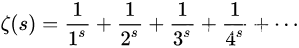一、YOLOV2改进的概述
做的改进如下图:

- Batch Normalization 批量归一化层
不加BN层,网络可能学偏,加上归一化进行限制。
从今天来看,conv后加BN是标配。

- 更大的分辨率
V1训练的时候使用224×224,测试用448×448。
V2训练的时候可以进行10个epoch448×448的微调。训练测试用一样大小的数据集。

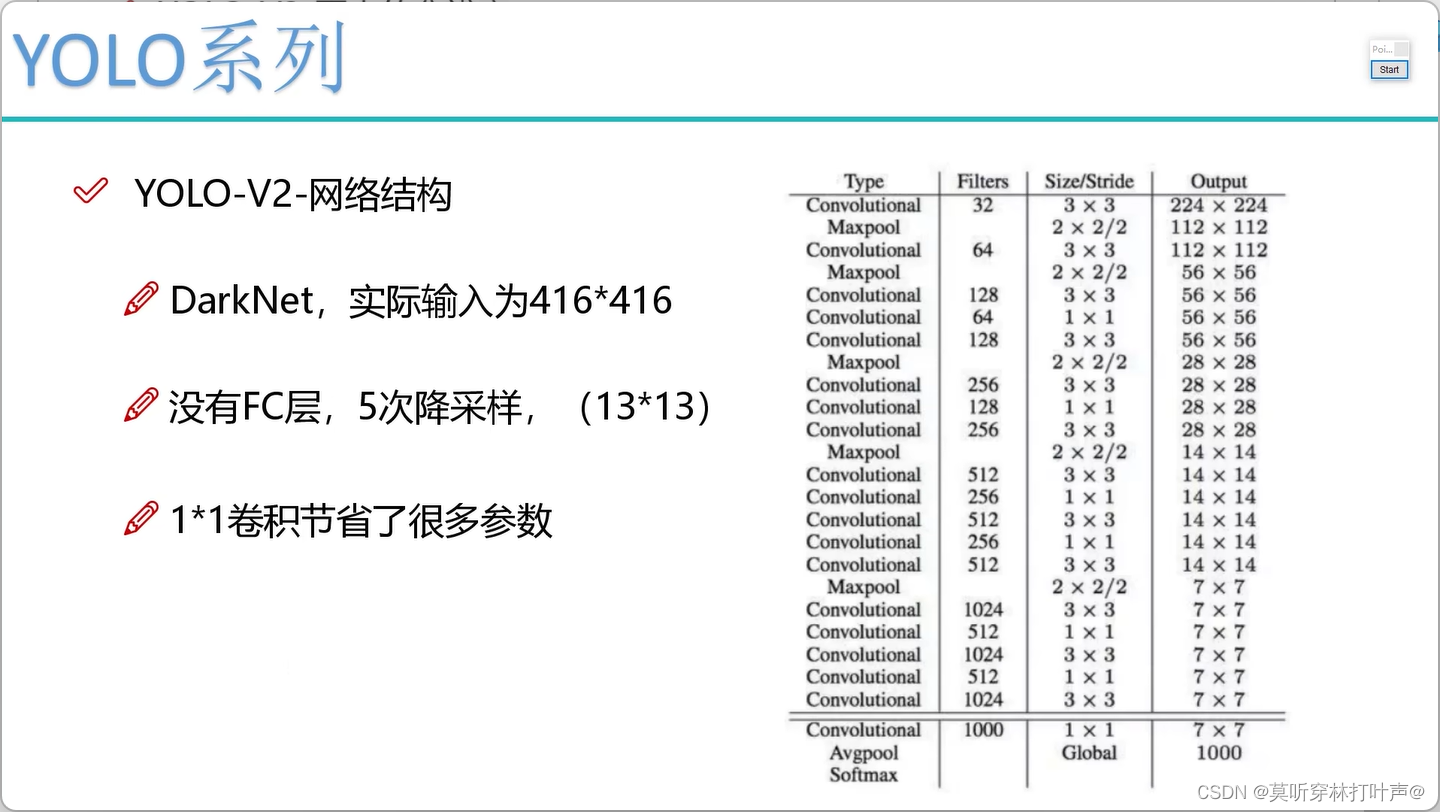
- 网络架构的改变
使用DarkNet19,借鉴了Alex和VGG的思想。所有的层都采用的卷积层,没有采用全连接层,全连接层容易过拟合,训练的也慢。
经过5次降采样,h/32,w/32,结果为13。V1版本的7×7太小。
实际输入416×416,希望416/32=奇数,中心点好选。
卷积核的卷积核为3×3,1×1,借鉴了VGG,19个卷积层。1×1是为了省参数。
