文章目录
- 前言
- 推荐系统定义
- 基本分类
- 相似度计算
- 欧式距离
- 皮尔逊系数
- 余弦相似度
- 协同过滤
- 案例
- 数据定义
- 相似度计算
- 推荐
- svd奇异值分解优化
- 完整代码
- 总结
前言
打瞌睡遇到送枕头的感觉真爽嘿嘿 @BoyC啊
废话不多说,开始吧。
推荐系统定义
推荐系统(Recommendation System, RS),就是根据用户的日常行为,自动预测用户的喜好,为用户提供更多完善的服务。例如给DY上的小姐姐疯狂点赞此时DY会疯狂推送小姐姐,那么我们这边也是这样的。
基本分类
主要可以分为以下两类:
- 基于内容(content-based)的推荐。主要依据的是推荐项的性质。
- 基于协同过滤(collaborative filtering)的推荐。主要依据的是用户或者项之间的相似性。
此外基于协同过滤的推荐系统用可以分为两类:
- 基于项的推荐系统。主要依据的是项与项之间的相似性。
- 基于用户的推荐系统。主要依据的是用户与用户之间的相似性。
所以我们的推荐算法,推荐系统大体上就是做这几件事情,基于用户时,找到和你趣味相投的小伙伴,通过这个小伙伴有的去补齐你没有的,举个例子,假设你喜欢刷小姐姐,但是你没有关注A主播,此时系统发现有个其他和你相似的用户都关注了A,那么下次就给你推荐A。那么基于项,这个类似,看你对于项的定义,总之,就是找到和当前有的类似的玩意,然后按照评分给你推荐,比如你刷视频的时候发现你对科技频道很感兴趣,那么此时,把和科技频道相似的例如数学频道推荐给你。
相似度计算
那么在我们这边比较核心的地方就是咱们的一个相似度的一个计算。那么这里的话有几个方法。
欧式距离
这个就不用我多说了吧,例如Lmeans用的比较多的一个方法,直接分类是吧。
皮尔逊系数
这个也不用我多说了吧:
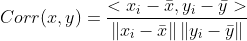
高中数学就已经开始见面了的东西。
余弦相似度
这个就更简单了,把两个东西,变成一个向量,计算向量夹角的值,然后的话,越相似越接近1.
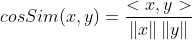
协同过滤
ok,此时的话,基本的概念是说完了,那么接下来说一说神马是协同过滤这个玩意。
这个东西其实容易理解。首先我们还是来好好解释一下这个名词的意思,首先什么是协同,过滤的话很好理解,我们的推荐算法本身就是在做一种过滤嘛。那么协同呢,我们把这两个字拆开来理解,说白了就是,联合,相同,联合类似的事物进行推断,之后过滤出可信度最高的一组结果。
所以我们基本上可以开始梳理出一套流程,那就是:
在猜测你喜欢啥的时候,例如推测你喜欢谁,那么此时我们的流程是这样子的
- 看看你的情史(你的历史数据/最近操作,点赞收藏等等)
- 根据你的情史,去找找和你有类似经历的家伙,查看这些家伙现在和什么样的女生在一起(找和你类似的用户)
- 找出和你情况最类似的几个家伙,看看他们现在和什么女生在一块(假设这些人存在,这里请不要带入你自己,我知道你没有)(找出相似度较高的一组用户的喜好的标签之类的数据)
- 判断那些家伙和那些女孩是不是达到了情侣程度,在筛选一次,找出那些家伙中的女朋友(选出了相似度高的用户喜好的标签后,筛选出他们最喜欢的几组标签)
- 结合那些女孩的特点,在你熟悉的圈子里面找到你最有可能喜欢的女孩(拿到推荐标签,到具体服务里面找到实际的数据)
那么这个就是一个基本大致的流程,这里不要对号入座哈,相信自己,你绝对是和我一样的!
