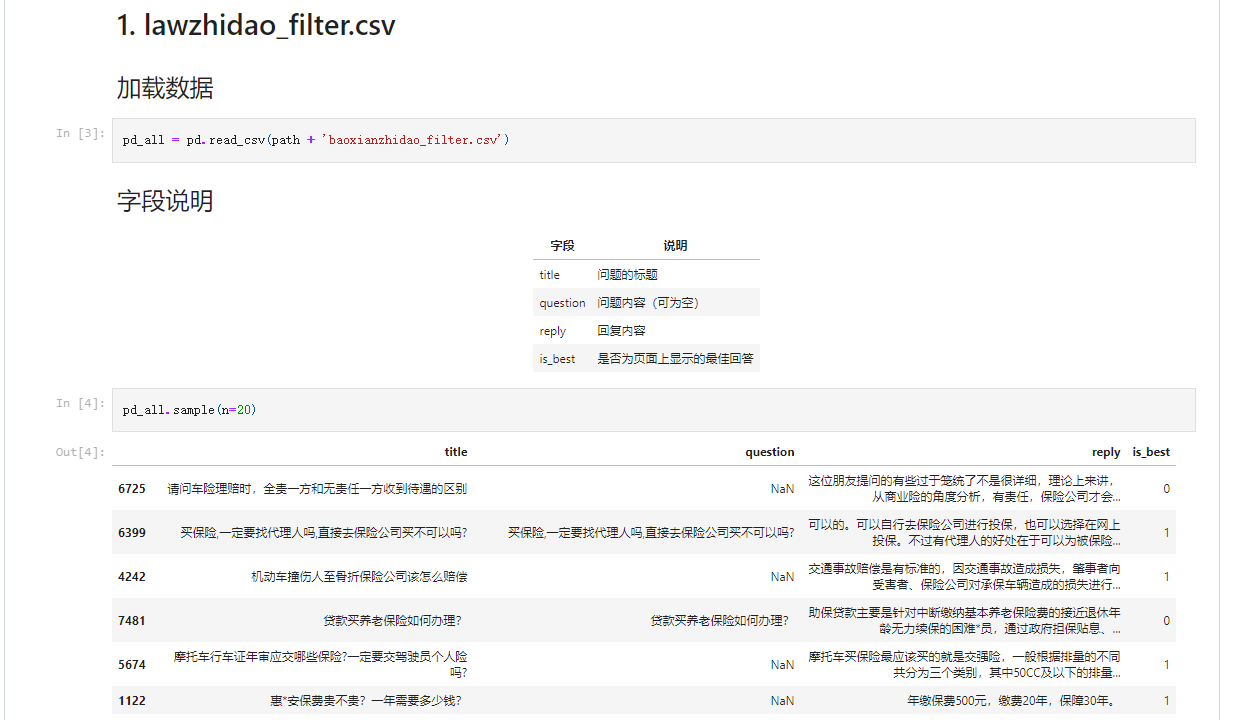
论文阅读–NeRF Representing Scenes as Neural Radiance Fields for View Synthesis
这是 2020 ECCV 的一篇文章,记得好像还获得了最佳论文奖的提名,这篇文章相当于将自由视点生成这个方向开辟出了一个新的解决思路。
文章的作者们提出了一种可以对复杂场景进行新视点生成的方法,这个方法只需要少量的不同视角的输入,通过优化一个潜在的连续体场景函数,从而可以对复杂场景的新视角进行渲染,获得非常逼真的渲染效果。文章中的方法将场景用一个全连接的深度网络来表征,该网络的输入是单个的 5 维的连续坐标,包括 3 个空间坐标 x , y , z x, y, z x,y,z 以及两个方向坐标 θ , ϕ \theta, \phi θ,ϕ,深度网络的输出是体密度以及与视角相关的在某个空间位置上的辐射场。在合成新视角的时候,通过查询沿相机光线方向的 5 维坐标,然后再利用经典的体渲染技术将输出的颜色投射到输出图像上。因为体渲染本身是可微的,为了优化这个网络,唯一需要的输入就是已知相机位姿的一组图像。这篇文章相比以前的方法,能够对复杂场景的几何及纹理信息进行影像级的渲染。
首先,文章作者将一个静态场景用一个连续的 5 维函数来表征,这个 5 维的函数在空间中会输出任意位置 ( x , y , z ) (x,y,z) (x,y,z) 及任意方向的 ( θ , ϕ ) (\theta, \phi) (θ,ϕ) 辐照值,同时输出每个点处的一个密度值,表示环境的透光程度,这个密度值也是可微的,文章中的方法构建了一个全连接网络来表示这样一个 5 维函数,全连接网络的输入就是一个 5 维坐标 ( x , y , z , θ , ϕ ) (x,y,z,\theta,\phi) (x,y,z,θ,ϕ),输出就是一个单一的体密度值以及与视角相关的颜色值。为了能够沿着某个特定的方向进行 neural radiance field (NeRF) 的渲染,文章主要通过三个步骤,1)沿着相机的视角方向生成一组 3D 点,2) 利用这些点和对应的 2D 的视角方向输入神经网络中得到一组颜色和密度值,3) 利用经典的体渲染技术将这些颜色和密度值渲染得到一张 2D 图像。整个过程都是可微的,所以可以利用梯度下降进行优化,损失函数就是渲染得到的图像与真实图像的差值。

- 插入图片 Fig.2
文章中也提到,这个基本的技术实现无法对复杂场景渲染得到高分辨率的图像,对相机的每根光线无法得到足够的采样点。为了解决这个问题,文章中将 5 维的坐标转换成一个位置编码,以使得全连接函数(MLP)可以表征更高频的函数,此外,文章作者提出层级采样的策略,以减少生成高频信息丰富的场景所需要的采样点数量。
Neural Radiance Field Scene Representation
文章中将一个场景用一个连续的 5 维函数来表征,这个函数的输入包括一个3维的空间坐标 x = ( x , y , z ) \mathbf{x}=(x,y,z) x=(x,y,z) 以及两个方向坐标 ( θ , ϕ ) (\theta, \phi) (θ,ϕ),函数的输出就是该点的颜色值 c = { r , g , b } \mathbf{c}=\{r,g,b\} c={r,g,b} 以及体密度 σ \sigma σ,实际实现的时候,文章中将方向坐标表示为 3 维的归一化的笛卡尔坐标 d \mathbf{d} d。这个连续的 5 维函数就是用一个 MLP 来近似,整个的输入输出就可以表示为如下所示:
F Θ : ( x , d ) → ( c , σ ) F_{\Theta}: (\mathbf{x}, \mathbf{d}) \to (\mathbf{c}, \sigma) FΘ:(x,d)→(c,σ)
需要优化 MLP 的参数 Θ \Theta Θ, 使得每一个输入都能映射到对应的输出上。
作者也希望这个表征在多个视角之间是连续的,在具体实现上,体密度 σ \sigma σ 只由空间坐标 x \mathbf{x} x 决定,然后颜色值 c \mathbf{c} c 才由空间坐标与方向坐标一起决定。所以这个 MLP 在架构上首先是只输入空间坐标 x \mathbf{x} x,然后经过 8 个全连接层,每一层都是 256 个神经元,得到体密度 σ \sigma σ 值以及一个 256 维的特征向量,这个特征向量和方向坐标连接在一起,在经过一个全连接层,这个全连接层是 128 个神经元,输出颜色值。
Volume Rendering with Radiance Fields
如前面所述,MLP 只是估计环境中的辐射场,整个辐射场用色彩值以及体密度值表示,得到辐射场之后,需要利用经典的体渲染技术进行渲染,才能得到最终的 2D 图像。体密度 σ ( x ) \sigma(\mathbf{x}) σ(x) 可以表示为光线被一个无穷小粒子挡住的概率,光线 r ( t ) = o + t d \mathbf{r}(t)=\mathbf{o}+t\mathbf{d} r(t)=o+td 在一个范围内的色彩值可以表示为:
C ( r ) = ∫ t n t f T ( t ) σ ( r ( t ) ) c ( r ( t ) , d ) d t C(\mathbf{r}) = \int_{t_n}^{t_f} T(t)\sigma(\mathbf{r}(t))\mathbf{c}(\mathbf{r}(t),\mathbf{d})dt C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dt
其中, T ( t ) = exp ( − ∫ t n t f σ ( r ( s ) ) d s ) T(t) = \exp(-\int_{t_n}^{t_f}\sigma(\mathbf{r}(s))ds) T(t)=exp(−∫tntfσ(r(s))ds) 表示光线沿着某一段路径的积分,也表示光线在这段路径中没有遇到任何遮挡的概率。从连续的神经辐射场中渲染一个视角,需要对每个像素发出的光线进行这样的积分运算。文章中将这样一个连续积分转化成了离散的求和,利用一个分层抽样的策略,将范围 [ t n , t f ] [t_n, t_f] [tn,tf] 均匀地分成 N 份,然后基于均匀分布的概率,每次从这 N 个点中随机抽取一个
t i ∼ U [ t n + i − 1 N ( t f − t n ) , t n + i N ( t f − t n ) ] t_i \sim \mathcal{U} \left[t_n + \frac{i-1}{N}(t_f - t_n), t_n + \frac{i}{N}(t_f - t_n) \right] ti∼U[tn+Ni−1(tf−tn),tn+Ni(tf−tn)]
利用一组离散的采样来代替积分,进而可以得到:
C ( r ) ^ = ∑ i = 1 N T i ( 1 − exp ( − σ i δ i ) ) c i \hat {C(\mathbf{r})} = \sum_{i=1}^{N} T_i(1 - \exp(-\sigma_{i}\delta_{i}))\mathbf{c}_i C(r)^=i=1∑NTi(1−exp(−σiδi))ci
