引言
本文是七月在线《NLP中的对话机器人》的视频笔记,主要介绍FAQ问答型聊天机器人的实现。
场景二
上篇文章中我们解决了给定一个问题和一些回答,从中找到最佳回答的任务。
在场景二中,我们来实现: 给定新问题,从问答库中找到能回答该问题的最佳答案。
那怎么实现呢? 一种方案是直接匹配问题和答案,计算一个匹配分数,选出匹配分数最高的。
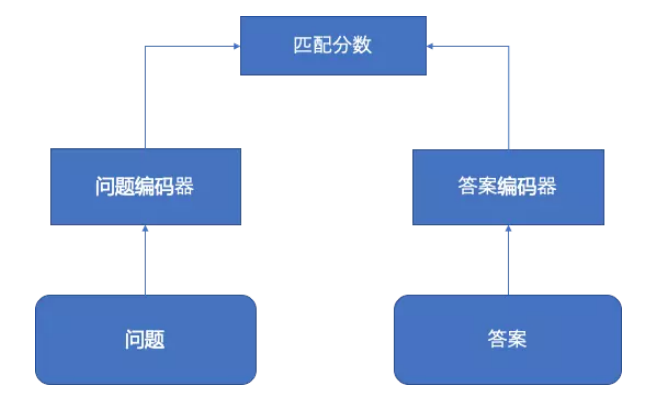
但是基于这些数据集上,这种方法的效果不佳。
另一种做法是类似相似问题检索,从问答库中找到给定问题的最相似的问题,用它的答案作为给定问题的答案。
那如何计算问题之间的相似度呢?
我们这里尝试两个简单的基准模型,分别是基于ELMo和BERT的语句表示,得到问题的句向量,然后通过余弦相似度来计算问题间的相似得分。
我们这里使用现成的ELMo和BERT模型。
ELMo基准模型
数据集
https://pan.baidu.com/s/1z1Rnnk-ubRSvzDu4UvLlIw

实现
可以使用哈工大的预训练的ELMo模型, 仓库为: https://github.com/HIT-SCIR/ELMoForManyLangs
选择简体中文版,可能仓库中的链接打不开,可以从百度云: https://pan.baidu.com/s/1RNKnj6hgL-2orQ7f38CauA?errno=0&errmsg=Aut 下载。
下载并解压之后,我们需要修改config.json当中的config_path参数,改成:configs/cnn_50_100_512_4096_sample.json,即去掉前面的../。
还要安装ELMoForManyLangs的包:
git clone https://github.com/HIT-SCIR/ELMoForManyLangs
cd ELMoForManyLangs
python setup.py install
在安装分词工具pkuseg。
上面步骤都做好之后,我们进行测试,看能否正常工作:
from elmoformanylangs import Embedder
import pkuseg
# 得到我们的elmo encoder
e = Embedder('zhs.model')
sents = ["今天天气真好啊",
"潮水退了就知道谁没穿裤子"]
seg = pkuseg.pkuseg()
sents = [seg.cut(sent) for sent in sents]
print(sents)
embeddings = e.sents2elmo(sents)
print(embeddings)
测试失败了吗,报错:
TypeError: Highway.forward: return type `<class 'torch.Tensor'>` is not a `<class 'NoneType'>`.
解决:
pip uninstall -y overrides
pip install overrides==3.1.0
再次运行,结果:
[['今天', '天气', '真', '好', '啊'], ['潮水', '退', '了', '就', '知道', '谁', '没', '穿', '裤子']]
[array([[ 0.07444969, 0.12170488, 0.18306534, ..., -0.27513036,
0.03082917, -0.6021218 ],
[-0.17950936, 0.3002583 , 0.41858768, ..., -0.7238658 ,
1.5381049 , -1.1729732 ],
[ 0.2640982 , 0.53036195, 0.6604749 , ..., 0.12223349,
0.5540275 , -0.50095123],
[ 0.5308723 , 0.05570847, 0.09236425, ..., -0.9979615 ,
0.13710646, -0.33056557],
[ 0.22956477, 0.43202046, -0.42210087, ..., -0.9834735 ,
0.0821436 , -0.15420763]], dtype=float32), array([[ 0.04015709, 0.42856467, 0.6768381 , ..., -0.10523877,
0.48780942, 0.00312402],
[ 0.5922051 , 0.21770744, 1.1809255 , ..., -0.12190163,
0.61034995, 0.1050753 ],
[ 0.614235 , -0.04580465, -0.03073702, ..., 0.34837866,
0.5443483 , 0.02076633],
...,
[ 0.76723504, 1.413464 , 1.071545 , ..., -1.464156 ,
0.5184709 , -0.5683145 ],
[ 0.13504069, 0.44970334, 0.8248094 , ..., -0.17855829,
-0.39308357, 0.24178888],
[ 0.44061318, 0.6780157 , -0.07952423, ..., -1.2203757 ,
0.14167261, 0.3741262 ]], dtype=float32)]
正常运行,下面可以开始编码了。
首先引入相关包:
import os
import pickle
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import pandas as pd
import pkuseg
from elmoformanylangs import Embedder # 通过上面的python setup.py install安装
目录结构如下:
具体实现非常简单,只需要把分词后的句子列表传给ELMo模型,就可以得到每个单词的词向量。
