本文属于专栏《构建工业级QPS百万级服务》
继续上篇《QPS百万级的有状态服务实践》02 - 冷启动和热更新。我们的架构如图1。上一章在热更新部分,我们引入了消息队列。本章我们介绍下各个消息队列的优缺点,并选择其中一个说下核心概念和原理。
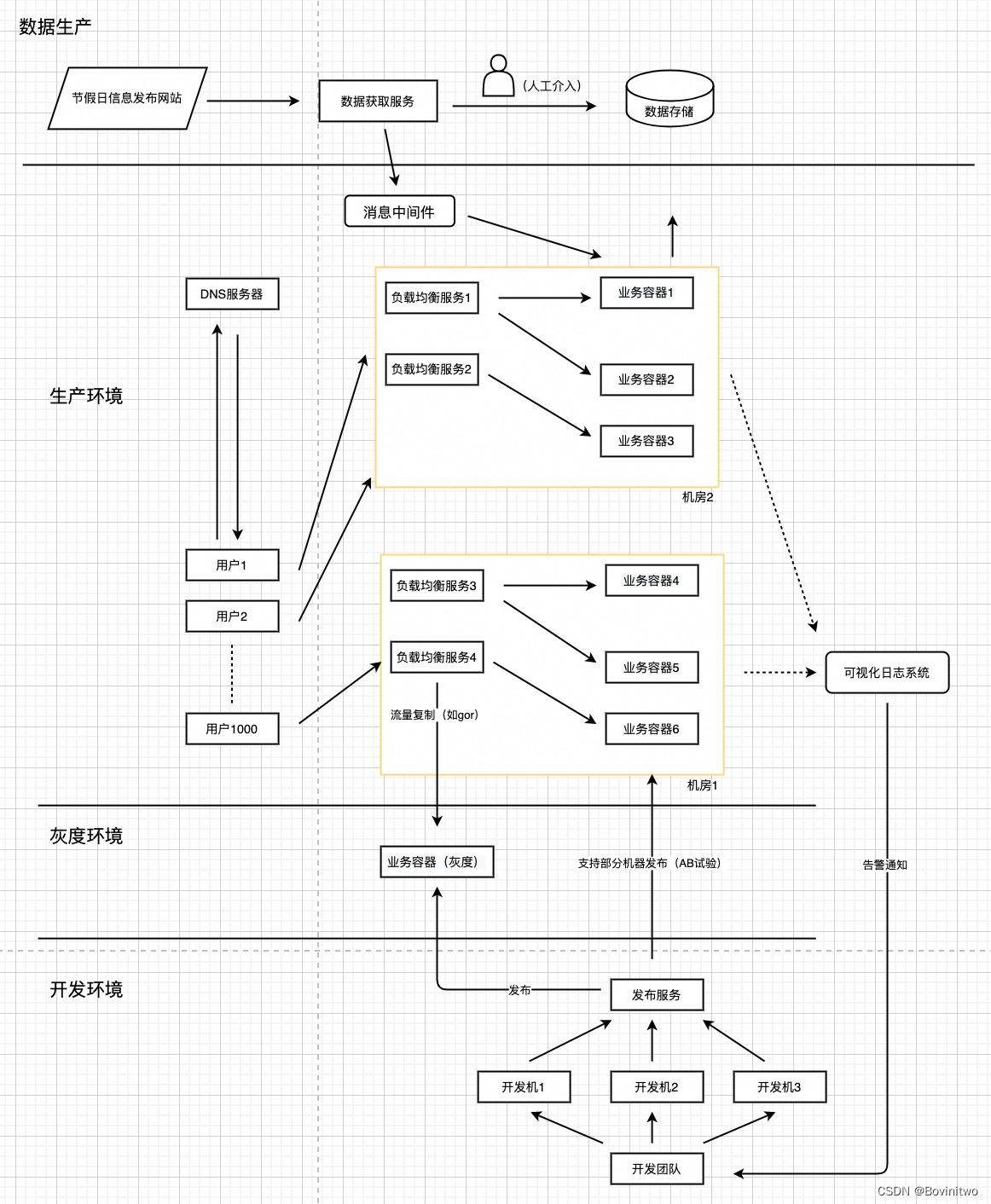
图1
目前市面上的消息中间件优缺点和使用案例如下。
| 消息中间件 | 优点 | 缺点 | 著名使用案例 |
|---|---|---|---|
| Apache Kafka | 高吞吐量、可扩展性好、持久化、故障容错 | 配置复杂、消息重复(至多一次或至少一次的交付保证)、较高的学习曲线 | LinkedIn, Netflix, Uber, Twitter |
| RabbitMQ | 支持多种消息协议、轻量级、易于部署、管理界面友好 | 性能受限于单节点、集群配置和网络分区敏感 | Reddit, Instagram, Robinhood |
| Apache Pulsar | 扩展性强、持久化、原生支持多租户 | 相对较新的系统、社区和生态相对较小 | Yahoo, Tencent |
| Apache ActiveMQ | 成熟稳定、支持多种语言客户端、易于理解和部署 | 在极高吞吐量场景下性能可能受限、内存占用较高 | Canadian Tire, E*TRADE |
| Redis Pub/Sub | 低延迟、简单易用、支持多种数据结构用于消息 | 不持久化(Pub/Sub模式下)、无消费者确认机制导致不可靠消息传输 | Twitch, GitHub, Stack Overflow |
| Amazon SQS | 完全托管、高可靠性、无需服务器维护、集成AWS服务 | 有消息大小限制(256KB)、可能存在延迟问题、费用可能随使用量显著增加 | Airbnb, Samsung, BMW |
| Google Pub/Sub | 完全托管、无服务器、全球分布式、与Google Cloud服务集成 | 与Google Cloud平台耦合、价格可能较高 | Spotify, Wix, Coca-Cola |
