一、数据类型方法论
程序本质上是对数据的处理(逻辑运算),因此任何语言都需先解决如何表征【数据】这个核心概念。数据作为抽象的概念,天然的包含2个方面属性:
类型:类型决定了数据只能和同类型的数据进行运算才有意义,不同类型的数据必须进行类型转换数值:是数据的数学意义上的大小或内容。
同时数据保存在内存或磁盘中,总是占用一定的存储空间,因此一个数据在程序中是由类型、数值和存储空间表示的。
二、Java 数据类型
Java 是一种强类型语言,每个变量在声明时必须指定其数据类型。根据参数传递时的赋值方式,Java 中的数据类型分2类:
1、基本数据类型(值类型)
参数传递时总是以值拷贝的形式,赋值给接收变量。
本质是对数学意义上的纯数值类数据的抽象,因此又叫值类型.
注意: 基本数据类型在语言层面是不可分割的基本单元,但硬件层面并非是不可分割的,因为内存的读写是以内存行(64位)为基本单位的,占用2个或2个以上内存行的数据在高并发下是不安全的。
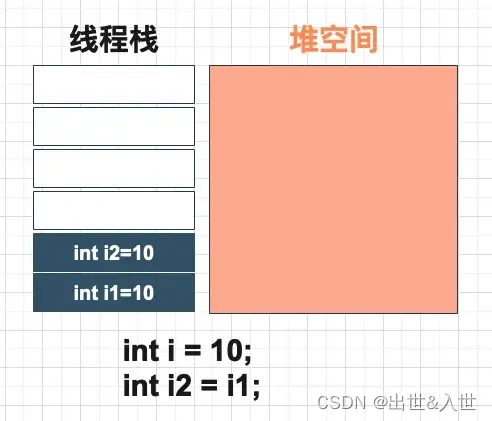
2、引用类型
即参数传递时是以拷贝引用地址的方式传递给接收变量,而非复制整个"数据"本体。
除了基本数据类型外的、其他结构化的数据类型,如字符串类型String、或自定义的类(如Person),本质上是对现实世界结构化、关系化数据的抽象,因为一个对象(如人)总是具备多个特征属性的,每个属性都是一个基本数据类型。
为什么不是拷贝值?
