HBase 2.x主要包含以下核心功能:
1、基于Procedure v2重新设计了HBase的Assignment Manager和核心管理流程。通过Procedure v2,HBase能保证各核心步骤的原子性,从设计上解决了分布式场景下多状态不一致的问题。
2、实现了In Memory Compaction功能。该功能将MemStore分成若干小数据块,将多个数据块在MemStore内部做Compaction,一方面缓解了写放大的问题,另一方面降低了写路径的GC压力。
3、存储MOB数据。2.0.0版本之前对大于1MB的数据支持并不友好,因为大value场景下Compaction会加剧写放大问题,同时容易挤占HBase的BucketCache。而新版本通过把大value存储到独立的HFile中来解决这个问题,更好地满足了多样化的存储需求。
4、读写路径全链路Offheap化。在2.0版本之前,HBase只有读路径上的BucketCache可以存放Offheap,而在2.0版本中,社区实现了从RPC读请求到完成处理,最后到返回数据至客户端的全链路内存的Offheap化,从而进一步控制了GC的影响。
5、异步化设计。异步的好处是在相同线程数的情况下,提升系统的吞吐量。2.0版本中做了大量的异步化设计,例如提供了异步的客户端,采用Netty实现异步RPC,实现asyncFsWAL等。
一、Procedure功能
1, Procedure定义
一个Procedure一般由多个subtask组成,每个subtask是一些执行步骤的集合,这些执行步骤中又会依赖部分Procedure。
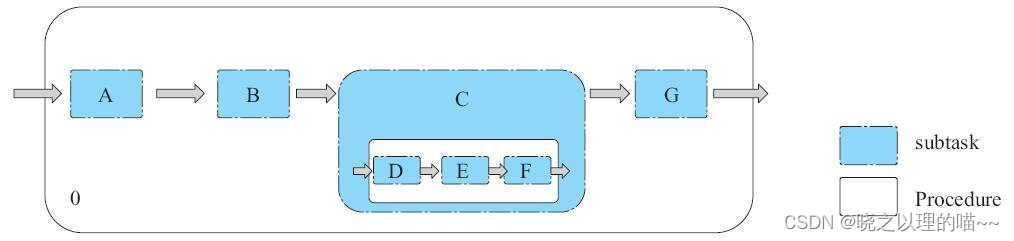
上图Procedure.0有A、B、C、G共4个subtask,而这4个subtask中的C又有1个Procedure,也就是说只有等这个Procedure执行完,C这个subtask才能算执行成功。而C中的子Procedure,又有D、E、F共3个subtask。
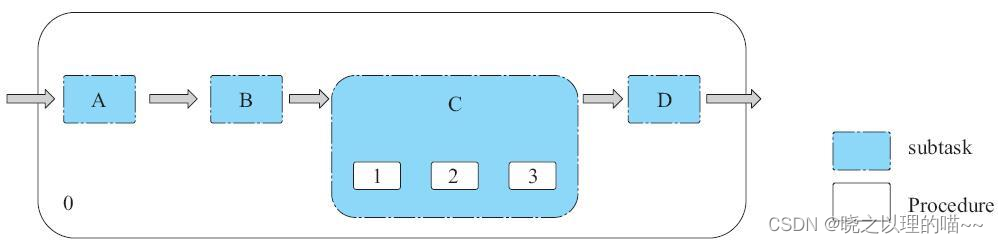
上图Procedure.0有A、B、C、D共4个subtask。其中subtask C又有Procedure.1、Procedure.2、Procedure.3共3个子Procedure。
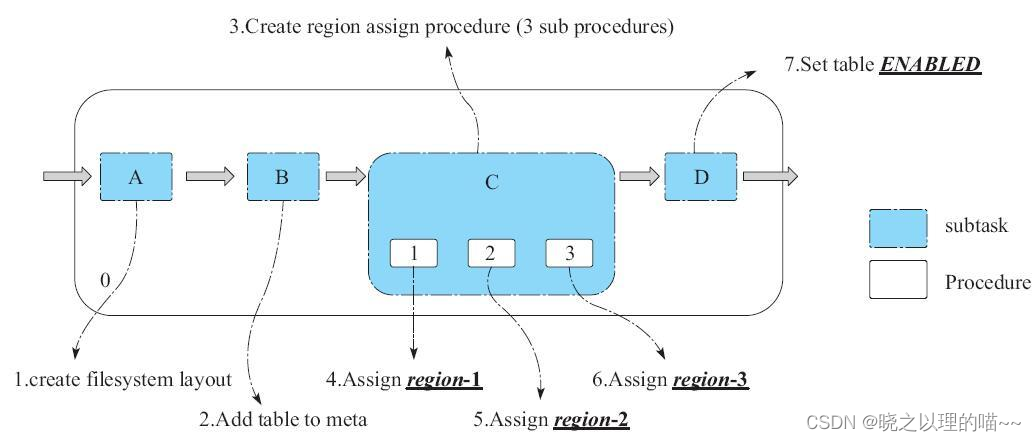
建表操作可以认为是一个Procedure,它由4个subtask组成。
(1)subtask.A:用来初始化Test表在HDFS上的文件。
(2)subtask.B:在hbase:meta表中添加Test表的Region信息。
(3)subtask.C:将3个region分配到多个节点上,而每个Assign region的过程又是一个Procedure。
(4)subtask.D:最终将表状态设置为ENABLED
在明确了Procedure的结构之后,需要理解Procedure提供的两个接口:execute()和rollback(),其中execute()接口用于实现Procedure的执行逻辑,rollback()接口用于实现Procedure的回滚逻辑。这两个接口的实现需要保证幂等性。也就是说,如果x=1,执行两次increment(x)后,最终x应该等于2,而不是等于3。因为我们需要保证increment这个subtask在执行多次之后,同执行一次得到的结果完全相等。
2,Procedure执行和回滚
以建表的Procedure为例,探讨Procedure v2是如何保证整个操作的原子性的。
首先,引入Procedure Store的概念,Procedure内部的任何状态变化,或者Procedure的子Procedure状态发生变化,或者从一个subtask转移到另一个subtask,都会被持久化到HDFS中。持久化的方式也很简单,就是在Master的内存中维护一个实时的Procedure镜像,然后有任何更新都把更新顺序写入Procedure WAL日志中。由于Procedure的信息量很少,内存占用小,所以只需内存镜像加上WAL的简单实现,即可保证Procedure状态的持久性。
其次,需要理解回滚栈和调度队列的概念。回滚栈用于将Procedure的执行过程一步步记录在栈中,若要回滚,则一个个出栈依次回滚,即可保证整体任务流的原子性。调度队列指的是Procedure在调度时使用的一个双向队列,如果某个Procedure调度优先级特别高,则直接入队首;如果优先级不高,则直接入队尾。
Procedure的回滚:有了回滚栈这个状态之后,在执行任何一步发生异常需要回滚的时候,都可以按照栈中顺序依次将之前已经执行成功的subtask或者子Procedure回滚,且严格保证了回滚顺序和执行顺序相反。如果某一步回滚失败,上层设计者可以选择重试,也可以选择跳过继续重试当前任务(设计代码抛出不同类型的异常),直接回滚栈中后一步状态。
