另类字符
回忆上次内容
- 上次再次输出了大红心♥
- 找到了红心对应的编码
- 黑红梅方都对应有编码
- 原来的编码叫做 ascii️
\u这种新的编码方式叫unicode- 包括了 中日韩字符集等 各书写系统的字符集
- 除了这些常规字符之外
- 还有什么好玩的东西呢?
颠倒字符

- 这个网站可以把文字上下颠倒
- https://www.upsidedowntext.com/
- 这些颠倒字符的编码多少呢?
- 自己试试
尝试
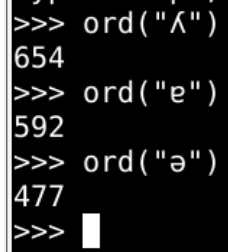
- 序号还是比较靠前的
- 应该是一些拉丁字符
- 类似的还有带圈圈的英文字符
带圈字符
- https://www.bubbleballtext.com/
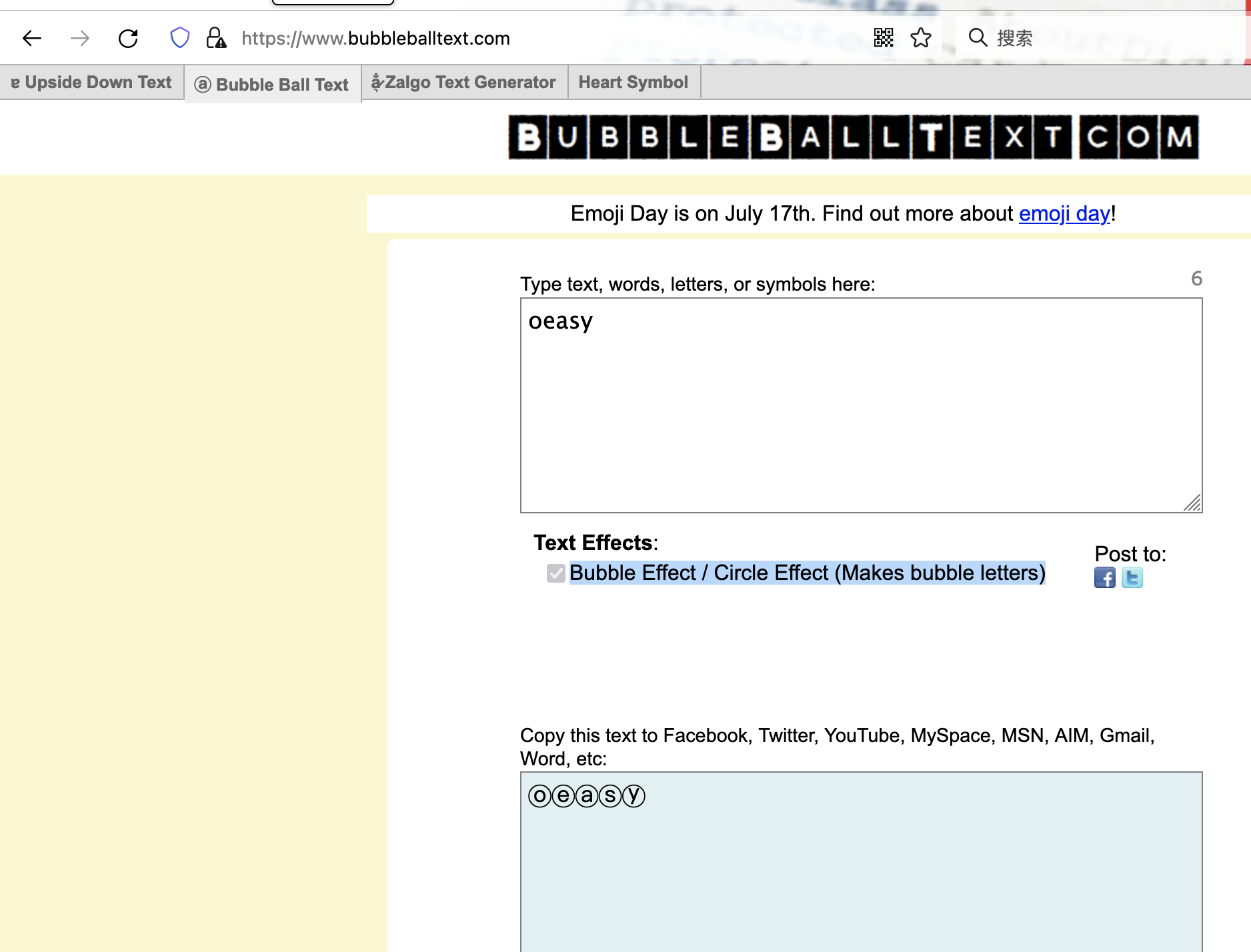
- 带上圈圈之后
- 给人一种ꫛꫀꪝ的感觉
- 这些都是谁规定的呢?