| Microsoft Azure Service Bus | 完全托管、与Azure生态系统集成良好、支持多种通信模式如队列、主题和事件网格 | 与Azure平台耦合、可能存在一定的延迟、成本随使用量增长 | BMW, GEICO, Fujifilm |
| NATS | 轻量级、高性能、简单高效的API、支持多种消息模式 | 不支持持久化(NATS Streaming Server除外)、功能简单可能不适合复杂场景 | Baidu, Siemens, HTC |
| ZeroMQ | 高性能、无中心节点、可以用作库集成到应用中、灵活的拓扑结构 | 不是传统意义上的消息队列服务、需要自行处理消息持久化、没有管理界面 | AppNexus, BitTorrent, Wargaming.net |
| Apache RocketMQ | MQ高性能、高吞吐量、支持分布式事务、多种消息模式、丰富的客户端语言支持 | 部署配置相对复杂、社区相比Kafka较小、学习曲线相对陡峭 | 阿里巴巴, DiDi, OPPO |
正如我之前的文章《选择项目工具的方法论》所说,在业务深入,对关键节点,是需要自己制作最时候自己的业务。毕竟工具只有最适合,没有最好。虽然每个中间件都有自己的特点,但是核心原理也有很多共通点,我们以开源RocketMQ为例,介绍一下中间件的核心思想。
中间件架构如图2。Producer集群对应我们的架构就是数据生产服务集群,Consumer集群就是计算节假日数量的服务容器集群,这两个都是业务方自己维护的集群。而RocketMQ的核心功能有客户端和服务端两个部分。客户端部分,一方面集成在Producer集群,业务代码使用RocketMQ提供的三方库函数进行数据发送,另一方面继承在Consumer集群,业务代码使用RocketMQ提供的三方库函数进行数据接受。
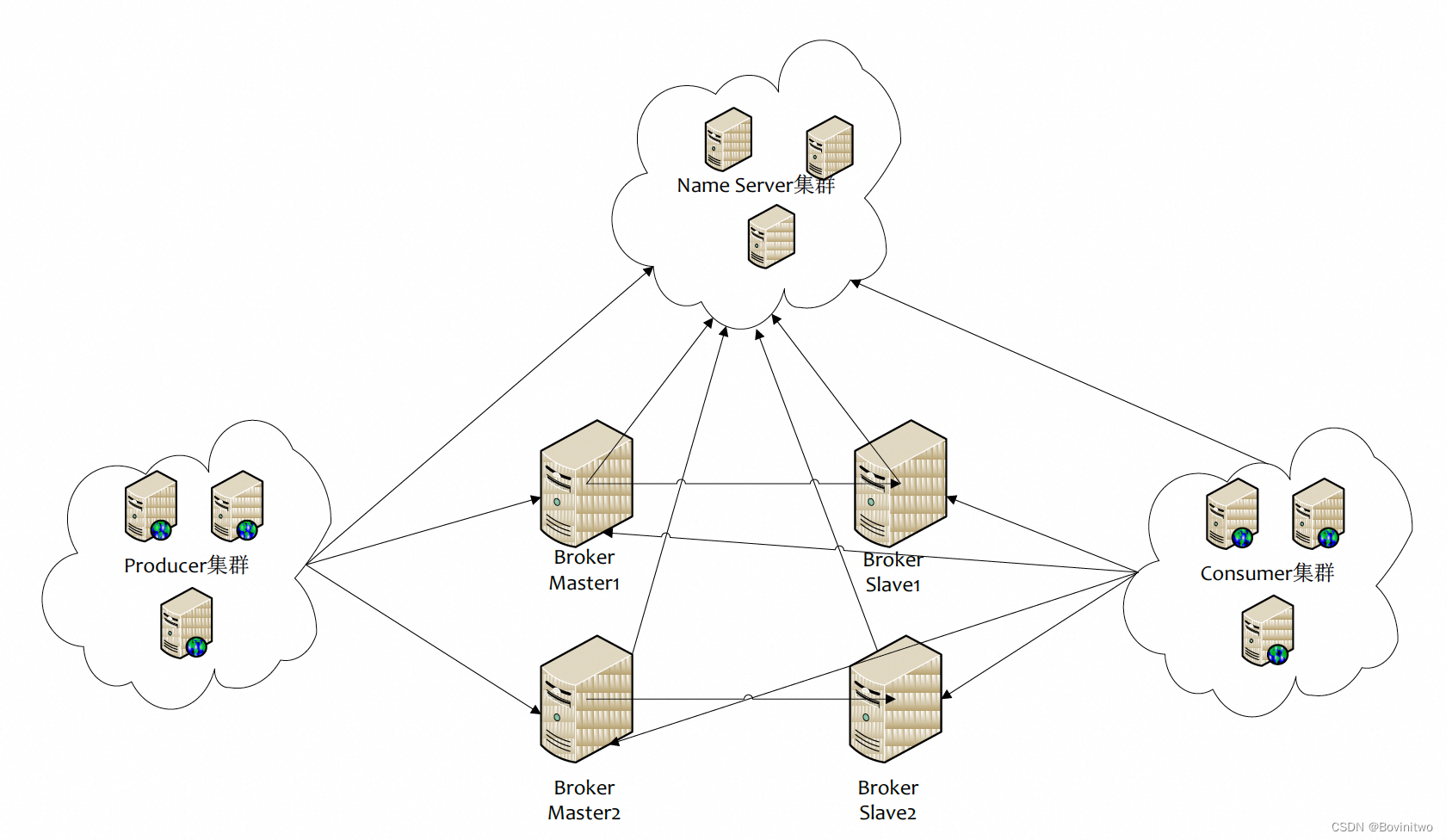
图2
