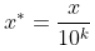ClassMix
- 相关介绍
- 主要思想
- 方法
- Mean-Teacher
- 损失函数
- 交叉熵损失
- 标签污染
- 实验
- 实验反思
- 参考资料
相关介绍
从DAFormer溯源到这篇文章,ClassMix主要是集合了伪标签和一致性正则化,思想来源于CutMix那条研究路线,但是优化了CutMix中的标签污染的情况,后续会说。一致性正则化的半监督学习在图像分类中取得了显著的进展,主要利用强数据增强来加强对未标记的一致性预测图片,然而在半监督语义分割中被证明是无效的。
主要思想
- 从一张图片中随机选取一半的类粘贴到另外一张图片上,形成一个新的样本,标签也不需要真正注释,只需要获取原来的两张图对应的标签即可。
- 利用网络学习预测原始图像的像素级语义,对混合的图像的预测被强制训练成和混合前一致。
- 根据分类一致性正则化趋势,还继承了熵最小化,来鼓励网络进行低熵预测。
方法
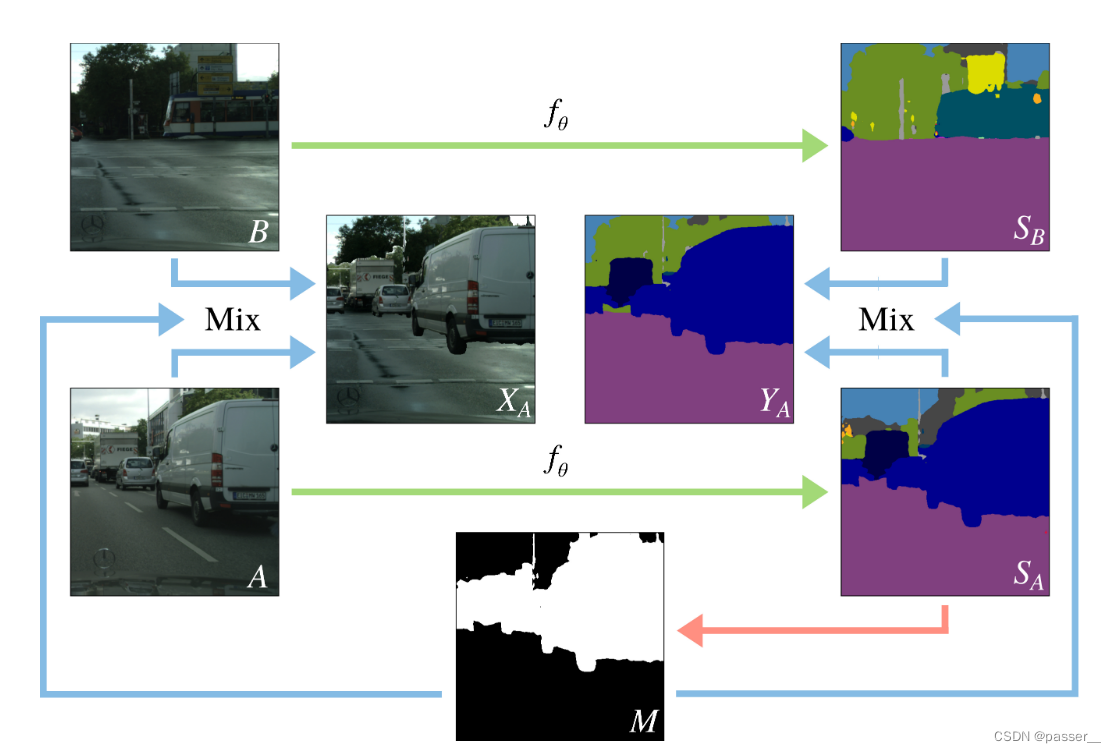
如图所示,ClassMix使用两张没有标记的图片A、B,然后分别通过网络f(θ)生成对应的Sa、Sb。随机获取Sa中的一半的类,然后获取到类别像素点的位置为1,其余位置为0,生成一个Mask掩码M,把A、B两张图片作为输入同时加上掩码M,生成一张增强的图片Xa,其对应的标签Ya,通过Sa,Sb和M获取对应的标签Ya,由于混合策略的性质,刚开始可能会出现人工标签,但随着训练的进行,会越来越少。
伪代码如下:

Mean-Teacher
先留坑。
去看Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results这篇论文,看完回来填坑
损失函数
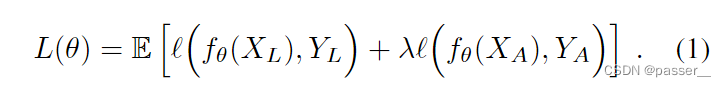
Xl是从带标签的数据集中均匀随机采样的图像,Yl是对应的ground-truth语义图。
Xa是增强方法产生的图像,Ya是对应的人工标签。
λ是一个控制监督和非监督之间平衡的超参数。
ℓ是交叉熵损失函数
交叉熵损失
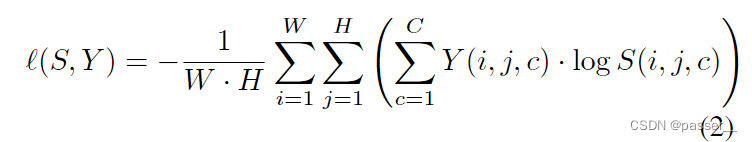
W,H对应着图像的宽度和高度,该损失函数就是一个多分类的损失函数。Y(i,h,c)和S(i,j,c)分别对应着目标和预测中(i,j)这个位置对应着c这个类别的概率。
标签污染
对于物体的边界来说会有很大的不确定性,因为分割任务在接近边界时候是最难的,这就会导致一个污染的问题,如下图所示:当由M选择的类被粘贴到图像B的顶部时,其相邻的上下文将经常改变,例如中间那个图,按照白色的线作为决定边界线,将下半部分粘贴到C上,就会导致在红色和绿色之间出现一些奇奇怪怪的类别(一些不确定性的类别),就会增添不确定性,就会得到较差的人工标签。伪标记有效地缓解了这一问题,因为每个像素的概率质量函数被改变为最可能类别的一个热向量,从而尖锐了这个问题,从而导致不会受到污染。

实验
使用PyTorch框架,两块V100训练,采用了基于ResNet101为backbone的DeepLab-V2框架。刚开始在ImageNet和MSCoCo上预训练,在Cityscapes和Pascal Voc2012两个数据集上给出结果。
