Java 之 ElasticSearch8.x.x 【一篇文章精通系列】【上:ES的基本操作,ES安装,ES head + Kibana】
- 一、ElasticSearch的安装
- 1、解压安装ES
- 2、熟悉目录
- 3、启动ES
- 4、安装可视化界面(elasticsearch head)
- 5、了解ELK
- 6、安装Kibana
- (1)下载解压Kibana
- (2)启动Kibana
- (3)访问:[http://localhost:5601](http://localhost:5601)
- (4)Kibana开发工具
- (5)汉化`Kibana`,设置在`config`下的`kibana.yml`
- 二、ElasticSearch的核心概念
- 1、基本概念
- 2、物理设计:节点和分片
- 三、IK分词器
- 1、什么是IK分词器
- 2、安装,启动IK分词器
- 3、elasticsearch-plugin
- 4、使用Kibana进行测试!,通过ik分词器进行基本的分词测试
- (1)使用ik_smart分词器(最少切分)
- (2)使用ik_max_word(最细粒度划分)
- (3)问题???
- 5、ik分词器增加自己的配置!(自定义分词字典)
- 四、ElasticSearch 索引的基本操作
- 1、Rest风格说明
- 2、创建索引
- (1)删除一些索引
- (2)创建索引(添加数据的同时创建索引库)
- (3)查看索引
- (4)字段类型
- (5)指定字段类型(创建规则,只创建索引不添加数据)
- 3、获取索引信息、其他信息
- (1)查看默认信息
- (2)获取一些信息(cat系列命令)
- 4、修改索引
- (1)直接PUT覆盖(不推荐)(如果PUT的时候少字段会丢失数据)
- (2)通过POST命令更新数据
- 3、删除索引
- 4、删除文档
- 四、ElasticSearch 文档的基本操作
- 1、添加数据
- 2、查询数据 GET
- (1)获取索引信息
- (2)查询所有文档数据
- (3)查询一条数据
- 3、更新数据
- 4、简单搜索
- (1)通过id查询
- (2)简单的条件查询
- 5、复杂搜索
- (1)直接匹配查询,match:匹配
- (2)_source过滤查询返回字段
- (3)排序查询(sort)
- (4)分页查询(from,size)
- (5)布尔值查询(bool)
- (6)布尔值查询(bool)--filter复杂查询操作
- (7)匹配多个搜索条件
- (8)单个值匹配精确查询(term)
- (9)多个值匹配精确查询(term)
- (10)高亮显示(highlight)
- 四、ElasticSearch NLP
- 1、什么是自然语言处理?
- 2、ElasticSearch 当中的自然语言处理
- 3、NLP在 Elasticsearch 7.x和8.x 中的区别
- 4、安装opennlp
- 5、下载NER模型
一、ElasticSearch的安装
1、解压安装ES
声明:JDK1.8,最低要求! ElasticSearch客户端,界面工具! |
Java开发,ElasticSearch 的版本和我们之后对应的Java的核心jar包!版本对应!
官网:https://www.elastic.co/cn/elasticsearch/
下载安装解压即可


2、熟悉目录
bin:启动文件
config:配置文件
log4j2:日志配置文件
jvm.options:Java虚拟机相关配置
elasticsearch.yml : elasticsearch的配置文件
lib: 相关jar包
logs:日志
models:功能模块
plugins:插件!ik分词器
3、启动ES
双击bin目录下的
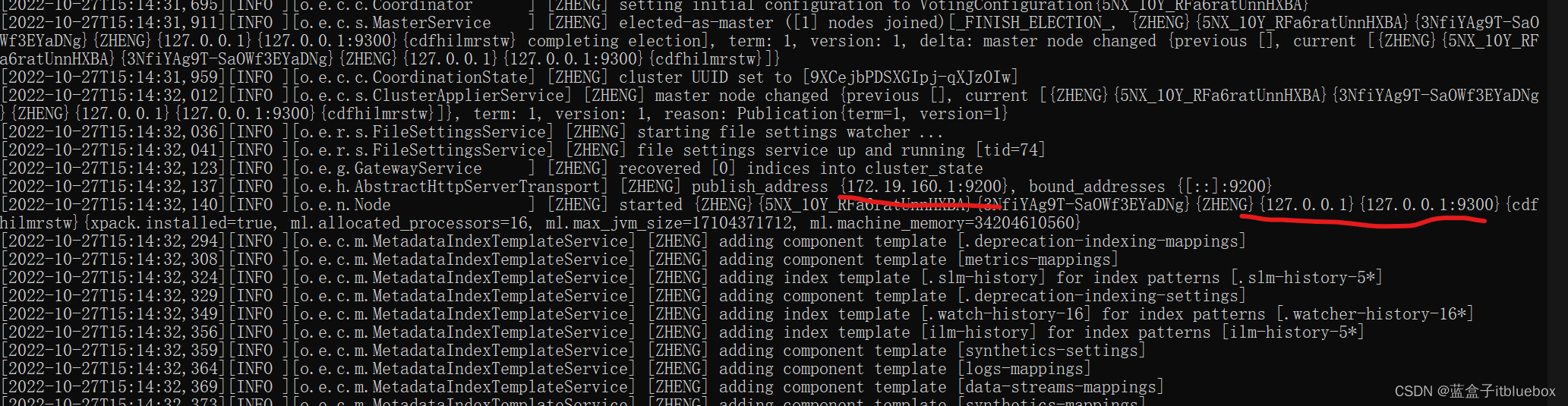
启动成功,公开地址9200,通信地址:9300
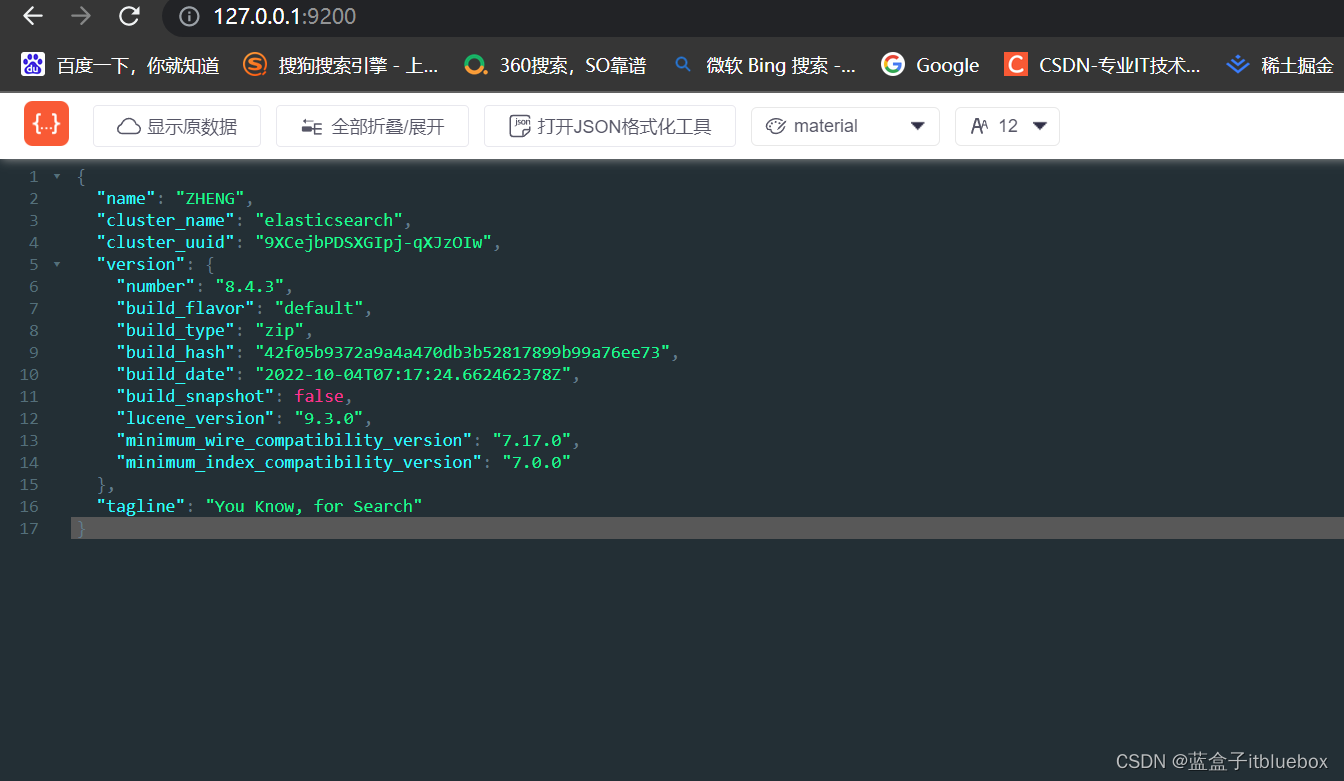
访问:http://127.0.0.1:9200/ 发现无法访问
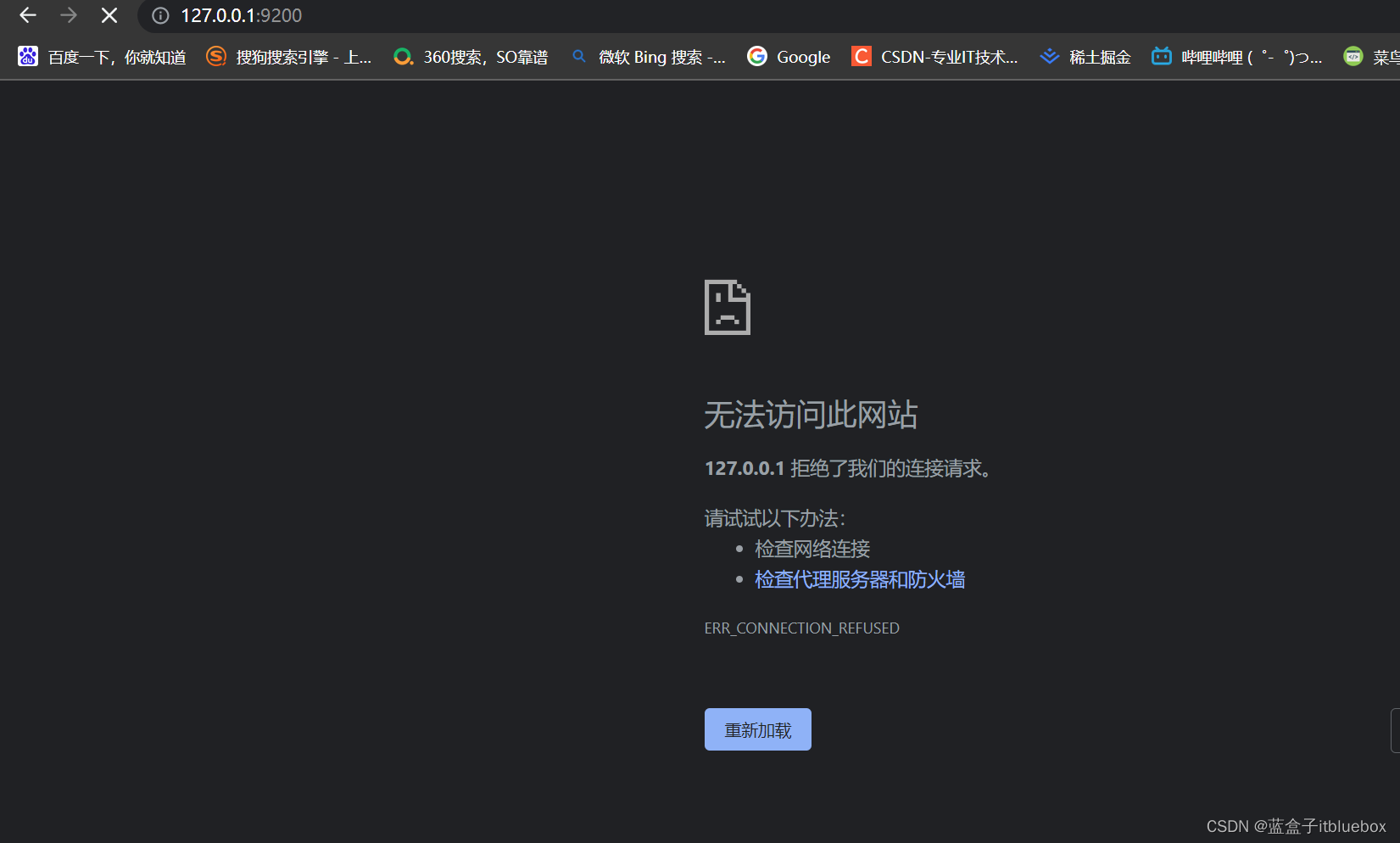
新版的ES默认开启了 ssl 认证。
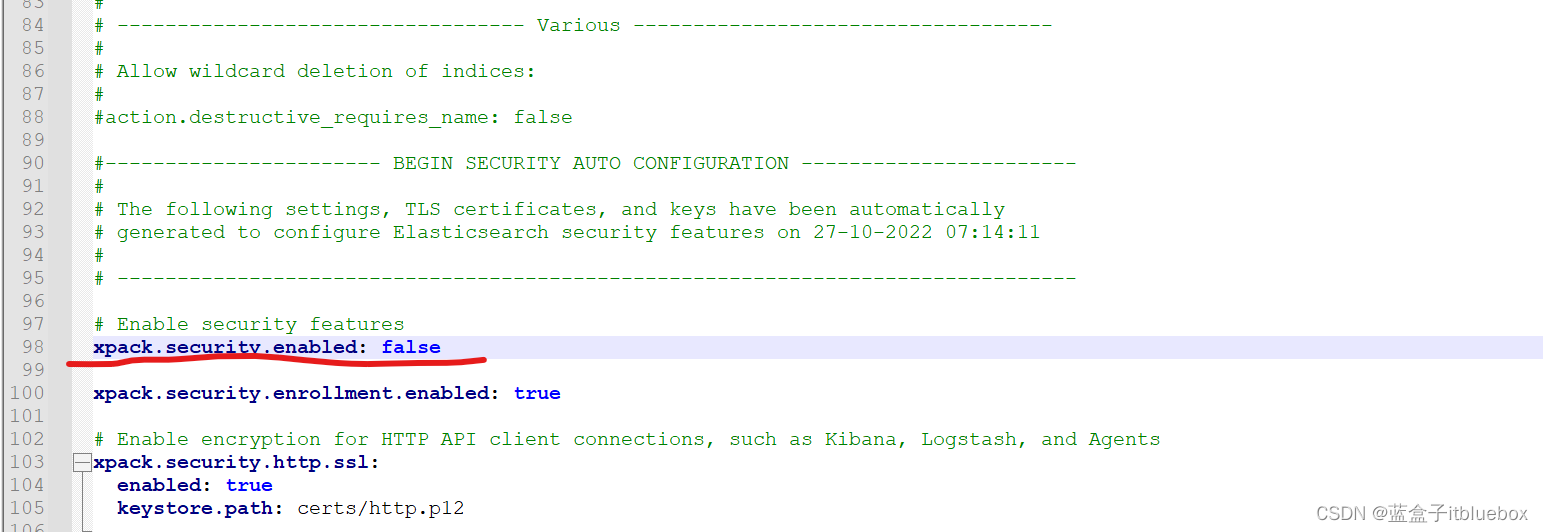
在 ES/config/elasticsearch.yml 文件中把 xpack.security.http.ssl:enabled 设置成 false 即可
停止运行ES
修改config/elasticsearch.yml
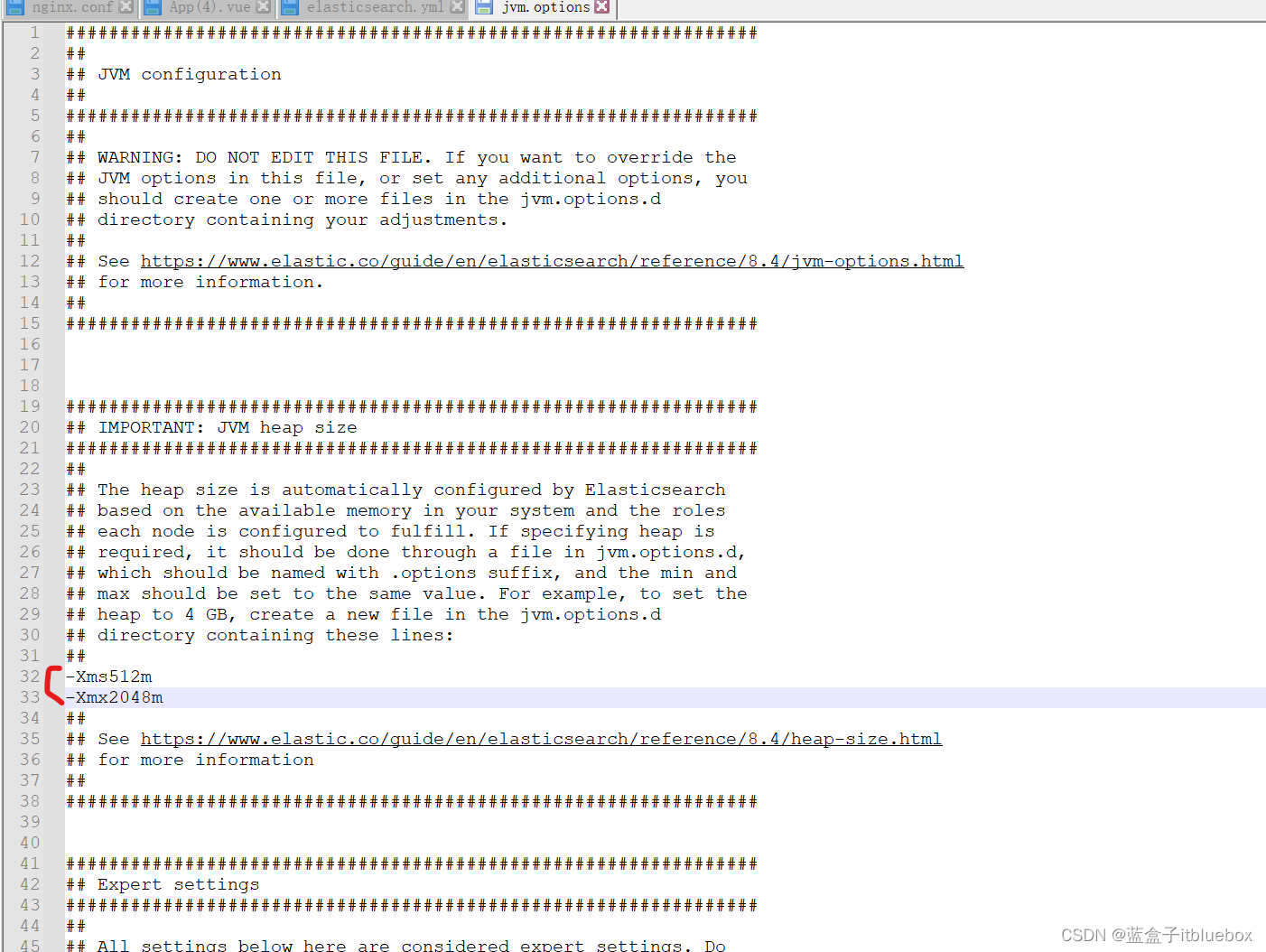
顺便修改一下JVM的配置信息,修改config/jvm.options
-Xms512m
-Xmx2048m
重新启动ES
访问成功:http://127.0.0.1:9200/
4、安装可视化界面(elasticsearch head)
(1)安装elasticsearch head
地址:https://github.com/mobz/elasticsearch-head

解压启动,在github上有启动方式
在启动之前确保安装了nodejs 环境,如果没有安装请看这里:
进入解压后的目录

在上面搜索框当中输入cmd
弹出cmd命令框
安装依赖
输入该命令:npm install
出现上面的内容则安装成功
启动项目:npm run start
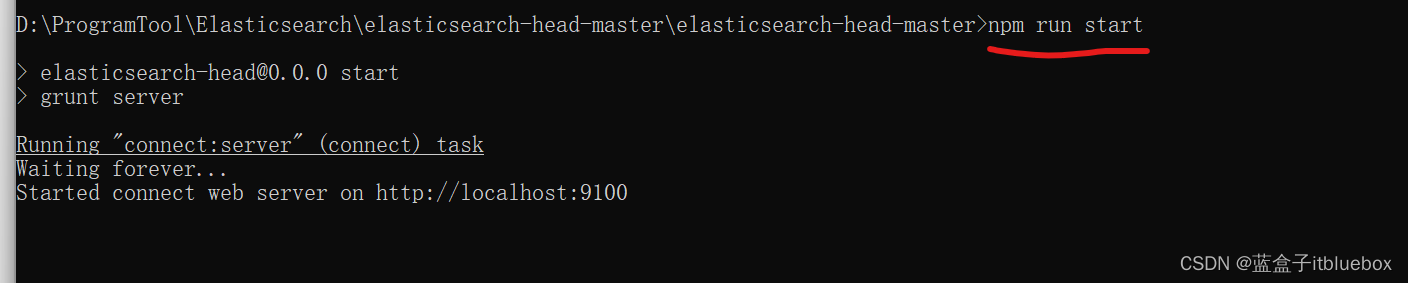
启动成功访问:http://localhost:9100/
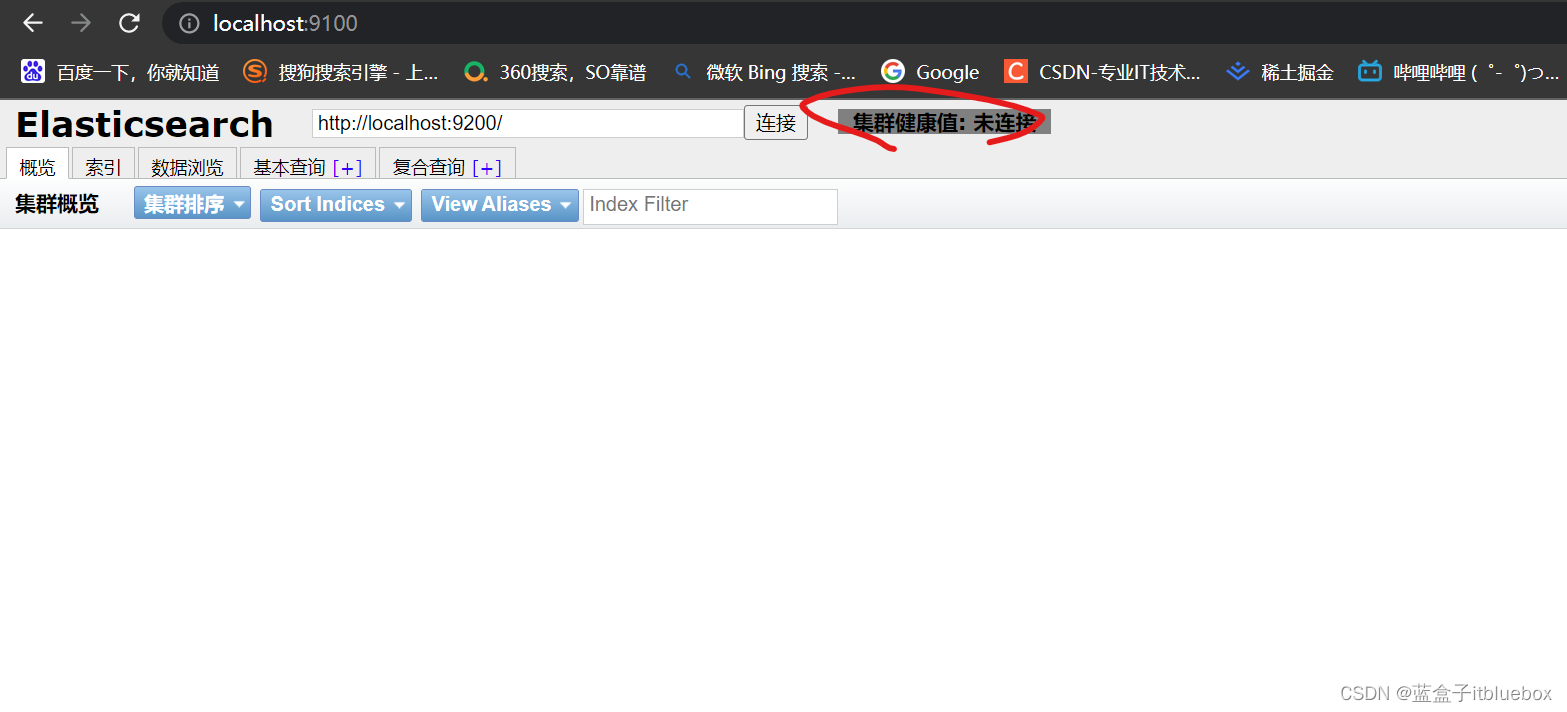
访问成功,但是是未连接状态
我们点击F12打开调试,抛出跨域的异常(跨域是指:跨端口,跨网站,跨IP)
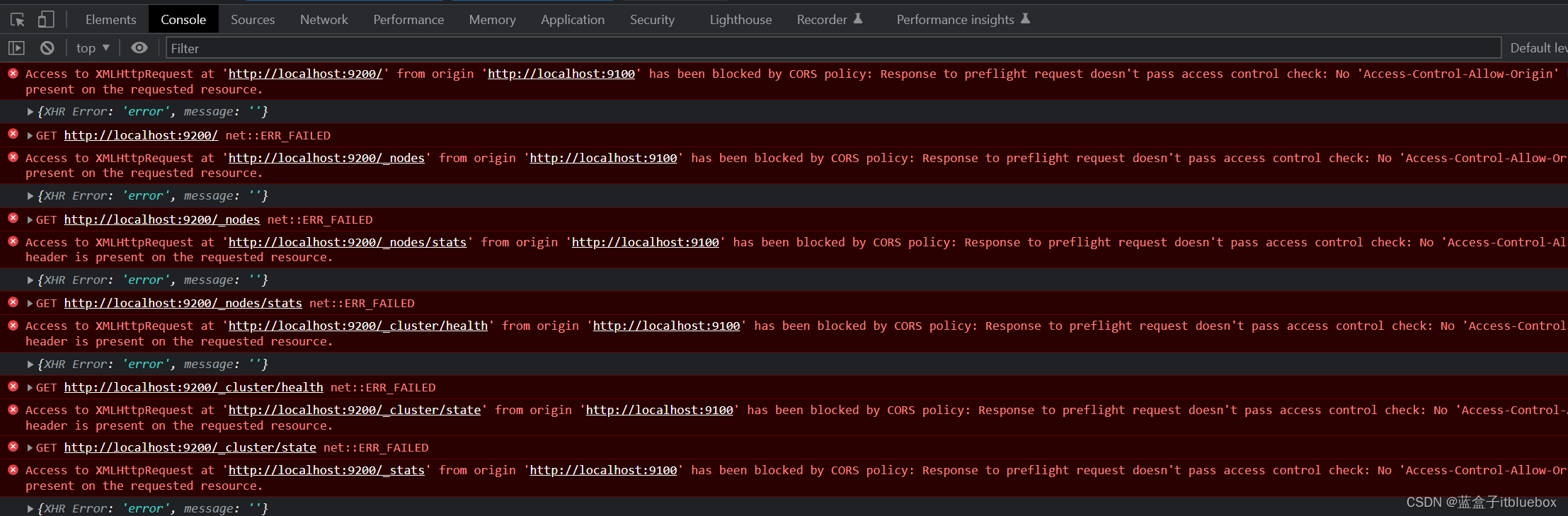
(2)解决插件出现的跨域异常无法使用的问题
关闭:ElasticSearch
修改elasticsearch.yml开启跨域,设置任何人都可以访问
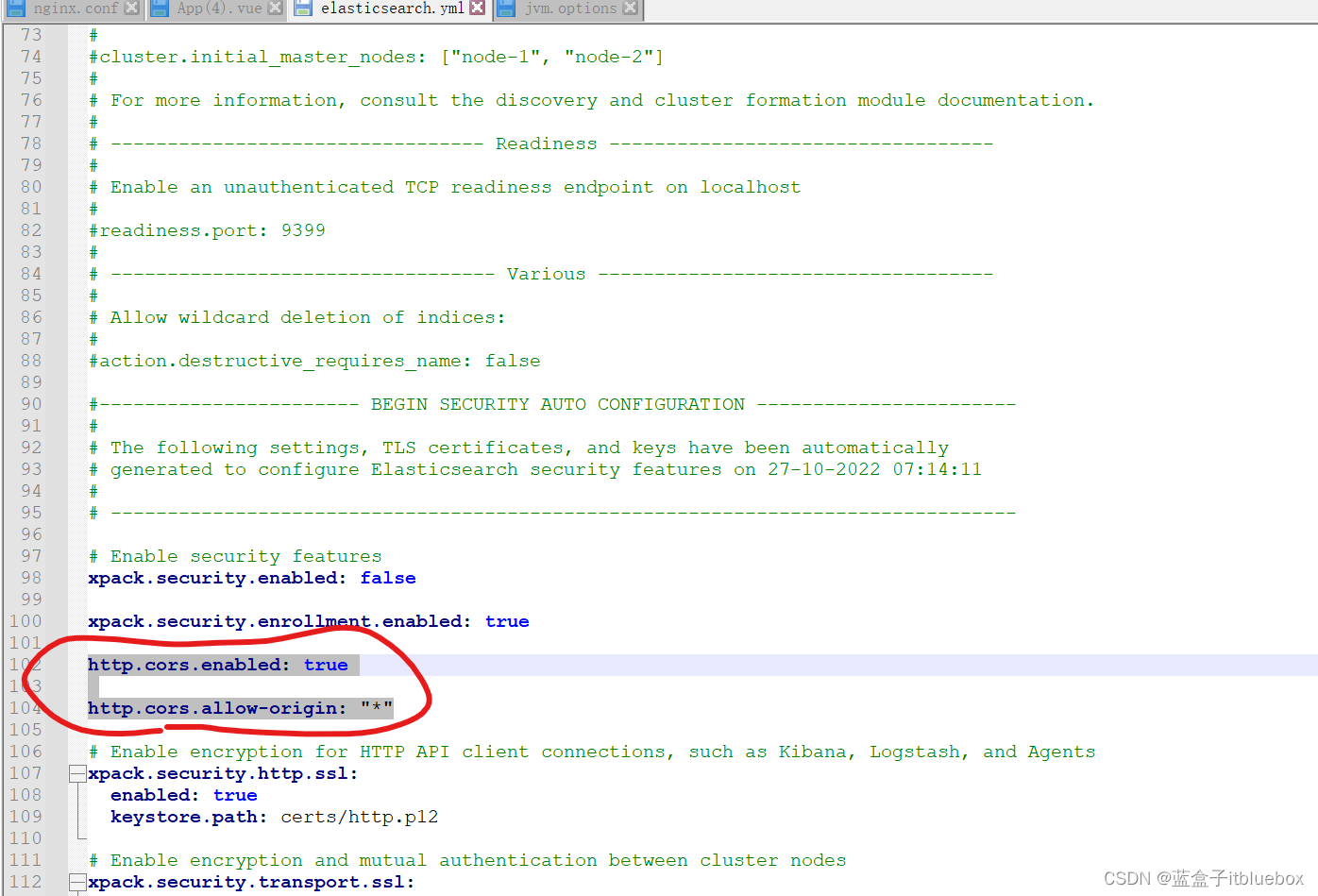
http.cors.enabled: true
http.cors.allow-origin: "*"
重新启动ES
回到9100端口,点击连接即可连接成功
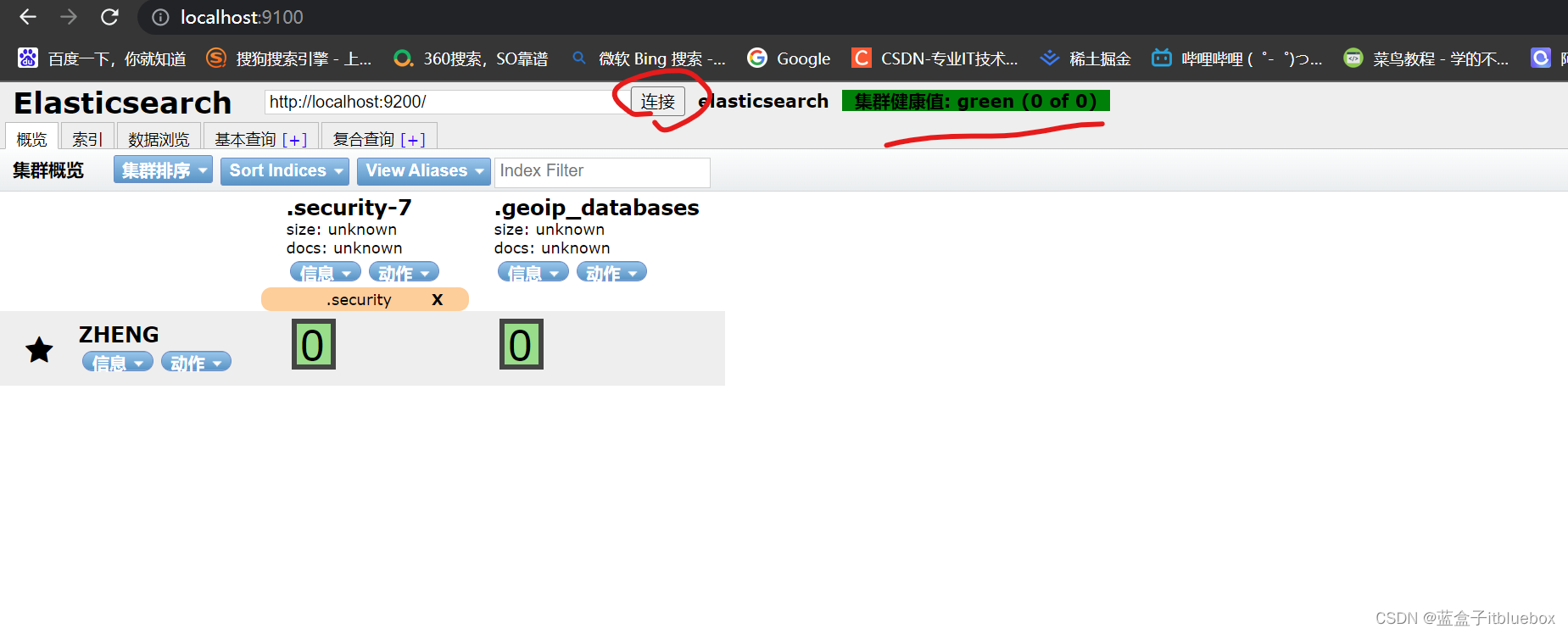
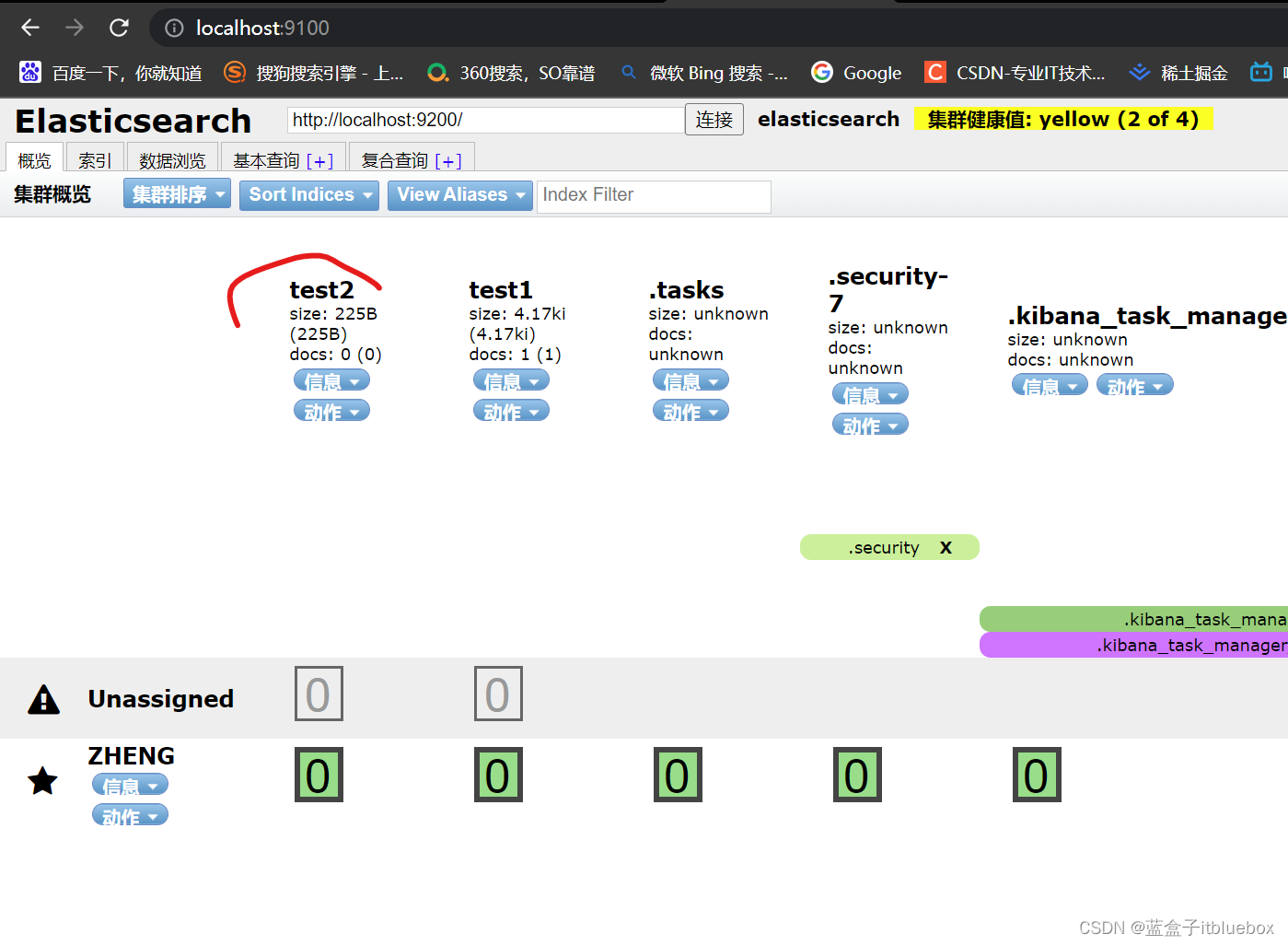
(2)elasticsearch head基本操作
a、查看信息

b、建立索引
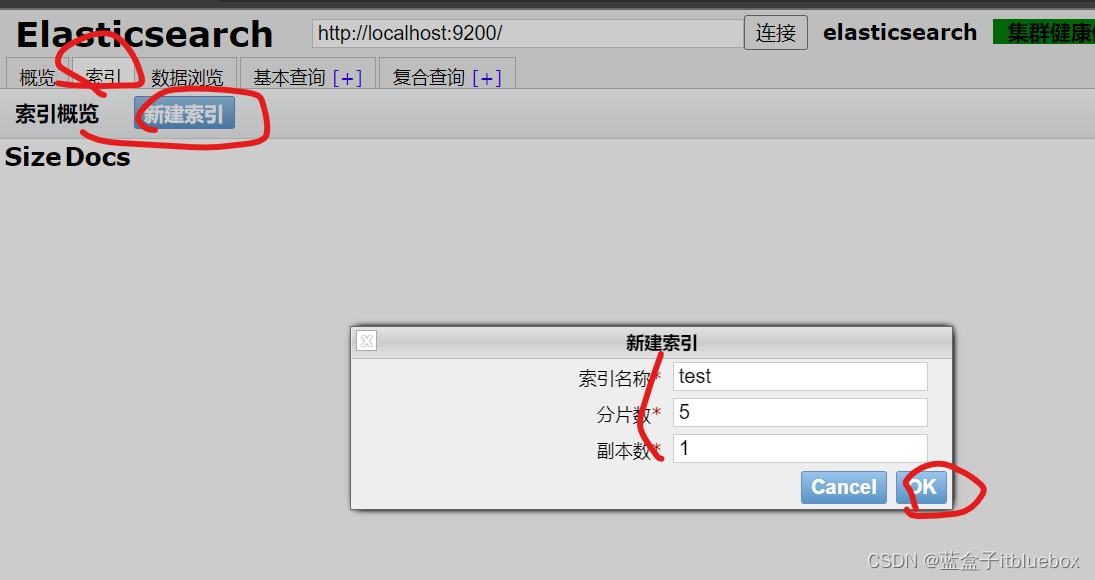
成功
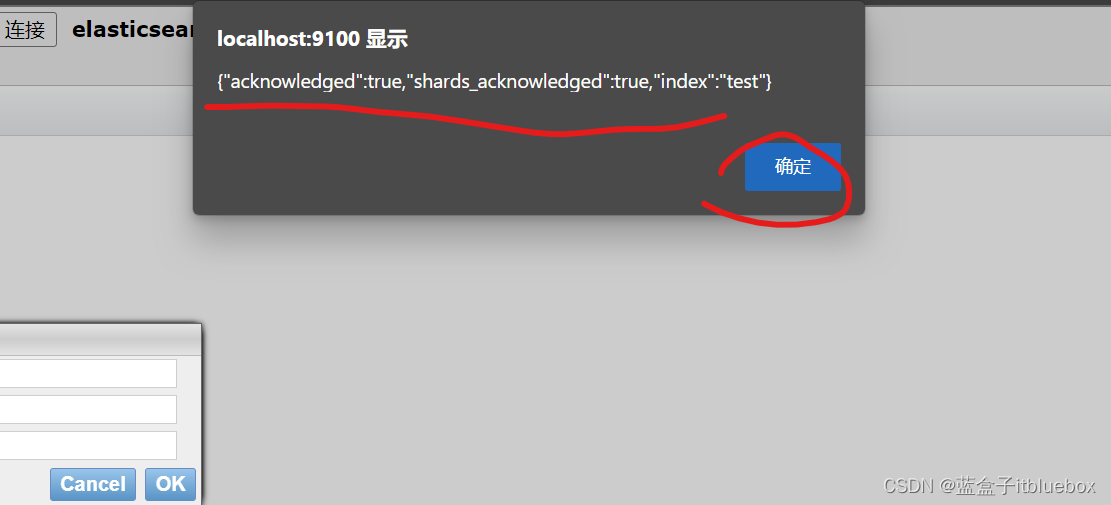