案例
那么接下来,我们来玩玩这个。这里的话我们来玩玩这个基于用户的过滤,这里我们还是拿那个上面的例子举个栗子吧,就是假设咱们有一个脱单App,现在有一些数据,我们现在要做一个匹配(给你推荐什么类型的女孩子是适合你的)
但是咱们这块的话简化一下流程,先前是还要找到和你相似的家伙,现在的话简化一下,我们假设数据是这样的:

我们这边就只是说,根据你目前在这个脱单App产生的一些数据,例如上面表中表示的是,当前这个用户点在了上面类型女孩多少次。我们这边通过这些你点赞的女孩类型去推测你会对哪些类型感兴趣。这个时候你可能会说了,我都点赞了,我肯定是对点赞的女孩类型感兴趣了,如果不是喜欢谁TM天天看咧,但是怎么说呢,你当前喜欢这些女孩类型可能只是你目前只能接触到这些女生或者男生,有可能有更好的你压根没有接触到(等等党,不吃亏)那么这个时候,我是不是可能根据别的用户,别的一些也对你当前点赞了的女孩类型的用户,他们所喜欢的其他的类型的女孩进行一个拓展推荐,甚至就是说,我们发现你当前点赞了女孩类型9,此时我们发现点赞了9这个类型的用户都点赞了类型1,并且点赞的次数远远大于类型9,那么是不是有可能是说类型1可能会更好?
所以这个就是咱们的这个推荐的一个逻辑。
ok,那么首先对于这个我们要做的其实很简单,咱们这里的话其实有两个方案。
- 基于用户去推荐,看看相似的用户喜欢啥类型
- 直接基于标签类型去做,看看相似的标签还有那些
但是不管是哪一种,咱们都是基于这个目前的数据去做的。
那么咱们这边的话就是直接基于这个第2点去做吧。
数据定义
我们看到数据定义的代码:
data_ = [[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
feature = ["女孩类型"+str(i) for i in range(1,len(data_[0])+1)]
users = ["用户" + str(i) for i in range(1,len(data_)+1)]
data = np.mat(data_)
df = pd.DataFrame(data, columns=feature, index=users)
print("测试数据为:")
print(df)

相似度计算
咱们的相似度是基于这个用户的点赞来算的,群众的眼睛是雪亮的嘛。
def cos_sim(self,x, y):
"""
计算余弦值(相似度
:param x:
:param y:
:return:
"""
return ((x * y.T) / (np.sqrt(x * x.T) * np.sqrt(y * y.T)))[0, 0]
def similarity(self,data):
"""
计算相似度
:return:
"""
m = np.shape(data)[0]
simil = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
simil[i, j] = self.cos_sim(data[i, :], data[j, :])
simil[j, i] = simil[i, j]
else:
simil[i, j] = 0
return simil
这里用的是cos,计算简单一点。
推荐
咱们现在有了这个相似度,我们的相似度矩阵是一个二维的,此时表示的是类别之间的一个关系。
那么此时传入一个用户当前喜欢哪一些类型,计算出这些类型相似的标签,然后做出一个排序,推荐。
def __recommend(self,data, simil, user):
"""
根据当前的用户进行一个推荐,通过咱们的这个
相似度矩阵,然后进行评分
:param data:
我们这边是对用户喜欢的女孩类型进行推荐,所以data做了一个转置
:param simil:
相似度矩阵,我们这里做的是不同女孩类型的相似度
:param user:
要知道哪些用户的一个推荐
:return:
interaction: 互动(其实就是原来的表)
"""
m, n = np.shape(data)
interaction = data[:, user].T
predict = {}
not_inter = []
for i in range(n):
# 用户没有点赞的类型
if interaction[0, i] == 0:
not_inter.append(i)
else:
predict[i] = interaction[0,i]
# 对点赞进行预测
for x in not_inter:
for j in range(m):
if interaction[0, j] != 0:
if x not in predict:
predict[x] = simil[x, j] * interaction[0, j]
else:
predict[x] = predict[x] + simil[x, j] * interaction[0, j]
# 按照预测的评分大小从大到小排序
return sorted(predict.items(), key=lambda d: d[1], reverse=True)
如果你想基于用户也简单,反一下。
此时我们还可以筛选出前面几个
def RecomtopK(self,user,k):
"""
推荐前面K个
:param predict:
:param k:
:return: 返回适合的类型的下标以及对应的评分
"""
data_T = self.data.T
if(self.simil.all()==None):
raise Exception("请先build")
predict = self.__recommend(data_T, self.simil, user)
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])
return top_recom
svd奇异值分解优化
之后的话,咱们这里还涉及到一个优化,就是这个svd,主要是计算咱们的这个相似度矩阵的时候的一个优化,通过svd,可以对原来的矩阵进行一个压缩,之后的加速运算得到相似度矩阵。
因为这个协同过滤其实最重要的就是计算出相似度矩阵,之后通过这个矩阵进行一个搜索过滤。
def __svd(self,data,threshold=0.9):
"""
:param data:
:param threshold: 保留多少特征
:return:
"""
n = np.shape(data)[1]
U, Sigma, VT = np.linalg.svd(data)
sig2 = Sigma ** 2
cut = 0
for i in range(n):
if sum(sig2[:i]) / sum(sig2) > threshold :
cut = i
break
Sig4 = np.mat(np.eye(cut) * Sigma[:cut])
xformedItems = data.T * U[:, :cut] * Sig4.I