DarkNet深度自己选择
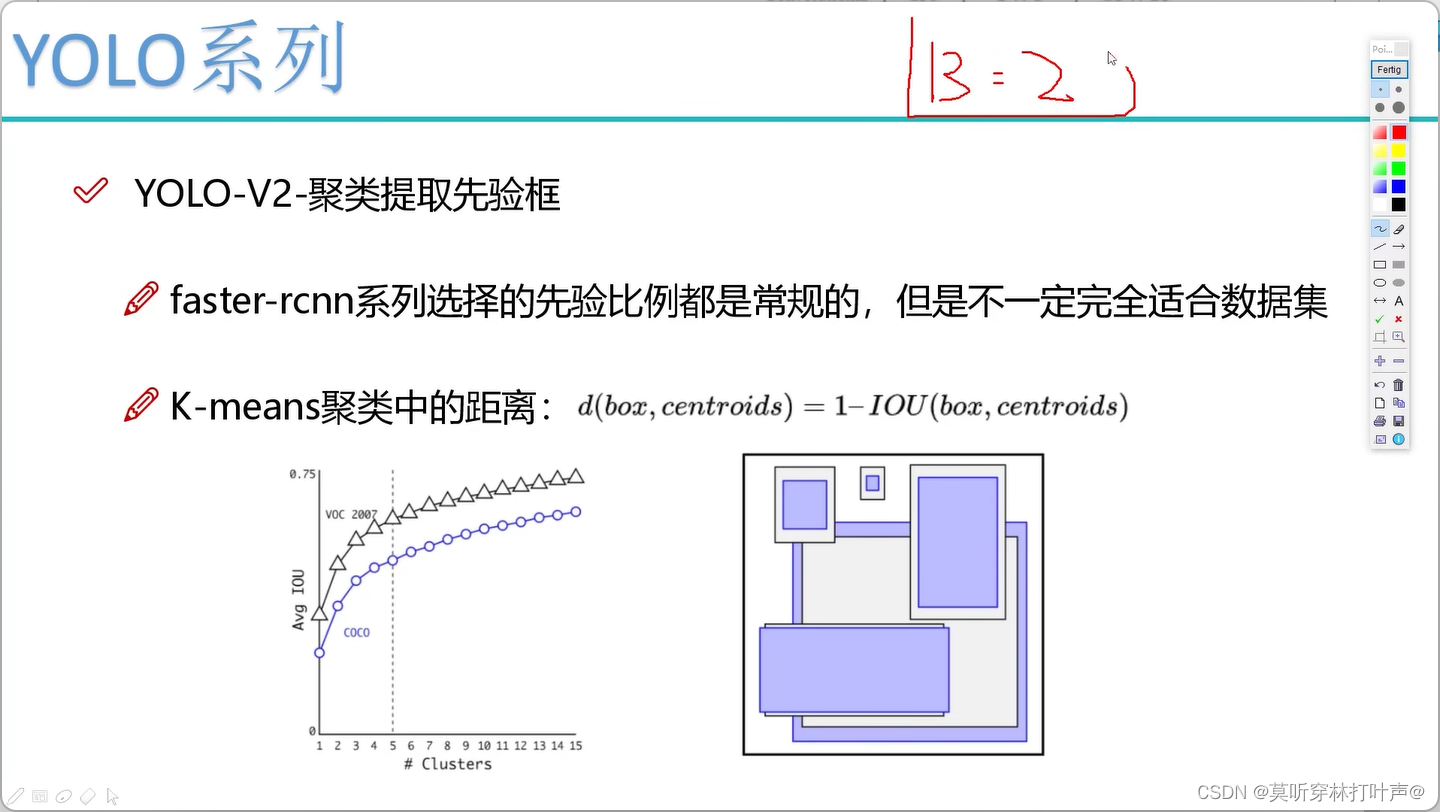
- 聚类提取先验框
比如数据集里100w个标注好的框,为了使得先验框更加符合实际要求,使用K-means,K=5,聚成5类(都是实际的值),5类中都有一个中心点(h,w),将这些(h,w)做成先验框。
正常的距离:欧氏距离。
在YOLO中的距离:用1-IOU
K越大,越精确,K=5的时候,平均IOU还可以,再往上走的时候,走势不明显。
