一、泛型算法
1.1 泛型算法概述
c++标准库不仅包含数据结构(容器、容器适配器等),还有很多算法。数据结构可以帮助存放特定情况下需要保存的数据,而算法则会将数据结构中存储的数据进行变换。标准库没有给容器添加大量的功能函数,而是选择提供一组算法,这些算法大都不依赖特定的容器类型,是通过泛型编程(模板)实现的,可作用在不同类型的容器和不同类型的元素上。
为了快速了解泛型算法,来看下面一个简要案例,第三参数0是累加初始化值:
vector<int> v{100, 400, 200, 300, 200, 500, 100, 400, 600, 300 };
int sum = 0;
for (auto &&i : v)
{
sum += i;
}
cout << "sum = " << sum << endl; //sum = 3100
//调用泛型算法计算
cout << "sum = " << accumulate(begin(v), end(v), 0) << endl;//sum = 3100,第三参数0是累加初始化值两者都能得到同样的结果,例子中循环变量也不是很长,不过其可读性比 accumulate 差很多。标准库泛型算法的思想就是提供丰富的算法(通用为主)供开发者使用,避免耗费大量的时间在重复制造轮子上面。
一方面就是,即便开发者会自己去实现相应标准库中的算法,也要进行大量的测试来确保自己实现的算法是否正确,标准库提供的算法都是经过了严格的测试。所以没有必要做重复的工作,这样也能节省代码审阅者的时间,否则他们还要确定算法实现中是否有Bug。
另一方面是STL算法非常的高效。很多标准库算法提供了多种特化实现,这样足以应对依赖迭代器类型的使用方式。例如,将 vector 中的所有元素都填充0时,就可以使用 std::fill 。因为 vector 使用的是一段连续的内存,对于这种使用连续内存存放数据的结构都可以使用 std::fill 进行填充,这个函数类似于C中的 memset 函数。
标准容器定义了很少的操作。大部分容器主要是支持到元素增删、访问、遍历,获取容器大小等功能。用户若希望对容器元素进行更多其他有用的操作:例如给顺序容器排序,或者查找某个特定的元素,或者查找最大或最小的元素,等等。标准库并没有为每种容器类型都定义实现这些操作的成员函数,而是定义了一组泛型算法:因为它们实现共同的操作,所以称之为“算法”;而“泛型”指的是通过模板支持,它们可以操作在多种容器类型上,即不但可作用于 vector 或 list 这些标准库类型,还可用在内置数组类型、甚至其他类型的序列上。
1.2 泛型算法应用示例
例如,针对排序,标准库提供了 sort算法,为需要排序的各个容器提供服务,对于list 这种不支持到sort泛型算法的,还提供了功能函数sort来实现。而对于关联容器,本身是已排序的。下面针对sort算法在相关容器的一些应用,看看都是如何达成排序目的的。
//创建一个大数组vector
vector<int> v_sort;
const int v_size = 10000; //数组大小
const int read_size = 20; //输出数量
for(int i=0; i<v_size;i++)
{
v_sort.push_back(rand()%v_size); //随机赋值
}
//构造一个新的vertor,为了公平测试后面容器,调用sort算法排序vector
vector<int> v_sort_new(v_sort.begin(),v_sort.end());
cout << "clock()1 = " << clock() <<endl;
sort(v_sort_new.begin(),v_sort_new.end());
cout << "clock()2 = " << clock() <<endl;
//输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort_new[i] << " ";
}
cout << "\n";
//将vector拷贝构造list,调用list的sort函数排序
list<int> l_sort(v_sort.begin(),v_sort.end());
cout << "clock()3 = " << clock() <<endl;
l_sort.sort();
cout << "clock()4 = " << clock() <<endl;
//输出已排序的list前一段数据
list<int>::iterator it_list=l_sort.begin();
for (int i=0; i<read_size;i++)
{
/* code */
cout << *(it_list++) << " ";
}
cout << "\n";
//将vector拷贝构造multiset,multiset在构造时就自动排序
cout << "clock()5 = " << clock() <<endl;
multiset<int> set_sort(v_sort.begin(),v_sort.end());
cout << "clock()6 = " << clock() <<endl;
//输出已排序的multiset前一段数据
multiset<int>::iterator it_mset = set_sort.begin();
for (int i=0; i<read_size;i++)
{
/* code */
cout << *(it_mset++) << " ";
}
cout << "\n";
//将multiset拷贝回vector,multiset在构造时就自动排序,vector同样得到已排序结构
cout << "clock()7 = " << clock() <<endl;
v_sort.clear();
v_sort.assign(set_sort.begin(),set_sort.end());
cout << "clock()8 = " << clock() <<endl;
