系列文章目录
MySQL之BufferPool
文章目录
- 系列文章目录
- 前言
- 一、free链表
- 1.1结构简图
- 1.2 结构说明
- 二、flush链表
- 2.1 结构简图
- 2.2 结构说明
- 三、LRU链表
- 3.1 结构简图
- 3.2 LRU优化后结构简图
- 附录
前言
提示:这里可以添加本文要记录的大概内容:
本文会介绍free链表,flush链表,LRU链表是什么,以及在Buffer pool中的作用与使用
一、free链表
1.1结构简图
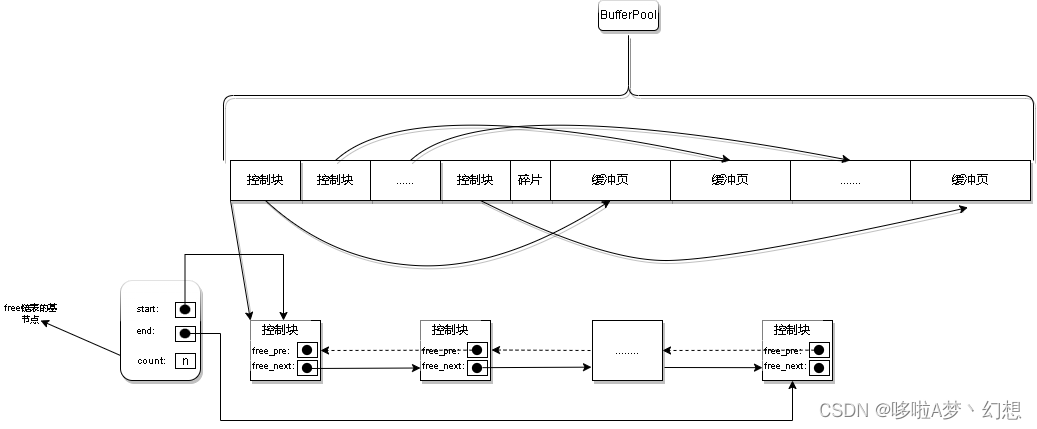
1.2 结构说明
free链表组成: 由双向链表构成,free_pre指向上一个节点,free_next指向下一个节点,基节点中count代表空闲节点数量
free链表作用: free链表管理BufferPool中空闲缓冲页,BufferPool初始化后,所有缓冲页都是空闲,每个缓冲页对应的控制块都会加入free链表中
free链表基节点:管理free链表的节点,由free链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。另外开辟的内存,不保存在BufferPool中
free链表使用: 从磁盘中加载一个页到BufferPool中时,检查hash表中是否已经加载该缓冲页(了解hash表结构),如果加载了,则直接读取,如果没有则从free链表中取出一个空闲缓冲页,并将该缓冲页对应的控制块信息填入,然后把该缓冲页对应的free链表节点(控制块)从free链表中移除,count-1
二、flush链表
2.1 结构简图
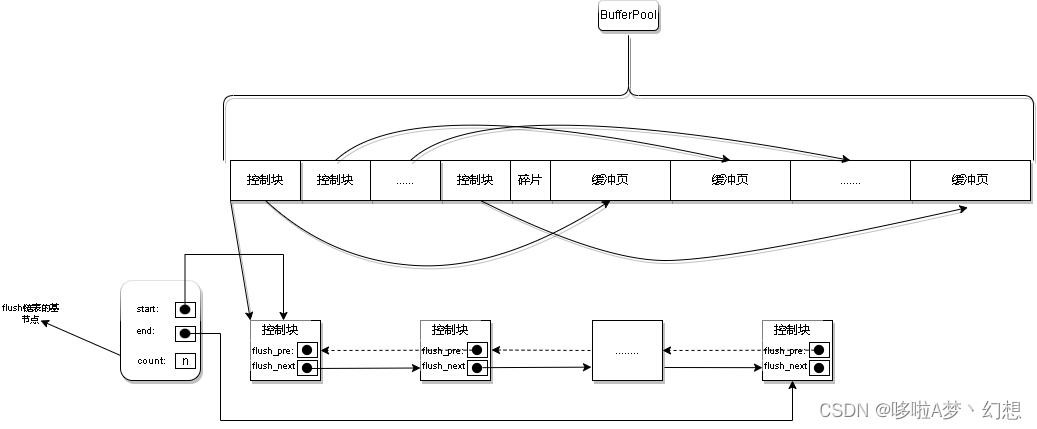
2.2 结构说明
flush链表组成: 由双向链表构成,free_pre指向上一个节点,free_next指向下一个节点,基节点中count代表脏页节点数量
flush链表作用: 管理脏页,将需要刷新到磁盘的脏页保存在flush链表中
flush链表使用: 同样产生了脏页就加到flush链表中,等待刷新到(同步)磁盘中
三、LRU链表
3.1 结构简图

LRU链表组成: 全称Least Recently Used链表。由双向链表构成,free_pre指向上一个节点,free_next指向下一个节点,基节点中count代表节点数量
LRU链表作用: 解决BufferPool内存有限问题,淘汰使用的比较少的缓冲页。按照最少使用原则进行淘汰
LRU链表使用: 如果该页不在BufferPool中,将该页从磁盘加载到BufferPool的缓冲页时,将free链表节点减去,把该缓冲页对应得控制块作为节点塞到LRU链表得头部,如果以及加载在BufferPool中,则将该页对应得控制块移动到LRU链表得头部
LRU链表的局限性:预读问题, 针对全表扫描时占用大量使用频率非常低的页面问题。这两种问题都严重降低了BufferPool的命中率
3.2 LRU优化后结构简图
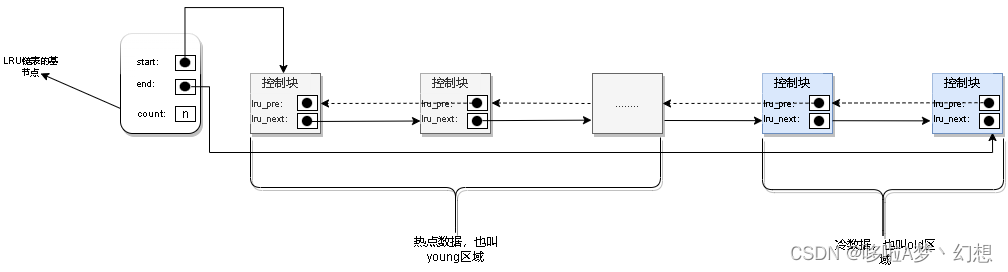
LRU链表的优化点:如图,将LRU链表分为young区域和old区域。其中young区域存储热点数据,old区域存储使用频率低的数据。
可通过系统变了innodb_old_blocks_pct控制,old区域默认占比37%
LRU链表的优化内容:
- 针对 预读问题:初次加载到BufferPool的缓冲页对应的控制块会放到old区域的头部,这样既不会影响到young中的热点数据,如果预读后不进行访问则会逐渐被淘汰