为了得到句向量,这里我们采用对句子中每个单词向量求均值的方法。
e = Embedder('zhs.model') # EMLo模型
seg = pkuseg.pkuseg() # 分词工具
# 如果第一次执行(较耗时)
if not os.path.exists("embeddings.pkl"):
train_df = pd.read_csv("financezhidao_filter.csv").sample(frac=0.1) # 只取10%的数据量
# 取最佳答案中的tile和reply字段
candidates = train_df[train_df["is_best"] == 1][["title", "reply"]]
candidate_title = candidates["title"].tolist()
candidate_reply = candidates["reply"].tolist()
# 对title分词
titles = [seg.cut(title) for title in candidates["title"]]
# 计算title中单词词向量
embeddings = e.sents2elmo(titles)
# list of numpy arrays, each array with shape [seq_len * 1024]
# code.interact(local=locals())
# 对seq_len中的单词取平均,这样不管句子长度多少,都可以得到维度一致的句向量
# 除了取平均还可以:求和/取最大值等
candidate_embeddings = [np.mean(embedding, 0) for embedding in embeddings] # a list of 1024 dimensional vectors
# 保存嵌入
with open("embeddings.pkl", "wb") as f:
pickle.dump([candidate_title, candidate_reply, candidate_embeddings], f)
print("Save embeddings to embeddings.pkl")
else:
with open("embeddings.pkl", "rb") as f:
candidate_title, candidate_reply, candidate_embeddings = pickle.load(f)
print("Load embeddings success")
我们可以先为问答库中的问题计算好句向量,然后保存下来,下次直接加载就可以了。
当有了新问题进来,我们只需要按照相同的方法计算新问题的句向量,然后与问答库中的问题计算余弦相似度。
while True:
title = input("你的问题是?\n > ")
if len(title.strip()) == 0:
continue
title = [seg.cut(title.strip())]
title_embedding = [np.mean(e.sents2elmo(title)[0], 0)] # 得到了新问题的ELMo embedding
scores = cosine_similarity(title_embedding, candidate_embeddings)[0]
# 得到得分最高的5个问题对应的索引
top5_indices = scores.argsort()[-5:][::-1]
print("[得分] 参考问题 对应答案")
for index in top5_indices:
print(f"[{scores[index]}] {candidate_title[index]} 对应答案:{candidate_reply[index]}\n")
运行效果:
你的问题是?
> 如何发财
2023-02-26 15:07:57,114 INFO: 1 batches, avg len: 4.0
[得分] 参考问题 对应答案
[0.6191050410270691] 如何去理财,教我如何理财 对应答案:欢迎关注招行理财,招行有储蓄、大额存单、基金、理财产品、外汇、黄金、白银等投资可供您选择。风险和收益基本成正比,要求保本就选择储蓄,追求低风险可以考虑货币基金和低风险的理财产品,追求高收益可以了解投资型基金、外汇,黄金及白银,若您当地有招行,可以联系网点客户经理交流理财事宜。
[0.6009083390235901] 100万年轻人现在如何理财 对应答案:要是这100万是你所有的资产、建议你分散投资,可以选择三种不同的风险投资。1、低风险占40%,收益在5%左右一年利息两万左右,可以把钱做银行理财或买国债。2、中风险占50%,收益在11%左右一年利息五六万,可以选择一些靠谱的P2P网贷。3、高风险占10%,收益20%多甚至更高,可以做一些股票、期货类的。要么就找个有升值空间的三、四线城市或海边投资套房子,剩下的理财。
[0.5920484066009521] 聪明女人应该怎样理财 对应答案:所在城市若有招商银行,可了解下招行发售的理财产品,首次购买理财产品,需先办理风险评估,评估后,可购买对应您的风险承受能力等级的理财产品。您可以进入招行主页,点击“理财产品”-“个人理财产品”页面查看,也可通过“搜索”分类您需要的理财产品。温馨提示:购买之前请详细阅读产品说明书。
[0.58339524269104] 年轻人应该如何理财? 对应答案:目前招行个人投资理财方式较多:定期、国债、受托理财、基金、黄金等做组合投资,不同产品的投资起点不一,对应的风险级别也不相同。建议您可以到我行网点咨询理财经理的相关建议。
[0.5725947022438049] 手头几万闲钱如何理财最靠谱 对应答案:欢迎关注招行理财,招行有储蓄、大额存单、基金、理财产品、外汇、黄金、白银等投资可供您选择。风险和收益基本成正比,要求保本就选择储蓄,追求低风险可以考虑货币基金和低风险的理财产品,追求高收益可以了解投资型基金、外汇,黄金及白银,若您当地有招行,可以联系网点客户经理交流理财事宜。
你的问题是?