继续探索
- unicode 其实有个委员会
- 各种大厂都在里面指定标准
- 我们也可以访问 unicode.org
- 具体的编码字符都可以在里面找

炼金术师的符号
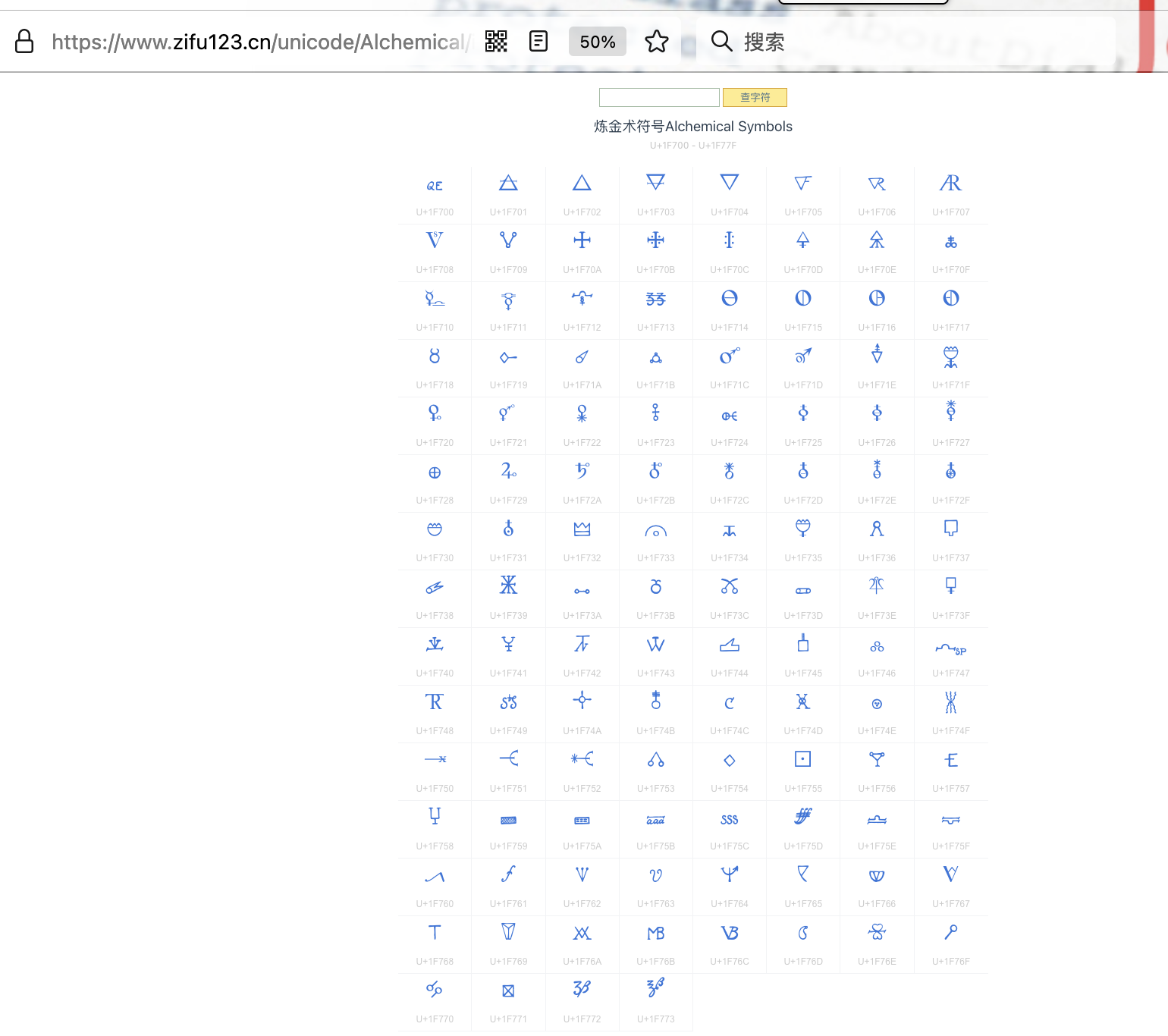
- https://www.zifu123.cn/unicode/Alchemical/index.htm
古代字符编码
- 埃及圣书体
- https://www.zifu123.cn/unicode/Egyptian_Hieroglyphs/index.htm
- 腓尼基楔形文字
- https://www.zifu123.cn/unicode/Early_Dynastic_Cuneiform/index.htm