svd_data = xformedItems.T
return svd_data
完整代码
之后是完整的代码:
import numpy as np
import pandas as pd
class RecmBaseDome(object):
def __init__(self,data):
self.data = data
self.simil = None
def cos_sim(self,x, y):
"""
计算余弦值(相似度
:param x:
:param y:
:return:
"""
return ((x * y.T) / (np.sqrt(x * x.T) * np.sqrt(y * y.T)))[0, 0]
def similarity(self,data):
"""
计算相似度
:return:
"""
m = np.shape(data)[0]
simil = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
simil[i, j] = self.cos_sim(data[i, :], data[j, :])
simil[j, i] = simil[i, j]
else:
simil[i, j] = 0
return simil
def __recommend(self,data, simil, user):
"""
根据当前的用户进行一个推荐,通过咱们的这个
相似度矩阵,然后进行评分
:param data:
我们这边是对用户喜欢的女孩类型进行推荐,所以data做了一个转置
:param simil:
相似度矩阵,我们这里做的是不同女孩类型的相似度
:param user:
要知道哪些用户的一个推荐
:return:
interaction: 互动(其实就是原来的表)
"""
m, n = np.shape(data)
interaction = data[:, user].T
predict = {}
not_inter = []
for i in range(n):
# 用户没有点赞的类型
if interaction[0, i] == 0:
not_inter.append(i)
else:
predict[i] = interaction[0,i]
# 对点赞进行预测
for x in not_inter:
for j in range(m):
if interaction[0, j] != 0:
if x not in predict:
predict[x] = simil[x, j] * interaction[0, j]
else:
predict[x] = predict[x] + simil[x, j] * interaction[0, j]
# 按照预测的评分大小从大到小排序
return sorted(predict.items(), key=lambda d: d[1], reverse=True)
def __svd(self,data,threshold=0.9):
"""
:param data:
:param threshold: 保留多少特征
:return:
"""
n = np.shape(data)[1]
U, Sigma, VT = np.linalg.svd(data)
sig2 = Sigma ** 2
cut = 0
for i in range(n):
if sum(sig2[:i]) / sum(sig2) > threshold :
cut = i
break
Sig4 = np.mat(np.eye(cut) * Sigma[:cut])
xformedItems = data.T * U[:, :cut] * Sig4.I
svd_data = xformedItems.T
return svd_data
def build(self,svd=True,threshold=0.9):
"""
构建这个推荐系统(表)
:param svd: 要不要使用svd对数据进行一个压缩
:param threshold:
:return:
"""
svd_data = self.data
if(svd):
svd_data = self.__svd(self.data,threshold)
svd_data = svd_data.T
self.simil = self.similarity(svd_data)
def RecomtopK(self,user,k):
"""
推荐前面K个
:param predict:
:param k:
:return: 返回适合的类型的下标以及对应的评分
"""
data_T = self.data.T
if(self.simil.all()==None):
raise Exception("请先build")
predict = self.__recommend(data_T, self.simil, user)
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])
return top_recom
if __name__ == '__main__':
data_ = [[0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
feature = ["女孩类型"+str(i) for i in range(1,len(data_[0])+1)]
users = ["用户" + str(i) for i in range(1,len(data_)+1)]
data = np.mat(data_)
df = pd.DataFrame(data, columns=feature, index=users)
print("测试数据为:")
print(df)
#每次上面那个pd就是拿来看的
recbase = RecmBaseDome(data)
recbase.build()
top_recom = recbase.RecomtopK(0,3)
print(top_recom)
#接下来看看这个用户0(用户1)适合的类型是啥
items = []
for top in top_recom:
items.append(feature[top[0]])
print(items)
之后是咱们的一个测试:

我们测试的是用户1
0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5
可以发现这个用户对于类型6的女孩也是有点赞的而且点赞了3次,但是top3却没有这个类型6。这个也印证了前面说的,可能更加适合的在后面,那么依据是什么呢,很简单“群众的眼睛是雪亮的”,类型6可能存在一定的问题,当然也有可能是说,你最先发现了类型6的好,她可能是影藏款,但是随着数据量加大,这种可能性还是比较低的。
总结
水完了一个dome,下班~