学习前请先掌握线段树:线段树(维护区间信息)
一,思想:
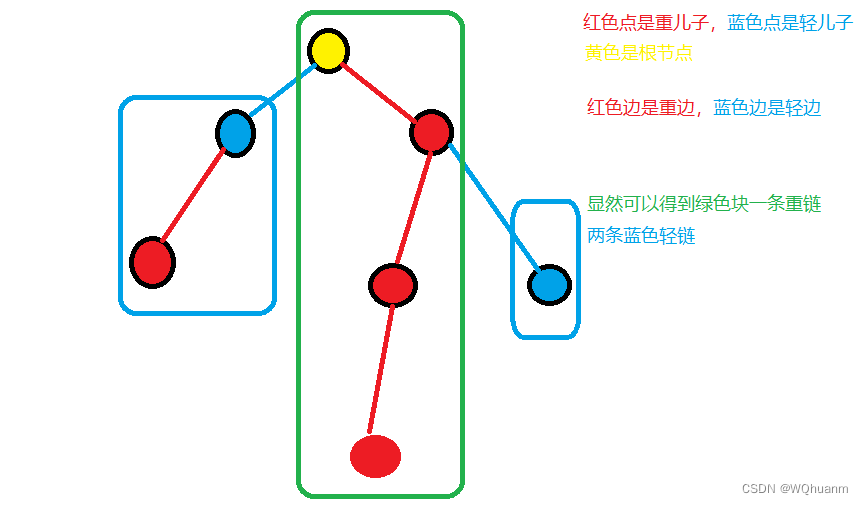
将一颗树拆成多条线性链以方便维护(如线段树)。
先给出以下定义(通过这些定义我们就可以组成链):
- 重儿子:子节点最多的儿子就是重儿子
- 轻儿子:除了重儿子,其余都是轻儿子
- 重边:连接重儿子的边。
- 轻边:除了重边,其余都是轻边
- 重链:这条链上的边都是重边
1,建树:
在dfs1中我们需要遍历这颗树,建立每个点的父子关系,并统计每个点的子节点数,从而得出其重儿子
void dfs1(int u, int f)
{
fa[u] = f;//存储u点父亲
dep[u] = dep[f] + 1;//深度是父亲深度+1
tot[u] = 1, son[u] = idx[u] = 0;//tot是子节点(包括自己)的数量,son是重儿子,idx是u的重新编号,对这3个初始化
int maxn = -1;
for (int i = head[u]; i; i = edge[i].next)
{
int v = edge[i].to;
if (v == f)continue;
dfs1(v, u);
tot[u] += tot[v];//增加u的子节点数
if (tot[v] > maxn)maxn = tot[v], son[u] = v;//更新重儿子
}
}2,重新编号形成线性链
- 我们要对一条线性链操作,显然要求链上的点连续。因此我们需要给点重新编号。即从跟节点开始,每次优先给重儿子编号,这样这颗树最后就形成(同一条链是的点编号连续(因为优先给重儿子编号且优先以重儿子建链)并且子树内的点也是连续的)。
- 当然,我们需要知道链的端点,所以我们每个点都存储他所在链的顶点top。
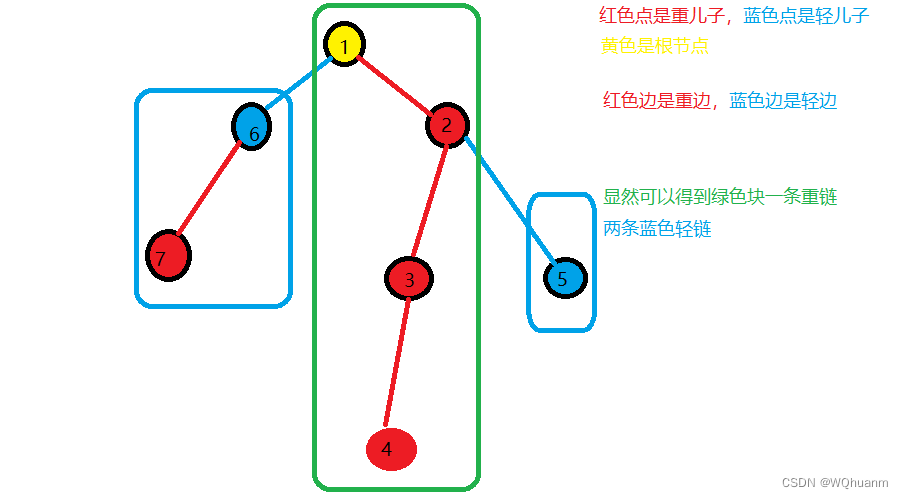
我们dfs2实现的功能就是新编号,并记录每个点的top。观察上图我们发现,轻儿子就是一条新链的开端,所以他开新链时自己就是top
void dfs2(int u, int topfa)
{
top[u] = topfa;//记录链顶点
idx[u] = ++cnt;//新编号,从根节点的1不断编号
a[cnt] = b[u];//把原来编号的值存入新编号的值
if (!son[u])return;//如果没用儿子就不用往下
dfs2(son[u], topfa);//有儿子先访问重儿子(重儿子优先编号)
for (int i = head[u]; i; i = edge[i].next)
{
int v = edge[i].to;
if (!idx[v])dfs2(v, v);//idx为0,说明没用编号(也说明一定不是重儿子),进行编号,v自己是轻链顶点
}
}3,树上更新操作
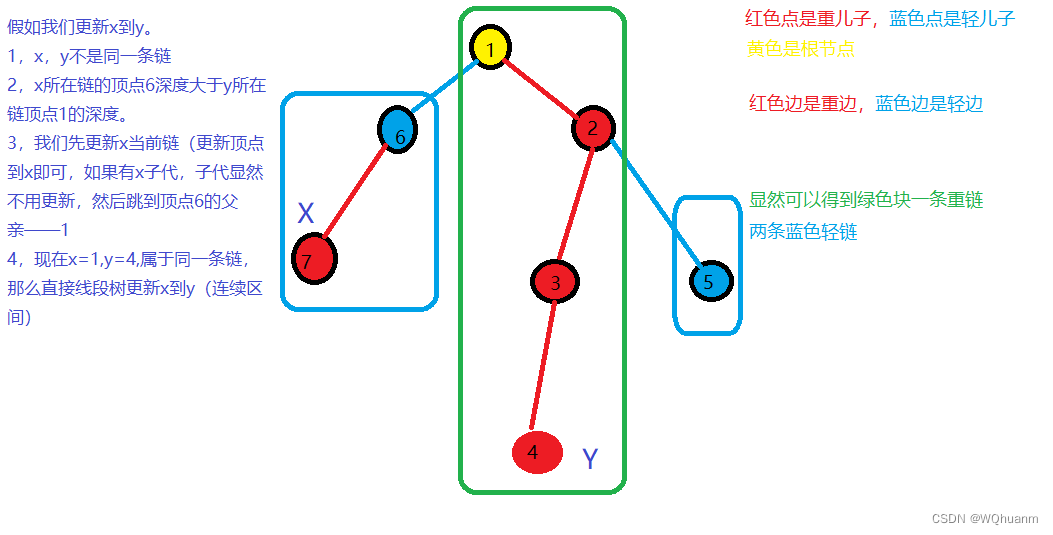
更新x到y:
- 如果x,y是同一条链,那他们在连续区间内,直接更新。
- 如果不是,我们显然是更新完当前链(优先更新深度大的链,这样才能不断将两条链往上跳),然后跳到链上方的链进行更新(与lca一个原理),直到新x,y是同一条链,进行操作1。
void treeadd(int x, int y, ll z)
{
while (top[x] != top[y])//不是同一条链,就更新到是为止
{
if (dep[top[x]] < dep[top[y]])swap(x, y);//为了方便,始终保持x所在链的顶点深度大(注意,比较的是顶点深度,不是x与y深度
update(idx[top[x]], idx[x], 1, z);//链是连续区间,直接线段树更新
x = fa[top[x]];//x成为顶点父亲
}
if (dep[x] > dep[y])swap(x, y);//出来后,为了方便,让x深度小,因为我们的线段树必须更新小编号到大编号
update(idx[x], idx[y], 1, z);
}4,树上查询
跟更新没什么区别
ll treeask(int x, int y)
{
ll ans = 0;
while (top[x] != top[y])//不是同一条链,就不断累加经过的链的区间的值
{
if (dep[top[x]] < dep[top[y]])swap(x, y);
ans = (ans + ask(idx[top[x]], idx[x], 1)) % mod;
x = fa[top[x]];
}
if (dep[x] > dep[y])swap(x, y);