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
//out log
clock()1 = 3
clock()2 = 10
0 0 2 3 3 3 4 4 6 8 8 9 12 12 12 12 14 16 16 17
clock()3 = 19
clock()4 = 34
0 0 2 3 3 3 4 4 6 8 8 9 12 12 12 12 14 16 16 17
clock()5 = 38
clock()6 = 53
0 0 2 3 3 3 4 4 6 8 8 9 12 12 12 12 14 16 16 17
clock()7 = 62
clock()8 = 65
0 0 2 3 3 3 4 4 6 8 8 9 12 12 12 12 14 16 16 17上述这段代码,构建了一个大随机数组,然后将数据复制构造到vector、list、mulset看看其排序功能及排序耗时,由于mulset插入数据就已排序,把数据重新拷贝会vector,也能同样获得已排序结构。
而is_sorted 函数会告诉我们,容器内部的值是否已经经过排序:
//创建一个大数组vector
vector<int> v_sort;
const int v_size = 10000;
const int read_size = 20;
for(int i=0; i<v_size;i++)
{
v_sort.push_back(rand()%v_size);
}
cout << "v_sort is_sorted = "<< is_sorted(v_sort.begin(), v_sort.end()) << endl;
...见前代码...
cout << "clock()7 = " << clock() <<endl;
v_sort.clear();
v_sort.assign(set_sort.begin(),set_sort.end());
cout << "clock()8 = " << clock() <<endl;
...见前代码...
cout << "v_sort is_sorted = "<< is_sorted(v_sort.begin(), v_sort.end()) << endl;
//out log
v_sort is_sorted = 0
...省略...
clock()7 = 49
clock()8 = 51
0 0 2 3 3 3 4 4 6 8 8 9 12 12 12 12 14 16 16 17
v_sort is_sorted = 1shuffle 将打乱 vector 中的内容,前两个参数是容器的首尾迭代器,第三个参数是一个随机数生成器:
random_device rd;
mt19937 g {rd()};
//
shuffle(v_sort.begin(),v_sort.end(),g); //g是随机数生成器
cout << "v_sort is_sorted = "<< is_sorted(v_sort.begin(), v_sort.end()) << endl; //=0有时候,并不需要对列表完全进行排序,只需要比它前面的某些值小就可以。所以,让使用 partition 将数值小于20的元素放到前面:
//
partition(v_sort.begin(),v_sort.end(), [] (int i) { return i < 20; });
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
//out log
0 17 16 16 4 12 0 2 9 14 6 12 3 3 3 4 8 8 12 12或者只想对部分元素排序,可以调用partial_sort 。这个函数对容器的内容在某种程度上的排序。其会将 vector 中最小的N个数,放在容器的前半部分。其余的留在 vector 的后半部分,不进行排序:
//
shuffle(v_sort.begin(),v_sort.end(),g);
auto middle (next(begin(v_sort), 100));//[0,100)
partial_sort(begin(v_sort), middle, end(v_sort));//将小的数放置前面,并排序
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
//out log
0 0 2 3 3 3 4 4 6 8 8 9 12 12 12 12 14 16 16 17sort 函数还支持使用者将自行定义的比较函数作为第三个参数进行传入,按实际场景意愿排序,例如上述vector降序排序。
bool compare(int a,int b){ return a>b;}; //降序排序
//
shuffle(v_sort.begin(),v_sort.end(),g);
sort(v_sort.begin(),v_sort.end(),compare);
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
//out log
9997 9996 9995 9994 9993 9991 9990 9989 9988 9986 9984 9984 9984 9984 9983 9982 9982 9981 9981 99811.3 泛型算法与容器
可以看出,标准库提供的泛型算法一般与容器的类型无关,不依赖于容器类型。但会隐式地依赖元素类型(算法函数的模板参数类型):必须能够对元素做比较等运算。然后,泛型算法用迭代器来实现算法与容器的绑定,例如sort(begin(v),end(v)),通过遍历容器及排序。所有迭代器都支持自增操作符,从一个元素定位下一个元素,并提供解引用操作符访问元素的值,迭代器还支持相等和不等操作符,用于判断两个迭代是否相等。
大多数情况下,每个算法都需要使用(至少)两个迭代器指出该算法操纵的元素范围。第一个迭代器指向第一个元素,而第二个迭代器则指向最后一个元素的下一位置。第二个迭代器所指向的元素[有时被称为超出末端迭代器]本身不是要操作的元素,而被用作终止遍历的哨兵(sentinel)。