其中, T i = exp ( − ∑ j = 1 i − 1 σ j δ j ) T_{i} = \exp\left(-\sum_{j=1}^{i-1}\sigma_{j}\delta_{j} \right) Ti=exp(−∑j=1i−1σjδj), δ i = t i + 1 − t i \delta_{i} = t_{i+1} - t_i δi=ti+1−ti 表示相邻两个采样的距离,通过这样的离散化,这个求和过程变得可微。
Optimizing a Neural Radiance Field
前面介绍了基本的技术思路,在实际测试的时候,发现对于复杂的场景,这样的渲染并不能得到令人满意的效果,所以文章作者接下来做了几点改进,一个是位置编码,一个是层级采样。
Positional encoding
虽然理论上来说,神经网络的拟合能力已经非常强大了,不过在这个问题上,文章作者发现网络对场景的高频信息拟合地并不是很好,网络倾向于拟合场景的低频信息,为了让网络更好地拟合高频信息,文章中将函数拆成两个部分, F Θ = F Θ ′ ∘ γ F_{\Theta} = F'_{\Theta} \circ \gamma FΘ=FΘ′∘γ,这两部分一部分需要学习,另外一部分不需要学习,通过这样的拆解,整个函数的拟合能力得到很大提升,函数 γ \gamma γ 是一个映射,从 R \mathcal{R} R 到 R 2 L \mathcal{R}^{2L} R2L 的映射,具体的形式如下所示:
γ ( p ) = ( sin ( 2 0 π p ) , cos ( 2 0 π p ) , . . . , sin ( 2 L − 1 π p ) , cos ( 2 L − 1 π p ) ) \gamma(p) = \left(\sin(2^{0}\pi p), \cos(2^{0}\pi p), ..., \sin(2^{L-1}\pi p), \cos(2^{L-1}\pi p) \right) γ(p)=(sin(20πp),cos(20πp),...,sin(2L−1πp),cos(2L−1πp))
具体实现的时候,函数 γ \gamma γ 对空间位置坐标与方向坐标分别单独编码,对于位置编码,L=10,对于方向编码,L=4
Hierarchical volume sampling
进行体渲染的时候,文章作者发现对每根相机的光线等密度的进行采样并不合适,为了对不同的区域采用不同的采样方式,文章提出了一种层级采样的方式,一个 coarse 网络后面接一个 fine 网络,首先对需要渲染的区域进行采样,并利用 coarse 网络对这些区域进行评估,然后对需要更多采样的区域进行调整,为了实现这个设计,对之前的颜色值的渲染公式进行改写:
C ^ c ( r ) = ∑ i = 1 N c w i c i , w i = T i ( 1 − exp ( − σ i δ i ) ) \hat {C}_c(\mathbf{r})= \sum_{i=1}^{N_c} w_i\ c_i, \quad w_i = T_{i}(1 - \exp(-\sigma_{i}\delta_{i})) C^c(r)=i=1∑Ncwi ci,wi=Ti(1−exp(−σiδi))
