一、哈希表介绍
1.1 哈希表初了解
哈希表是属于一个数据结构,并不是一个算法
哈希表:hashtable,也叫散列表,根据关键码值(Key value)而直接进行访问的数据结构。通过把关键码值映射到表中的一个位置来访问记录,以加快查找的速度。这个映射的函数叫做散列函数(柑橘关键码值能迅速的定位表中位置的方法),存放记录的数组叫做散列表。
需求:当有新员工来报道时,要求将该员工的信息加入(id,性别,年龄,住址....),当输入该员工的id时,要求查找到该员工的所有信息
要求:不使用数据库,尽量节省内存,越快越好
对于这种需求和要求,我们就可以 使用哈希表
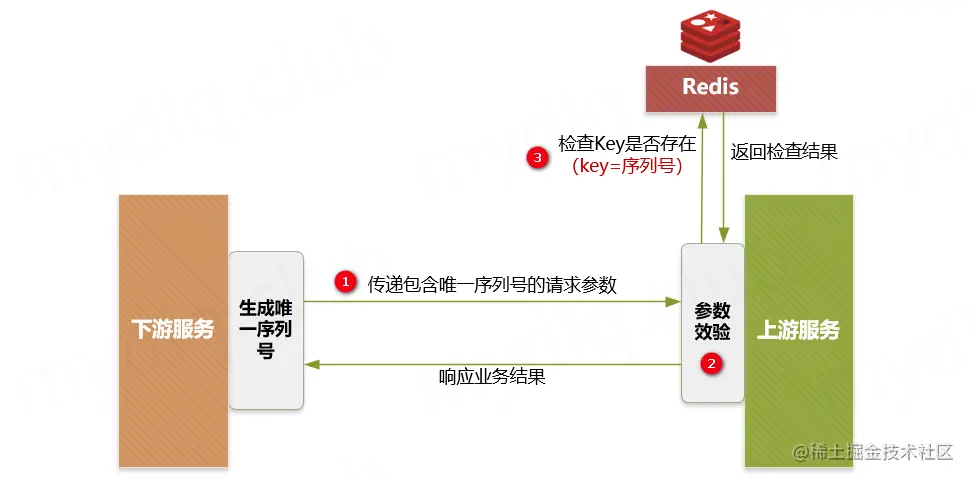
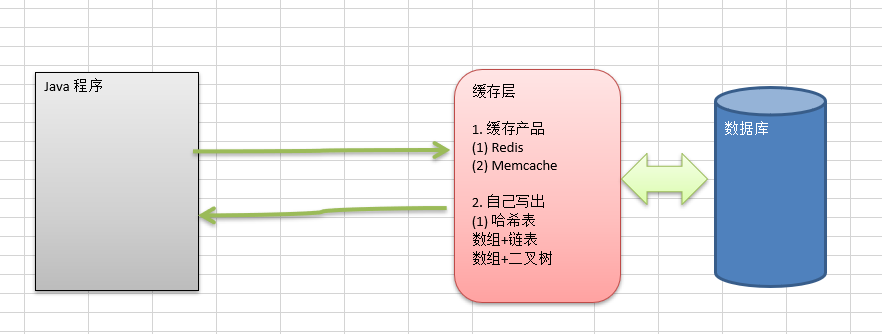
每一次都查询数据库的话对数据库的压力很大,我们需要加一个缓存层(当然也可以加多个缓存层),缓存层的实现方式可以看下图。
比如,我们看下图,若我们用哈希表实现的缓存层,我们可以先把数据放在哈希表,当取数据时先在哈希表中取,取不到再到数据库,如果数据库有的话再给用户返回并添加到哈希表中。
1.2 哈希表的内存结构图
百度来的,不是自己做的
数据+链表的形式,形成散列表(也叫哈希表)
先用散列函数进行计算,看看查找的数据下标进行计算,这样就直接精确到某条链表,更快的查找效率
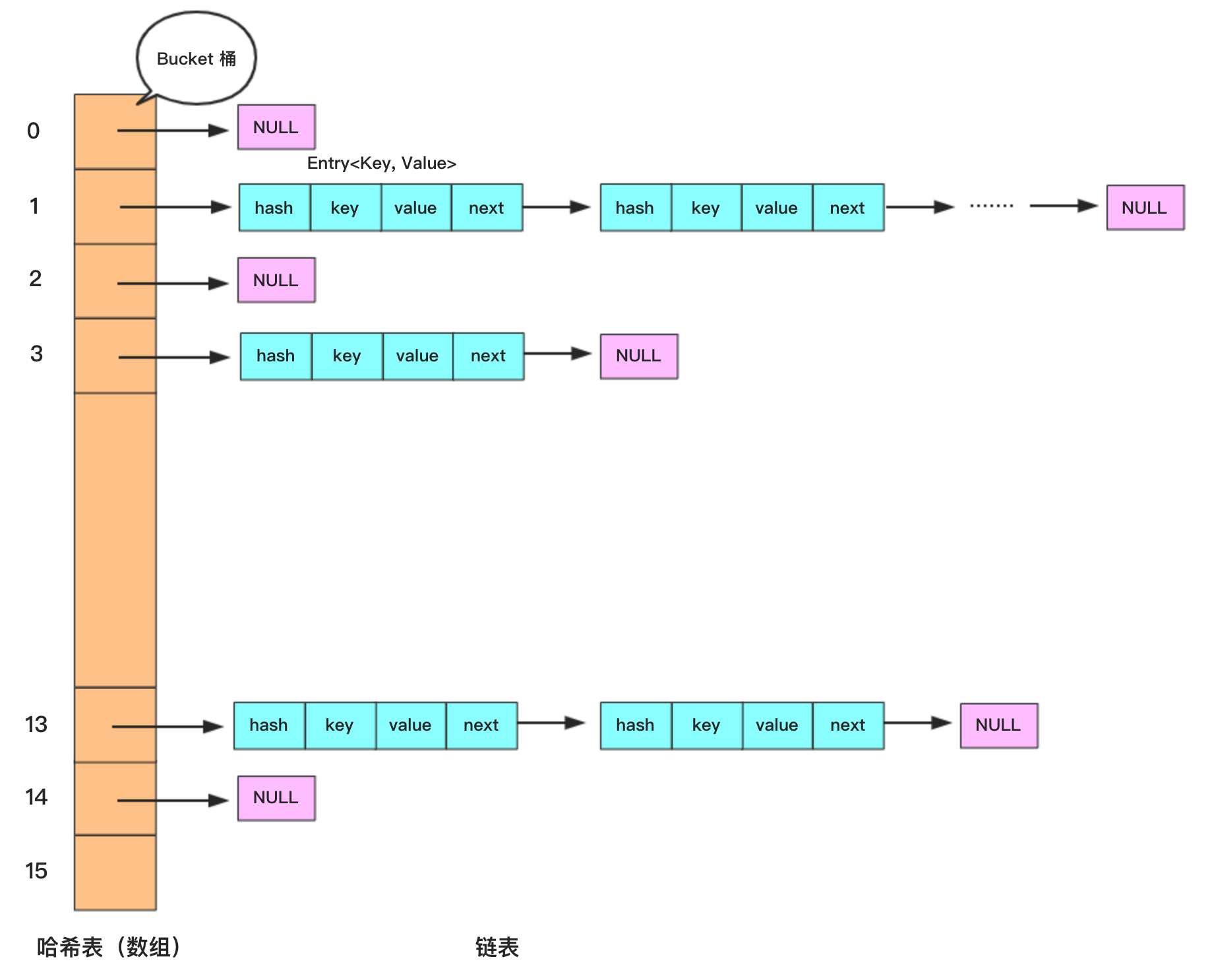
1.3哈希表实现思路图解
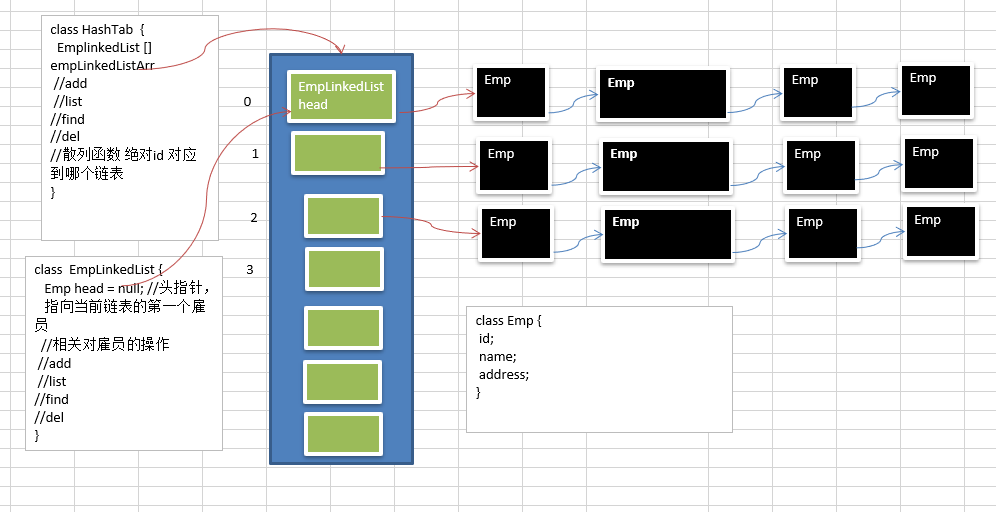
二、代码实现
在之前链表的基础上又添加了一个数组而已,并没有那么的难
哈希表在一定程度上就是一个缓存层但是没有redis缓存那么强大
public class HashTabDemo {
public static void main(String[] args) {
// 创建hash表
HashTab hashTab = new HashTab(7);
Emp emp = new Emp(5, "Tom");
Emp emp2 = new Emp(10, "Tom");
Emp emp3 = new Emp(11, "Tom");
Emp emp4 = new Emp(12, "Tom");
hashTab.add(emp);
hashTab.add(emp2);
hashTab.add(emp3);
hashTab.add(emp4);
hashTab.list();
hashTab.findEmpById(6);
}
}
/**
* 创建HashTab,管理多条链表
*/
class HashTab {
// 链表EmpLinked类型的数组
private EmpLinkedList[] empLinkedListArray;
// 我们要创建的数组的大小,表示最多有多少条链表
private int size;
/**
* 构造方法
*
* @param size 指定empLinkedListArray数组的大小
*/
public HashTab(int size) {
this.size = size;
// 初始化empLinkedListArray,记住,这个仅仅是将数组创建出来了,即 empLinkedListArray!=null,但是 empLinkedListArray[i]==null
empLinkedListArray = new EmpLinkedList[size];
// 有坑,不要忘记这个操作!!!!!!
