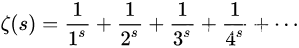【论文阅读】Semi-supervised Sequence Learning半监督学习
前言
半监督学习(Semi-Supervised Learning,SSL) 是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性,因此,半监督学习目前正越来越受到人们的重视。
无监督学习(Un-Supervised Learning,UL ) 现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题。
——来自百度百科
其实总的来说就是:
有监督是所有的训练文本为人工标记的;
半监督是一部分是有标记的,剩下的为无标记的(一般无标记>>有标记);
无监督就是全部都是无标记的。
零、摘要
本篇工作围绕如何使用无标注数据来辅助有标注的更好的训练这一任务,作者用两句话描述了这篇工作提出的两种的使用无标签数据改进循环网络的序列学习的方法,一种是:预测一个序列中接下来的内容,这是自然语言处理中的一种传统语言模型; 另一种是:使用序列自动编码器,它将输入序列读入向量并再次预测输入序列。 作者通过实验发现用这两种方法预训练后的长短期记忆循环网络更稳定,泛化能力更强。通过预训练,能够训练数百个时间步长的长短期记忆循环网络,从而在许多文本分类任务中实现强大的性能。例如IMDB(全球信息量最大最全的电影数据库网站);DBpedia(是一个很特殊的语义网应用范例, 同时也是世界上最大的多领域知识本体之一);以及20个新闻主题分类。
一、简介
RNN虽然是序列数据建模的强大工具,但是通过时间的反向传播来训练模型却是非常困难。由于这个原因,RNN很少用于自然语言处理任务,例如文本分类,尽管它在表示顺序结构方面很强大。
在若干文件分类任务中,人们发现可以用过训练一个长短期记忆网络(LSTM)并仔细的调优超参数是有可能实现良好的性能的。此外,一个简单的预训练步骤可以显著稳定LSTMs的训练效果。例如,可以使用下一步预测模型(NSP,next ste prediction);另一种方法是序列自编码,它使用RNN将长输入序列读入单个向量。这个向量将被用来重建原始序列。通过这两种预训练方法得到的权值可以作为标准LSTM RNN的初始化,从而提高训练效果和泛化能力。
在作者使用20个新闻组和DBpedia进行文档分类的实验,以及使用IMDB和 Rotten Tomatoes进行情感分析的实验中,使用循环语言模型或序列自编码器预训练的LSTM通常优于随机初始化的LSTM。