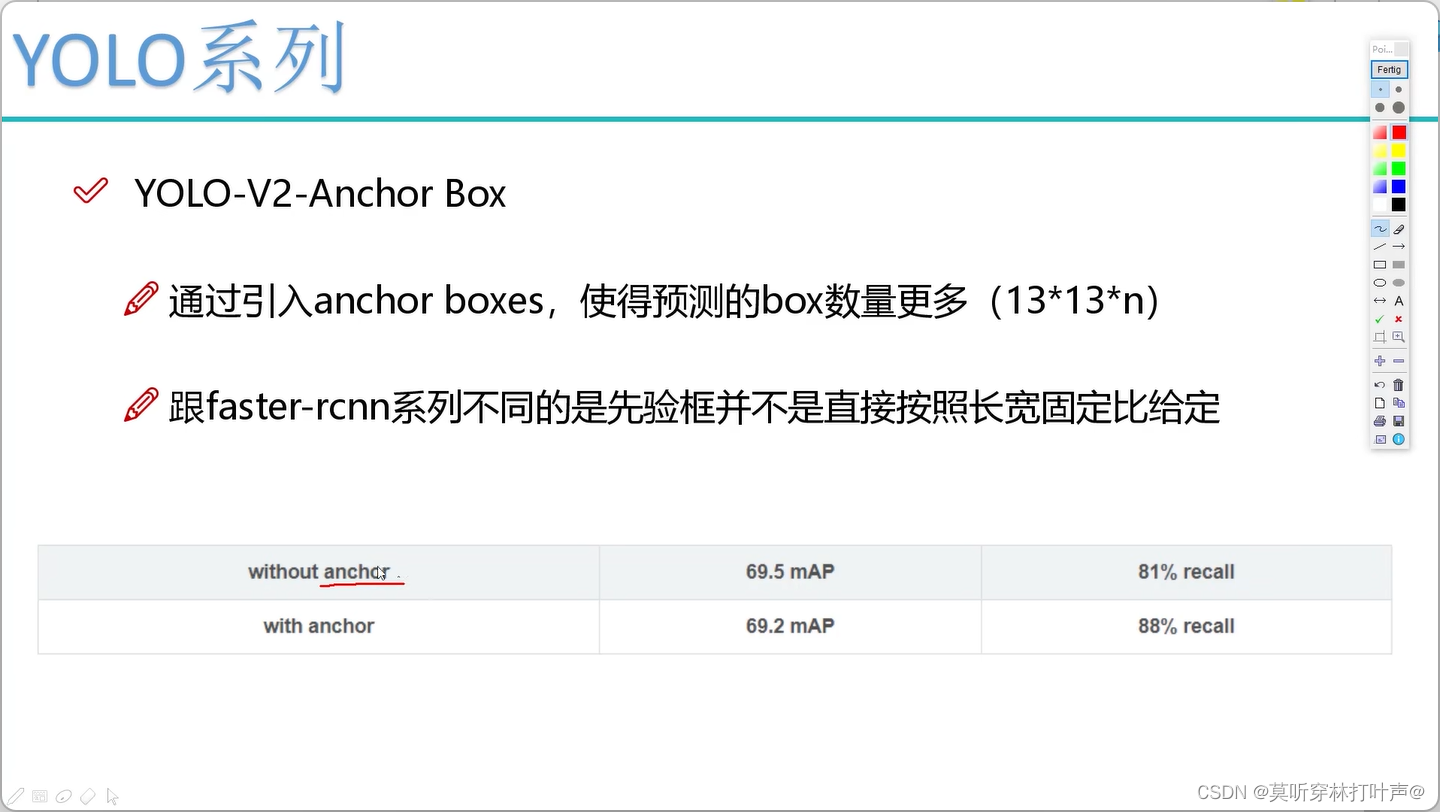
- Anchor Box先验框
MAP值没有提升:框多了,不一定每个框都能做对。
recall提升了:框多了,之前不能框出来了可以框出来了。
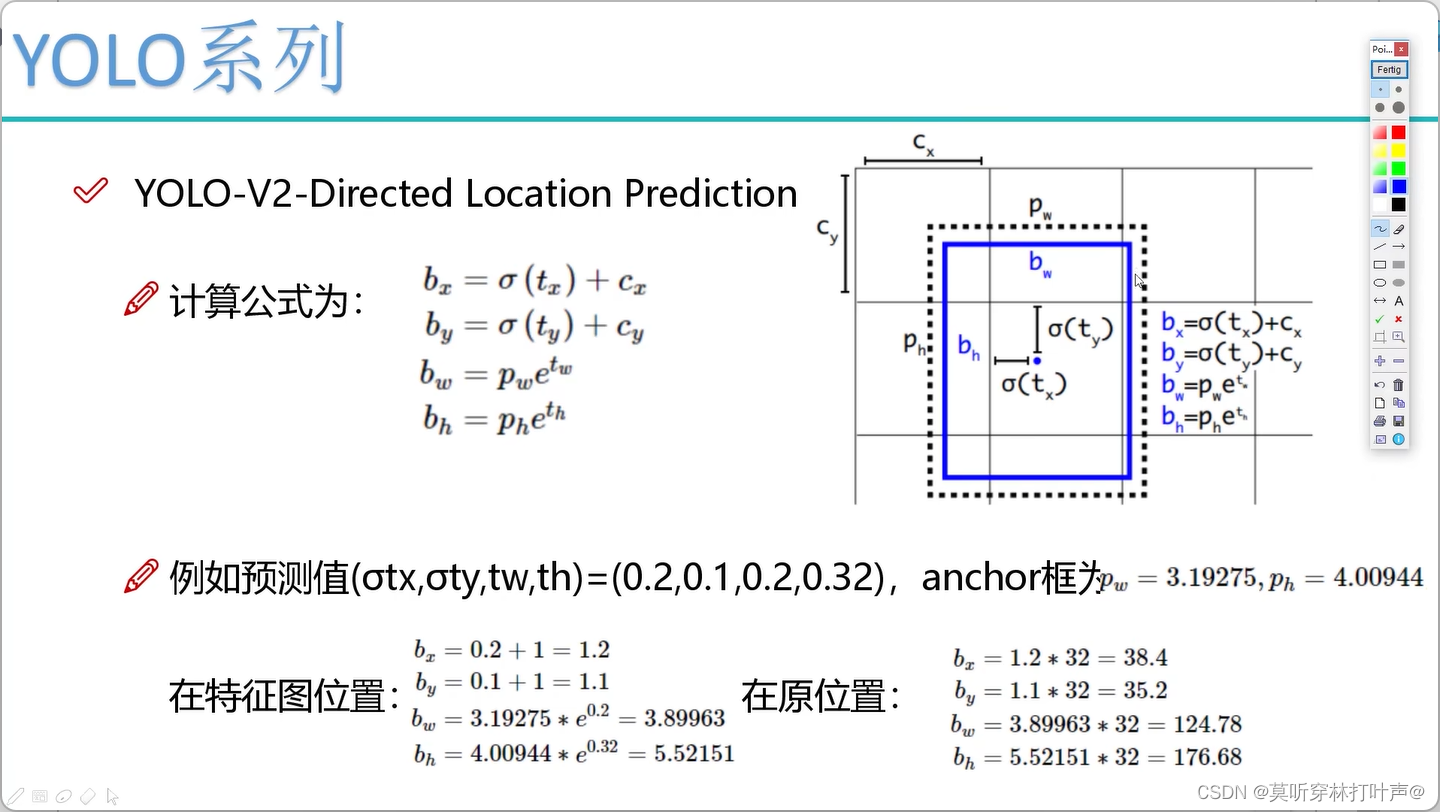
- Directed Location Prediction
直接预测相对位置,相对网格的偏移量。

