CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
2023.02.20—2023.02.26
文摘词云

Top Papers
Subjects: cs.CL
1.LLaMA: Open and Efficient Foundation Language Models
标题:LLaMA:开放高效的基础语言模型
作者:Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux
文章链接:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/

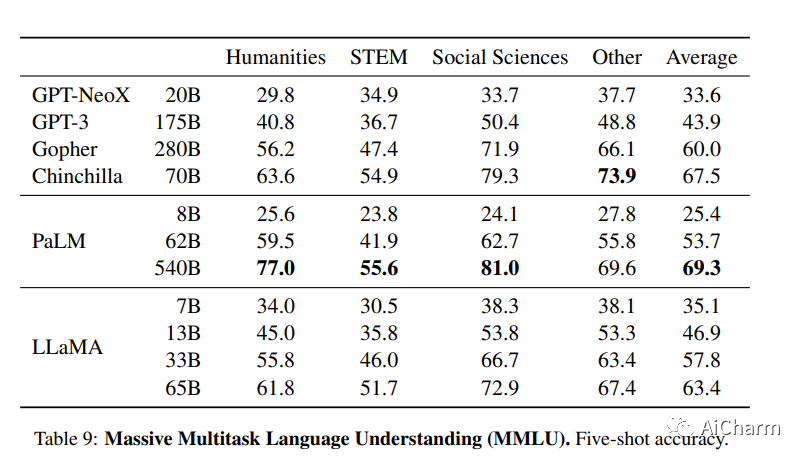
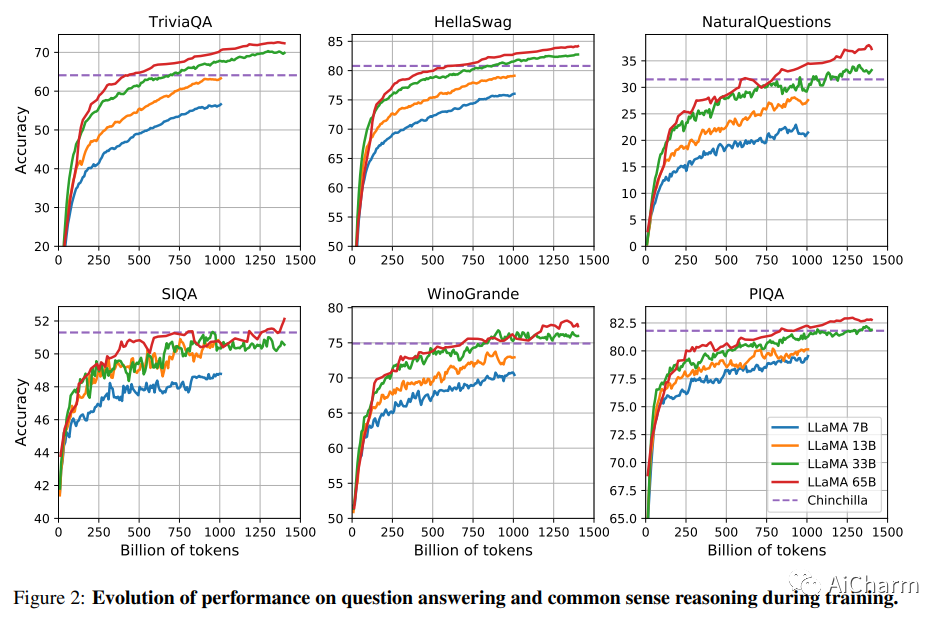
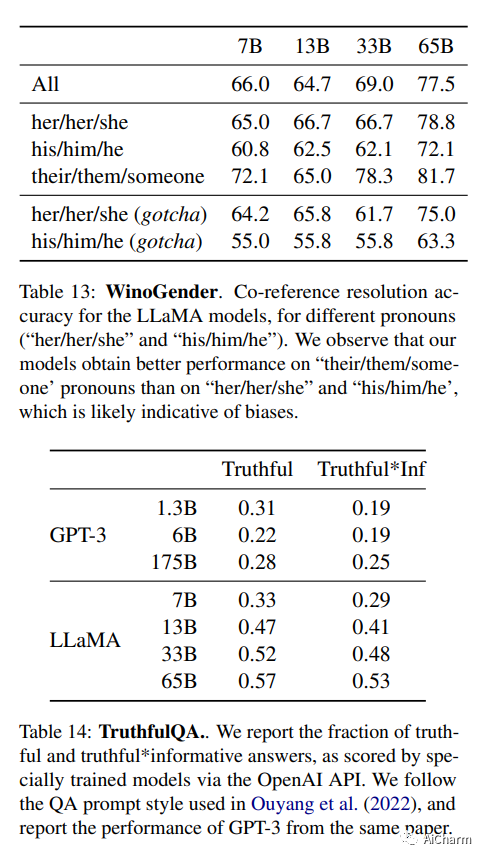
我们介绍了 LLaMA,这是一组基础语言模型,参数范围从 7B 到 65B。我们在数万亿个令牌上训练我们的模型,并表明可以仅使用公开可用的数据集来训练最先进的模型,而无需诉诸专有和不可访问的数据集。特别是,LLaMA-13B 在大多数基准测试中都优于 GPT-3 (175B),而 LLaMA-65B 可与最佳模型 Chinchilla70B 和 PaLM-540B 竞争。我们将所有模型发布给研究社区。
上榜理由
这是Meta在2.24最新发布的大模型LLaMA:
与 Chinchilla、PaLM 或 GPT-3 不同,它只使用公开可用的数据集,使我们的工作与开源兼容且可重现,而大多数现有模型依赖于非公开可用或未记录的数据。
所有的模型都接受了至少 1T tokens的训练,远远超过通常在这个规模上使用的tokens。有趣的是,即使在 1T tokens之后,7B 模型仍在改进。