RocketMQ客户端逻发送辑,先通过Name Server获取Broker地址,然后向对应地址发送消息。这里有一些性能优化点值得注意。第一,数据发送是I/O密集型,占用CPU有限,为了提高发送速度,配置多线程发送是很有必要的,最佳线程数量,需要业务测试。第二,对没有顺序性要求的数据,使用异步发送。第三,在单个消息体很小,在可接受延迟范围内,在Producer逻辑中对数据聚合之后再发送,以减少网络调用次数。最后,还有一些数据发送/拉取失败的重试次数、每次数据下拉等众多细节参数,建议在业务遇到相关问题时再看。
RocketMQ客户端接受逻辑,是先通过Name Server获取Broker地址,然后向Broker轮询,主动Pull数据。这里Pull的方式,牺牲了少量的延迟,减少了RocketMQ服务端,也就是Broker集群的复杂度。性能方面,主要是调整Pull的线程数。另外在Pull时有两个模式可以选择。
- 集群消费:一条消息被其中一个机器消费
- 广播消费:一条消息被每个机器都消费一次
消息队列,核心数据流水线是“发+存+收”,Producer负责发,Consumer负责收,那数据在RocketMQ服务端是如何存的呢。 简单的说,如图3,数据生产者把消息发送给Broker,Broker把数据存在Commit Log中,并根据标签,在每个Consume Queue中添加索引。图中有几个概念需要了解:
- topic:消息发布和订阅的类别或者标签,它用来区分不同的消息流。在生产者发送消息时,必须指定一个topic,这个topic描述了消息的类别或者用途。消费者则订阅它感兴趣的topic来接收消息。在RocketMQ中,一个topic可以有多个producer(生产者)发送消息,也可以有多个consumer(消费者)订阅消息
- Queue ID:在RocketMQ中,每个Topic都可以细分成若干个队列,称为Message Queue(消息队列)。Queue ID是消息队列的唯一标识符。在一个broker里,一个Topic可以有多个Queue ID,这是为了实现消息负载均衡和并行处理。Queue ID可以帮助在分布式环境中水平扩展消息处理能力。每个消息队列都有自己的Commit Log和Consume Queue,并且保证队列内的消息是有序的