注意:Procedure的rollback()实现必须是幂等的,因此在重试的时候,即使某一步回滚多次,依然能保证状态的一致性。
3,Procedure Suspend
在执行Procedure时,可能在某个阶段遇到异常后需要重试。而多次重试之间可以设定一段休眠时间,防止因频繁重试导致系统出现更恶劣的情况。这时候需要suspend当前运行的Procedure,等待设定的休眠时间之后,再重新进入调度队列,继续运行这个Procedure。
下面仍然以上文讨论过的CreateTableProcedure为例,说明Procedure的Suspend过程。首先,需要理解一个简单的概念——DelayedQueue,也就是说每个Suspend的Procedure都会被放入这个DelayedQueue队列,等待超时时间消耗完之后,一个叫作TimeoutExecutorThread的线程会把Procedure取出,放到调度队列中,以便继续执行。
4,Procedure Yield
Procedure v2框架还提供了另一种处理重试的方式——把当前异常的Procedure直接从调度队列中移走,并将Procedure添加到调度队列队尾。等待前面所有的Procedure都执行完成之后,再执行上次有异常的Procedure,从而达到重试的目的。
HBase 2.x版本的大量任务调度流程都使用Procedure v2重写,典型如建表流程、删表流程、修改表结构流程、Region Assign和Unassign流程、故障恢复流程、复制链路增删改流程等。当然,仍然有一些管理流程没有采用Procedure v2重写,例如权限管理(HBASE-13687)和快照管理(HBASE-14413),这些功能将作为Procedure v2的第三期功能在未来的HBase3.0中发布,社区非常欢迎有兴趣的读者积极参与。
另外,值得一提的是,由于引入Procedure v2,原先设计上的缺陷得到全面解决,因此在HBase 1.x中引入的HBCK工具将大量简化。当然,HBase 2.x版本仍然提供了HBCK工具,目的是防止由于代码Bug导致某个Procedure长期卡在某个流程,使用时可以通过HBCK跳过某个指定Prcedure,从而使核心流程能顺利地运行下去。
二、In Memory Compaction
在HBase 2.0版本中,为了实现更高的写入吞吐和更低的延迟,社区团队对MemStore做了更细粒度的设计。这里,主要指的就是In Memory Compaction。
一个表有多个Column Family,而每个Column Family其实是一个LSM树索引结构,LSM树又细分为一个MemStore和多个HFile。随着数据的不断写入,当MemStore占用内存超过128MB(默认)时,开始将MemStore切换为不可写的Snapshot,并创建一个新MemStore供写入,然后将Snapshot异步地flush到磁盘上,最终生成一个HFile文件。可以看到,这个MemStore设计得较为简单,本质上是一个维护cell有序的ConcurrentSkipListMap。
1,Segment
Segment本质上是维护一个有序的cell列表。
根据cell列表是否可更改,Segment可以分为两种类型:
(1)MutableSegment:该类型的Segment支持添加cell、删除cell、扫描cell、读取某个cell等操作。因此一般使用一个ConcurrentSkipListMap来维护列表。
(2)ImmutableSegment:该类型的Segment只支持扫描cell和读取某个cell这种查找类操作,不支持添加、删除等写入操作。因此简单来说,只需要一个数组维护即可。
注意:无论是何种类型的Segment,都需要实时保证cell列表的有序性。
2,CompactingMemstore
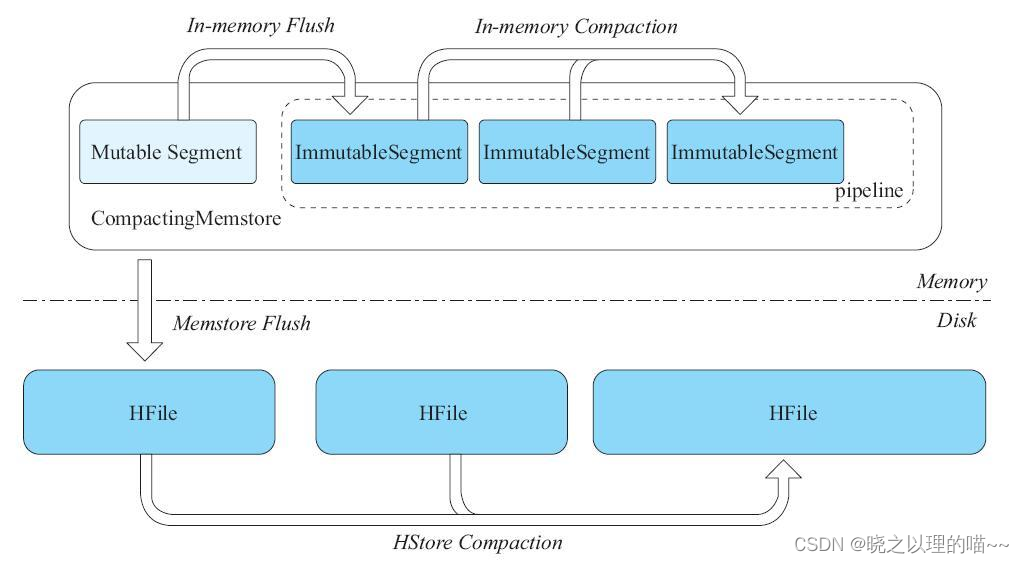
在HBase 2.0中,设计了CompactingMemstore。CompactingMemstore将原来128MB的大MemStore划分成很多个小的Segment,其中有一个MutableSegment和多个ImmutableSegment。该Column Family的写入操作,都会先写入MutableSegment。一旦发现MutableSegment占用的内存空间超过2MB,则把当前MutableSegment切换成ImmutableSegment,然后再初始化一个新的MutableSegment供后续写入。
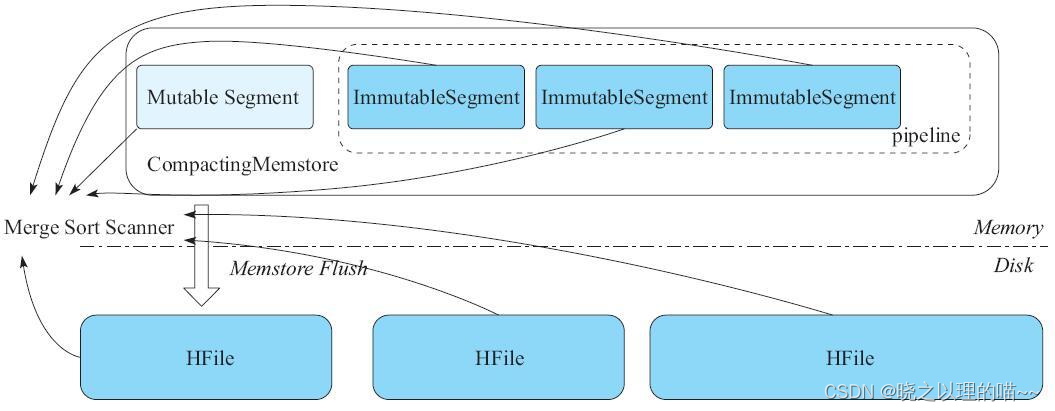