索引相当于数据库,文档相当于(表,库当中的数据)
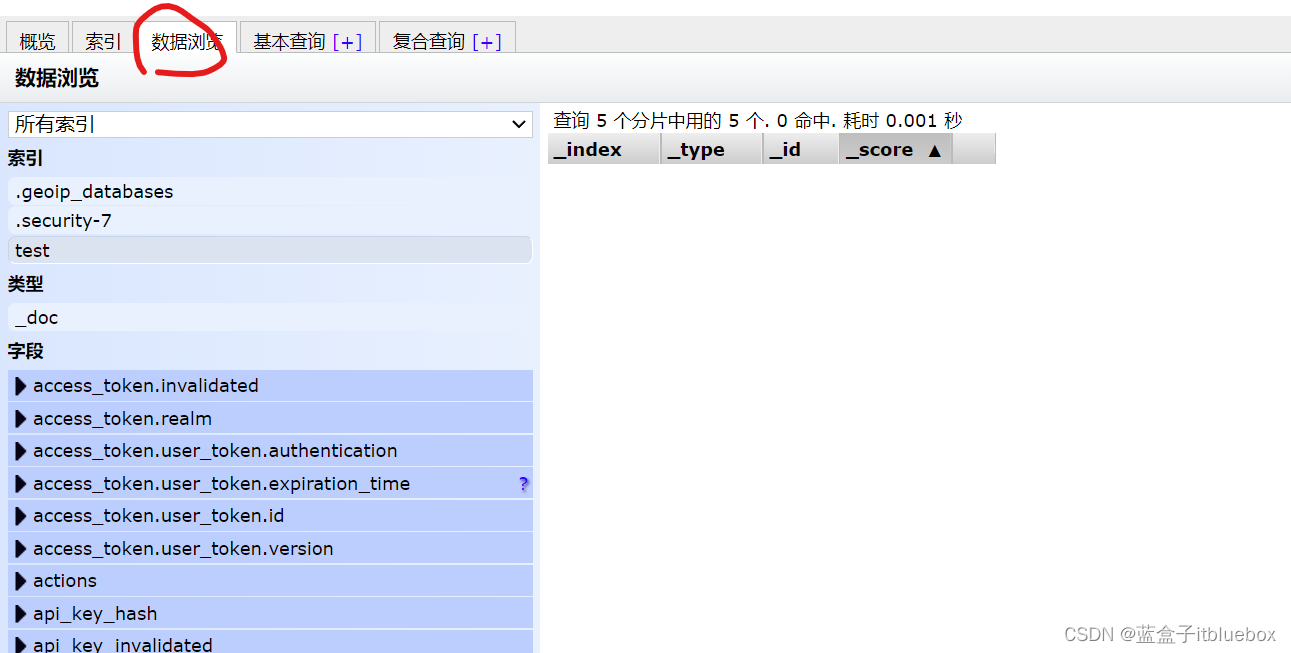
查询操作
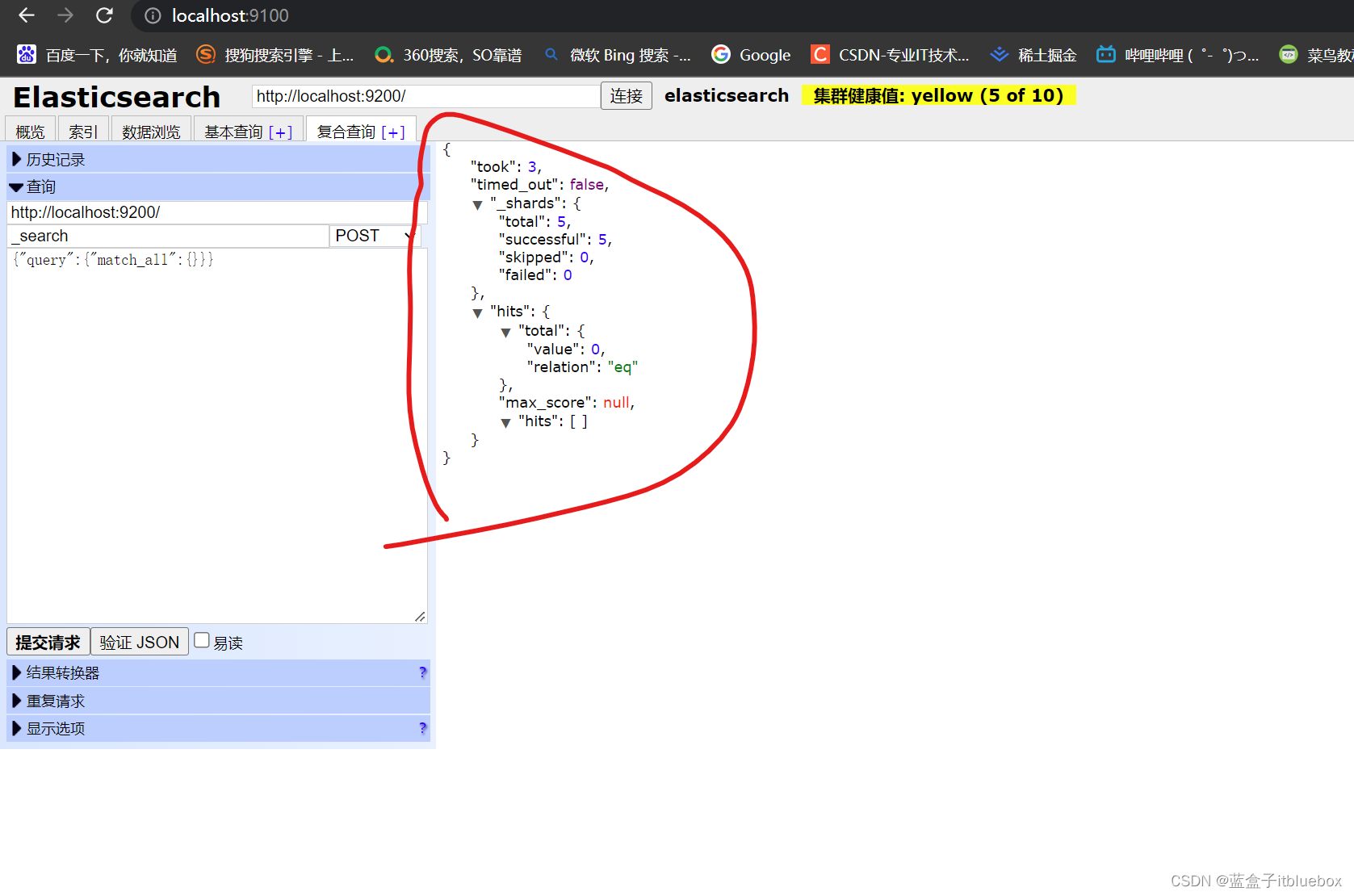
5、了解ELK
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
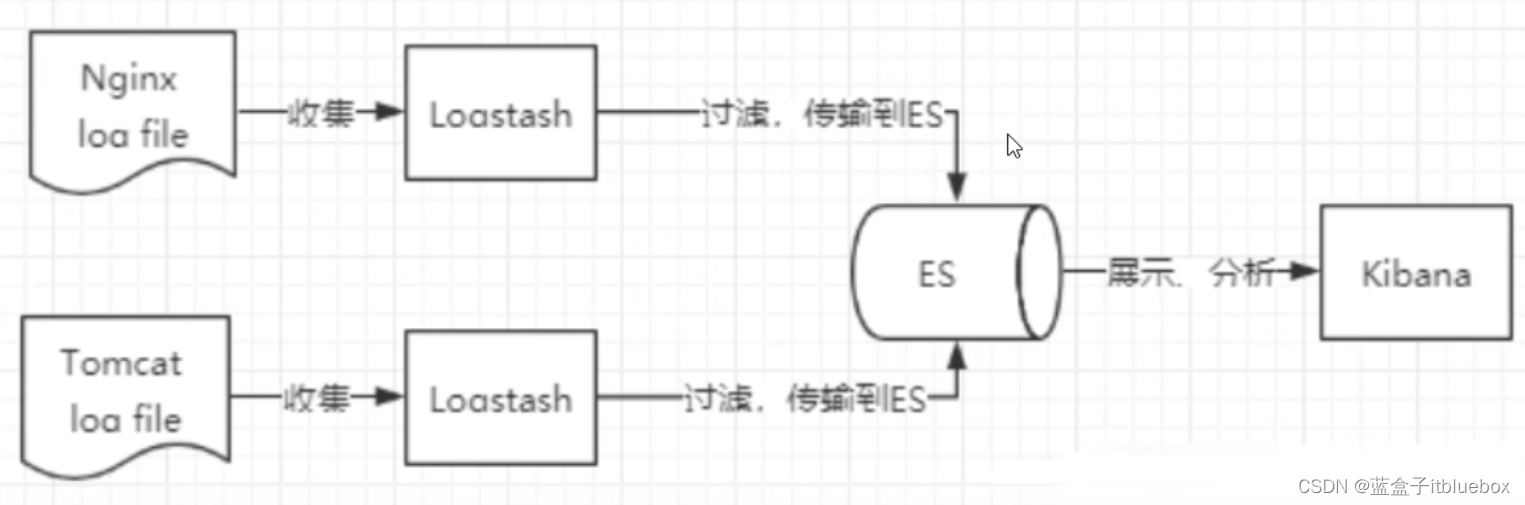
6、安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana ,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。
它操作简单,基于浏览器的用户界面可以快述创建仪表板( dashboard )实时显示Elasticsearch查询动态。
设置Kibana非常简单,无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
(1)下载解压Kibana
官网: https://www.elastic.co/cn/kibana

解压后的目录
(2)启动Kibana
启动成功
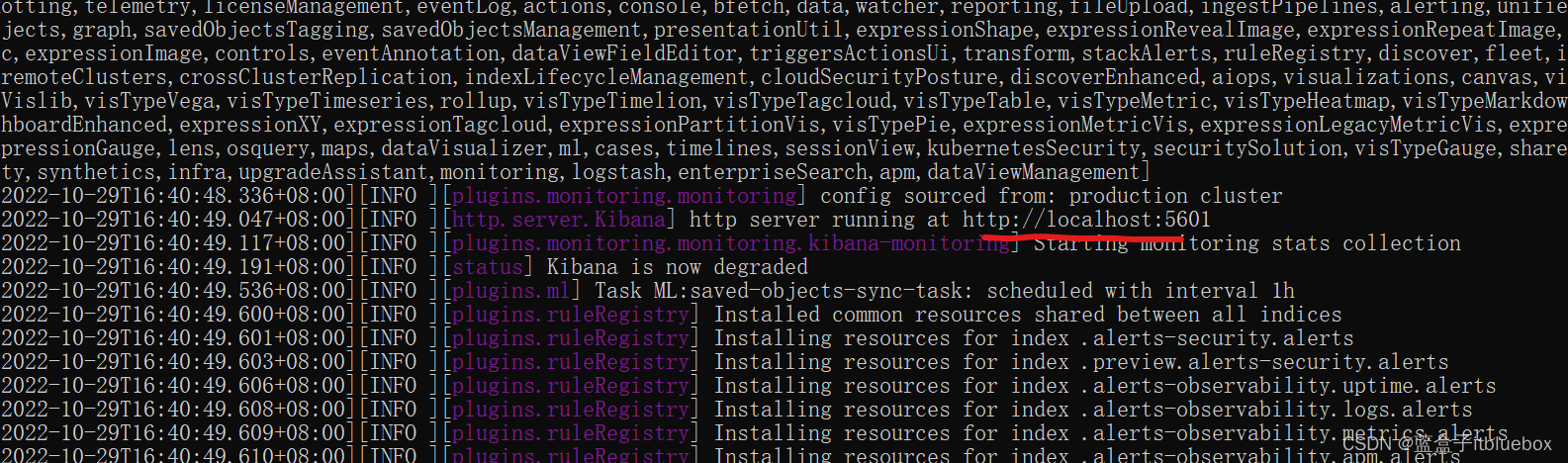
(3)访问:http://localhost:5601
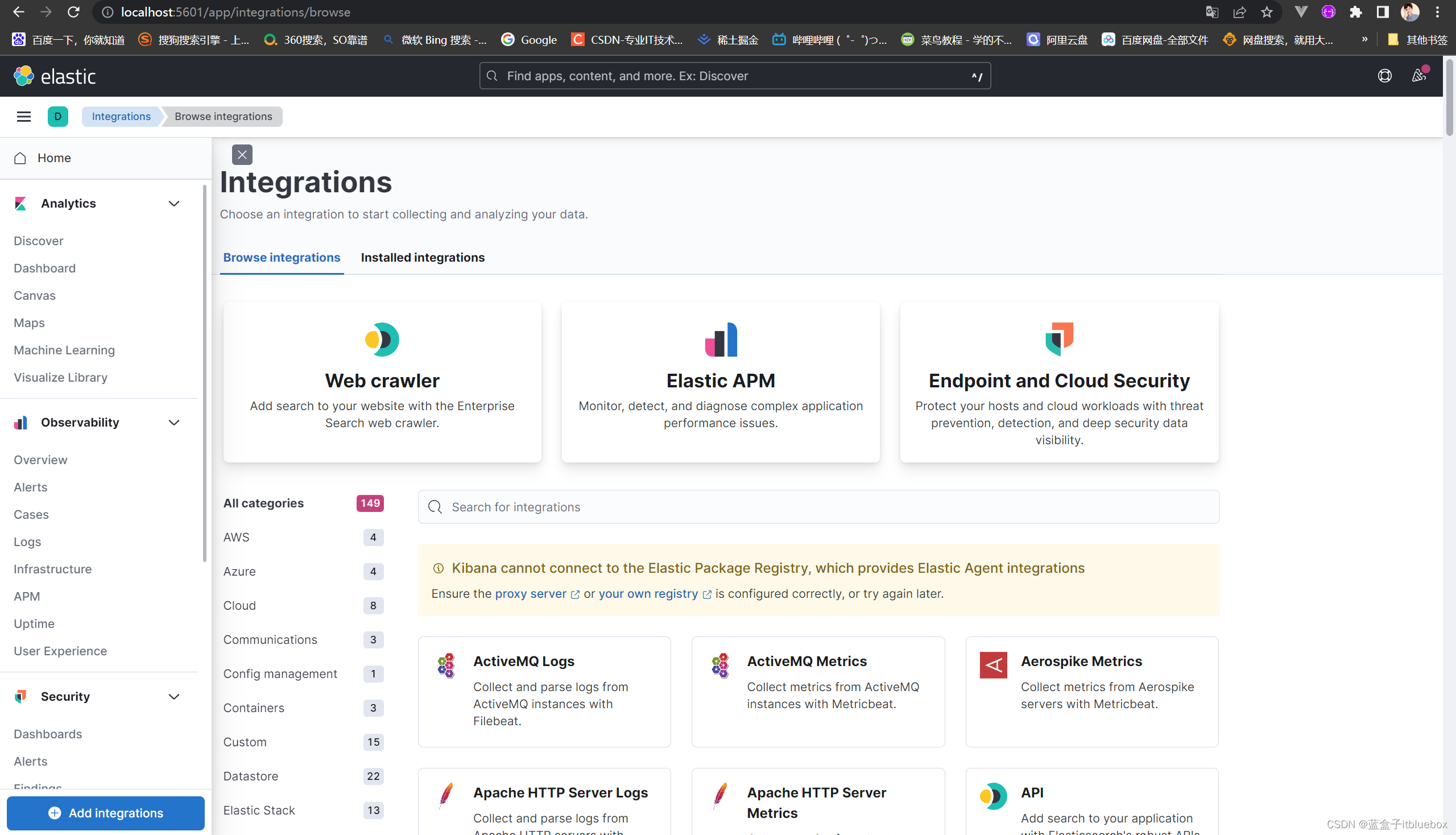
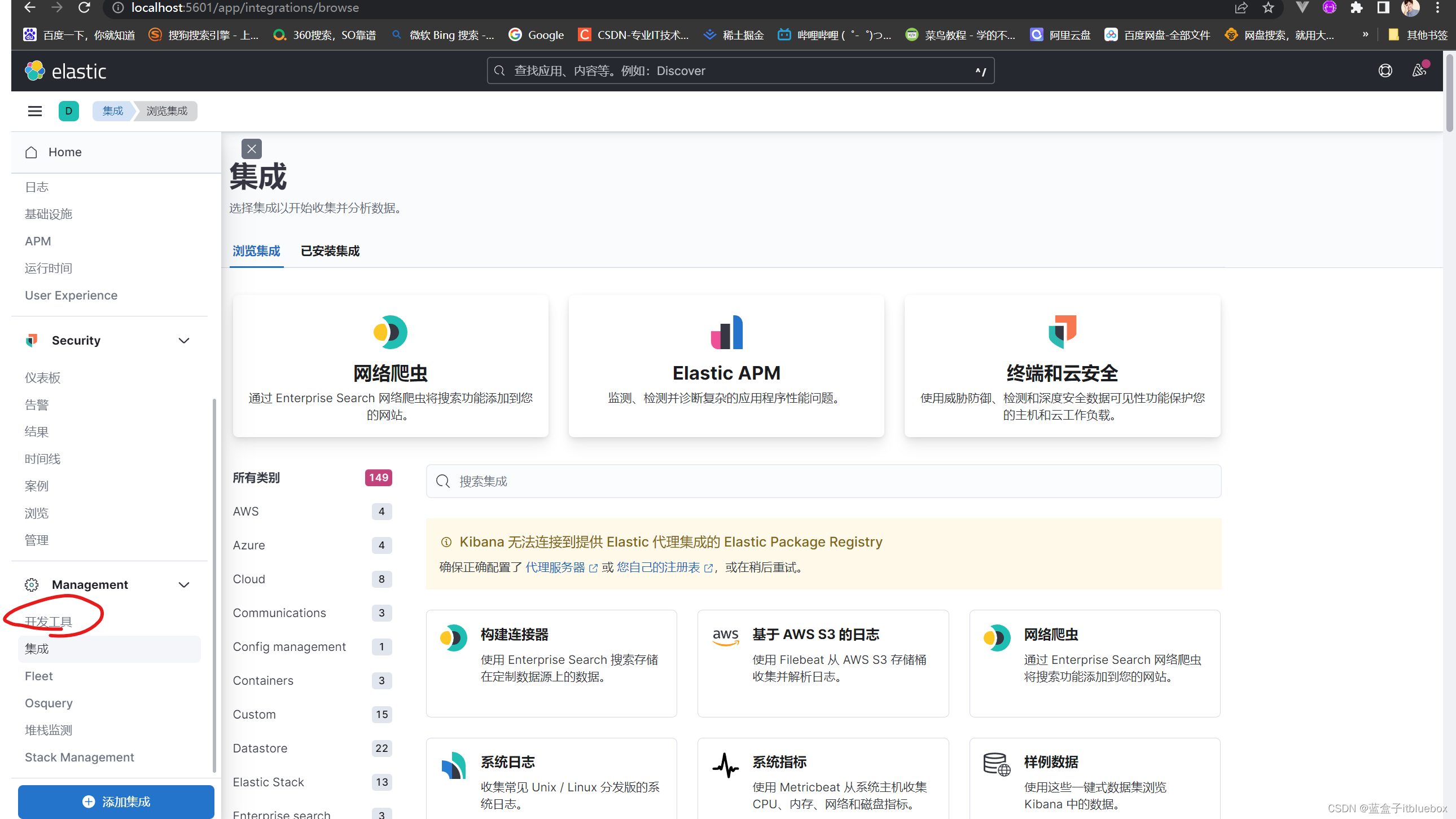
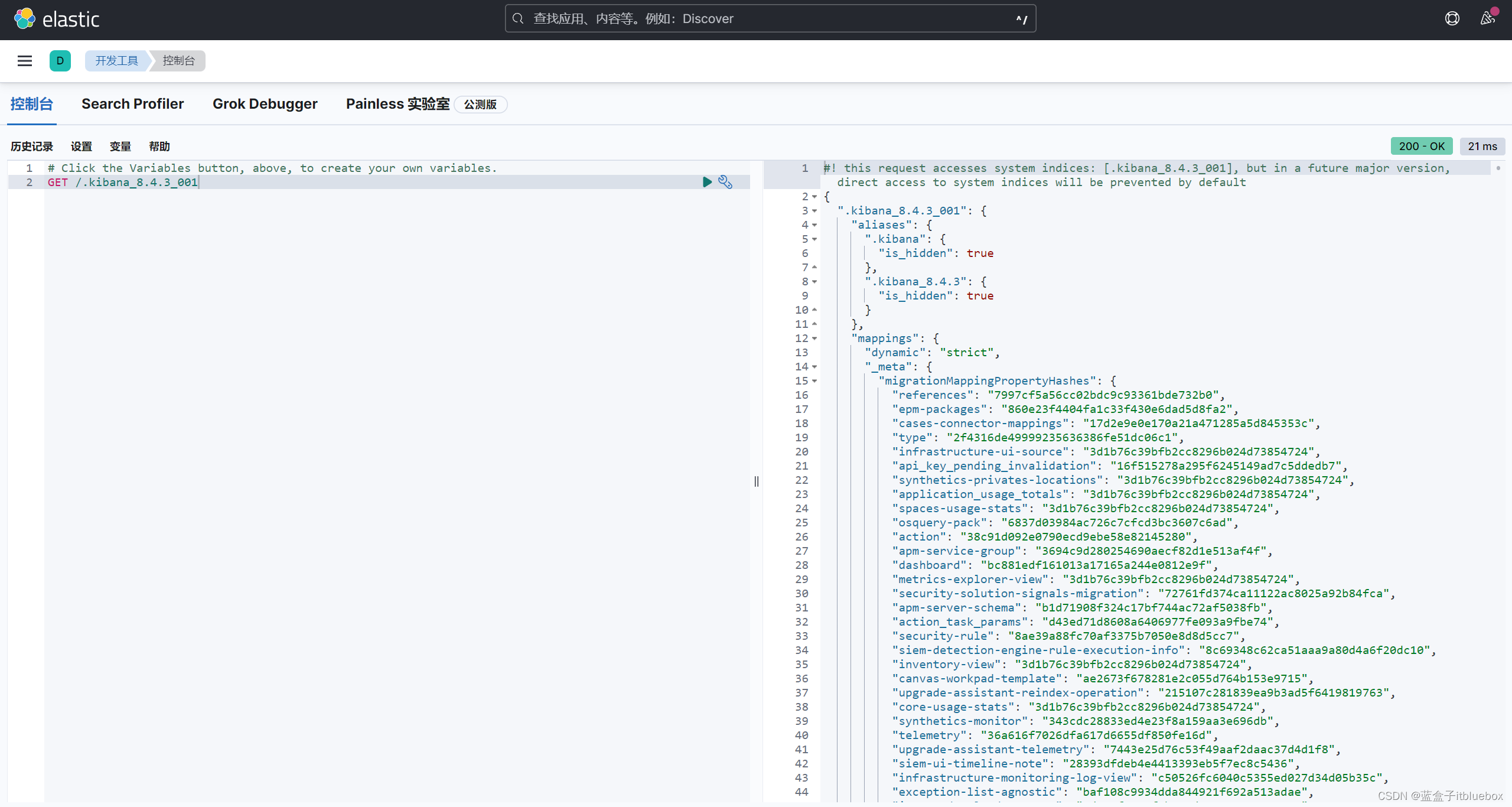
(4)Kibana开发工具
打开开发工具,点击小三角运行查询
查询成功
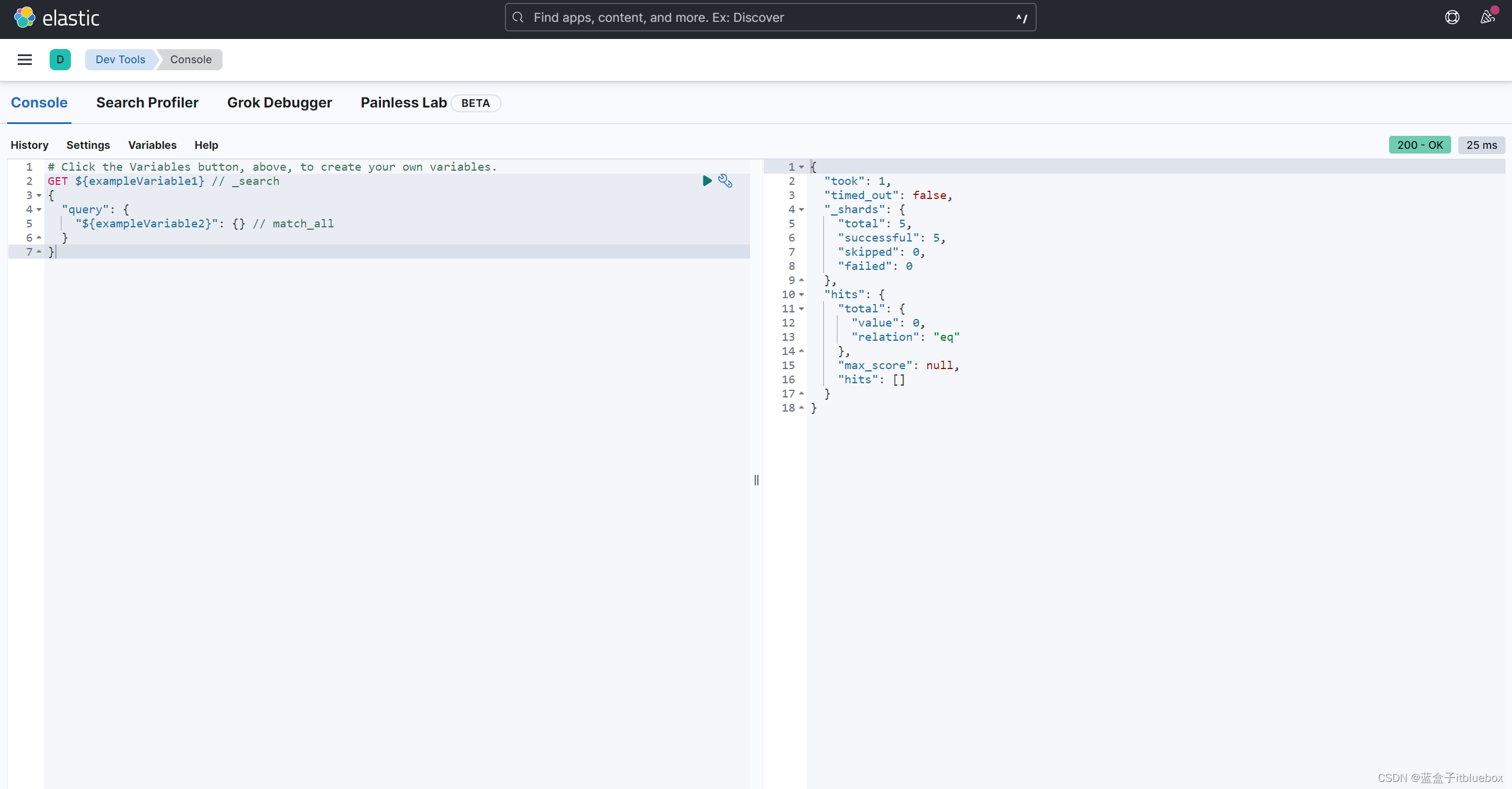
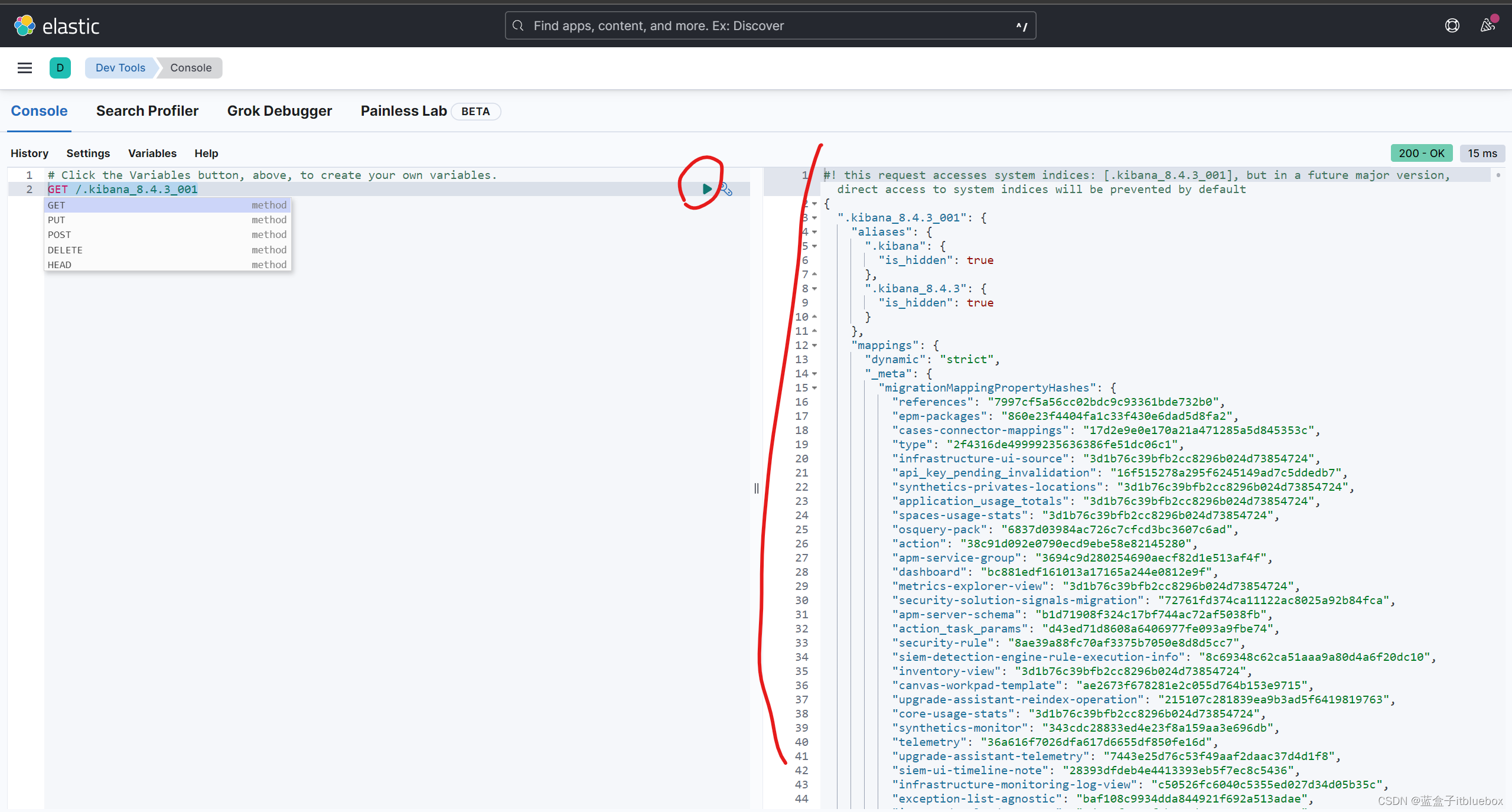
查询测试
GET /.kibana_8.4.3_001
(5)汉化Kibana,设置在config下的kibana.yml
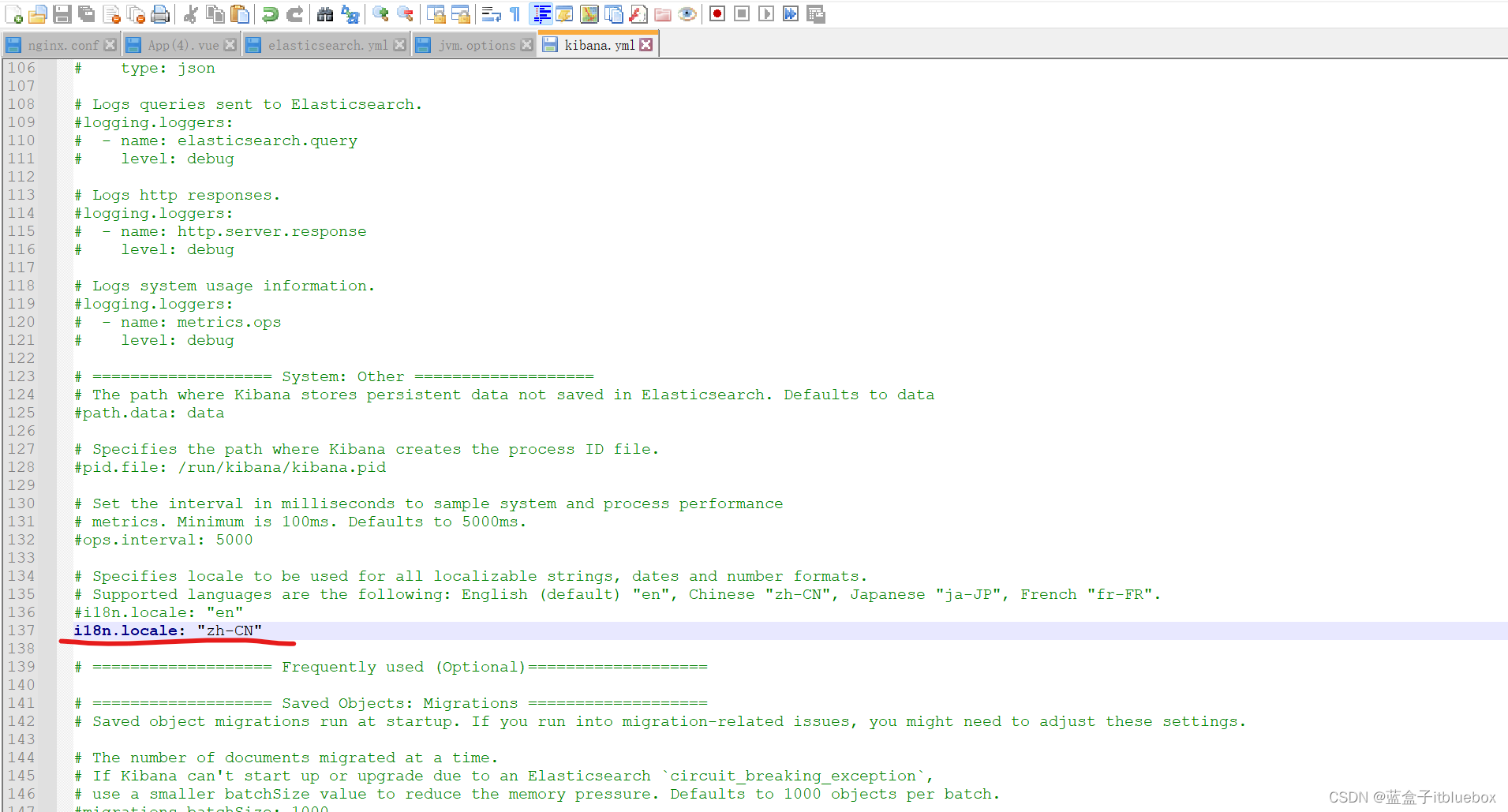
i18n.locale: "zh-CN"
重新启动Kibana
停止项目
重新启动

再次访问:http://localhost:5601
汉化成功
二、ElasticSearch的核心概念
1、基本概念
- 概念:
在前面的学习中,我们已经掌握了es是什么,同时也把es的服务已经安装启动,那么es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢﹖我们先来聊聊ElasticSearch的相关概念吧!
集群,节点,索引,类型,文档,分片,映射是什么?
- elasticsearch是面向文档,关系行数据库和elasticsearch 客观的对比!。ES一切都是JSON
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types(弃用) |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
物理设计:
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移。
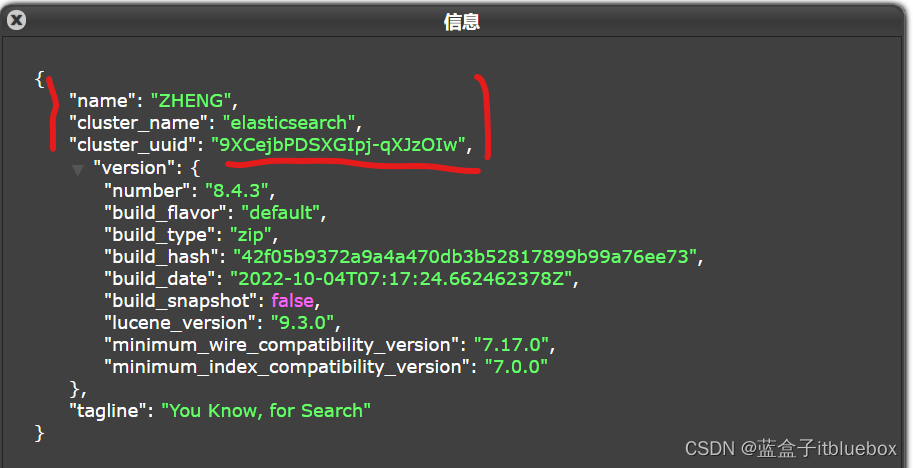
一个人就是一个集群!默认的集群名称ElasticSearch
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的一各顺序找到它:索引>类型>文档ID,通过这个组合我们就能索引到某个具体的文档。
注意:ID不必是整数,实际上它是个字符串。
-
文档:
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
· 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:vallue!(一行数据统称文档)
· 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!【就是一个JSON对象!java当中通过fastjson自动转换!】
· 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。 -
类型:(ES8当中已经弃用-了解即可)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。 -
索引:
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合(相当于数据库)。
索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
2、物理设计:节点和分片
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard ,又称主分片)构成的,每一个主分片会有一个副本( replica shard ,又称复制分片)
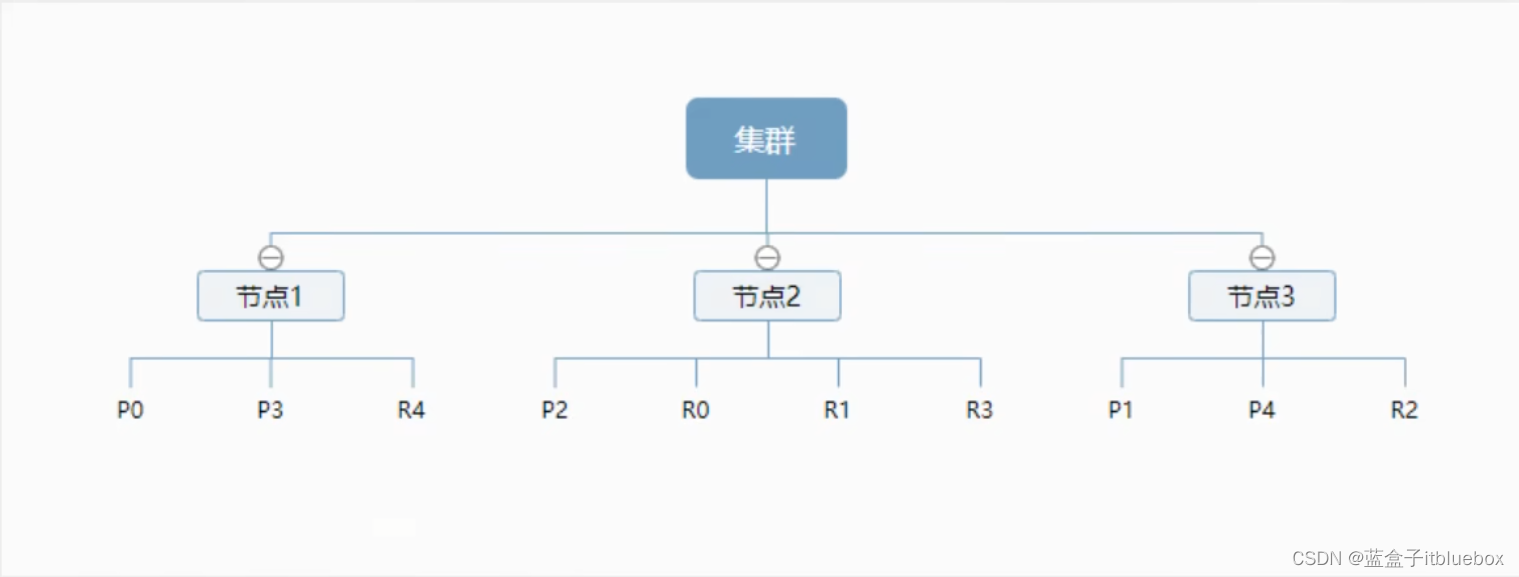
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
- 倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
例如,现在有两个文档,每个文档包含如下内容:
Study every day,good good up to forever # 文档1包含的内容
To forever,study every day,good good up #文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | x |
| To | x | x |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | x | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | x |
| up | √ | √ |
现在,我们试图搜索to forever,只需要查看包含每个词条的文档,
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | x |
| forever | √ | √ |
| total(匹配度) | 2 | 1 |
两个文档都匹配,但是第一个文档比第二个匹配程度更高。
如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。
那么倒排索引列表就是这样的一个结构:
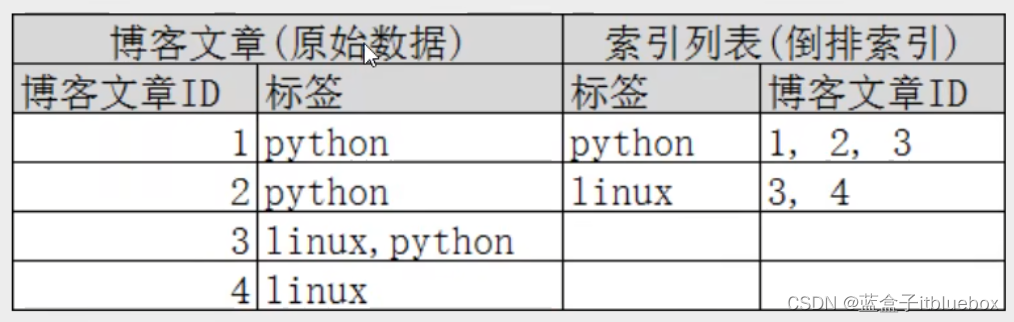
左边博客文章为一行为一个文档,右边将对应的文档进行倒排索引,找到对应关键字,所在的文档id进行统计。
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。
只需要查看标签这一栏,然后获取相关的文章ID即可。
elasticsearch的索引和Lucene的索引对比,
在elasticsearch中,索引这个词被频繁使用,这就是术语的使用。
在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。
所以一个elasticsearch索引是由多个Lucene索引组成的。
别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作!
三、IK分词器
1、什么是IK分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱中国"会被分为"我"∵"爱"“中”"国”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
如果要使用中文,建议使用IK分词器。
IK提供了两个分词算法: ik_smart和ik_max_word ,其中ik_smart为最少切分,ik_max_word为最细粒度划分!一会我们测试!
2、安装,启动IK分词器
下载IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases

将其放入ElasticSearch 的插件当中,
在ElasticSearch的plugins目录下解压即可
重新启动ElasticSearch ,elasticsearch head,Kibana
在重新启动ElasticSearch 的时候我们可以看到IK分词器被加载了

3、elasticsearch-plugin
通过elasticsearch-plugin命令查看加载进来的插件
列出elasticsearch安装的插件列表
进入es的bin目录下
elasticsearch-plugin list
我们可以看到已经安装成功了ik分词器的插件

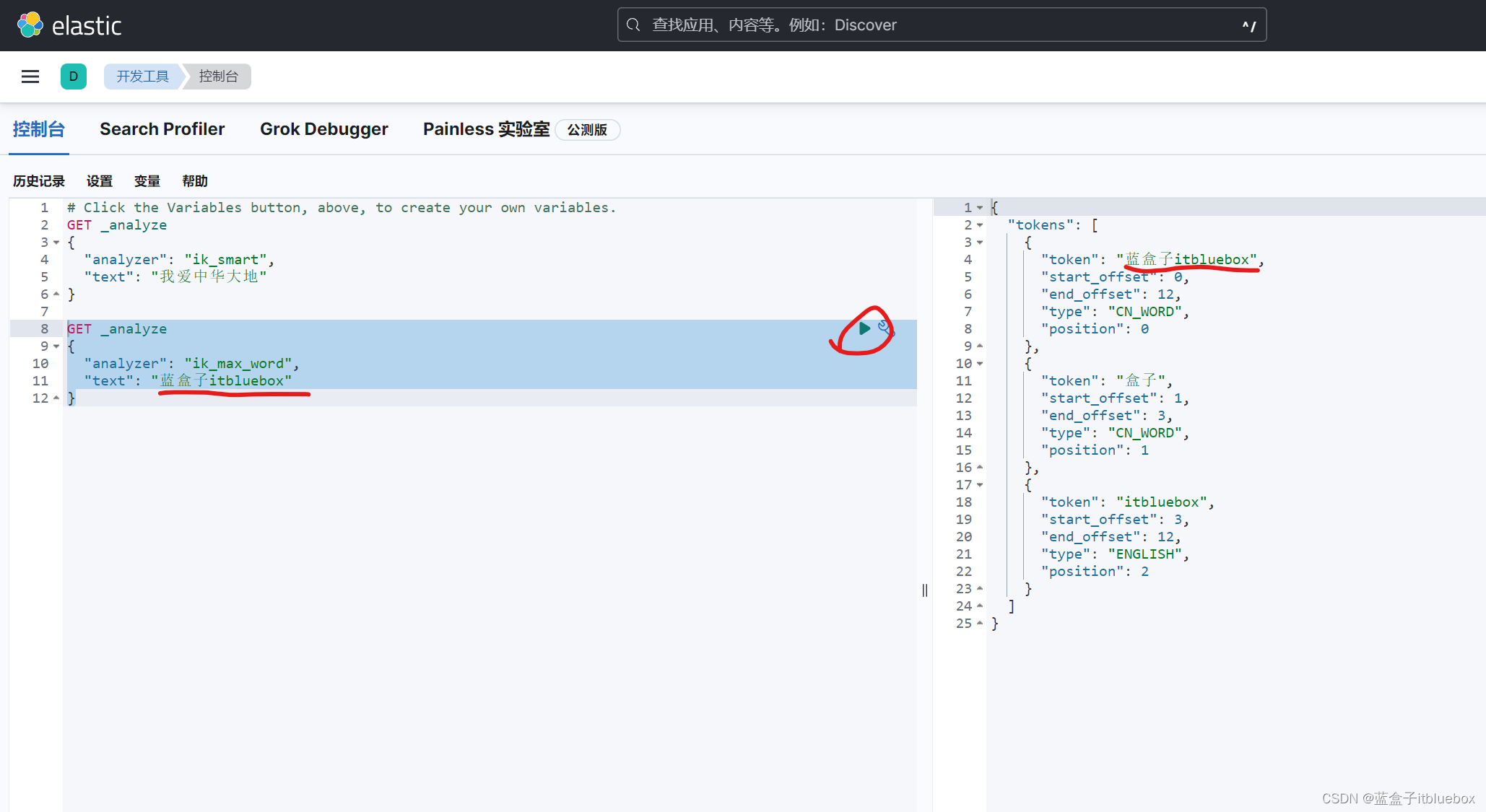
4、使用Kibana进行测试!,通过ik分词器进行基本的分词测试
(1)使用ik_smart分词器(最少切分)
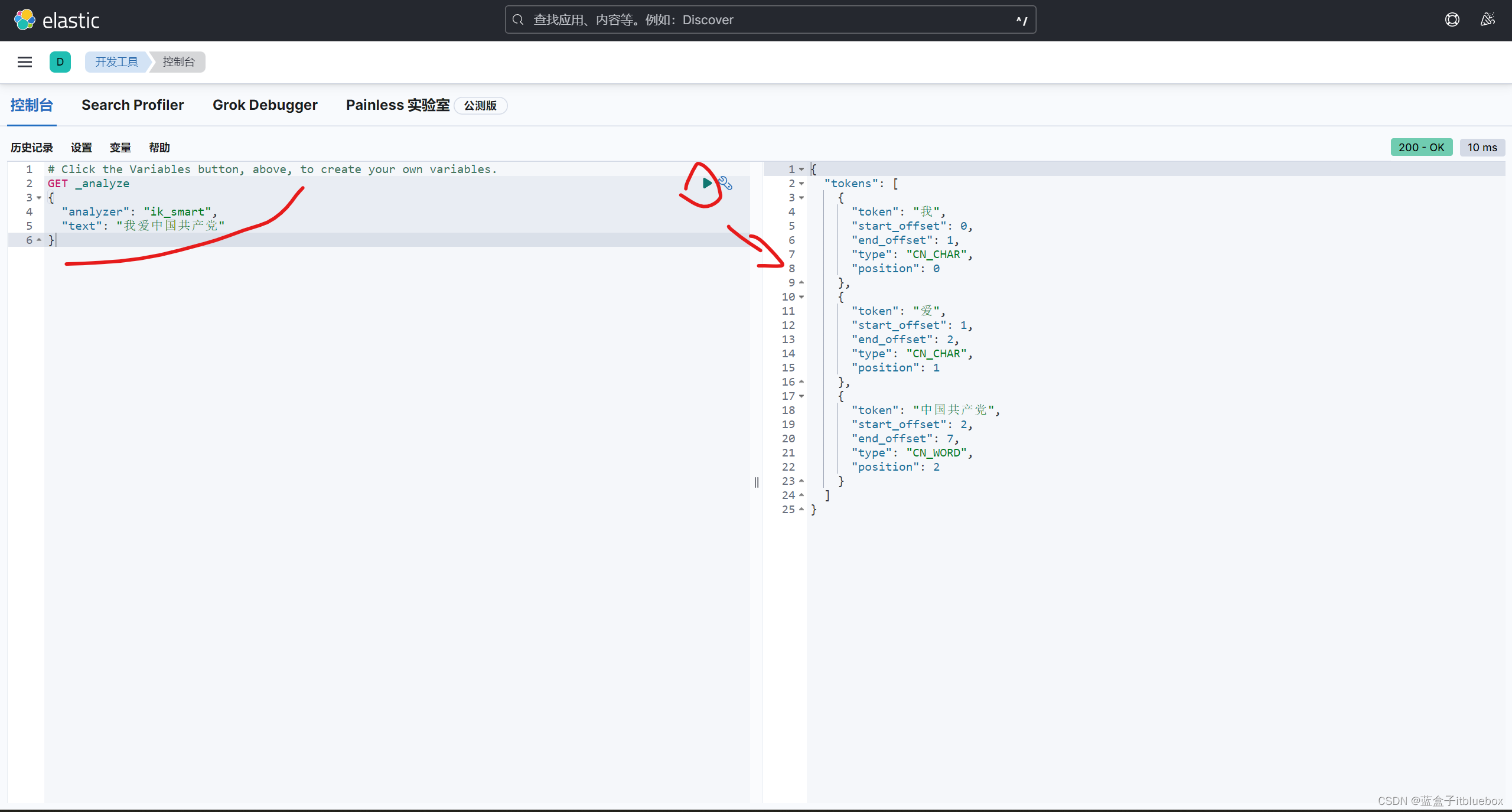
(2)使用ik_max_word(最细粒度划分)

(3)问题???
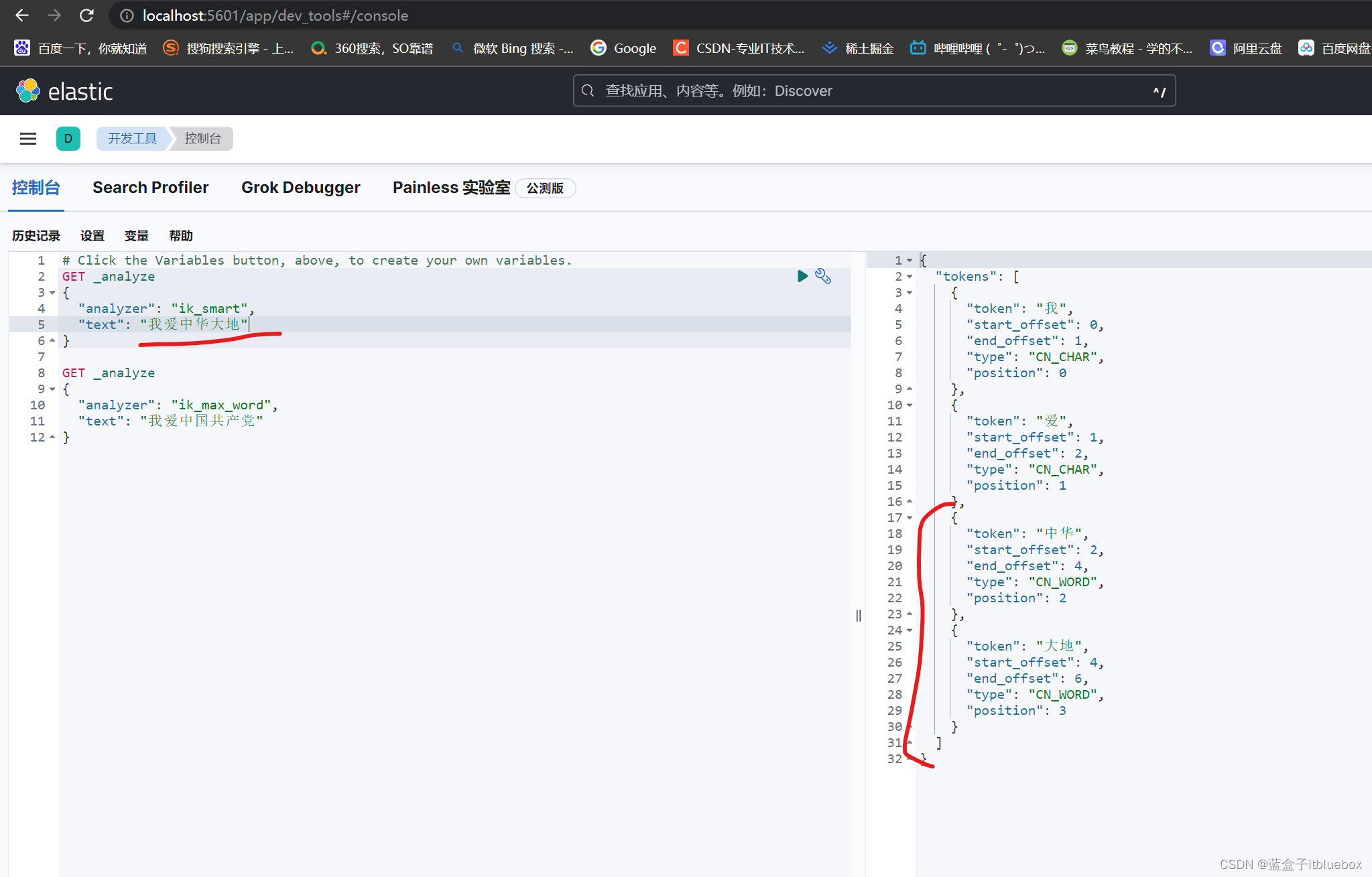
在对‘我爱中华大地’进行分词的时候,将中华和大地拆分为两个词语,这样可以,但是我们更加希望可以将其识别为一个单词,不对齐进行分词
这种情况需要自己将对应的数据添加到分词器的字典当中!
5、ik分词器增加自己的配置!(自定义分词字典)
进入ik分词的目录当中
在elasticsearch-8.4.3-windows-x86_64\elasticsearch-8.4.3\plugins\elasticsearch-analysis-ik-8.4.3\config当中的
创建自定义词典
创建my.dic字典文件
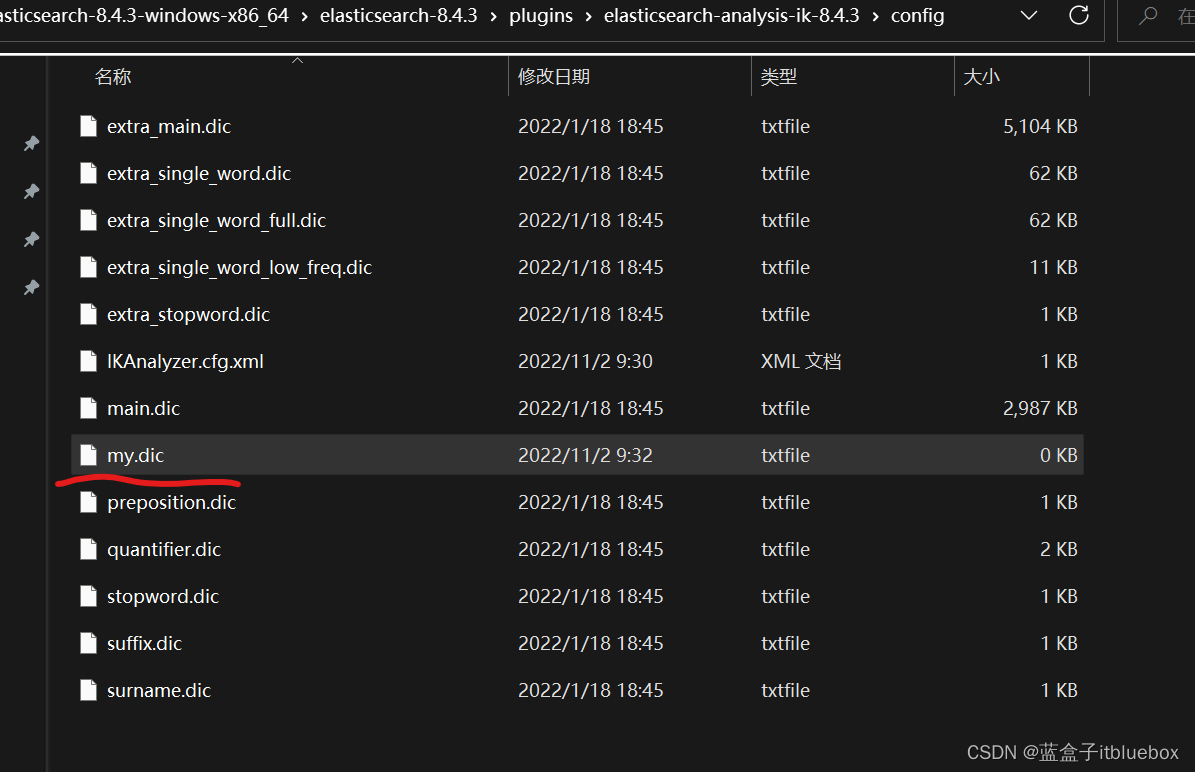
编辑里面的内容
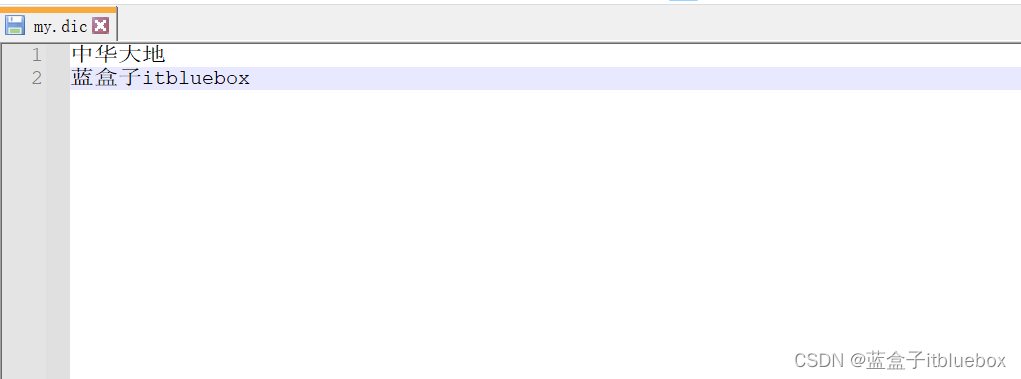
中华大地
蓝盒子itbluebox
config当中的IKAnalyzer.cfg.xml配置字典
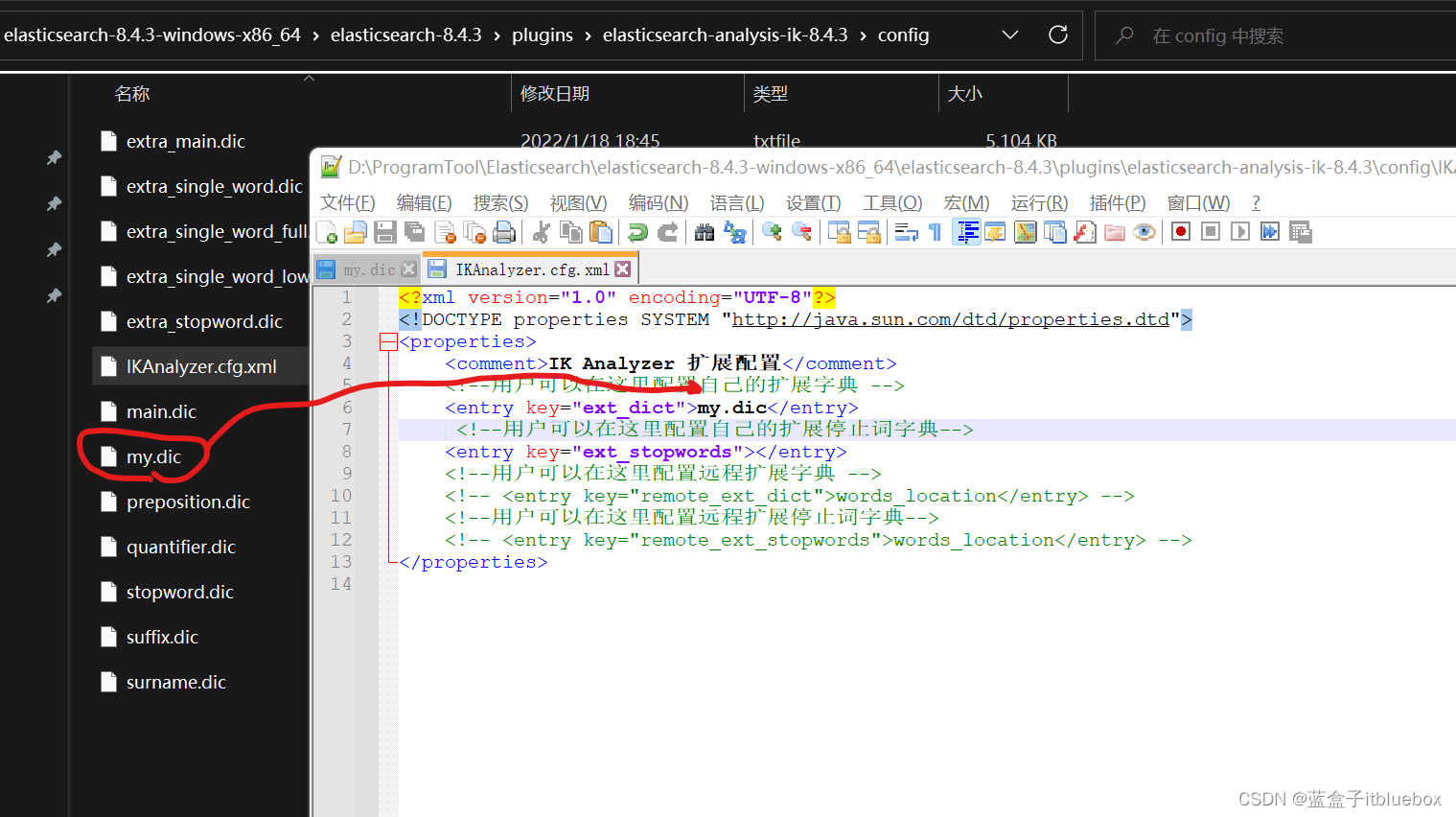
<entry key="ext_dict">my.dic</entry>
重新启动ES再次测试
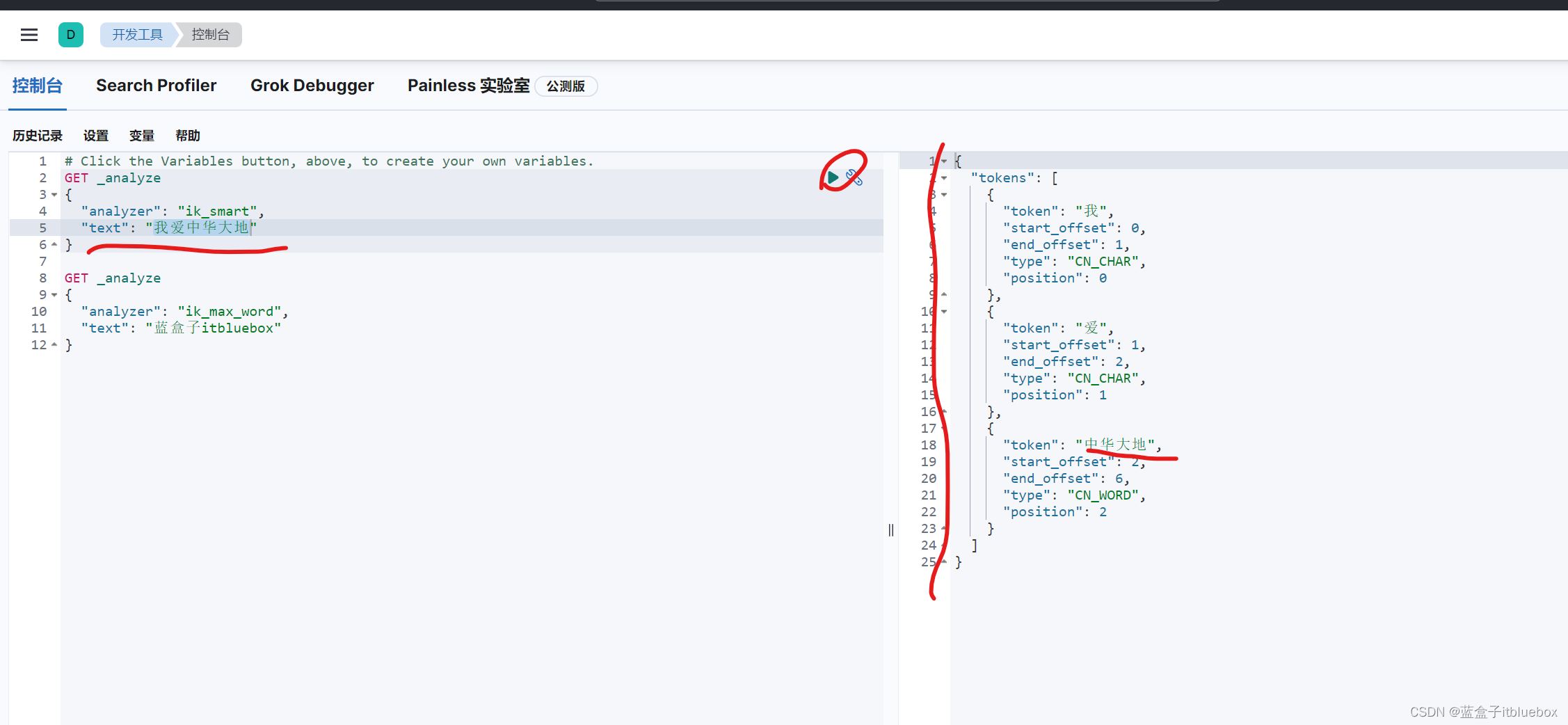
以后的话,我们需要自己配置 分词就在自定义的dic文件中进行配置即可
四、ElasticSearch 索引的基本操作
1、Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id ) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id ) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
2、创建索引
打开
elasticsearch head
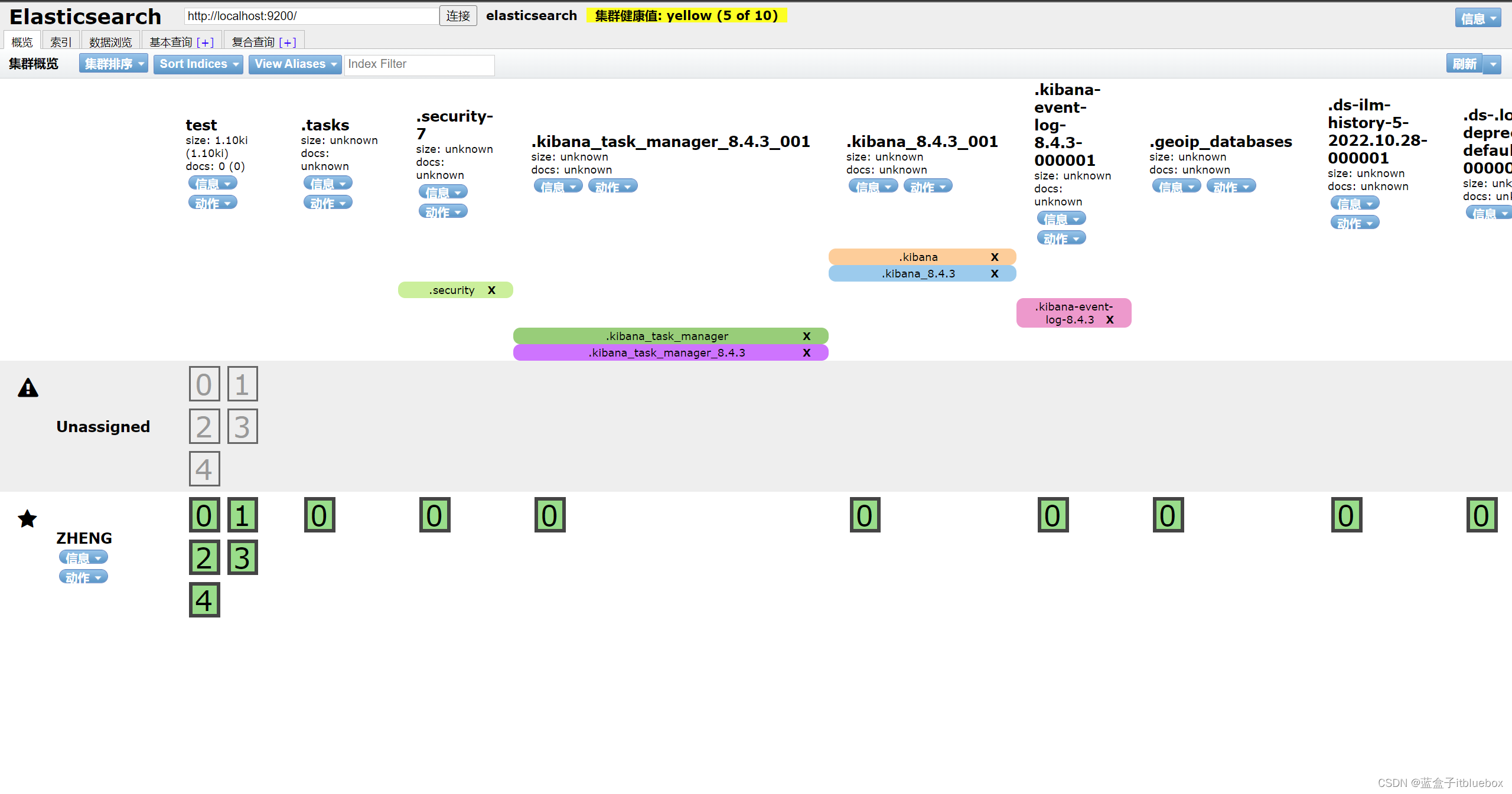
(1)删除一些索引
(2)创建索引(添加数据的同时创建索引库)
PUT /索引名/默认数据类型/id
{请求体}
打开Kibana
输入以下内容创建索引
PUT /test1/_doc/1
{
"name":"itbluebox",
"age":3
}
返回值
{
"_index": "test1",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
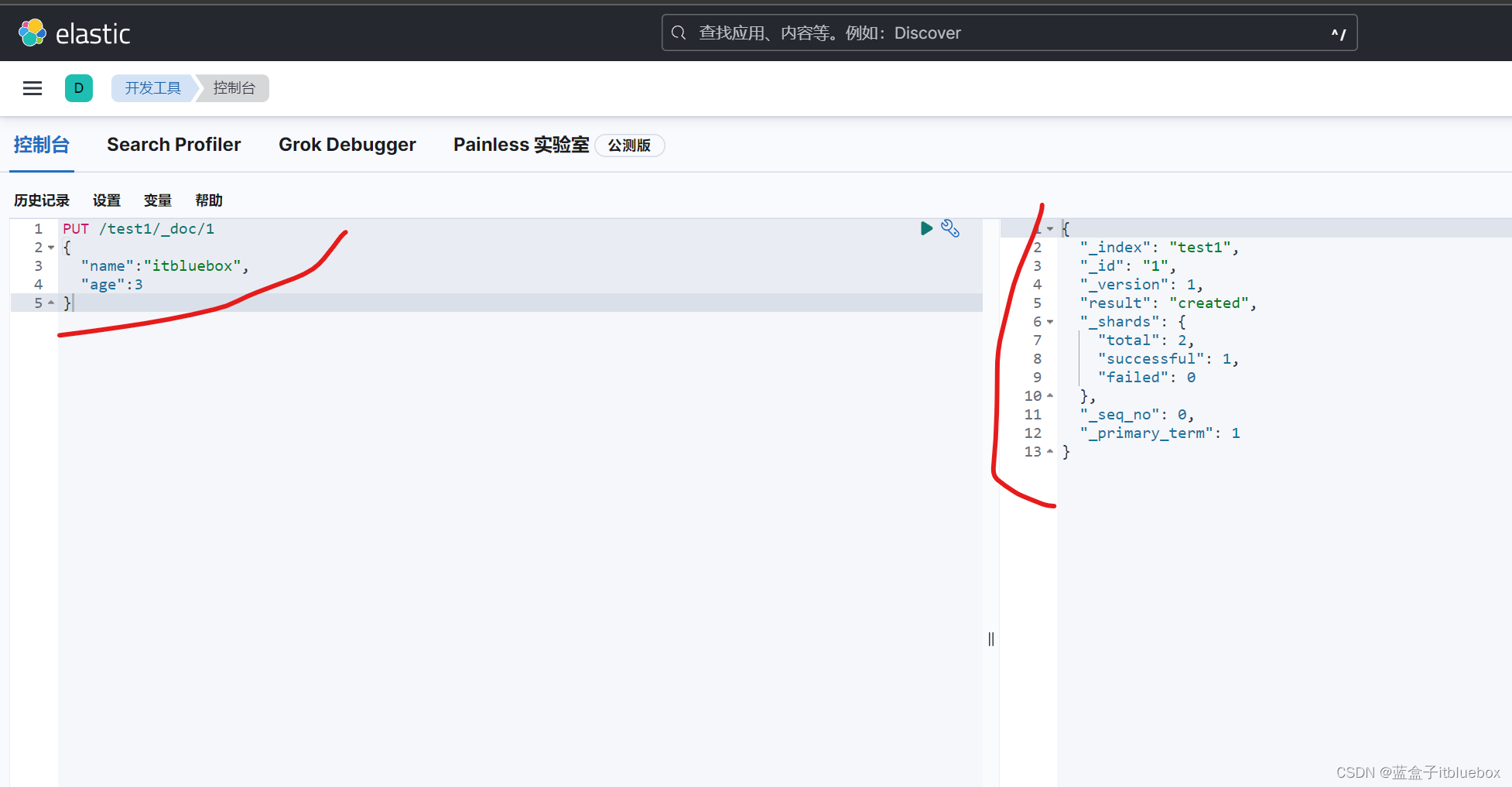
创建索引成功
— 拓展如果您使用的是8.0之前的版本,请这样创建
PUT /索引名/~类型名~/id
{请求体}
PUT /test1/type1/1
{
"name":"itbluebox",
"age":3
}
(3)查看索引
在head当中查看
多了一个索引
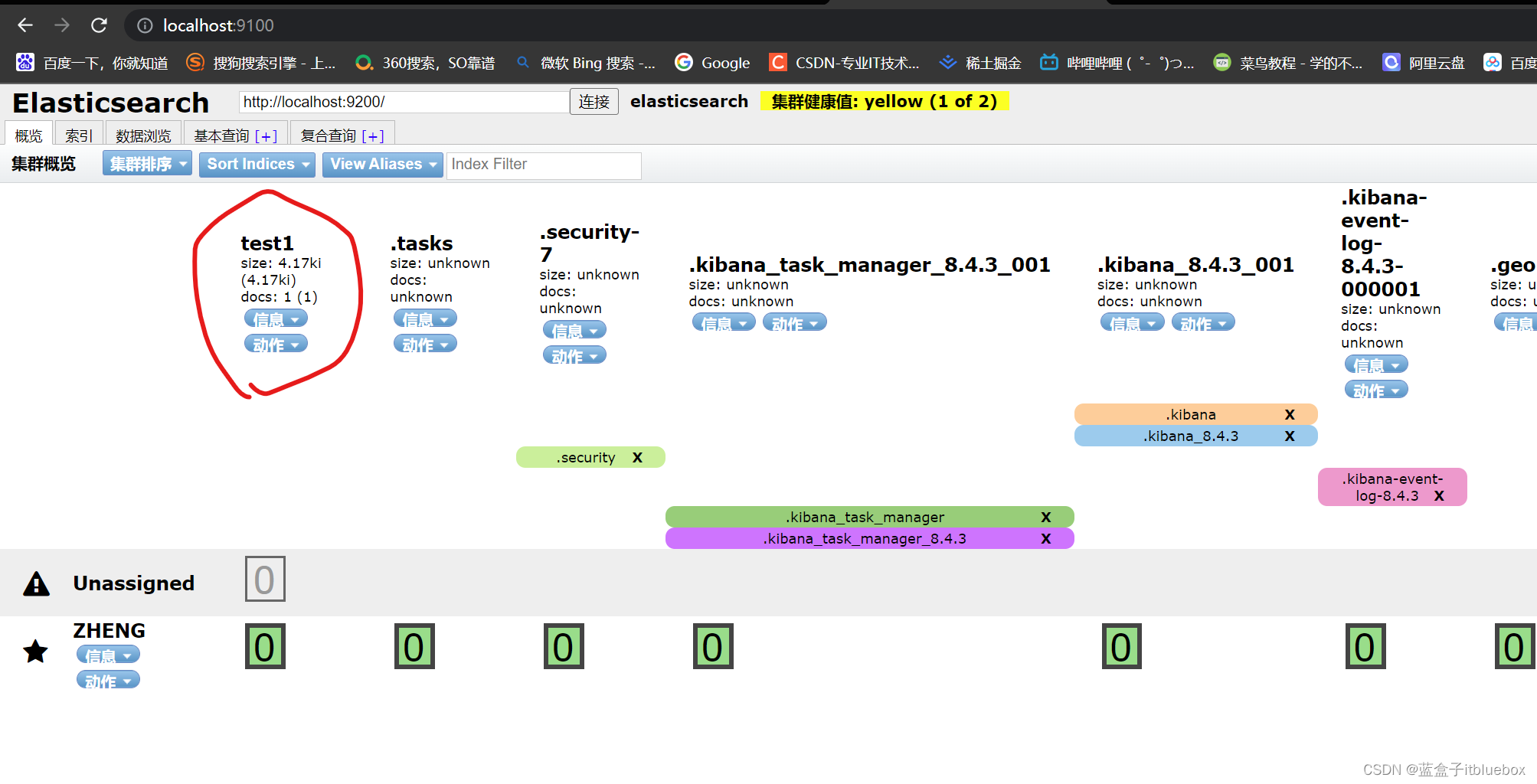
查看索引
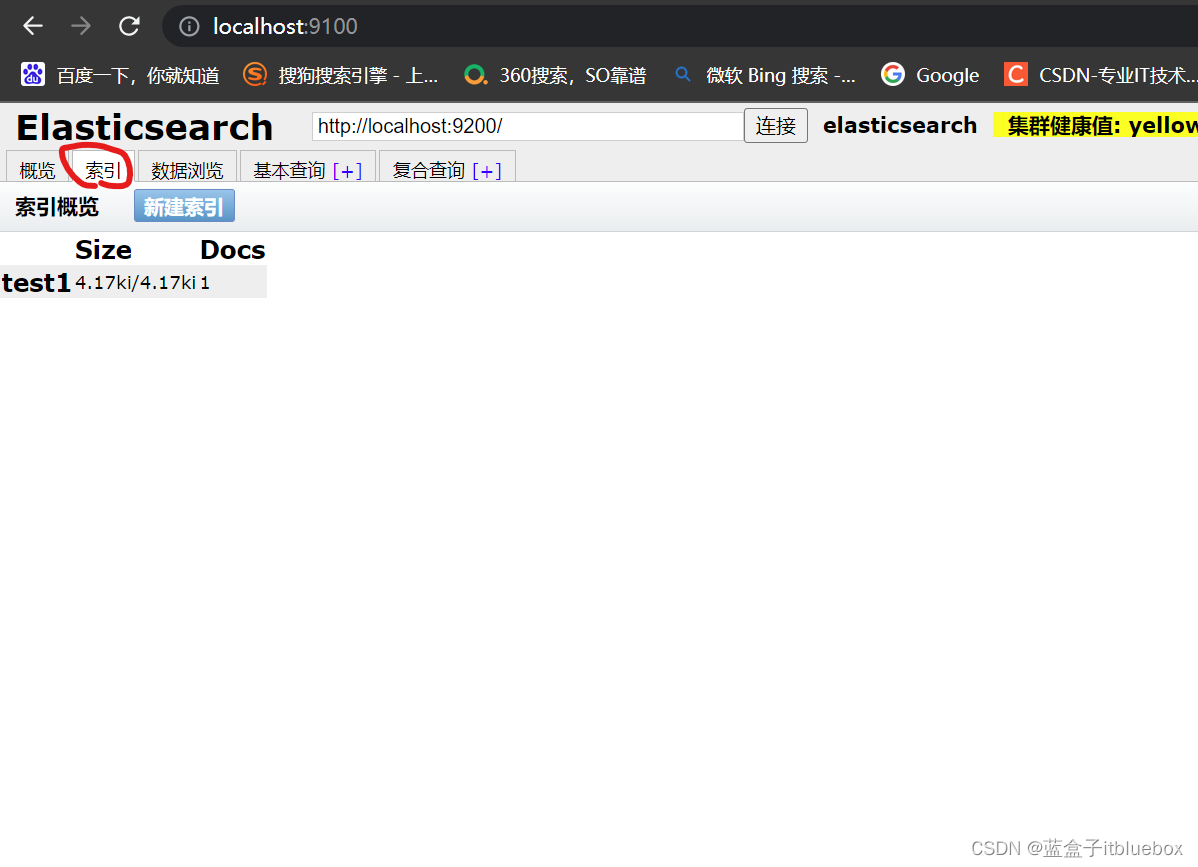
数据浏览
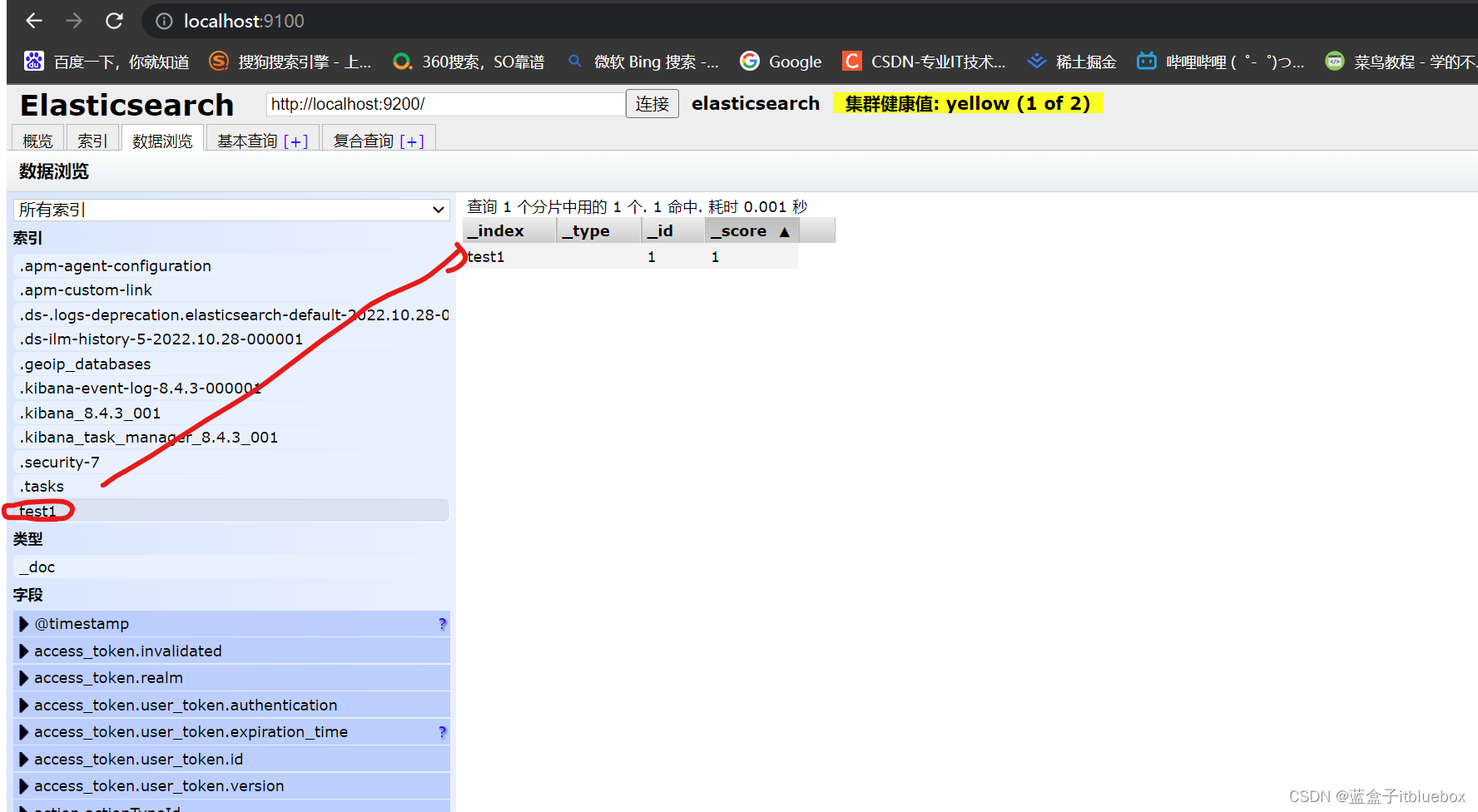
索引创建成功,并成功添加索引
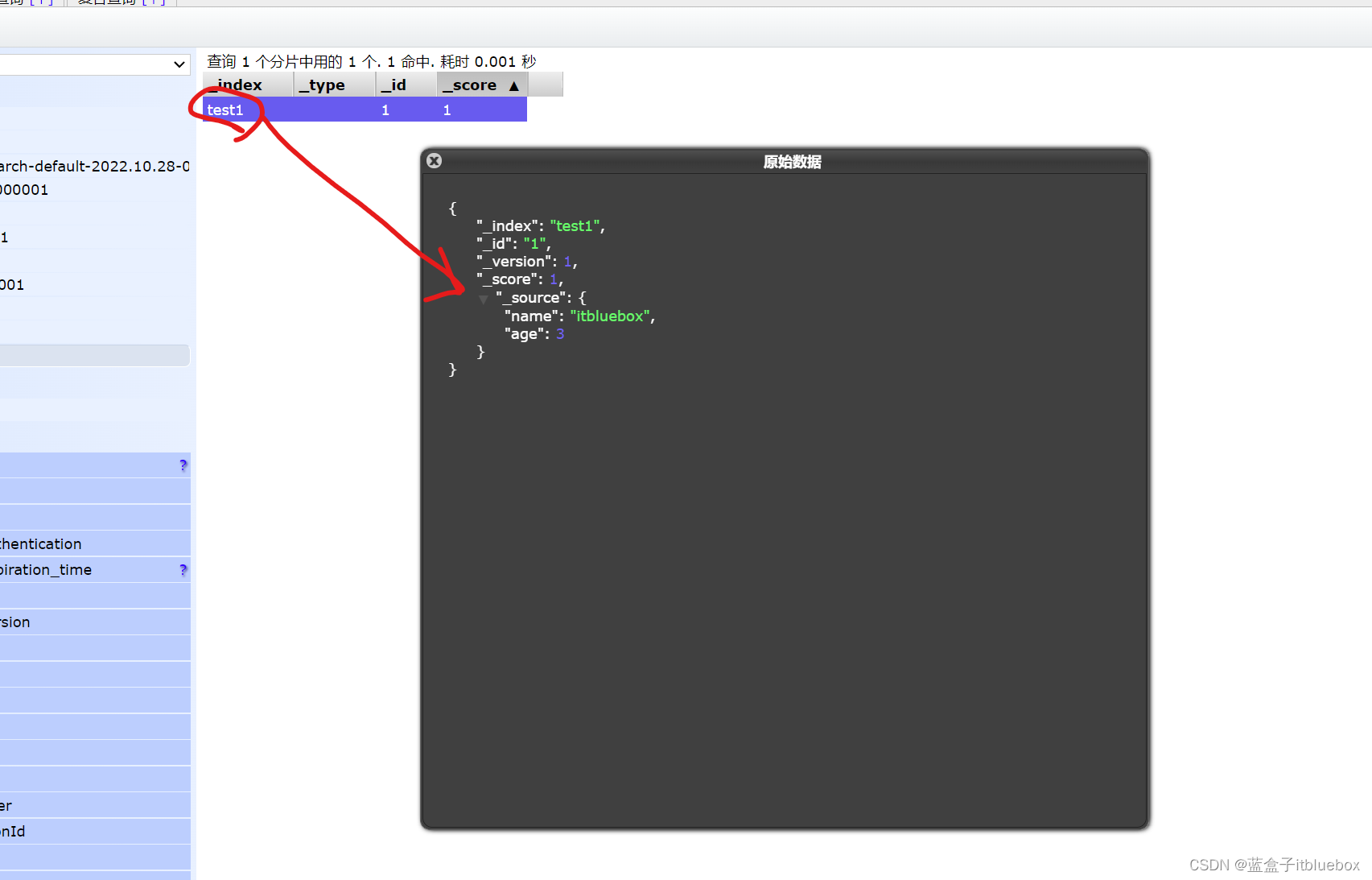
(4)字段类型
那么name这个字段用不用指定类型呢。毕竟我们关系型数据库是需要指定类型的啊!
- 字符串类型
text 、 keyword - 数值类型
long, integer, short, byte, double, float, half float, scaled float - 日期类型
date - te布尔值类型
boolean - 二进制类型
binary
(5)指定字段类型(创建规则,只创建索引不添加数据)
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
在Kibana当中创建对应索引库

