KL 散度,是一个用来衡量两个概率分布的相似性的一个度量指标。
现实世界里的任何观察都可以看成表示成信息和数据,一般来说,我们无法获取数据的总体,我们只能拿到数据的部分样本,根据数据的部分样本,我们会对数据的整体做一个近似的估计,而数据整体本身有一个真实的分布(我们可能永远无法知道)。
那么近似估计的概率分布和数据整体真实的概率分布的相似度,或者说差异程度,可以用 KL 散度来表示。
KL 散度,最早是从信息论里演化而来的。所以在介绍 KL 散度之前,先介绍一下信息论里有关熵的概念。
熵
信息论中,某个信息 x i \large x_{i} xi 出现的不确定性的大小定义为 x i \large x_{i} xi 所携带的信息量,用 I ( x i ) I(x_{i}) I(xi) 表示。 I ( x i ) I(x_{i}) I(xi) 与信息 x i \large x_{i} xi 出现的概率 P ( x i ) P(x_{i}) P(xi) 之间的关系为
I ( x i ) = l o g 1 P ( x i ) = − l o g P ( x i ) (1) \begin{aligned} I(x_i) = & log\frac{1}{P(x_i)} = -logP(x_i) \tag{1} \\ \end{aligned} I(xi)=logP(xi)1=−logP(xi)(1)
例:掷两枚骰子,求点数和为7的信息量 点数和为7的情况为:(1,6) ; (6,1) ; (2,5) ; (5,2) ; (3,4) ; (4,3) 这6种。总的情况为 6*6 = 36 种。
那么该信息出现的概率为 P x = 7 = 6 36 = 1 6 P_{x=7}=\frac{6}{36}=\frac{1}{6} Px=7=366=61
包含的信息量为 I ( 7 ) = − log P ( 7 ) = − log 1 6 = log 6 I(7)=-\log P(7)=-\log\frac{1}{6}=\log 6 I(7)=−logP(7)=−log61=log6
以上是求单一信息的信息量。但实际情况中,会要求我们求多个信息的信息量,也就是平均信息量。
假设一共有 n 种信息,每种信息出现的概率情况由以下列出:
| X 1 X_1 X1 | X 2 X_2 X2 | X 3 X_3 X3 | X 4 X_4 X4 | . . . . . ..... ..... | X n X_n Xn |
|---|---|---|---|---|---|
| P ( x 1 ) P(x_1) P(x1) | P ( x 2 ) P(x_2) P(x2) | P ( x 3 ) P(x_3) P(x3) | P ( x 4 ) P(x_4) P(x4) | … | P ( x n ) P(x_n) P(xn) |
同时满足:
∑
i
=
1
n
P
(
x
i
)
=
1
(2)
\begin{aligned} \sum^n_{i=1} P(x_i) = 1 \tag{2} \\ \end{aligned}
i=1∑nP(xi)=1(2)
则
x
1
,
x
2
,
.
.
.
.
.
,
x
n
x_1,x_2,.....,x_n
x1,x2,.....,xn 所包含的信息量分别是 KaTeX parse error: Undefined control sequence: \logP at position 2: -\̲l̲o̲g̲P̲(x_1),-\logP(x_…平均信息量为
KaTeX parse error: Undefined control sequence: \logP at position 49: …^n_{i=1} P(x_i)\̲l̲o̲g̲P̲(x_i) \tag{3} \…
H 与热力学中的熵的定义类似,故这又被称为信息熵。
与热力学中的熵的定义类似,故这又被称为信息熵。
