❀DQN算法原理
DQN,Deep Q Network本质上还是Q learning算法,它的算法精髓还是让 Q 估计 Q_{估计} Q估计尽可能接近 Q 现实 Q_{现实} Q现实,或者说是让当前状态下预测的Q值跟基于过去经验的Q值尽可能接近。在后面的介绍中 Q 现实 Q_{现实} Q现实也被称为TD Target
再来回顾下DQN算法和核心思想
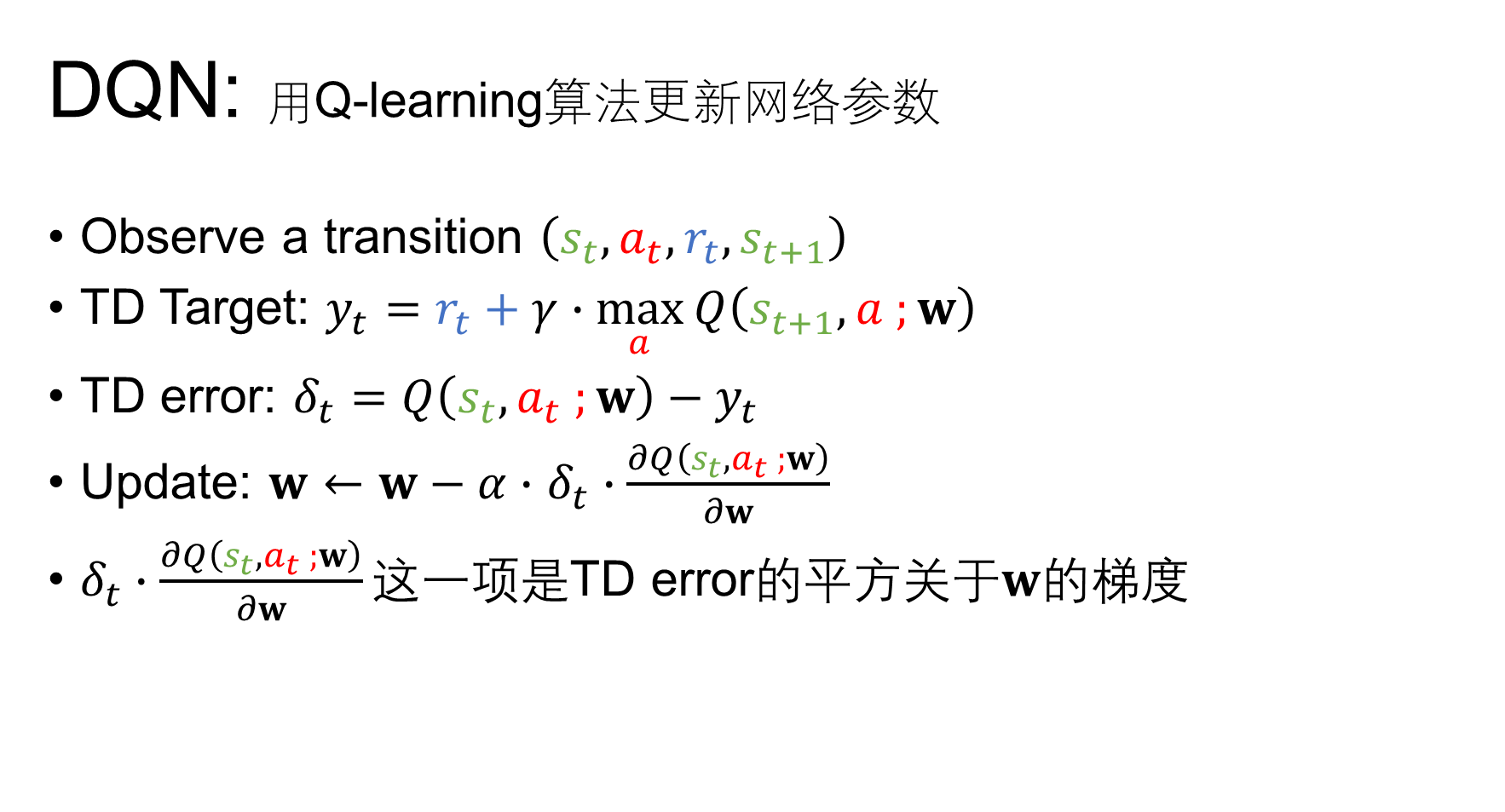
相比于Q Table形式,DQN算法用神经网络学习Q值。

我们可以理解为神经网络是一种估计方法,神经网络本身不是DQN的精髓,神经网络可以设计成MLP也可以设计成CNN等等,DQN的巧妙之处在于两个网络、经验回放等trick
下面介绍下DQN算法的一些trick,是希望帮助小伙伴们梳理区分两个网络的作用,阐述清楚经验回放等概念的本质,以及使用它们训练网络的技巧
Trick 1:两个网络
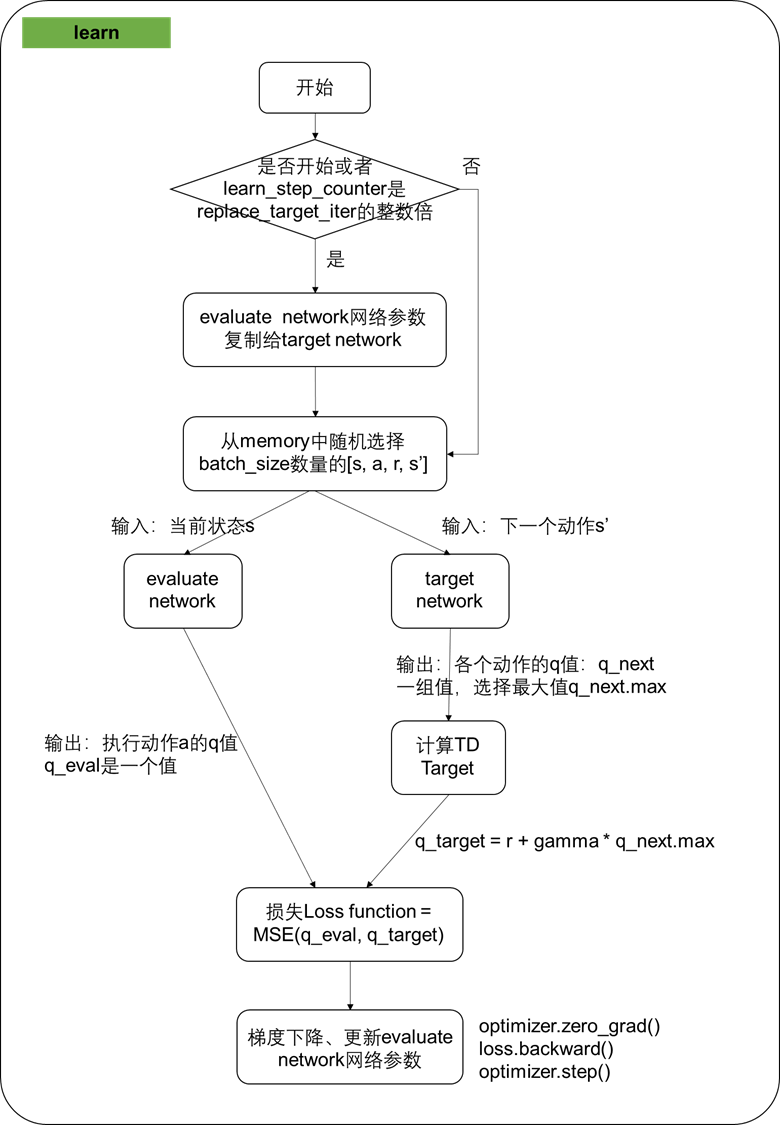
DQN算法采用了2个神经网络,分别是evaluate network(Q值网络)和target network(目标网络),两个网络结构完全相同
- evaluate network用用来计算策略选择的Q值和Q值迭代更新,梯度下降、反向传播的也是evaluate network
- target network用来计算TD Target中下一状态的Q值,网络参数更新来自evaluate network网络参数复制
设计target network目的是为了保持目标值稳定,防止过拟合,从而提高训练过程稳定和收敛速度
这里会有容易混淆的地方,梯度更新的是evaluate network的参数,不更新target network,然后每隔一段时间将evaluate network的网络参数复制给target network网络参数,那么优化器optimizer设置的时候用的也是evaluate network的parameters
Trick 2:基本框架
算法分成两个部分,分别是策略选择和策略评估,这也是强化学习算法基本的两个模块,梳理算法逻辑的时候从策略选择和策略评估两个方面入手,更容易弄清楚。策略选择部分,epsilon-greedy策略选择动作,策略评估部分使用贪婪策略
Trick 3:经验回放Experience Replay
DQN算法设计了一个固定大小的记忆库memory,用来记录经验,经验是一条一条的observation或者说是transition,它表示成 [ s , a , r , s ′ ] [s, a, r, s'] [s,a,r,s′],含义是当前状态→当前状态采取的动作→获得的奖励→转移到下一个状态
一开始记忆库memory中没有经验,也没有训练evaluate network,积累了一定数量的经验之后,再开始训练evaluate network。记忆库memory中的经验可以是自己历史的经验(epsilon-greedy得到的经验),也可以学习其他人的经验。训练evaluate network的时候,是从记忆库memory中随机选择(划重点哦,是随机选择!)batch size大小的经验,喂给evaluate network
设计记忆库memory并且随机选择经验喂给evaluate network的技巧打破了相邻训练样本之间相关性,试着想下,状态→动作→奖励→下一个状态的循环是具有关联的,用相邻的样本连续训练evaluate network会带来网络过拟合泛化能力差的问题,而经验回放技巧增强了训练样本之间的独立性
❀算法流程图
每个episode流程是下面这样
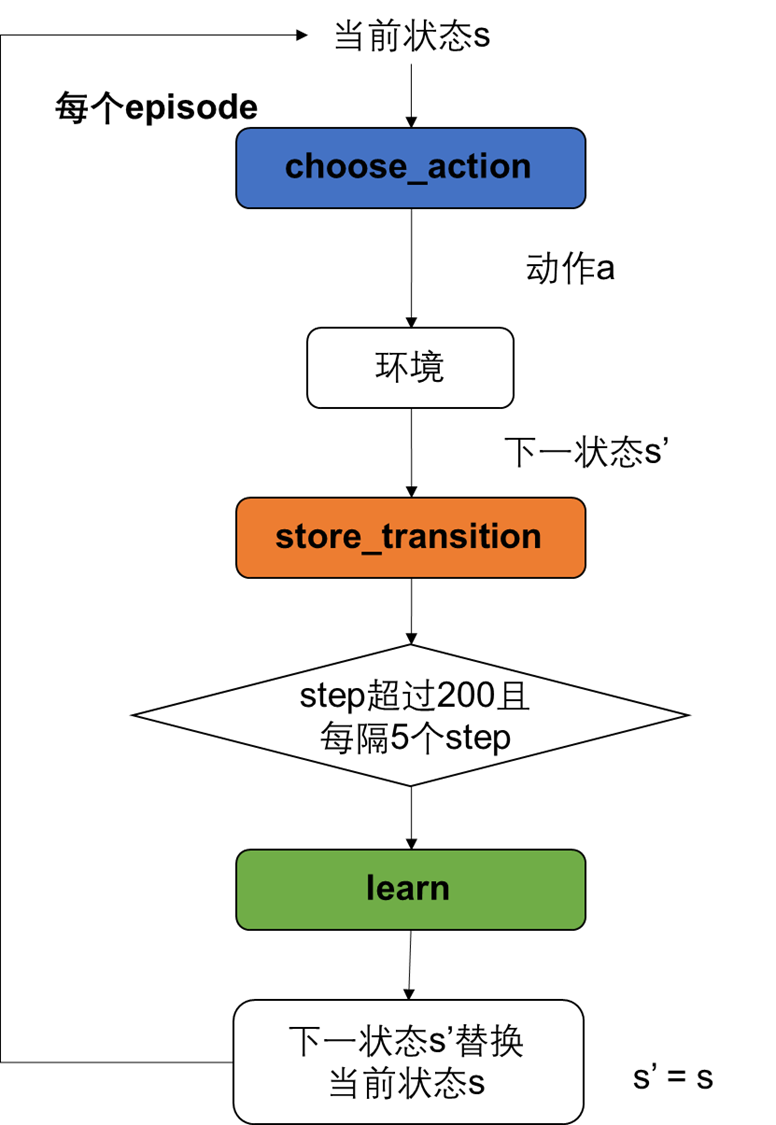
其中choose_action、store_transition、learn是相互独立的函数模块,它们内部的算法逻辑是下面这样


❀Pytorch版本代码
采用Pytorch实现了DQN算法,完成了走迷宫Maze游戏,哈哈哈,这个游戏来自莫烦Python教程,代码嘛是自己修改过哒,代码贴在github上啦
ningmengzhihe/DQN_base: DQN algorithm by Pytorch - a simple maze game https://github.com/ningmengzhihe/DQN_base