test2当做没有数据
3、获取索引信息、其他信息
可以通过GET请求,获取具体的信息
GET test2
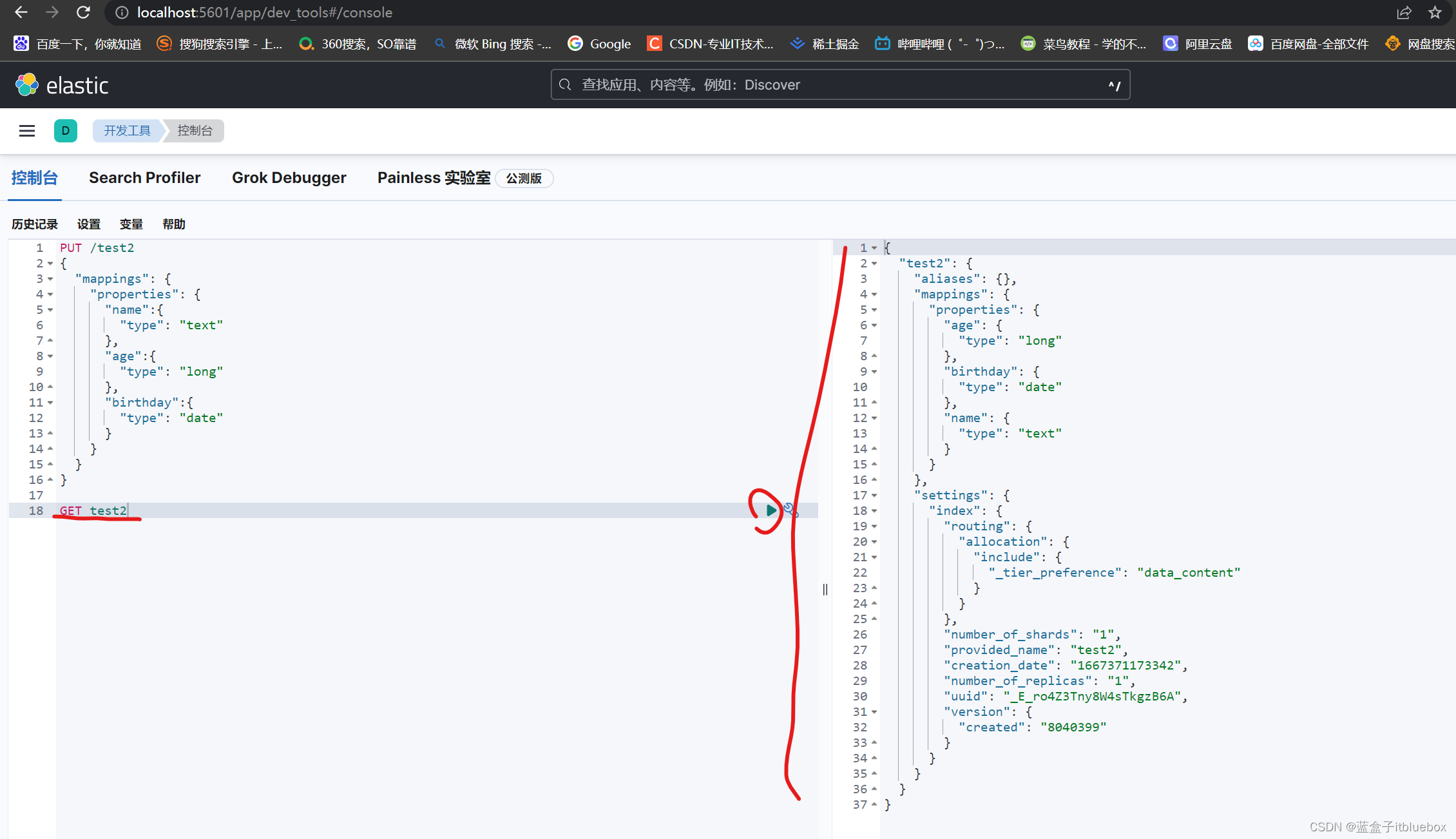
(1)查看默认信息
创建新的索引并添加对应的信息
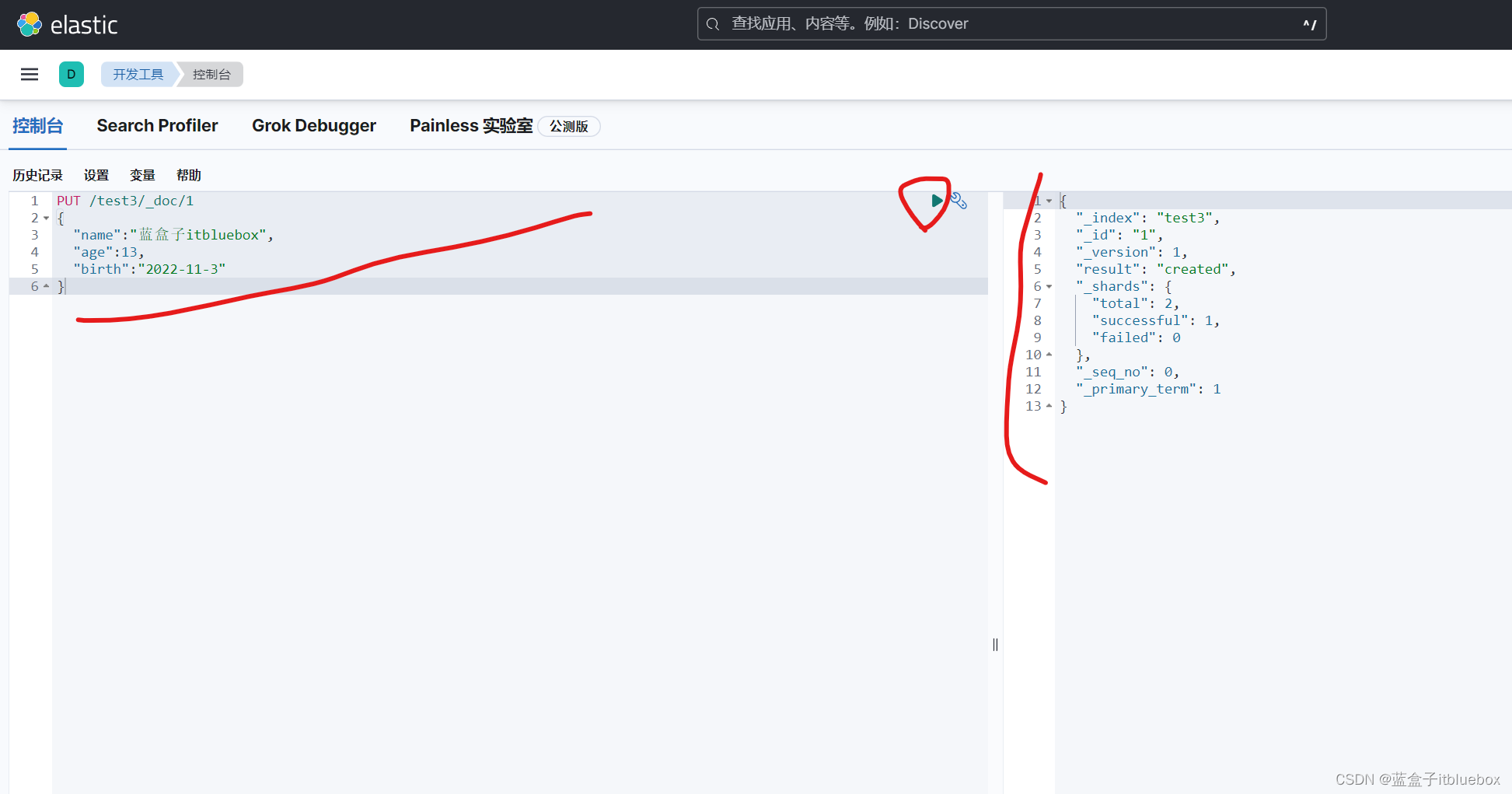
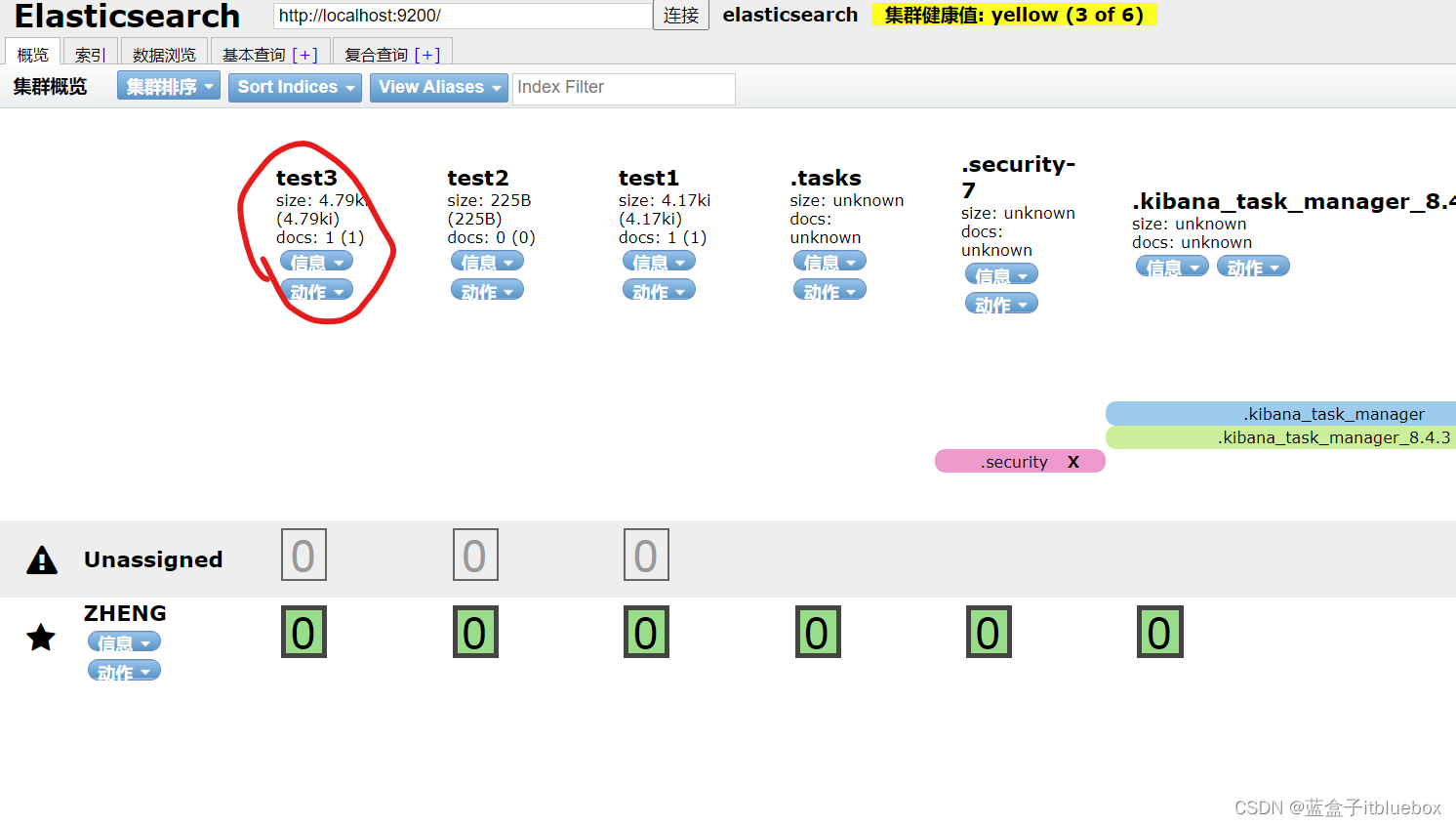
PUT /test3/_doc/1
{
"name":"蓝盒子itbluebox",
"age":13,
"birth":"2022-11-3"
}
在head当中查看
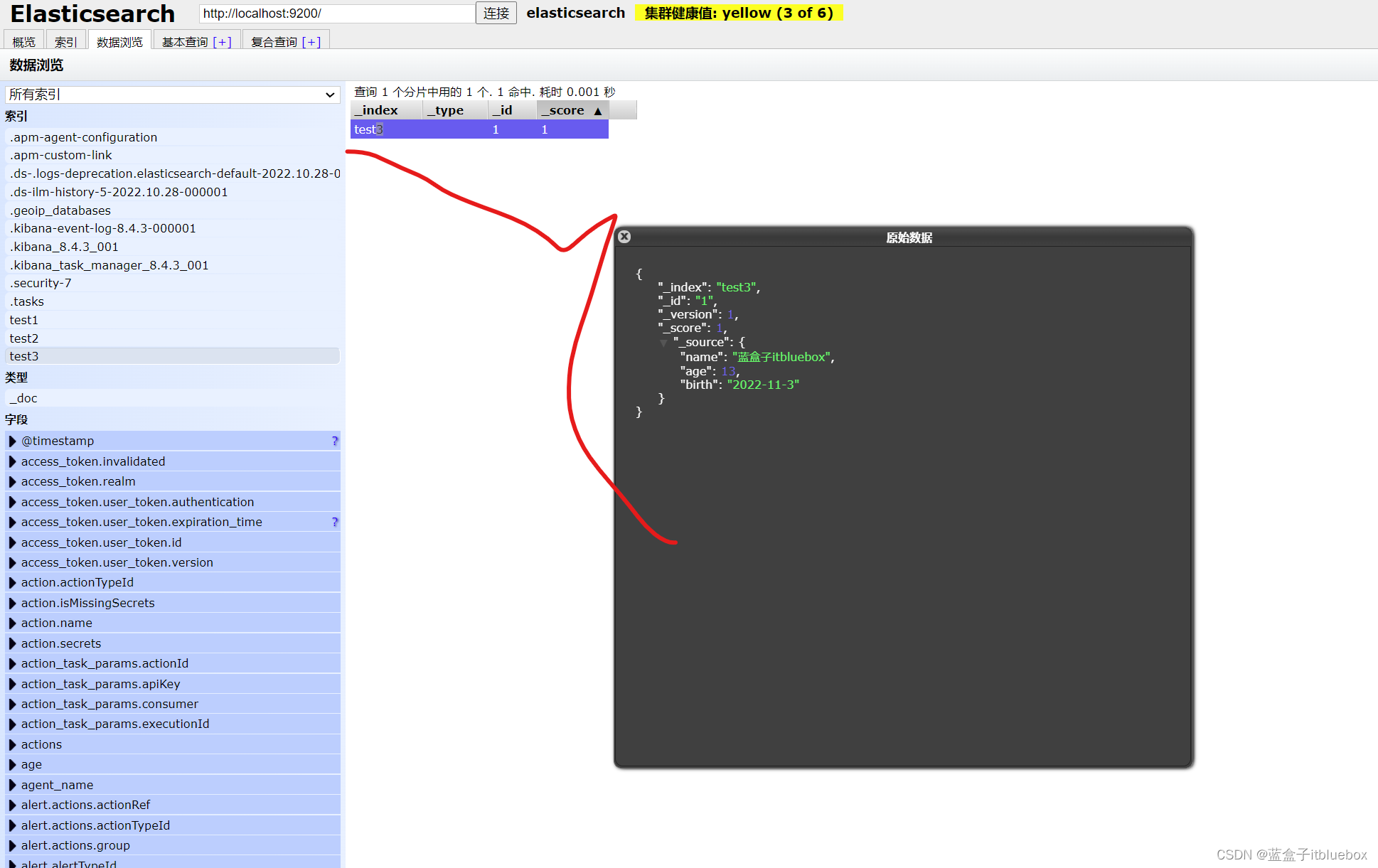
查看默认信息
GET test3
如果在创建创建索引的时候,文档的字典没有指定数据类型,ElasticSearch 帮助默认匹配类型
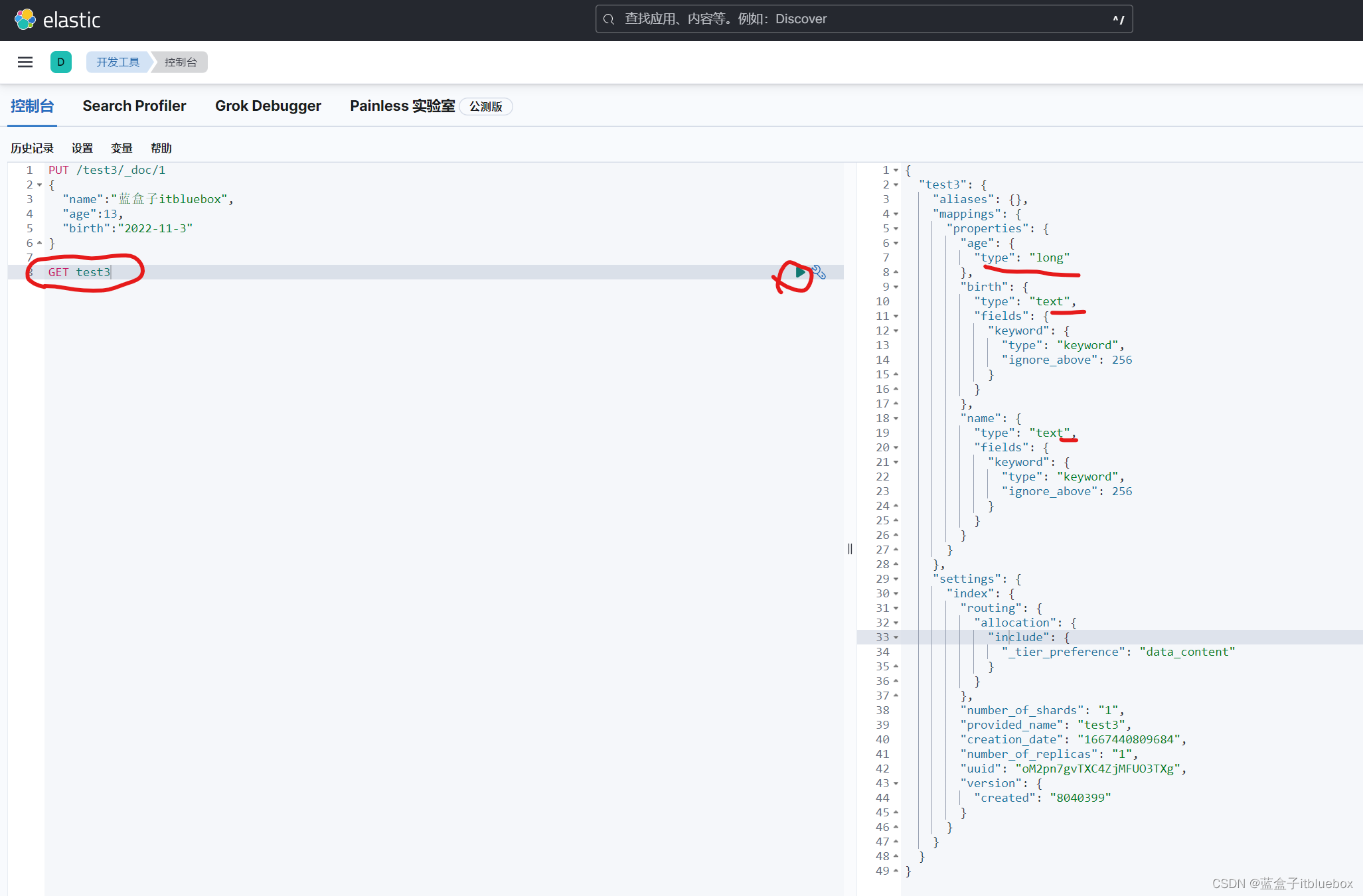
(2)获取一些信息(cat系列命令)
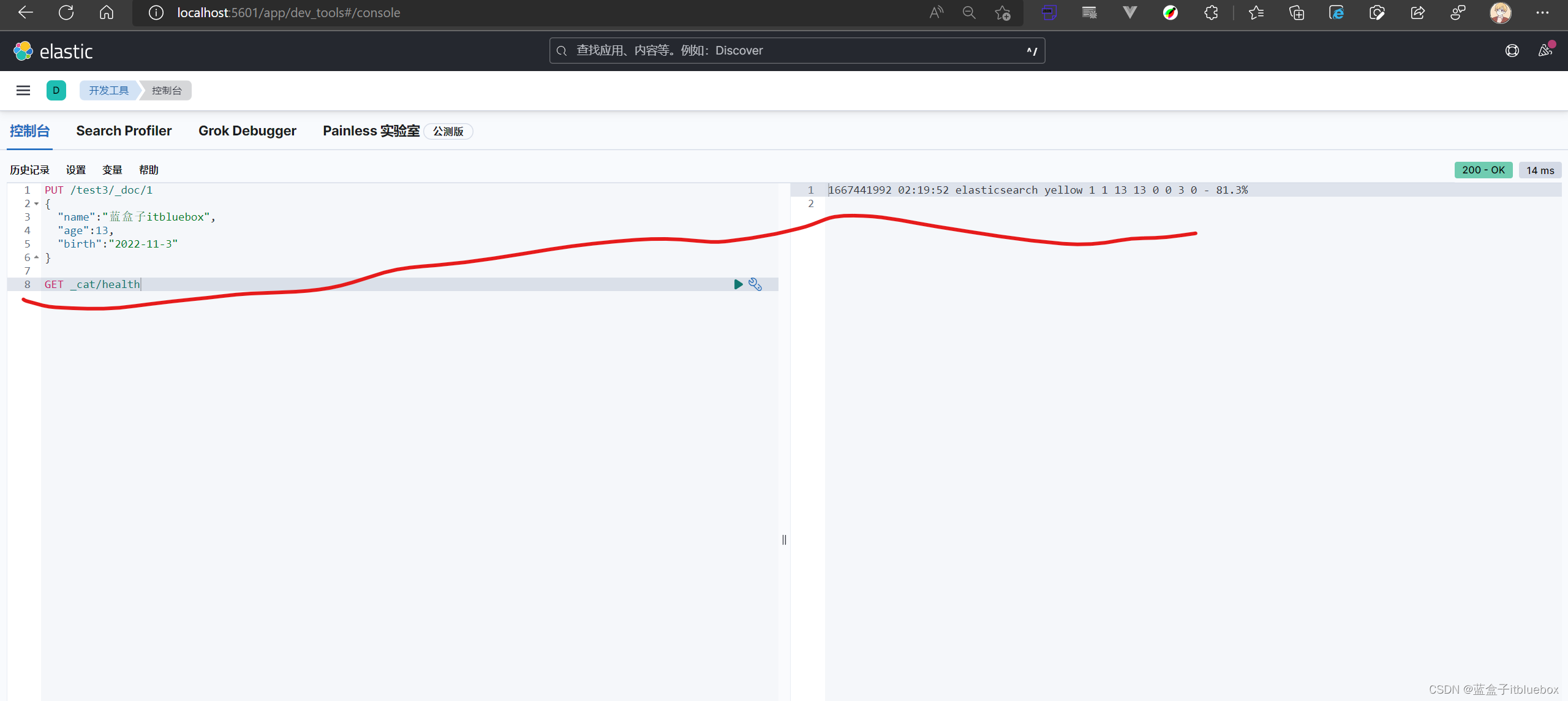
健康值
GET _cat/health
# 获取集群状态
GET _cat/health
# 当使用v参数是 会显示列名的详细信息
GET _cat/health?v
# 这里对照不加help的命令可以显示每一列的信息说明
GET _cat/health?help
# 显示所有的node信息
GET _cat/nodes?v
# 只显示ip和load_5m这两列
GET _cat/nodes?v&h=ip,load_5m
# 显示左右索引并按照存储大小排序
GET _cat/indices?v&s=store.size:desc
# 通过json格式显示输出
GET _cat/indices?v&format=json&pretty
# 列出说有templates,按照order降序,version降序
GET /_cat/templates?v&s=order:desc,version:desc
4、修改索引
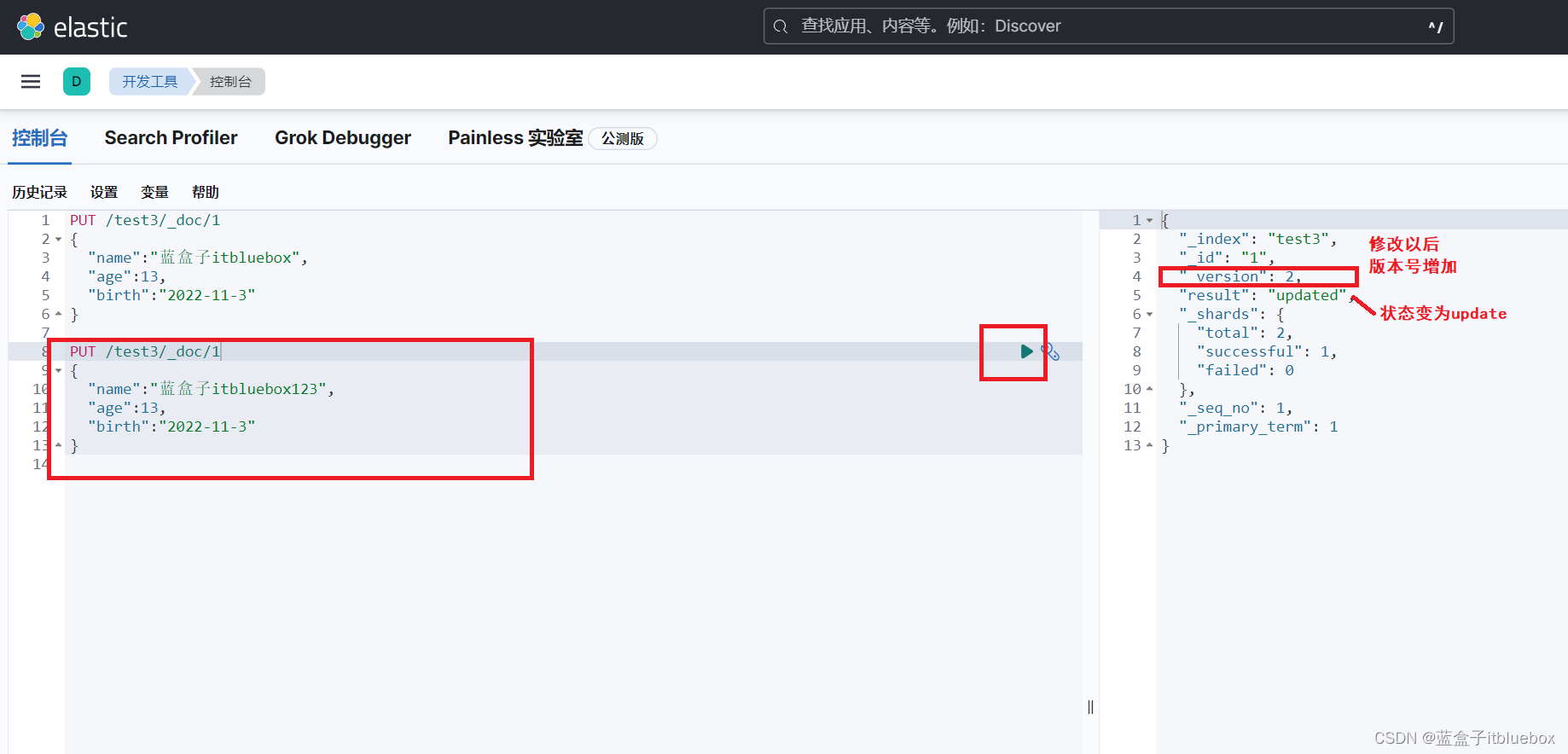
(1)直接PUT覆盖(不推荐)(如果PUT的时候少字段会丢失数据)
PUT /test3/_doc/1
{
"name":"蓝盒子itbluebox123",
"age":13,
"birth":"2022-11-3"
}
PUT之后_version为2版本号增加了,
缺少字段PUT数据
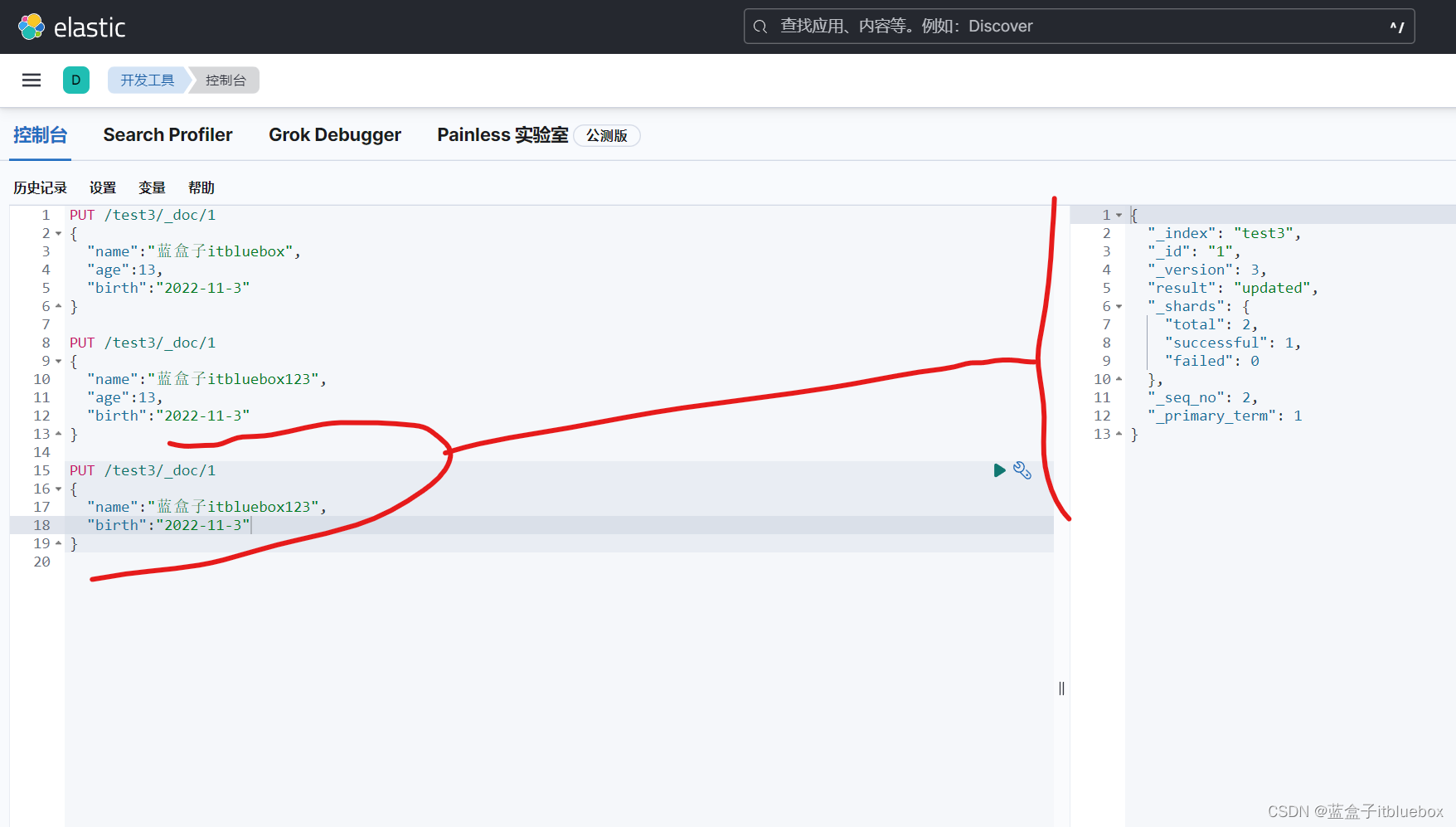
PUT /test3/_doc/1
{
"name":"蓝盒子itbluebox123",
"birth":"2022-11-3"
}
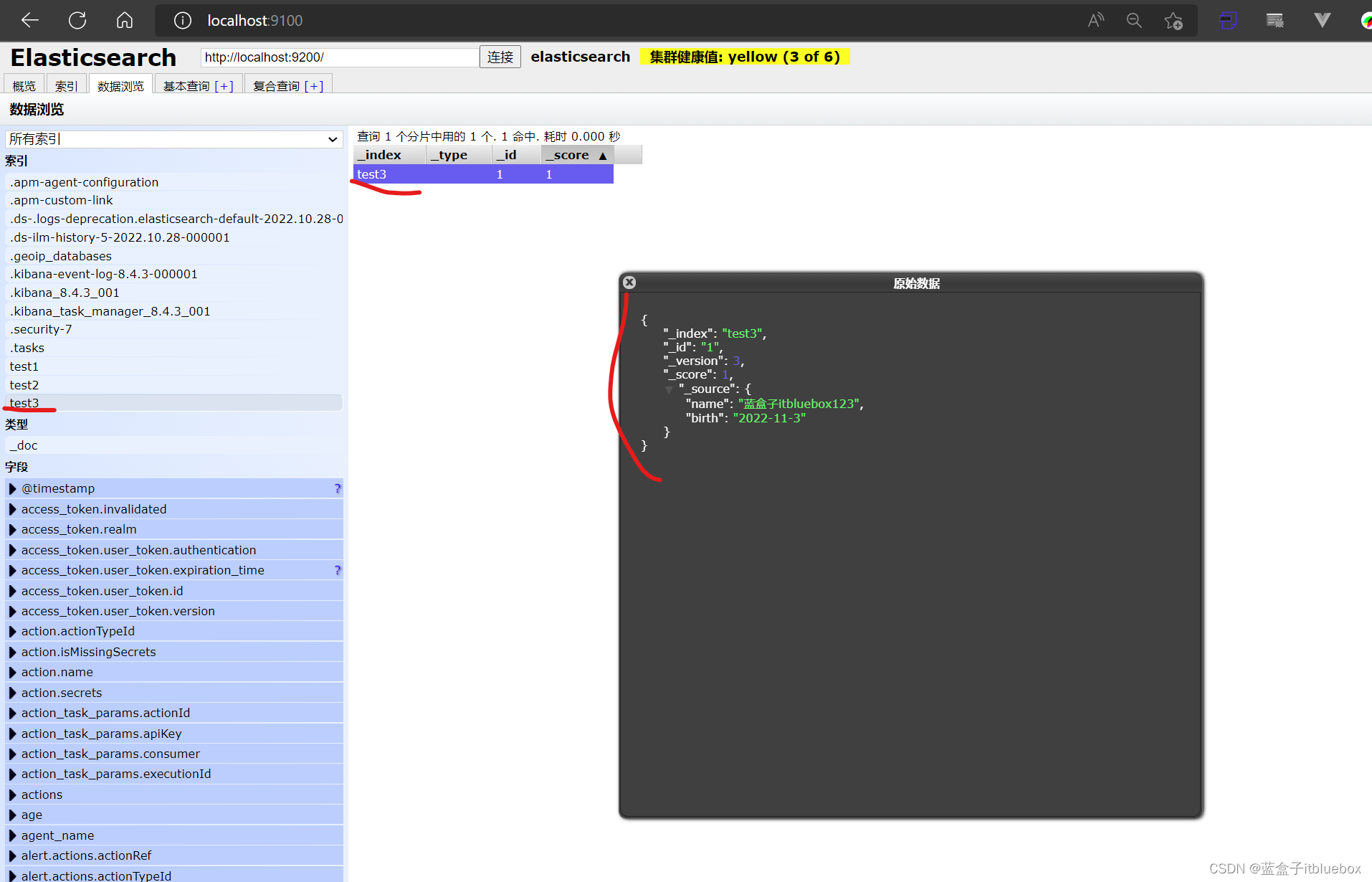
在head当中查看,发现丢失数据,没有了age
(2)通过POST命令更新数据
执行一些PUT先把数据还原
PUT /test3/_doc/1
{
"name":"蓝盒子itbluebox",
"age":13,
"birth":"2022-11-3"
}
POST命令更新数据
POST /test3/_update/1
{
"doc":{
"name":"法外狂徒张三111"
}
}
head当中查看
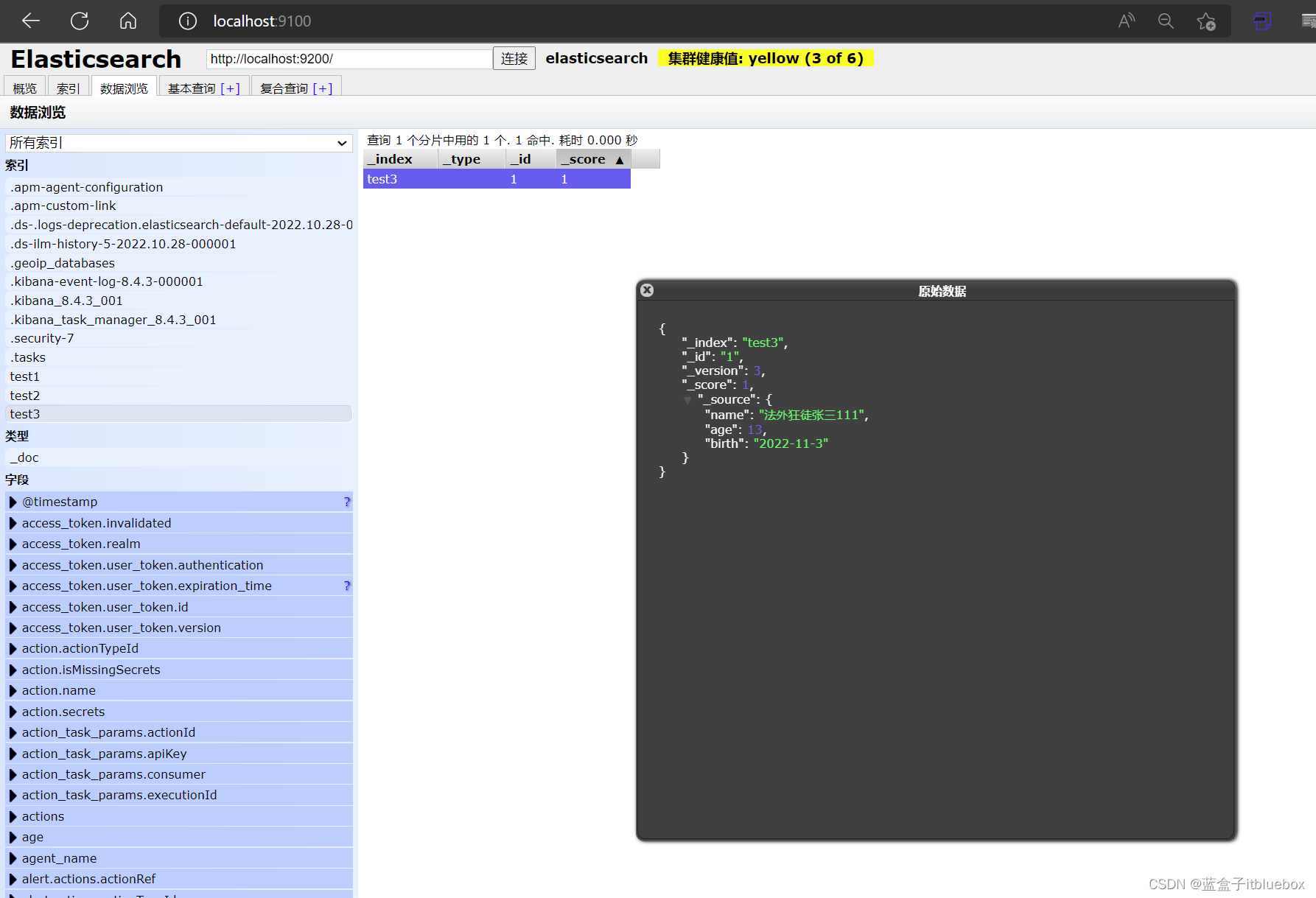
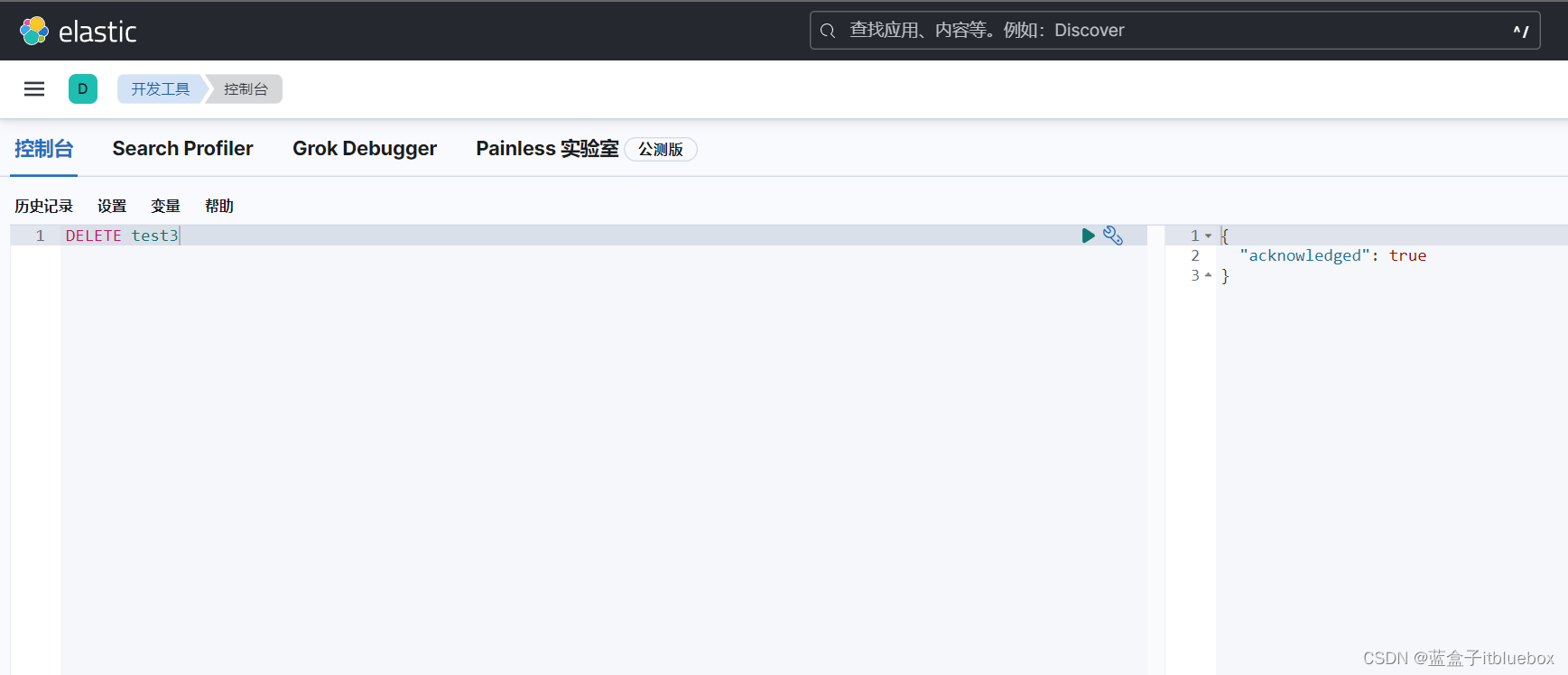
3、删除索引
DELETE test3
删除成功
head当中也没有了
4、删除文档
创建多条数据
PUT /test3/_doc/1
{
"name":"蓝盒子itbluebox111",
"age":13,
"birth":"2022-11-3"
}
PUT /test3/_doc/2
{
"name":"蓝盒子itbluebox222",
"age":13,
"birth":"2022-11-3"
}
PUT /test3/_doc/3
{
"name":"蓝盒子itbluebox333",
"age":13,
"birth":"2022-11-3"
}
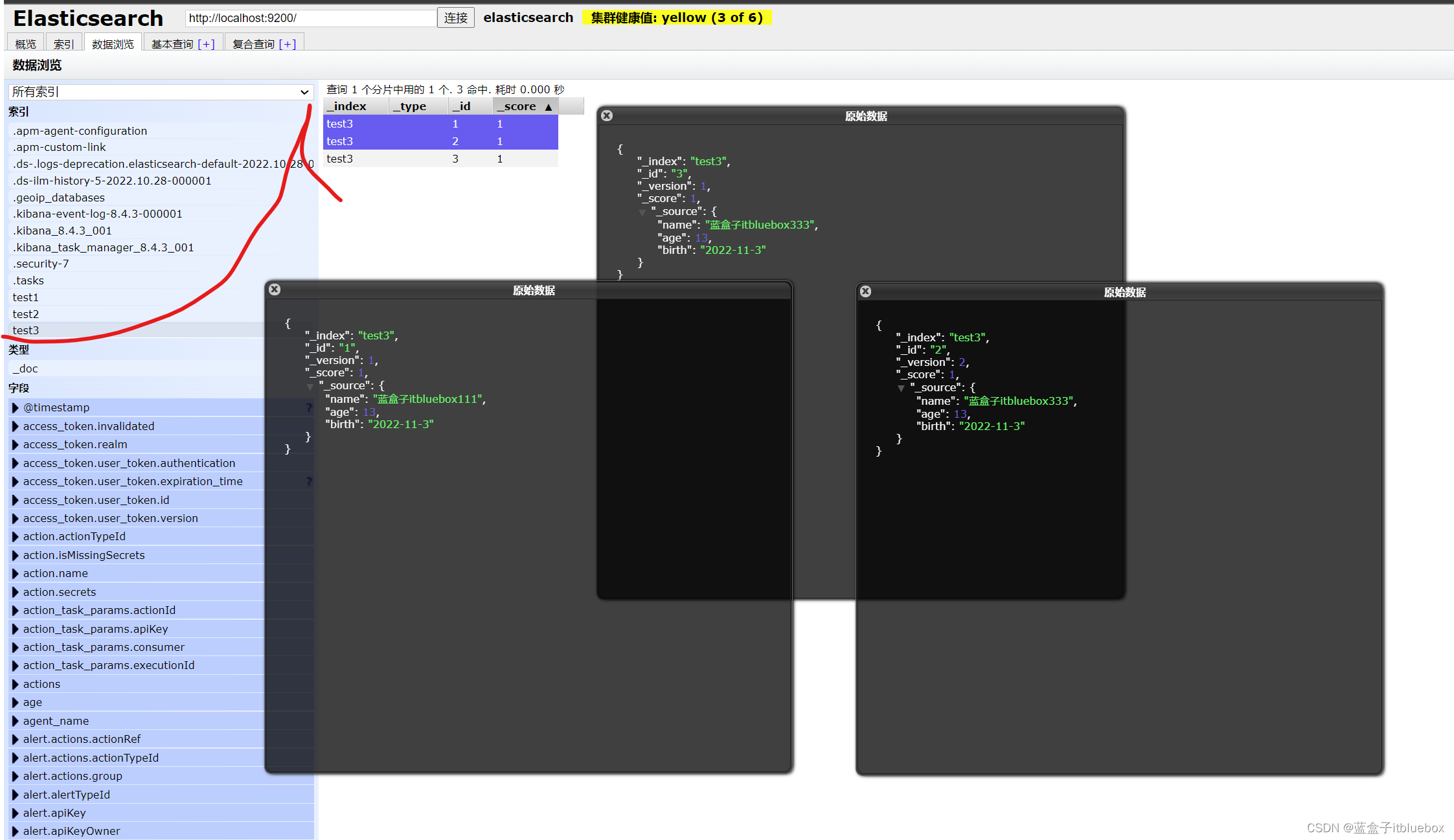
删除id对应的文档
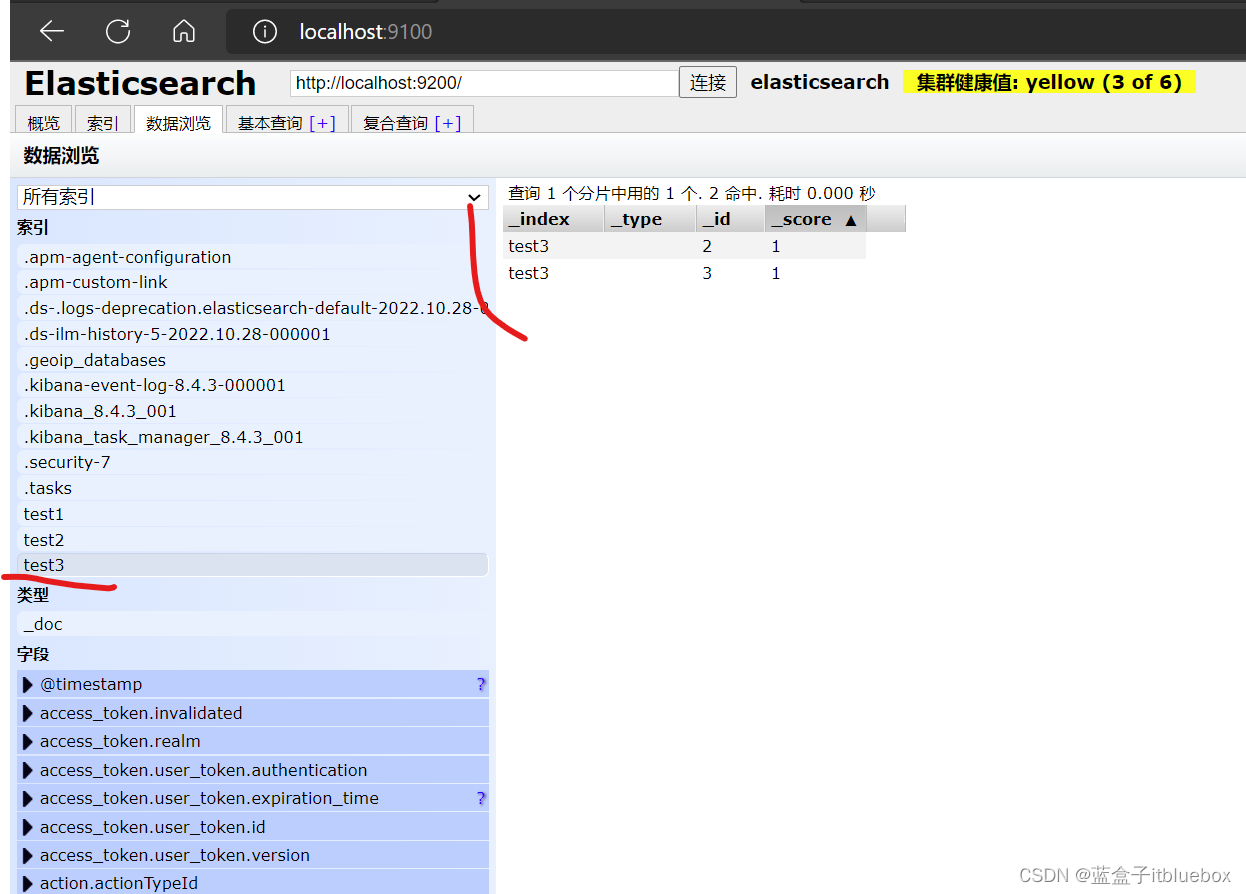
DELETE /test3/_doc/1
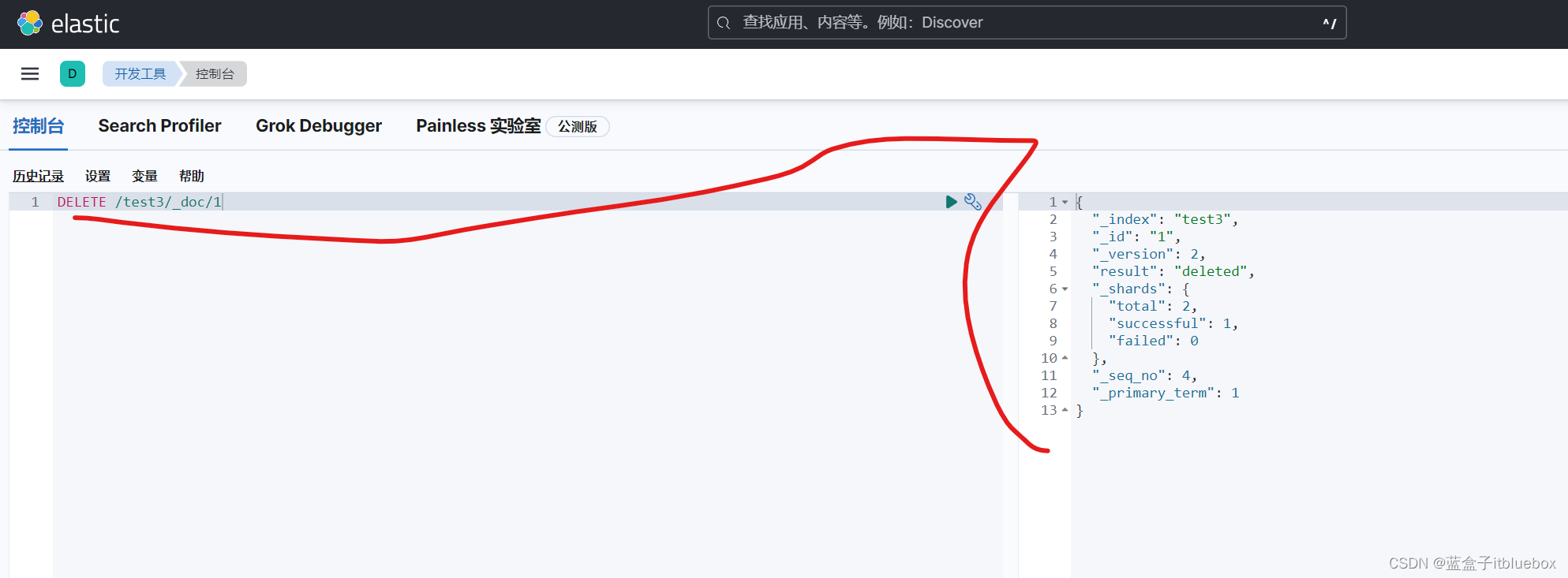
删除成功
四、ElasticSearch 文档的基本操作
基本操作
1、添加数据
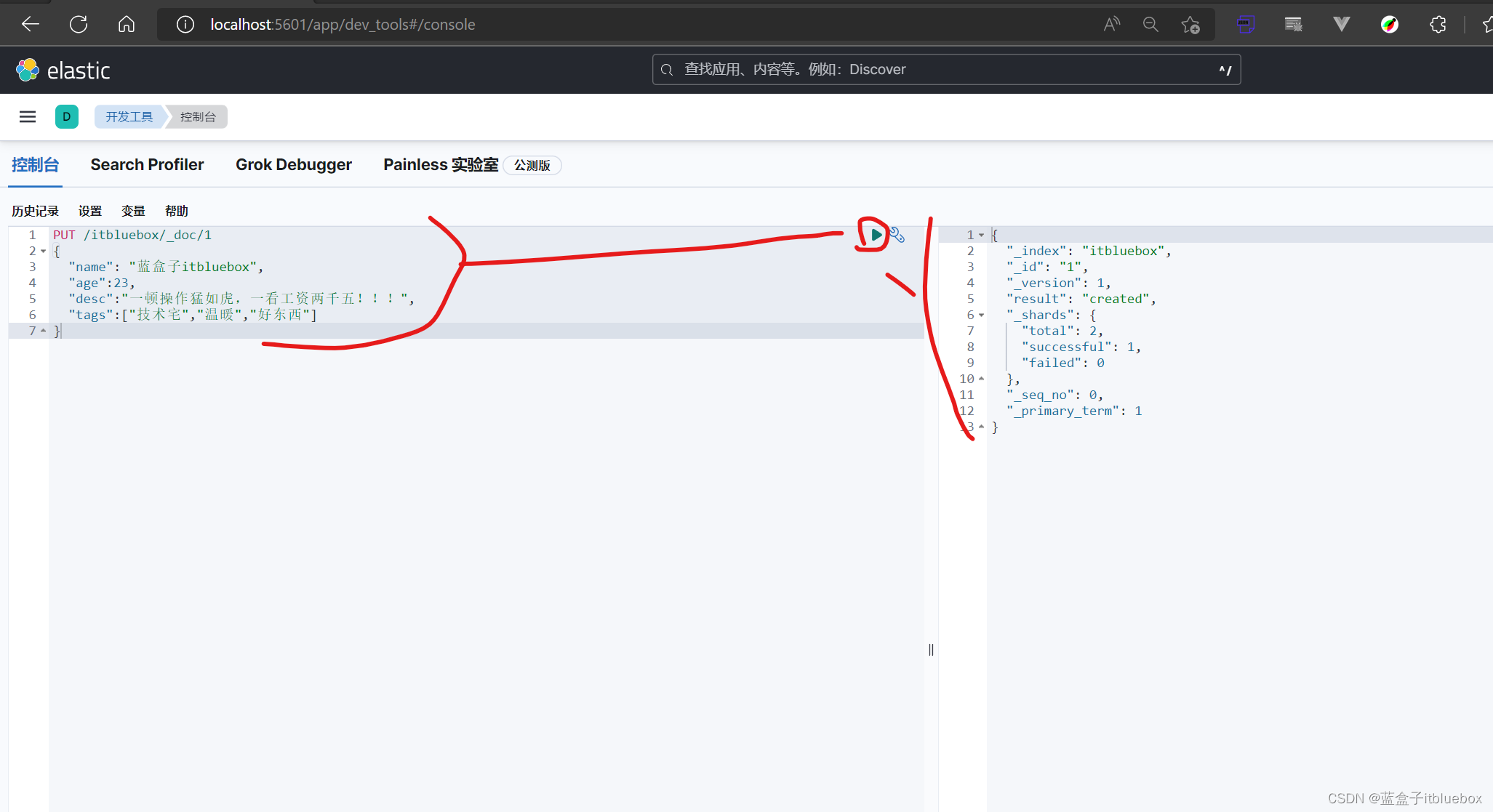
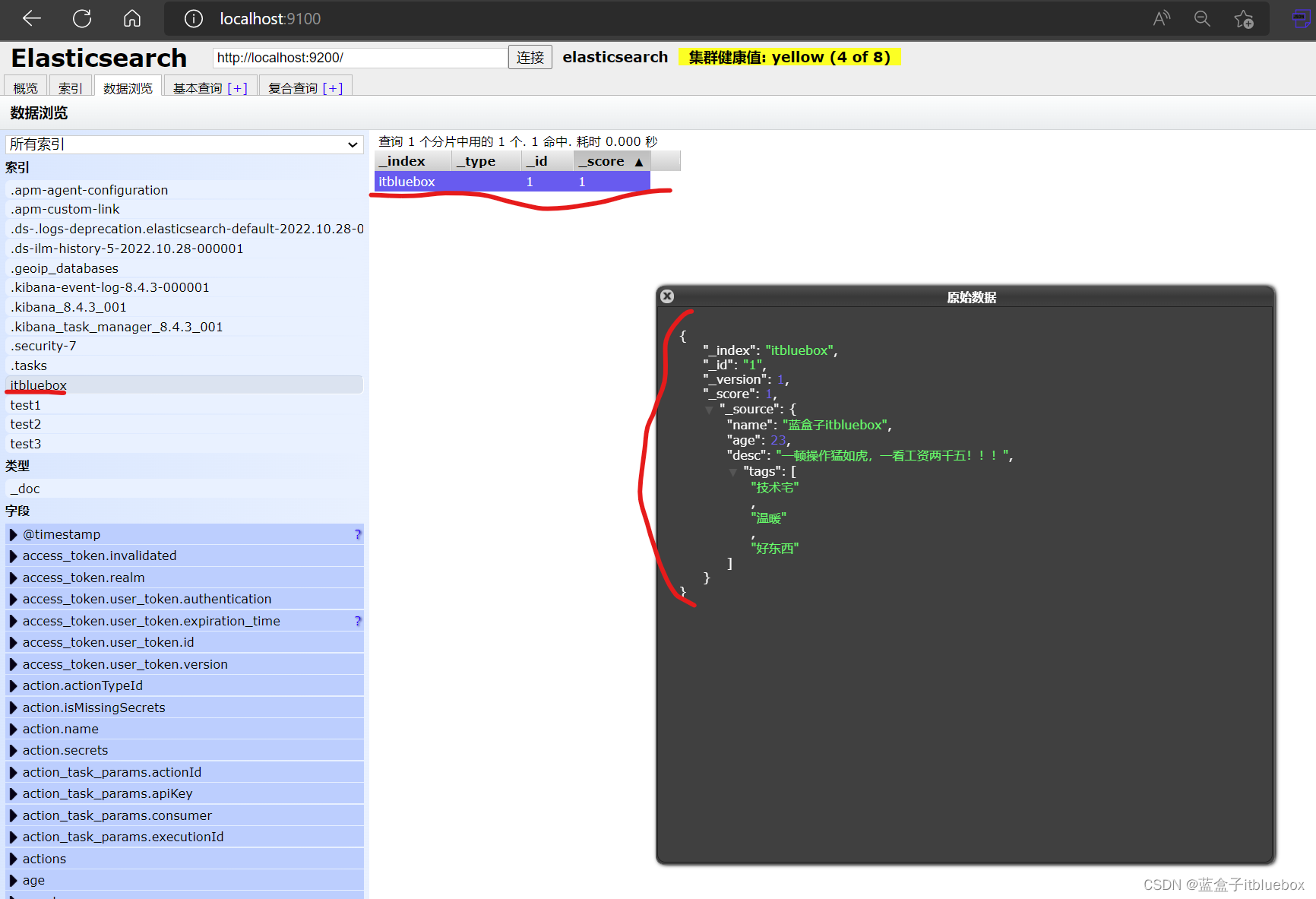
新增加一条数据
PUT /itbluebox/_doc/1
{
"name": "蓝盒子itbluebox",
"age":23,
"desc":"一顿操作猛如虎,一看工资两千五!!!",
"tags":["技术宅","温暖","好东西"]
}
多创建一些用户数据
PUT /itbluebox/_doc/2
{
"name": "张三",
"age":3,
"desc":"法外狂徒",
"tags":["交友","旅游","乒乓球"]
}
PUT /itbluebox/_doc/3
{
"name": "李四",
"age":15,
"desc":"兵乓球、足球、滑旱冰、跑步、跳绳、举重等",
"tags":["听音乐","看电影","绘画"]
}
PUT /itbluebox/_doc/4
{
"name": "王五",
"age":19,
"desc":"做弹弓玩、做木剑玩、做橡皮枪玩",
"tags":["滑板","羽毛球","喜欢篮球"]
}
2、查询数据 GET
(1)获取索引信息
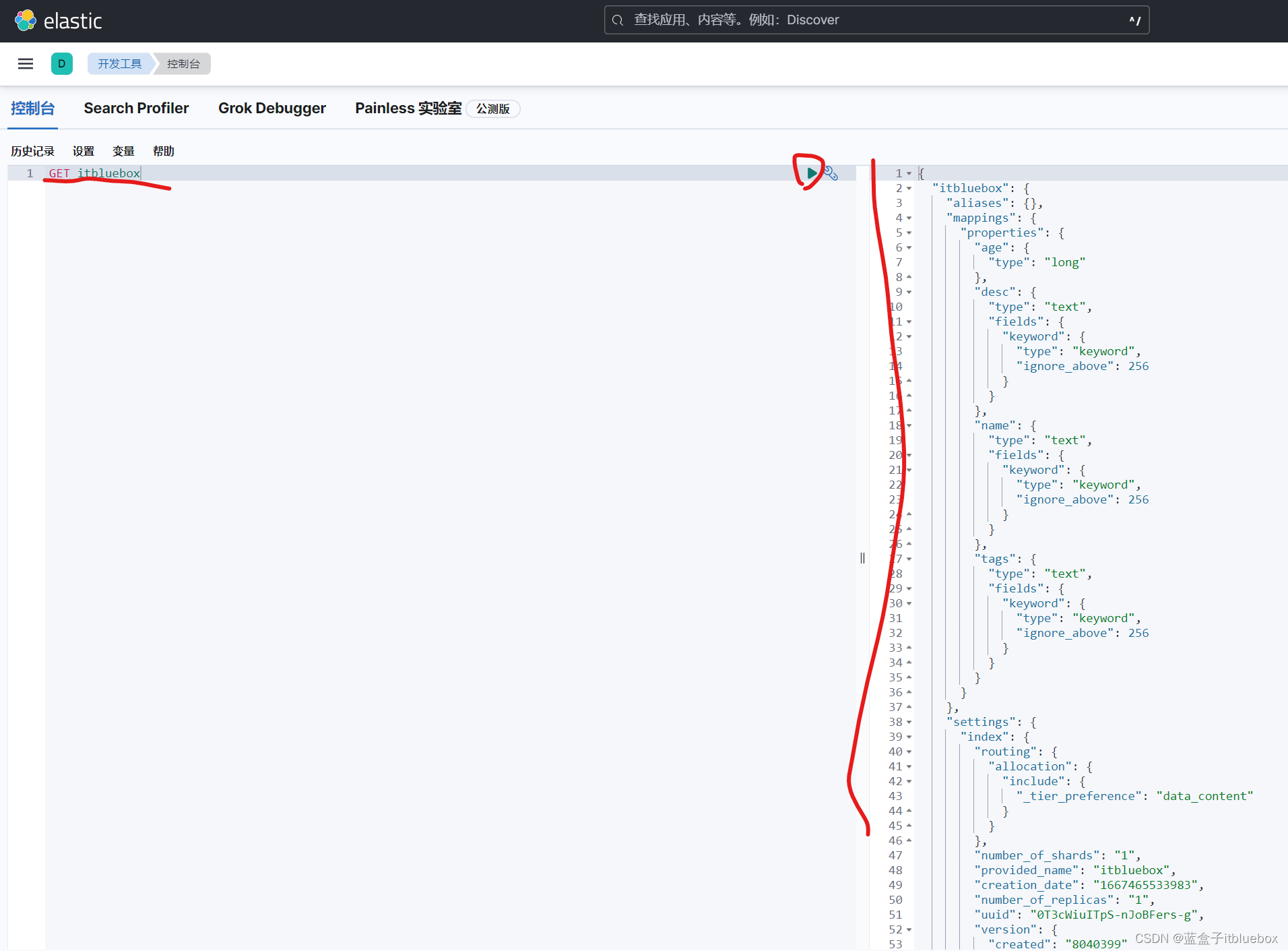
GET itbluebox
(2)查询所有文档数据
GET itbluebox/_search
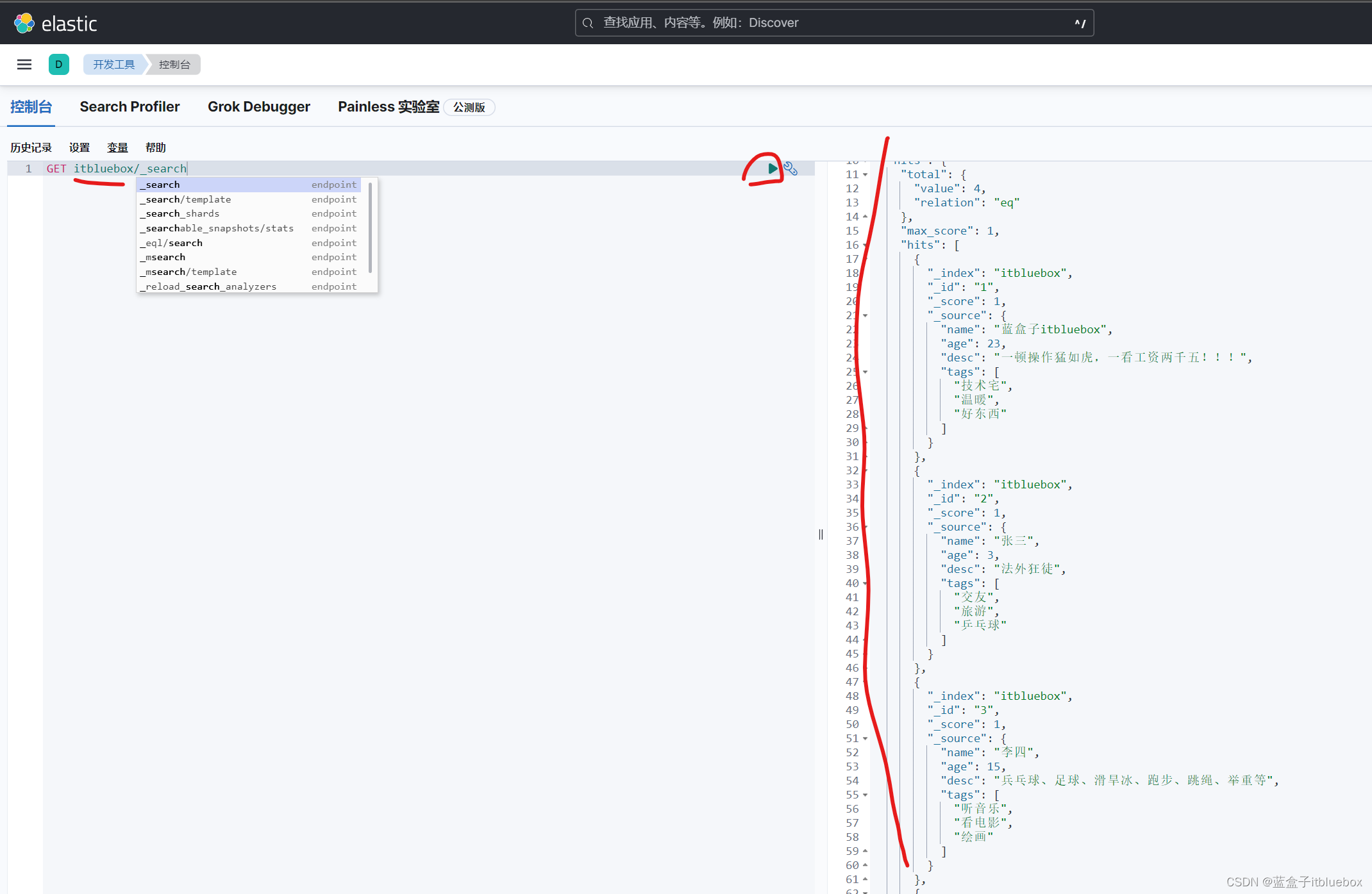
返回值:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "itbluebox",
"_id": "1",
"_score": 1,
"_source": {
"name": "蓝盒子itbluebox",
"age": 23,
"desc": "一顿操作猛如虎,一看工资两千五!!!",
"tags": [
"技术宅",
"温暖",
"好东西"
]
}
},
{
"_index": "itbluebox",
"_id": "2",
"_score": 1,
"_source": {
"name": "张三",
"age": 3,
"desc": "法外狂徒",
"tags": [
"交友",
"旅游",
"乒乓球"
]
}
},
{
"_index": "itbluebox",
"_id": "3",
"_score": 1,
"_source": {
"name": "李四",
"age": 15,
"desc": "兵乓球、足球、滑旱冰、跑步、跳绳、举重等",
"tags": [
"听音乐",
"看电影",
"绘画"
]
}
},
{
"_index": "itbluebox",
"_id": "4",
"_score": 1,
"_source": {
"name": "王五",
"age": 19,
"desc": "做弹弓玩、做木剑玩、做橡皮枪玩",
"tags": [
"滑板",
"羽毛球",
"喜欢篮球"
]
}
}
]
}
}
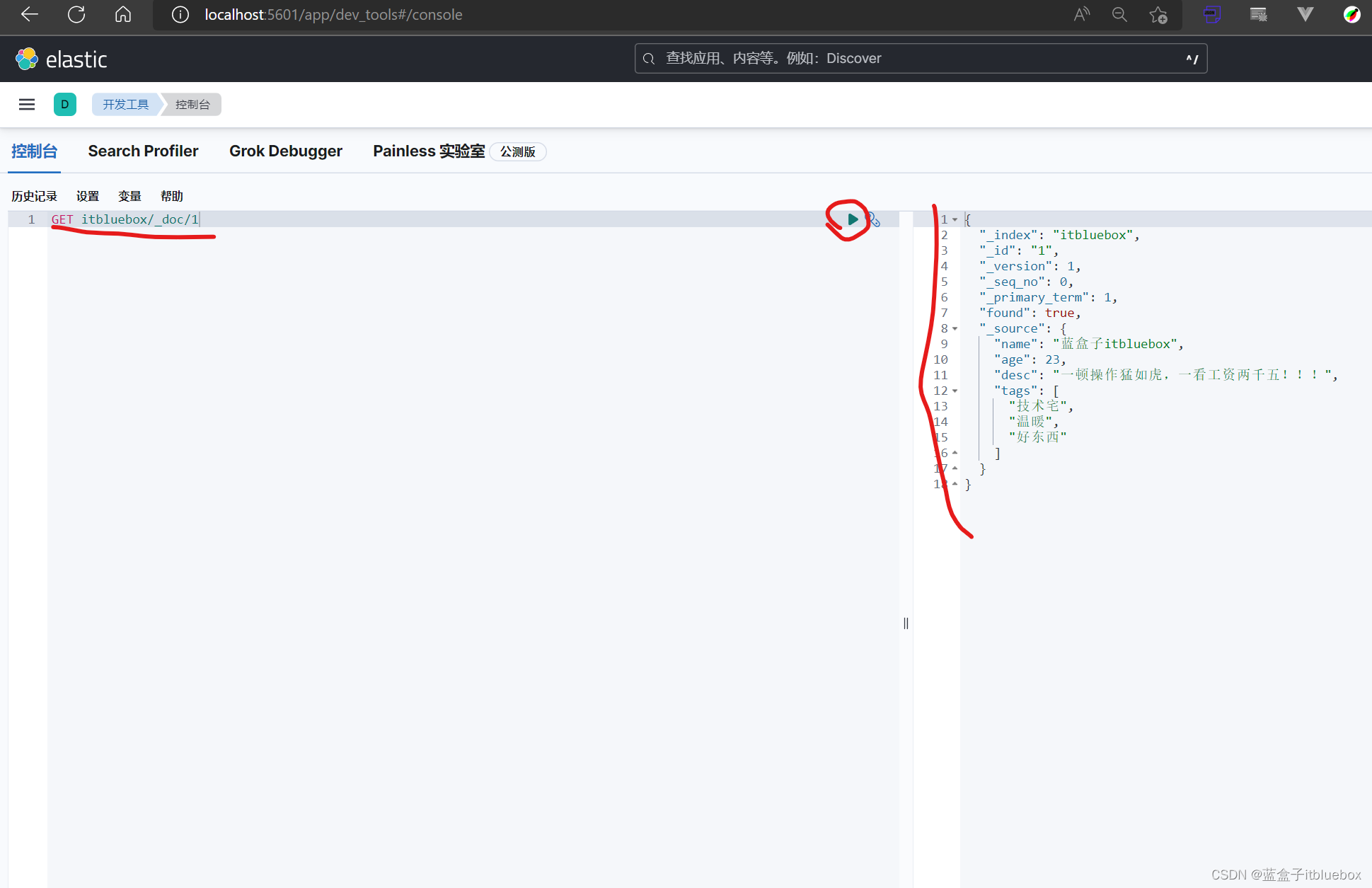
(3)查询一条数据
GET itbluebox/_doc/1
{
"_index": "itbluebox",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "蓝盒子itbluebox",
"age": 23,
"desc": "一顿操作猛如虎,一看工资两千五!!!",
"tags": [
"技术宅",
"温暖",
"好东西"
]
}
}
3、更新数据
PUT【注意如果PUT不传递值,那么值就会被覆盖】
PUT /itbluebox/_doc/1
{
"name": "蓝盒子",
"age":23,
"desc":"一顿操作猛如虎,一看工资两千五!!!",
"tags":["技术宅","温暖","好东西"]
}
更新成功
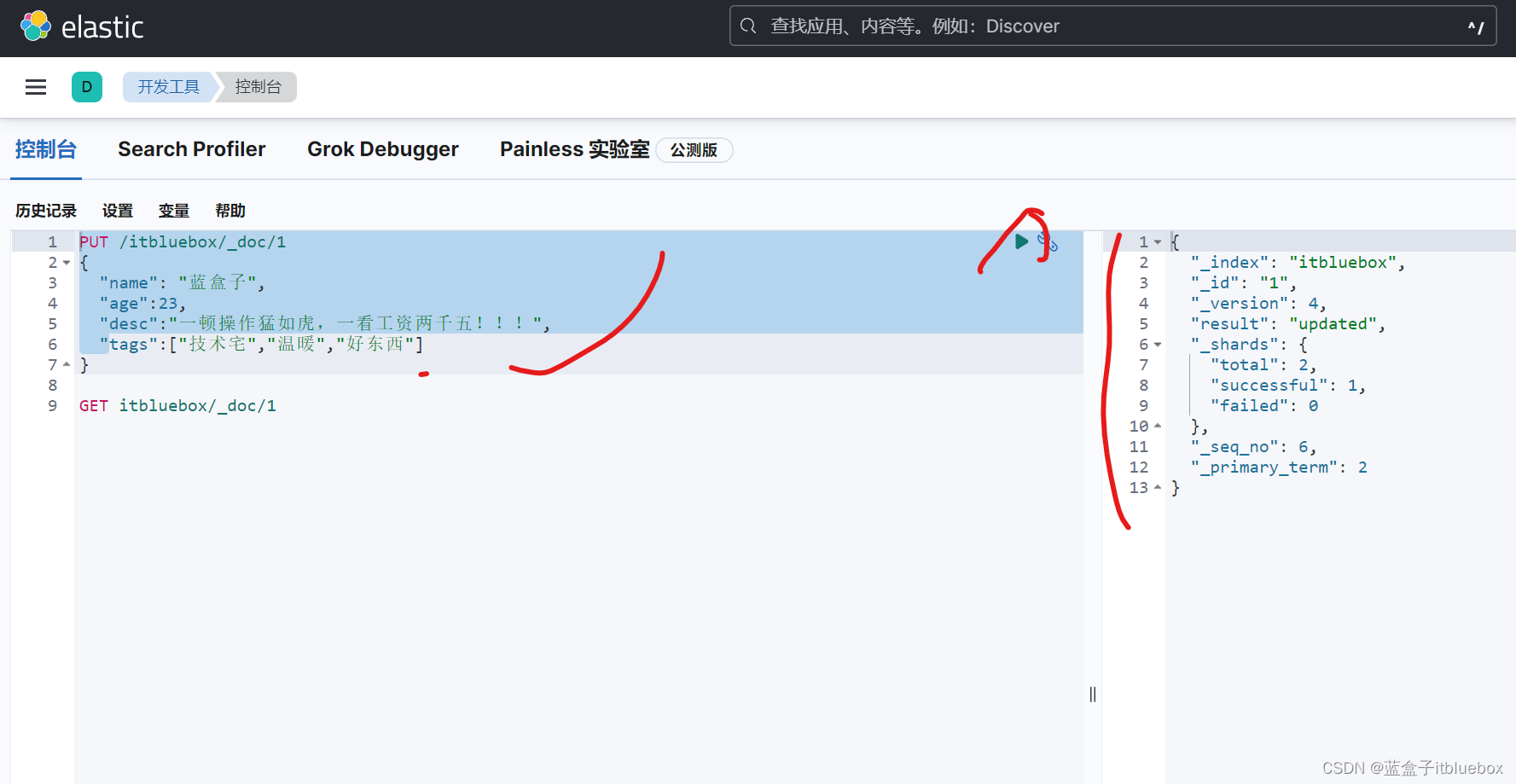
查询一下
GET itbluebox/_doc/1
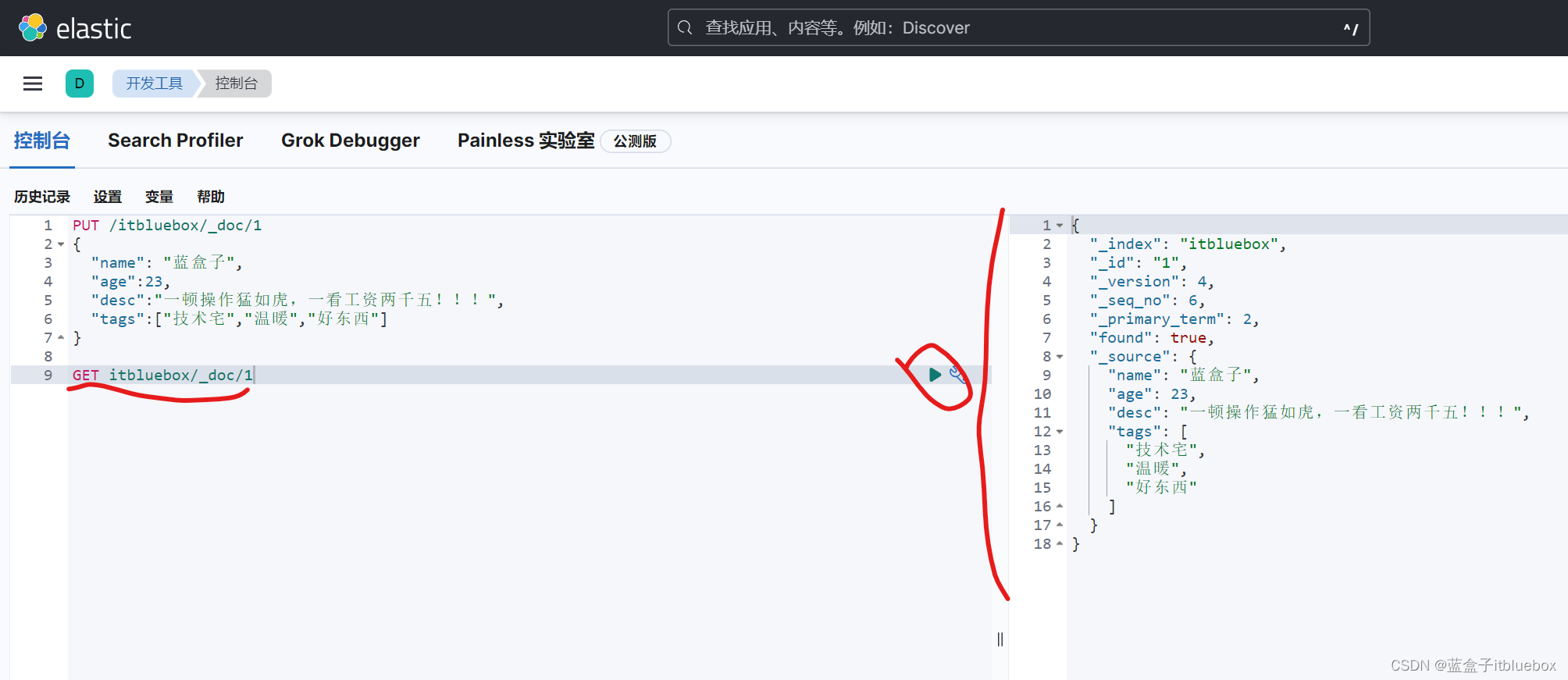
POST【灵活性更高】
POST /itbluebox/_doc/1
{
"name": "疯狂的蓝盒子"
}

