Detr源码解读(mmdetection)
1、原理简要介绍
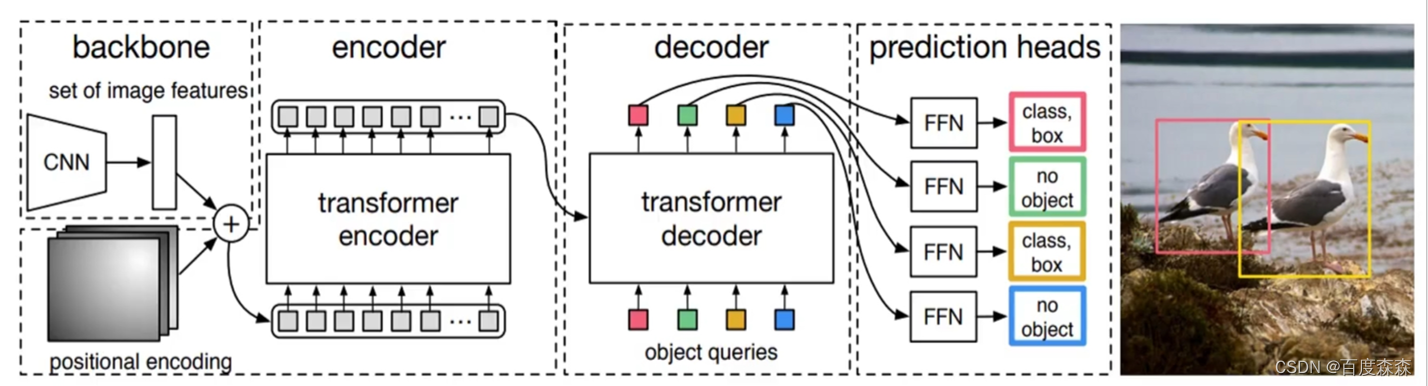
整体流程: 在给定一张输入图像后,1)特征向量提取: 首先经过ResNet提取图像的最后一层特征图F。注意此处仅仅用了一层特征图,是因为后续计算复杂度原因,另外,由于仅用最后一层特征图,故对小目标检测不友好,这也是后续deformable detr改进的原因。 2)添加位置编码信息: 经F拉平成一维张量并添加上位置编码信息得到I。3)Transformer中encoder部分4)Transformer中decoder部分,学习位置嵌入object queries。5)FFN部分:6)后续匈牙利匹配+损失计算。
2、mmdetection中源码介绍
2.1. 整体逻辑
Detr的内部逻辑如下:在mmdet/models/detector/single_stage.py。即首先提取图像特征向量,之后经过DetrHead来计算最终的损失。img[b,3,224,224] x[b,2048,7,7]
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None):
super(SingleStageDetector, self).forward_train(img, img_metas)
# img[b,3,224,224] x[b,2048,7,7]
x = self.extract_feat(img) # 提取图像特征向量
# 经过DetrHead得到loss
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
return losses
forward_train
跟其他的检测头差不多,先是调用自己,也就是自身的 forward 函数,得到输出的 class label 和 reg coordinate,再调用自身的 loss 函数,不过这里是重载了一下,将 img_meta 传输进了 forward 函数的参数。执行完outs = self(x, img_metas)跳转到forward的num_levels = len(feats)
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""Forward function for training mode.
Args:
x (list[Tensor]): Features from backbone.
img_metas (list[dict]): Meta information of each image每个图像的元信息, e.g.,
image size, scaling factor, etc.
gt_bboxes (Tensor): Ground truth bboxes of the image,图像的地面真相框
shape (num_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be ignored,要忽略的基本事实框,
shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,测试/后处理配置
if None, test_cfg would be used.