(1)环境构建代码maze_env.py
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_features = 2
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_W * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
# hell2_center = origin + np.array([UNIT, UNIT * 2])
# self.hell2 = self.canvas.create_rectangle(
# hell2_center[0] - 15, hell2_center[1] - 15,
# hell2_center[0] + 15, hell2_center[1] + 15,
# fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.1)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return (np.array(self.canvas.coords(self.rect)[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
next_coords = self.canvas.coords(self.rect) # next state
# reward function
if next_coords == self.canvas.coords(self.oval):
reward = 1
done = True
elif next_coords in [self.canvas.coords(self.hell1)]:
reward = -1
done = True
else:
reward = 0
done = False
s_ = (np.array(next_coords[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
return s_, reward, done
def render(self):
# time.sleep(0.01)
self.update()
(2)DQN算法代码,包括神经网络定义、Q值更新:RL_brain.py
"""
Deep Q Network off-policy
"""
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
np.random.seed(42)
torch.manual_seed(2)
class Network(nn.Module):
"""
Network Structure
"""
def __init__(self,
n_features,
n_actions,
n_neuron=10
):
super(Network, self).__init__()
self.net = nn.Sequential(
nn.Linear(in_features=n_features, out_features=n_neuron, bias=True),
nn.Linear(in_features=n_neuron, out_features=n_actions, bias=True),
nn.ReLU()
)
def forward(self, s):
"""
:param s: s
:return: q
"""
q = self.net(s)
return q
class DeepQNetwork(nn.Module):
"""
Q Learning Algorithm
"""
def __init__(self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None):
super(DeepQNetwork, self).__init__()