H ( x ) = − ( 1 8 log ( 1 8 ) + 1 8 log ( 1 8 ) + 1 4 log ( 1 4 ) + 1 2 log ( 1 2 ) ) = 1.75 \begin{aligned}H(x) = -(\frac{1}{8}\log(\frac{1}{8}) + \frac{1}{8}\log(\frac{1}{8}) + \frac{1}{4}\log(\frac{1}{4}) + \frac{1}{2}\log(\frac{1}{2}) ) = 1.75 \end{aligned} H(x)=−(81log(81)+81log(81)+41log(41)+21log(21))=1.75
连续信息的平均信息量可定义为
H ( x ) = − ∫ f ( x ) log f ( x ) d x (3) \begin{aligned} H(x) = -\int f(x)\log f(x)dx \tag{3} \end{aligned} H(x)=−∫f(x)logf(x)dx(3)
这里的 f ( x ) f(x) f(x) 是信息的概率密度。
上述我们提到了信息论中的信息熵
H
(
x
)
=
−
∑
i
=
1
n
P
(
x
i
)
log
P
(
x
i
)
=
∑
i
=
1
n
P
(
x
i
)
log
1
P
(
x
i
)
=
H
(
P
)
(4)
\begin{aligned} H(x) = -\sum^n_{i=1}P(x_i) \log P(x_i) = \sum^n_{i=1} P(x_i) \log \frac{1}{P(x_i)} = H(P) \tag{4} \end{aligned}
H(x)=−i=1∑nP(xi)logP(xi)=i=1∑nP(xi)logP(xi)1=H(P)(4)
这是一个平均信息量,又可以解释为:用基于P的编码去编码来自P的样本,其最优编码平均所需要的比特个数
接下来我们再提一个概念:交叉熵
H ( P , Q ) = − ∑ i = 1 n P ( x i ) log Q ( x i ) = ∑ i = 1 n P ( x i ) log 1 Q ( x i ) (6) \begin{aligned} H(P,Q) = -\sum^n_{i=1}P(x_i) \log Q(x_i) = \sum^n_{i=1} P(x_i) \log \frac{1}{Q(x_i)} \tag{6} \end{aligned} H(P,Q)=−i=1∑nP(xi)logQ(xi)=i=1∑nP(xi)logQ(xi)1(6)
这就解释为:用基于P的编码去编码来自Q的样本,所需要的比特个数
【注】 P ( x ) P(x) P(x) 为各字符出现的频率, log 1 P ( x ) \log \frac{1}{P(x)} logP(x)1 为该字符相应的编码长度, log 1 Q ( x ) \log \frac{1}{Q(x)} logQ(x)1 为对应于Q 的分布各字符编码长度。
KL 散度
让我们从一个问题开始我们的探索。假设我们是太空科学家,正在访问一个遥远的新行星,我们发现了一种咬人的蠕虫,我们想研究它。我们发现这些蠕虫有10颗牙齿,但由于它们不停地咀嚼,很多最后都掉了牙。在收集了许多样本后,我们得出了每条蠕虫牙齿数量的经验概率分布:
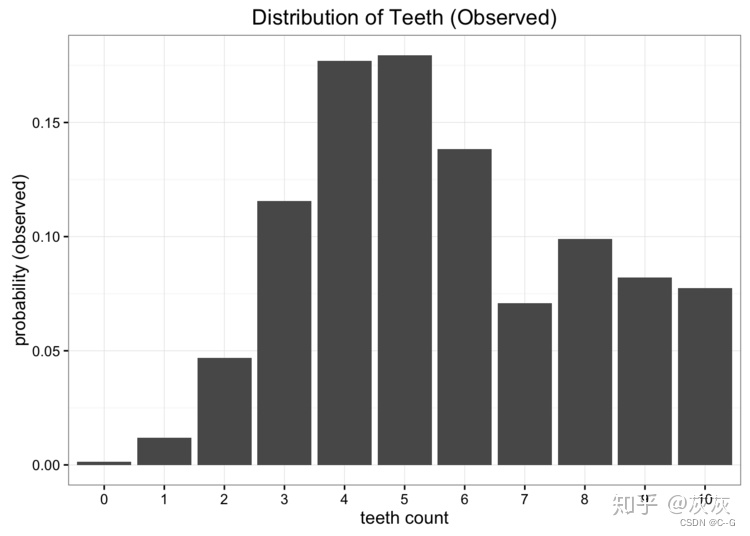
虽然这些数据很好,但我们有一个小问题。我们离地球很远,把数据寄回家很贵。我们要做的是将这些数据简化为一个只有一两个参数的简单模型。一种选择是将蠕虫牙齿的分布表示为均匀分布。我们知道有11个可能的值,我们可以指定1/11的均匀概率
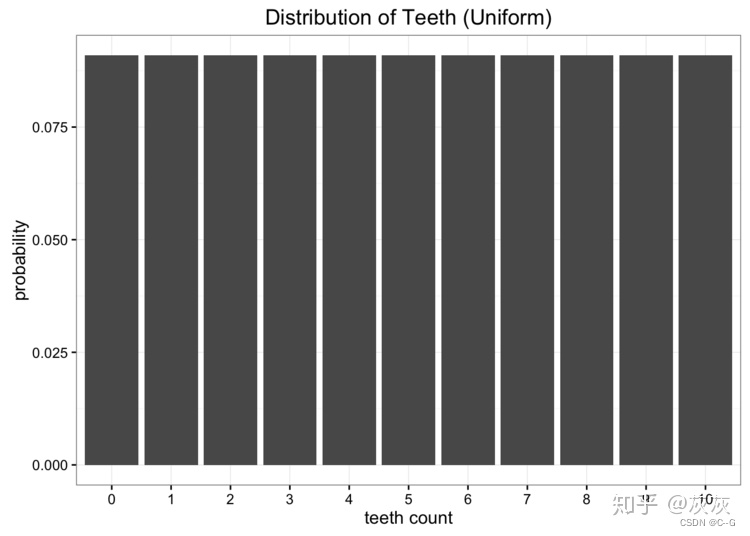
显然,我们的数据不是均匀分布的,但是看起来也不像我们所知道的任何常见分布。我们可以尝试的另一种选择是使用二项分布对数据进行建模。在这种情况下,我们要做的就是估计二项分布的概率参数。我们知道如果我们有n次试验,概率是p,那么期望就是E[x]= np。在本例中n = 10,期望值是我们数据的平均值,计算得到5.7,因此我们对p的最佳估计为0.57。这将使我们得到一个二项分布,如下所示:
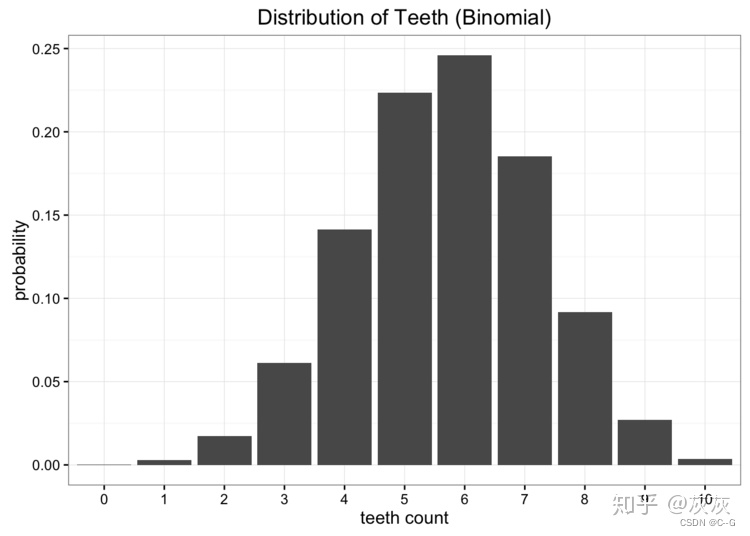
将我们的两个模型与原始数据进行比较,我们可以看出,两个都没有完美匹配原始分布,但是哪个更好?