使用超出末端迭代器还可以很方便地处理第四个要求,只要以此迭代器为返回值,即可表示没有找到要查找的元素。如果要查找的值未找到,则返回超出末端迭代器;否则,返回的迭代器指向匹配的元素。
第三个要求——元素值的比较,有两种解决方法。默认情况下,sort操作要元素类型定义了比较<、>等操作符,算法使用这个操作符比较元素。如果元素类型不支持这些操作符,或者打算用不同的测试方法来比较元素,则可使用一个额外的参数:实现元素比较的函数名字。
使用泛型算法必须包含 algorithm 头文件:
#include <algorithm>,
标准库还定义了一组泛化的算术算法(generalized numeric algorithm),其命名习惯与泛型算法相同。使用这些算法则必须包含 numeric 头文件:
#include <numeric>,
除了少数例外情况,所有算法都在一段范围内的元素上操作,我们将这段范围称为“输出范围(input range)”。带有输入范围参数的算法总是使用头两个形参标记该范围。
算法对算法对输入范围的操作是类似的,但在该范围内如何操纵元素却有所不同:有些操作只读取数据(accumulat、find...),有些操作会修改数据(replace、fill...),有些操作会移动数据(sort、stable_sort 、move...)。
标准库算法与容器关系要点:
1)泛型算法本身从不执行容器操作,只是单独依赖迭代器和迭代器操作实现,因而其实现与容器类型无关。实际的容器类型未知(甚至所处理的元素是否存储在容器中也是未知的)。
//算法与容器类型无关
vector<int>::const_iterator result_vec = find(v_sort.begin(),v_sort.end(),99);//vector查找
list<int>::const_iterator result_list = find(l_sort.begin(),l_sort.end(),99); //list查找
multiset<int>::iterator result_mset = find(set_sort.begin(),set_sort.end(),99);//multiset 查找
int vg[12] = {71,73,29,34,40,23,84,99,21,78,18,58};
int *result_vg = find(vg,vg+12,99); //数组查找这个事实也许比较意外,但本质上暗示了:使用“普通”的迭代器时,算法从不修改基础容器的大小。正如我们所看到的,算法也许会改变存储在容器中的元素的值,也许会在容器内移动元素,但是,算法从不直接添加或删除元素。
//算法修改容器值
fill(v_sort.begin(),v_sort.begin()+2, 0); //前两个值设为0
fill(vg,vg+2, 0); //前两个值设为0
//算法会移动容器内的数据位置
sort(vg,vg+12,compare);2)泛型算法都是在标记容器(或其他序列)内的元素范围的迭代器上操作的。标记范围的两个实参类型必须精确匹配,而迭代器本身必须标记一个范围:它们必须指向同一个容器中的元素(或者超出容器末端的下一位置),并且如果两者不相等,则第一个迭代器通过不断地自增,必须可以到达第二个迭代器。
fill(vg,vg+2, 0); //前两个值设为0
fill(vg,vg+10, 10); //前10个值设为10
fill(vg,vg+sizeof(vg), 10); //前每个值设为103)标准库为所有泛型和算术算法的每一个迭代器形参指定了范围最小的迭代器种类(迭代器分类见下一小节)。
例如,find(以只读方式单步遍历容器)至少需要一个输入迭代器。replace 函数至少需要一对前向迭代器。replace_copy 函数的头两个迭代器必须至少是前向迭代器,第三个参数代表输出目标,必须至少是输出迭代器。对于每一个形参,迭代器必须保证最低功能。将支持更少功能的迭代器传递给函数是错误的;而传递更强功能的迭代器则没问题。向算法传递无效的迭代器类别所引起的错误,无法保证会在编译时被捕获到。
1.4 泛型算法与迭代器
可以看出,标准库的算法是通过迭代器间接来操作容器的,迭代器作为算法与容器之间的桥梁。标准库除了提供平时使用最多的迭代器-iterator迭代器,标准库还提供了其他特殊用途的迭代器:
- 插入迭代器(inserter、back_inserter 、front_inserter):这类迭代器与容器绑定在一起,实现在容器中插入元素的功能。
• back_inserter,创建使用 push_back 实现插入的迭代器。
• front_inserter,使用 push_front 实现插入。
• inserter,使用 insert 实现插入操作。除了所关联的容器外,inserter还带有第二实参:指向插入起始位置的迭代器。
//
list<int> ilst, ilst2, ilst3, ilst4; // empty lists
for (list<int>::size_type i = 0; i != 4; ++i){ ilst.push_front(i); }
copy (ilst.begin(), ilst.end(), front_inserter(ilst2)); // after copy ilst2 contains: 0 1 2 3
copy (ilst.begin(), ilst.end(), back_inserter(ilst3)); // after copy, ilst3 contains: 3 2 1 0
copy (ilst.begin(), ilst.end(), inserter (ilst4, ilst4.begin()));// after copy, ilst4 contains: 3 2 1 0- 流迭代器(istream_iterator、 ostream_iterator):这类迭代器可与输入或输出流绑定在一起,用于迭代遍历所关联的 IO 流。