> 我要如何借钱
2023-02-26 15:08:40,206 INFO: 1 batches, avg len: 6.0
[得分] 参考问题 对应答案
[0.8377593159675598] 我是说要怎样挂失 对应答案:如果是招商银行一卡通或信用卡,都可以致电相应的客服热线,进入人工挂失。也可以通过网上银行挂失。
[0.8101509213447571] 我可以借钱吗 对应答案:建议您通过正规平台咨询办理。若在招行申请个人贷款,目前规定贷款人的年龄需年满18周岁,且年龄+贷款年限不得超过70岁。未成年人如需申请贷款,可尝试由父母(或一方)作为共同贷款申请人;具体能否办理,建议您联系当地网点的个贷部门详询。
[0.8072128295898438] 我要还款怎么搞 对应答案:若是招行信用卡,我行信用卡还款有多种方式,如通过自助存款机存现、网点柜面还款,网络还款、便利店还款等,您可以登录以下网址查看我行的还款方式介绍,以选择适合您的方式(网址:http://cc.cm####na.com/Cu######ce/Re#####nt.aspx)。
[0.7984545230865479] 我想贷你能? 对应答案:所在城市若有招商银行,可通过招行尝试申请贷款,由于各贷款项目所需条件及申请材料有所不同,请您在8:30-18:00致电9####选择3个人客户服务-3-3-8进入人工服务提供贷款用途及城市详细了解所需资料。贷款申请是否通过,请以经办行个贷部门的综合审核结果为准。
[0.7939909100532532] 我要贷款谁能帮我 对应答案:若您所在城市有招行,可通过招行尝试申请贷款,请您在8:30-18:00致电9####选择“2人工服务-“1”个人银行业务-“4”个人贷款业务进入人工服务提供贷款用途及城市详细了解所需资料。
你的问题是?
>
可以看到,我们没有进行任何训练,就可以得到一个效果还行的模型,我们可以利用分数排名来计算mean receiprocal rank。
然后基于此,去实现一个比基准模型更好的模型。
下面,我们来看如何实现BERT基准模型。
BERT基准模型
与ELMo模型类似,我们可以用BERT来对句子进行编码。BERT句向量表示有多种方式,比如使用[CLS]的向量表示句向量,但在这里效果不好,推荐和ELMo一样,才有句子中单词的平均值。
数据集
下载地址: https://pan.baidu.com/s/18Lwq16VBo6wBD_qLb3i33g
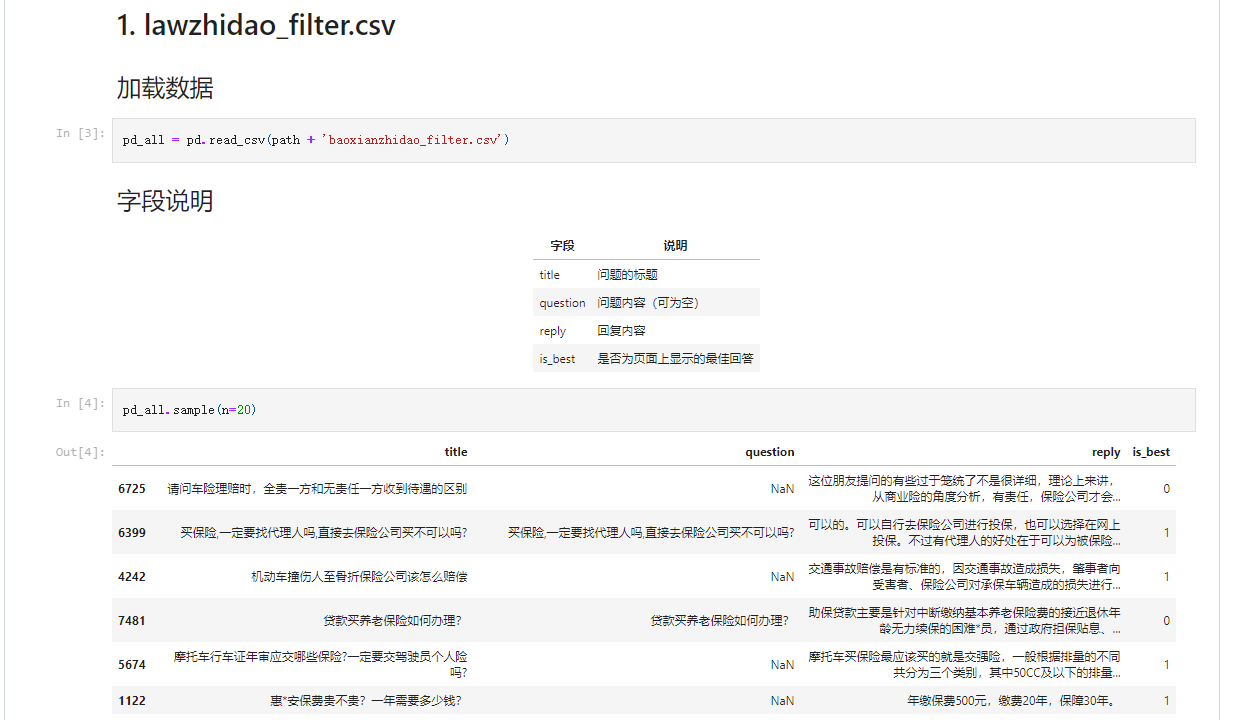
这次我们使用法律知道数据集,如上图所示。
实现
同样也是使用哈工大提供的预训练模型: https://github.com/ymcui/Chinese-BERT-wwm 。
我们利用HuggingFace包,这里可以不用费劲地去寻找该模型的下载地址,而可以直接通过huggingface下载。
下面会看到怎么做。
首先加载相应的包:
import logging
import os
import pickle
import pandas as pd
import torch
from sklearn.metrics.pairwise import cosine_similarity
from torch.utils.data import DataLoader, SequentialSampler, TensorDataset
from tqdm import tqdm
from transformers import (
BertConfig,
BertModel,
BertTokenizer,
)
from transformers import glue_convert_examples_to_features
from transformers.data.processors.utils import InputExample, DataProcessor
然后定义需要用到的参数:
# 参数
# 从HuggingFace官网下载
model_path = "hfl/chinese-bert-wwm-ext"
max_seq_length = 128
learning_rate = 2e-5
batch_size = 32
data_dir = "lawzhidao_filter.csv"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
定义数据处理类:
class FAQProcessor(DataProcessor):
"""处理我们的数据"""
def get_example_from_tensor_dict(self, tensor_dict):
"""
构建输入样本,我们这里针对BERT的输入只是单个句子,所以只有text_a参数
:param tensor_dict:
:return:
"""
return InputExample(
tensor_dict["idx"].numpy(), # 样本ID
tensor_dict["sentence"].numpy().decode("utf-8"), # text_a
None, # text_b
str(tensor_dict["label"].numpy()) # 标签
)
def get_candidates(self, file_dir):
train_df = pd.read_csv(file_dir)
# 只需要最佳答案中的title和reply
candidates = train_df[train_df["is_best"] == 1][["title", "reply"]]
# 转换为列表
self.candidate_title = candidates["title"].tolist()
# 保存在属性candidate_reply中
self.candidate_reply = candidates["reply"].tolist()
return self._create_examples(self.candidate_title, "train")
def _create_examples(self, lines, set_type):
"""创建训练样本"""
examples = []