4、简单搜索
(1)通过id查询
GET itbluebox/_doc/1
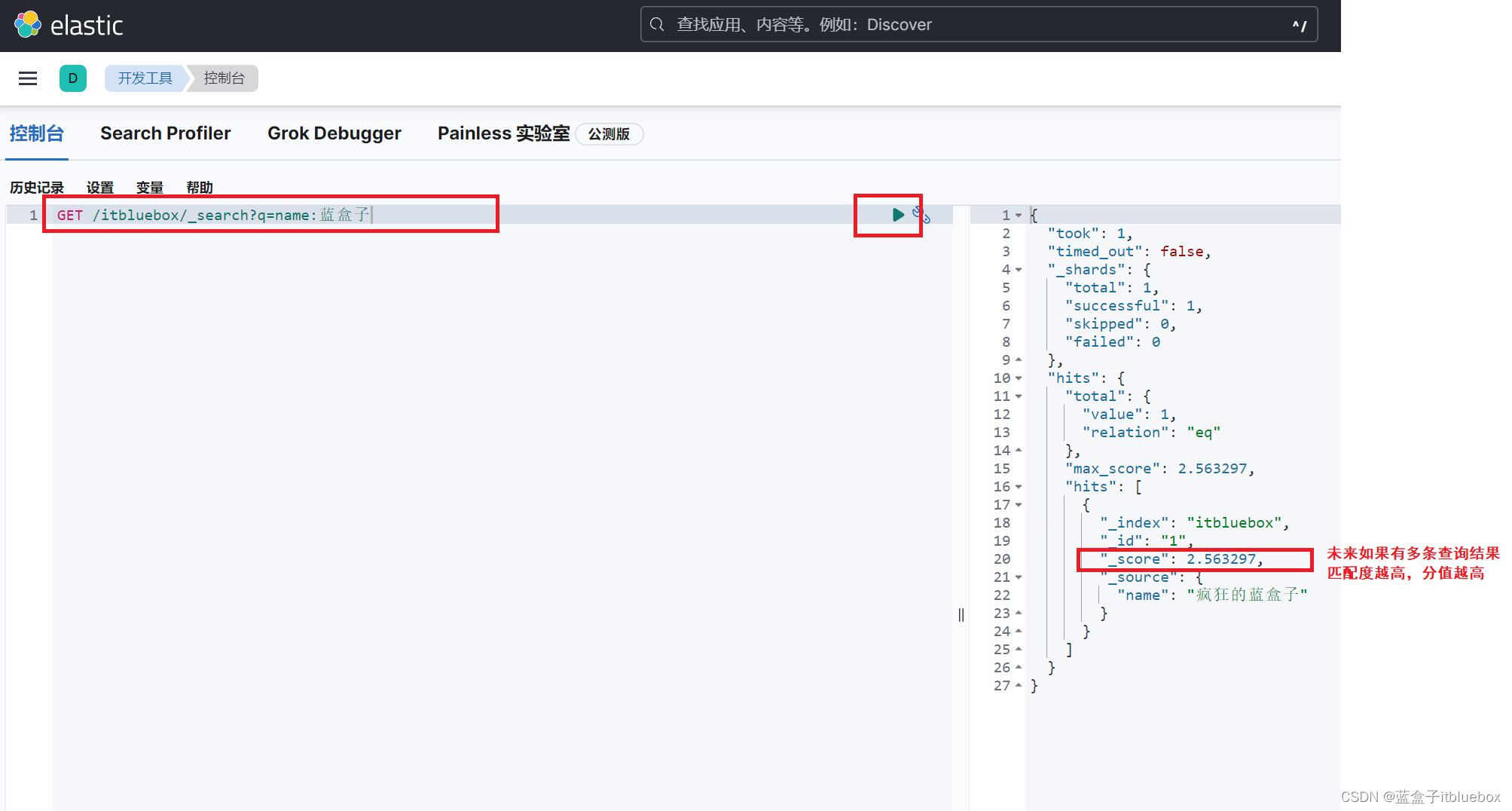
(2)简单的条件查询
GET /itbluebox/_search?q=name:蓝盒子
简单的条件查询,可以根据默认的映射规则,产生基本的查询
5、复杂搜索
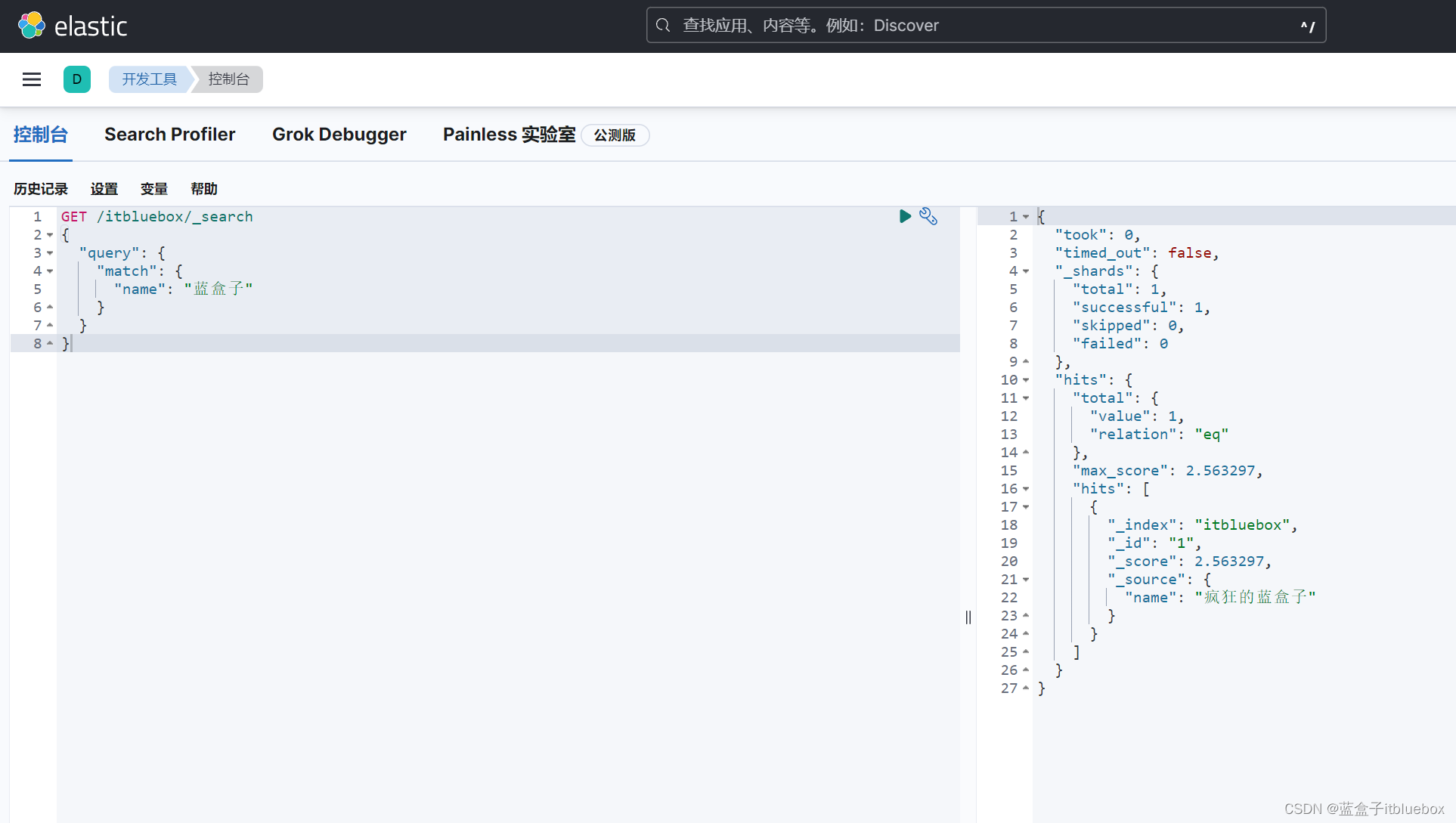
(1)直接匹配查询,match:匹配
GET /itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
}
}
查询的参数体,使用JSON构建
为了后续查询方便我们多添加几条数据
PUT /itbluebox/_doc/4
{
"name": "蓝盒子后端",
"age":23,
"desc":"一顿操作猛如虎,一看工资两千五!!!",
"tags":["技术宅","温暖","好东西"]
}
PUT /itbluebox/_doc/5
{
"name": "蓝盒子前端",
"age":23,
"desc":"一顿操作猛如虎,一看工资两千五!!!",
"tags":["技术宅","温暖","好东西"]
}
PUT /itbluebox/_doc/6
{
"name": "蓝盒子后端",
"age":13,
"desc":"一顿操作猛如虎,一看工资两千五!!!",
"tags":["技术宅","温暖","好东西"]
}
PUT /itbluebox/_doc/7
{
"name": "蓝盒子Java",
"age":3,
"desc":"一顿操作猛如虎,一看工资两千五!!!",
"tags":["技术宅","温暖","好东西"]
}
PUT /itbluebox/_doc/7
{
"name": "蓝盒子Python",
"age":5,
"desc":"一顿操作猛如虎,一看工资两千五!!!",
"tags":["技术宅","温暖","好东西"]
}
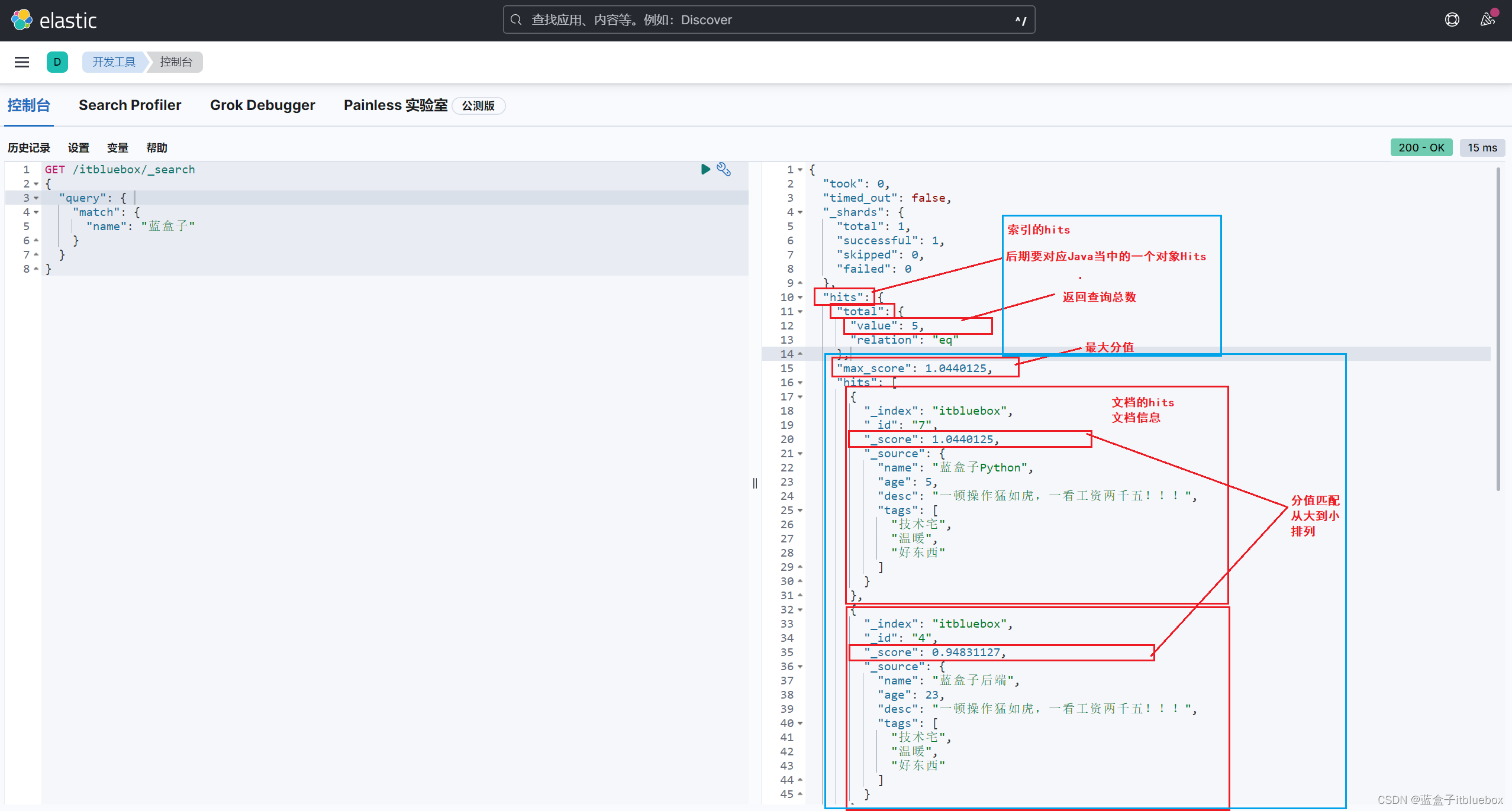
再次查询
GET /itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
}
}
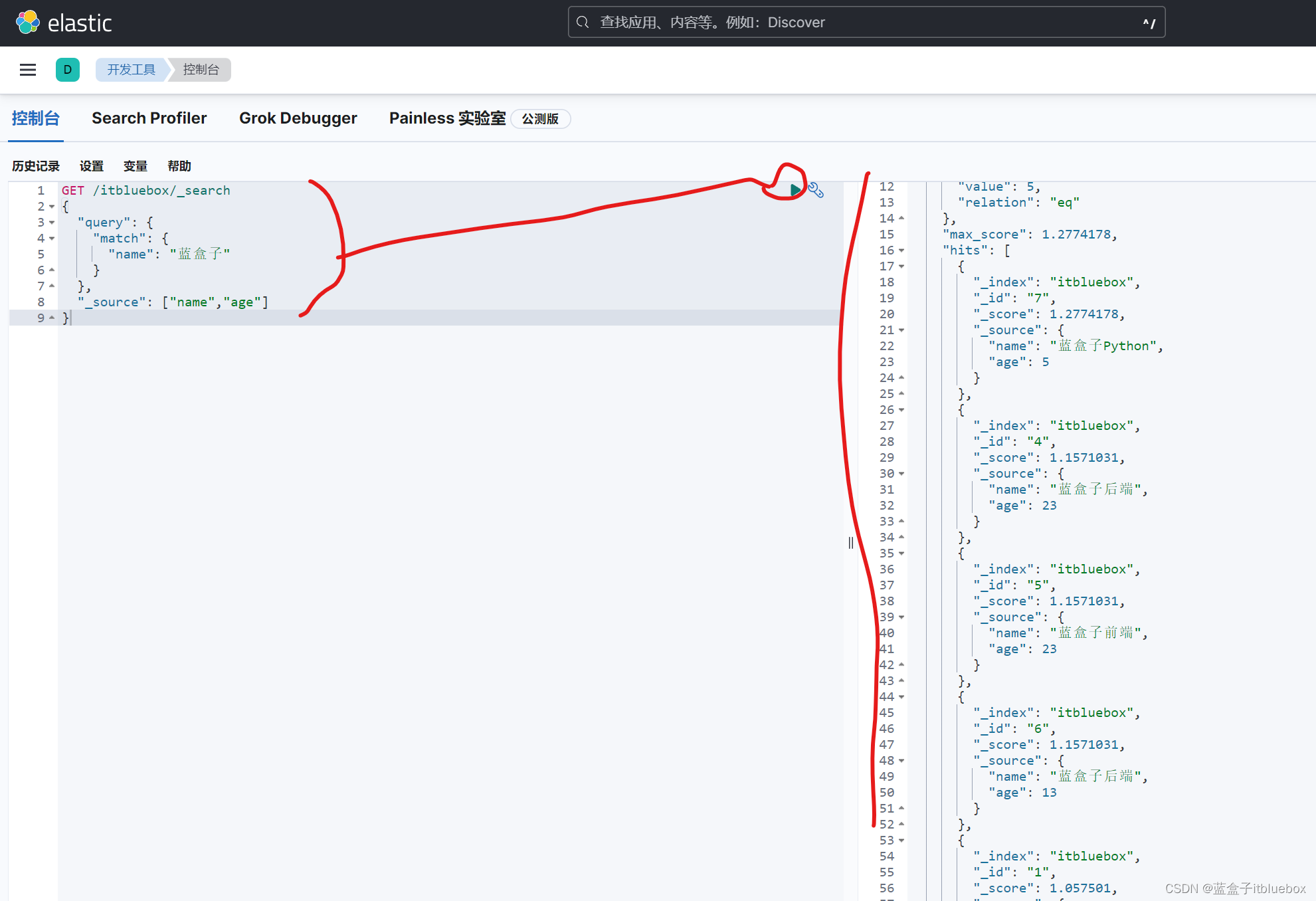
(2)_source过滤查询返回字段
设置只显示name和age
GET /itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
},
"_source": ["name","age"]
}
"_source": ["name","age"] 为结果的过滤
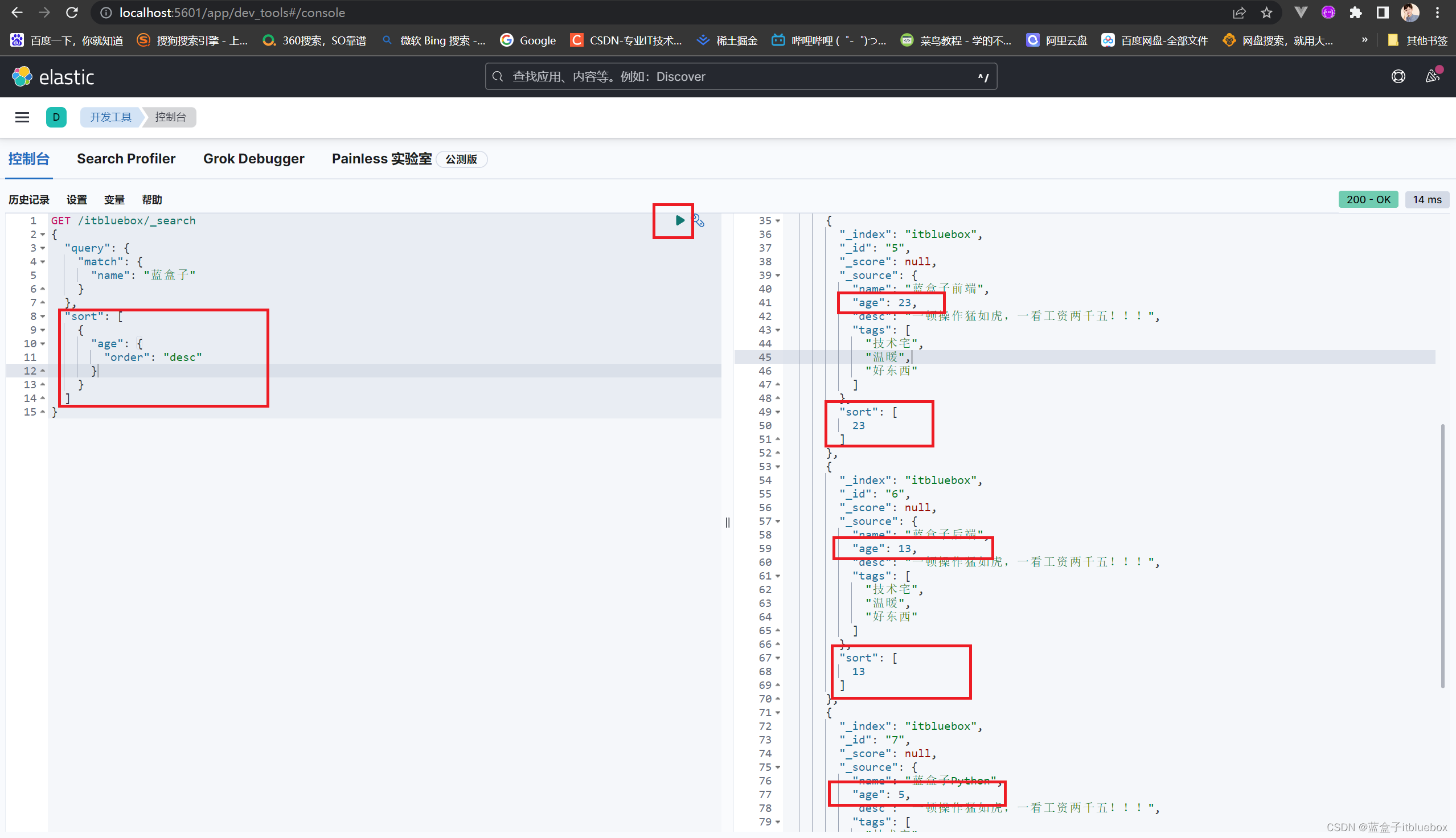
(3)排序查询(sort)
通过年龄进行降序排列
GET /itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
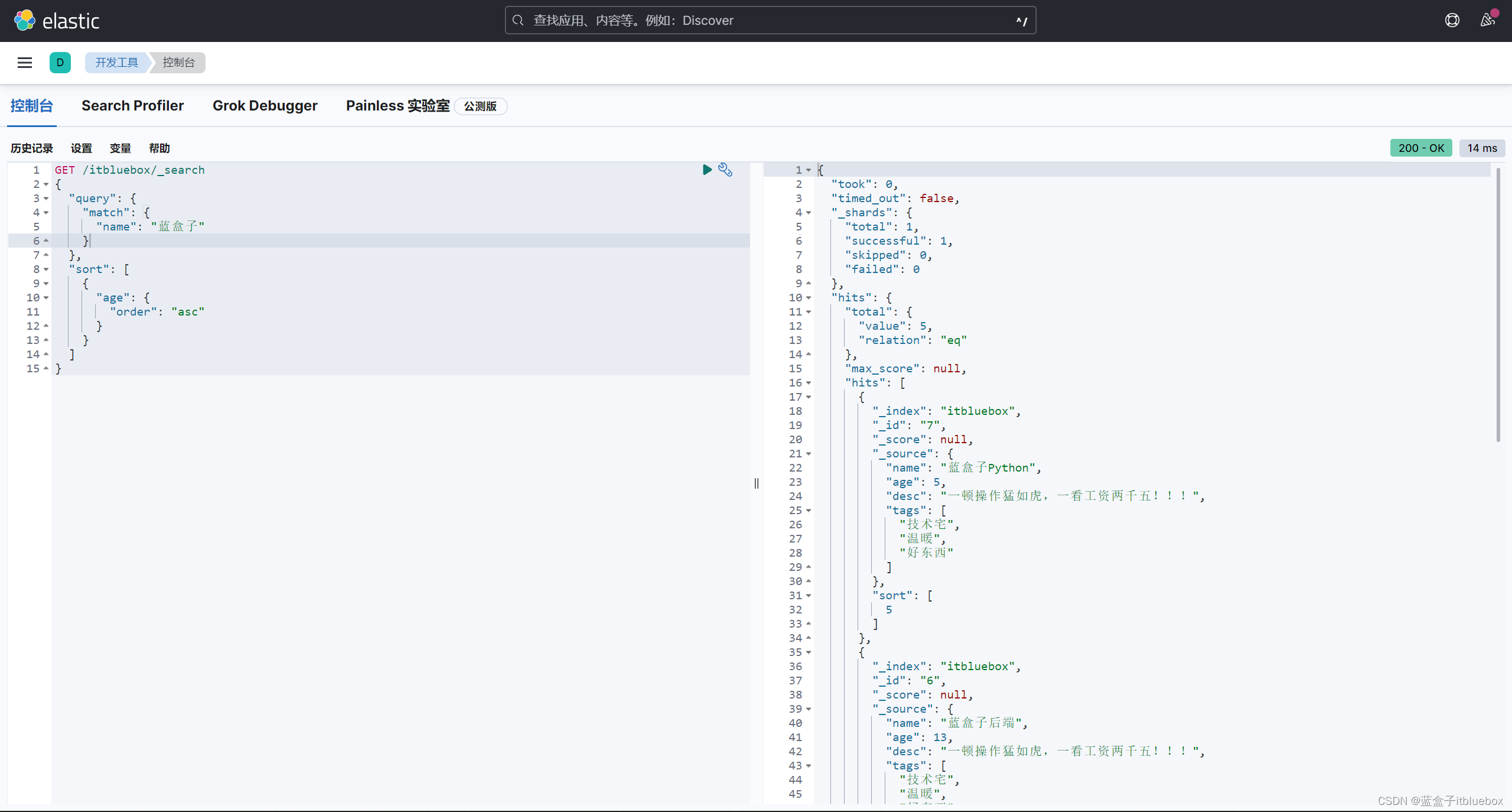
通过年龄进行升序排列
GET /itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
(4)分页查询(from,size)
from,size 相当于mysql数据库limit当中的两个参数
GET /itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0,
"size": 2
}
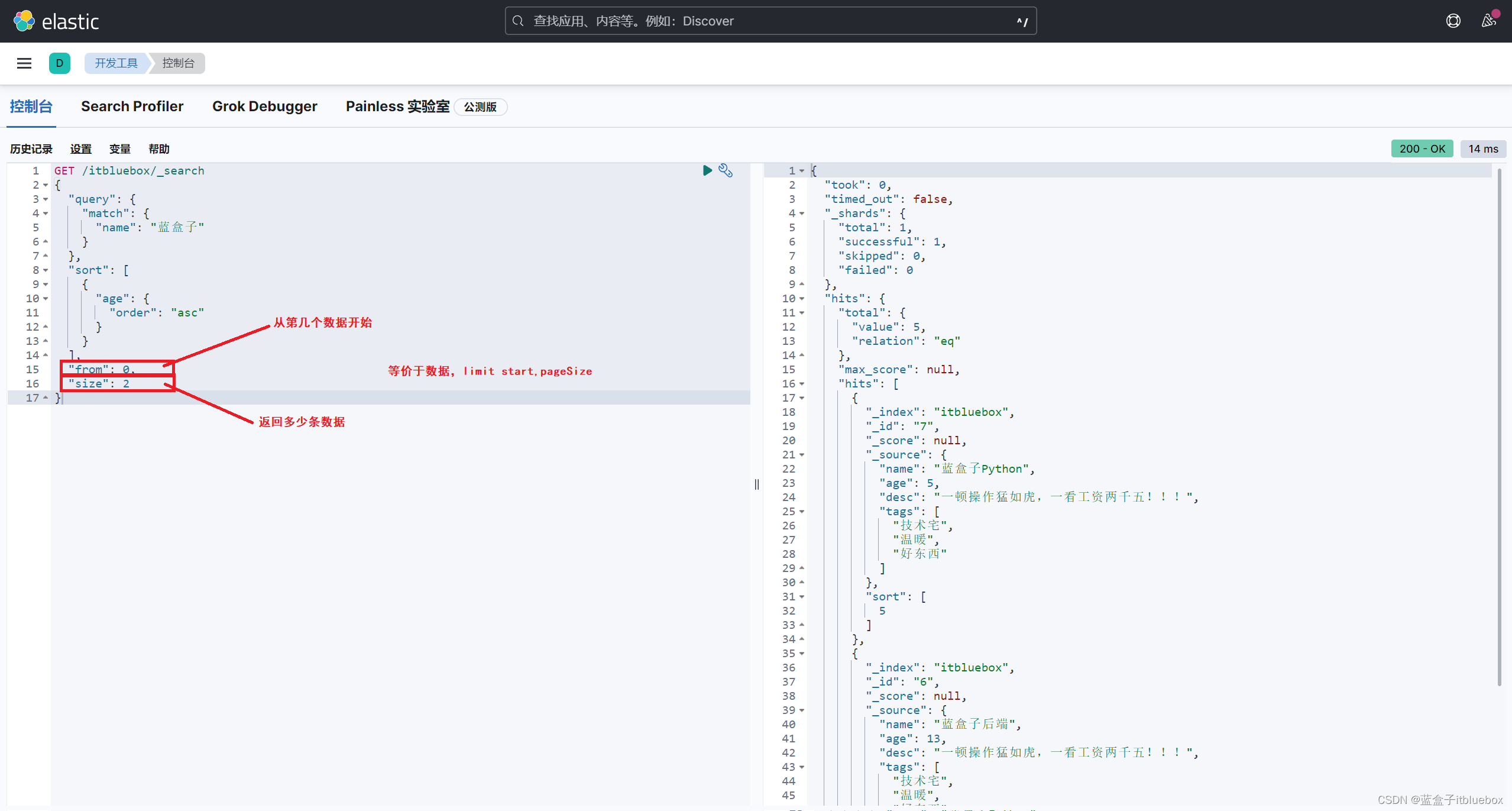
数据下标还是从0开始的,和学的所有的数据结构的一样的!
(5)布尔值查询(bool)
must:多条件精确查询(相当于mysql当中的and),所有的条件都要符合(where id = 1 and name = xxx)
实现多条件查询
GET /itbluebox/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "蓝盒子"
}
},
{
"match": {
"age": 13
}
}
]
}
}
}
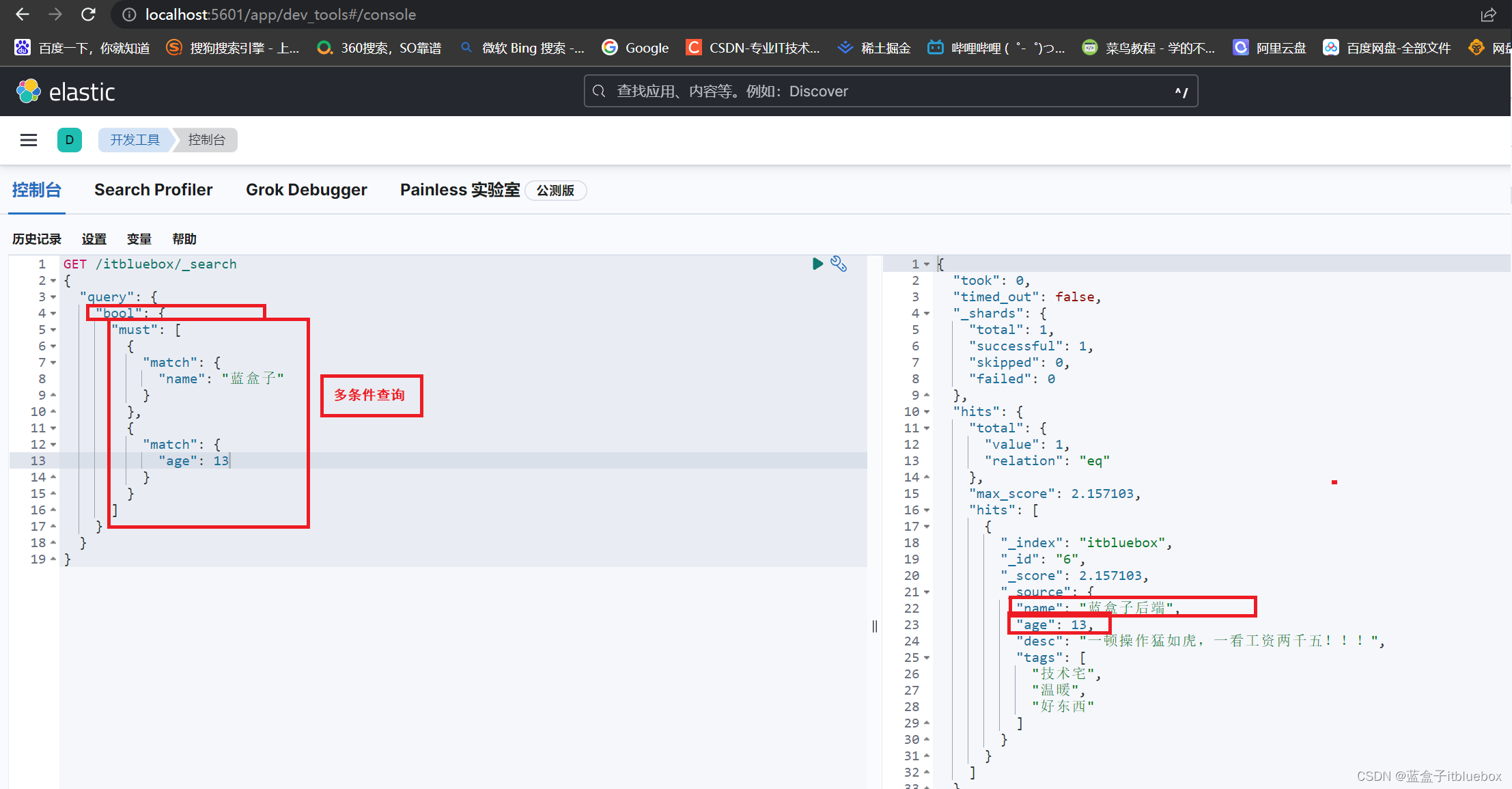
must_not:多条件精确查询(相当于mysql当中的!=),所有的条件都要符合(where id != 13)
查询年龄不为13的
GET /itbluebox/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 13
}
}
]
}
}
}
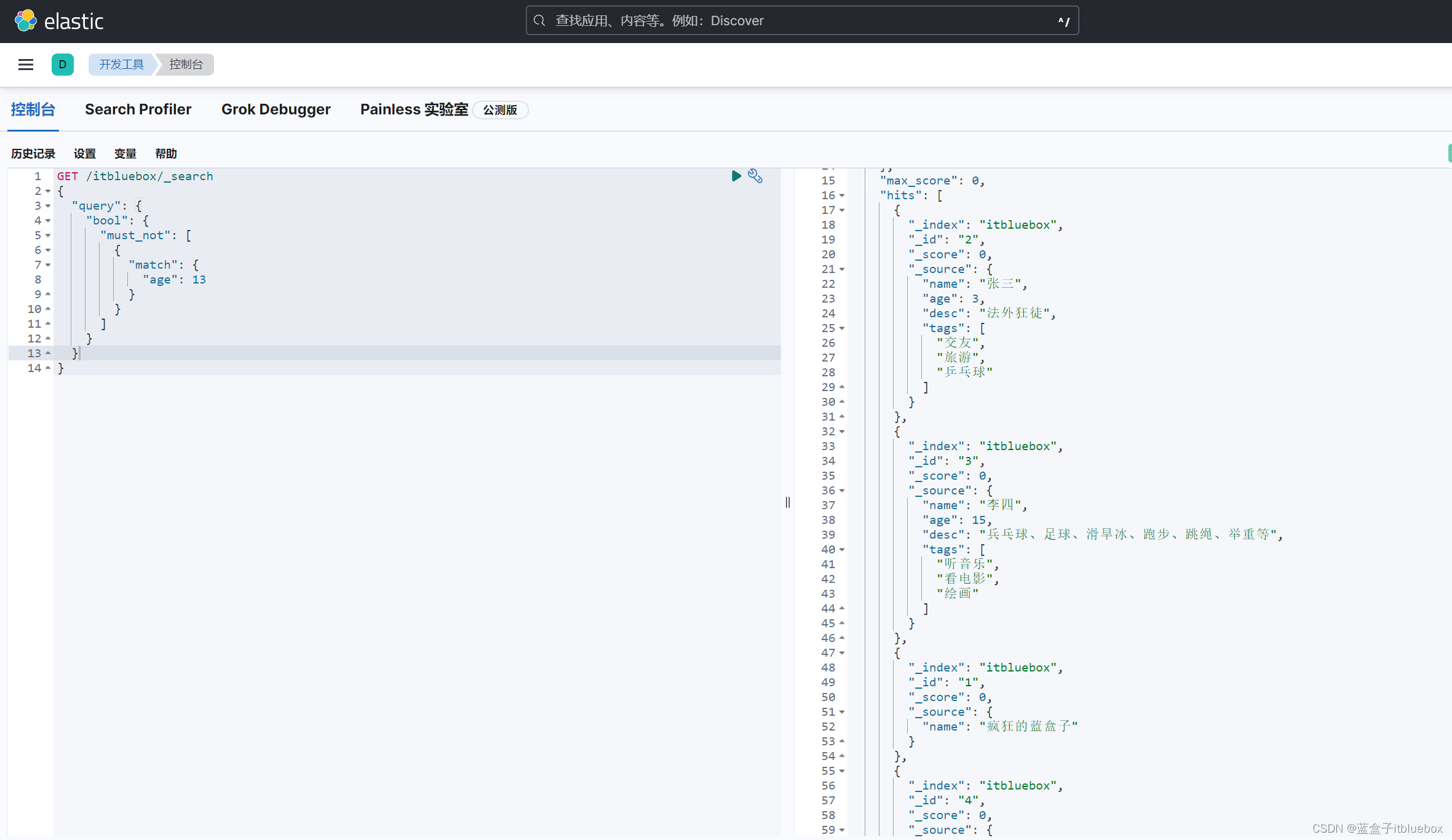
should:多条件精确查询(相当于mysql当中的or),所有的条件都要符合(where id = 1 or name = xxx)
GET /itbluebox/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "蓝盒子"
}
},
{
"match": {
"age": 13
}
}
]
}
}
}