•istream_iterator 用于读取输入流
•ostream_iterator 则用于写输出流
istream_iterator<T> in(strm);//创建从输入流 strm 中读取 T 类型对象的istream_iterator 对象
istream_iterator<T> in; //istream_iterator 对象的超出末端迭代器
ostream_iterator<T> in(strm);//创建将 T 类型的对象写到输出流 strm 的ostream_iterator 对象
ostream_iterator<T> in(strm, delim);//创建将 T 类型的对象写到输出流 strm 的ostream_iterator 对象,在写入过程中使用 delim作为元素的分隔符。delim 是以空字符结束的字符数组流迭代器除了最基本的迭代器操作:自增、解引用和赋值外,还提供了可比较两个 istream 迭代器是否相等(或不等)的操作,而 ostream 迭代器则不提供比较运算 。
流迭代器都是类模板:任何已定义输入操作符(>> 操作符)的类型都可以定义 istream_iterator。类似地,任何已定义输出操作符(<< 操作符)的类型也可定义 ostream_iterator。
#include <iterator>
#include <fstream>
//从输入流cin读取数据,并将读取内容刷新到cout屏幕输出和文件中,输入quit标识退出命名行输入读取
//
istream_iterator<string> cin_it(cin),eof; // reads int from cin,
ofstream outfile("test.txt");
ostream_iterator<string> outputf(outfile, " ");// writes string from the ofstream named outfile
ostream_iterator<string> output(cout, "\n");
string end_str = "quit";
while (cin_it != eof)
{
if(0==strcmp((*cin_it).c_str(),end_str.c_str()))
{
break;
}
*outputf++ = *cin_it;
*output++=*cin_it++;
flush(cout);
}
flush(outfile);- reverse_iterator (反向迭代器):这类迭代器实现向后遍历,而不是向前遍历。所有容器类型都定义了自己的 reverse_iterator 类型,由 rbegin 和 rend 成员函数返回。
反向迭代器是一种反向遍历容器的迭代器。也就是,从最后一个元素到第一个元素遍历容器。反向迭代器将自增(和自减)的含义反过来了:对于反向迭代器,++ 运算将访问前一个元素,而 -- 运算则访问下一个元素。
//
cout << "ilst.size() = " << ilst.size() << endl;
list<int>::reverse_iterator it_rvec = ilst.rbegin();
for (size_t i = 0; i < ilst.size(); i++)
{
cout << *it_rvec << " ";
/* code */
it_rvec++;
}
cout << "\n";
it_rvec = ilst.rend();
it_rvec--;
for (size_t i = 0; i < ilst.size(); i++)
{
cout << *it_rvec << " ";
/* code */
it_rvec--;
}
cout << "\n";- const_iterator(常量迭代器):相当于常量指针,迭代器指向内容无法修改。
//
list<int>::const_iterator it_const = ilst.begin();
it_const++; //OK
//*it_const = 10; //error
list<int>::iterator it_val= ilst.begin();
*it_val = 10; //OK对于迭代器,容器类在其定义时,会依据自身特点来明确其支持的迭代器类型;而对于泛型算法,根据算法要求它的迭代器提供什么类型的操作,对算法分类。因此迭代器是算法与容器沟通的桥梁。
算法要求的迭代器操作分为五个类别:
Input iterator//(输入迭代器) 读,不能写;只支持自增运算
Output iterator//(输出迭代器) 写,不能读;只支持自增运算
Forward iterator//(前向迭代器) 读和写;只支持自增运算
Bidirectional iterator//(双向迭代器) 读和写;支持自增和自减运算
Random access iterator//(随机访问迭代器) 读和写;支持完整的迭代器算术运算例如,map、set 和 list 类型提供双向迭代器,而 string、vector 和 deque 容器上定义的迭代器都是随机访问迭代器,用作访问内置数组元素的指针也是随机访问迭代器。istream_iterator 是输入迭代器,而ostream_iterator 则是输出迭代器。
二 、标准库算法阐述
1.1 算法形参结构
大多数算法采用下面四种形式形参结构:
alg (beg, end, other parms);
alg (beg, end, dest, other parms);
alg (beg, end, beg2, other parms);
alg (beg, end, beg2, end2, other parms);其中,alg 是算法的名字,beg 和 end 指定算法操作的元素范围。通常将该范围称为算法的“输入范围”。尽管几乎所有算法都有输入范围,但算法是否使用其他形参取决于它所执行的操作。这里列出了比较常用的其他形参:dest、beg2 和 end2,它们都是迭代器。这些迭代器在使用时,充当类似的角色。除了这些迭代器形参之外,有些算法还带有其他的菲迭代器形参,它们是这些算法特有的。