- 回忆起拉丁字符走过的路
拉丁字符之路

时间相关
- 这个编码可以解决
等宽的问题 - 而且还有汉字
- 目前大多数字体支持
- ㋀㋁㋂㋃㋄㋅㋆㋇㋈㋉㋊㋋
- ㏠㏡㏢㏣㏤㏥㏦㏧㏨㏩㏪㏫㏬㏭㏮㏯㏰㏱㏲㏳㏴㏵㏶㏷㏸㏹㏺㏻㏼㏽㏾
- ㍘㍙㍚㍛㍜㍝㍞㍟㍠㍡㍢㍣㍤㍥㍦㍧㍨㍩㍪㍫㍬㍭㍮㍯㍰
货币相关

音乐相关
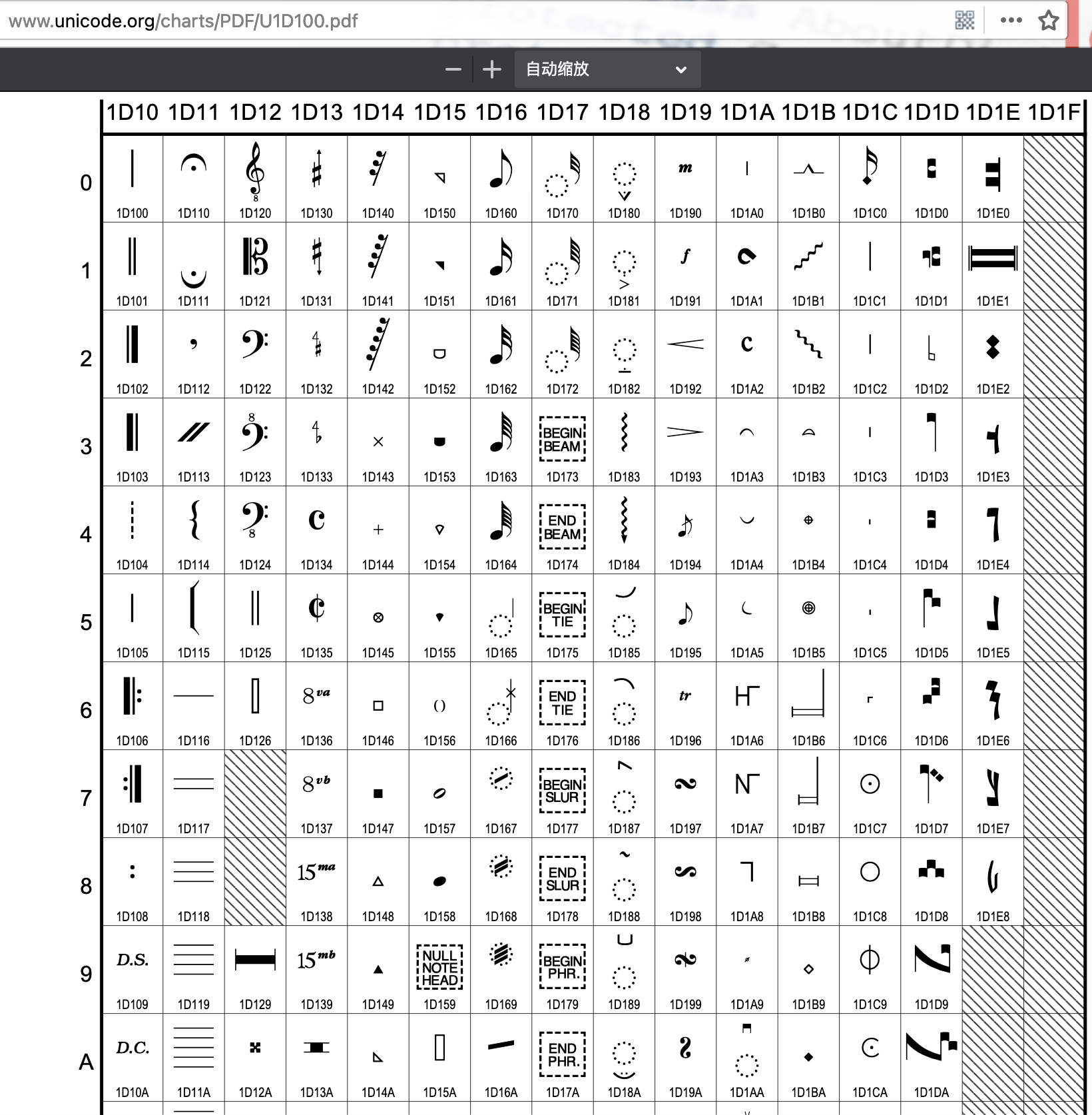
中文字符


- 这些编码实在是偏门
亚文化
- 不过很有趣
- 目前大多数字库文件还不支持
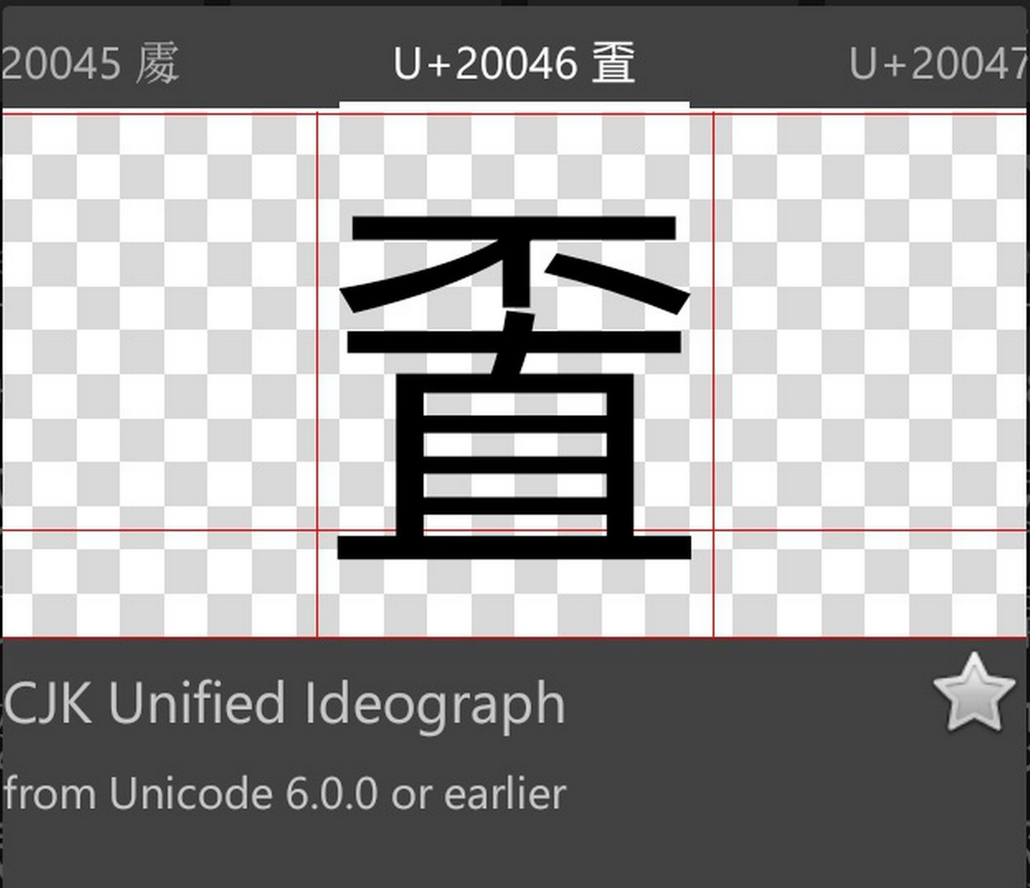
- 不知道这些参与 unicode 编码规则制定的大公司在想些什么?