- 针对 针对全表扫描时占用大量使用频率非常低的页面问题:我们知道全表扫描时会对每一条数据进行访问,而数据都存在页中,所以全表扫描时会对页进行多次访问,所以针对预读问题能解决的办法并不适用于全表扫描问题,故此提供了一个时间间隔来处理该问题。
对全表扫描加入old区域的缓冲页,进行第一次访问时记录这个时间点,如果后续访问时间与第一次访问的时间点在某个时间点内(系统变量innodb_old_blocks_time控制这个时间点大小,默认值为1000ms),那么该页面就不会从old区域移动到young区域,否则会将其移动到young区域的头部
其它优化方式: 目的提高BufferPool命中率
- 优化问题:young区域缓冲页每次访问一个缓冲页就要将该缓冲页移动到LRU链表头部,移动频率较高
为了管理好BufferPool,还有很多链表结构,unzip LRU链表,zip clean链表等等
附录
脏页: 与磁盘上的页数据不一致的缓冲页(其实也就是内存与磁盘数据不一致),这类页需要与磁盘同步
redo日志:记录数据库修改删除操作,满足系统崩溃后数据还能保证恢复的功能(持久性)。
lsn值: lsn值代表系统写入的redo日志量的一个总和
checkpoint: 因为redo日志文件组容量有限,所以redo日志是循环使用的,而checkpoint就是覆盖的redo日志操作
预读问题:预读出的数据,用不到的话就会白白占用BufferPool内存,同时还可能挤压到其他语句在BufferPool中的内存空间
InnoDB提供了预读功能:如果InnoDB认为执行当前请求时,可能会在后面读取某些页面,就会预先将这些页面加载到BufferPool中。根据触发方式分为:
- 线性预读:由系统变量innodb_read_ahead_threshold控制,默认值是56。如果顺序访问某个区的页面超过这个系统变量,就会触发一次异步读取下一个区中全部的页面到BufferPool中的请求。
- 随机预读:由系统变量innodb_random_read_ahead控制,默认值为OFF(关闭)。如果某个区的13个连续的页面都被加载到BufferPool中,无论这个页面是不是顺序读取,都会触发一次异步读取本区中所有其他页面到BufferPool中的请求。
针对全表扫描时,占用大量使用频率非常低的页面问题: 全表扫描读取大量页,而BufferPool又没有足够空间容纳的话,就会将其他语句占用的BufferPool空间给覆盖,这样其他语句在执行的时候又需要重新从磁盘中加载页到BufferPool中。
使用频率非常低的页占用了使用频率非常高的页在BufferPool的内存,严重降低了BufferPool的命中率。
区:表空间的页太多了,为了更好的管理这些页,InndDB提出来区的概念,对于16kb的页来说,连续的64个页就是一个区,也就是一个区默认占用1M空间,每256个区划分为一组
其它:一般情况下都是后台线程对flush链表与LRU链表刷脏页,但是如果当前系统页面修改操作十分频繁,这就导致redo日志的操作十分频繁,系统lsn值增长过快,后台线程不能将脏页快速刷出,无法及时执行checkpoint,可能就会用到用户线程刷脏页(只有刷完脏页了,redo日志才会失效,才可以执行checkpoint),当然用用户线程刷脏页,肯定会影响到mysql效率,读写分离,能提高效率也有解决这一层问题的原因
想要体系的了解BufferPool,建议看书。
作者写的很好,通俗易通,读之前建议读者先了解基本的数据结构,有过mysql使用经验的读起来会更有趣
参考资料: 《MySQL是怎样运行的》