CompactingMemstore中的所有ImmutableSegment,我们称之为一个Pipeline对象。本质上,就是按照ImmutableSegment加入的顺序,组织成一个FIFO队列。当对该Column Family发起读取或者扫描操作时,需要将这个CompactingMemstore的一个MutableSegment、多个ImmutableSegment以及磁盘上的多个HFile组织成多个内部数据有序的Scanner。然后将这些Scanner通过多路归并算法合并生成Scanner,如上图所示,最终通过这个Scanner可以读取该Column Family的数据。
但随着数据的不断写入,ImmutableSegment个数不断增加,如果不做任何优化,需要多路归并的Scanner会很多,这样会降低读取操作的性能。所以,当ImmutableSegment个数到达某个阈值(可通过参数hbase.hregion.compacting.pipeline.segments.limit设定,默认值为2)时,CompactingMemstore会触发一次In Memory的Memstore Compaction,也就是将CompactingMemstore的所有ImmutableSegment多路归并成一个ImmutableSegment。这样,CompactingMemstore产生的Scanner数量会得到很好的控制,对读性能基本无影响。同时在某些特定场景下,还能在Memstore Compact的过程中将很多可以确定为无效的数据清理掉,从而达到节省内存空间的目的。这些无效数据包括:TTL过期的数据,超过Family指定版本的cell,以及被用户删除的cell。
在内存中进行Compaction之后,MemStore占用的内存增长会变缓,触发MemStore Flush的频率会降低。
3, 更多优化
CompactingMemstore中有了ImmutableSegment之后,我们便可以做更多细致的性能优化和内存优化工作。
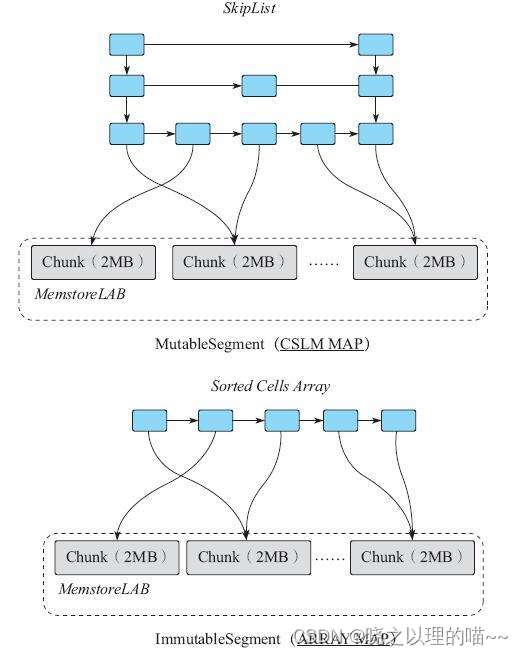
ConcurrentSkipListMap是一个内存和CPU都开销较大的数据结构。采用In Memory Compaction后,一旦ImmutableSegment需要维护的有序列表不可变,就可以直接使用数组(之前使用跳跃表)来维护有序列表。相比使用跳跃表,至少节省了跳跃表最底层链表之上所有节点的内存开销,对Java GC是一个很友好的优化。
因为,ImmutableSegment占用的内存更少,同样是128MB的MemStore,Compacting-Memstore可以在内存中存放更多的数据。相比DefaultMemstore,CompactingMemstore触发Flush的频率就会小很多,单次Flush操作生成的HFile数据量会变大。于是,磁盘上HFile数量的增长速度就会变慢。
优化效果:
(1)磁盘上Compaction的触发频率降低。很显然,HFile数量少了,无论是Minor Compaction还是Major Compaction,次数都会降低,这就节省了很大一部分磁盘带宽和网络带宽。
(2)生成的HFile数量变少,读取性能得到提升。
(3)新写入的数据在内存中保留的时间更长了。针对那种写完立即读的场景,性能有很大提升。
在查询的时候,数组可以直接通过二分查找来定位cell,性能比跳跃表也要好很多(虽然复杂度都是O(logN),但是常数好很多)。使用数组代替跳跃表之后,每个ImmutableSegment仍然需要在内存中维护一个cell列表,其中每一个cell指向MemstoreLAB中的某一个Chunk(默认大小为2MB)。这个cell列表仍然可以进一步优化,也就是可以把这个cell列表顺序编码在很少的几个Chunk中。这样,ImmutableSegment的内存占用可以进一步减少,同时实现了零散对象的“凑零为整”,这对Java GC来说,又是相当友好的一个优化。尤其MemStore Offheap化之后,cell列表这部分内存也可以放到offheap,onheap内存进一步减少,Java GC也会得到更好的改善。
三、MOB对象存储
1,HBase MOB设计
HBase MOB方案的设计本质上与HBase+HDFS方案相似,都是将Meta数据和MOB数据分开存放到不同的文件中。区别是,HBase MOB方案完全在HBase服务端实现,cell首先写入MemStore,在MemStore Flush到磁盘的时候,将Meta数据和cell的Value分开存储到不同文件中。之所以cell仍然先存MemStore,是因为如果在写入过程中,将这些cell直接放到一个单独的文件中,则在Flush过程中很难保证Meta数据和MOB数据的一致性。因此,这种设计也就决定了cell的Value数据量不能太大,否则一次写入可能撑爆MemStore,造成OOM或者严重的Full GC。