- dest 形参是一个迭代器,用于指定存储输出数据的目标对象。算法假定无论需要写入多少个元素都是安全的。
- 类似beg 和 end,beg2 和 end2 则标记第二个输入范围,是有些算法所需要的。
- 很多算法通过检查其输入范围内的元素实现其功能。这些算法通常要用到标准关系操作符:== 或 <。其中的大部分算法会提供第二个版本的函数parms,允许程序员提供比较或测试函数parms取代操作符的使用。
sort (beg, end); //采用默认比较
sort (beg, end, comp); //采用自定义的parms-comp函数来比较1.2 算法命名规范
标准库使用一组相同的命名和重载规范来定义算法名称。
1)很多算法通过检查其输入范围内的元素实现其功能。这些算法通常要用到标准关系操作符:== 或 <。其中的大部分算法会提供第二个版本的函数,允许程序员提供比较或测试函数取代操作符的使用。
sort(beg, end);
stable_sort(beg, end); //保证排序后元素的原始顺序
sort(beg, end, comp);
//
find(beg, end, val);
find_if(beg, end, pred); 2)实现复制的算法版本,标准库会在这些算法在名字中添加了_copy 后缀区分。
reverse(beg, end);
reverse_copy(beg, end, dest
replace_copy_if(beg, end, dest, pred, new_val);1.3 容器特有算法
泛型算法具有通用性,但算法是否其作用归根还是和数据结构关联的,有些容器其特有结构,对一些算法是无法支持到的。但标准库也相应地为这些容器提供了功能函数支持,使得获得容器一致性。
在我们前面的sort应用例子就看到,list容器是采用了list内置的sort函数,而非公用的sort算法。list 容器上的迭代器是双向的,而不是随机访问类型。由于 list 容器不支持随机访问,因此,在此容器上不能使用需要随机访问迭代器的算法, 例如sort 算法及其相关的算法。还有一些其他的泛型算法,如 merge、remove、reverse 和 unique,虽然可以用在 list 上,但却付出了性能上的代价。如果这些算法利用 list 容器实现的特点,则可以更高效地执行。
如果可以结合利用 list 容器的内部结构,则可能编写出更快的算法。与其他顺序容器所支持的操作相比,标准库为 list 容器定义了更精细的操作集合,使它不必只依赖于泛型操作。表 11.4 列出了 list 容器特有的操作,其中不包括要求支持双向或更弱的迭代器类型的泛型算法,这类泛型算法无论是用在list 容器上,还是用在其他容器上,都具有相同的效果。
/*
*将 lst2 的元素合并到 lst 中。这两个 list 容器对象都必须排序。
*lst2 中的元素将被删除。合并后,lst2 为空。返回 void 类型。
*/
lst.merge(lst2) //第一个版本使用 < 操作符
lst.merge(lst2, comp)//第二个版本则使用 comp 指定的比较运算
/*调用 lst.erase 删除所有等于指定值或使指定的谓词函数返回非零值的元素。返回 void 类型*/
lst.remove(val)
lst.remove_if(unaryPred)
/*反向排列 lst 中的元素*/
lst.reverse()
/*对 lst 中的元素排序*/
lst.sort
/*将 lst2 的元素移到 lst 中迭代器 iter 指向的元素前面。在 lst2 中删除移出的元素。*/
lst.splice(iter, lst2) //第一个版本将 lst2 的所有元素移到 lst 中;合并后,lst2 为空。lst 和 lst2 不能是同一个 list 对象
lst.splice(iter, lst2, iter2)//
第二个版本只移动 iter2 所指向的元素,这个元素必须是 lst2 中的元素。在这种情况中,lst 和lst2 可以是同一个 list 对象。也就是说,可在一个 list对象中使用 splice 运算移动一个元素
lst.splice(iter, beg, end) //第三个版本移动迭代器 beg 和 end 标记的范围内的元素。beg 和 end 照例必须指定一个有效的范围。这两个迭代器可标记任意 list 对象内的范围,包括 lst。当它们指定 lst 的一段范围时,如果 iter 也指向这个范围的一个元素,则该运算未定义。
/*调用 erase 删除同一个值的集合副本。*/
lst.unique() //第一个版本使用 ==操作符判断元素是否相等
lst.unique(binaryPred)//第二个版本则使用指定的谓词函数实现判断1.4 标准算法库简述
标准库提供了超过 100 种算法。与容器一样,算法有着一致的结构。下面就将这些算法分类归纳一下,来看看算法对容器提供了那些常用操作。
1)容器排序
std::sort(beg, end)//接受一定范围的元素,并对元素进行排序
std::stable_sort(beg, end)//接受一定范围的元素,并对元素进行排序,其能保证排序后元素的原始顺序
std::sort(beg, end, comp)
std::stable_sort(beg, end, comp)//
std::is_sorted(beg, end) //接受一定范围的元素,并判断该范围的元素是否经过排序。
std::shuffle(beg, end,gen) //类似于反排序函数;其接受一定范围的元素,并打乱这些元素。
std::random_shuffle(beg, end)//按随机次序重新安排元素,要求随机访问迭代器支持
std::random_shuffle(beg, end, rand)