扑克编码
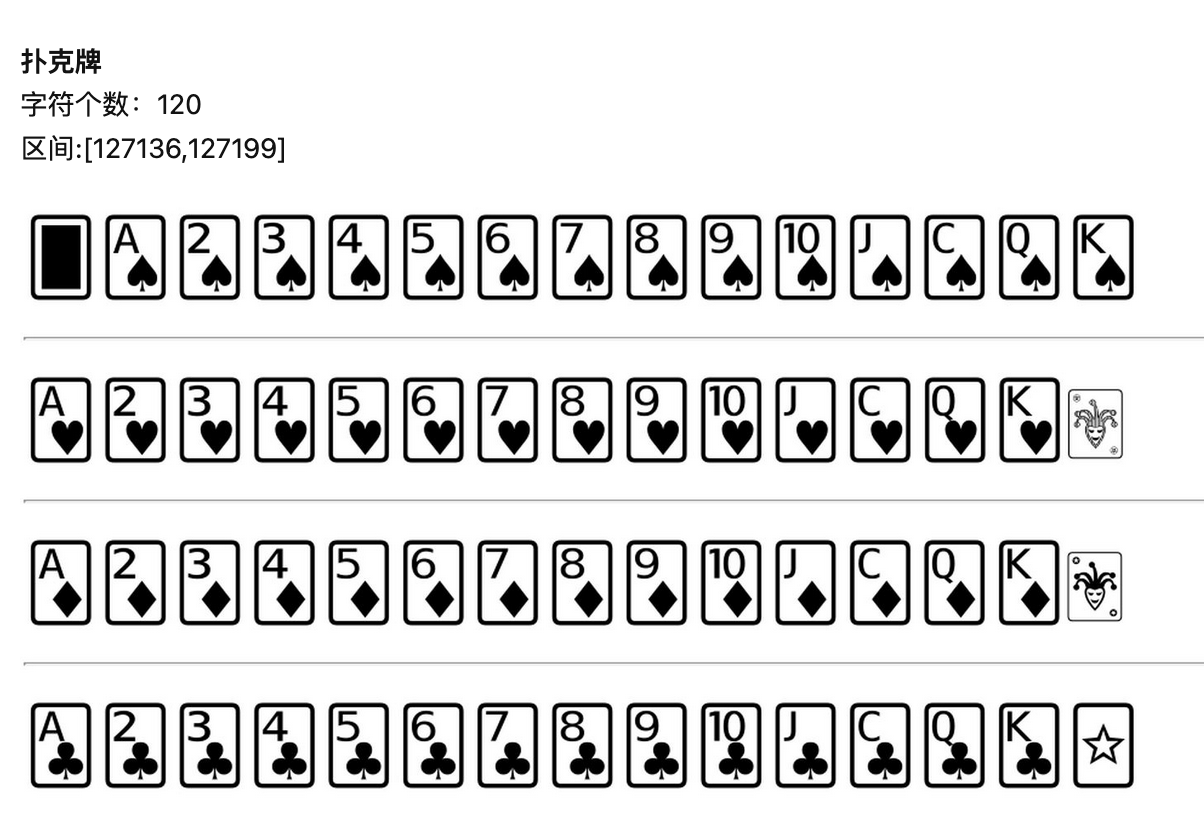
- 我们以前介绍过黑红梅方的编码
- 配合数字可以做出扑克效果
- 这个编码直接就是牌
- C 是骑士牌(knight card)
- 我们一般都是 54 张牌
- 目前大多数字符库还不支持 unicode 这个编码段的部分
- 支持了之后就可以直接字符打牌了
国际象棋
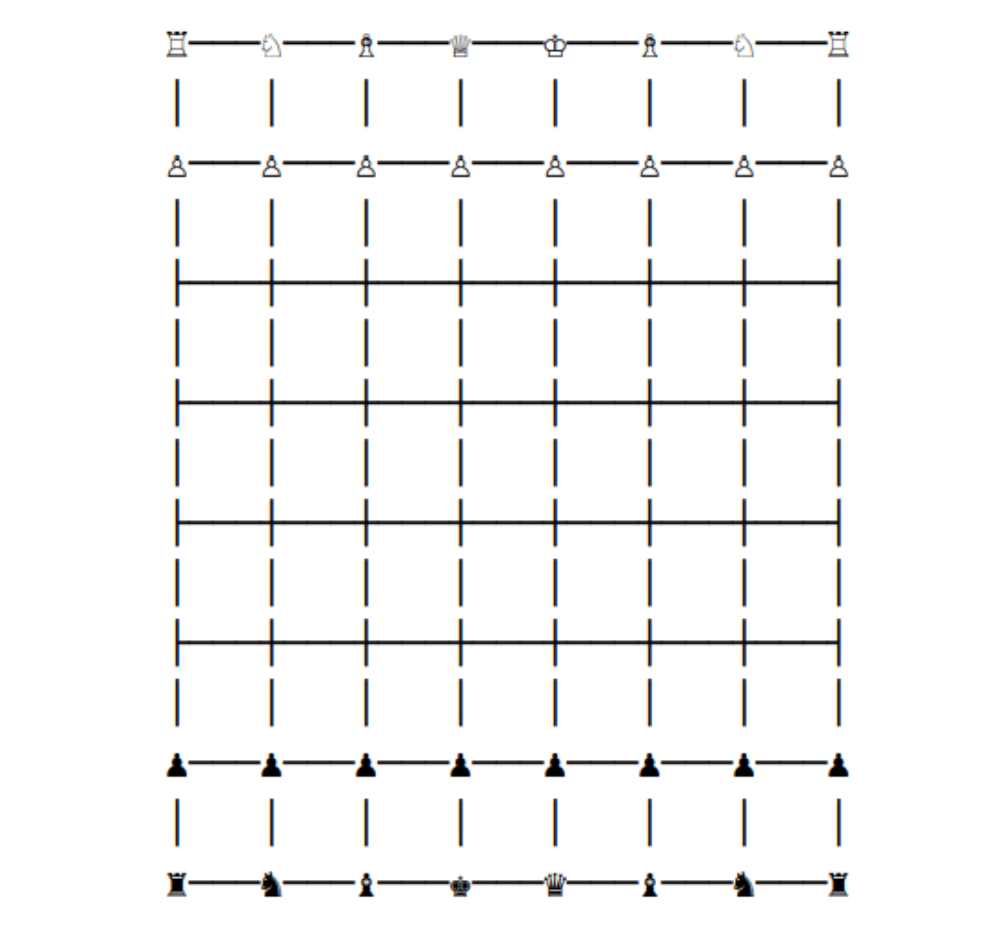
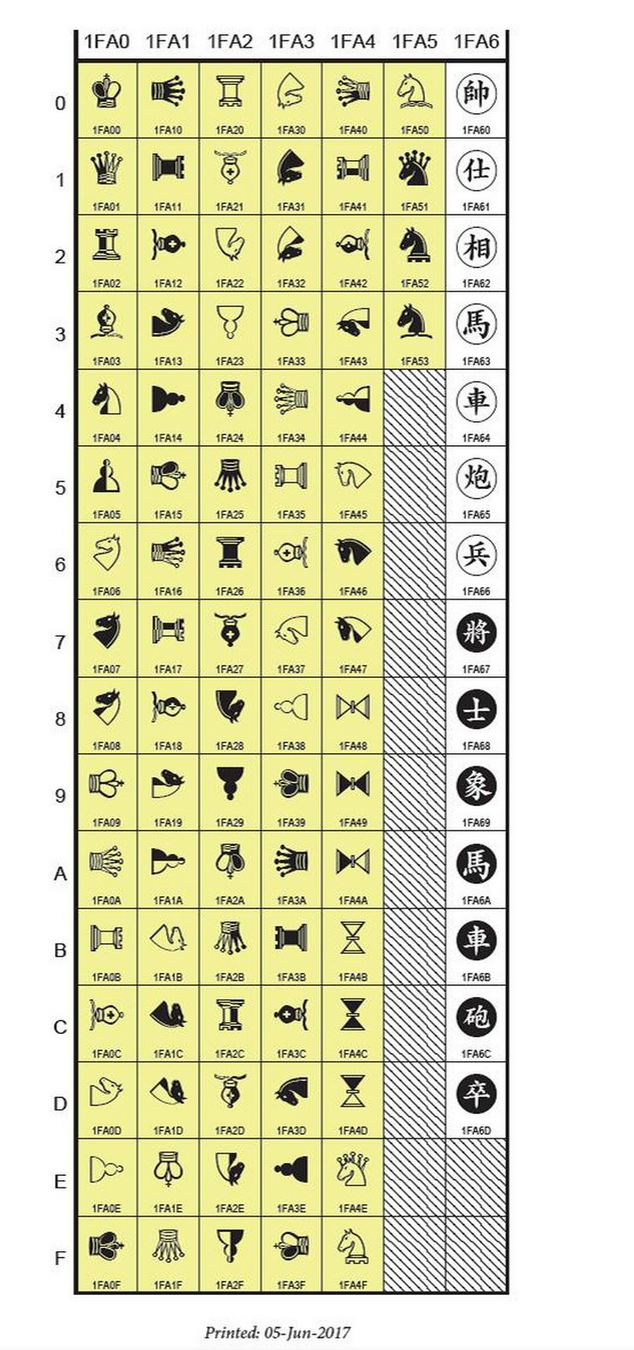
- 目前大多数字体不支持
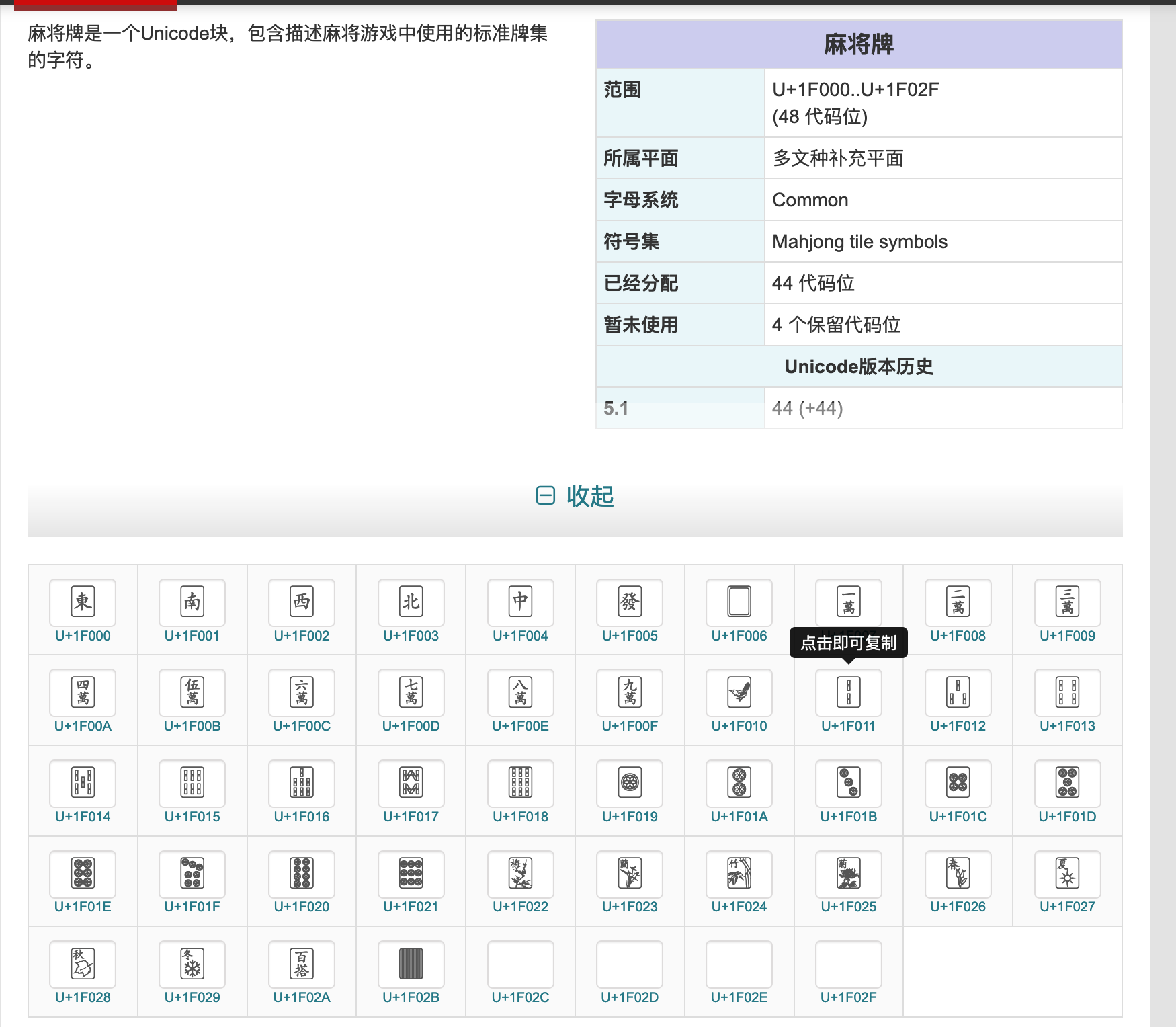
麻将
- 中式麻将牌在这里
- 红红火火
- 梅兰竹菊 春夏秋冬 就连百搭都有