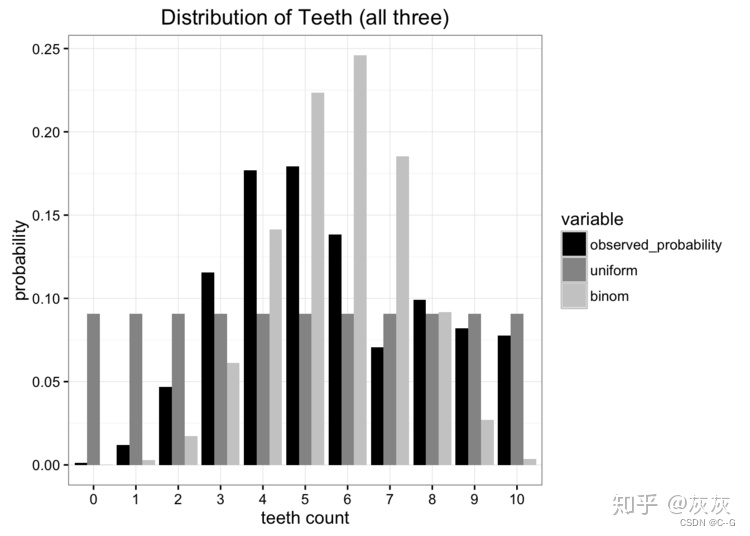
现如今有许多错误度量标准,但是我们主要关注的是必须使发送的信息量最少。这两个模型都将我们的问题所需的参数量减少。最好的方法是计算分布哪个保留了我们原始数据源中最多的信息。这就是Kullback-Leibler散度的作用。
KL散度又可称为相对熵,描述两个概率分布 P 和 Q 的差异或相似性,用 D K L ( P ∣ ∣ Q ) D_{KL}(P\left | \right |Q) DKL(P∣∣Q) 表示
D K L ( P ∣ ∣ Q ) = H ( P , Q ) − H ( P ) = ∑ i P ( x i ) log 1 Q ( x i ) − ∑ i P ( x i ) log 1 P ( x i ) = ∑ i P ( x i ) log P ( x i ) Q ( x i ) (7) \begin{aligned} D_{KL}(P || Q) & = H(P,Q) - H(P) \\ & = \sum_i P(x_i) \log \frac{1}{Q(x_i)} - \sum_i P(x_i) \log \frac{1}{P(x_i)} \\ & = \sum_i P(x_i) \log \frac{P(x_i)}{Q(x_i)} \tag{7} \\ \end{aligned} DKL(P∣∣Q)=H(P,Q)−H(P)=i∑P(xi)logQ(xi)1−i∑P(xi)logP(xi)1=i∑P(xi)logQ(xi)P(xi)(7)
很显然,散度越小,说明概率 Q 与概率 P 之间越接近,那么估计的概率分布与真实的概率分布也就越接近。
KL散度的性质:
- 非对称性: D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{KL}(P || Q) \neq D_{KL}(Q || P) DKL(P∣∣Q)=DKL(Q∣∣P)
- D K L ( P ∣ ∣ Q ) ≥ 0 D_{KL}(P || Q) \geq 0 DKL(P∣∣Q)≥0,仅在 P=Q时等于0
性质2是很重要的,可以用 Jensen 不等式证明。
Jensen 不等式与凸函数是密切相关的。可以说 Jensen 不等式是凸函数的推广,而凸函数是 Jensen 不等式的特例。




![[LeetCode周赛复盘] 第 334 场周赛20230226](https://img-blog.csdnimg.cn/fc364e3f9f944874b814a0d211fdb92f.png)