文章目录
- 一、集群简介
- 二、Redis集群结构设计
- 🍉2.1 数据存储设计
- 🍉2.2 内部通信设计
- 三、cluster 集群结构搭建
- 🍓3-1 cluster配置 .conf
- 🍓3-2 cluster 节点操作命令
- 🍓3-3 redis-trib 命令
- 🍓3-4 搭建 3主3从结构
- 🍌①开启6个redis服务器
- 🍌②节点连接
- 🍌③读写数据
- 🍌④从节点下线
- 🍌⑤主节点下线 --> 主从切换
提示:以下是本篇文章正文内容,Redis系列学习将会持续更新
一、集群简介
现状问题:业务发展过程中遇到的峰值瓶颈,如
- redis提供的服务OPS可以达到10万/秒,当前业务OPS已经达到10万/秒
- 内存单机容量达到256G,当前业务需求内存容量1T
- 使用集群的方式可以快速解决上述问题
什么是集群?
集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果。
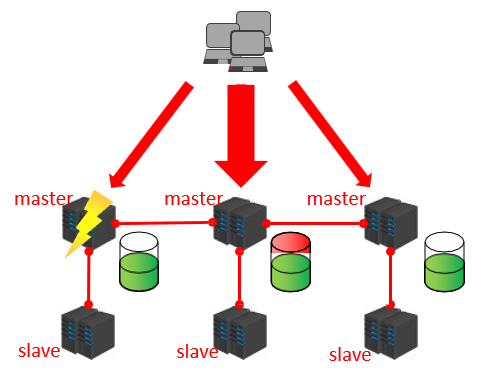
集群作用:
- 分散单台服务器的访问压力,实现负载均衡。
- 分散单台服务器的存储压力,实现可扩展性。
- 降低单台服务器宕机带来的业务灾难。
回到目录…
二、Redis集群结构设计
🍉2.1 数据存储设计
- 通过算法设计,计算出 key 应该保存的位置。
- 将所有的存储空间计划切割成16384份,每台主机保存一部分;
每份代表的是一个存储空间,不是一个 key 的保存空间。 - 将 key 按照计算出的结果放到对应的存储空间。
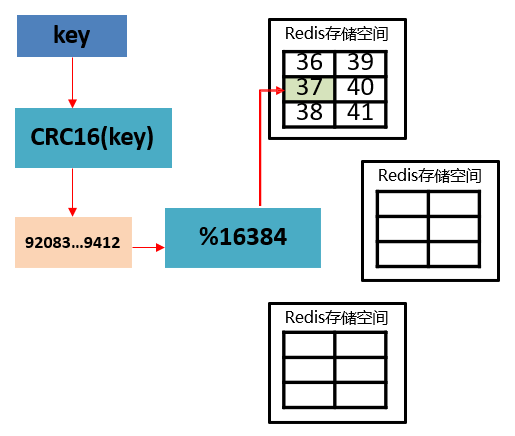
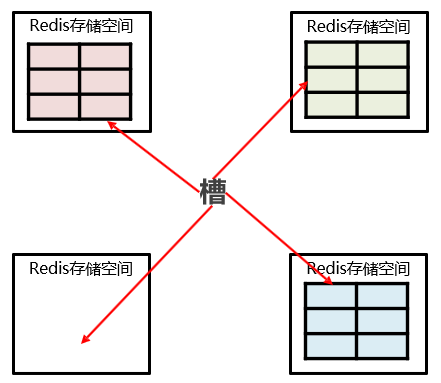
- 增强扩展性。当加入新的master节点时,原本的主节点会各自分出一部分"槽",分给新节点。
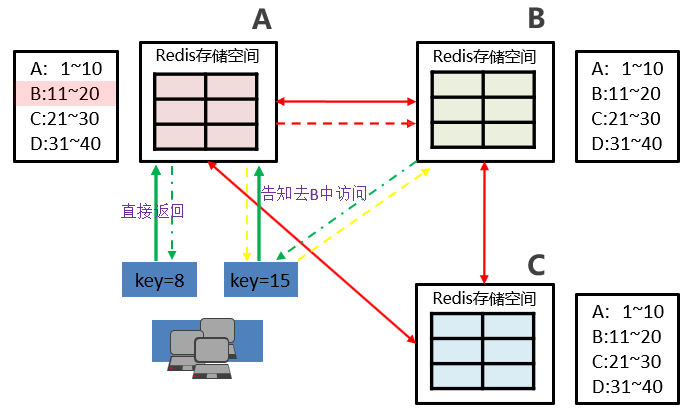
🍉2.2 内部通信设计
- 各个数据库相互通信,保存各个库中槽的编号数据。
- 一次命中,直接返回。
- 一次未命中,告知具体位置。让客户端直接去找编号节点。
回到目录…
三、cluster 集群结构搭建
-
集群采用了多主多从,按照一定的规则进行分片,将数据分别存储,一定程度上解决了哨兵模式下单机存储有限的问题。
-
集群模式一般是3主3从,且需要 ruby 辅助搭建。
🍓3-1 cluster配置 .conf
● 添加节点
cluster-enabled yes|no
● cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file <filename>
● 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-node-timeout <milliseconds>