ans = (ans + ask(idx[x], idx[y], 1)) % mod;
return ans % mod;
}5,求lca,因为我们树链建好,也可以用于求lca,很显然两个点同步到同一条链(都是不断往祖先跳),此时谁深度小谁就是他们的LCA
ll lca(int u, int v)
{
while (top[u] != top[v])
{
if (dep[top[u]] > dep[top[v]])u = fa[top[u]];//所在链顶点深度大的求往祖先跳
else v = fa[top[v]];
}
return dep[u] > dep[v] ? v : u;
}二,模板题:P3384 【模板】重链剖分/树链剖分
思路:
操作1,2上面都说过了。
操作3,4也很显然:我们说过,同一个子树是连续区间的点,如果父节点是x(线段树上编号idx[x]),那么树的最后一个点就是idx[x]+tot[x]-1。(tot[x]记录x子树上的节点数(包括x))。
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define int ll
const int N = 1e5 + 10;
int n, m, r, mod, num, cnt;
int head[N << 1], tot[N], dep[N], fa[N], son[N], top[N], idx[N];
int a[N], b[N];
struct node
{
int next, to;
} edge[N << 1];
struct tree
{
int l, r;
int sum, add;
} t[4 * N + 2];
void add(int u, int v)
{
edge[++num].next = head[u];
edge[num].to = v;
head[u] = num;
}
void dfs1(int u, int f)
{
fa[u] = f;//存储u点父亲
dep[u] = dep[f] + 1;//深度是父亲深度+1
tot[u] = 1, son[u] = idx[u] = 0;//tot是子节点(包括自己)的数量,son是重儿子,idx是u的重新编号,对这3个初始化
int maxn = -1;
for (int i = head[u]; i; i = edge[i].next)
{
int v = edge[i].to;
if (v == f)continue;
dfs1(v, u);
tot[u] += tot[v];//增加u的子节点数
if (tot[v] > maxn)maxn = tot[v], son[u] = v;//更新重儿子
}
}
void dfs2(int u, int topfa)
{
top[u] = topfa;//记录链顶点
idx[u] = ++cnt;//新编号,从根节点的1不断编号
a[cnt] = b[u];//把原来编号的值存入新编号的值
if (!son[u])return;//如果没用儿子就不用往下
dfs2(son[u], topfa);//有儿子先访问重儿子(重儿子优先编号)
for (int i = head[u]; i; i = edge[i].next)
{
int v = edge[i].to;
if (!idx[v])dfs2(v, v);//idx为0,说明没用编号(也说明一定不是重儿子),进行编号,v自己是轻链顶点
}
}
//---------以下是线段树代码-------//
void build(int l, int r, int p)
{
t[p].l = l, t[p].r = r;
if (l == r)
{
t[p].sum = a[l] % mod;
return;
}
int mid = l + ((r - l) >> 1);
build(l, mid, p << 1);
build(mid + 1, r, p << 1 | 1);
t[p].sum = (t[p << 1].sum + t[p << 1 | 1].sum) % mod;
}
void lazy(int p)
{
if (t[p].l == t[p].r)t[p].add = 0;
if (t[p].add)
{
t[p << 1].sum = (t[p << 1].sum + t[p].add * (t[p << 1].r - t[p << 1].l + 1)) % mod;
t[p << 1 | 1].sum = (t[p << 1 | 1].sum + t[p].add * (t[p << 1 | 1].r - t[p << 1 | 1].l + 1)) % mod;