(6)布尔值查询(bool)–filter复杂查询操作
filter过滤查询
自定义查询条件
查询年龄大于10岁的
gt:大于
gte:大于等于
GET /itbluebox/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "蓝盒子"
}
}
],
"filter": [
{
"range": {
"age": {
"gt": 10
}
}
}
]
}
}
}
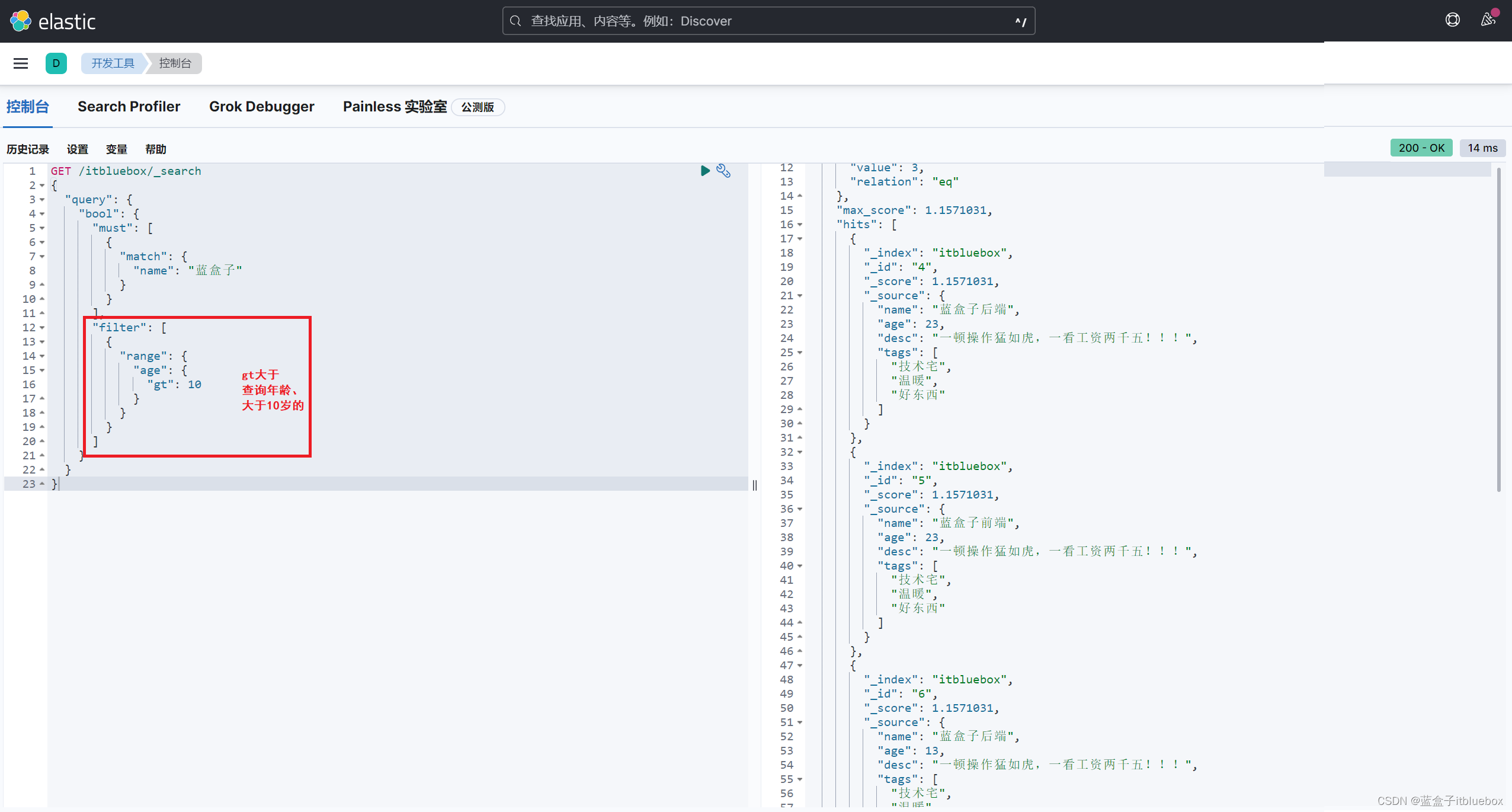
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.1571031,
"hits": [
{
"_index": "itbluebox",
"_id": "4",
"_score": 1.1571031,
"_source": {
"name": "蓝盒子后端",
"age": 23,
"desc": "一顿操作猛如虎,一看工资两千五!!!",
"tags": [
"技术宅",
"温暖",
"好东西"
]
}
},
{
"_index": "itbluebox",
"_id": "5",
"_score": 1.1571031,
"_source": {
"name": "蓝盒子前端",
"age": 23,
"desc": "一顿操作猛如虎,一看工资两千五!!!",
"tags": [
"技术宅",
"温暖",
"好东西"
]
}
},
{
"_index": "itbluebox",
"_id": "6",
"_score": 1.1571031,
"_source": {
"name": "蓝盒子后端",
"age": 13,
"desc": "一顿操作猛如虎,一看工资两千五!!!",
"tags": [
"技术宅",
"温暖",
"好东西"
]
}
}
]
}
}
查询年龄小于10岁的
lt:小于
lte:小于等于
GET /itbluebox/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "蓝盒子"
}
}
],
"filter": [
{
"range": {
"age": {
"lt": 10
}
}
}
]
}
}
}
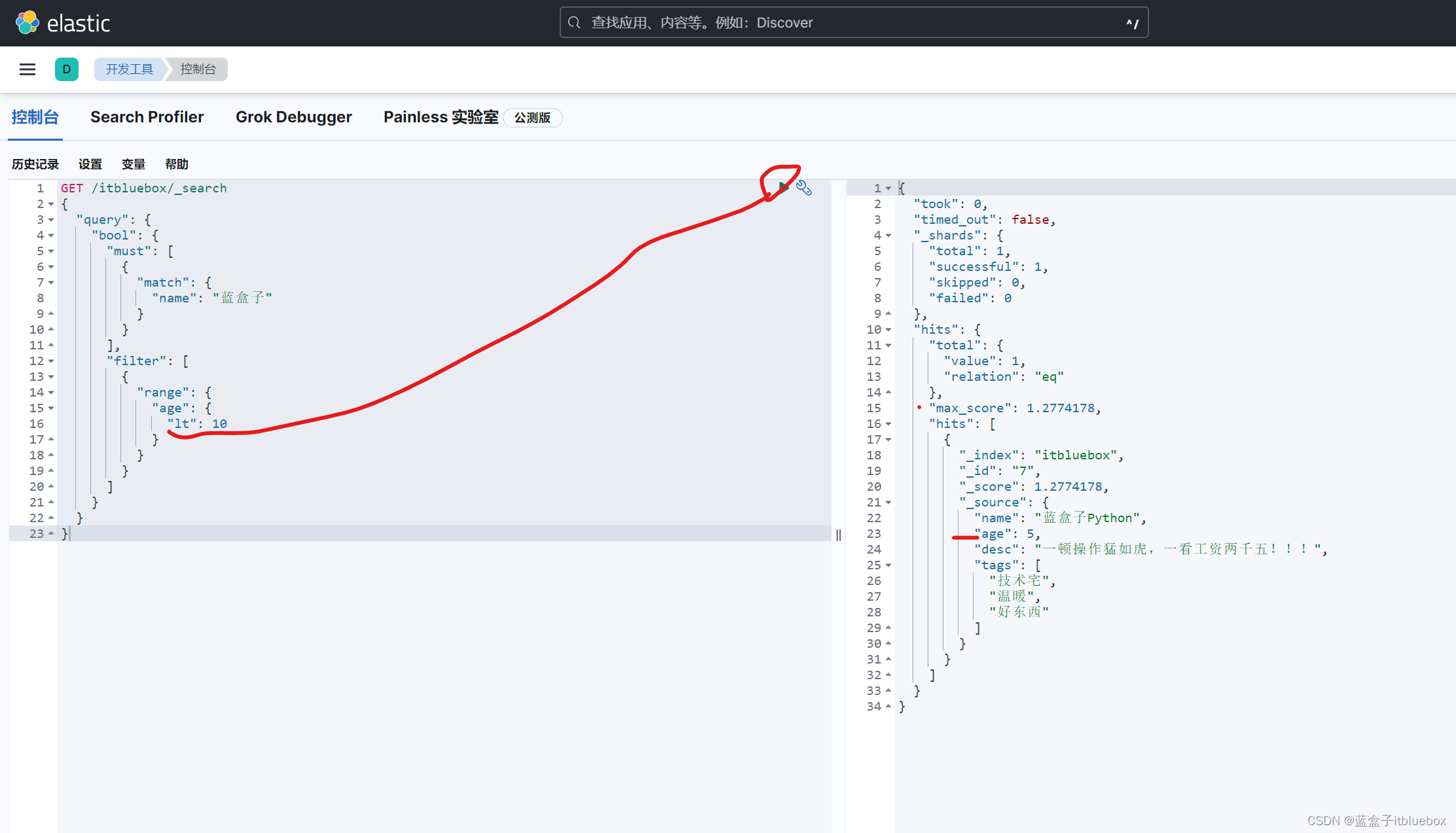
使用多个条件进行过滤
查询10岁到20岁之间的人
GET /itbluebox/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "蓝盒子"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}