(1)写操作
在建表时,我们可以对某个Family设置MOB属性,并指定MOB阈值,如果cell的Value超过MOB阈值,则按照MOB的方式来存储cell;否则按照正常方式存储cell。
MOB数据的写路径实现,超过MOB阈值的cell仍然和正常cell一样,先写WAL日志,再写MemStore。但是在MemStore Flush的时候,RegionServer会判断当前取到的cell是否为MOB cell,若不是则直接按照原来正常方式存储cell;若是MOB cell,则把Meta数据写正常的StoreFile,把MOB的Value写入到一个叫作MobStoreFile的文件中。
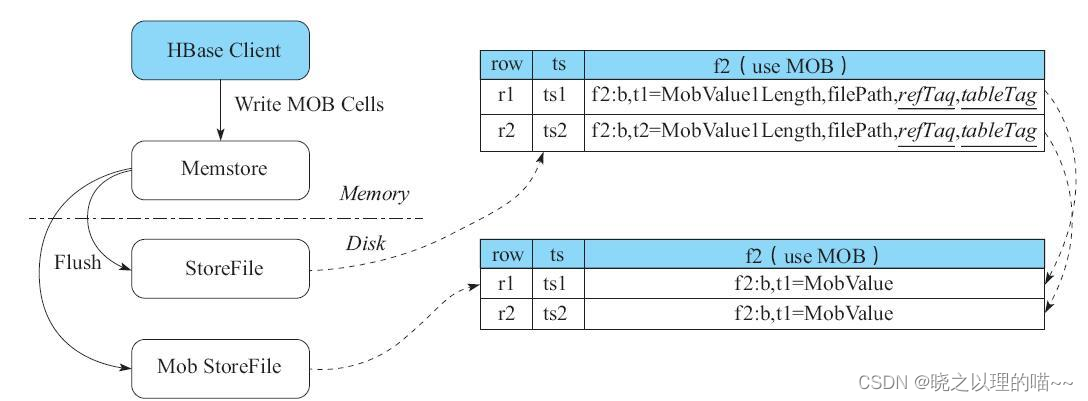
Meta数据cell内存储的内容包括:
1)row、timestamp、family、qualifer这4个字段,其内容与原始cell保持一致。
2)value字段主要存储——MOB cell中Value的长度(占4字节),MOB cell中Value实际存储的文件名(占72字节),两个tag信息。其中一个tag指明当前cell是一个reference cell,即表明当前Cell是一个MOB cell,另外一个tag指明所属的表名。注意,MobStoreFile的文件名长度固定为72字节。
(2)读操作
首先按照正常的读取方式,读正常的StoreFile。若读出来的cell不包含reference tags,则直接将这个cell返回给用户;否则解析这个cell的Value值,这个值就是MobStoreFile的文件路径,在这个文件中读取对应的cell即可。
注意,默认的BucketCache最大只缓存513KB的cell。所以对于大部分MOB场景而言,MOB cell是没法被Bucket Cache缓存的,事实上,Bucket Cache也并不是为了解决大对象缓存而设计的。所以,在第二次读MobStoreFile时,一般都是磁盘IO操作,性能会比读非MOB cell差一点,但是对于大部分MOB读取场景,应该可以接受。
当然,MOB方案也设计了对应的Compaction策略,来保证MOB数据能得到及时的清理,只是在Compaction频率上设置得更低,从而避免由于MOB而导致的写放大现象。
2,实践
为了能够正确使用HBase 2.0版本的MOB功能,用户需要确保HFile的版本是version 3。添加如下配置选项到hbase-site.xml:
hfile.format.version=3
在HBase Shell中,可以通过如下方式设置某一个Column Family为MOB列。换句话说,如果这个列簇上的cell的Value部分超过了100KB,则按照MOB方式来存储;否则仍按照默认的KeyValue方式存储数据。
create 't1', {NAME => 'f1', IS_MOB => true, MOB_THRESHOLD => 102400}
当然,也可以通过如下Java代码来设置一个列簇为MOB列:
HColumnDescriptor hcd = new HColumnDescriptor("f");
hcd.setMobEnabled(true);
hcd.setMobThreshold(102400);
对于MOB功能,可以指定如下几个参数:
hbase.mob.file.cache.size=1000
hbase.mob.cache.evict.period=3600
hbase.mob.cache.evict.remain.ratio=0.5f
HBase目前提供了如下工具来测试MOB的读写性能。
./bin/hbase org.apache.hadoop.hbase.IntegrationTestIngestWithMOB \
-threshold 1024 \
-minMobDataSize 512 \
-maxMobDataSize 5120
3,总结
HBase MOB功能满足了在HBase中直接存储中等大小cell的需求,而且是一种完全在服务端实现的方案,对广大HBase用户非常友好。同时,还提供了HBase大部分的功能,例如复制、BulkLoad、快照等。但是,MOB本身也有一定局限性:
1)每次cell写入都要存MemStore,这导致没法存储Value过大的cell,否则内存容易被耗尽。
2)暂时不支持基于Value过滤的Filter。当然,一般很少有用户会按照一个MOB对象的内容做过滤。
四、Offheap读路径和Offheap写路径
HBase作为一个分布式数据库系统,需要保证数据库读写操作有可控的低延迟。由于使用Java开发,一个不可忽视的问题是GC的STW(Stop The World)的影响。在CMS中,主要考虑YoungGC和Full GC的影响,在G1中,主要考虑Young GC和mixed GC的影响。下面以G1为例探讨GC对HBase的影响。