t[p << 1].add = (t[p << 1].add + t[p].add) % mod;
t[p << 1 | 1].add = (t[p << 1 | 1].add + t[p].add) % mod;
t[p].add = 0;
}
}
void update(int l, int r, int p, ll z)
{
if (l <= t[p].l && t[p].r <= r)
{
t[p].sum = (t[p].sum + z * (t[p].r - t[p].l + 1)) % mod;
t[p].add = (t[p].add + z) % mod;
return;
}
lazy(p);
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
if (l <= mid)update(l, r, p << 1, z);
if (r > mid)update(l, r, p << 1 | 1, z);
t[p].sum = (t[p << 1].sum + t[p << 1 | 1].sum) % mod;
}
ll ask(int l, int r, int p)
{
if (l <= t[p].l && t[p].r <= r)return t[p].sum % mod;
lazy(p);
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
ll ans = 0;
if (l <= mid)ans = (ans + ask(l, r, p << 1)) % mod;
if (r > mid)ans = (ans + ask(l, r, p << 1 | 1)) % mod;
return ans;
}
//------以上是线段树代码------//
void treeadd(int x, int y, ll z)
{
while (top[x] != top[y])//不是同一条链,就更新到是为止
{
if (dep[top[x]] < dep[top[y]])swap(x, y);//为了方便,始终保持x所在链的顶点深度大(注意,比较的是顶点深度,不是x与y深度
update(idx[top[x]], idx[x], 1, z);//链是连续区间,直接线段树更新
x = fa[top[x]];//x成为顶点父亲
}
if (dep[x] > dep[y])swap(x, y);//出来后,为了方便,让x深度小,因为我们的线段树必须更新小编号到大编号
update(idx[x], idx[y], 1, z);
}
ll treeask(int x, int y)
{
ll ans = 0;
while (top[x] != top[y])//不是同一条链,就不断累加经过的链的区间的值
{
if (dep[top[x]] < dep[top[y]])swap(x, y);
ans = (ans + ask(idx[top[x]], idx[x], 1)) % mod;
x = fa[top[x]];
}
if (dep[x] > dep[y])swap(x, y);
ans = (ans + ask(idx[x], idx[y], 1)) % mod;
return ans % mod;
}
//这模板题用不到
ll lca(int u, int v)
{
while (top[u] != top[v])
{
if (dep[top[u]] > dep[top[v]])u = fa[top[u]];//所在链顶点深度大的求往祖先跳
else v = fa[top[v]];
}
return dep[u] > dep[v] ? v : u;
}
int32_t main()
{
cin >> n >> m >> r >> mod;
for (int i = 1; i <= n; ++i)cin >> b[i];
int h, x, y, z;
for (int i = 1; i < n; ++i)
{
cin >> x >> y;
add(x, y), add(y, x);
}
dfs1(r, 0);
dfs2(r, r);
build(1, n, 1);
while (m--)
{
cin >> h;
if (h == 1)
{
cin >> x >> y >> z;
treeadd(x, y, z);
}
else if (h == 2)
{
cin >> x >> y;