// 一定给要记好下面的初始化数组下标对应的链表,即让empLinkedListArray[i]!=null
for (int i = 0; i < size; i++) {
empLinkedListArray[i] = new EmpLinkedList();
}
}
/**
* 添加雇员:
* 根据员工的id,得到该员工应该添加到哪条链表之上
*
* @param emp 要添加的雇员
*/
public void add(Emp emp) {
//根据员工的确定员工在哪条链之上
int empLinkedListNo = hashFun(emp.id);
//EmpLinkedList就是链表,在链表上进行添加
empLinkedListArray[empLinkedListNo].add(emp);
}
/**
* 遍历hash表(数组+链表共同组成hash表)
*/
public void list() {
for (int i = 0; i < size; i++) {
// 数组的每一个元素都是一个列表
empLinkedListArray[i].list(i);
}
}
/**
* 根据用户的id,查找雇员
*
* @param id
* @return
*/
public void findEmpById(int id) {
// 根据id我们先确定好在哪条链
int empLinkedListNO = hashFun(id);
// 确定好链之后我们再从链中找元素
Emp emp = empLinkedListArray[empLinkedListNO].findEmpById(id);
if (emp != null) {
// 找到
System.out.println("在"+empLinkedListNO+"中找到雇员:"+emp.id+"---->"+emp.name);
} else {
// 没有找到
System.out.println("没有在哈希表中找到该雇员 ");
}
}
/**
* 编写散列函数,使用一个简单取模法
* 作用:根据员工的id确定在哪条链表之上
*
* @param id
* @return
*/
public int hashFun(int id) {
return id % size;
}
}
/**
* 表示雇员
*/
class Emp {
public int id;
public String name;
public Emp next; //指向下一个节点的引用 next默认为空就可以了
public Emp(int id, String name) {
this.id = id;
this.name = name;
}
}
/**
* 表示链表
*/
class EmpLinkedList {
// 头指针,链表的head,指向第一个雇员Emp,因此我们这里直接这么写就可以
private Emp head; //默认为空
/**
* 添加雇员到列表
* 说明:
* 假定,添加雇员时,id是自增长的,即id的分配总是从小到达,因此我们将该雇员加入到本链表的最后即可
*
* @param emp
*/
public void add(Emp emp) {
if (head == null) {
// head为空说明是第一个雇员,直接将雇员emp赋值给head
head = emp;
// 添加成功直接返回
return;
}
// 运行到这里说明不是第一个雇员,接下来我们就要遍历链表找到对应的地方添加进去
Emp curEmp = head;
while (curEmp.next != null) {
// 移动指针
curEmp = curEmp.next;
}
// 运行到这里curEmp的next是null,我们加在这里就好了
curEmp.next = emp;
}
/**
* 遍历链表的雇员信息
*/
public void list(int number) {
if (head == null) {
// 链表为空
System.out.println("第" + number + "条链表为空");
return;
}
System.out.println("第" + number + "条链表的信息为:");
// 辅助指针遍历链表
Emp curEmp = head;
while (curEmp != null) {
System.out.println("====>id=" + curEmp.id + "-----name=" + curEmp.name);
// 指针后移动
curEmp = curEmp.next;
}
// 单纯的想输出一个换行
System.out.println();
}
/**
* 如果查找到,就返回Emp,没找到返回空
*
* @param id
* @return
*/
public Emp findEmpById(int id) {
if (head == null) {
System.out.println("链表为空");
// 就不用再往下找了
return null;
}
// 辅助指针
Emp curEmp = head;
// 遍历所在的链
while (curEmp != null) {
if (curEmp.id == id) {
break;
}
// 后移
curEmp = curEmp.next;
}
// 这个情况可能是找到了返回结果,也有可能是这个链上直接没有返回的null
return curEmp;
}
}