在常识推理、闭卷问答和阅读理解方面,LLaMA-65B 在几乎所有基准测试中都优于 Chinchilla 70B 和 PaLM 540B。
LLaMA-65B 在 GSM8k 上的表现优于 Minerva-62B,尽管它尚未在任何数学数据集上进行微调。在 MATH 基准测试中,它优于 PaLM-62B(但远低于 Minerva-62B)
在代码生成基准测试中,LLaMA-62B 优于 cont-PaLM (62B) 和 PaLM-540B。
据官方:开源、一块GPU就能跑,1/10参数量打败GPT-3。
2.FRMT: A Benchmark for Few-Shot Region-Aware Machine Translation
标题:FRMT:小样本区域感知机器翻译的基准
作者:Parker Riley, Timothy Dozat, Jan A. Botha, Xavier Garcia, Dan Garrette, Jason Riesa, Orhan Firat, Noah Constant
文章链接:https://arxiv.org/abs/2210.00193
项目代码:https://github.com/google-research/google-research/tree/master/frmt

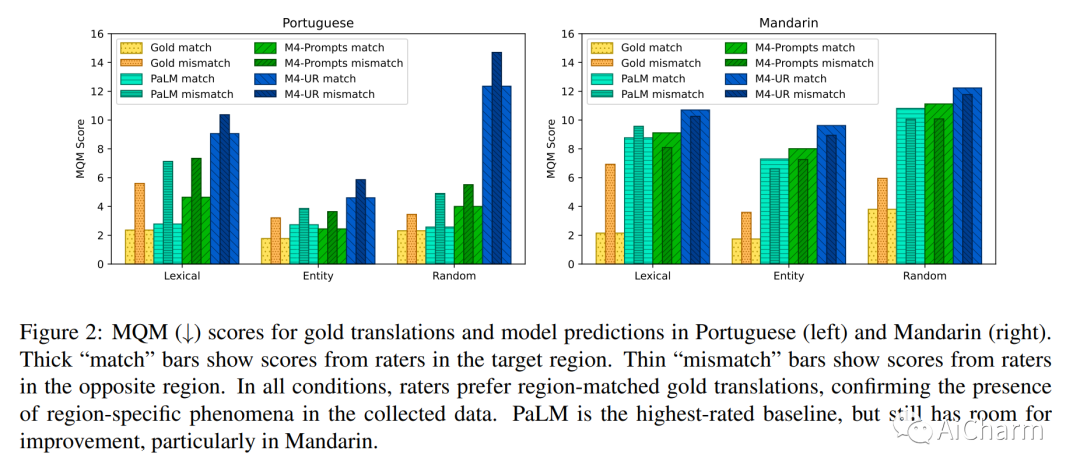
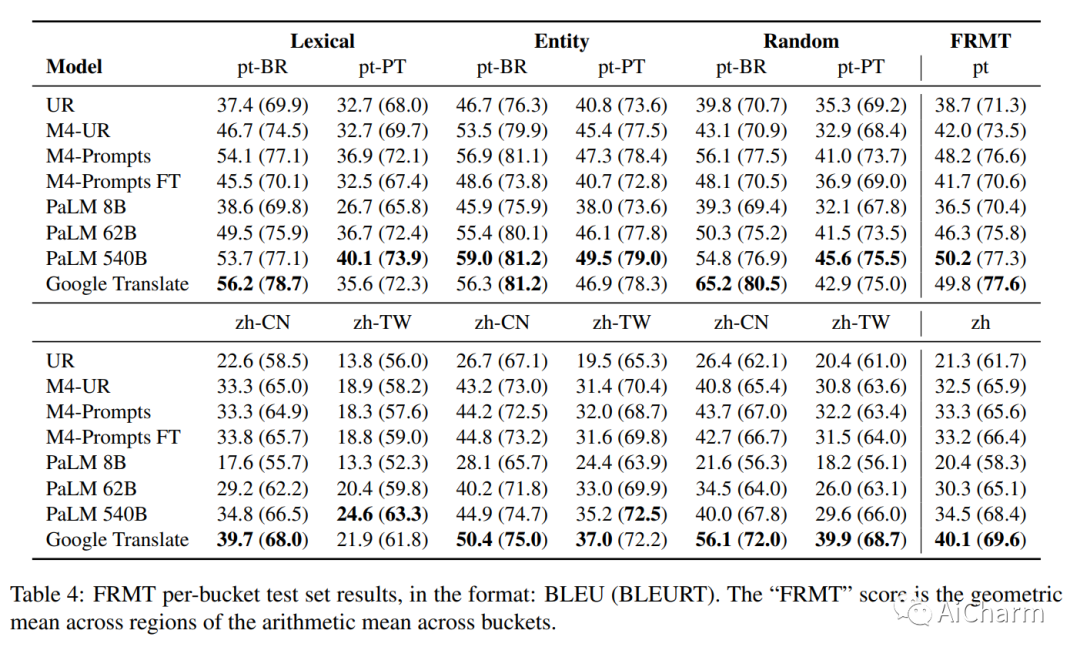
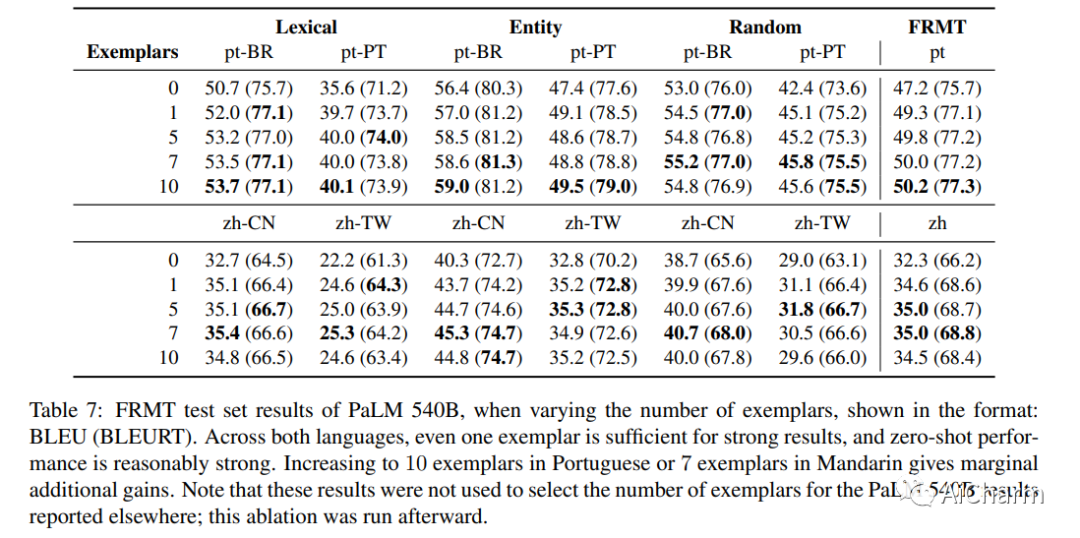
我们展示了 FRMT,这是一种新的数据集和评估基准,适用于 Few-shot Region-aware Machine Translation,一种以风格为目标的翻译。该数据集包括从英语到葡萄牙语和普通话两种区域变体的专业翻译。选择源文档是为了能够对感兴趣的现象进行详细分析,包括词汇上不同的术语和干扰项。我们探索 FRMT 的自动评估指标,并在区域匹配和不匹配的评级场景中验证它们与专家人类评估的相关性。最后,我们为这项任务提供了一些基线模型,并为研究人员如何训练、评估和比较他们自己的模型提供了指导方针。