● 每个master连接的slave最小数量
cluster-migration-barrier <count>
回到目录…
🍓3-2 cluster 节点操作命令
● 查看集群节点信息
# 在客户端操作,查看节点情况
cluster nodes

● 进入一个从节点 redis,切换其主节点
cluster replicate <master-id>
● 发现一个新节点,新增主节点
cluster meet ip:port
● 忽略一个没有solt的节点
cluster forget <id>
● 手动故障转移
cluster failover
回到目录…
🍓3-3 redis-trib 命令
● 添加节点
redis-trib.rb add-node
● 删除节点
redis-trib.rb del-node
● 重新分片
redis-trib.rb reshard
回到目录…
🍓3-4 搭建 3主3从结构
redis集群需要提前安装脚本和环境,参考文章:Linux 离线安装Ruby和RubyGems环境
🍌①开启6个redis服务器
6个服务器的配置文件(除端口外)都一致,设置了相同的cluster配置。
port 6381
daemonize no
dir /root/redis-4.0.0/data
dbfilename dump-6381.rdb
rdbcompression yes
rdbchecksum yes
save 10 2
appendonly yes
appendfsync always
appendfilename appendonly-6381.aof
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000
全部开启:
redis-server /root/redis-4.0.0/conf/redis-6381.conf
使用 ps -ef | grep redis 查进程:

服务器日志:此时6个基本一致
[root@VM-4-12-centos ~]# redis-server /root/redis-4.0.0/conf/redis-6381.conf
2346399:C 25 Feb 12:09:58.554 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2346399:C 25 Feb 12:09:58.554 # Redis version=4.0.0, bits=64, commit=00000000, modified=0, pid=2346399, just started
2346399:C 25 Feb 12:09:58.554 # Configuration loaded
2346399:M 25 Feb 12:09:58.554 * Increased maximum number of open files to 10032 (it was originally set to 1024).