在整个JVM进程中,HBase占用内存最大的是写缓存和读缓存。写缓存是上文所说的MemStore,因为所有写入的KeyValue数据都缓存在MemStore中,只有等MemStore内存占用超过阈值才会Flush数据到磁盘上,最后内存得以释放。读缓存,即我们常说的BlockCache。HBase并不提供行级别缓存,而是提供以数据块(Data Block)为单位的缓存,也就是读一行数据,先将这一行数据所在的数据块从磁盘加载到内存中,然后放入LRU Cache中,再将所需的行数据返回给用户后,数据块会按照LRU策略淘汰,释放内存。
MemStore和BlockCache两者一般会占到进程总内存的80%左右,而且这两部分内存会在较长时间内被对象引用(例如MemStore必须Flush到磁盘之后,才能释放对象引用;Block要被LRUCache淘汰后才能释放对象引用)。因此,这两部分内存在JVM分代GC算法中,会长期位于old区。而小对象频繁的申请和释放,会造成老年代内存碎片严重,从而导致触发并发扫描,最终产生大量mixed GC,大大提高HBase的访问延迟。
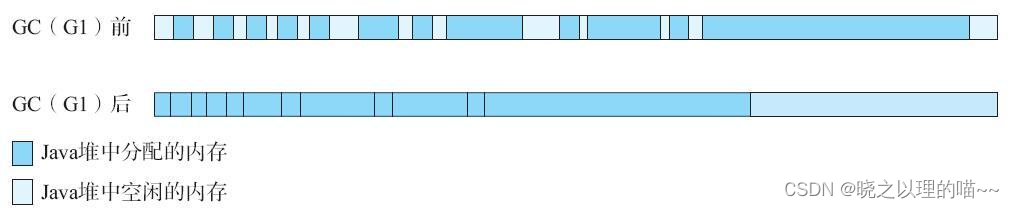
一种最常见的内存优化方式是,在JVM堆内申请一块连续的大内存,然后将大量小对象集中存储在这块连续的大内存上。这样至少减少了大量小对象申请和释放,避免堆内出现严重的内存碎片问题。本质上也相当于减少了old区触发GC的次数,从而在一定程度上削弱了GC的STW对访问延迟的影响。
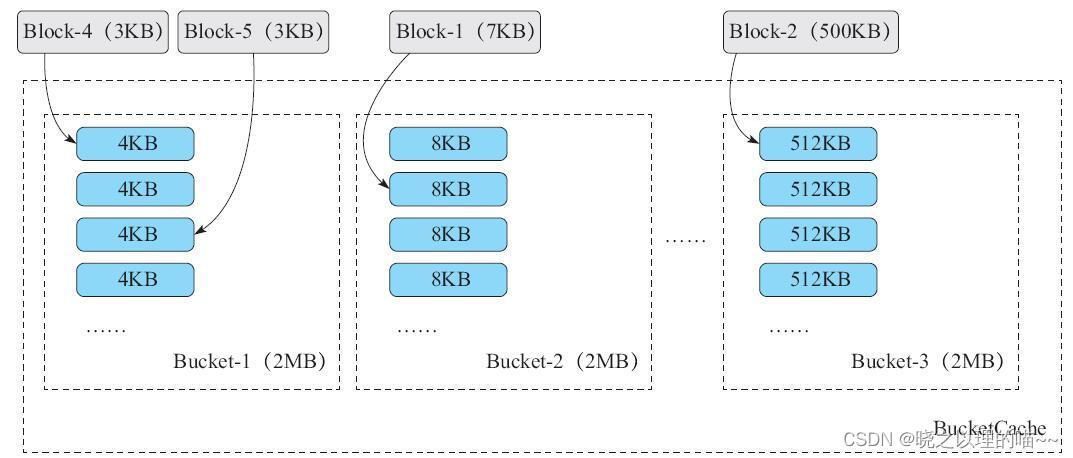
MemStore的MSLAB和BlockCache的BucketCache,核心思想就是上述的“凑零为整”,也就是将多个零散的小对象凑成一个大对象,向JVM堆内申请。以堆内BucketCache为例,HBase向堆内申请多块连续的2MB大小的内存,然后每个2MB的内存划分成4KB,8KB,…,512KB的小块。若此时有两个3KB的Data Block,则分配在图中的Bucket-1中,因为4KB是能装下3KB的最小块。若有一个7KB的Data Block,则分配在图中的Bucket-2,因为8KB是能装下7KB的最小块。内存释放时,则直接标记这些被占用的4KB,8KB,…512KB块为可用状态。这样,我们把大量较小的数据块集中分布在多个连续的大内存上,有效避免了内存碎片的产生。有些读者会发现用512KB装500KB的数据块,有12KB的内存浪费,这其实影响不大,因为BucketCache一旦发现内存不足,就会淘汰掉部分Data Block以腾出内存空间。
基本解决了因MemStore和BlockCache中小对象申请和释放而造成大量碎片的问题。虽然堆内的申请和释放都是以大对象为单位,但是old区一旦触发并发扫描,这些大对象还是要被扫描。如图15-36所示,对G1这种在old GC会整理内存(compact)的算法来说,这些占用连续内存的大对象还是可能从一个区域被JVM移动到另外一个区域,因此一旦触发Mixed GC,这些MixedGC的STW时间可能较高。换句话说,“凑零为整”主要解决碎片导致GC过于频繁的问题,而单次GC周期内STW过长的问题,仍然无法解决。

事实上,JVM支持堆内(onheap)和堆外(offheap)两种内存管理方式。堆内内存的申请和释放都是通过JVM来管理的,平常所谓GC都是回收堆内的内存对象;堆外内存则是JVM直接向操作系统申请一块连续内存,然后返回一个DirectByteBuffer,这块内存并不会被JVM的GC算法回收。因此,另一种常见的GC优化方式是,将那些old区长期被引用的大对象放在JVM堆外来管理,堆内管理的内存变少了,单次old GC周期内的STW也就能得到有效的控制。
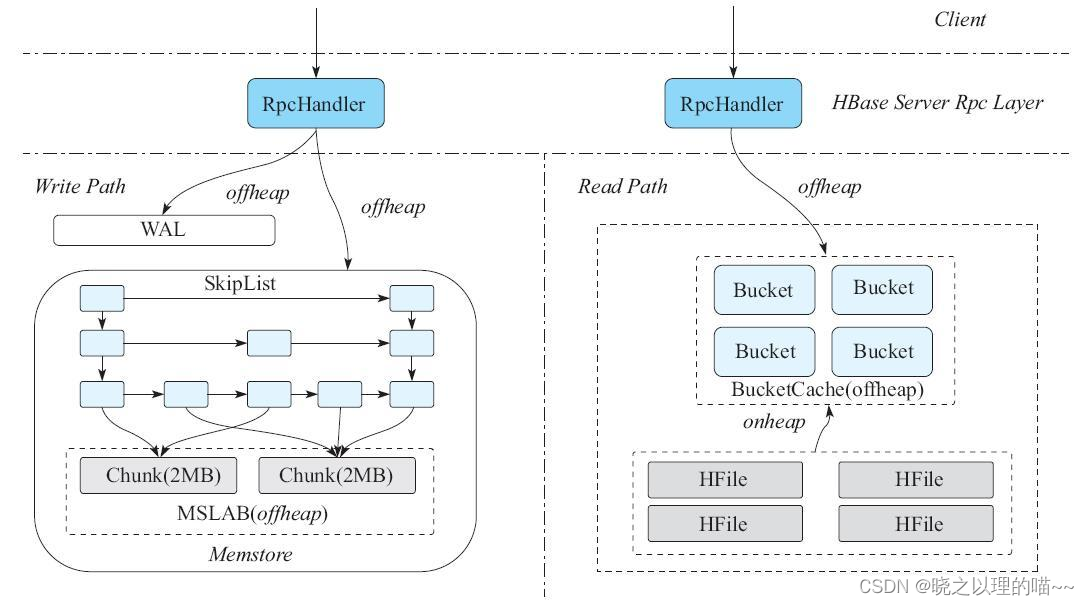
具体到HBase,就是把MemStore和BucketCache这两块最大的内存从堆内管理改成堆外管理。甚至更进一步,我们可以从RegionServer读到客户端RPC请求那一刻起,把所有内存申请都放在堆外,直到最终这个RPC请求完成,并通过socket发送到客户端。所有的内存申请都放在堆外,这就是后面要讨论的读写全路径offheap化。
但是,采用offheap方式分配内存后,一个严重的问题是容易内存泄漏,一旦某块内存忘了回收,则会一直被占用,而堆内内存GC算法会自动清理。因此,对于堆外内存而言,一个高效且无泄漏的内存管理策略显得非常重要。目前HBase 2.x上的堆外内存分配器较为简单,内存分配器由堆内分配器和堆外分配器组合而成,堆外内存划分成多个64KB大小内存块。
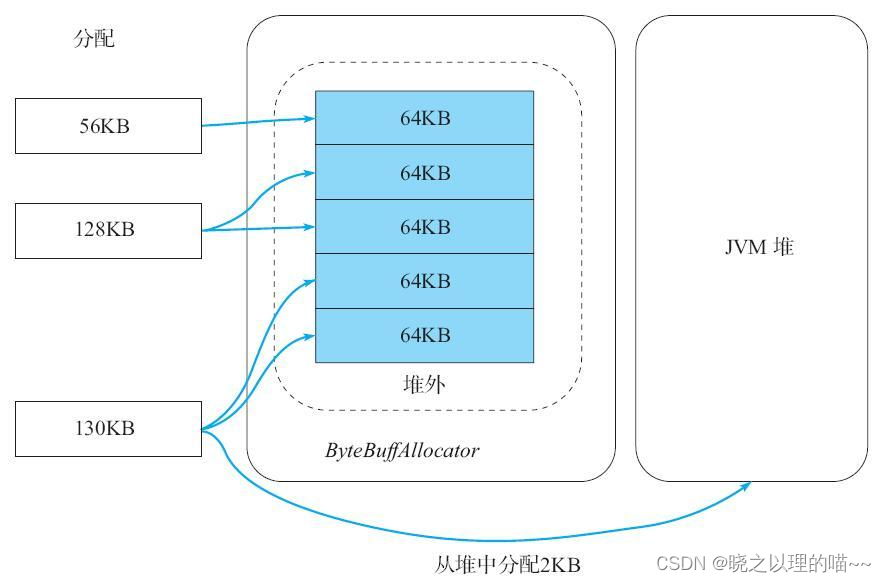