实验的另一个结果是:在预训练中使用更多相关任务的无标签数据可以提高后续有监督模型的泛化能力。例如,使用Amazon评论中的无标记数据来预训练序列自动编码器,可以将Rotten Tomatoes上的分类准确率从79.7%提高到83.3%,这相当于添加了大量的标签数据。这一证据支持了以下论点:使用更多无标签数据的无监督学习可以改善监督学习。使用序列自编码器和外部无标记数据,LSTMs能够匹配甚至超过先前工作的结果。
作者提出的 semi-supervised approach 与 Skip-Thought vectors相关,但存在两个差异,一个是: Skip-Thought vectors的目标是预测相邻的句子,更难;另一个是: Skip-Thought vectors是纯粹的无监督学习,没有微调。
二、Sequence autoencoders and recurrent language models 序列自编码和循环语言模型
序列自动编码方法是受到Sutskever提出的sequence to sequence方法的启发,seq2seq方法的关键是使用循环网络作为编码器,将输入序列读取到隐藏状态,隐藏状态是预测输出序列的解码器循环网络的输入。
与seq2seq不同的是,Sequence autoencoders 是一个无监督学习方法,目标是重建输入序列本身。encoder输入为这个WXYZ,decoder输出为依然为WXYZ,这里的encoder和decoder隐层是共享的。
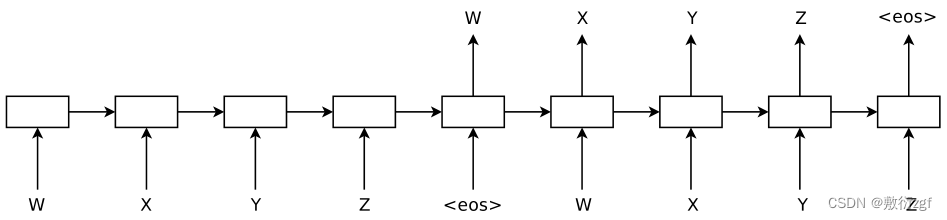
图1:序列“WXYZ”的序列自动编码器。序列自动编码器使用循环网络将输入序列读取到隐藏状态,然后可用于重建原始序列。
作者发现,从序列自编码器获得的权重可以用作另一个试图对序列进行分类的监督网络的初始化。作者假设这是因为网络已经能够记住输入序列。这个原因,以及梯度有shortcuts跨越(想想残差网络)的事实,是作者的假设,为什么序列自编码器是一个良好和稳定的初始化循环网络的方法。
序列自编码器的一个重要特性是它是无监督的,因此可以用大量的无标记数据进行训练,以提高其质量。结果是,增加无标记数据可以提高循环网络的泛化能力。这对于标记数据有限的任务尤其有用。
作者提出第二种方法:循环语言模型可以作为LSTM的预训练方法。这相当于删除图1中序列自动编码器的编码器部分。实验结果表明,该方法比随机初始化的LSTMs算法性能更好。

三、方法概述
在本篇工作的实验中,使用LSTM循环网络,因为它们通常比RNN更好(其实在大多数情况下,人们说RNN通常指的就是LSTM)。标准的LSTM包含输入门、输出门、遗忘门,将基本的LSTM与采用序列自编码初始化的LSTM(SA-LSTMs)进行对比,采用循环语言模型初始化的LSTM(LM-LSTMs)。大多数实验中,输出层从LSTM输出的最后一个时间步预测文档标签。还尝试了在每个时间步上都贴上标签,并将预测目标的权重从0线性增加到1的方法。这样就可以在循环网络的早期步骤中注入梯度。我们称这种方法为线性标签增益。