for i, line in enumerate(lines):
guid = f"{set_type}-{i}"
examples.append(InputExample(guid=guid, text_a=line, text_b=None, label=1))
return examples
将数据转换为BERT能理解的格式:
def convert_examples_to_dataset(examples, tokenizer):
# 将数据转换为特征
features = glue_convert_examples_to_features(
examples,
tokenizer,
max_length=max_seq_length,
label_list=[1],
output_mode="classification"
)
# 转换为tensor
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids)
return dataset
定理模型推理函数:
def infer(model, dataset):
"""
让model在数据dataset上进行推理
:param model:
:param dataset:
:return:
"""
sentence_outputs = []
sampler = SequentialSampler(dataset)
dataloader = DataLoader(dataset, sampler=sampler, batch_size=batch_size)
logger.info(f" Num examples = {len(dataset)}, Batch size = {batch_size}")
for batch in tqdm(dataloader, desc="Inferring"):
model.eval()
batch = tuple(t.to(device) for t in batch)
with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": (batch[2])
}
outputs = model(**inputs)
# 我们计算句子中单词向量的均值
sequence_output, _ = outputs[:2]
sequence_output = sequence_output.mean(axis=1)
sentence_outputs.append(sequence_output)
return sentence_outputs
我们也是直接加载预训练好的模型来使用:
def main():
# 配置日志打印格式
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
config = BertConfig.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path, config=config)
model.to(device)
if not os.path.exists("embeddings.pkl"):
processor = FAQProcessor()
candidate_title, candidate_reply = processor.candidate_title, processor.candidate_reply
examples = (processor.get_candidates(data_dir))
dataset = convert_examples_to_dataset(examples, tokenizer)
outputs = infer(model, dataset)
candidate_embeddings = torch.cat([o.cpu().data for o in outputs]).numpy()
with open("embeddings.pkl", "wb") as fout:
pickle.dump([candidate_title, candidate_reply, candidate_embeddings], fout)
print("Save candidate_embeddings to embeddings.pkl")
else:
with open("embeddings.pkl", "rb") as fin:
candidate_title, candidate_reply, candidate_embeddings = pickle.load(fin)
print("Embeddings loaded.")
while True:
title = input("你的问题是?\n >")
if len(title.strip()) == 0:
continue
# 单个InputExample
examples = [InputExample(guid=0, text_a=title, text_b=None, label=1)]
dataset = convert_examples_to_dataset(examples, tokenizer)
output = infer(model, dataset)[0]
title_embedding = output.cpu().data.numpy()
# title_embedding = torch.cat([o.cpu().data for o in outputs]).numpy()
scores = cosine_similarity(title_embedding, candidate_embeddings)[0]
top5_indices = scores.argsort()[-5:][::-1]
print("[得分] 参考问题 对应答案")
for index in top5_indices:
print(f"[{scores[index]}] {candidate_title[index]} 对应答案:{candidate_reply[index]}\n")
if __name__ == '__main__':
main()
测试:
你的问题是?