- 以后用户名也许可以用麻将字符了
- 🀀🀁🀂🀃🀆🀅🀄
- 🀇🀈🀉🀊🀋🀌🀍🀎🀏
- 🀐🀑🀒🀓🀔🀕🀖🀗🀘
- 🀙🀚🀛🀜🀝🀞🀟🀠🀡
- 九筒
- 不过目前多数字库还不支持
各种符号

- 符号还在不断添加中
新的符号


- 各种杂项费用还是很多的甚至包含 emoji
- 这些新增的字符除了好玩之外
- 也会对于我们产生影响
- 其实我们也有这种符号
五岳真形图

- 也许有一天unicode中会出现五岳的符号
- 还有一些同型不同序号的字
易混淆文字
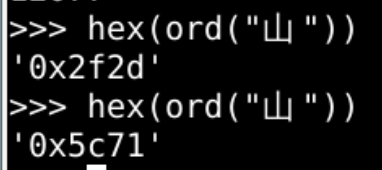
- 这两个文字非常相像但却是两个不同的字符
- 第1个是常用的
- 第2个是1999年更新中新加进去的康熙部首
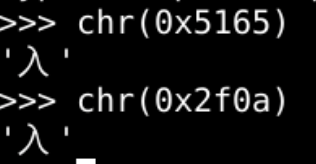