最后,作者对监督学习任务与序列自编码器联合训练的方法进行了实验,称之为联合训练。
四、实验
IMDB and Rotten Tomatoes任务是情感分析和20 Newsgroups and DBpedia任务是文本分类。
在序列自动编码器的实验中,训练它在读取所有输入单词后重新生成完整的文档。换句话说,不执行任何截断或窗口操作。在每个输入序列的末尾添加一个句末标记< eos >,然后训练网络在该标记之后开始复制序列。为了加快性能并减少GPU内存的使用,从序列的末尾开始执行截断的反向传播,最多可达400个时间步。对文本进行预处理,以便将标点符号视为单独的标记,并忽略DBpedia文本中的任何非英语字符和单词。还删除在每个数据集中只出现一次且不执行任何术语加权或词干的单词。
在训练循环语言模型或序列自动编码器大约500K步(批处理大小为128)之后,使用单词嵌入参数和LSTM权重来初始化监督任务的LSTM。然后,对该任务进行训练,同时微调嵌入参数和权重,并在验证错误开始增加时使用提前停止。根据验证集选择dropout参数。
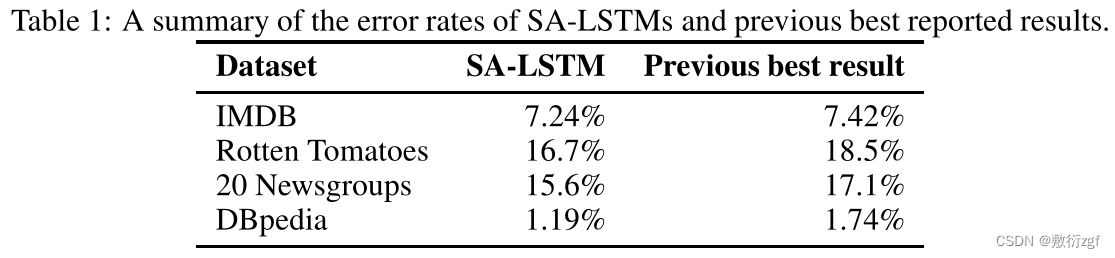
使用SA-LSTM,能够匹配或超过所有数据集的报告结果。必须强调的是,以前的最佳结果来自各种不同的方法。因此,一种方法对所有数据集都能获得强大的结果是很重要的,大概是因为这种方法可以用作任何类似任务的通用模型。实验结果汇总如表所示
4.1Sentiment analysis experiments with IMDB
第一组实验:在Maas等人提出的IMDB电影情感数据集上对作者的方法进行基准测试。通过调优,可以训练LSTM循环网络来适应长文档训练集。
lstm对长文档的超参数非常敏感,训练会很容易崩溃。相比之下,SA-LSTM算法工作得更好,也更稳定。如果使用序列自编码器,改变隐藏状态的大小或backprop 步骤的数量几乎不会影响LSTM的训练,模型训练起来更加实用。
利用序列自编码器克服了LSTMs的优化不稳定性,从而在训练集上快速、容易地实现完美分类。为了避免过拟合,再次使用输入维度dropout,并在验证集上选择退出率。
结果表明,带输入嵌入dropout的SA-LSTM算法在该数据集上可以取得与以往最好的结果相同的结果。相比之下,没有序列自编码器的LSTMs在优化目标时遇到麻烦,因为文档中存在很长的依赖关系。
使用语言建模(LM-LSTM)作为初始化的效果很好,达到了8.98%,但与SA-LSTM相比效果较差。这可能是因为语言建模是一个短期目标,所以隐藏状态只捕获预测接下来几个单词的能力。