Subjects: cs.CV
1.Composer: Creative and Controllable Image Synthesis with Composable Conditions
标题:Composer:具有可组合条件的创造性和可控图像合成
作者:Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, Jingren Zhou
文章链接:hhttps://arxiv.org/abs/2302.09778
项目代码:https://damo-vilab.github.io/composer-page/



我们最近在大数据上学习的大规模生成模型能够合成令人难以置信的图像,但可控性有限。这项工作提供了一种新一代范例,可以灵活控制输出图像,例如空间布局和调色板,同时保持合成质量和模型创造力。以组合性为核心思想,我们首先将图像分解为具有代表性的因素,然后以所有这些因素为条件训练扩散模型对输入进行重组。在推理阶段,丰富的中间表示作为可组合元素工作,为可定制的内容创建带来巨大的设计空间(即,与分解因子的数量成指数比例)。值得注意的是,我们称之为 Composer 的方法支持各种级别的条件,例如作为全局信息的文本描述、作为局部指导的深度图和草图、用于低级细节的颜色直方图等。除了提高可控性外,我们确认 Composer 是一个通用框架,无需重新训练即可促进各种经典生成任务。
上榜理由
这是阿里巴巴团队在2.20日发表的最新扩散模型Composer:
Composer 是一个大型(50 亿个参数)可控扩散模型,在数十亿(文本、图像)对上进行训练.