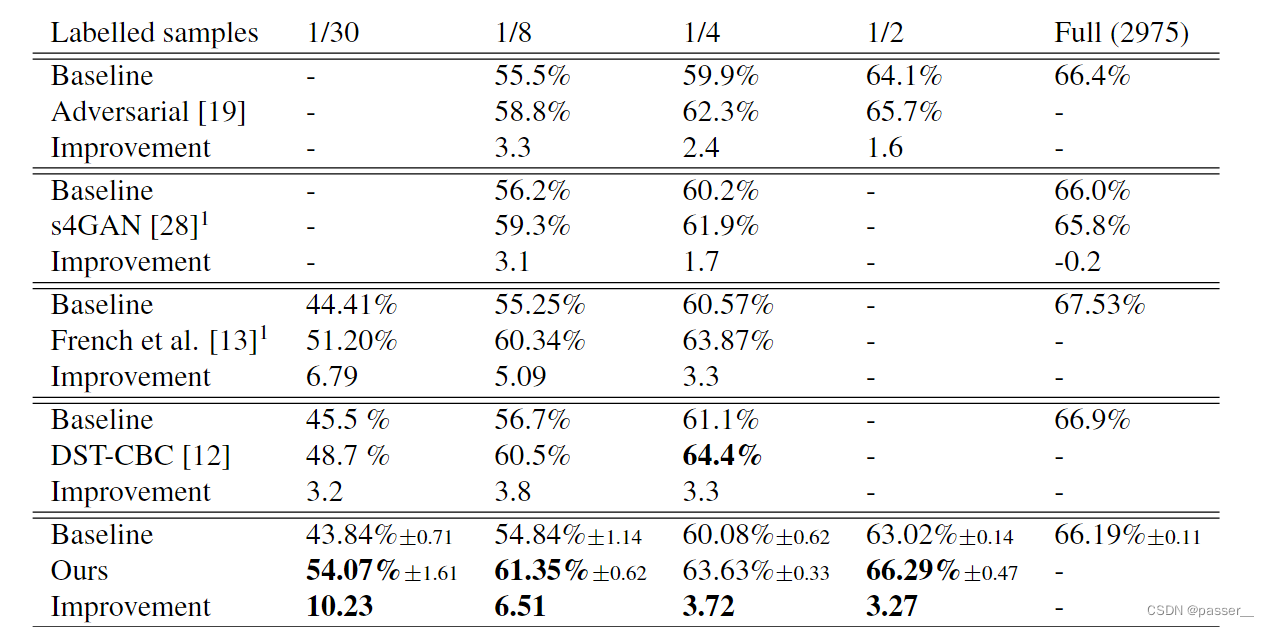
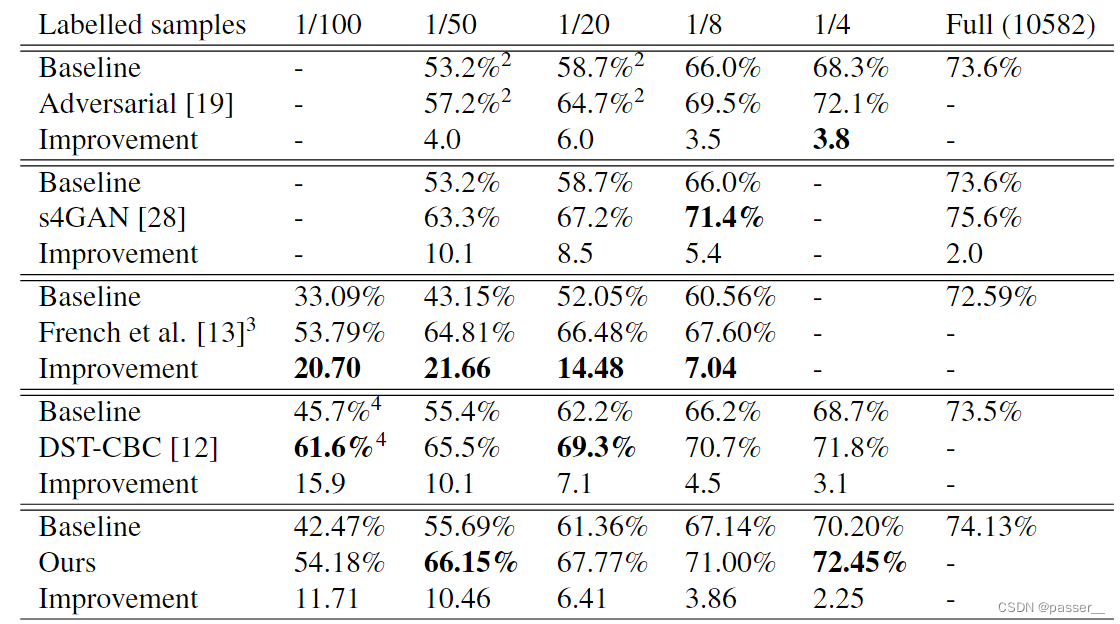
实验反思
作者对于在Cityscapes表现良好的原因归结于数据中的图片的分布类似(论文分析了数据中类别的分类情况),还有一个原因就是类别的分布不是很均匀,而是集中在一些地方(同上),所以将一个图像粘贴到另外一个图像就显得很合理,效果也不错。但是对于Pascal VOC 2012就不一样了,所取得结果虽然也具有竞争性,在一些类别上达到了stoa的水平,但是不如在Cityscapes整体取得的效果。主要原因是Pascal VOC 2012这个数据集中类别比较少,生成的mask掩码会出现重复的情况,所以效果会不如,另外与Cityscapes不同,Pascal的数据集中类彼此之间不是那么的相似,因此随机将两个图中的类别放到一起会经常出现不合理的情况,所以会影响效果,但是ClassMix的性能仍然处于sota的水平。
参考资料
- https://arxiv.org/abs/2007.07936
- https://github.com/WilhelmT/ClassMix





![[ROC-RK3399-PC Pro] 手把手教你移植主线Buildroot(基于2023.02-rc3版本)](https://img-blog.csdnimg.cn/a4a420ba60fb4a618bb8ea1b3a9e4f53.png)