std::partial_sort(beg, mid, end)//接受一定范围的元素和另一个迭代器,前两个参数决定排序的范围,后两个参数决定不排序的范围。
std::partial_sort(beg, mid, end, comp)
std::partial_sort_copy(beg, end, destBeg, destEnd)
std::partial_sort_copy(beg, end, destBeg, destEnd, comp)
std::reverse(beg, end) //向后处理输入序列排序,要求双向迭代器支持
std::reverse_copy(beg, end, dest)
std::partition(beg, end, unaryPred)//能够接受谓词函数。所有元素都会在谓词函数返回true时,被移动到范围的前端。剩下的将放在范围的后方。
std::stable_partition(beg, end, unaryPred)//类似std::partition,不同的是能保证排序后元素的原始顺序
std::nth_element(beg, nth, end)//实参 nth 是一个迭代器,定位输入序列中的一个元素。
std::nth_element(beg, nth, end, comp)
std::next_permutation(beg, end)//对序列进行前向和后向处理,要求双向迭代器
std::next_permutation(beg, end, comp)
std::prev_permutation(beg, end)//与 next_permutation 很像,但变换序列以形成前一个排列
std::prev_permutation(beg, end, comp)
...2)在容器中查找元素
std::find(beg, end, val) //可将一个搜索范围和一个值作为参数。函数将返回找到的第一个值的迭代器。线性查找。
std::find_if(beg, end, unaryPred) //在 unaryPred 为真的输入范围中查找。
std::count(beg, end, val) //count 算法返回元素在输入序列中出现次数的计数
std::count_if(beg, end, unaryPred) //在 unaryPred 为真的输入范围中查找。
std::find_first_of(beg1, end1, beg2, end2)//返回第二个范围的任意元素在第一个范围的首次出现的迭代器,如果找不到匹配就返回 end1。
std::find_first_of(beg1, end1, beg2, end2, binaryPred)//使用 binaryPred 比较来自两个序列的元素,返回第一个范围中第一个这种元素的迭代器
std::find_end(beg1, end1, beg2, end2) //返回第二个范围的任意元素在第一个范围的最后出现的迭代器
std::find_end(beg1, end1, beg2, end2, binaryPred)//
std::adjacent_find(beg, end)//返回重复元素的第一个相邻对。如果没有相邻的重复元素。就返回 end。
std::adjacent_find(beg, end, binaryPred)
std::search(beg1, end1, beg2, end2)//返回输入范围中第二个范围作为子序列出现的第一个位置。
std::search(beg1, end1, beg2, end2, binaryPred)
std::search_n(beg, end, count, val)
std::search_n(beg, end, count, val, binaryPred)
std::binary_search(beg, end, val)//可将一个搜索范围和一个值作为参数。执行二分查找,当找到对应元素时,返回true;否则,返回false。
std::binary_search(beg, end, val, comp)
std::lower_bound(beg, end, val)//可将一个查找返回和一个值作为参数,并且执行二分查找,返回第一个不小于给定值元素的迭代器。
std::lower_bound(beg, end, val, comp)
std::upper_bound(beg, end, val)//与 std::lower_bound 类似,不过会返回第一个大于给定值元素的迭代器。
std::upper_bound(beg, end, val, comp)
std::equal_range(beg, end, val)//可将一个搜索范围和一个值作为参数,并且返回一对迭代器。其第一个迭代器和返回结果一样,第二个迭代器和 std::upper_bound 返回结果一样。
std::equal_range(beg, end, val, comp)
std::equal(beg1, end1, beg2)//确定两个序列是否相等。
std::equal(beg1, end1, beg2, binaryPred) //
std::mismatch(beg1, end1, beg2)//比较两个序列中的元素,返回一对表示第一个不匹配元素的迭代器。
std::mismatch(beg1, end1, beg2, binaryPred) //
for_each(beg, end, f)//对其输入范围中的每个元素应用函数f。
...3)从容器中删除指定元素
std::remove(beg, end, val)//接受一个容器范围和一个具体的值作为参数,并且移除对应的值。返回一个新的end迭代器,用于修改容器的范围。
std::remove_if(beg, end, unaryPred)
std::remove_copy(beg, end, dest, val)//接受一个容器范围,一个输出迭代器和一个值作为参数。并且将所有不满足条件的元素拷贝到输出迭代器的容器中。