它可以根据文本和深度、蒙面图像和文本、草图、深度和嵌入、文本和调色板等等生成图像,也可以修复草图、重新配置图像、颜色插值、 特定区域的图像编辑,在图片翻译、风格转移、姿势转移、虚拟试穿经典的任务上也表现的很好。
现在扩散模型的发展简直可以用飞速来形容,每天都有令人瞠目结舌的成果发布。
2.Adding Conditional Control to Text-to-Image Diffusion Models
标题:向文本到图像扩散模型添加条件控制
作者:Lvmin Zhang, Maneesh Agrawala
文章链接:https://arxiv.org/abs/2302.05543
项目代码:https://github.com/lllyasviel/controlnet
摘要:
深度生成模型在文本到图像合成方面取得了令人瞩目的成果。然而,当前的文本到图像模型通常会生成与文本提示不充分对齐的图像。我们提出了一种使用人类反馈来对齐此类模型的微调方法,包括三个阶段。首先,我们从一组不同的文本提示中收集评估模型输出对齐的人类反馈。然后,我们使用人工标记的图像文本数据集来训练预测人类反馈的奖励函数。最后,文本到图像模型通过最大化奖励加权似然来改进图像文本对齐进行微调。我们的方法比预训练模型更准确地生成具有指定颜色、计数和背景的对象。我们还分析了几种设计选择,发现对此类设计选择进行仔细调查对于平衡对齐保真度权衡非常重要。我们的结果证明了从人类反馈中学习以显着改进文本到图像模型的潜力。

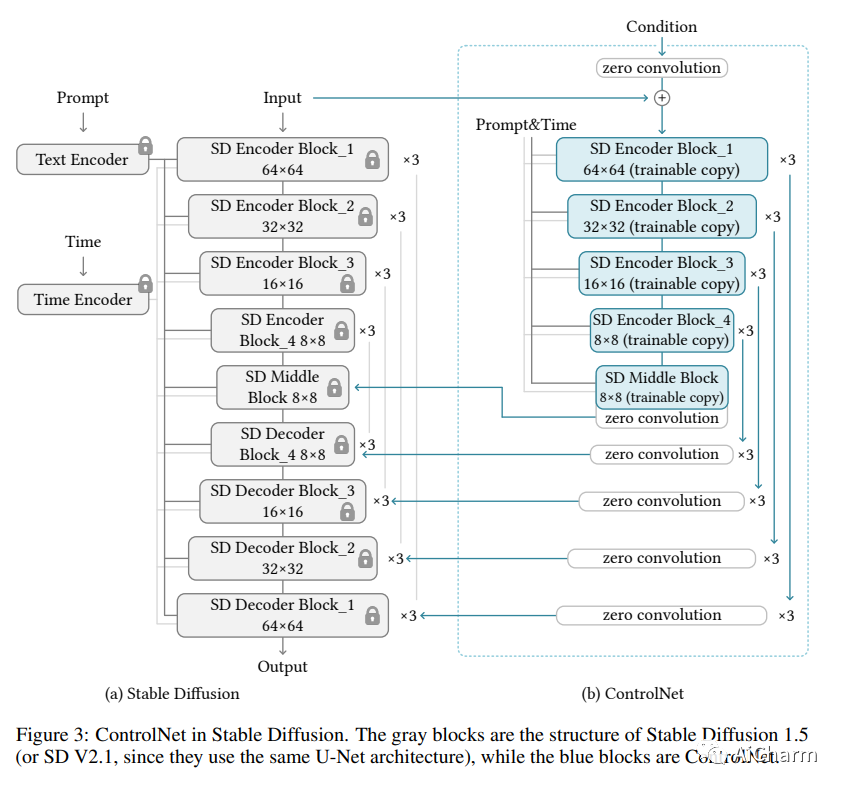