- message:消息是在生产者和消费者之间传递的数据包。每个消息都有一个具体的内容体(Payload)和一组属性(例如,消息键、标签、延迟级别等)。在RocketMQ中,消息被附加到指定的topic,然后可被发送到对应topic下的一个或多个消息队列。消费者从订阅的消息队列中拉取并处理消息。消息在提交到broker时会追加到Commit Log中,并且通过Consume Queue来索引,以便快速检索和消费
- Message Tag HashCode:
tag是与消息(Message)关联的一个可选字段,它为消息提供了额外的维度来进行分类和过滤。tag可以看作是对同一个topic下消息的进一步细分。你可以将tag理解为对消息主题(topic)的子分类,它使得消费者(Consumer)能够更精细地选择感兴趣的消息进行消费。tag一个重要的作用是在服务端过滤消费者不想要的数据。比如Topic为动物园的动物们,消息内容为每个动物的编号,那tag是每个动物的类型,如鱼类、鸟类。作为管理鱼类的系统,在消费时就可以告诉Broker,只想消费鱼类的数据,这样数据就在服务端过滤了,而不是客户端

图3
除了以上介绍的核心功能,RocketMQ还有一些重置消费Offset位点、消息优先级队列、消息重复、消息顺序等细节功能或问题,但不是本系列的重点,对大部分业务,理解上面的内容已经足够。
截止目前为止,我们的架构通过消息队列,增加了数据更新的推送机制。但是不同机器收到消息的时间是有差别的,那机器更新数据版本的时间就有差别,比如一个机器已经是版本B了,另一个机器还是版本A,那一个请求方的短时间大量请求结果,可能在两个版本反复横跳,用户体验会很不好。那如何解决数据一致性问题,架构还需要做怎样的升级。我会在后续的文章中说下我的经验。
![[ansible] playbook运用](https://img-blog.csdnimg.cn/direct/c7b90c3d4966472dbfc938518e25df44.png)