这类类型的变量本质上是一段存储空间的起始地址,因为结构化数据的存储空间的大小是由所有属性叠加的,且是可变的,不能或很难实现原子性的拷贝,且空间代价很大,因此参数传递时并不是机械的拷贝所有属性、所有空间,而是仅复制拷贝起始地址就行了,其他字段可以据此基地址和字段顺序进行偏移计算所得。

3、值类型和引用类型的区别
- 概念方面
基本类型:变量名指向具体的数值,参数传递会拷贝值的副本,原值不受影响
引用类型:变量名指向存数据对象的内存地址,参数传递是复制内存段的起始地址,最终指向同一内存段。
- 相等语义
基本类型:使用时需要赋具体值,使用 == 号判断值是否相等。
引用类型:== 是判断引用地址是否相同;通常应重写 equals 方法实现自定义的逻辑,如同一学生会存在多个缓存中,重写equals,根据学号no是否相等判断是否是同一学生。
三、基本数据类型(值类型)
Java 语言共提供了4 类、8 种基本类型
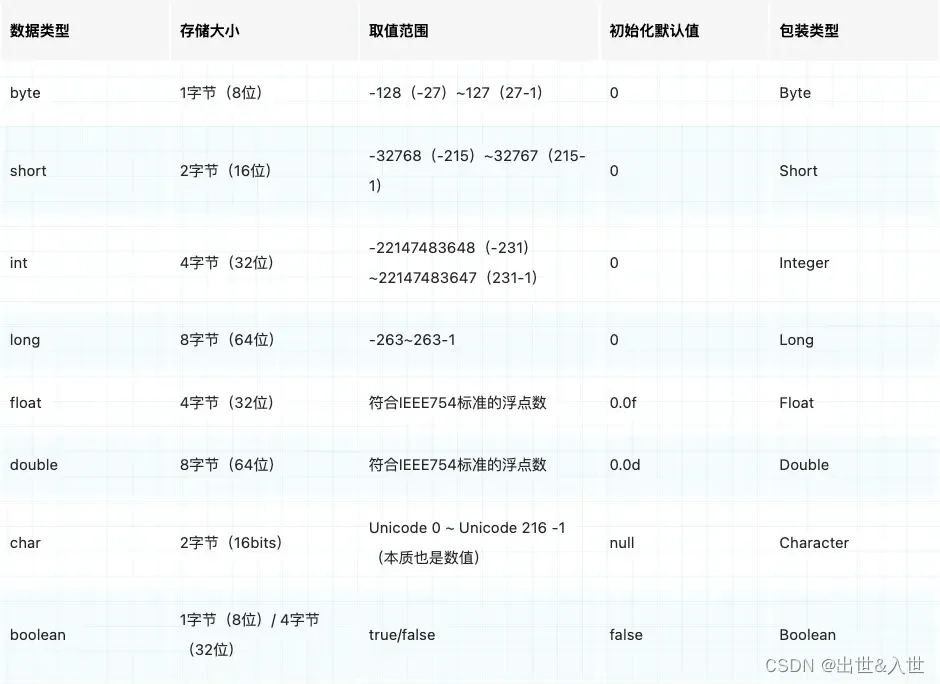
1、整数型
是对数学中整数的表达,按照数值范围和存储空间大小顺序:byte < short < int < long
2、浮点型
是对数学中的小数的表达,即有浮动小数点的数,
float - 32 位,直接赋值时必须在数字后加上 f 或 F,指示编译器这是一个float型浮点数double - 64 位,赋值时一般在数字后加 d 或 D,指示编译器这是一个double型浮点数
3、Unicode 字符型
是对Unicode编码的表达,Unicode编码是对全世界所有主要语言中各类字符、符号的编码,是将文档转存成计算机的二进制序列进行保存的理论基础。
char- 16 位,存储 Unicode 码,用单引号赋值。