预测的偏移量:tx,ty,tw,th,实际的预测值bx,by,bw,bh看下面的计算结果
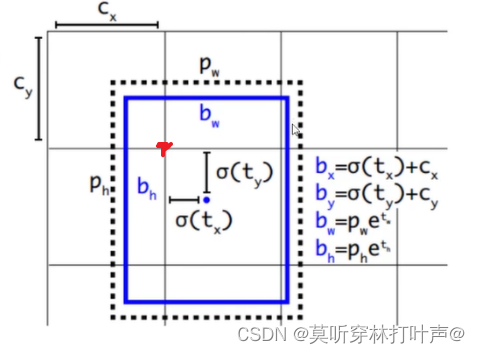
黑色:先验框
蓝色:预测的框
蓝色的点是预测的框的中心点,学的是蓝色点相对于当前网格左上角点的相对位置(图中所标的红色的点),是0-1之间的。所以无论怎么偏移,都不会飘出这个网格了。
这里的cx,cy都是1,换一个网格就不是了。
δ是sigmoid。
- 计算方式
tw和th预测的是对数,所以转换回来。
pw和ph是等比例缩小后在特征图中的大小。(V2里面就是输入尺寸/32,因为做了5次降采样)。pw和ph是聚类得到的先验框,是已知条件。
计算出来后要进行还原,×32
- 感受野
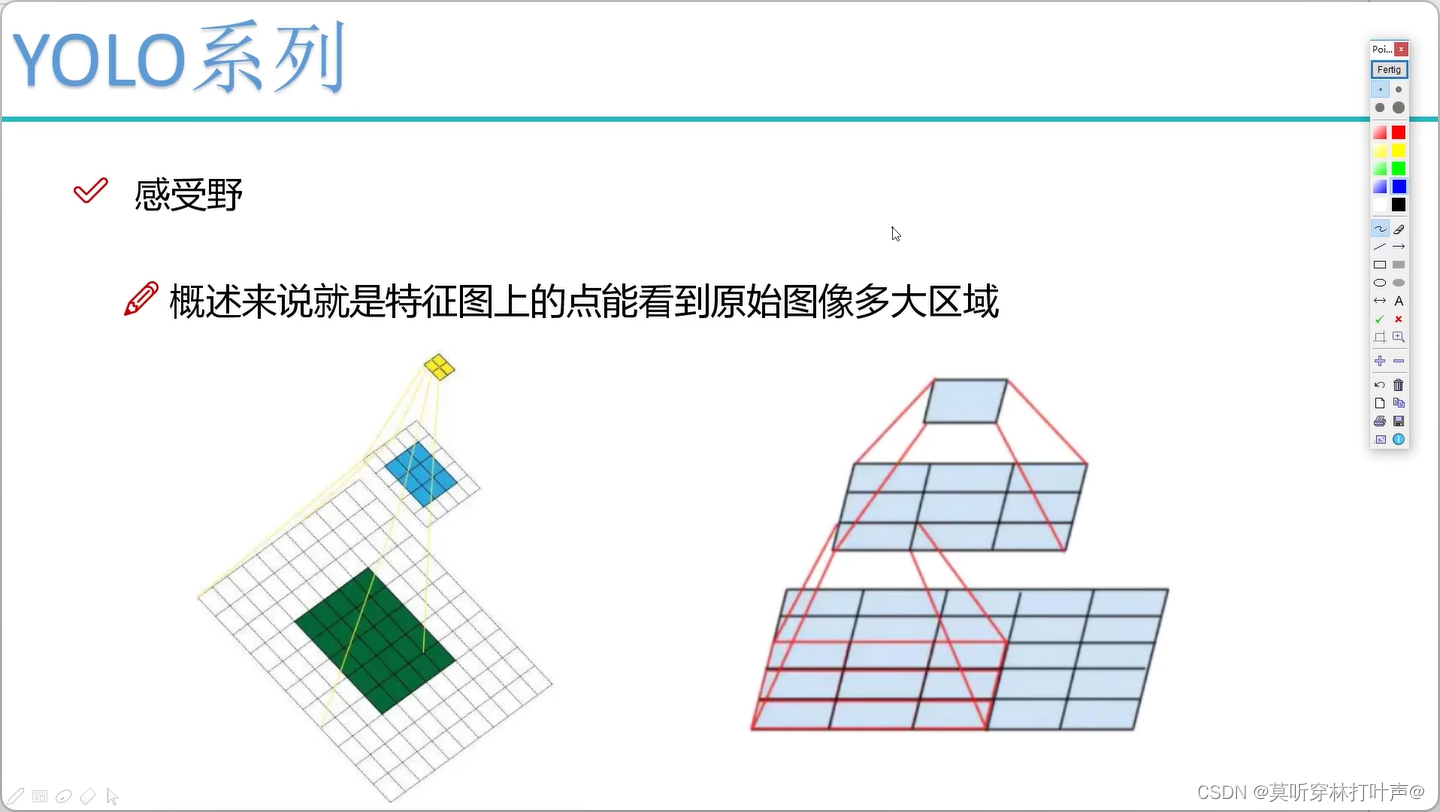
参数少。
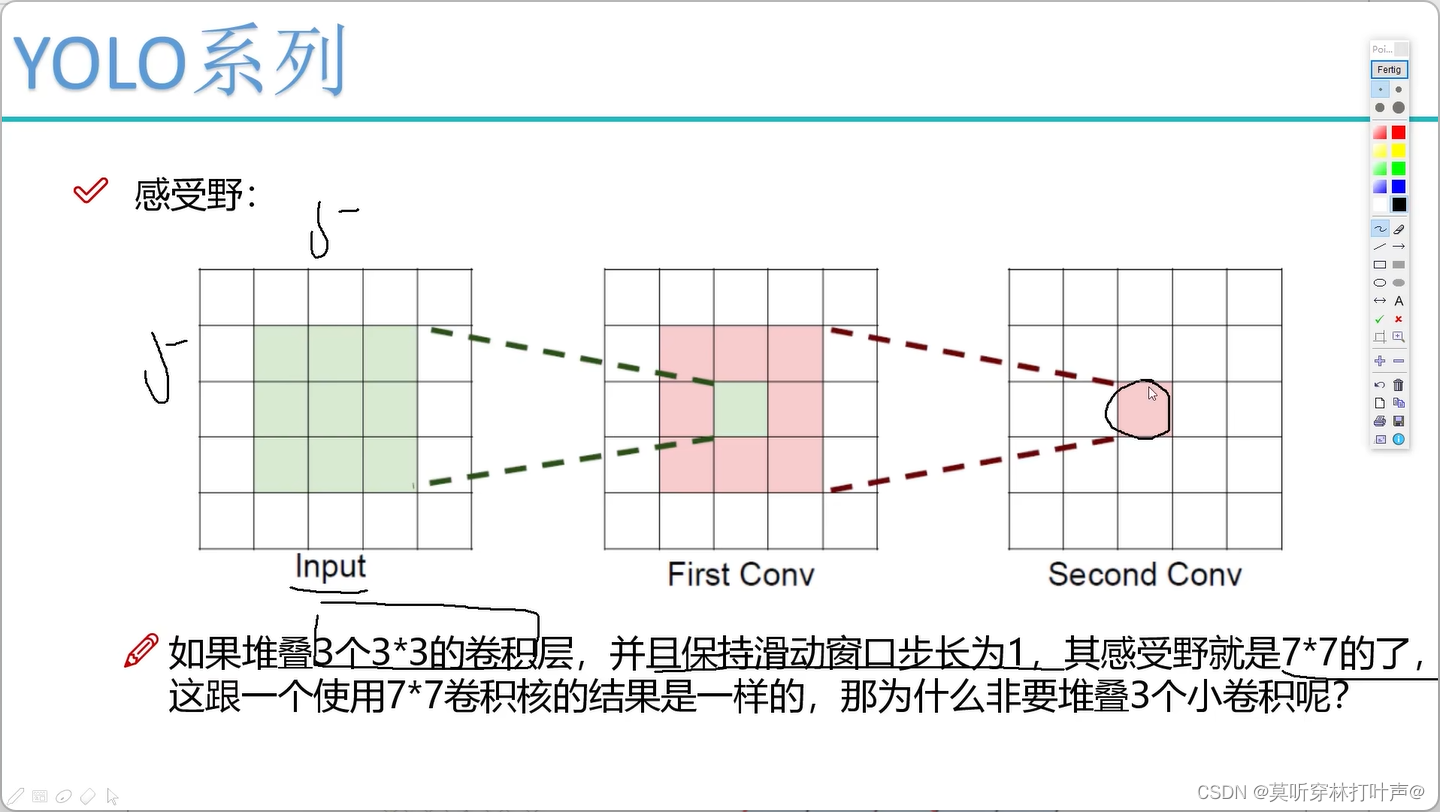
channel数=卷积核数=得到的特征图数