2346399:M 25 Feb 12:09:58.555 * Node configuration loaded, I'm 0ed68dc297e87f62154aa236e46cb287c22c735a
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.0 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in cluster mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6381
| `-._ `._ / _.-' | PID: 2346399
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
2346399:M 25 Feb 12:09:58.556 # Server initialized
2346399:M 25 Feb 12:09:58.556 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
2346399:M 25 Feb 12:09:58.556 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
2346399:M 25 Feb 12:09:58.556 * DB loaded from disk: 0.000 seconds
2346399:M 25 Feb 12:09:58.556 * Ready to accept connections
回到目录…
🍌②节点连接
# 进入redis的src下
cd /root/redis-4.0.0/src
# 执行 redis-trib.rb 程序,该程序需要依赖 ruby 和 rubygem
# replicas 1 表示为集群中的每个主节点创建 1 个从节点
./redis-trib.rb create --replicas 1 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 127.0.0.1:6386
例如:构建3主6从,一拖二的结构
./redis-trib.rb create --replicas 2 id:p主 id:p主 id:p主 id:p从 id:p从 id:p从 id:p从 id:p从 id:p从
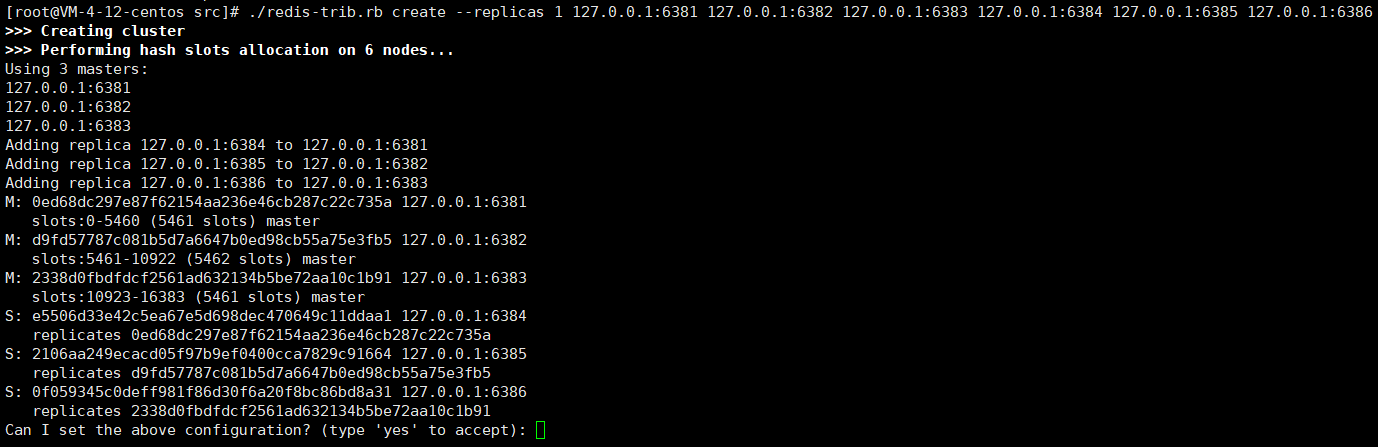
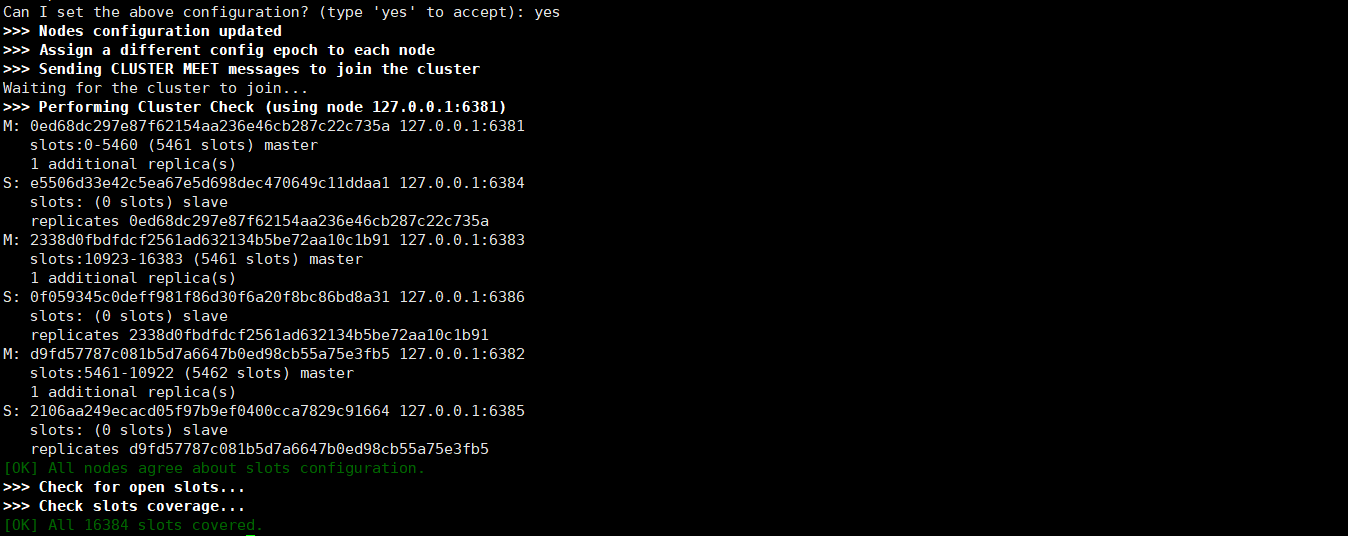
连接成功!
master-6381 日志: 内容和 master-6382、master-6383 差不多
.......
