Topic Coherence You Need to Know
皮皮,京哥 皮皮,京哥 皮皮,京哥 C o m m u n i c a t i o n U n i v e r s i t y o f C h i n a Communication\ University\ of\ China Communication University of China
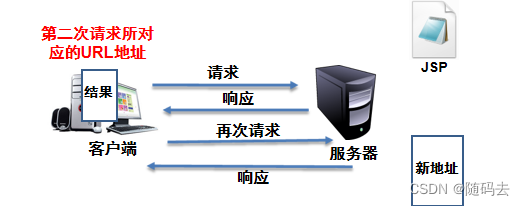
在大多数关于主题建模的文章中,常用主题连贯度(Topic Coherence,主题一致性)或主题连贯度指标(Topic Coherence Metrics)来表示整体主题的可解释性,用于评估主题的质量。
但是,该指标到底指什么?它是如何衡量主题的可解释性的?该值是否越大越好?本文将就这些问题做出解答。
1.主题建模
主题建模将文本数据集分解为主题和单词这两个分布来进行解释。一般基于以下假设:
- 一个文档由几个主题组成
- 一个主题由一组单词组成
因此,可以将主题建模算法理解为一种数学上的统计模型,用于推断哪些主题更能代表数据。
简单来说,主题可以被描述为单词的集合,例如 [ball, cat, house] 和 [airplane, clouds]。但实际上,算法要做的是为我们词汇表中的每个单词分配一个给定主题的参与值。具有高参与值的单词可以被视为该主题的代表。

2.评估主题
主题建模算法基于数学和统计学。但站在人的视角,数学上最优的主题并不一定是最好的主题。
例如,根据主题建模算法得到以下两个主题:
- Topic 1:
cat,dog,home,toy(可能是个好的主题) - Topic 2:
super,nurse,brick(可能是个比较糟的主题)
从人的视角来看,第一个主题要比第二个主题更连贯,但对于算法而言,它们可能拥有相同的指标。
构建的主题应该是易于理解的。因此,盲目地遵循主题模型算法背后的数学原理可能会误导我们,并生成无意义的主题。
正因如此,主题评估工作通常需要人工参与,例如阅读每个主题中最重要的单词,查看与每个文档相关的主题。但是,对于具有数千个主题的大规模数据集,此任务可能非常耗时且不切实际。它还需要有关数据集领域的先验知识,并且可能需要专家意见。
主题连贯度试图以 独特、客观且易于评估的数字 来代表对主题的 高质量人类感知。
3.如何计算主题连贯性
通常,连贯性指的是 合作特征。如果一组论点相互印证,我们可以认为它们是连贯的。
此处,主题连贯性指的是文本集(称为参考语料库,reference corpus)支持 主题的程度。它从参考语料中提取统计数据和概率,并特别关注单词的上下文,计算主题连贯性分数。这也说明主题连贯性度量不仅取决于主题本身,还取决于参考语料。

Röder, M. 等人在论文《Exploring the Space of Topic Coherence Measures》中提出了主题连贯性度量的一般结构如下:

该结构由不同的独立模块组合而成,每个模块都执行特定的任务。
可以把计算主题连贯性度量看做是一个管道(Pipeline),它接收主题和参考语料作为输入,并输出一个代表 整体主题连贯性 的值。该过程模拟了人类对主题进行评估。
3.1 Segmentation
该模块负责创建用来评估主题连贯性的单词子集。
假设 W W W 包含了主题 t t t 的前 n n n 个最重要的单词 { w 1 , w 2 , … , w n } \{w_1, w_2, …, w_n\} {w1,w2,…,wn},对 W W W 的进行分割,得到子集对 S S S。

W
∗
W^*
W∗ 用于对
W
′
W^{'}
W′ 进行确认。下一小节将会结合实例对此进行介绍。简单来说,分割可以理解为如何 混合 主题中的单词,以进行后面的评估步骤。
例如,S-one-one 表示对不同的词进行配对。此种模式下,模型对主题中任意两个词之间的关系感兴趣。所以,若
W
W
W 为
{
‘
c
a
t
’
,
‘
d
o
g
’
,
‘
t
o
y
’
}
\{‘cat’, ‘dog’, ‘toy’\}
{‘cat’,‘dog’,‘toy’},则有:

而 S-one-all 则表示将每个词与其他所有词配对。此种模式下,连贯性分数将基于单个词与主题中其余词之间的关系。应用于
W
W
W,则有:

3.2 Probability Calculation
例如,假设我们对两种不同的概率感兴趣:
- P ( w ) P(w) P(w):词 w w w 出现的概率
- P ( w 1 a n d w 2 ) P(w1\ and\ w2) P(w1 and w2):词 w 1 w1 w1 和 w 2 w2 w2 出现的概率
针对这些概率有不同的计算方法,例如:
-
P
b
d
Pbd
Pbd(
b
d
bd
bd 代表
boolean document): P ( w ) P(w) P(w) 表示包含单词 w w w 的文档数除以文档总数, P ( w 1 a n d w 2 ) P(w1\ and\ w2) P(w1 and w2) 表示包含单词 w 1 w1 w1 和 w 2 w2 w2 的文档数除以文档总数。 -
P
b
s
Pbs
Pbs(
b
s
bs
bs 代表
boolean sentence),该方法与 P b d Pbd Pbd 方法类似,但它考虑的是单词在句子中的出现次数,而不是文档中的出现次数。 -
P
s
w
Psw
Psw(
s
w
sw
sw 代表
sliding window),它考虑的是单词在文本滑动窗口中出现的次数。
3.3 Confirmation Measure
该步骤是计算主题连贯性的核心。用从 P P P 中得到的概率在 S S S 上计算确认度量,即用从语料库计算的概率来量化两个子集之间的 关系。
此步骤会计算 W ∗ W^{*} W∗ 对 W ′ W^{'} W′ 的支持程度。因此,如果 W ′ W^{'} W′ 中的词与 W ∗ W^{*} W∗ 中的词相关联(例如,经常出现在同一文档中),则确认度会很高。

