的通信会显著复杂化架构,就像在ZooKeeper中一样。
Telnet演示
在这个演示中,我们将启动一系列Memcached Docker实例。您需要安装Docker并拥有Docker账号,因为Memcached镜像是受账号保护的。一旦您完成了这些步骤,就可以下载镜像,并且可以启动任意数量的Memcached实例。需要注意的是,Memcached不支持身份验证,因此您需要自行实现身份验证。
首先,我们要启动一个包含Memcached实例的Docker容器。可以使用以下命令来完成。我们可以添加-d以避免阻塞终端。
docker run --name mem1 -p 11211:11211 -d memcached
运行docker ps来确保镜像正在运行。
让我们使用telnet进行测试。运行telnet husseinmac 11211,将husseinmac替换为您的主机名。一旦连接成功,您就可以发出诸如stats之类的命令。
我们还可以在此控制台中设置键值对。例如,set foo 0 3600 2。foo是键的名称,0是标志,3600是TTL(生存时间),2是字符数。按下回车键后,它会提示您输入foo键的值。键的值应与在set命令中设置的字符数完全匹配。可以使用get命令读取键值对:get foo。可以使用delete命令删除键值对:delete foo。
这个演示的有趣部分是关于Memcached的架构。您会注意到,一旦添加了foo键,您可以输入stats slabs来获取slab统计信息。您将看到有一个slab类(查看STAT 1,其中1表示slab类)。此外,您还可以看到关于块、页面、命中次数、使用的总内存量等很多有趣的统计信息...
使用Node.js进行分布式Memcached
为了测试分布式缓存,Node.js提供了一个智能客户端,支持Memcached实例的连接池。首先,让我们从Node.js连接到一个单独的Memcached实例,并写入一些键。
创建一个名为nodemem的文件夹,并进入该文件夹。然后,使用npm init -y初始化项目。接下来,我们将创建一个名为index.js的文件,并填入以下内容:请注意:您需要将husseinmac替换为您的主机名。
const MEMCACHED = require("memcached");
const serverPool = new MEMCACHED(["husseinmac:11211"]);
function run() {
[1, 2, 3, 4, 5, 6, 7, 8, 9].forEach(a => serverPool.set("foo" + a, "bar" + a, 3600, err => console.log(err)))
}
run();
这段代码使用了Memcached的Node.js客户端,并初始化了一个Memcached服务器池。然后,它将格式为foo1: bar1、foo2: bar2等的九个键值对添加到Memcached服务器池中。
在运行脚本之前,我们需要使用npm install memcached安装Memcached的Node.js客户端。然后,使用以下命令运行代码:
node index.js
脚本运行后,您应该能够使用telnet连接到Memcached服务器,并使用get foo1、get foo2等命令读取键值对。所有的键值对将存储在11211服务器中。
现在,让我们启动更多的Memcached实例:
docker run --name mem2 -p 11212:11211 -d memcached
docker run --name mem3 -p 11213:11211 -d memcached
docker run --name mem4 -p 11214:11211 -d memcached
在启动容器后,您需要将这些服务器添加到Node.js脚本中的服务器池中:
const MEMCACHED = require("memcached");
const serverPool = new MEMCACHED(["husseinmac:11211",
"husseinmac:11212",
"husseinmac:11213",
"husseinmac:11214"]);
function run() {
[1, 2, 3, 4, 5, 6, 7, 8, 9].forEach(a => serverPool.set("foo" + a, "bar" + a, 3600, err => console.log(err)))
}
run();
运行此脚本后,您将注意到所有键值对将分布到所有4个服务器上。尝试一下!使用telnet连接到Memcached服务器,并运行get foo1、get foo2等命令,查看键值对在哪个服务器上。这是因为Node.js客户端根据自己的哈希算法选择池中的一个服务器来存储键值对。
对于读取操作,Node.js的Memcached客户端会进行哈希计算,找到包含该键的服务器,并向该服务器发出命令。请注意,这种哈希计算与Memcached执行的哈希计算是不同的。
const MEMCACHED = require("memcached");
const serverPool = new MEMCACHED(["husseinmac:11211",
"husseinmac:11212",
"husseinmac:11213",
"husseinmac:11214"]);
function run() {
[1, 2, 3, 4, 5, 6, 7, 8, 9].forEach(a => serverPool.set("foo" + a, "bar" + a, 3600, err => console.log(err)))
}
function read() {
[1, 2, 3, 4, 5, 6, 7, 8, 9].forEach(a => serverPool.get("foo" + a, (err, data) => console.log(data)))
}
read();
如果您使用node index.js运行此脚本,您会注意到尽管并非所有Memcached服务器都拥有全部答案,但所有值都会显示出来。
总结
在本文中,我们讨论了Memcached的架构。我们讨论了内存管理的重要性,以及使用slabs和pages来分配内存以避免碎片化的方法。我们还讨论了LRU(最近最少使用)算法,我个人认为它应该是用户可以选择禁用的选项。接下来,我们讨论了线程对于处理大量连接时如何提高性能的重要性。我们通过一些Memcached的读写示例来说明这一点,并介绍了锁定对它们的影响。最后,我们讨论了使用Node进行分布式缓存架构的演示。
如果你喜欢我的文章,点赞,关注,转发!