- 这种长相类似的字符有什么用么?
阴阳话题
- 作为计算机理解这就是两个词条

- 这是公关降热度的一个手法
部首
- 还有什么类似的字符吗?

- 康熙部首
- 2F00-2FD5
- 扩展部首
- 2E80-2EF3
- 如果当前系统不认识这个字符
- 怎么办呢?
不识别
- 但是如果发送过来的字符
- 在当前的系统中没有对应的字符
- 应该怎么办呢?
�
- 发过来一个不认识的字符
- 机器就傻了
- 因为不知道如何表现
- 于是他会用一个问号对应的字符进行替换
- U+FFFD �
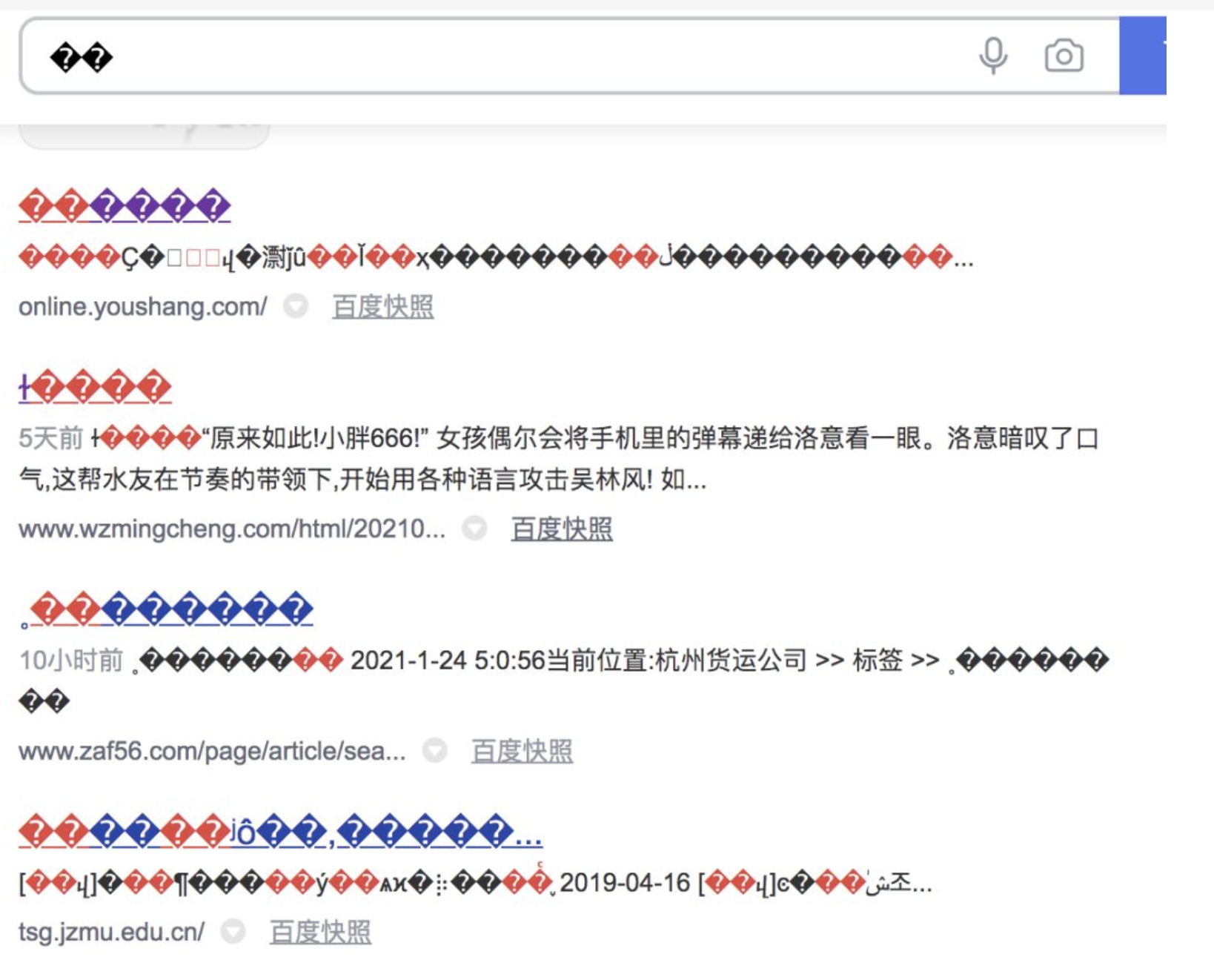
- 这个字符本应该是 unicode 中的字符
- 但如果硬要用 gbk 解码会如何呢?