在上表中,使用1024个单元作为存储单元,在LM-LSTM和SA-LSTM中使用512个单元作为输入嵌入层。还使用了512个隐藏层单元,在最后一个隐藏状态和分类器之间的dropout为50%。在接下来的实验中继续使用这些设置,除了最终隐藏层中有30个单元。在表中,给出了一些来自IMDB数据集的例子,这些例子是通过SALSTM而不是bigram NBSVM模型正确分类的。这些例子通常有长期的依赖关系,或者有很难仅从短语中找到的。
4.2 Sentiment analysis experiments with Rotten T omatoes and the positive effects of additional unlabeled data


4.3 Text classification experiments with 20 newsgroups
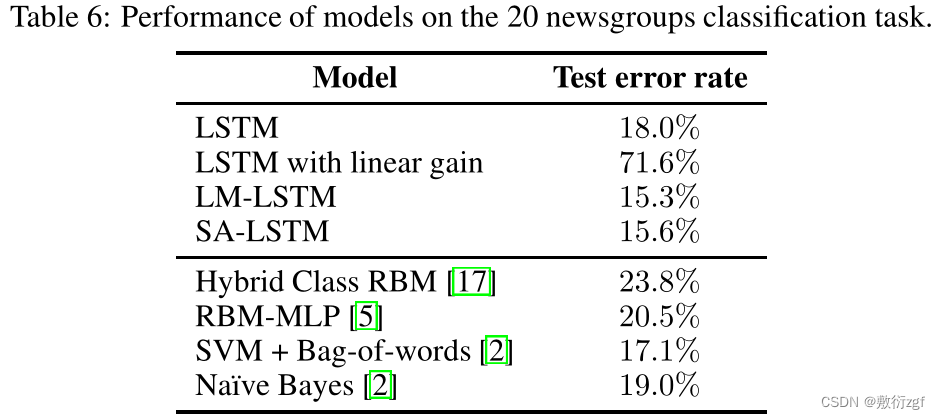
到目前为止,实验都是在文档中标记数量相对较少的数据集上进行的,只有几百个字。我们的问题变成是否可以将salstm用于具有大量单词的任务。为此,我们在20个新闻组数据集[16].4上进行了接下来的实验训练集有11,293个文档,测试集有7,528个文档。我们使用15%的培训文档作为验证集。每个文档都是一封邮件,平均长度为267字,最大长度为11925字。附件、PGP键、副本和空消息被删除。由于新闻组文档很长,以前认为循环网络不可能从数据集中学到任何东西。
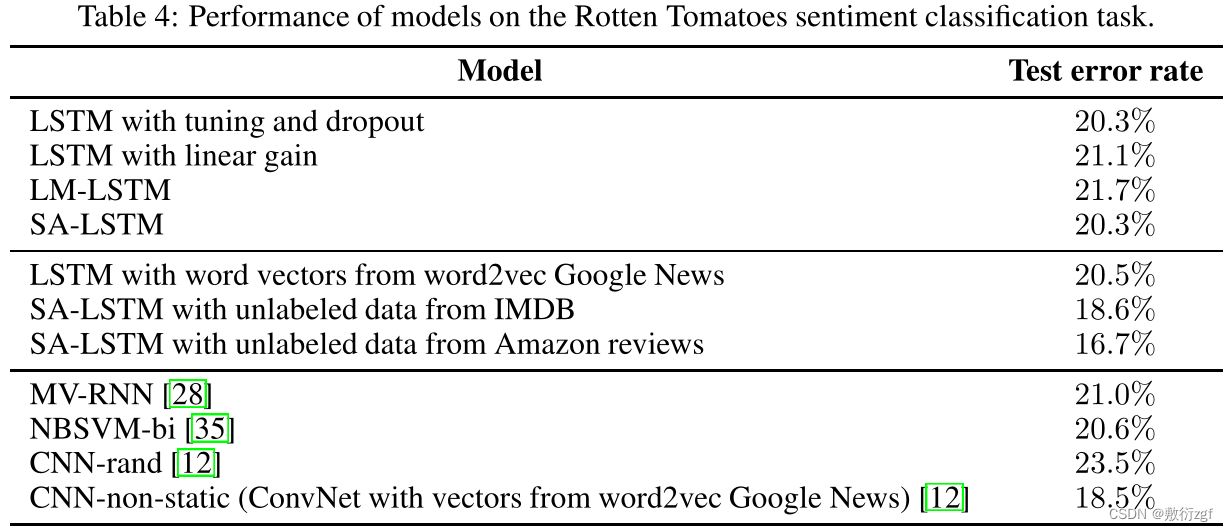
在这个数据集上对LSTMs和SA-LSTMs重复同样的实验。与之前实验的观察结果相似,SA-LSTMs通常比LSTMs训练更稳定。为了提高模型的泛化性,我们再次使用在验证集中选择的输入嵌入dropout和单词dropout。在70%的输入嵌入缺失和75%的单词缺失的情况下,SA-LSTM获得了15.6%的测试集误差,大大优于以往的分类器。结果如表6所示。
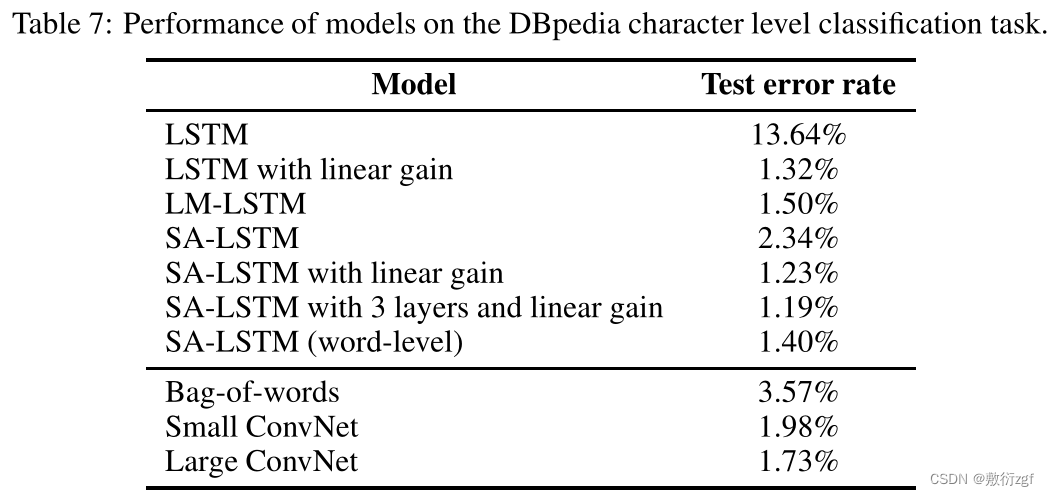
4.4 Character-level document classification experiments with DBpedia
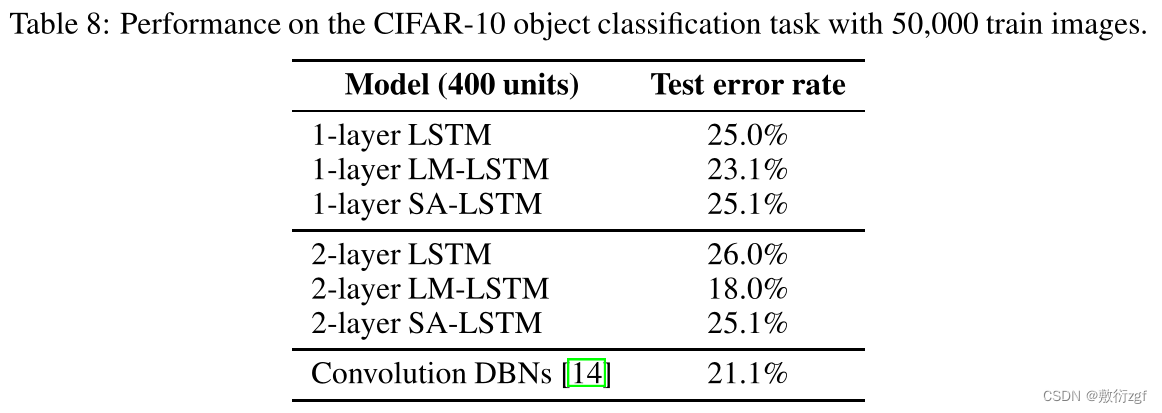
4.5 Object classification experiments with CIFAR-10
五、结论
在本文中,作者证明了使用LSTM循环网络来完成诸如文档分类等NLP任务是可能的。进一步,证明了语言模型或序列自编码器可以帮助稳定LSTM循环网络的学习。在作者尝试的五个基准上,LSTM可以达到或超过所有以前基准的性能水平。






![[CISCN2019 华北赛区 Day1 Web2]ikun](https://img-blog.csdnimg.cn/fbdd8952efec48fab93a5af5f40c911b.png)