self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter = replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
# total learning step
self.learn_step_counter = 0
# initialize zero memory [s, a, r, s_]
# 这里用pd.DataFrame创建的表格作为memory
# 表格的行数是memory的大小,也就是transition的个数
# 表格的列数是transition的长度,一个transition包含[s, a, r, s_],其中a和r分别是一个数字,s和s_的长度分别是n_features
self.memory = pd.DataFrame(np.zeros((self.memory_size, self.n_features*2+2)))
# build two network: eval_net and target_net
self.eval_net = Network(n_features=self.n_features, n_actions=self.n_actions)
self.target_net = Network(n_features=self.n_features, n_actions=self.n_actions)
self.loss_function = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=self.lr)
# 记录每一步的误差
self.cost_his = []
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
# hasattr用于判断对象是否包含对应的属性。
self.memory_counter = 0
transition = np.hstack((s, [a,r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory.iloc[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
# forward feed the observation and get q value for every actions
s = torch.FloatTensor(observation)
actions_value = self.eval_net(s)
action = [np.argmax(actions_value.detach().numpy())][0]
else:
action = np.random.randint(0, self.n_actions)
return action
def _replace_target_params(self):
# 复制网络参数
self.target_net.load_state_dict(self.eval_net.state_dict())
def learn(self):
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self._replace_target_params()
print('\ntarget params replaced\n')
# sample batch memory from all memory
batch_memory = self.memory.sample(self.batch_size) \
if self.memory_counter > self.memory_size \
else self.memory.iloc[:self.memory_counter].sample(self.batch_size, replace=True)
# run the nextwork
s = torch.FloatTensor(batch_memory.iloc[:, :self.n_features].values)
s_ = torch.FloatTensor(batch_memory.iloc[:, -self.n_features:].values)