std::remove_copy_if(beg, end, dest, unaryPred)//用 new_val 代替每个匹配元素,对每个元素执行unaryPred,代替使 unaryPred 为真的那些元素
std::replace(beg, end, old_val, new_val)//接受一个容器范围和两个值作为参数,将使用第二个数值替换所有与第一个数值相同的值。
std::replace_if(beg, end, unaryPred, new_val)
std::replace_copy(beg, end, dest, old_val, new_val)//与 std::replace 功能类似,将每个元素复制到 dest,用 new_val 代替指定元素。
std::replace_copy_if(beg, end, dest, unaryPred, new_val)
//
std::unique(beg, end)//清楚非唯一性的元素,只保留一个
std::unique(beg, end, binaryPred)
std::unique_copy(beg, end, dest)//将唯一元素复制到 dest
std::unique_copy(beg, end, dest, binaryPred)
std::rotate(beg, mid, end)//围绕由 mid 表示的元素旋转元素。mid 处的元素成为第一个元素,从 mid +1 到 end 的元素其次,后面是从 beg 到 mid 的范围。返回 void
std::rotate_copy(beg, mid, end, dest)//除了保持输入序列不变并将旋转后的序列写至 dest 之外,与 rotated 很像。返回 void
std::copy_if //与 std::copy 功能相同,可以多接受一个谓词函数作为是否进行拷贝的依据。
...4)修改内容
std::copy(beg, end, dest) //将一个容器的数据拷贝到另一个容器
std::copy_n //
std::copy_backward(beg, end, dest)//按逆序将元素复制到输出迭代器 dest。返回 dest
std::move //
std::fill(beg, end, val)//范围内写入val
std::fill_n(dest, cnt, val)//将 cnt 个值写到 dest。fill_n 函数写 val 值的 cnt 个副本
std::generate(beg, end, Gen)//将新值赋给输入序列中的每个元素,执行 Gen()来创建新值
std::generate_n(dest, cnt, Gen)//对发生器 Gen() 进行 cnt 次计算
std::transform(beg, end, dest, unaryOp)//将容器某一范围的元素放置到其他容器中,在拷贝的同时,修改容器中的元素
std::transform(beg, end, beg2, dest, binaryOp)
std::merge(beg1, end1, beg2, end2, dest)//合并序列,两个输入序列都必须是已排序的。将合并后的序列写至 dest
std::merge(beg1, end1, beg2, end2, dest, comp)
std::inplace_merge(beg, mid, end)//将同一序列中的两个相邻子序列合并为一个有序序列:将从 beg 到 mid 和从 mid 到 end 的子序列合并为从 beg 到 end 的序列
std::inplace_merge(beg, mid, end, comp)
std::swap(elem1, elem2)//算法要求前向迭代器,因为修改输入序列中的元素,交换指定元素或由给定迭代器表示的元素
std::swap_ranges(beg1, end1, beg2)//用开始于 beg2 的第二个序列中的元素交换输入范围中的元素。
std::iter_swap(iter1, iter2)
...5)输入迭代器特有算法
includes(beg, end, beg2, end2)//如果输入序列包含第二个序列中的每个元素,就返回 true;否则,返回 false
includes(beg, end, beg2, end2, comp)
set_union(beg, end, beg2, end2, dest)//创建在任一序列中存在的元素的有序序列。两个序列中都存在的元素在输出序列中只出现一次。将序列存储在 dest 中
set_union(beg, end, beg2, end2, dest, comp)
set_intersection(beg, end, beg2, end2, dest)//创建在两个序列中都存在的元素的有序序列。将序列存储在 dest 中。
set_intersection(beg, end, beg2, end2, dest, comp)
set_difference(beg, end, beg2, end2, dest)//创建在第一个容器中但不在第二个容器中的元素的有序序列。
set_difference(beg, end, beg2, end2, dest, comp)
set_symmetric_difference(beg, end, beg2, end2, dest)//创建在任一容器中存在但不在两个容器中同时存在的元素的有序序列。
set_symmetric_difference(beg, end, beg2, end2, dest, comp)6)最大最小值
min(val1, val2)
min(val1, val2, comp)
max(val1, val2)
max(val1, val2, comp)
min_element(beg, end)
min_element(beg, end, comp)
max_element(beg, end)
max_element(beg, end, comp)7)简单数学计算
accumulate(beg, end, init)//返回输入范围中所有值的总和