>如何进行车险理赔
D:\Tools\Anaconda\lib\site-packages\transformers\data\processors\glue.py:67: FutureWarning: This function will be removed from the library soon, preprocessing should be handled with the 🤗 Datasets library. You can have a look at this example script for pointers: https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py
warnings.warn(DEPRECATION_WARNING.format("function"), FutureWarning)
02/26/2023 21:01:53 - INFO - __main__ - Num examples = 1, Batch size = 32
Inferring: 100%|██████████| 1/1 [00:00<00:00, 6.67it/s]
[得分] 参考问题 对应答案
[0.9664379358291626] 如何进行交通事故损害赔偿 对应答案:一、造成当事人损害1、同时投保机动车第三者责任强制保险和第三者责任商业保险的机动车发生造成损害,当事人同时侵权人和的,人民法院应当按照下列规则确定赔偿责任:(1)先由承保的保险公司在责任限额范围内予以赔偿;(2)不足部分,由承保商业三者险的保险公司根据予以赔偿;(3)仍有不足的,依照和侵权责任法的相关规定由侵权人予以赔偿。被侵权人或者其近亲属请求承保交强险的保险公司优先赔偿精神损害的,人民法院应予支持。2、投保人允许的驾驶人驾驶机动车致使投保人遭受损害,当事人可以请求承保交强险的保险公司在责任限额范围内予以赔偿,但投保人为本车上人员的除外。二、造成第三人损害1、有下列情形之一导致第三人人身损害,当事人请求保险公司在交强险责任限额范围内予以赔偿:(1)驾驶人未取得驾驶资格或者未取得相应驾驶资格的;(2)醉酒、服用国家的精神药品或者麻醉药品后驾驶机动车发生交通事故的;(3)驾驶人故意制造交通事故的。保险公司在赔偿范围内向侵权人主张追偿权的,人民法院应予支持。追偿权的诉讼时效期间自保险公司实际赔偿之日起计算。2、多辆机动车发生交通事故造成第三人损害(1)损失超出各机动车交强险责任限额之和的,由各保险公司在各自责任限额范围内承担赔偿责任;损失未超出各机动车交强险责任限额之和,当事人可以请求由各保险公司按照其责任限额与责任限额之和的比例承担赔偿责任。(2)依法分别投保交强险的牵引车和挂车连接使用时发生交通事故造成第三人损害,当事人可以请求由各保险公司在各自的责任限额范围内平均赔偿。(3)多辆机动车发生交通事故造成第三人损害,其中部分机动车未投保交强险,当事人请求先由已承保交强险的保险公司在责任限额范围内予以赔偿的,人民法院应予支持。保险公司就超出其应承担的部分向未投保交强险的投保义务人或者侵权人行使追偿权。
[0.9585154056549072] 车险事故如何处理 对应答案:一、报案1、事故发生后,保留事故现场,并立即向车辆的投保公司报案;2、如第三方损失为道路设施或者第三方损失为车辆,需向交警部门报案;二、现场处理-1、保险公司人员到达现场,并出具《查勘报告》2、交警部门到达现场,并现场出具《事故认定书》提醒:一般情况下,如果在向保险公司报案时,保险公司要求向交警报案时,保险公司人员无需到现场处理!三、第三者修理1、如果第三者非机动车,则最好要求保险公司人员在进行现场处理时,直接达成三方(第三者、保险公司、车主)公认的一个核损价格,如果当场不能核定损失,则在进行第三者损失核定的时候或者过程中,要求保险公司给出核损价格提醒:如果不经过保险公司允许,自行答应第三者有关索赔金额的承诺,这种承诺保险公司是有权推翻重来的,如果重新核定的价格与第三者的要求有差距,则这个差距会由车主自行承担2、如果第三者是机动车,则要分以下两种情况:第一、如果第三者同意与车主一同前往车主选定的修理厂进行修理,则当场不必支付第三者任何现金!第二、如果第三者要求去自己选定的修理厂进行修理,也就是说第三者将与车主去不同的修理厂进行车辆修理时,则第三者可能要求车主在事故现场先支付一部分修理费用,或称押金或定金,(因为担心事后找不到车主或者事后车主不认账),切记:一、现场掏钱,一定要立收据;二、支付一半的修理费用比较适当(因为也有可能发生事后第三者不认账的情况)提醒1:第三者车辆修理完毕后,车主必须先将修理费交付给第三者或其选择的修理厂,然后拿到第三者的修理发票及维修明细才能进行保险索赔的,如果事后第三者不提供相关资料或者找不到第三者时,第三者的维修费用保险公司是不能赔付的提醒2:虽然上文提到在现场掏钱时,要第三者立收据,虽说这种收据是不能作为赔偿依据的,但是这种收据至少可以避免第三者事后不认账的情况。因为第三者修理完毕后,车主须将修理费交付给第三者或者第三者选择的修理厂,如果没有这个收据,第三者万一不认账的情况下,车主到底应该在第三者车辆修理完毕后,支付多少钱呢?四、车辆定损修理1、将受损车辆送抵定损中心并同时通知保险公司,定损;2、修理厂修车;3、车主提车。五、提交单证进行索赔理赔:收集索赔资料交给保险公司办理索赔手续六、损失理算保险公司收到齐备的索赔单证之后进行理算,以最后确定最终的赔付金额。七、赔付:保险公司财务人员根据理赔人员理算得出的金额,向车主的指定帐户划拨赔款。