(7)匹配多个搜索条件
首先是单个匹配
查询初tags当中有术的内容
GET /itbluebox/_search
{
"query": {
"match": {
"tags": "术"
}
}
}
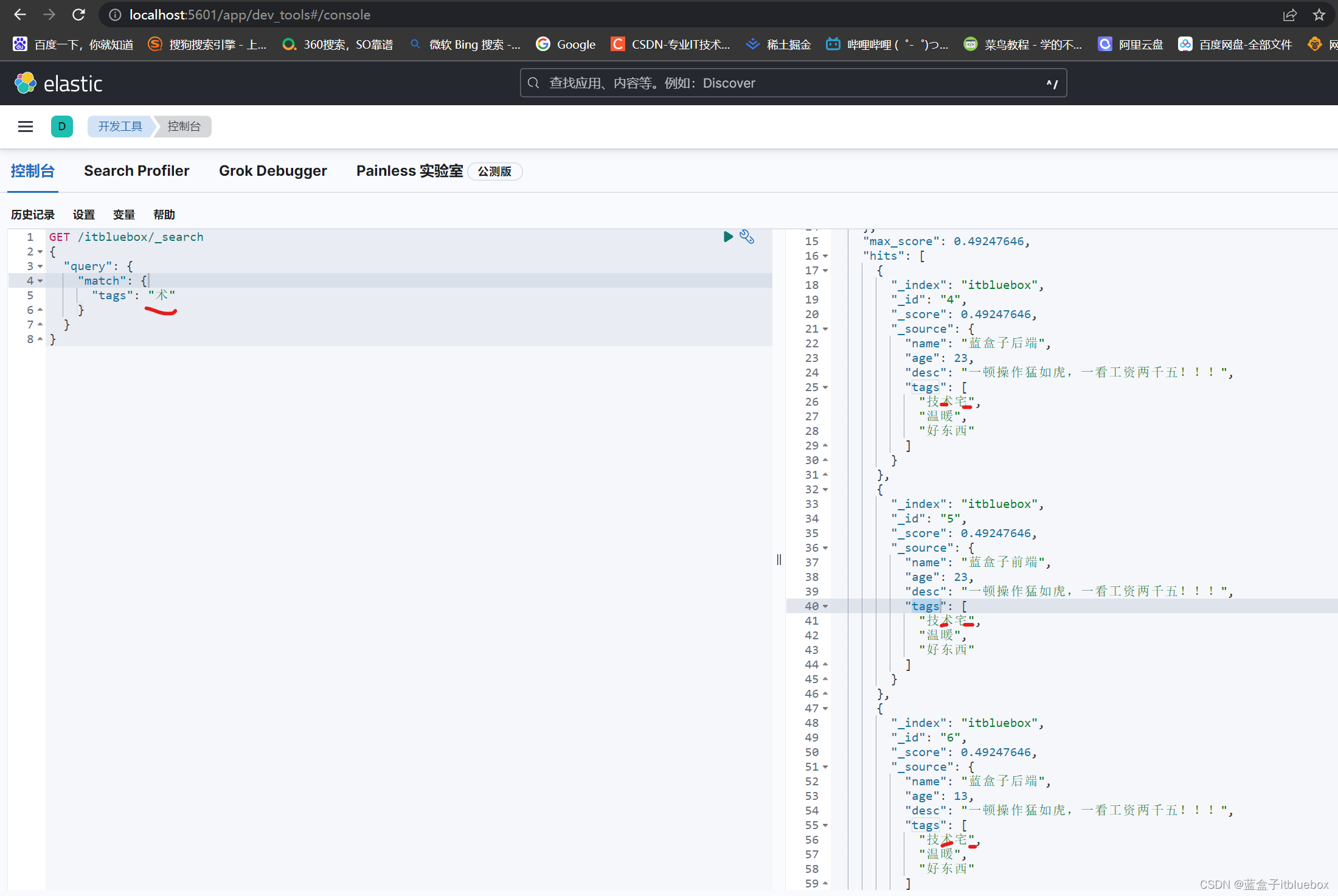
多个条件,直接空格分割。
方便后续查询我吗技术添加一些东西
PUT /itbluebox/_doc/8
{
"name": "蓝盒子编程",
"age":53,
"desc":"一顿操作猛如虎,一看工资两千五!!!,编程",
"tags":["暖男","乒乓球","技术宅"]
}
PUT /itbluebox/_doc/9
{
"name": "蓝盒子java",
"age":43,
"desc":"一顿操作猛如虎,一看工资两千五!!!,java",
"tags":["靓女","篮球","艺术家"]
}
PUT /itbluebox/_doc/10
{
"name": "蓝盒子java",
"age":43,
"desc":"一顿操作猛如虎,一看工资两千五!!!,java",
"tags":["靓女","羽毛球","技术宅"]
}
首先是多个匹配
查询初tags当中有男和技术的内容
GET /itbluebox/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
多个条件使用空格隔开,只要满足其中一个结果,就可以被查出,
这个时候通过分值基本的判断
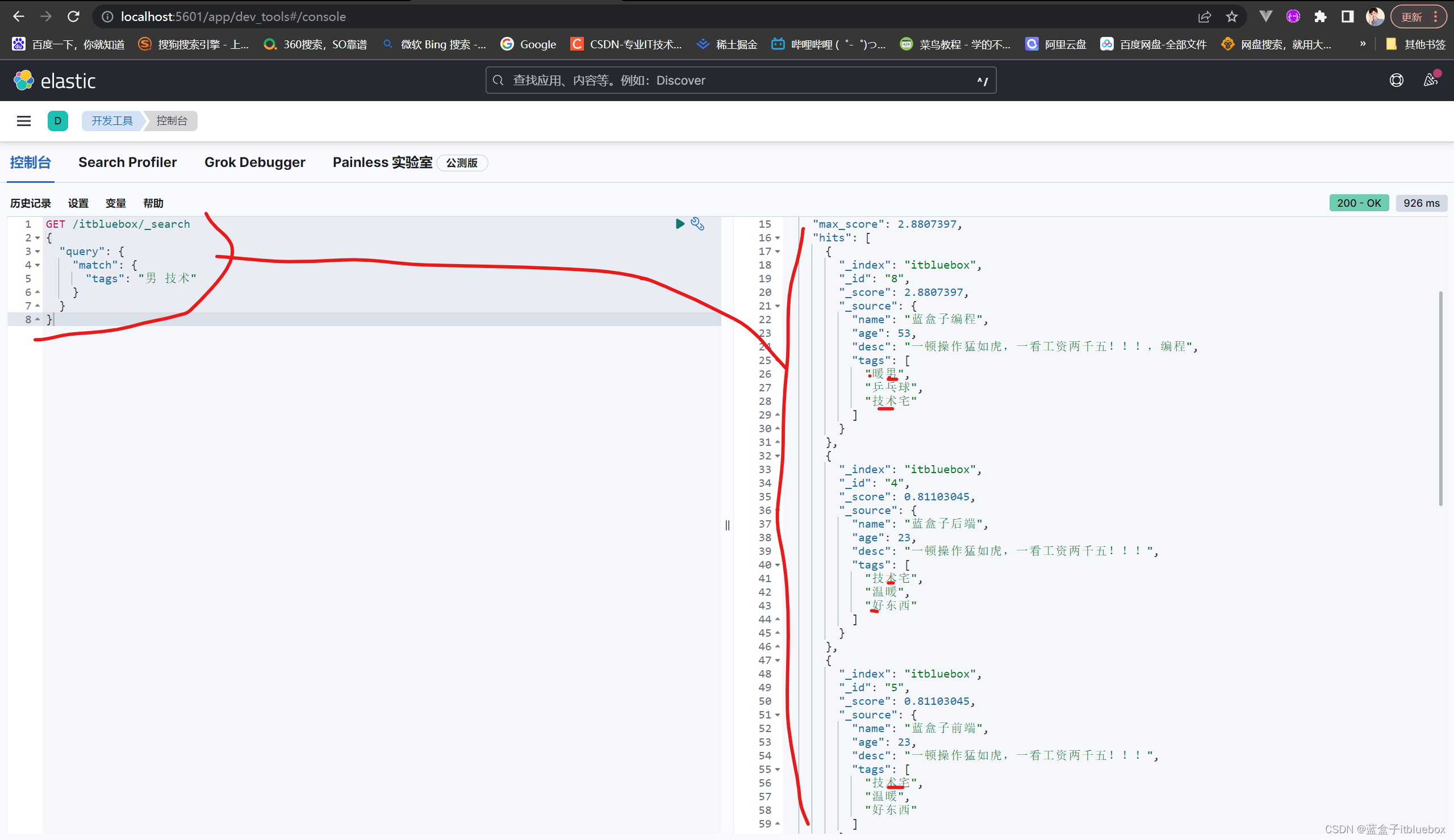
(8)单个值匹配精确查询(term)
创建索引库
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type": "keyword"
}
}
}
}
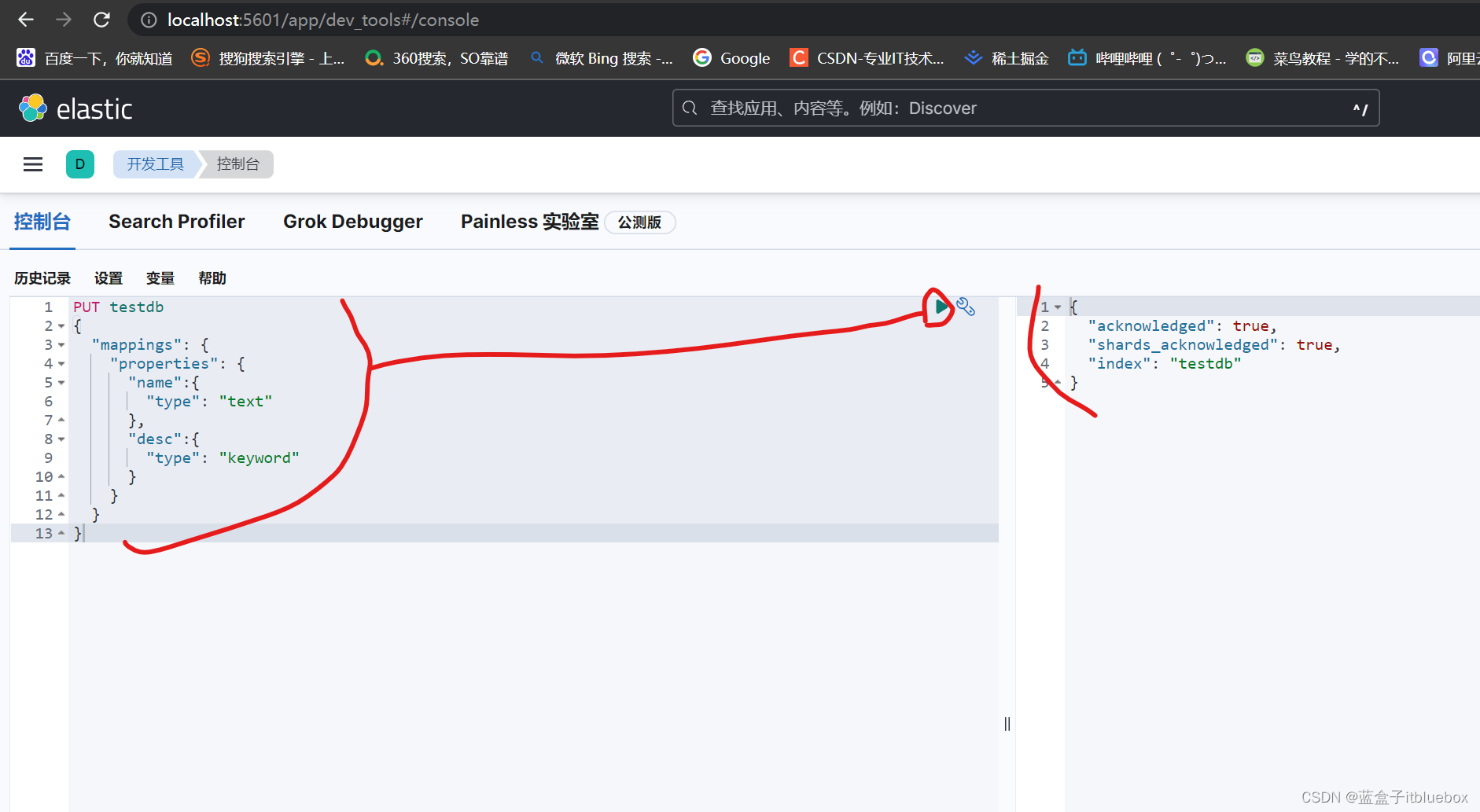
添加一些数据
PUT testdb/_doc/1
{
"name":"蓝盒子Java name",
"desc":"蓝盒子Java desc"
}
PUT testdb/_doc/2
{
"name":"蓝盒子Java name",
"desc":"蓝盒子Java desc2"
}
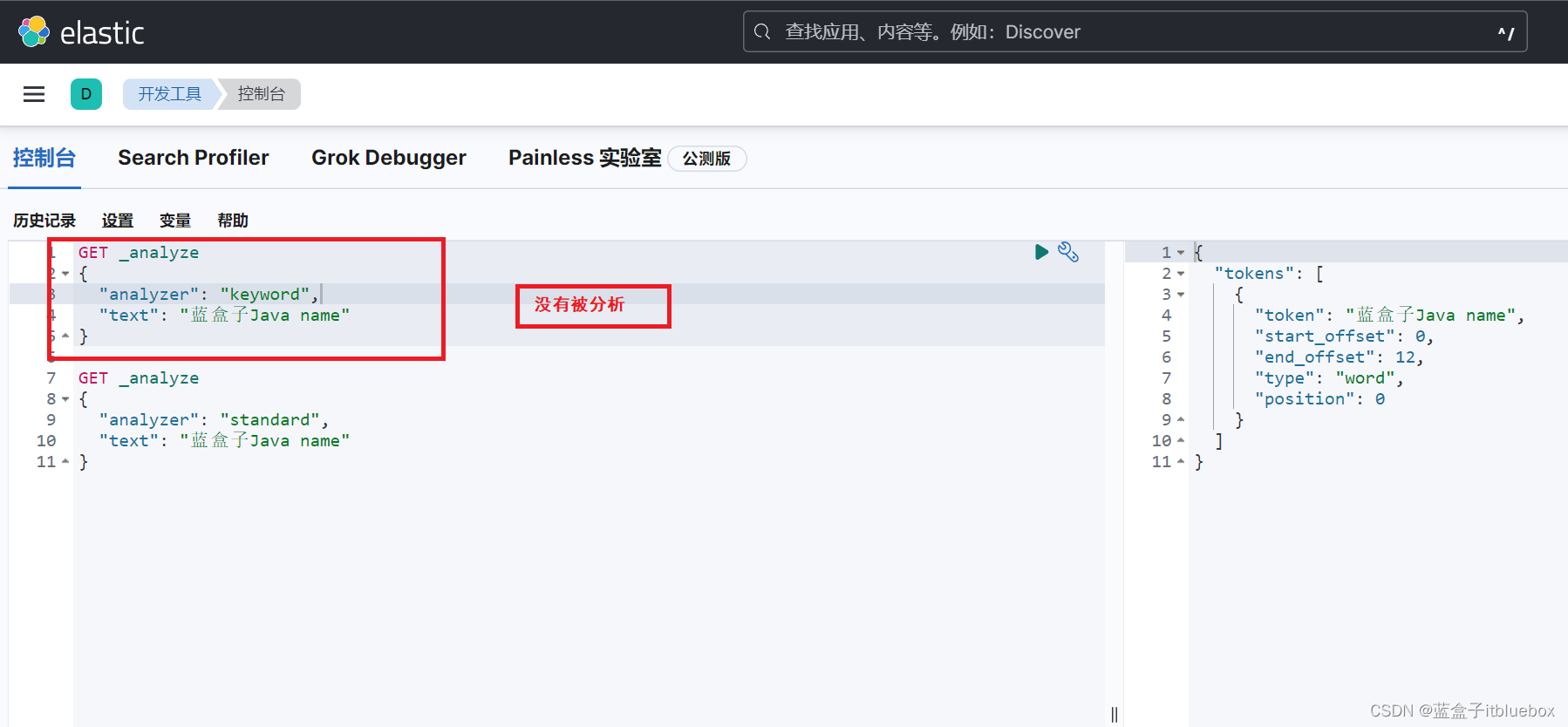
GET _analyze
{
"analyzer": "keyword",
"text": "蓝盒子Java name"
}
term查询是直接通过倒排索引指定的词条进行精确的查询!
关于分词:
- term,直接查找精确值
- match,会使用分词器进行解析!(先分析文档,然后在通过分析的文档进行查询!)
两个类型 text keyword
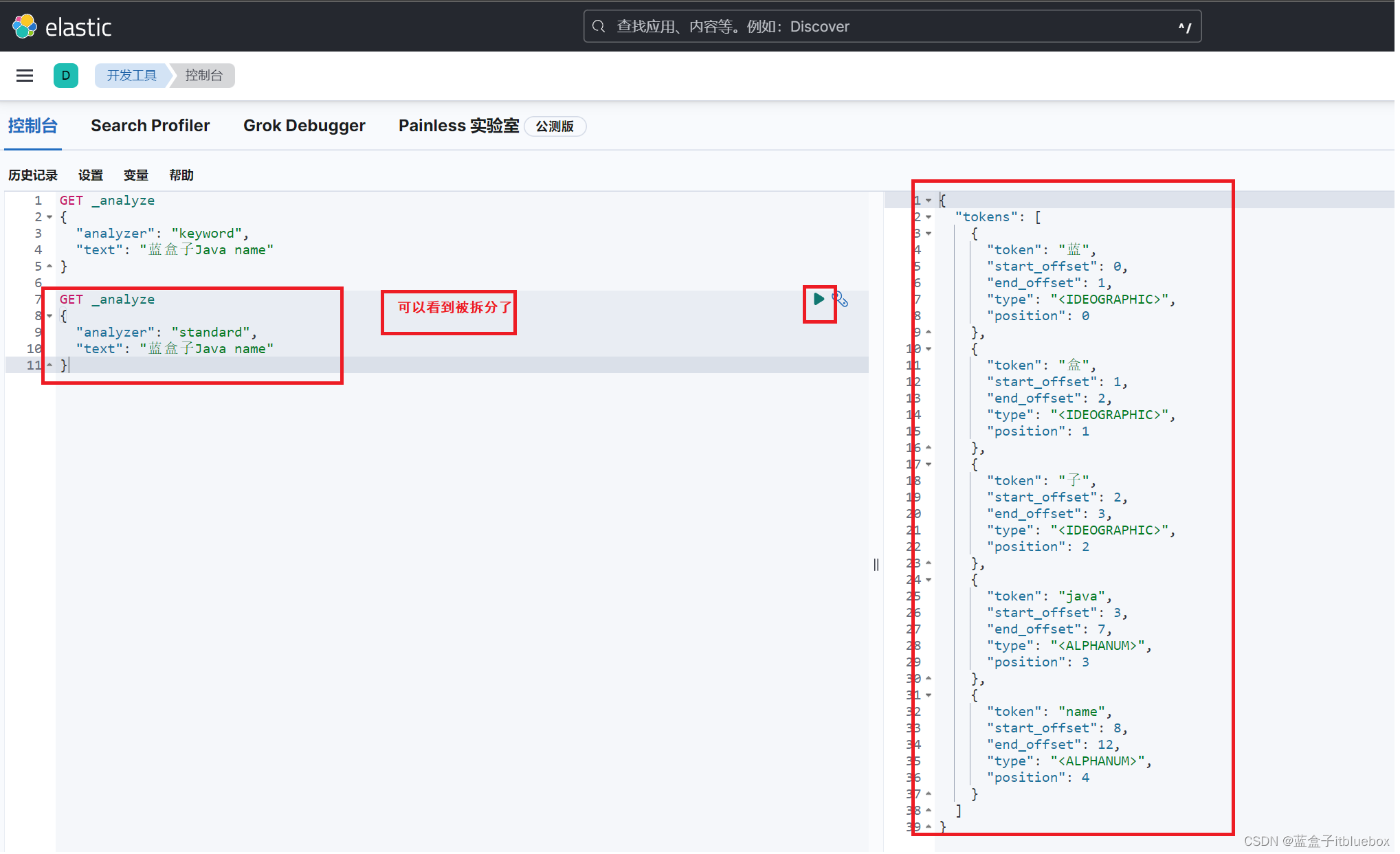
查询name当中有蓝的数据
因为name字段是text类型,在进行分词的时候会被分词器解析
GET testdb/_search
{
"query": {
"term": {
"name": "蓝"
}
}
}
搜索出来name当中有蓝的内容
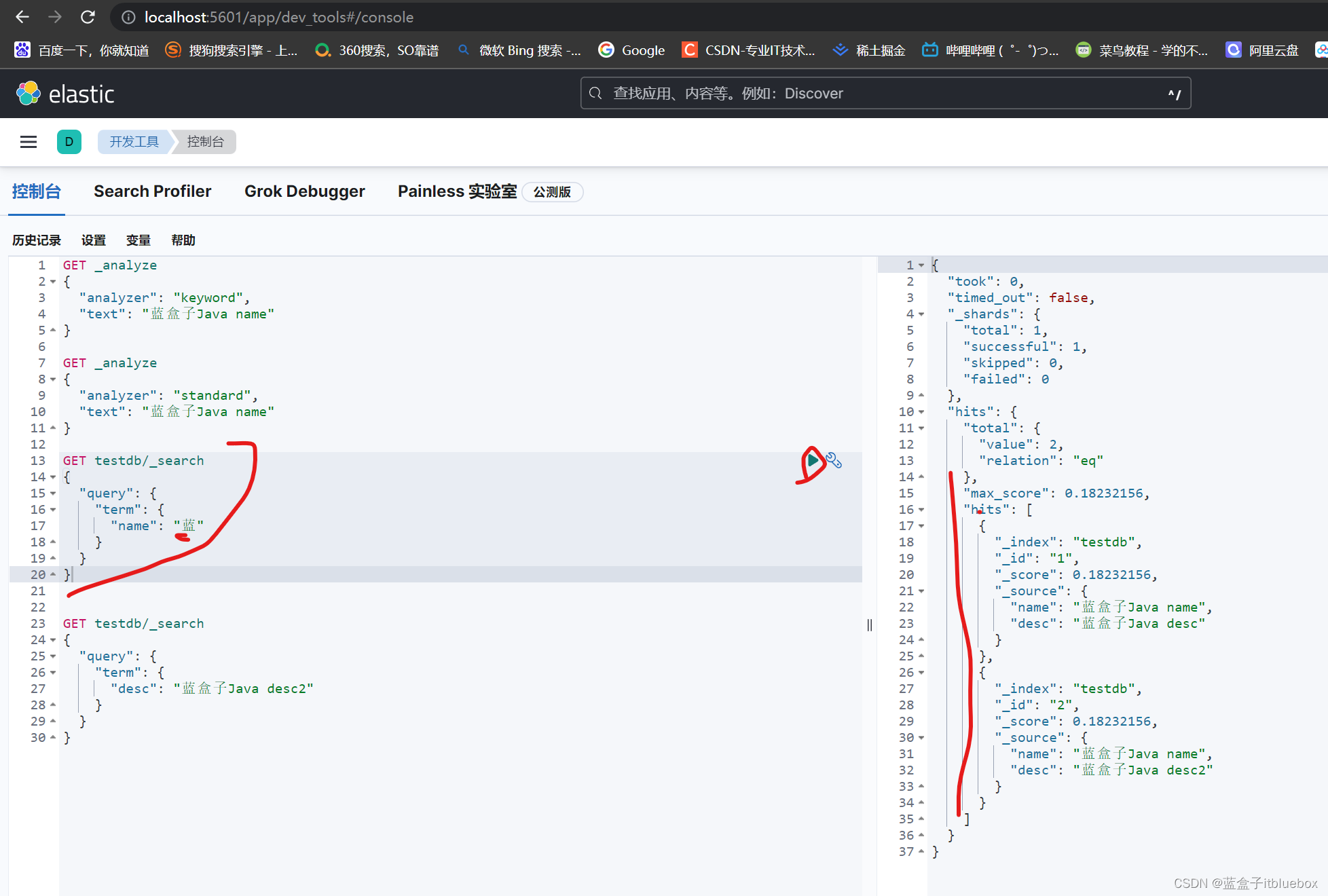
desc是keyword类型,所以在进行搜索的時候没有进行分词,直接匹配
GET testdb/_search
{
"query": {
"term": {
"decs": "蓝"
}
}
}
搜索之后没有任何结果
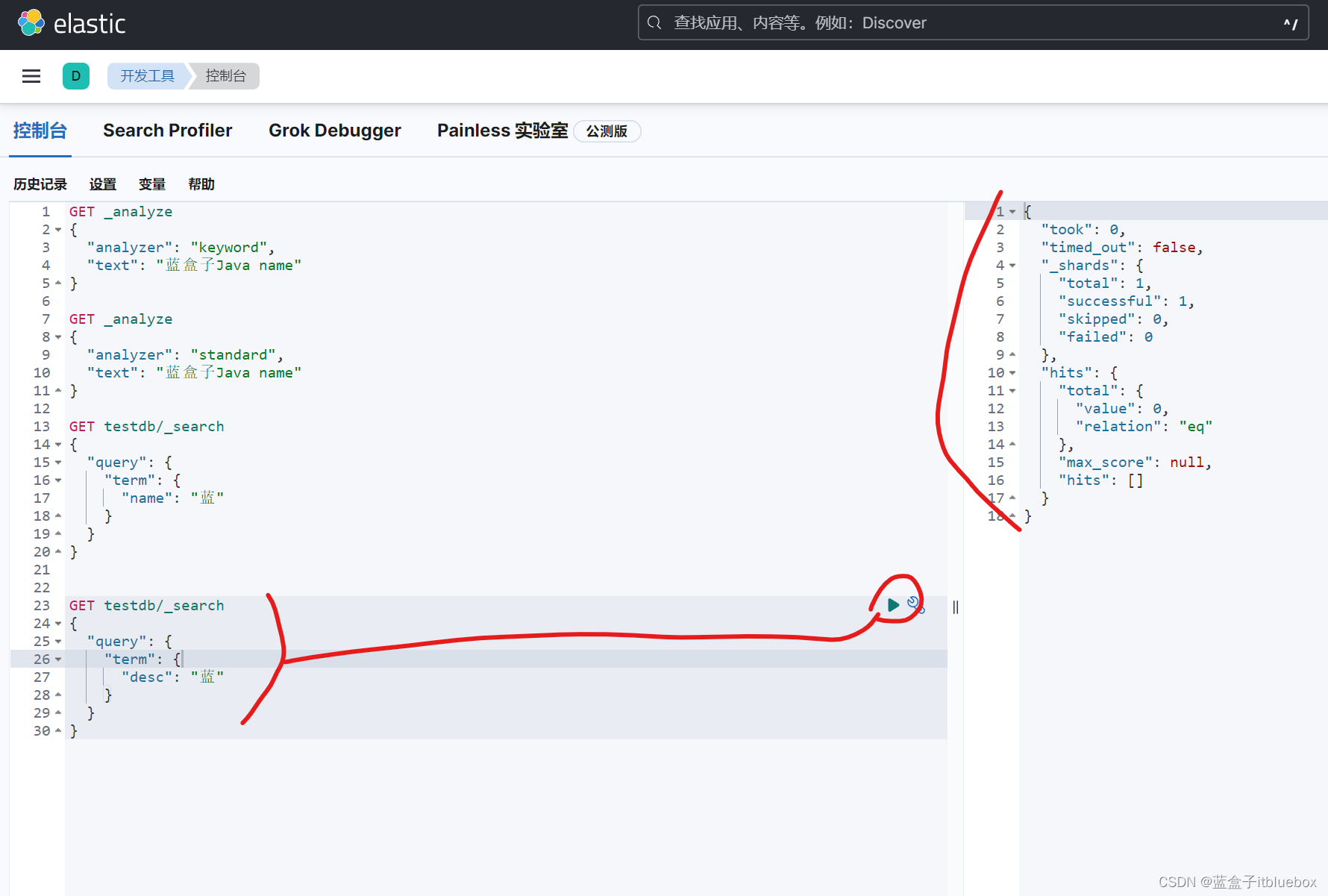
GET testdb/_search
{
"query": {
"term": {
"desc": "蓝盒子Java desc2"
}
}
}
将全部的内容作为搜索,搜索出来了对应的信息,
keyword字段类型不会被分词器解析
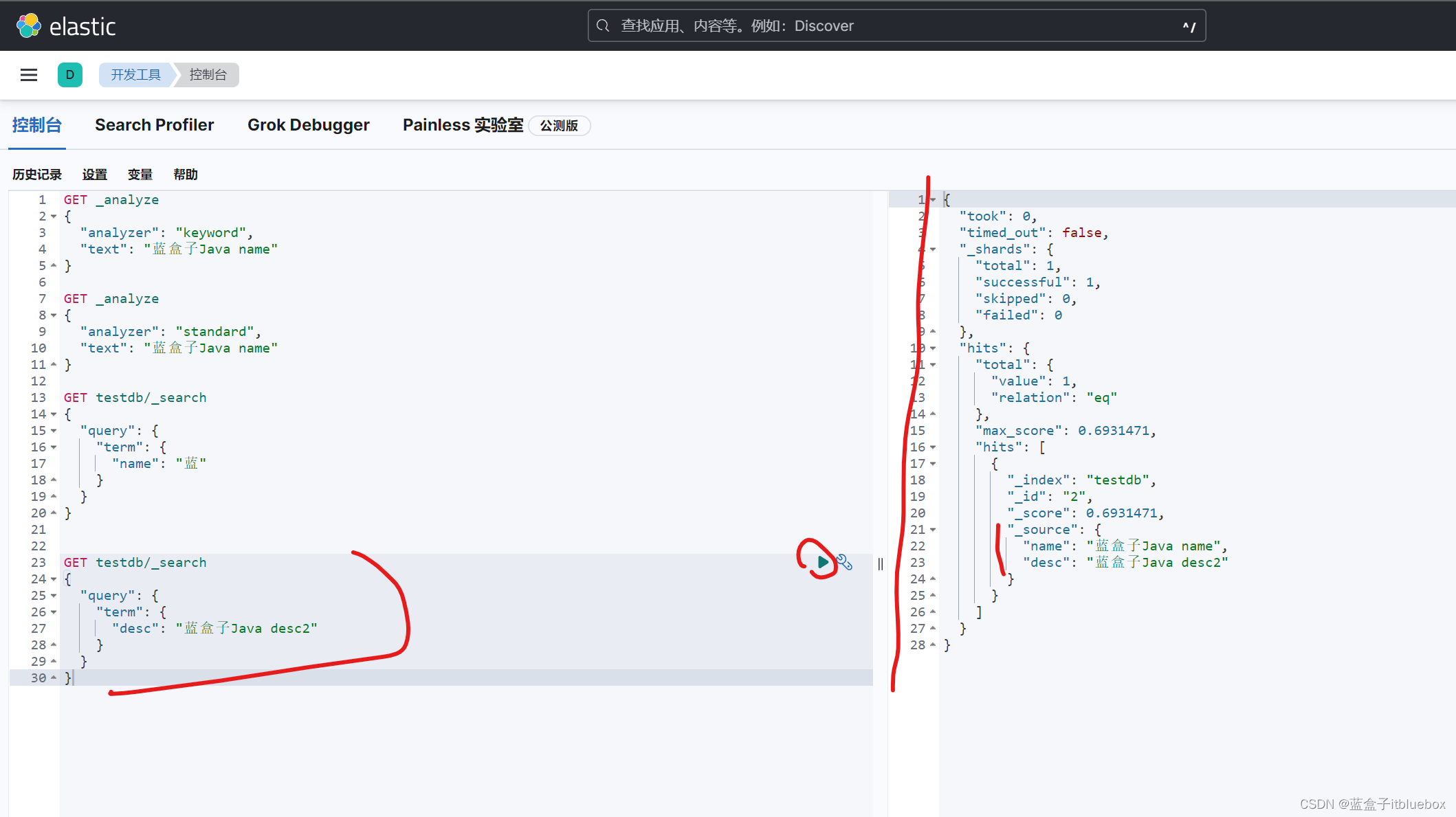
(9)多个值匹配精确查询(term)
继续添加一些测试数据
PUT testdb/_doc/3
{
"t1":"22",
"t2":"2022-11-05"
}
PUT testdb/_doc/4
{
"t1":"33",
"t2":"2022-11-06"
}
实现精确查询多个值
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1":"22"
}
},
{
"term": {
"t1":"33"
}
}
]
}
}
}
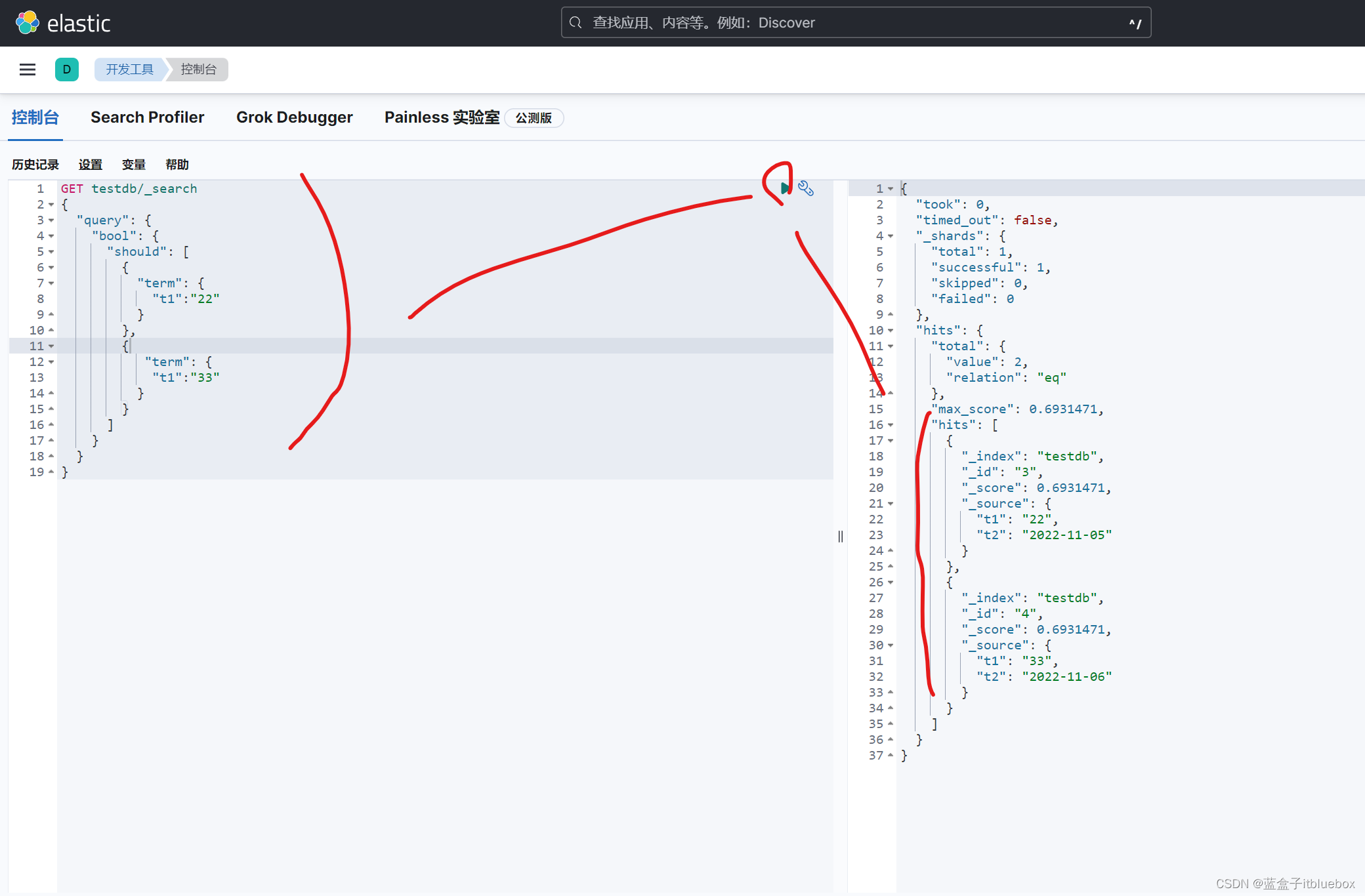
(10)高亮显示(highlight)
GET itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
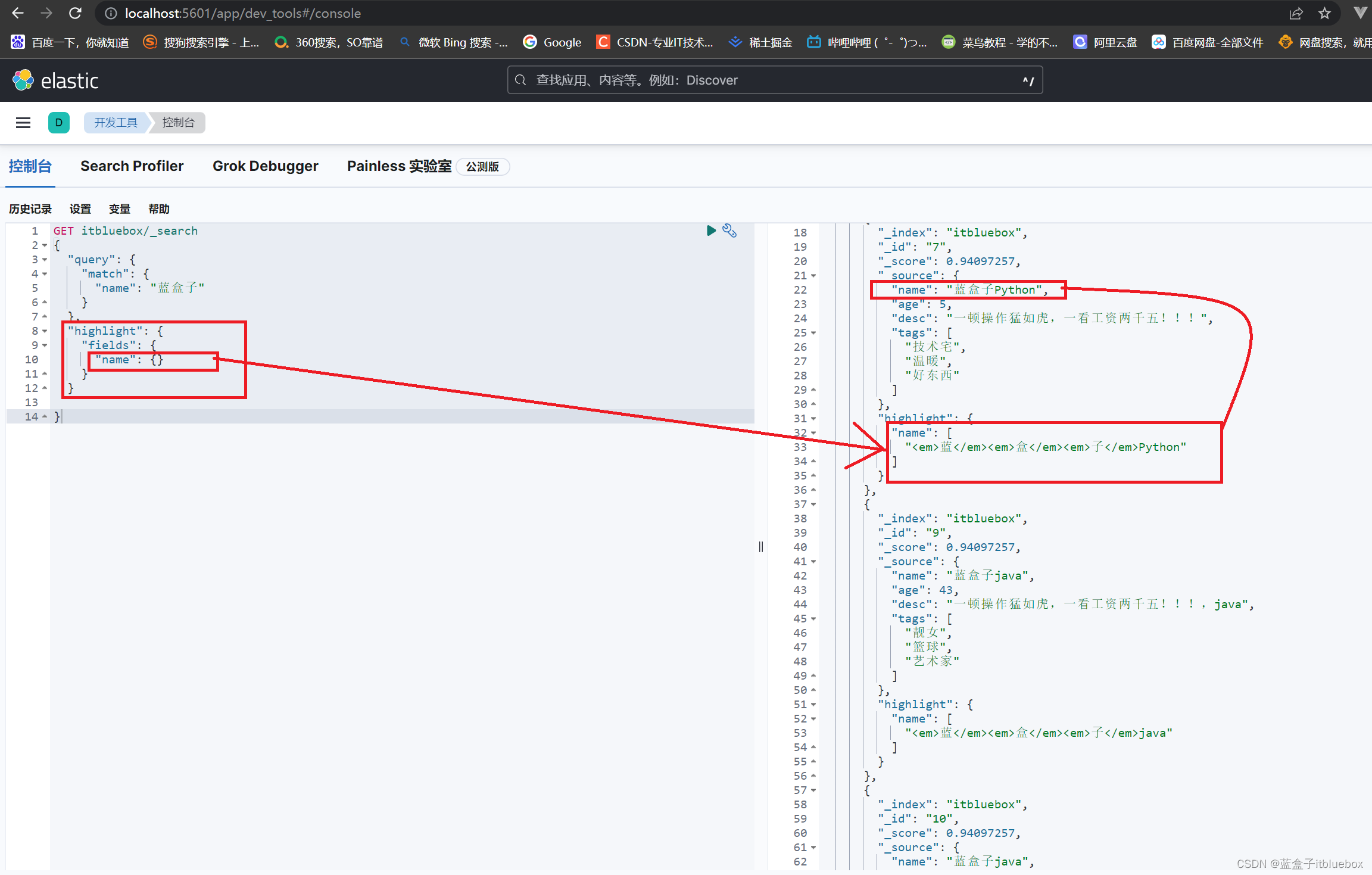
高亮显示,搜索:蓝盒子后其对应内容被高亮标签em包裹
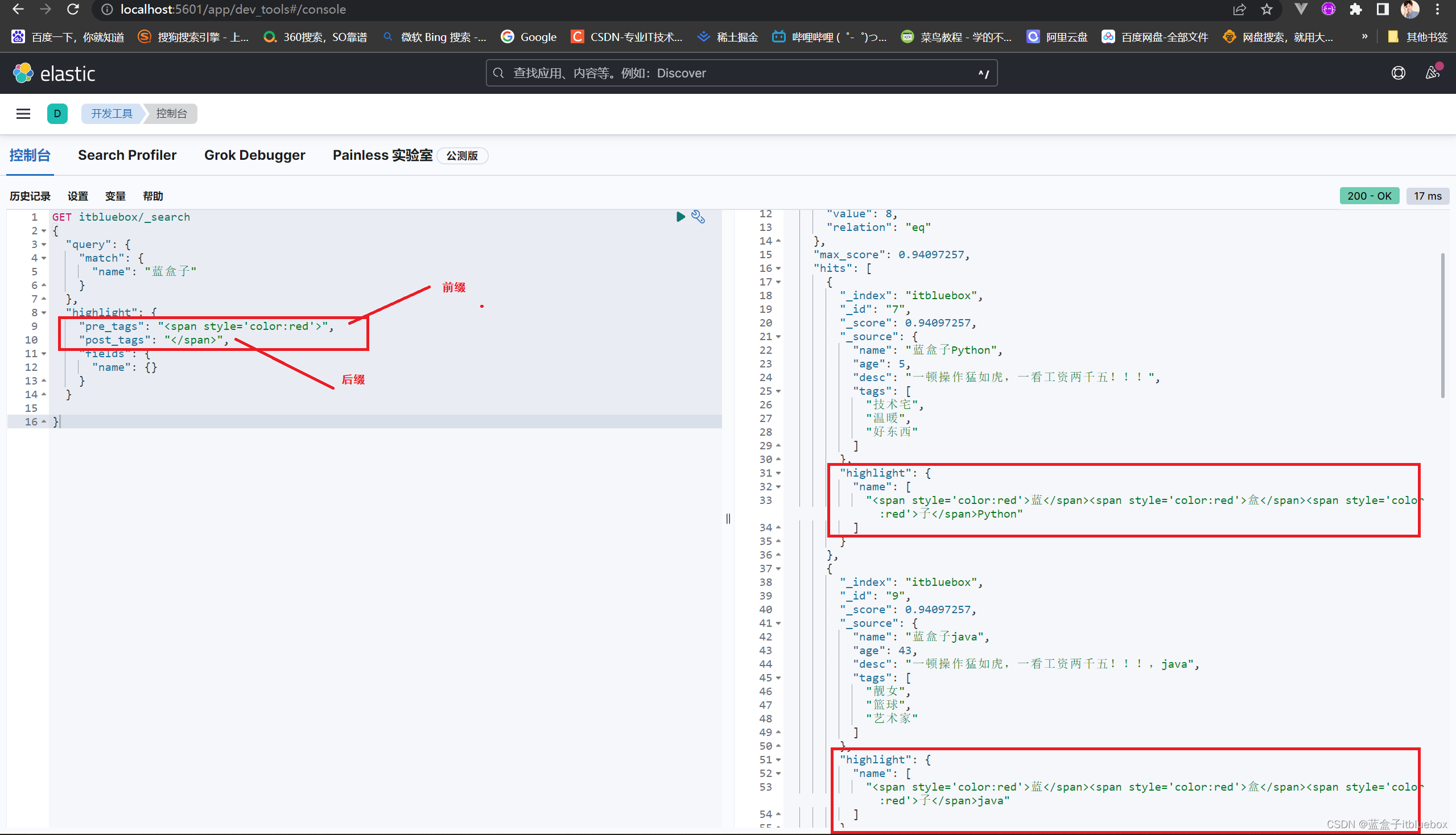
设置自定义标签,自定义搜索高亮,不使用em(pre_tags前缀,post_tag后缀)
GET itbluebox/_search
{
"query": {
"match": {
"name": "蓝盒子"
}
},
"highlight": {
"pre_tags": "<span style='color:red'>",
"post_tags": "</span>",
"fields": {
"name": {}
}
}
}
四、ElasticSearch NLP
随着8.0的发布,Elastic很高兴能够将PyTorch机器学习模型上传到 Elasticsearch 中,以在 Elastic Stack中提供现代自然语言处理(NLP)。现在,Elasticsearch用户能够集成用于构建NLP模型的最流行的格式之一,并将这些模型作为NLP数据管道的一部分通过我们的Inference processor整合到Elasticsearch中
1、什么是自然语言处理?
NLP是指我们可以使用软件来操作和理解口语或书面文本或自然语言的方式。2018年,Google开源了一种用于NLP 预训练的新技术,称为来自Transformers的双向编码器呈现,或BERT。BERT通过在没有任何人工参与的情况下对互联网大小的数据集(例如,想想所有的维基百科和数字书籍)进行训练来利用“trransfer learning”。
Transfer learning 允许对 BERT模型进行预训练以进行通用语言理解。一旦模型只经过一次预训练,它就可以被重用并针对更具体的任务进行微调,以了解语言的使用方式。
为了支持类 BERT模型(使用与 BERT 相同的标记器的模型),Elasticsearch 将首先通过 PyTorch模型支持支持大多数最常见的NLP任务。PyTorch是最受欢迎的现代机器学习库之一,拥有大量活跃用户,它是一个支持深度神经网络的库,例如 BERT使用的Transformer架构。
以下是一些示例NLP任务:
■情绪分析:用于识别正面与负面陈述的二元分类
■命名实体识别(NER):从非结构化文本构建结构,尝试提取名称、位置或组织等细节
■文本分类:零样本分类允许你根据你选择的类对文本进行分类,而无需进行预训练。
■文本嵌入:用于k近邻(kNN)搜索
2、ElasticSearch 当中的自然语言处理
在将NLP模型集成到 Elastic平台时,我们希望为上传和管理模型提供出色的用户体验。使用用于上传 PyTorch模型的 Eland客户端和用于管理Elasticsearch集群上模型的Kibana的ML模型管理用户界面,用户可以尝试不同的模型并很好地了解它们在数据上的表现。
我们还希望使其可跨集群中的多个可用节点进行扩展,并提供良好的推理吞吐量性能。
为了使这一切成为可能,我们需要一个机器学习库来执行推理。在 Elasticsearch中添加对PyTorch的支持需要使用原生库libtorch,它支持PyTorch,并且仅支持已导出或保存为TorchScript表示的 PyTorch模型。
这是libtorch需要的模型的表示,它将允许Elasticsearch 避免运行Python解释器。