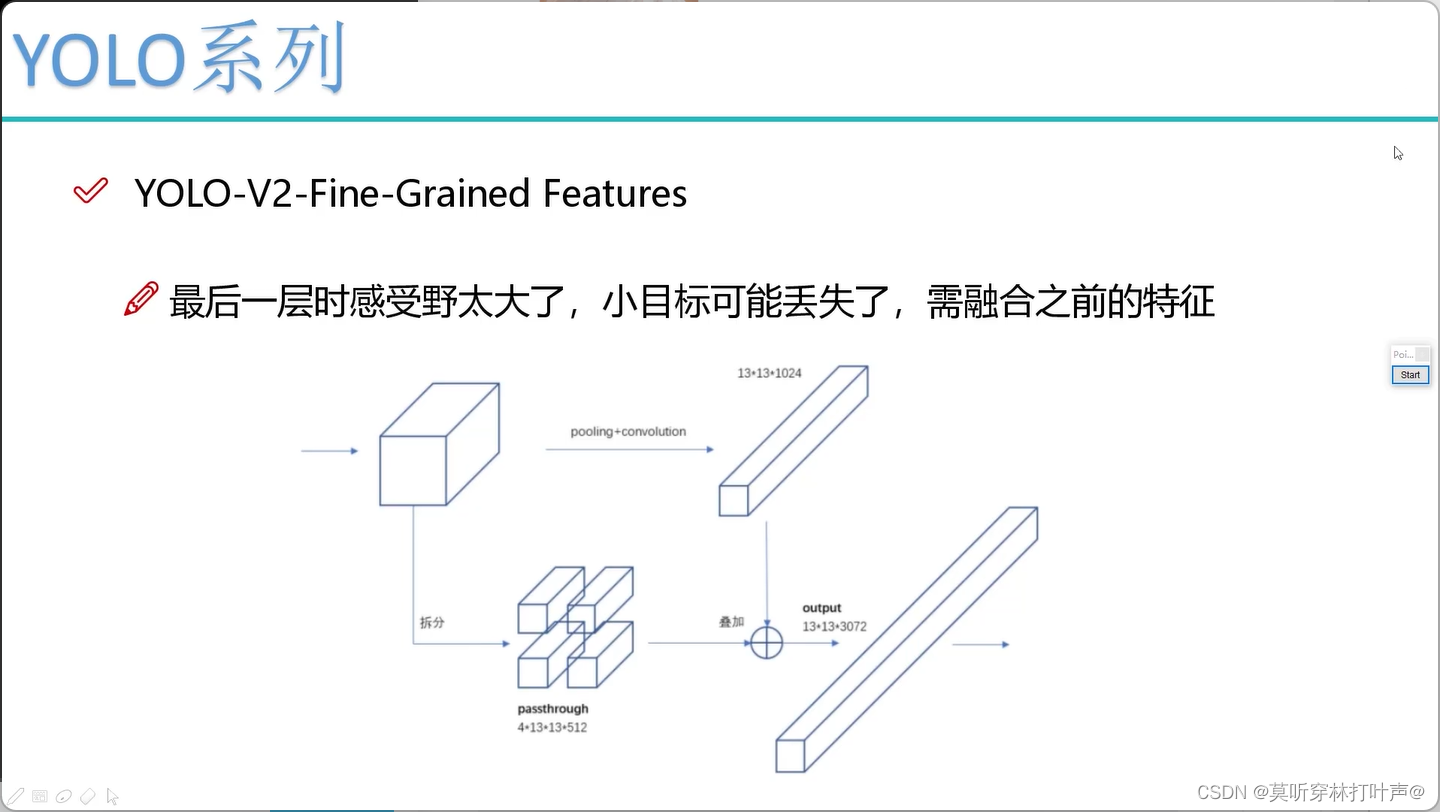
最后的感受野太大了,适合捕捉比较大的目标,所以会导致小物体的丢失。
前面层的感受野较小,可以把前面的特征图进行融合。
把前面胖点的特征图拆成4个瘦的特征图,再拼在一起。
胖的:26×26×512拆成4×13×13×512
瘦的:13×13×1024
最后拼成4×512+1024
- Multi-Scale多尺度
网络都是卷积,不用固定图片尺寸大小。