我们提出了一种神经网络结构 ControlNet,用于控制预训练的大型扩散模型以支持额外的输入条件。ControlNet 以端到端的方式学习特定于任务的条件,即使训练数据集很小 (< 50k),学习也很稳健。此外,训练 ControlNet 与微调扩散模型一样快,并且可以在个人设备上训练模型。或者,如果可以使用强大的计算集群,该模型可以扩展到大量(数百万到数十亿)数据。我们报告说,像 Stable Diffusion 这样的大型扩散模型可以通过 ControlNets 进行增强,以启用边缘图、分割图、关键点等条件输入。这可能会丰富控制大型扩散模型的方法,并进一步促进相关应用。
PS:效果非常的amazing的一篇成果,ControlNet可能会改变 AI 图像生成游戏规则。
3.Designing an Encoder for Fast Personalization of Text-to-Image Models
标题:设计用于快速个性化文本到图像模型的编码器
作者:Rinon Gal, Moab Arar, Yuval Atzmon, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or
文章链接:https://arxiv.org/abs/2302.04761
项目代码:https://tuning-encoder.github.io/

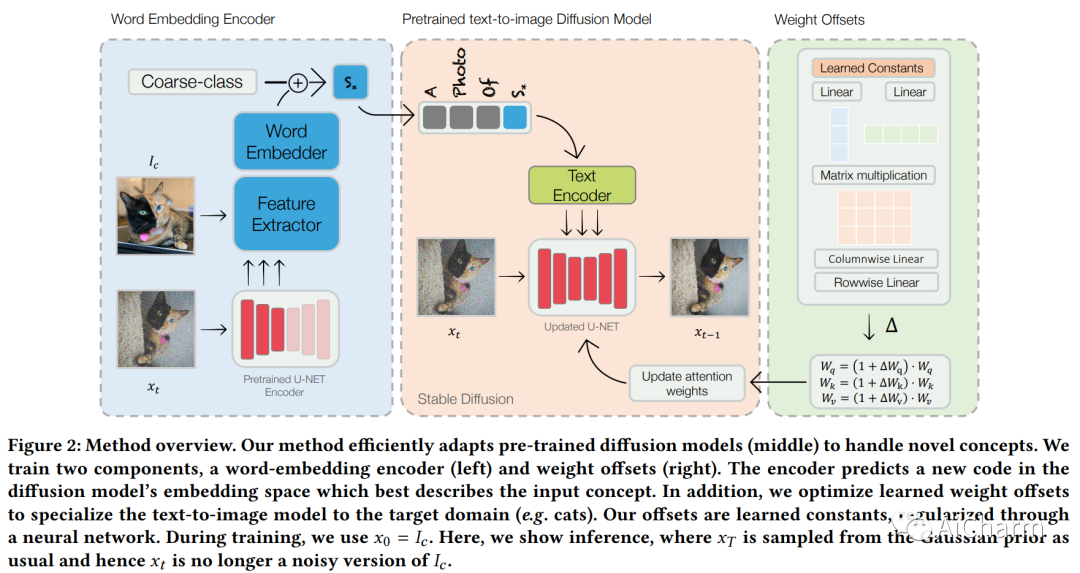
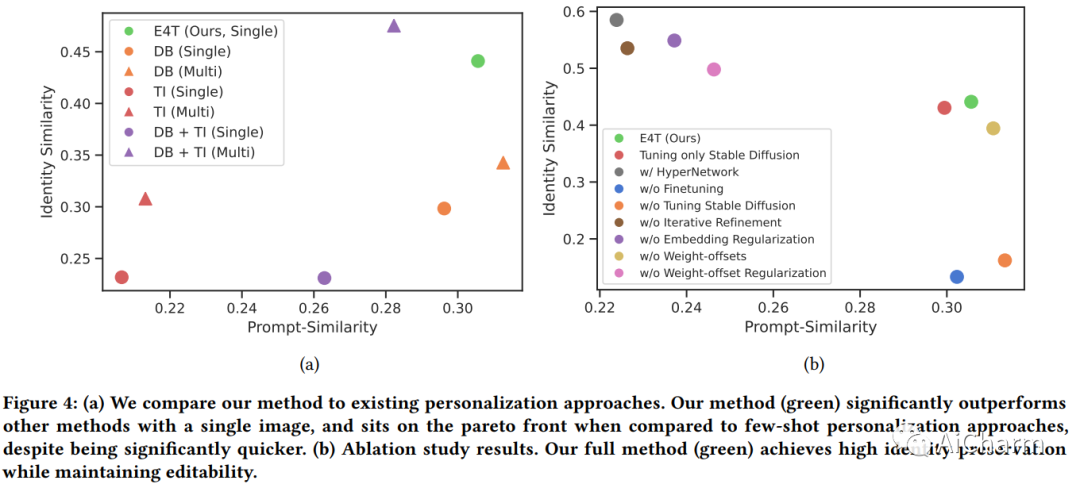

文本到图像的个性化旨在教授预训练的扩散模型来推理新颖的、用户提供的概念,并将它们嵌入到由自然语言提示引导的新场景中。然而,当前的个性化方法与冗长的训练时间、高存储要求或身份丢失作斗争。为了克服这些限制,我们提出了一种基于编码器的域调整方法。我们的主要见解是,通过欠拟合来自给定领域的大量概念,我们可以提高泛化能力并创建一个更适合快速添加来自同一领域的新概念的模型。