2346399:M 25 Feb 12:09:58.556 * Ready to accept connections
2346399:M 25 Feb 14:22:02.884 # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH
2346399:M 25 Feb 14:22:02.890 # IP address for this node updated to 127.0.0.1
2346399:M 25 Feb 14:22:06.906 * Slave 127.0.0.1:6384 asks for synchronization
2346399:M 25 Feb 14:22:06.906 * Unable to partial resync with slave 127.0.0.1:6384 for lack of backlog (Slave request was: 1).
2346399:M 25 Feb 14:22:06.906 # Warning: slave 127.0.0.1:6384 tried to PSYNC with an offset that is greater than the master replication offset.
2346399:M 25 Feb 14:22:06.906 * Starting BGSAVE for SYNC with target: disk
2346399:M 25 Feb 14:22:06.907 * Background saving started by pid 2378127
2378127:C 25 Feb 14:22:06.915 * DB saved on disk
2378127:C 25 Feb 14:22:06.916 * RDB: 6 MB of memory used by copy-on-write
2346399:M 25 Feb 14:22:07.002 * Background saving terminated with success
2346399:M 25 Feb 14:22:07.002 * Synchronization with slave 127.0.0.1:6384 succeeded
2346399:M 25 Feb 14:22:07.803 # Cluster state changed: ok
slave-6384 日志: 内容和 slave-6385、slave-6386 差不多
...........
2346637:M 25 Feb 12:10:42.962 * Ready to accept connections
2346637:M 25 Feb 14:22:02.885 # configEpoch set to 4 via CLUSTER SET-CONFIG-EPOCH
2346637:M 25 Feb 14:22:02.992 # IP address for this node updated to 127.0.0.1
2346637:S 25 Feb 14:22:06.897 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
2346637:S 25 Feb 14:22:06.897 # Cluster state changed: ok
2346637:S 25 Feb 14:22:06.905 * Connecting to MASTER 127.0.0.1:6381
2346637:S 25 Feb 14:22:06.905 * MASTER <-> SLAVE sync started
2346637:S 25 Feb 14:22:06.905 * Non blocking connect for SYNC fired the event.
2346637:S 25 Feb 14:22:06.905 * Master replied to PING, replication can continue...
2346637:S 25 Feb 14:22:06.905 * Trying a partial resynchronization (request 4037f6d4ae3c949826df258a306140250b64ae2f:1).
2346637:S 25 Feb 14:22:06.907 * Full resync from master: cde4a8dc111330cc81ec5c0d1321b2959741f441:0
2346637:S 25 Feb 14:22:06.907 * Discarding previously cached master state.
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: receiving 175 bytes from master
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: Flushing old data
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: Loading DB in memory
2346637:S 25 Feb 14:22:07.002 * MASTER <-> SLAVE sync: Finished with success
回到目录…
🍌③读写数据
常规的连接方式,会出现以下错误:
[root@VM-4-12-centos ~]# redis-cli -p 6381
127.0.0.1:6381> set name zhangsan
(error) MOVED 5798 127.0.0.1:6382
所以应该 redis-cli -c 指令连接。
master客户端添加数据:
[root@VM-4-12-centos ~]# redis-cli -c -p 6381
127.0.0.1:6381> set name zhangsan
-> Redirected to slot [5798] located at 127.0.0.1:6382
OK
127.0.0.1:6382> set age 21
-> Redirected to slot [741] located at 127.0.0.1:6381
OK
127.0.0.1:6381>
slave客户端获取数据:
[root@VM-4-12-centos ~]# redis-cli -c -p 6384
127.0.0.1:6384> get name
-> Redirected to slot [5798] located at 127.0.0.1:6382
"zhangsan"
127.0.0.1:6382> get age
-> Redirected to slot [741] located at 127.0.0.1:6381
"21"
127.0.0.1:6381>
回到目录…
🍌④从节点下线
slave-6384 下线:

master-6381 日志: 发现它的从节点6384丢失了,并且作了标记
...........
2346399:M 25 Feb 15:22:07.315 # Connection with slave 127.0.0.1:6384 lost.