通过与在 PyTorch模型中构建NLP模型的最流行的格式之一集成,Elasticsearch可以提供一个平台,该平台可处理大量NLP任务和用例。许多优秀的库可用于训练NLP模型,因此我们暂时将其留给其他工具。无论你是使用 PyTorch NLP、Hugging Face Transformers还是Facebook 的 fairseq等库来训练模型,你都可以将模型导入 Elasticsearch 并对这些模型进行推理。Elasticsearch推理最初将仅在摄取时进行,未来还可以扩展以在查询时引入推理。
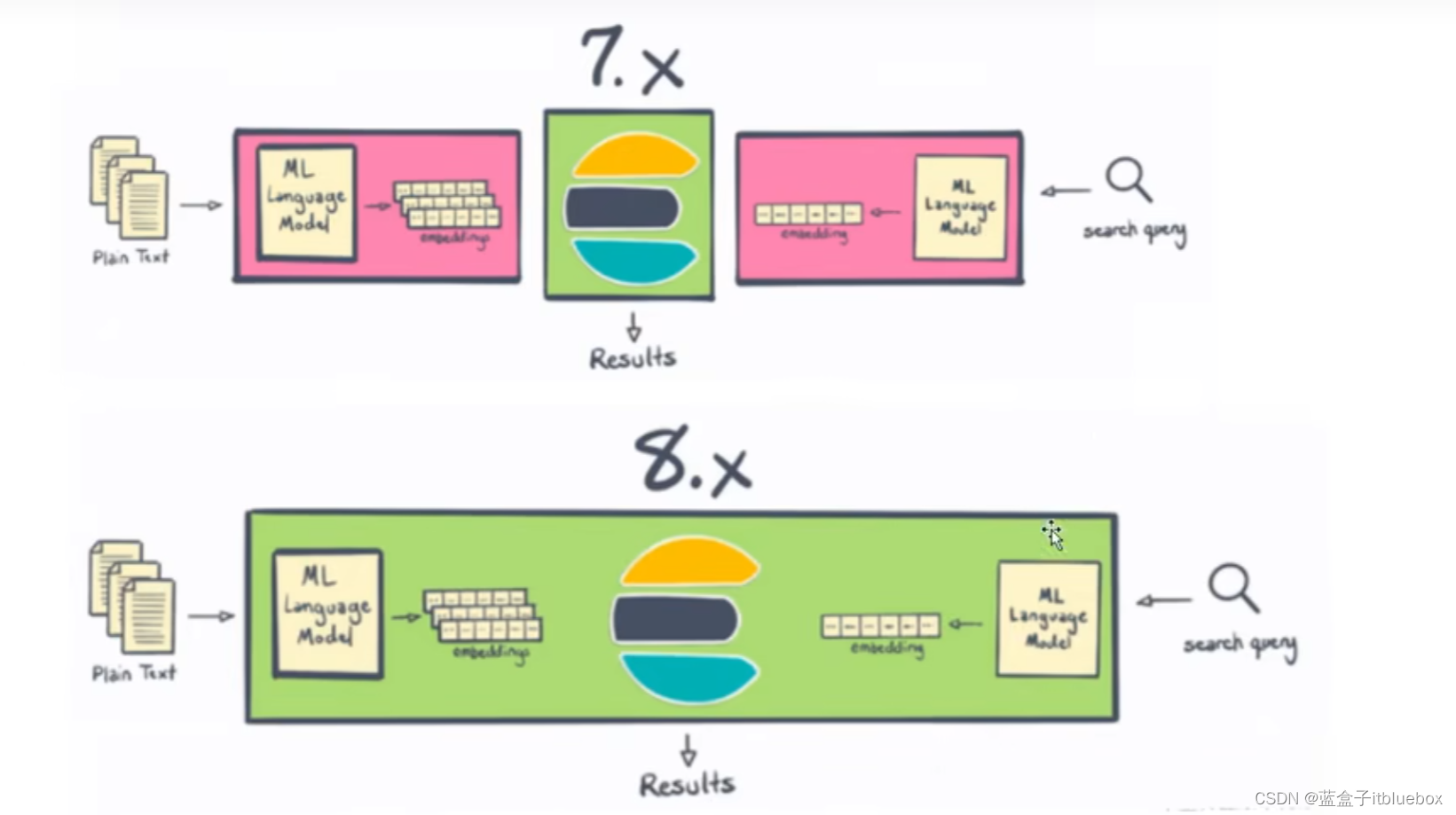
3、NLP在 Elasticsearch 7.x和8.x 中的区别
Elasticsearch一直是进行NLP的好地方,但从历史上看,它需要在Elasticsearch之外进行一些处理,或者编写一些非常复杂的插件。借助8.0,用户现在可以在Elasticsearch 中更直接地执行命名实体识别、情感分析、文本分类等操作—一无需额外的组件或编码。不仅在Elasticsearch中本地计算和创建向量在水平可扩展性方面是“胜利”(通过在服务器集群中分布计算)——这一变化还为Elasticsearch 用户节省了大量时间和精力。
4、安装opennlp
下载插件
https://github.com/spinscale/elasticsearch-ingest-opennlp/
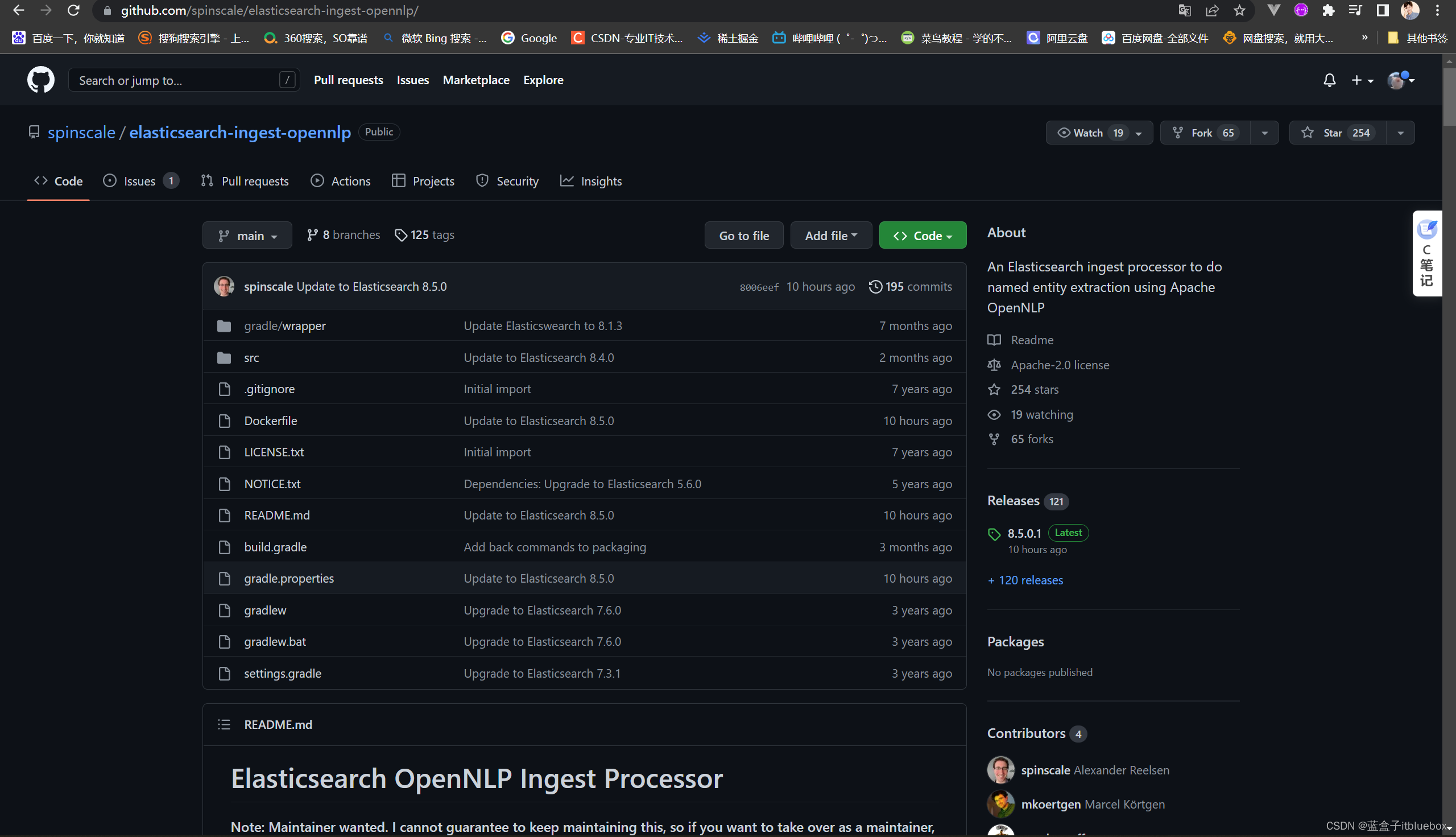
目前这个NLP支持检测Date,Person,Location, POS(part of speech)及其它。
下载与本地安装ES版本对应的
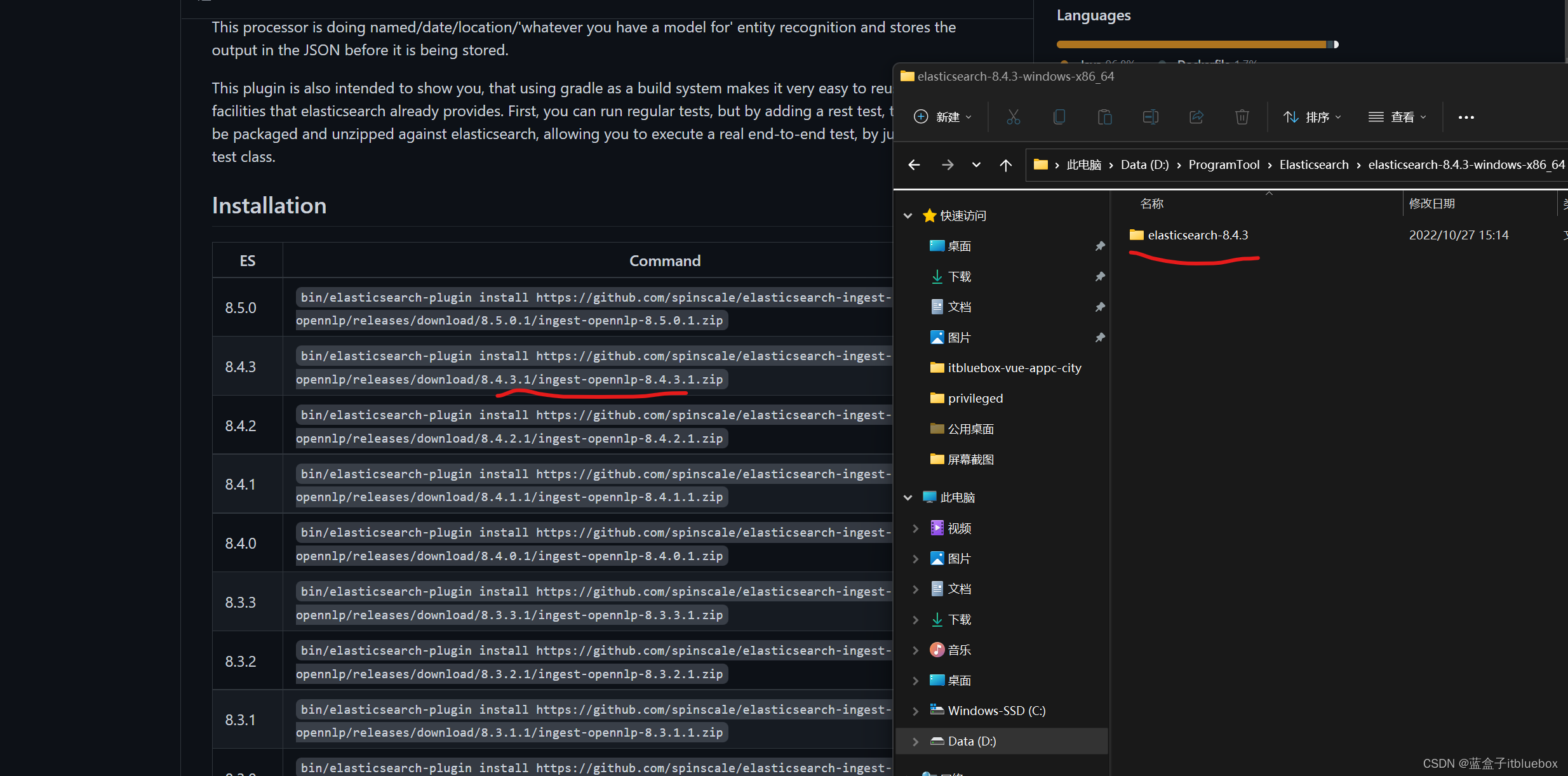
将这个复制到浏览器下载即可

https://github.com/spinscale/elasticsearch-ingest-opennlp/releases/download/8.4.3.1/ingest-opennlp-8.4.3.1.zip
安装解压后放入ES的plugins目录下
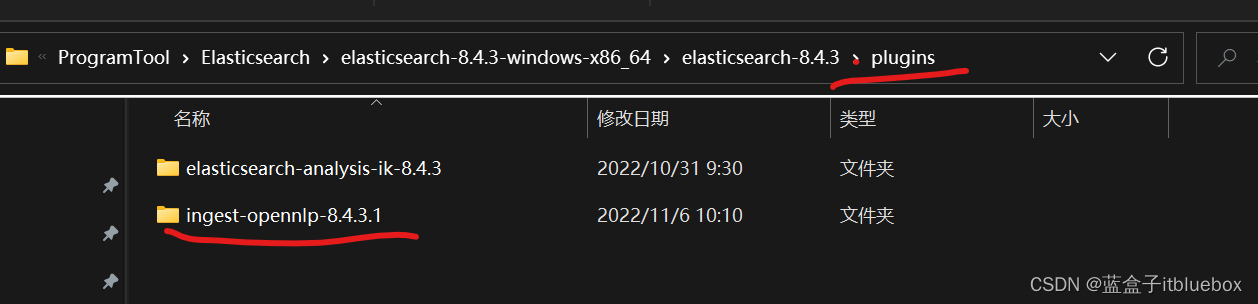
重新启动ES
5、下载NER模型
我们需要从sourceforge下载最新的NER模型
bin/ingest-opennlp/download-models
执行时,可能会提示脚本路径不对等问题。
直接修改脚本文件改正即可。
wget http://opennlp.sourceforge.net/models-1.5/en-ner-person.bin
wget http://opennlp.sourceforge.net/models-1.5/en-ner-location.bin
wget http://opennlp.sourceforge.net/models-1.5/en-ner-date.bin
创建一个支持NLP的pipeline预处理通道,经过opennlp-pipeline的数据都会被提前处理
PUT _ingest/pipeline/opennlp-pipeline
{
"description": "A pipline to do named entity extraction",
"processors": [
{
"opennlp":{
"field":"message"
}
}
]
}
ingest的作用
在es cluster中每个node都会有分工,比如master,data,ingest等等,这个参考node的功能设置。
ingest就是其中的一种。
ingest 主要就是对indexing request进行预处理,
比如改变某个field的值,添加一两个field,忽略一些有问题的doc等。
也可以通过修改index的元数据字段_index来索引到不同的index当中。
添加两条常用的数据
PUT my-nlp-index/_doc/1?pipeline=opennlp-pipeline
{
"message":"Shay Banon announced the release of Elasticsearch 8.0 in NoveEmber"
}
PUT my-nlp-index/_doc/2?pipeline=opennlp-pipeline
{
"message":"Kobe Bryant was one of the best basketball players of all timesNot even Michael Jordan has ever scored 81 points in one game. Munich isreally an awesome city, but New York is as well. Yesterday has been thehottest day of the year"
}
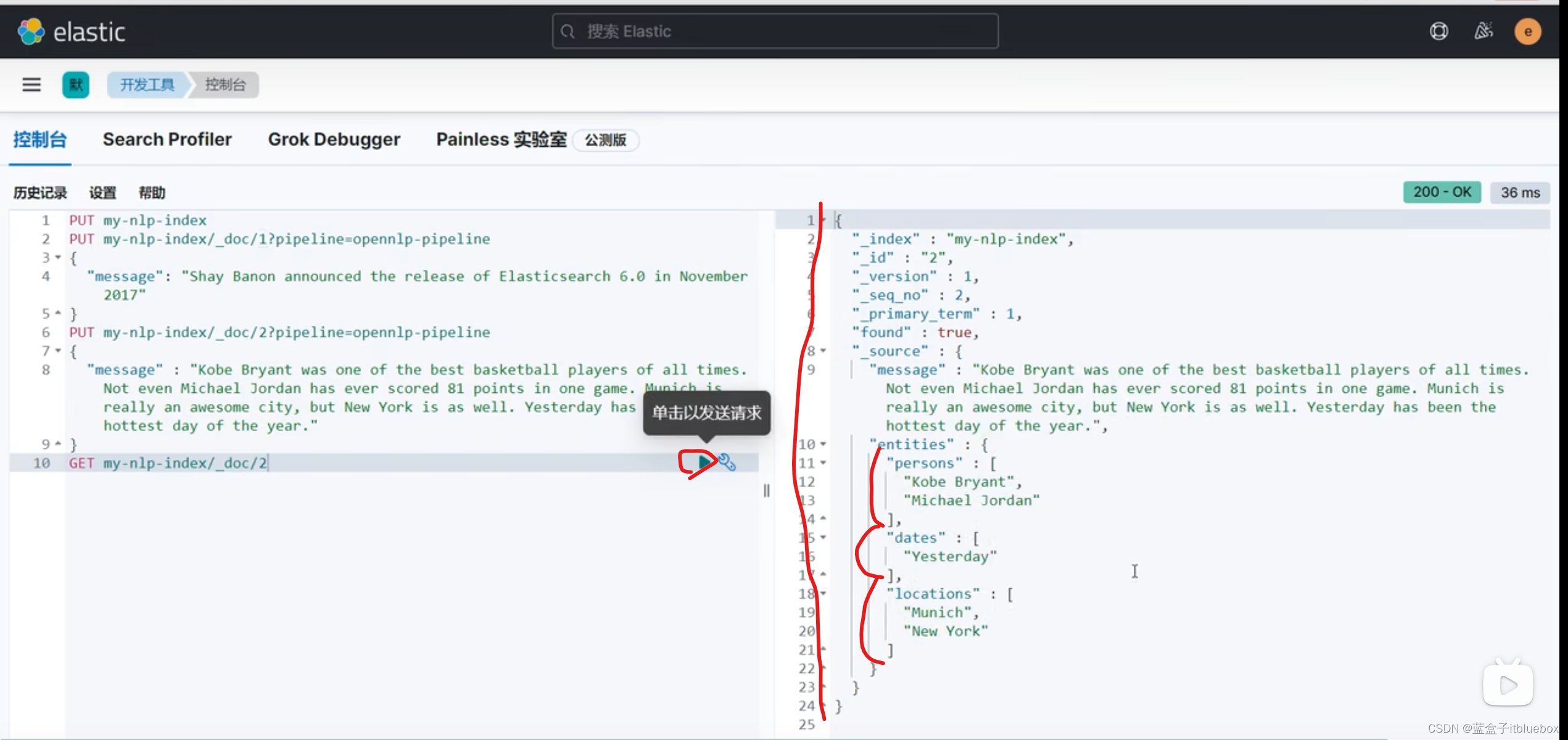
查询
GET my-nlp-index/_doc/2
识别出来了Date,Person,Location






![[CISCN2019 华北赛区 Day1 Web2]ikun](https://img-blog.csdnimg.cn/fbdd8952efec48fab93a5af5f40c911b.png)