具体来说,我们采用了两个组件:首先,一个编码器,它将来自给定域的目标概念的单个图像作为输入,例如一个特定的面孔,并学习将其映射到表示该概念的词嵌入中。其次,一组用于文本到图像模型的正则化权重偏移,学习如何有效地摄取额外的概念。这些组件共同用于指导未知概念的学习,使我们能够仅使用一张图像和少至 5 个训练步骤来个性化模型——将个性化从几十分钟加速到几秒钟,同时保持质量。
4.MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
标题:MERF:用于无界场景中实时视图合成的内存高效辐射场
作者:Christian Reiser, Richard Szeliski, Dor Verbin, Pratul P. Srinivasan, Ben Mildenhall, Andreas Geiger, Jonathan T. Barron, Peter Hedman
文章链接:https://arxiv.org/abs/2302.04761
项目代码:t https://merf42.github.io

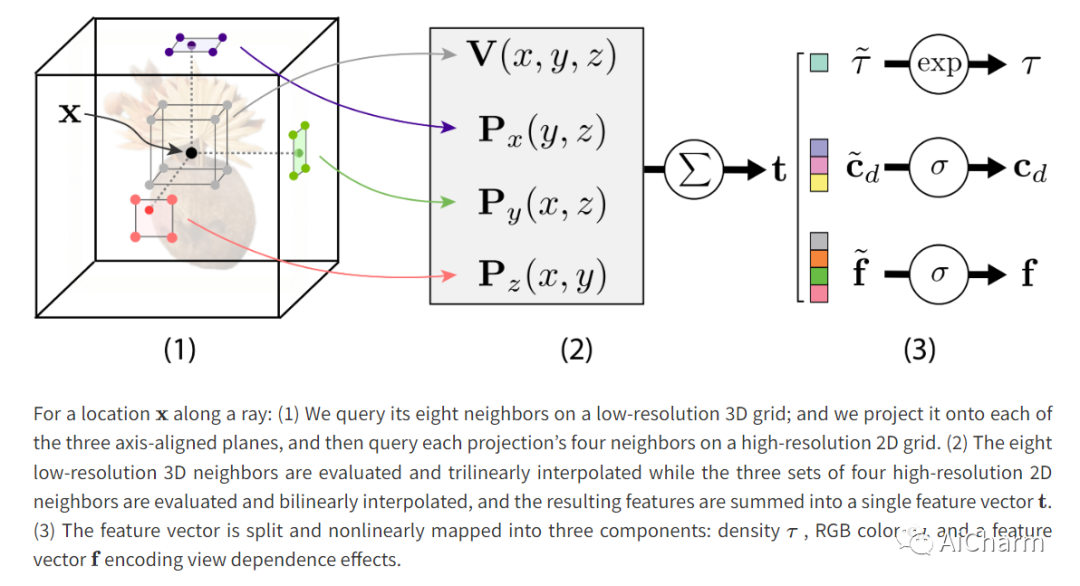
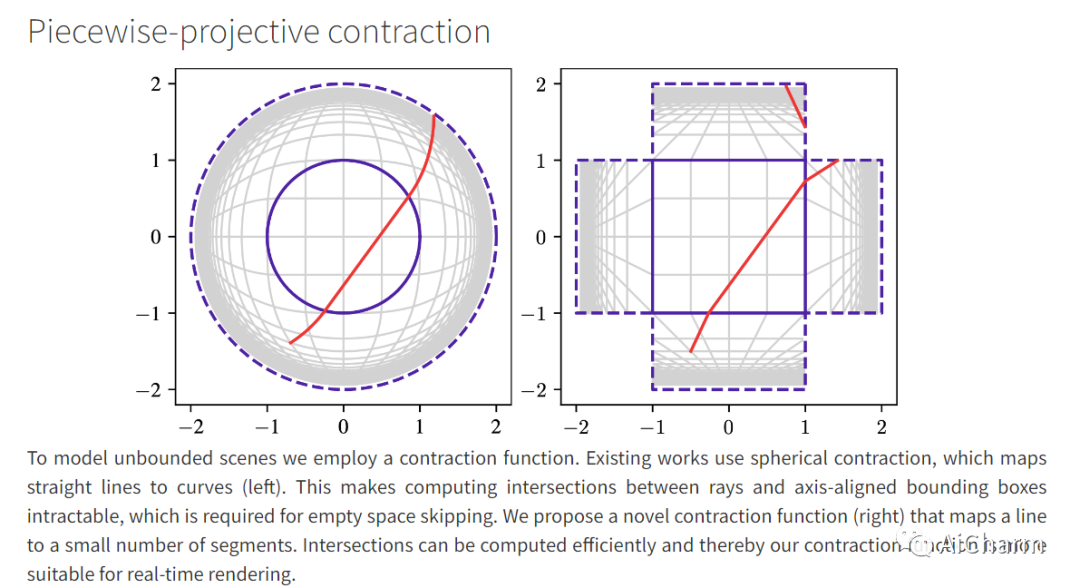

神经辐射场可实现最先进的逼真视图合成。然而,现有的辐射场表示对于实时渲染来说计算量太大,或者需要太多内存才能扩展到大型场景。我们提出了一种内存高效辐射场 (MERF) 表示,可在浏览器中实现大规模场景的实时渲染。MERF 使用稀疏特征网格和高分辨率 2D 特征平面的组合减少了先验稀疏体积辐射场的内存消耗。为了支持大规模无界场景,我们引入了一种新颖的收缩函数,可将场景坐标映射到有界体积中,同时仍允许有效的光线盒相交。我们设计了一个无损程序,用于将训练期间使用的参数化烘焙到一个模型中,该模型可实现实时渲染,同时仍保留体积辐射场的逼真视图合成质量。