HBase申请内存时,需要遵循以下规则:
1)分配小于8KB的小内存,如果直接分一个堆外的64KB块会比较浪费,所以此时仍然从堆内分配器分配。
2)分配大于等于8KB且不超过64KB的中等大小内存,此时可以直接分配一个64KB的堆外内存块。
3)分配大于64KB的较大内存,此时需要将多个64KB的堆外内存组成一个大内存,剩余部分通过第1条或第2条规则来分配。例如,要申请130KB的内存,首先分配器会申请2个64KB的堆外内存块,剩余的2KB直接去堆内分配。
1,读路径offheap化
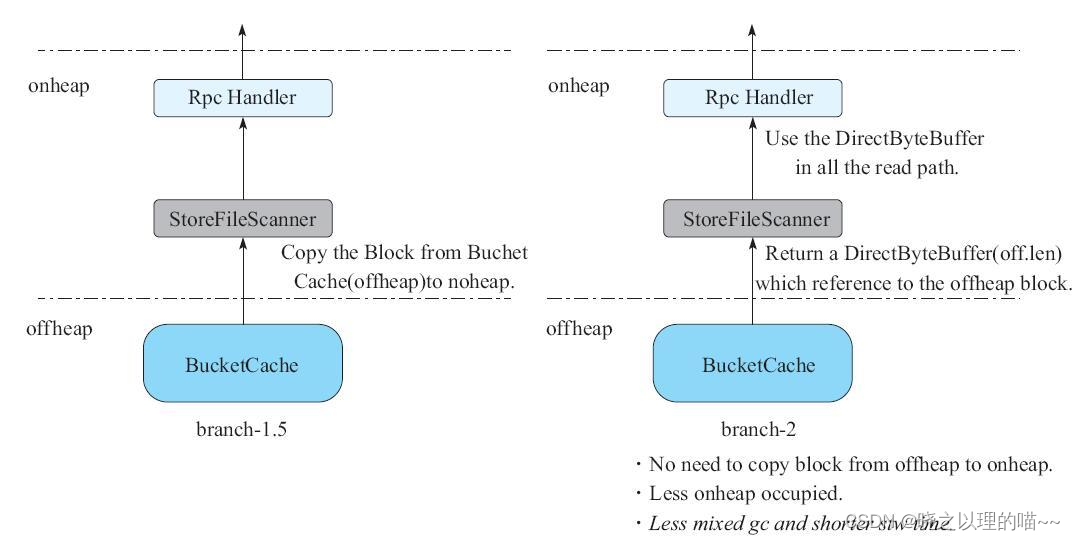
在HBase 2.0版本之前,如果用户的读取操作命中了BucketCache的某个Block,那么需要把BucketCache中的Block从堆外拷贝一份到堆内,最后通过RPC将这些数据发送给客户端。
从HBase 2.0开始,一旦用户命中了BucketCache中的Block,会直接把这个Block往上层Scanner传,不需要从堆外把Block拷贝一份到堆内,因为社区已经把整个读路径都ByteBuffer化了,整个读路径上并不需要关心Block到底来自堆内还是堆外,这样就避免了一次拷贝的代价,减少了年轻代的内存垃圾。
2,写路径offheap化
客户端的写入请求发送到服务端时,服务端可以根据protobuffer协议提前知道这个request的总长度,然后从ByteBufferPool里面拿出若干个ByteBuffer存放这个请求。写入WAL的时候,通过ByteBuffer接口写入HDFS文件系统(原生HDFS客户端并不支持写入ByteBuffer接口,HBas自己实现的asyncFsWAL支持写入ByteBuffer接口),写入MemStore的时,则直接将ByteBuffer这个内存引用存入到CSLM(CocurrentSkip ListMap),在CSLM内部对象compare时,则会通过ByteBuffer指向的内存来比较。直到MemStore flush到HDFS文件系统,KV引用的ByteBuffer才得以最终释放到堆外内存中。这样,整个KV的内存占用都是在堆外,极大地减少了堆内需要GC的内存,从而避免了出现较长STW(Stop The World)的可能。
在测试写路径offheap时,一个特别需要注意的地方是KV的overhead。如果我们设置的kvlength=100字节,则会有100字节的堆内额外开销。因此如果原计划分6GB的堆内内存给MemStore,则需要分3GB给堆内,3GB给堆外,而不是全部6GB都分给堆外。
3,总结
为了尽可能避免Java GC对性能造成不良影响,HBase 2.0已经对读写两条核心路径做了offheap化,也就是直接向JVM offheap申请对象,而offheap分出来的内存都不会被JVM GC,需要用户自己显式地释放。在写路径上,客户端发过来的请求包都被分配到offheap的内存区域,直到数据成功写入WAL日志和MemStore,其中维护MemStore的ConcurrentSkipListSet其实也不是直接存cell数据,而是存cell的引用,真实的内存数据被编码在MSLAB的多个Chunk内,这样比较便于管理offheap内存。类似地,在读路径上,先尝试读BucketCache,Cache命中时直接去堆外的BucketCache上读取Block;否则Cache未命中时将直接去HFile内读Block,这个过程在Hbase 2.3.0版本之前仍然是走heap完成。拿到Block后编码成cell发送给用户,大部分都是走BucketCache完成的,很少涉及堆内对象申请。
但是,在小米内部最近的性能测试中发现,100%get的场景受Young GC的影响仍然比较严重,在HBASE-21879中可以非常明显地观察到get操作的p999延迟与G1Young GC的耗时基本相同,都为100ms左右。按理说,在HBASE-11425之后,所有的内存分配都是在offheap的,heap内应该几乎没有内存申请。但是,仔细梳理代码后发现,从HFile中读Block的过程仍然是先拷贝到堆内去的,一直到BucketCache的WriterThread异步地把Block刷新到Offheap,堆内的DataBlock才释放。而磁盘型压测试验中,由于数据量大,Cache命中率并不高(约为70%),所以会有大量的Block读取走磁盘IO,于是堆内产生大量的年轻代对象,最终导致Young区GC压力上升。
消除Young GC的直接思路就是,从HFile读DataBlock开始,直接去Offheap上读。小米HBase团队已经在持续优化这个问题,可以预期的是,HBase 2.x性能必定朝更好的方向发展,尤其是GC对p99和p999的影响会越来越小。
五、异步化设计
1,异步客户端