Returns:
dict[str, Tensor]: A dictionary of loss components.损失成分词典。
"""
assert proposal_cfg is None, '"proposal_cfg" must be None'
outs = self(x, img_metas) #x[b,2048,7,7]
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
return losses
执行完outs = self(x, img_metas)跳转到forward的num_levels = len(feats)。feats[b,2048,7,7]
def forward(self, feats, img_metas):
#这里默认为1,因为DETR默认用最后一层特征图
num_levels = len(feats)
img_metas_list = [img_metas for _ in range(num_levels)]
return multi_apply(self.forward_single, feats, img_metas_list)
执行完return multi_apply(self.forward_single, feats, img_metas_list)跳转到forward_single函数
2.2. 图像特征向量提取
mmdet中提取图像特征向量的config配置文件如下,可以发现用ResNet50并只提取了最后一层特征层,即out_indices=(3,)。骨干网络会输出特征图的1/32,输入为【2,3,224,224】。通过backbone后得到图像大小为【2, 2048, 7, 7】和mask大小为【2,7,7】
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(3, ), # detr仅要resnet50的最后一层特征图,并不需要FPN
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'))
2.3. 给图像特征向量添加位置编码信息(forward_single函数,里面是 head 前向的逻辑)。
本部分代码来自mmdet/models/dense_heads/detr_head.py的 forward_single函数中。
mmdet中生成位置编码信息借助的是mask矩阵(所谓的mask就是为了统一批次大小而对图像进行了pad,被填充的部分在后续计算多头注意力时应该舍弃)故需要一个mask矩阵遮挡住,具体形状为[batch, h,w]这里先贴下生成mask的过程:
batch_size = x.size(0)
input_img_h, input_img_w = img_metas[0]['batch_input_shape']# 一个批次图像大小
# 先将 mask 设置为全 1
masks = x.new_ones((batch_size, input_img_h, input_img_w)) # [b,224,224]
# 对每一张图来说,在原来图片有像素的地方把 mask 置 0
# 因此 mask 中 padding 的地方才是 1
for img_id in range(batch_size):
img_h, img_w, _ = img_metas[img_id]['img_shape'] # 创建了一个mask,非0代表无效区域, 0 代表有效区域
masks[img_id, :img_h, :img_w] = 0 # 将pad部分置为1,非pad部分置为0.
输入图像的经过resnet50下采样后hw已经变了,所以还需进一步将mask下采样成和图像特征向量一样的shape。代码如下:
# 将每一层的特征图先投影到指定的特征维度,2048通道太多了转成256通道
x = self.input_proj(x) #Conv2d(self.in_channels, self.embed_dims, kernel_size=1)#[b,256,7,7]
# interpolate masks to have the same spatial shape with x
masks = F.interpolate( #masks[b,7,7]
masks.unsqueeze(1), size=x.shape[-2:]).to(torch.bool).squeeze(1) # masks和x的shape一样:[b,2,2]
后续便可以生成位置编码部分(mmdet/models/utils/position_encoding.py),代码里采用了sine位置编码,该函数给masks的每个像素位置生成了一个256维的唯一的位置向量。shape:[B, 256, 7, 7]
# position encoding
pos_embed = self.positional_encoding(masks)
2.4 送入Transformer
4.1. 整体逻辑
在得到图像特征向量x=[b,256,7,7]、masks[b,7,7]矩阵以及位置编码pos_embed[b,256,7,7]后,便可送入Transformer。进入transformer的之前四个变量维度分别为, x->[2, 256, 7, 7],mask->[2, 7, 7],query_embed->[100, 256],pos_embed->[2, 256, 7, 7]
# outs_dec: [nb_nb_decdec, bs, num_query, embed_dim]
outs_dec, _ = self.transformer(x, masks, self.query_embedding.weight,pos_embed)
在进入transformer之前,定义了一个query_embed(就是后边的object query),其第一个维度为num_queries(原文解释为一张图片里的最大检测数量),第二个维度为hidden_dim,就是256。
self.query_embedding = nn.Embedding(self.num_query, self.embed_dims)
关键是理清encoder和decoder的QKV分别指啥, 本部分代码来自mmdet\models\utils\transformer.py的 Transformer函数中。看代码:
bs, c, h, w = x.shape
# use `view` instead of `flatten` for dynamically exporting to ONNX
x = x.view(bs, c, -1).permute(2, 0, 1) # [bs, c, h, w] -> [h*w, bs, c] [49,2,256]
pos_embed = pos_embed.view(bs, c, -1).permute(2, 0, 1) # [49,2,256]
query_embed = query_embed.unsqueeze(1).repeat( #[100,b,256]
1, bs, 1) # [num_query, dim] -> [num_query, bs, dim]
mask = mask.view(bs, -1) # [bs, h, w] -> [bs, h*w] [2,49]
"""
经过变换后的四个变量维度分别为, img->[49, 2, 256],mask->[2, 49],
query_embed->[100, 2, 256],pos_embed->[49, 2, 256]
"""
memory = self.encoder(
query=x, # [49,b,256]
key=None,
value=None,
query_pos=pos_embed, # [49,b,256]
query_key_padding_mask=mask) # [b,49]
target = torch.zeros_like(query_embed) # decoder初始化全0
# out_dec: [num_layers, num_query, bs, dim]
out_dec = self.decoder(