对系数 w i w_i wi 进行归一化, w ^ i = w i / ∑ j = 1 N c w j \hat{w}_i = w_i / \sum_{j=1}^{N_c} w_j w^i=wi/∑j=1Ncwj,这样可以得到沿着光线的概率密度函数。然后,从这个分布中采样第二组,每根光线有 N f N_f Nf 个位置,最后将两次采样的光线都用 “fine” 网络进行评估,这个过程可以让想要显示的区域内容可以获得更多的采样点。
Implementation details
这篇文章在实现的时候,对每个场景,需要单独训练一个网络,每个场景的训练数据包括这个场景某些视角下的 RGB 图像以及这些图像对应的相机位姿以及相机内参,场景的范围。对于仿真数据,可以获得真实的 GT, 对于实际数据,可以用 COLMAP structure-from-motion package 估计。训练的时候,每次迭代,随机选择一定数量的光线,然后利用层级采样的策略,对于每根光线,从 coarse network 中获得 N c N_c Nc 个采样,从 fine network 中获得 N f + N c N_f + N_c Nf+Nc 个采样,然后再利用体渲染的技术,将这些采样渲染得到每根光线对应的色彩值。训练的损失函数就是简单的 L 2 L_2 L2 loss,同时考虑了 coarse network 和 fine network 的采样:
L = ∑ r ∈ R [ ∣ ∣ C ^ c ( r ) − C ( r ) ∣ ∣ 2 2 + ∣ ∣ C ^ f ( r ) − C ( r ) ∣ ∣ 2 2 ] \mathcal{L} = \sum_{r \in \mathcal{R}} \left[ || \hat{C}_c(r) - C(r) ||_{2}^{2} + || \hat{C}_f(r) - C(r) ||_{2}^{2} \right] L=r∈R∑[∣∣C^c(r)−C(r)∣∣22+∣∣C^f(r)−C(r)∣∣22]
其中, R \mathcal{R} R 表示每个 batch 的光线数量,$\hat{C}_c®, \hat{C}_f®,C® $ 分别表示 coarse network,fine network 以及真实的颜色值。
具体实现的时候,每个 batchsize = 4096,也就是采样 4096 条光线,然后每条光线,coarse network 生成 N c = 64 N_c = 64 Nc=64 个采样坐标,fine network 生成 N f = 128 N_f = 128 Nf=128 个采样坐标,利用 Adam 的训练策略,初始学习率为 5 e − 4 5e-4 5e−4,对于每个场景,需要迭代 100-200 千次,大概需要 1-2 天的时间。
具体的网络结构如下所示:
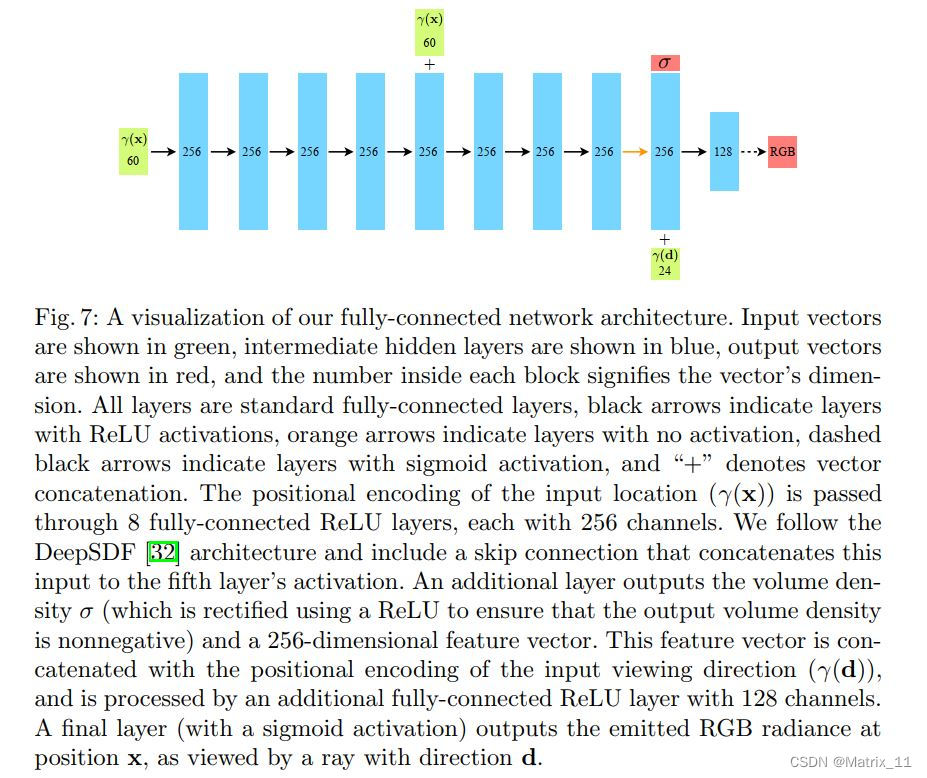
- 插入图片 Fig.7
可以看到,网络的输入是一个 60 维的向量,因为前面提到网络对空间坐标(3 维的向量)进行了编码,用的是三角函数, L = 10 L=10 L=10,每每一维的空间坐标编码成了一个 20 维的向量,3 维的空间坐标最终编码成了一个 60 维的向量。方向坐标也是如此, L = 4 L=4 L=4,每一维的方向坐标编码成了一个 8 维的向量,3 维的方向坐标最终编码成了一个 24 维的向量。从前面的介绍知道,文章用了两个网络,一个是 coarse 网络,一个是 fine 网络,我理解这两个网络结构应该是一样的,而且输入也是一样的,只是输出的采样坐标数量不同,所以文章中的损失函数也包括了两部分,一部分用于训练 coarse 网络,一部分用于训练 fine 网络。