cout << treeask(x, y) << endl;
}
else if (h == 3)
{
cin >> x >> z;
update(idx[x], idx[x] + tot[x] - 1, 1, z);
}
else if (h == 4)
{
cin >> x;
cout << ask(idx[x], idx[x] + tot[x] - 1, 1) << endl;
}
}
return 0;
}三:例题:The LCIS on the Tree
思路:
很考验细节...
重点就是对区间合并时的操作与区间的维护
我们对于一段区间需要维护
fl:左降序,sl:左升序,fr:右降序,sr:右升序
左右端点值:lnum,rnum
区间边界:l,r
区间降序最大长度:fmaxn,区间升序最大长度:smaxn
区间节点数:size(用于决定该区间是否为空)
#include <bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 1e5 + 10;
int a[N], b[N], top[N], tot[N], dep[N], head[N], son[N], fa[N], idx[N];
int num, cnt, n, m;
struct node
{
int next, to;
} edge[N];
struct tree
{
int l, r, lnum, rnum, size;
int fl, fr, sl, sr;
int fmaxn, smaxn;
void init()
{
lnum = rnum = fl = fr = sl = sr = size = fmaxn = smaxn = 0;
}
void reverse()//用于把这个tree区间左右信息互换
{
swap(fl, sr), swap(sl, fr), swap(lnum, rnum);
swap(fmaxn, smaxn);
}
} t[4 * N];
void add(int u, int v)
{
edge[++num].next = head[u];
edge[num].to = v;
head[u] = num;
}
void init()
{
memset(head, 0, sizeof(head));
num = cnt = 0;
}
void dfs1(int u, int f)
{
fa[u] = f;
dep[u] = dep[f] + 1;
tot[u] = 1, son[u] = idx[u] = 0;
int maxn = -1;
for (int i = head[u]; i; i = edge[i].next)
{
int v = edge[i].to;
if (v == f)continue;
dfs1(v, u);
tot[u] += tot[v];
if (tot[v] > maxn)maxn = tot[v], son[u] = v;
}
}
void dfs2(int u, int topfa)
{
top[u] = topfa;
idx[u] = ++cnt;
a[cnt] = b[u];
if (!son[u])return;
dfs2(son[u], topfa);
for (int i = head[u]; i; i = edge[i].next)
{
int v = edge[i].to;
if (!idx[v])dfs2(v, v);
}
}
tree unit(tree l, tree r)
{
if (!l.size)return r;//如果左树没用节点(为空),那直接放回右部分即可
if (!r.size)return l;//同理
tree t;
t.l = l.l, t.r = r.r;
t.size = l.size + r.size;//sized等于左边加右边
t.lnum = l.lnum, t.rnum = r.rnum;
t.fl = l.fl;
if (l.fl == l.size && l.rnum > r.lnum)t.fl += r.fl;
t.sl = l.sl;
if (l.sl == l.size && l.rnum < r.lnum)t.sl += r.sl;
t.fr = r.fr;
if (r.fr == r.size && l.rnum > r.lnum)t.fr += l.fr;
t.sr = r.sr;
if (r.sr == r.size && l.rnum < r.lnum)t.sr += l.sr;