[0.9501453638076782] 工伤鉴定,如何理赔 对应答案:工伤认*之后并不能马上进行理赔,需要*工治疗完毕,进行医疗终结,根据是否存在后遗症进行劳*能*鉴*,根据劳*能*鉴*的结果以及医疗费用,住院时间等来进行报销及赔偿金额。工伤流程如下:1、及时送往医院治疗。2、申请工伤认*,由单位或者个人向当地劳*部门申请,认*为工伤。3、申请劳*能*鉴*,在*工治疗完毕或者达到一*医疗期之后向市*劳*能*鉴*委*会申请工伤鉴*,判*伤残等*。4、待遇审核,*工或者单位根据医院的治疗发票、工伤认*书、劳*能*鉴*书等想社保中心申请待遇审核,下发工伤待遇,包括医疗费用以及伤残补助费用。5、如果*工需要解除劳*关系,有伤残*工可以享受一次性就业补助金和一次性医疗补助金的待遇。依据《工伤保险条例》第十七条职工发生事故伤害或者按照职业病防治法规*被诊断、鉴*为职业病,所在单位应当自事故伤害发生之日或者被诊断、鉴*为职业病之日起30日内,向统筹地区社会保险行政部门提出工伤认*申请。遇有特殊情况,经报社会保险行政部门同意,申请时限可以适当延长。用人单位未按前款规*提出工伤认*申请的,工伤职工或者其近亲属、工会组织在事故伤害发生之日或者被诊断、鉴*为职业病之日起1年内,可以直接向用人单位所在地统筹地区社会保险行政部门提出工伤认*申请。按照本条第一款规*应当由省*社会保险行政部门进行工伤认*的事项,根据属地原则由用人单位所在地的设区的市*社会保险行政部门办理。用人单位未在本条第一款规*的时限内提交工伤认*申请,在此期间发生符合本条例规*的工伤待遇等有关费用由该用人单位负担。第二十三条劳*能*鉴*由用人单位、工伤职工或者其近亲属向设区的市*劳*能*鉴*委*会提出申请,并提供工伤认*决*和职工工伤医疗的有关资料。《社会保险法》第三十八条因工伤发生的下列费用,按照国家规*从工伤保险基金中支付:(一)治疗工伤的医疗费用和康复费用;(二)住院伙食补助费;(三)到统筹地区以外就医的交通食宿费;(四)安装配置伤残辅助器具所需费用;(五)生活不能自理的,经劳*能*鉴*委*会确认的生活护理费;(六)一次性伤残补助金和一至四*伤残职工按月领取的伤残津贴;(七)终止或者解除劳*合同时,应当享受的一次性医疗补助金;(八)因工死亡的,其遗属领取的丧葬补助金、供养亲属抚恤金和因工死亡补助金;(九)劳*能*鉴*费。第三十九条因工伤发生的下列费用,按照国家规*由用人单位支付:(一)治疗工伤期间的工资福利;(二)五*、六*伤残职工按月领取的伤残津贴;(三)终止或者解除劳*合同时,应当享受的一次性伤残就业补助金。
[0.9473228454589844] 如何申请工伤保险待遇 对应答案:提出工伤认定申请应当提交下列材料:(一)工伤认定申请表;(二)与用人单位存在劳动关系(包括事实劳动关系)的证明材料;(三)医疗诊断证明或者职业病诊断证明书(或者职业病诊断鉴定书)。工伤认定申请表应当包括事故发*的时间、地点、原因以及职工伤害程度等基本情况。工伤认定申请人提供材料不完整的,***险****应当一次性书面告知工伤认定申请人需要补正的全*材料。申请人按照书面告知要求补正材料后,***险****应当受*。第三十条职工因工作遭受事故伤害或者患职业病进*治疗,享受工伤医疗待遇。职工治疗工伤应当在签订服*协议的医疗机构就医,情况紧急时可以先到就近的医疗机构急救。治疗工伤所需费用符合工伤*险诊疗项目目录、工伤*险药*目录、工伤*险住*服*标准的,从工伤*险基金支付。工伤*险诊疗项目目录、工伤*险药*目录、工伤*险住*服*标准,由******险*****同***卫*****、食*药*监*管***等**规定。职工住*治疗工伤的伙食补助费,以及经医疗机构出具证明,报经办机构同意,工伤职工到统筹地区以外就医所需的交通、食宿费用从工伤*险基金支付,基金支付的具体标准由统筹地区人民*府规定。工伤职工治疗非工伤引发的疾病,不享受工伤医疗待遇,按照基本医疗*险办法处*。工伤职工到签订服*协议的医疗机构进*工伤康复的费用,符合规定的,从工伤*险基金支付。第三十一条***险****作出认定为工伤的决定后发***复议、**诉讼的,**复议和**诉讼期间不停止支付工伤职工治疗工伤的医疗费用。第三十二条工伤职工因日常*活或者就业需要,经劳动能力鉴定委员*确认,可以安装假肢、矫形器、假眼、假牙和配置轮椅等辅助器具,所需费用按照*家规定的标准从工伤*险基金支付。第三十三条职工因工作遭受事故伤害或者患职业病需要暂停工作接受工伤医疗的,在停工留薪期内,原工资福利待遇不变,由所在单位按月支付。停工留薪期一般不超过12个月。伤情严重或者情况特殊,经设区的市级劳动能力鉴定委员*确认,可以适当延长,但延长不得超过12个月。工伤职工评定伤残等级后,停发原待遇,按照本章的有关规定享受伤残待遇。工伤职工在停工留薪期满后仍需治疗的,继续享受工伤医疗待遇。*活不能自*的工伤职工在停工留薪期需要护*的,由所在单位负责。