上图中,确认度量
m
m
m 应用于每一个子集对,并输出确认分数。有两种不同类型的确认措施:
- 直接确认措施:这些度量通过直接使用子集 W ′ W^{'} W′ 和 W ∗ W^{*} W∗ 以及概率来计算确认值。例如:



- 间接确认措施:间接确认措施不会直接根据 W ′ W^{'} W′ 和 W ∗ W^{*} W∗ 计算分数。它们计算 W ′ W^{'} W′ 中的单词和 W W W 中所有其他单词的直接确认度量 m m m,构建了一个度量向量,如下图所示。再对 W ∗ W^{*} W∗ 进行相同的处理。最后以这两个向量之间的相似性(例如,余弦相似性)作为最后的确认度量结果。

![]()
例如,为了计算
(
‘
c
a
t
’,‘
d
o
g
’
)
(‘cat’,‘dog’)
(‘cat’,‘dog’) 的确认度量,首先计算每个元素和主题中所有单词的确认度量
m
m
m ,创建一个确认度量向量。然后,最终的确认措施是这两个向量之间的相似性。

该过程表明了直接方法的一些缺点。例如,cat 和 dog 这两个词可能永远不会在我们的数据集中出现,但它们可能经常与 toy、pets 和 cute 这些词一起出现。使用直接方法,这两个词的确认分数较低,但使用间接方法,相似性可能会很突出,因为它们出现在相似的上下文中。
3.4 Aggregation
此处会将上一步计算的所有值聚合成一个值,即最终的主题连贯性分数。聚合方法可以是 算术平均数、中位数、几何平均数 等。

3.5 小结
回顾一下上述步骤。
- 有一个待评估的主题
- 选择一个参考语料库
- 找到主题中最重要的前 n n n 个词,记为 W W W
- 将 W W W 分割成子集对 S S S
- 利用参考语料库,使用技术 P P P 计算单词概率
- 使用确认度量 m m m 来评估每个子集对之间的关系
- 汇总得到一个最终数字,即主题连贯性得分

在多个主题的情况下,最终结果是单个主题连贯性的平均值。

4.Gensim中的模型
Gensim 提供了四种计算主题连贯性的方法:u_mass、c_v、c_uci、c_npmi。

在原论文中,作者已经详细说明了这些模型是如何构建的。

以 C_NPMI 为例:
Segmentation:采用S-one-one的方法,即在成对的词上计算确认度。Probability Calculation:使用方法 P s w ( 10 ) Psw(10) Psw(10)。滑动窗口的大小为 10 10 10。Confirmation Measure:确认措施是归一化逐点互信息(NPMI)。

Aggregation:利用算术平均值进行聚合。
C_V 方法同理:
Segmentation:采用S-one-set的方法,即确认度量将在一个词和集合 W W W 的对上计算。Probability Calculation:使用方法 P s w ( 110 ) Psw(110) Psw(110)。滑动窗口大小为 110 110 110。Confirmation Measure:该步使用间接确认措施。使用度量 m n l r m_{nlr} mnlr,将每对元素的单词与 W W W 的所有其他单词进行比较。最终得分是两个度量向量之间的余弦相似度。Aggregation:利用算术平均值进行聚合。
5.实践
import pandas as pd
import re
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_20newsgroups
from gensim.models.coherencemodel import CoherenceModel
from gensim.corpora.dictionary import Dictionary
texts, _ = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'), return_X_y=True )
tokenizer = lambda s: re.findall('\w+', s.lower() )
texts = [tokenizer(t) for t in texts]
在 Gensim 中计算 Coherence 非常简单,只需要创建一组主题并传递文本即可。
# Creating some random topics
topics = [ ['space', 'planet', 'mars', 'galaxy'],
['cold', 'medicine', 'doctor', 'health', 'water'],
['cats', 'health', 'keyboard', 'car', 'banana'],
['windows', 'mac', 'computer', 'operating', 'system'] ]
# Creating a dictionary with the vocabulary
word2id = Dictionary(texts)
# Coherence model
cm = CoherenceModel(topics=topics,
texts=texts,
coherence='c_v',
dictionary=word2id)
coherence_per_topic = cm.get_coherence_per_topic()
.get_coherence_per_topic() 方法返回每个主题的连贯性值。
topics_str = ['\n '.join(t) for t in topics]
data_topic_score = pd.DataFrame(data=zip(topics_str, coherence_per_topic), columns=['Topic', 'Coherence'])
data_topic_score = data_topic_score.set_index('Topic')
fig, ax = plt.subplots(figsize=(2,6))
ax.set_title("Topics coherence\n $C_v$")
sns.heatmap(data=data_topic_score, annot=True, square=True,
cmap='Reds', fmt='.2f',
linecolor='black', ax=ax )
plt.yticks(rotation=0)
ax.set_xlabel('')
ax.set_ylabel('')
fig.show()

6.总结
主题连贯性是衡量一个主题质量的重要标准。本文中,我们深入探讨了主题连贯性的基本结构和数学原理。通过 Segmentation、Probability Calculation、Confirmation Measure、Aggregation 等步骤计算主题连贯性。并通过代码实例了解了如何在 Gensim 中计算主题连贯性。