Notable Papers
1.DisCO: Portrait Distortion Correction with Perspective-Aware 3D GANs
标题:DisCO:使用透视感知 3D GAN 进行人像失真校正
文章链接:https://arxiv.org/abs/2302.12253
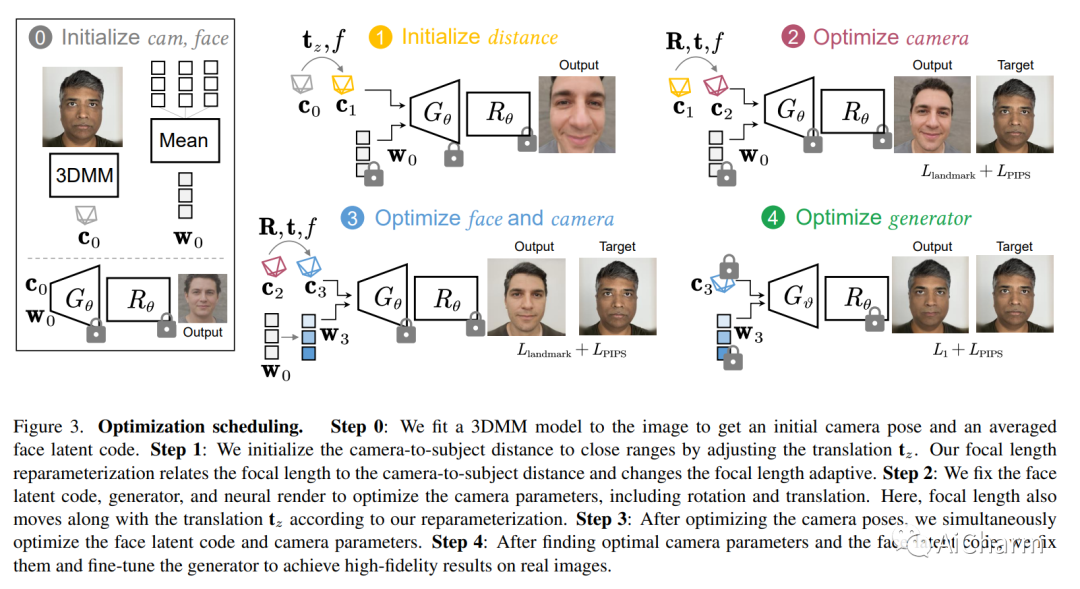
摘要:
在近距离拍摄的特写面部图像通常会出现透视失真,导致夸张的面部特征和不自然/不吸引人的外观。我们提出了一种简单而有效的方法来校正单个特写脸部中的透视失真。我们首先通过联合优化相机内部/外部参数和面部潜在代码,使用透视扭曲的输入面部图像执行 GAN 反演。为了解决联合优化的模糊性,我们开发了焦距重新参数化、优化调度和几何正则化。以适当的焦距和相机距离重新渲染肖像可以有效地纠正这些失真并产生更自然的效果。我们的实验表明,我们的方法在视觉质量方面优于以前的方法。我们展示了许多示例,以验证我们的方法在野外人像照片上的适用性。
2.Improving Adaptive Conformal Prediction Using Self-Supervised Learning
标题:使用自监督学习改进自适应适形预测
文章链接:https://arxiv.org/abs/2302.12238
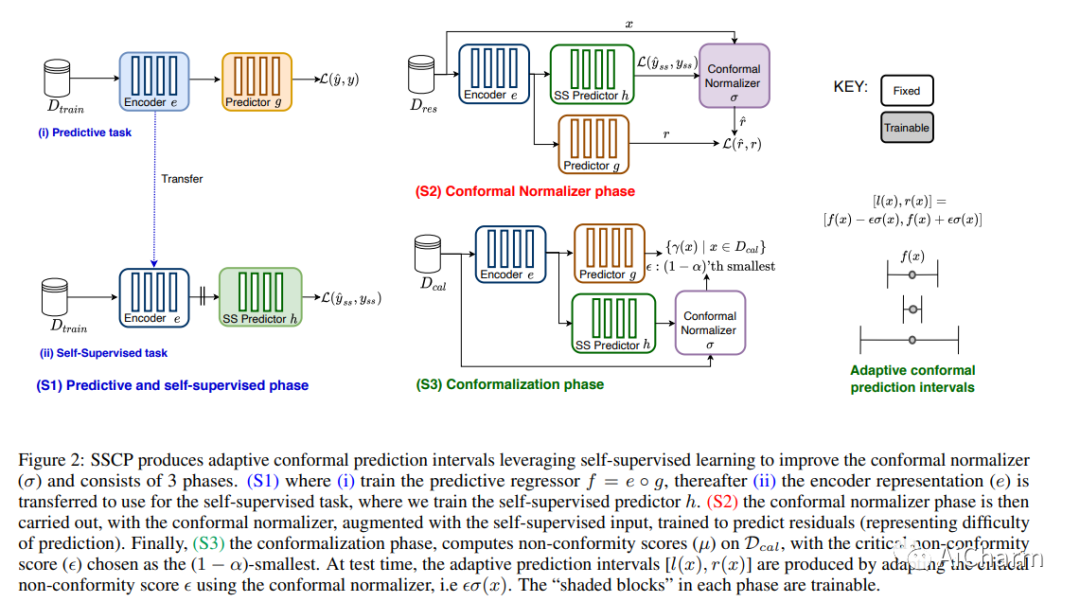
摘要:
共形预测是一种强大的无分布不确定性量化工具,可通过有限样本保证建立有效的预测区间。为了产生也适应每个实例难度的有效区间,一种常见的方法是在单独的校准集上计算归一化的不合格分数。自我监督学习已在许多领域得到有效利用,以学习下游预测变量的一般表示。然而,除了模型预训练和表示学习之外,自我监督的使用在很大程度上还没有被探索过。在这项工作中,我们研究了自我监督借口任务如何提高共形回归器的质量,特别是通过提高共形区间的适应性。我们在现有预测模型的基础上训练一个具有自我监督借口任务的辅助模型,并将自我监督错误作为附加特征来估计不合格分数。我们使用关于保形预测区间的效率(宽度)、不足和超额的合成和真实数据,凭经验证明了附加信息的好处。
3.Aligning Text-to-Image Models using Human Feedback
标题:使用人工反馈对齐文本到图像模型
文章链接:https://arxiv.org/abs/2302.12192
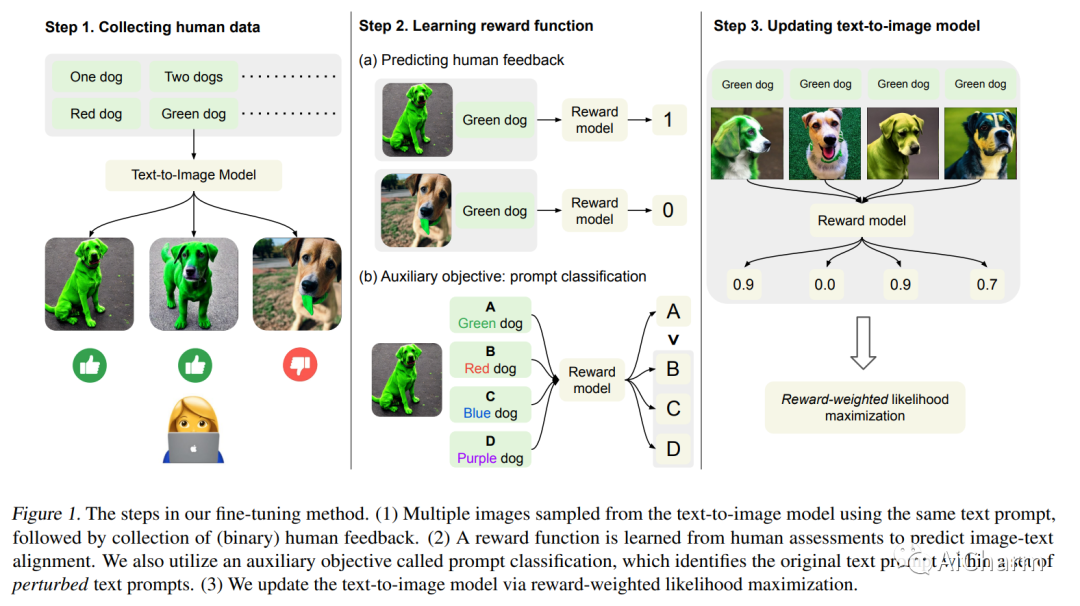
摘要:
深度生成模型在文本到图像合成方面取得了令人瞩目的成果。然而,当前的文本到图像模型通常会生成与文本提示不充分对齐的图像。我们提出了一种使用人类反馈来对齐此类模型的微调方法,包括三个阶段。首先,我们从一组不同的文本提示中收集评估模型输出对齐的人类反馈。然后,我们使用人工标记的图像文本数据集来训练预测人类反馈的奖励函数。最后,文本到图像模型通过最大化奖励加权似然来改进图像文本对齐进行微调。我们的方法比预训练模型更准确地生成具有指定颜色、计数和背景的对象。我们还分析了几种设计选择,发现对此类设计选择进行仔细调查对于平衡对齐保真度权衡非常重要。我们的结果证明了从人类反馈中学习以显着改进文本到图像模型的潜力。
更多Ai资讯:公主号AiCharm




![[LeetCode周赛复盘] 第 334 场周赛20230226](https://img-blog.csdnimg.cn/fc364e3f9f944874b814a0d211fdb92f.png)