可计算的
java 提供字符型,可以更方便的表述字符,同时支持基于编码的数值计算,因此char类型的值本质还是数值,可以参与数值计算。
4、布尔型(真假)
是对逻辑运算值的表达,即真True和假False。
boolean - 只有 true 和 false 两个取值。
非数值
boolean 类型是非数值类型的,因此和其他基本数据类型不能参与计算。
5、最小使用原则
即在满足需求的前提下,优先使用更小的类型,可以节省大量的内存,提升程序的性能。Java每个大类都提高了多个大小不一的类型,即是灵活的需要,更是内存优化的需要。
四、类型转换
正如方法论中所说,不同类型的数据不能直接混合计算,必须转换同一种类型。
Java 中,数据类型转换有两种方式:自动转换 和 强制转换
1、自动隐式转换
在符合下面的规则下,Java编译器会安全的、隐式的进行转换,降低用户手动转换的压力。
- 自动膨胀原则
即在精度不一致的混合场景下,Java编译器会隐式的将精度较小的类型转换成精度稍大的类型后才进行计算,由小转大,数据精度并不会丢失,因此是安全的。
膨胀的顺序是:byte -> short/char -> int -> long -> float -> double
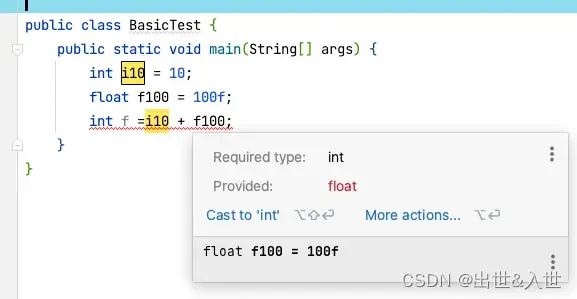
由下面的例子可以看出,Java编译器不仅自动优化了变量类型,减少了内存,而且自动隐式的将 byte 转换成了 float,整个表达式的最终结果已是float类型
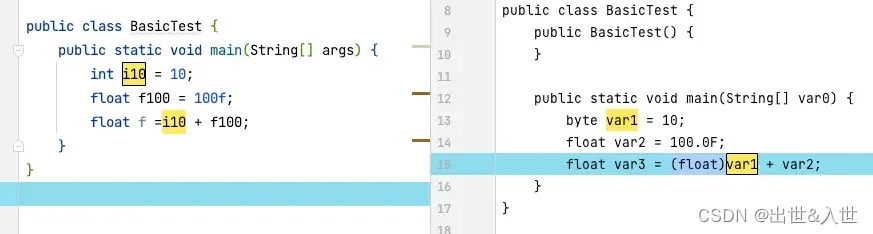