乱解码
- � 对应 utf-16 编码 0xFFFD
- 转化为 utf-8 对应 0xEF 0xBF 0xBD
- 但是如果这个编码用 gbk 解码的话
- 就会出现锟斤拷
- 锟(0xEFBF)
- 斤(0xBDEF)
- 拷(0xBFBD)

- 锟斤拷会出现在各种地方
- 甚至有个笑话
- 手持两把锟斤拷
- 口中疾呼烫烫烫
- 烫烫烫又是怎么回事
烫烫烫和屯屯屯
- 0xcc 正好是
- x86指令集中 中断(int 3)指令
- 起到保护作用
- 在分配内存的时候
- 栈内存默认初始数值为 0xcc
- 0xcccc 用使用 bgk 的终端来表示刚好就是
烫 - 未初始化的栈空间用 0xcc 填充
- 而未初始化的堆空间用 0xcd 填充
- 所以 0xcdcd 用 gbk 来解释的话,就是
屯
- 所以 0xcdcd 用 gbk 来解释的话,就是

- 动态分配的内存被回收之后
- 就是 DDDD
- 0xcdcd
- 在gbk编码格式中
- 对应汉字
葺
- 对应汉字
- 甚至有拼音标号
拼音标号
- https://www.zalgotextgenerator.com/
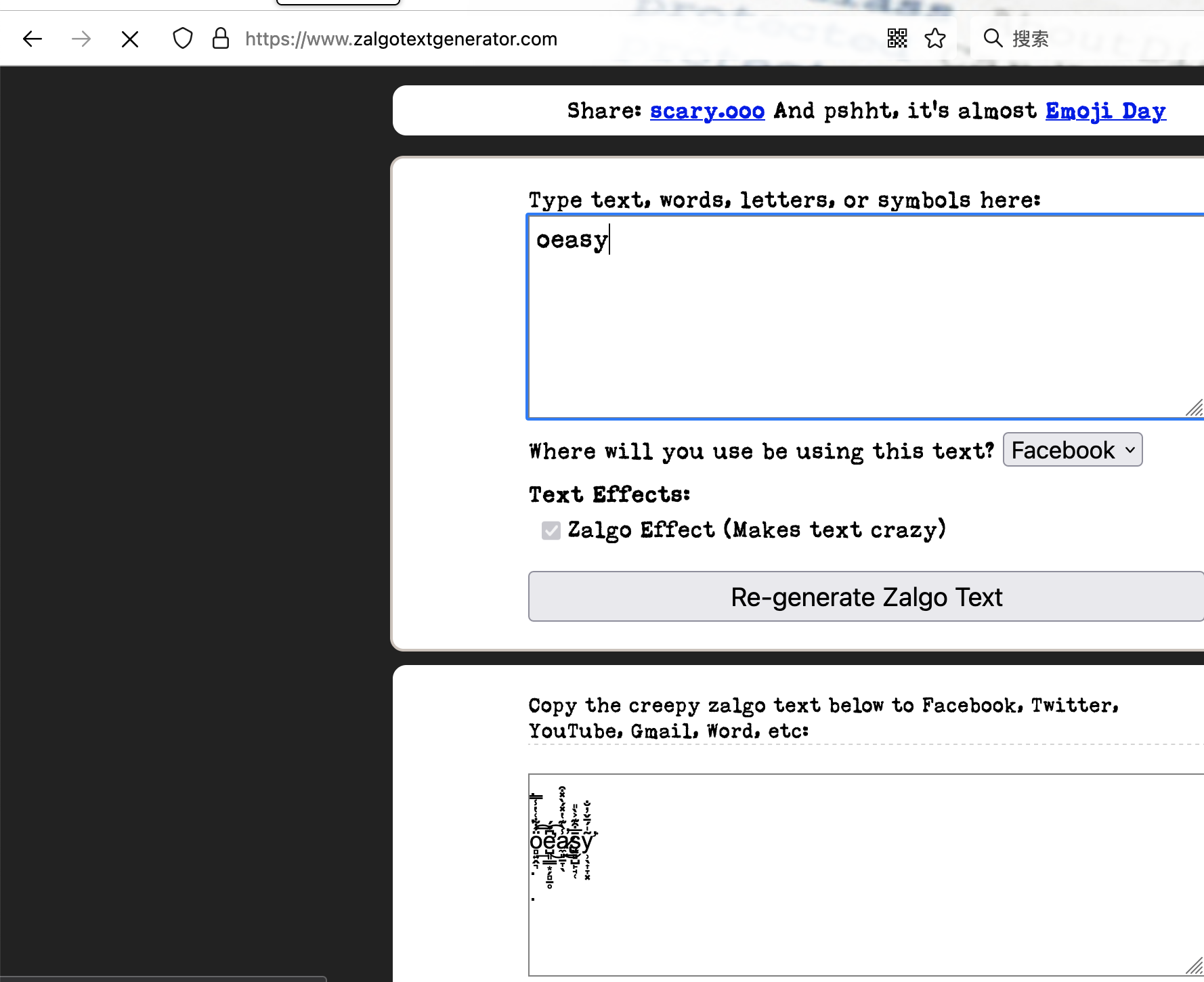
- 符号还在不断增加中
中文字符集进化
- unicode 如果 2 个字节总共 16 位
- 16 位最多 65536 各字符
- 想要把全世界的字符都编码是不现实的