2346399:M 25 Feb 15:22:12.428 * Marking node e5506d33e42c5ea67e5d698dec470649c11ddaa1 as failing (quorum reached).
master-6382、master-6383、slave-6385、slave-6386 日志: 其余4个服务器也发现了,并记下了这个消息
...........
2346482:M 25 Feb 15:22:12.429 * FAIL message received from 0ed68dc297e87f62154aa236e46cb287c22c735a about e5506d33e42c5ea67e5d698dec470649c11ddaa1
slave-6384 重新上线:

master-6381 日志: 重新作了连接
...........
2346399:M 25 Feb 15:32:33.828 * Clear FAIL state for node e5506d33e42c5ea67e5d698dec470649c11ddaa1: slave is reachable again.
2346399:M 25 Feb 15:32:34.759 * Slave 127.0.0.1:6384 asks for synchronization
2346399:M 25 Feb 15:32:34.759 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for 'bccefbb3fa28bfcb388a9f72af318c28169f4bc1', my replication IDs are 'cde4a8dc111330cc81ec5c0d1321b2959741f441' and '0000000000000000000000000000000000000000')
2346399:M 25 Feb 15:32:34.759 * Starting BGSAVE for SYNC with target: disk
2346399:M 25 Feb 15:32:34.764 * Background saving started by pid 2395173
2395173:C 25 Feb 15:32:34.771 * DB saved on disk
2395173:C 25 Feb 15:32:34.771 * RDB: 6 MB of memory used by copy-on-write
2346399:M 25 Feb 15:32:34.830 * Background saving terminated with success
2346399:M 25 Feb 15:32:34.830 * Synchronization with slave 127.0.0.1:6384 succeeded
master-6382、master-6383、slave-6385、slave-6386 日志: 其余4个服务器也发现了,清除了刚刚的信息
...........
2346482:M 25 Feb 15:32:33.828 * Clear FAIL state for node e5506d33e42c5ea67e5d698dec470649c11ddaa1: slave is reachable again.
回到目录…
🍌⑤主节点下线 --> 主从切换
master-6381 下线:

master-6382、master-6383 日志: 发现主节点6384丢失了,并且作了标记
.......
2346482:M 25 Feb 15:34:59.063 * Marking node 0ed68dc297e87f62154aa236e46cb287c22c735a as failing (quorum reached).
2346482:M 25 Feb 15:34:59.063 # Cluster state changed: fail
2346482:M 25 Feb 15:34:59.939 # Failover auth granted to e5506d33e42c5ea67e5d698dec470649c11ddaa1 for epoch 7
2346482:M 25 Feb 15:34:59.979 # Cluster state changed: ok
slave-6385、slave-6386 日志: 也发现了,并记下了这个消息
.......
2346782:S 25 Feb 15:34:59.063 * FAIL message received from 2338d0fbdfdcf2561ad632134b5be72aa10c1b91 about 0ed68dc297e87f62154aa236e46cb287c22c735a
2346782:S 25 Feb 15:34:59.063 # Cluster state changed: fail
2346782:S 25 Feb 15:34:59.943 # Cluster state changed: ok
slave-6384 -> master-6384 日志: 发现主节点丢失,请求重连,主从切换。
.......
# 发现主节点丢失了
2395168:S 25 Feb 15:34:53.651 # Connection with master lost.
2395168:S 25 Feb 15:34:53.651 * Caching the disconnected master state.
# 在设置的5000ms超时时间内开始重连
2395168:S 25 Feb 15:34:54.015 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:54.015 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:54.015 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:55.018 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:55.018 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:55.018 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:56.020 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:56.020 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:56.020 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:57.024 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:57.024 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:57.024 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:58.027 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:58.027 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:58.028 # Error condition on socket for SYNC: Connection refused
2395168:S 25 Feb 15:34:59.031 * Connecting to MASTER 127.0.0.1:6381
2395168:S 25 Feb 15:34:59.031 * MASTER <-> SLAVE sync started
2395168:S 25 Feb 15:34:59.031 # Error condition on socket for SYNC: Connection refused
# 确认丢失消息
2395168:S 25 Feb 15:34:59.064 * FAIL message received from 2338d0fbdfdcf2561ad632134b5be72aa10c1b91 about 0ed68dc297e87f62154aa236e46cb287c22c735a
# 开始由 从服务器 切换成 主服务器
2395168:S 25 Feb 15:34:59.064 # Cluster state changed: fail
2395168:S 25 Feb 15:34:59.131 # Start of election delayed for 796 milliseconds (rank #0, offset 5275).