再使用精度较小的int型变量接收时就会提示出错。
2、强制转换
在不符合自动转换条件时或者根据用户的需要,可以使用符号()对数据类型做强制的转换。
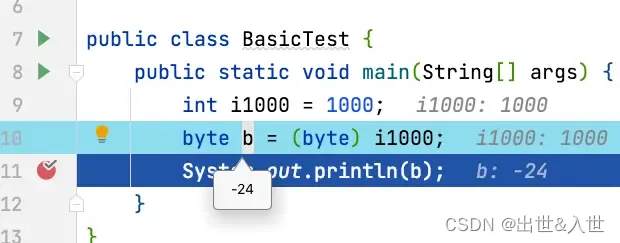
注意!!!:从精度大到精度小的强制转换,因为存储空间也会缩小一半,因此存在数据出错的不确定性问题,用户自身需要自我承担这样的风险。
可以看到虽然编译阶段是正常的,没有提示错误,但是运行时的结果却是一个不确定的数据,而不是预期的。
五、装箱和拆箱
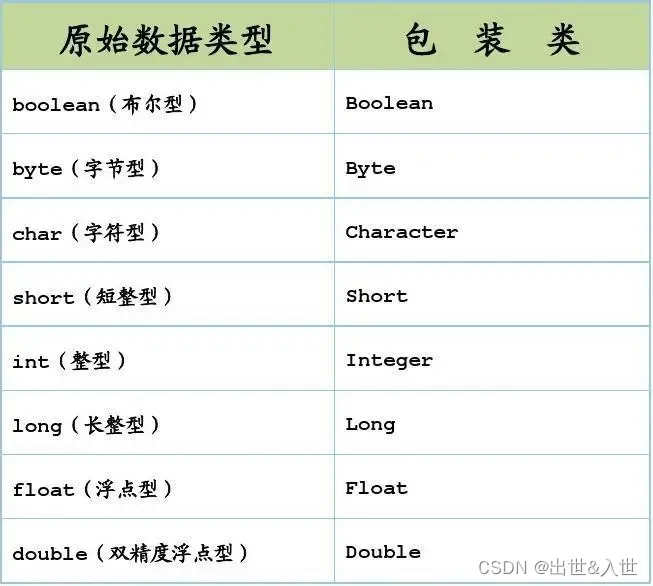
为了基本数据类型可以与引用类型互相转换,以利用彼此的特性,Java 为每一种基本数据类型提供了相应的包装(封装)类。
1、包装类和享元模式
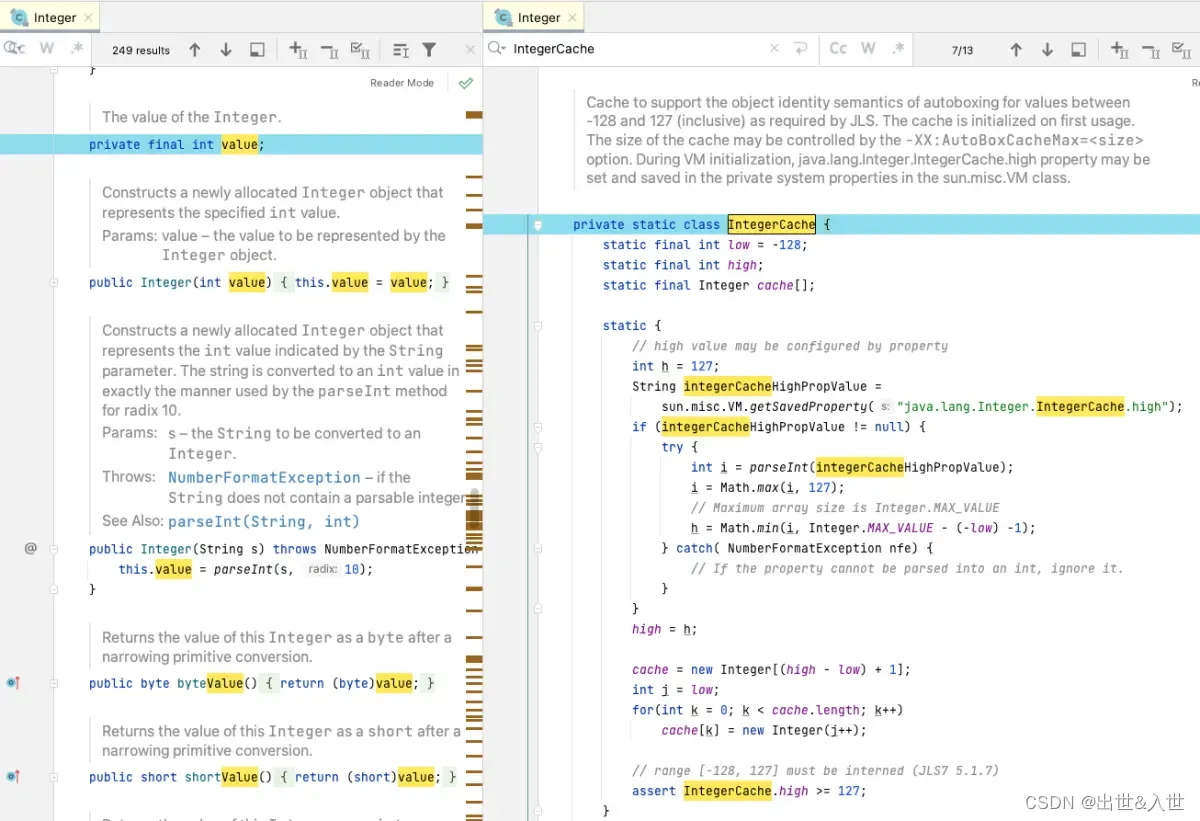
Java基本数据类型的包装类以value字段保留其对应的数值,如Integer#value,可以通过构造器或者valueof方法生成新的包装对象实例。
- 享元模式(即缓存池模式)
因为在堆中创建新的对象是相对比较重的操作,同时基本数据类型的自动装箱又是程序中最常见的情况之一,因此为为避免重复创建这些常用的对象,Jdk实现的基本类型包装类基本都会采用缓存池的设计,即享元模式,数量由jvm参数XX:AutoBoxCacheMax指定。
饥饿池化 - 包装类在首次加载时会对指定小范围内的数值进行饥饿式池化,如java.lang.Integer.IntegerCache.high指定