//以降序fmaxn为例,更新时要么去左边的fmaxn,要么右边的fmaxn,要么如果两边符合端点l.rnum > r.lnum,则可以多算中间一段
t.fmaxn = max(l.fmaxn, max(r.fmaxn, (l.rnum > r.lnum ? l.fr + r.fl : 0)));
t.smaxn = max(l.smaxn, max(r.smaxn, (l.rnum < r.lnum ? l.sr + r.sl : 0)));
return t;
}
void change(int p)
{
t[p] = unit(t[p << 1], t[p << 1 | 1]);
}
void build(int l, int r, int p)
{
t[p].l = l, t[p].r = r;
if (l == r)
{
t[p].lnum = t[p].rnum = a[l];
t[p].size = t[p].fmaxn = t[p].smaxn = t[p].fl = t[p].sl = t[p].sr = t[p].fr = 1;
return ;
}
int mid = l + ((r - l) >> 1);
build(l, mid, p << 1);
build(mid + 1, r, p << 1 | 1);
change(p);
}
tree ask(int l, int r, int p)
{
if (l <= t[p].l && t[p].r <= r)return t[p];
int mid = t[p].l + ((t[p].r - t[p].l) >> 1);
//如果l,r范围只在左右区间一边,直接返回那一边得到的tree即可
if (r <= mid)return ask(l, r, p << 1);
if (l > mid)return ask(l, r, p << 1 | 1);
tree t, tl, tr;
tl = ask(l, r, p << 1), tr = ask(l, r, p << 1 | 1);
return (t = unit(tl, tr));
}
int treeask(int x, int y)
{
bool flag = 0;
tree l, r;
//我们刚刚开始tree是空的,记得初始化,否则与别人连接出问题
l.init();
r.init();
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])swap(x, y), swap(l, r), flag ^= 1;//x,y每次翻转记录一下
tree tmp = ask(idx[top[x]], idx[x], 1);
l = unit(tmp, l);//越往上的段在左边
x = fa[top[x]];
}
if (dep[x] > dep[y])swap(x, y), swap(l, r), flag ^= 1;
tree tmp = ask(idx[x], idx[y], 1);//x深度小于y,则这一段跟y的链拼接
r = unit(tmp, r);
if (flag)swap(l, r);//如果翻转奇数次,那么我们最后得出结果是y->x,所以我们需要否则回来
l.reverse();//最后是x的顶端拼接y的端点,显然需要将x左右翻转
return unit(l, r).smaxn;
}
int main()
{
std::ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
int t, x, y;
cin >> t;
for (int ti = 1; ti <= t; ++ti)
{
init();
cin >> n;
for (int i = 1; i <= n; ++i)cin >> b[i];
for (int i = 2; i <= n; ++i)
{
cin >> x;
add(x, i);
}
dfs1(1, 0);
dfs2(1, 1);
build(1, n, 1);
cin >> m;
cout << "Case #" << ti << ":" << endl;
while (m--)
{
cin >> x >> y;
cout << treeask(x, y) << endl;
}
if (ti < t)cout << endl;
}
return 0;
}
![Windows 右键菜单扩展容器 [开源]](https://img-blog.csdnimg.cn/img_convert/ac38ccbcadc02ede7033f160708a1f07.png)