[0.9467172026634216] 发生工伤事故如何找老板赔偿 对应答案:*工工伤索取赔偿可分四步进行。1、*单位进行协商,在协商一致后单位支付工伤赔偿金额即可。2、向劳*部门进行投诉,由劳*部门进行协调,单位支付*工工伤赔偿费用。3、申请劳*仲*,由劳*仲*委*会安排劳*仲**决,要求单位赔偿。4、在仲*后任然不支付的,向法院起诉,申请强制执行。《社会保险法》第三十八条因工伤发生的下列费用,按照国家规定从工伤保险基金中支付:(一)治疗工伤的医疗费用*康复费用;(二)住院伙食补助费;(三)到统筹地区以外就医的交通食宿费;(四)安装配置伤残辅助器具所需费用;(五)生活不能自理的,经劳*能力鉴定委*会确认的生活护理费;(六)一次性伤残补助金*一至四级伤残职工按月领取的伤残津贴;(七)终止或者解除劳*合同时,应当享受的一次性医疗补助金;(八)因工死亡的,其遗属领取的丧葬补助金、供养亲属抚恤金*因工死亡补助金;(九)劳*能力鉴定费。第三十九条因工伤发生的下列费用,按照国家规定由用人单位支付:(一)治疗工伤期间的工资福利;(二)五级、六级伤残职工按月领取的伤残津贴;(三)终止或者解除劳*合同时,应当享受的一次性伤残就业补助金。《劳*争议调解仲*法》第二条中*人*共*国境内的用人单位与劳*者发生的下列劳*争议,适用本法:(一)因确认劳*关系发生的争议;(二)因订立、履行、变更、解除*终止劳*合同发生的争议;(三)因除名、辞退*辞职、离职发生的争议;(四)因工作时间、休息休假、社会保险、福利、培训以及劳*保护发生的争议;(五)因劳*报酬、工伤医疗费、经济补偿或者赔偿金等发生的争议;(六)法律、法规规定的其他劳*争议。
你的问题是?
>可以不交养老保险吗
D:\Tools\Anaconda\lib\site-packages\transformers\data\processors\glue.py:67: FutureWarning: This function will be removed from the library soon, preprocessing should be handled with the 🤗 Datasets library. You can have a look at this example script for pointers: https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py
warnings.warn(DEPRECATION_WARNING.format("function"), FutureWarning)
02/26/2023 21:02:25 - INFO - __main__ - Num examples = 1, Batch size = 32
Inferring: 100%|██████████| 1/1 [00:00<00:00, 21.27it/s]
[得分] 参考问题 对应答案
[0.9749515056610107] 个人可以交社保吗 对应答案:个人缴纳社保,只能缴纳养老金和医疗保险这两部分。具体流程如下:1、个人如何缴纳社保可以以自由职业者的身份上社保(养老+医疗);2、参保条件:城镇户口或农转非户口;3、办理地点:当地社区街道的社保服务点,或区县一级的社保局(劳*保*局);4、个人如何缴纳社保问题中所需基本资料:户口本、身份证和复印件,2张1寸照片;5、缴费标准:以上一年本地社平工资为基础,养老缴费比例是20%,医疗约9%,目前尚有80%和100%两档可以选择。
[0.9687256217002869] 交了35年养老保险可以提前退休吗 对应答案:全民所有制企业和县以上集体企业的职工,分别符合以下条件的可办理提前退休。所从事的特殊工种必须属于劳动部门和国*院有关行业主管部门规定的特殊工种的范围;提前退休的年龄限制是男性年满55周岁,女性年满45周岁;申请人必须是原始人事档案有明确记载他(她)曾经从事提前退休特殊工种,达到国*规定年限。如果符合以上条件,申请人向档案管理部门提出申请,由主管部门向劳动保障部门申报。按程序审批后,即可办理退休。《特种作业人*安全技术培训考核管理办法》指出,特种作业的范围应包括:电工作业;金属焊接、切割作业;起重机械(含电梯)作业;企业内机动车辆驾驶;登高架设作业;锅炉作业(含水质化验);压力容器操作;制冷作业;爆破作业;矿山通风作业(含瓦斯检验);矿山排水作业(含尾矿坝作业);由省、自治区、直辖市安全生产综合管理部门或国*院行业主管部门提出,并经国*经*贸*委*会批准的其他作业。根据以上范围,你公公不符合特殊工种。不过你可以去问问当地相关部门,或许地方政府有特殊规定。关于医保缴费年限:参保人*到达国*规定的退休年龄时,享受退休人*基本医疗保险待遇的最低缴费年限(含视同缴费年限)男必须满25年,女满20年。达不到医保最低缴费年限的,以上年度社会平均工资为基数,一次性补缴所差年限的基本医疗保险费。(每个地方对医保缴费年限的规定不一致,需参照本地规定)