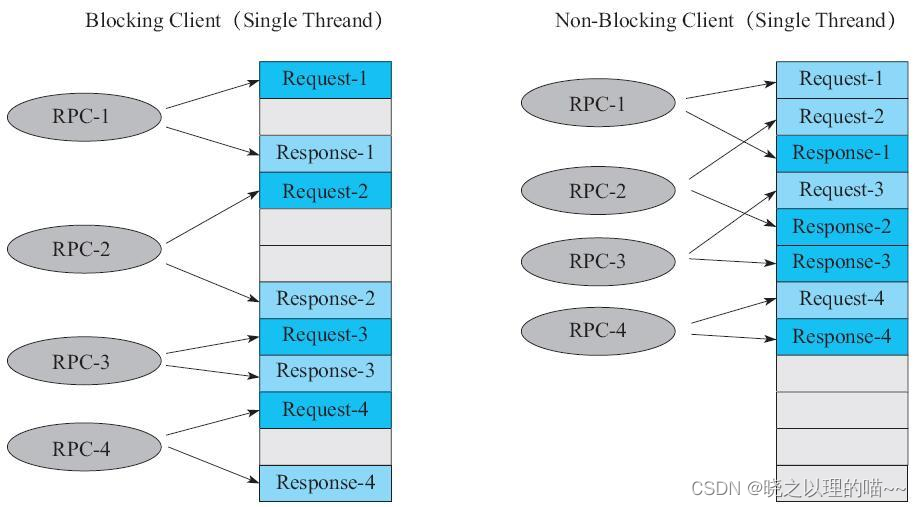
左侧是同步客户端处理流程,右侧是异步客户端处理流程。很明显,在客户端采用单线程的情况下,同步客户端必须等待上一次RPC请求操作完成,才能发送下一次RPC请求。如果RPC2操作耗时较长,则RPC3一定要等RPC2收到Response之后才能开始发送请求,这样RPC3的等待时间就会很长。异步客户端很好地解决了后面请求等待时间过长的问题。客户端发送完第一个RPC请求之后,并不需要等待这次RPC的Response返回,可以直接发送后面请求的Request,一旦前面RPC请求收到了Response,则通过预先注册的Callback处理这个Response。这样,异步客户端就可以通过节省等待时间来实现更高的吞吐量。
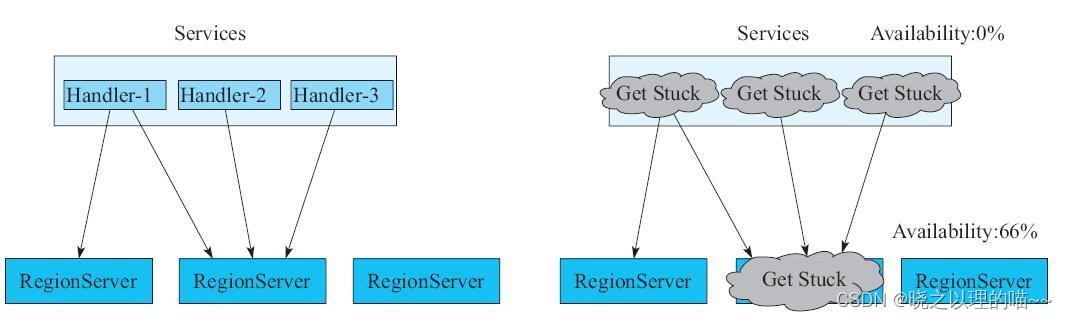
异步客户端还有其他的好处,如果HBase业务方设计了3个线程来同步访问HBase集群的RegionServer,其中Handler1、Handler2、Handler3同时访问了中间的这台RegionServer。如果中间的RegionServer因为某些原因卡住了,那么此时HBase服务可用性的理论值为66%,但实际情况是业务的可用性已经变成0%,因为可能业务方所有的Handler都因为这台故障的RegionServer而卡住。换句话说,在采用同步客户端的情况下,HBase方的任何故障,在业务方会被一定程度地放大,进而影响上层服务体验。事实上,影响HBase可用性的因素有很多,且没法完全避免。例如RegionServer或者Master由于STW的GC卡住、访问HDFS太慢、RegionServer由于异常情况挂掉、某些热点机器系统负载高,等等。因此,社区在HBase 2.0中设计并实现了异步客户端。
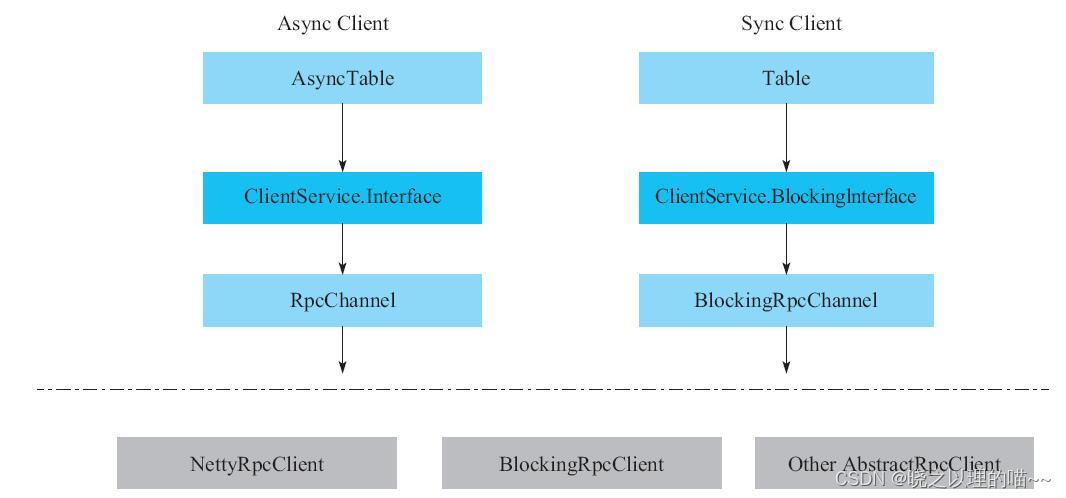
异步客户端和同步客户端的架构相比,异步客户端使用ClientService.Interface,而同步客户端使用ClientService.BlockingInterface,Interface的方法需要传入一个callback来处理返回值,而BlockingInterface的方法会阻塞并等待返回值。值得注意的是,异步客户端也可以跑在BlockingRpcClient上,因为本质上,只要BlockingRpcClient实现了传入callback的ClientService.Interface,就能实现异步客户端上层的接口。
异步客户端操作HBase的示例:
首先通过conf拿到一个异步的connection,并在asynConn的callback中继续拿到一个asyncTable,接着在这个asyncTable的callback中继续异步地读取HBase数据。可以看出,异步客户端的一个特点是,对那些所有可能做IO或其他耗时操作的方法来说,其返回值都是一个CompletableFuture,然后在这个CompletableFuture上注册回调函数,进一步处理返回值。
CompletableFuture<Result> asyncResult = new CompletableFuture<>();
ConnectionFactory.createAsyncConnection(conf).whenComplete((asyncConn, error) -> {
if (error != null) {
asyncResult.completeExceptionally(error);
return;
}
AsyncTable<?> table =asyncConn.getTable(TABLE_NAME);
table.get(new Get(ROW_KEY)).whenComplete((result, throwable) -> {
if (throwable != null) {
asyncResult.completeExceptionally(throwable);
return;
}
asyncResult.complete(result);
});
});
异步客户端有一些常见的注意事项:
(1)由于异步API调用耗时极短,所以需要在上层设计合适的API调用频率,否则由于实际的HBase集群处理速度远远无法跟上客户端发送请求的速度,可能导致HBase客户端OOM。
(2)异步客户端的核心耗时逻辑无法直观地体现在Java stacktrace上,所以如果想要通过stacktrace定位一些性能问题或者逻辑Bug,会有些麻烦。这对上层的开发人员有更高的要求,需要对异步客户端的代码有更深入的理解,才能更好地定位问题。
2,AsyncFsWAL