q_eval = self.eval_net(s)
q_next = self.target_net(s_)
# change q_target w.r.t q_eval's action
q_target = q_eval.clone()
# 更新值
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory.iloc[:, self.n_features].values.astype(int)
reward = batch_memory.iloc[:, self.n_features + 1].values
q_target[batch_index, eval_act_index] = torch.FloatTensor(reward) + self.gamma * q_next.max(dim=1).values
# train eval network
loss = self.loss_function(q_target, q_eval)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.cost_his.append(loss.detach().numpy())
# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
plt.figure()
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.show()
(3)每个episode代码:run_this.py
from maze_env import Maze
from RL_brain import DeepQNetwork
def run_maze():
step = 0 # 为了记录走到第几步,记忆录中积累经验(也就是积累一些transition)之后再开始学习
for episode in range(200):
# initial observation
observation = env.reset()
while True:
# refresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(observation)
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# !! restore transition
RL.store_transition(observation, action, reward, observation_)
# 超过200条transition之后每隔5步学习一次
if (step > 200) and (step % 5 == 0):
RL.learn()
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
step += 1
# end of game
print("game over")
env.destroy()
if __name__ == "__main__":
# maze game
env = Maze()
RL = DeepQNetwork(env.n_actions, env.n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200,
memory_size=2000)
env.after(100, run_maze)
env.mainloop()
RL.plot_cost()
❀参考资料
https://zhuanlan.zhihu.com/p/614697168
这份参考资料清晰的解释了2个Q值网络,pytorch代码值得参考
https://www.bilibili.com/video/BV13W411Y75P?p=14&vd_source=1565223f5f03f44f5674538ab582448c
莫烦Python在B站上的DQN教程







![[2021 东华杯]bg3](https://img-blog.csdnimg.cn/c814fb80016745fc97880bf949568051.png)