[0.9643365144729614] 我有社保,还需要买商业医疗保险吗 对应答案:不需要,但是商业保险是社保的一个补充,如果有足够的经济条件可以进行购买。1、社保覆盖面广,不存在拒保问题,但是保障较低,只能满足基本的保障需求。社保中的医疗保险,住院一般可报70%。而且这70%的医疗费,限于扣除起付线标准后。而且,在社保规定用药和规定项目内。许多检查费、专家诊疗、高新尖诊疗技术,社保都是不报的。这就需配合必要的商业保险了。2、另外,社保医疗是出院后报的,商业医保中的重疾险是确诊后就可以给钱,可以弥补很多家庭没钱治的困境;3、商业保险可以选择购买更高的保额,社保则很有限;社保医疗只是补偿医药费,而没有住院期间的收入损失补偿,商业医疗就有住院补贴。总之,建议在有了社保后,再购买适合自己的寿险,加上意外险、住院医疗、重疾医疗保险,就是非常的完善的保障了。
[0.9598730802536011] 小孩还没入户口可以报医保吗? 对应答案:新生儿要参加*保首先要做参保登记。新生儿的监护人需持新生儿的户口簿复印件和一寸新生儿照片,到户口所在的社区居委会填写《市城镇居民基本*疗保险参保登记表》,由经办人员签名盖章后,把参保登记表送到市*保*心居民科制作社会保障卡,缴纳*保费。新生儿(宝宝)年度内未能及时参保的,凭出生证、母亲参加我市城镇职工基本*疗保险或居民基本*疗保险的有效证件,可以享受出生当年城镇居民基本*疗保险待遇。符合计划生育政策并参加城镇*疗(生育)保险的妇女生孩子时,新生儿从出生日期算起至首次出院前一旦检查出任何病情,其*疗费用直接计入当次母亲住院*疗费*,并以其母亲名义按参保险种的规定报销。此外新生儿出生后60日内可以办理城镇居民*疗保险,在此期限内参保的新生儿,可立即按相关规定报销,取消一年的等待期。新生儿*疗保险办理需要以下资料:要带上户口本(首页和小孩户口页的复印件)、家长身份证(复印正反两面)和一张蓝底或者红底的新生儿一寸照片(有些地方需要)到户口所在街道或社区劳动保障所办理参保手续即可。从参保手续办理到拿到新生儿*保卡,需要一个多月的时间。一般来说,只要是出生12个月以内的新生儿,可随时办理参保手续。
[0.9593257904052734] 只要失业了,就能领失业保险金吗 对应答案:不是这样的。失业保险必须是等到失业条件出现才能领取,一般就是解除劳动合同后档案转街道,在街道领取。但是如果不领,则前后失业保险缴费时间可以累计。失业保险待遇如下:这个失业保险的待遇要高于第一点说的情况,具体如下:(一)累计缴费时间不满5年的,失业保险金月发放标准为422元;(二)累计缴费时间满5年不满10年的,失业保险金月发放标准为449元;(三)累计缴费时间满10年不满15年的,失业保险金月发放标准为476元;(四)累计缴费时间满15年不满20年的,失业保险金月发放标准为503元;(五)累计缴费时间满20年以上的,失业保险金月发放标准为531元;(六)从第13个月起,失业保险金月发放标准一律按422元发放。领取时间长短如下规定:(一)累计缴费时间1年以上不满2年的,可以领取3个月失业保险金;(二)累计缴费时间2年以上不满3年的,可以领取6个月失业保险金;(三)累计缴费时间3年以上不满4年的,可以领取9个月失业保险金;(四)累计缴费时间4年以上不满5年的,可以领取12个月失业保险金;(五)累计缴费时间5年以上的,按每满一年增发一个月失业保险金的办法计算,确定增发的月数。领取失业保险金的期限最长不得超过24个月。失业期间医疗保险补助金待遇—失业人员在领取失业保险金期间,患病(不含因打架斗殴或交通事故等行为致伤、致残的)到社会保险经办机构指定的医院就诊的,可以补助本人应领取失业保险金总额60%至80%的医疗补助金。具体标准为:(一)累计缴费时间不满5年的,其医疗费补助比例为60%;累计医疗补助金不超过本人应领取失业保险金总额的60%。(二)累计缴费时间满5年不满10年的,其医疗费补助比例为65%;累计医疗补助金不超过本人应领取失业保险金总额的65%。(三)累计缴费时间满10年不满15年的,其医疗费补助比例为70%;累计医疗补助金不超过本人应领取失业保险金总额的70%。(四)累计缴费时间满15年不满20年的,其医疗费补助比例为75%;累计医疗补助金不超过本人应领取失业保险金总额的75%。(五)累计缴费时间满20年以上的,其医疗费补助比例为80%;累计医疗补助金不超过本人应领取失业保险金总额的80%。
看起来BERT非常自信,但实际效果没有那么理想,此时我们可以进一步地在下游任务上进行微调。



![[LeetCode周赛复盘] 第 334 场周赛20230226](https://img-blog.csdnimg.cn/fc364e3f9f944874b814a0d211fdb92f.png)