- 光是中文就超了好几次
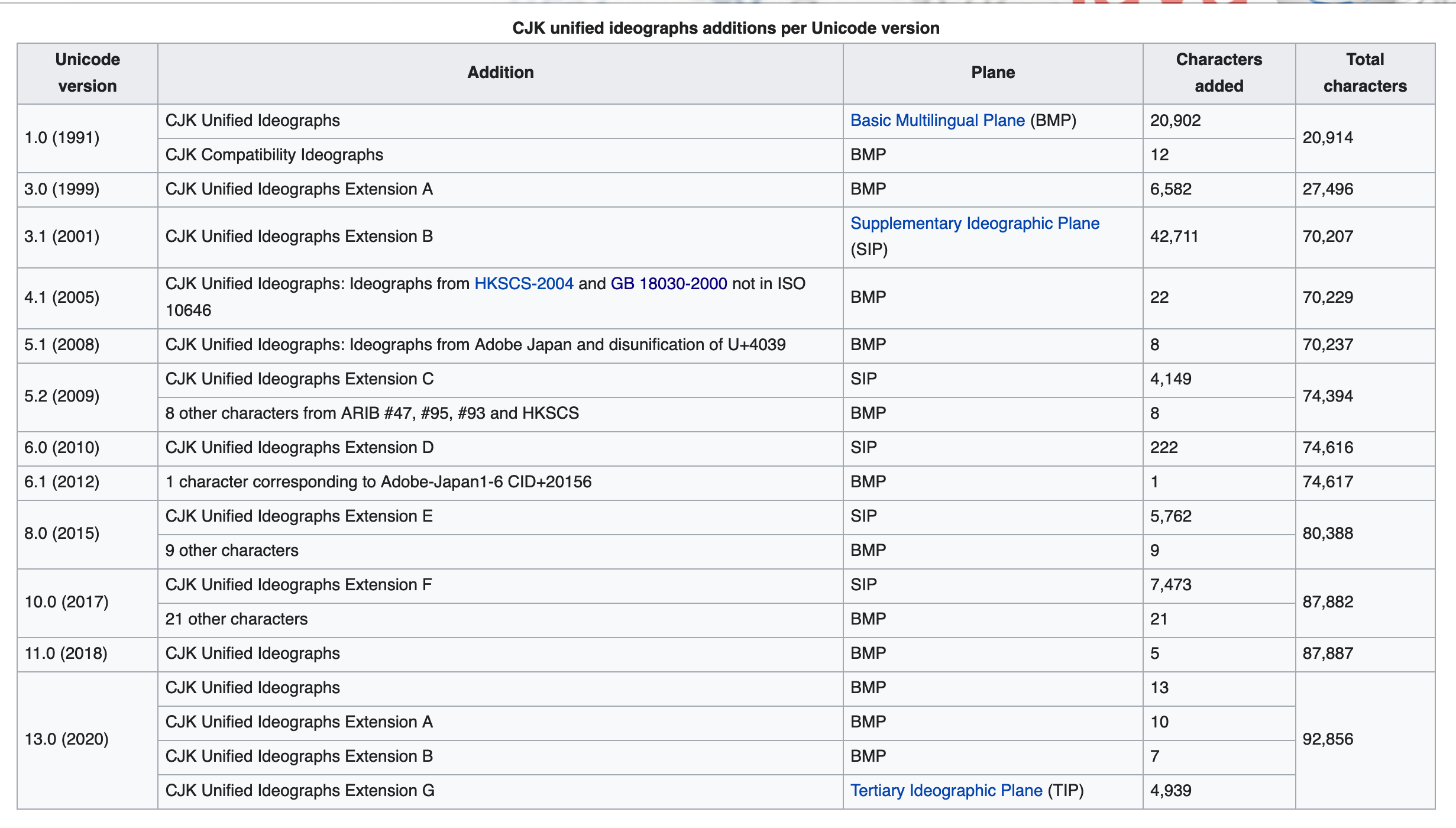
- 如果使用 3 字节编码就大大增加了存储和带宽的压力
- 那到底应该怎么办呢?
- 到底应该按照 1 字节、2 字节还是 3 字节进行读取呢?
总结
-
unicode 里面有各种字体
- 扑克
- 国际象棋
- 麻将
- 偏旁部首
- 各种好玩的编码
- 字符编码就是这样一步步发展过来的
-
但是有个问题
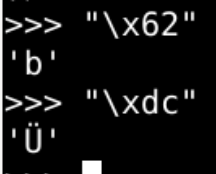
- 拜这个字
- 在字节中应该是b"\x62\xdc"两个字节
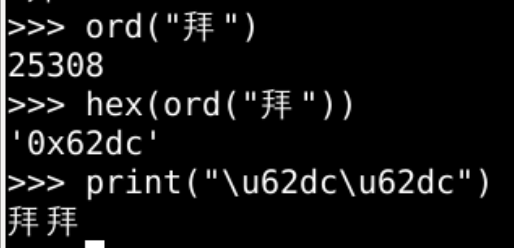
- 该如何理解b"\x62\xdc"这两个字节呢?🤔
- 究竟是"拜"
- 还是"bÜ"呢?
-
我们下次再说!👋
-
蓝桥->https://www.lanqiao.cn/courses/3584
-
github->https://github.com/overmind1980/oeasy-python-tutorial
-
gitee->https://gitee.com/overmind1980/oeasypython







![[2021 东华杯]bg3](https://img-blog.csdnimg.cn/c814fb80016745fc97880bf949568051.png)