2395168:S 25 Feb 15:34:59.934 # Starting a failover election for epoch 7.
2395168:S 25 Feb 15:34:59.939 # Failover election won: I'm the new master.
2395168:S 25 Feb 15:34:59.939 # configEpoch set to 7 after successful failover
2395168:M 25 Feb 15:34:59.939 # Setting secondary replication ID to cde4a8dc111330cc81ec5c0d1321b2959741f441, valid up to offset: 5276. New replication ID is f9337124051125fde50c606a79678a01de021ce7
2395168:M 25 Feb 15:34:59.939 * Discarding previously cached master state.
2395168:M 25 Feb 15:34:59.939 # Cluster state changed: ok
回到目录…
slave-6381 重新上线: 此时作为 slave 连接到 master-6384上
[root@VM-4-12-centos ~]# redis-server /root/redis-4.0.0/conf/redis-6381.conf
2402821:C 25 Feb 16:03:46.080 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2402821:C 25 Feb 16:03:46.080 # Redis version=4.0.0, bits=64, commit=00000000, modified=0, pid=2402821, just started
2402821:C 25 Feb 16:03:46.080 # Configuration loaded
2402821:M 25 Feb 16:03:46.081 * Increased maximum number of open files to 10032 (it was originally set to 1024).
2402821:M 25 Feb 16:03:46.082 * Node configuration loaded, I'm 0ed68dc297e87f62154aa236e46cb287c22c735a
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.0 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in cluster mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6381
| `-._ `._ / _.-' | PID: 2402821
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
2402821:M 25 Feb 16:03:46.083 # Server initialized
2402821:M 25 Feb 16:03:46.083 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
2402821:M 25 Feb 16:03:46.083 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
2402821:M 25 Feb 16:03:46.083 * DB loaded from disk: 0.000 seconds
2402821:M 25 Feb 16:03:46.083 * Ready to accept connections
2402821:M 25 Feb 16:03:46.083 # Configuration change detected. Reconfiguring myself as a replica of e5506d33e42c5ea67e5d698dec470649c11ddaa1
2402821:S 25 Feb 16:03:46.083 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
2402821:S 25 Feb 16:03:46.084 # Cluster state changed: ok
2402821:S 25 Feb 16:03:47.085 * Connecting to MASTER 127.0.0.1:6384
2402821:S 25 Feb 16:03:47.086 * MASTER <-> SLAVE sync started
2402821:S 25 Feb 16:03:47.086 * Non blocking connect for SYNC fired the event.
2402821:S 25 Feb 16:03:47.086 * Master replied to PING, replication can continue...
2402821:S 25 Feb 16:03:47.086 * Trying a partial resynchronization (request cde4a8dc111330cc81ec5c0d1321b2959741f441:5080).
2402821:S 25 Feb 16:03:47.086 * Successful partial resynchronization with master.
2402821:S 25 Feb 16:03:47.086 # Master replication ID changed to f9337124051125fde50c606a79678a01de021ce7
2402821:S 25 Feb 16:03:47.086 * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization.
master-6384 日志: 重新作了连接
......
2395168:M 25 Feb 16:03:46.096 * Clear FAIL state for node 0ed68dc297e87f62154aa236e46cb287c22c735a: master without slots is reachable again.
2395168:M 25 Feb 16:03:47.086 * Slave 127.0.0.1:6381 asks for synchronization
2395168:M 25 Feb 16:03:47.086 * Partial resynchronization request from 127.0.0.1:6381 accepted. Sending 196 bytes of backlog starting from offset 5080.
master-6382、master-6383、slave-6385、slave-6386 日志: 其余4个服务器也发现了,清除了刚刚的信息
......
2346482:M 25 Feb 16:03:46.095 * Clear FAIL state for node 0ed68dc297e87f62154aa236e46cb287c22c735a: master without slots is reachable again.
回到目录…
总结:
提示:这里对文章进行总结:
本文是对Redis集群的学习,了解了Redis集群的数据存储设计、内部通信设计,以及 cluster 集群结构搭建的具体方法。之后的学习内容将持续更新!!!