懒加载池化 - 对每个首次使用的其他数值进行懒加载池化和替换
享元模式是非常重要的设计模式一直,对内存优化和系统系统方面都是非常友好的。
2、装箱(boxing)
即将基本数据类型转换为对应封装类的引用类型,目的是获得对应封装类的各类方法的能力。例如:int 转 Integer,编译器是通过调用包装类的 valueOf 方法实现的。
自动装箱(auto boxing)
当基本数据类型赋值给对应包装类的引用类型时,Java会自动的将基本数值类型通过其包装类的valueOf,在堆上创建其对应的包装类对象。
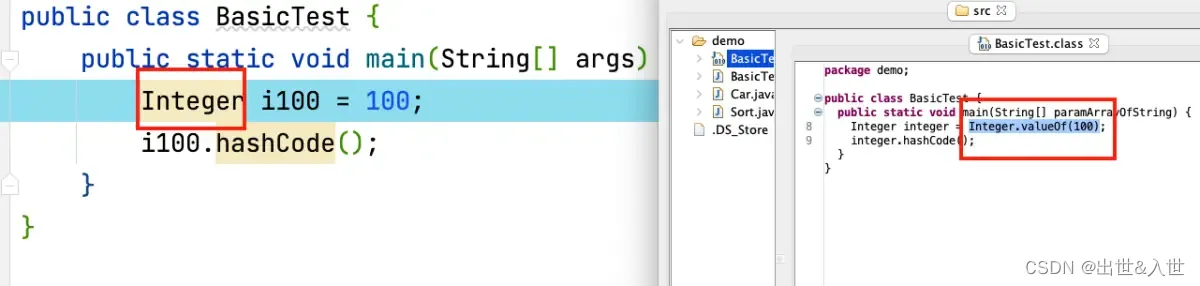
3、拆箱(unboxing)
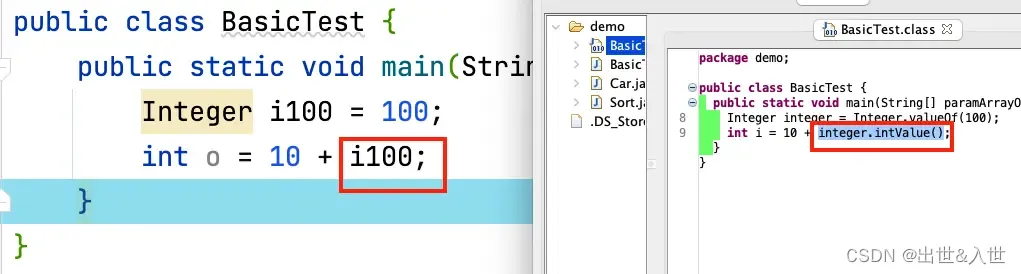
是将封装类的引用类型转换为基本数据类型,例如:Integer 转 int,目的是可以参与常规的数学运算。本质是编译器通过调用包装类的 xxxValue 方法实现的。(xxx 代表对应的基本数据类型)
自动拆箱(auto unboxing)
当包装类与基本数据类型混合运算时,Java会调用该包装类的xxxValue获得对应的值类型的值,然后才参与表达式的计算。
六、总结
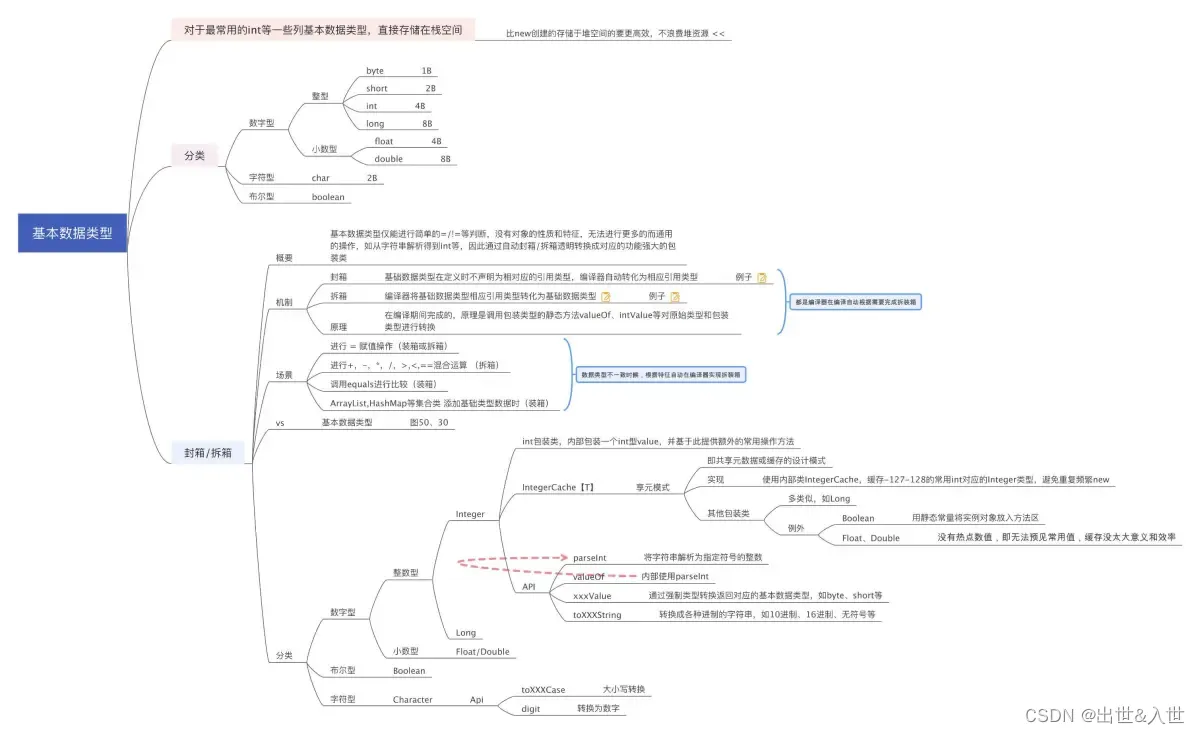
最后整理了一个完整的脑图。


![[LeetCode周赛复盘] 第 334 场周赛20230226](https://img-blog.csdnimg.cn/fc364e3f9f944874b814a0d211fdb92f.png)