query=target, # 全0的target, 后续在MultiHeadAttn中执行了
key=memory, # query = query + query_pos又加回去了。
value=memory,
key_pos=pos_embed,
query_pos=query_embed, # [num_query, bs, dim]
key_padding_mask=mask)
# outs_dec: [nb_nb_decdec, bs, num_query, embed_dim] [6,2,100,256]
out_dec = out_dec.transpose(1, 2)
memory = memory.permute(1, 2, 0).reshape(bs, c, h, w)
return out_dec, memory
其中encoder中q就是x,kv分别为None,query_pos代表位置编码,而query_key_padding_mask就是mask。decoder的q是全0的target,后续decoder会迭代更新q,而kv则 是memory,即encoder的输出;key_pos依旧是k的位置信息;query_embed即论文中Object query,可学习位置信息;key_padding_mask依然是mask。
4.2. encoder部分
先看下encoder初始化部分,内部循环调用了6次BaseTransformerLayer,因此只需讲解一层EncoderLayer即可。将img,mask,pos_embed送入transformer encoder中,进行注意力操作。得到[49, 2, 256]的输出
encoder=dict(
type='DetrTransformerEncoder',
num_layers=6, # 经过6层Layer
transformerlayers=dict( # 每层layer内部使用多头注意力
type='BaseTransformerLayer',
attn_cfgs=[
dict(
type='MultiheadAttention',
embed_dims=256,
num_heads=8,
dropout=0.1)
],
feedforward_channels=2048, # FFN中间层的维度
ffn_dropout=0.1,
operation_order=('self_attn', 'norm', 'ffn', 'norm'))), # 定义运算流程
先跳转到mmdet\models\utils\transformer.py的DetrTransformerEncoder函数。再来看下BaseTransformerLayer的forward部分。该部分可以损失detr的核心部分了,因为本质上mmdet内部只是封装了pytorch现有的nn.MultiHeadAtten函数。所以,需要理解nn.MultiHeadAttn中两种mask参数的含义,限于篇幅原因,这里可参考nn.Transformer来理解这两个mask。 不过简单理解就是:attn_mask在detr中没用到,仅用key_padding_mask。attn_mask是为了遮挡未来文本信息用的,而图像可以看到全部的信息,因此不需要用attn_mask。
def forward(self,
query,
key=None,
value=None,
query_pos=None,
key_pos=None,
attn_masks=None,
query_key_padding_mask=None,
key_padding_mask=None,
**kwargs):
#Forward function for `TransformerDecoderLayer`.
norm_index = 0
attn_index = 0
ffn_index = 0
identity = query
if attn_masks is None:
attn_masks = [None for _ in range(self.num_attn)]
elif isinstance(attn_masks, torch.Tensor):
attn_masks = [
copy.deepcopy(attn_masks) for _ in range(self.num_attn)
]
warnings.warn(f'Use same attn_mask in all attentions in '
f'{self.__class__.__name__} ')
else:
assert len(attn_masks) == self.num_attn, f'The length of ' \
f'attn_masks {len(attn_masks)} must be equal ' \
f'to the number of attention in ' \
f'operation_order {self.num_attn}'
for layer in self.operation_order: # 遍历config文件的顺序
if layer == 'self_attn':
temp_key = temp_value = query
query = self.attentions[attn_index]( # 内部调用nn.MultiHeadAttn
query,
temp_key,
temp_value,
identity if self.pre_norm else None,
query_pos=query_pos, # 若有位置编码信息则和query相加
key_pos=query_pos, # 若有位置编码信息则和key相加
attn_mask=attn_masks[attn_index],
key_padding_mask=query_key_padding_mask,
**kwargs)
attn_index += 1
identity = query
elif layer == 'norm':
query = self.norms[norm_index](query) # 层归一化
norm_index += 1
elif layer == 'cross_attn': # decoder用到
query = self.attentions[attn_index](
query,
key,
value,
identity if self.pre_norm else None,
query_pos=query_pos, # 若有位置编码信息则和query相加
key_pos=key_pos, # 若有位置编码信息则和key相加
attn_mask=attn_masks[attn_index],
key_padding_mask=key_padding_mask,
**kwargs)
attn_index += 1
identity = query
elif layer == 'ffn': # 残差连接加全连接层
query = self.ffns[ffn_index](
query, identity if self.pre_norm else None)
ffn_index += 1
return query
decoder部分和encoder流程类似,只是多了交叉注意力。decoder部分将[49,2,256]的输出和query_embed[100,2,256]输入到transformer decoder中,得到[6, 2, 100, 256]的输出。这里是合并了6个不同层级解码层的输出,其实只需要最后一层即可。
decoder这里其实是将query_embed和feature做了注意力机制,q为query_embed[100, 2, 256],k为memory也就是feature[49, 2, 256],v也是memory[49, 2, 256]。
**
总结
**
decoder的输出经过Prediction feed-forward networks (FFNs)生成最终的预测。即[6,2,100,256]经过线性层生成[6,2,100,92]的类别预测,经过线性层生成[6, 2, 100, 4]的框坐标预测。
由于后续在detr上改进的论文对匈牙利算法以及loss计算改动不大,因此这部分代码就不讲解了。