RegionServer在执行写入操作时,需要先顺序写HDFS上的WAL日志,再写入内存中的MemStore(不同HBase版本中,顺序可能不同)。很明显,在写入路径上,内存写速度远大于HDFS上的顺序写。而且,HDFS为了保证数据可靠性,一般需要在本地写一份数据副本,远程写二份数据副本,这便涉及本地磁盘写入和网络写入,导致写WAL这一步成为写入操作最关键的性能瓶颈。
HBase上的每个RegionServer都只维护一个正在写入的WAL日志,因此这个RegionServer上所有的写入请求,都需要经历以下4个阶段:
(1)拿到写WAL的锁,避免在写入WAL的时候其他的操作也在同时写WAL,导致数据写乱。
(2)Append数据到WAL中,相当于写入HDFS Client缓存中,数据并不一定成功写入HDFS中。读者可参考3.2节。
(3)Flush数据到HDFS中,本质上是将第2步中写入的数据Flush到HDFS的3个副本中,即数据持久化到HDFS中。一般默认用HDFS hflush接口,而不是HDFS hsync接口,同样可参考3.2节。
(4)释放写WAL的锁。
从本质上说所有的写入操作在写WAL的时候,是严格按照顺序串行地同步写入HDFS文件系统,这极大地限制了HBase的写入吞吐量。于是,在漫长的HBase版本演进中,社区对WAL写入进行了一系列的改进和优化。
最开始的优化方式是将写WAL这个过程异步化,这其实也是很多数据库在写WAL时采用的思路,典型如MySQL的Group Commit实现。
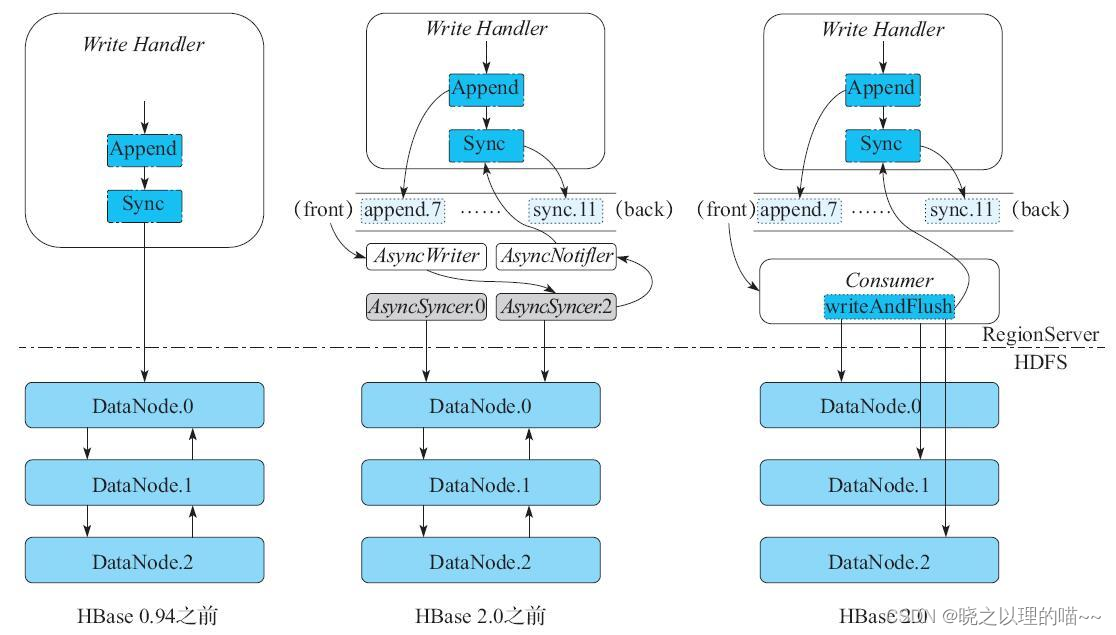
将写WAL的整个过程分成3个子步骤:
(1)Append操作,由一个名为AsyncWriter的独立线程专门负责执行Append操作。
(2)Sync操作,由一个或多个名为AsyncSyncer的线程专门负责执行Sync操作。
(3)通知上层写入的Handler,表示当前操作已经写完。再由一个独立的AsyncNotifier线程专门负责唤醒上层Write Handler。
当Write Handler执行某个Append操作时,将这个Append操作放入RingBuffer队列的尾部,当前的Write Handler开始wait(),等待AsyncWriter线程完成Append操作后将其唤醒。同样,Write Handler调用Sync操作时,也会将这个Sync操作放到上述RingBuffer队列的尾部,当前线程开始wait(),等待AsyncSyncer线程完成Sync操作后将其唤醒。
RingBuffer队列后有一个消费者线程AsyncWriter,AsyncWriter不断地Append数据到WAL上,并将Sync操作分给多个AsyncSyncer线程中的某一个开始处理。AsyncWriter执行完一个Append操作后,就会唤醒之前wait()的Write Handler。AsyncSyncer线程执行完一个Sync操作后,也会唤醒之前wait()的Write Handler。这样,短时间内的多次Append+Sync操作会被缓冲进一个队列,最后一次Sync操作能将之前所有的数据都持久化到HDFS的3副本上。这种设计大大降低了HDFS文件的Flush次数,极大地提升了单个RegionServer的写入吞吐量。HBASE-8755中的测试结果显示,使用这个优化方案之后,工程师们将HBase集群的写入吞吐量提升了3~4倍。
之后,HBase PMC张铎提出:由于HBase写WAL操作的特殊性,可以设计一种特殊优化的OutputStream,进一步提升写WAL日志的性能。这个优化称为AsyncFsWAL,本质上是将HDFS通过Pipeline写三副本的过程异步化,以达到进一步提升性能的目的。核心思路可以参考图15-43的右侧。与HBASE-8755相比,其核心区别在于RingBuffer队列的消费线程的设计。首先将每一个Append操作都缓冲进一个名为toWriteAppends的本地队列,Sync操作则通过Netty框架异步地同时Flush到HDFS三副本上。注意,在之前的设计中,仍然采用HDFS提供的Pipeline方式写入HDFS数据,但是在AsyncFsWAL中,重新实现了一个简化版本的OutputStream,这个OutputStream会同时将数据并发地写入到三副本上。相比之前采用同步的方式进行Pipeline写入,并发写入三副本进一步降低了写入的延迟,同样也使吞吐量得到较大提升。
理论上,可以把任何HDFS的写入都设计成异步的,但目前HDFS社区似乎并没有在这方面投入更多精力。所以HBase目前也只能是实现一个为写WAL操作而专门设计的AsyncFsWAL,一般一个WAL对应HDFS上的一个Block,所以目前AsyncFsWAL暂时并不需要考虑拆分Block等一系列问题,实现所以相对简单一点。
文章来源:《HBase原理与实践》 作者:胡争;范欣欣
文章内容仅供学习交流,如有侵犯,联系删除哦!