accumulate(beg, end, init, BinaryOp)
inner_product(beg1, end1, beg2, init)//返回作为两个序列乘积而生成的元素的总和。
inner_product(beg1, end1, beg2, init, BinOp1, BinOp2)
partial_sum(beg, end, dest)//将新序列写至 dest,其中每个新元素的值表示输入范围中在它的位置之前(不包括它的位置)的所有元素的总和。
partial_sum(beg, end, dest, BinaryOp)
adjacent_difference(beg, end, dest)//将新序列写至 dest,其中除了第一个元素之外每个新元素表示当前元素和前一元素的差。
adjacent_difference(beg, end, dest, BinaryOp)8)更多算法相关操作如下
头文件 名字
algorithm lower_bound
algorithm max
algorithm min
algorithm nth_element
algorithm partial_sort
algorithm stable_sort
algorithm unique
algorithm unique_copy
algorithm upper_bound
algorithm copy
algorithm count
algorithm count_if
algorithm equal_range
algorithm fill
algorithm fill_n
algorithm find
algorithm find_end
algorithm find_first_of
algorithm for_each
algorithm replace
algorithm replace_copy
algorithm set_difference
algorithm set_intersection
algorithm set_union
algorithm sort
cstdlib abort
functional bind2nd
bitset bitset
deque deque
exception exception
fstream fstream
fstream ifstream
cstddef ptrdiff_t
iomanip setfill
iomanip setprecision
iomanip setw
cstddef size_t
ios_base ios_base
cctype isalpha
cctype islower
cctype ispunct
cctype isspace
cctype isupper
functional less_equal
functional negate
functional not1
fstream of stream
functional plus
cmath sqrt
cstring strcmp
cstring strcpy
cstring strlen
cstring strncpy
exception terminate
cctype tolower
cctype toupper
exception unexpected
头文件 名字
iostream boolalpha
iostream cerr
iostream cin
iostream cout
iostream dec
iostream endl
iostream ends
iostream fixed
iostream flush
iostream hex
iostream internal
iostream right
iostream scientific
iostream showbase
iostream showpoint
iostream skipws
iostream istream
iostream left
iostream noboolalpha
iostream noshowbase
iostream noshowpoint
iostream noskipws
iostream nounitbuf
iostream nouppercase
iostream oct
iostream ostream
iostream unitbuf
iostream uppercase
头文件 名字
numeric accumulate
memory allocator
memory auto_ptr
iterator back_inserter
new bad_alloc
typeinfo bad_cast
iterator front_inserter
string getline
numeric inner_product
iterator inserter
queue priority_queue
queue queue
stdexcept range_error
iterator reverse_iterator
stdexcept runtime_error
set set
iterator istream_iterator
sstream istringstream
list list
stdexcept logic_error
utility make_pair
map map
map multimap
set multiset
iterator ostream_iterator
sstream ostringstream
stdexcept out_of_range
utility pair
stack stack
string string
sstream stringstream
typeinfo type_info
memory uninitialized_copy
vector vector 三、源码案例及测试
3.1 编译测试
创建test.h/cpp源文件,通过g++ test.cpp -o test.exe编译指令生成程序,运行测试:
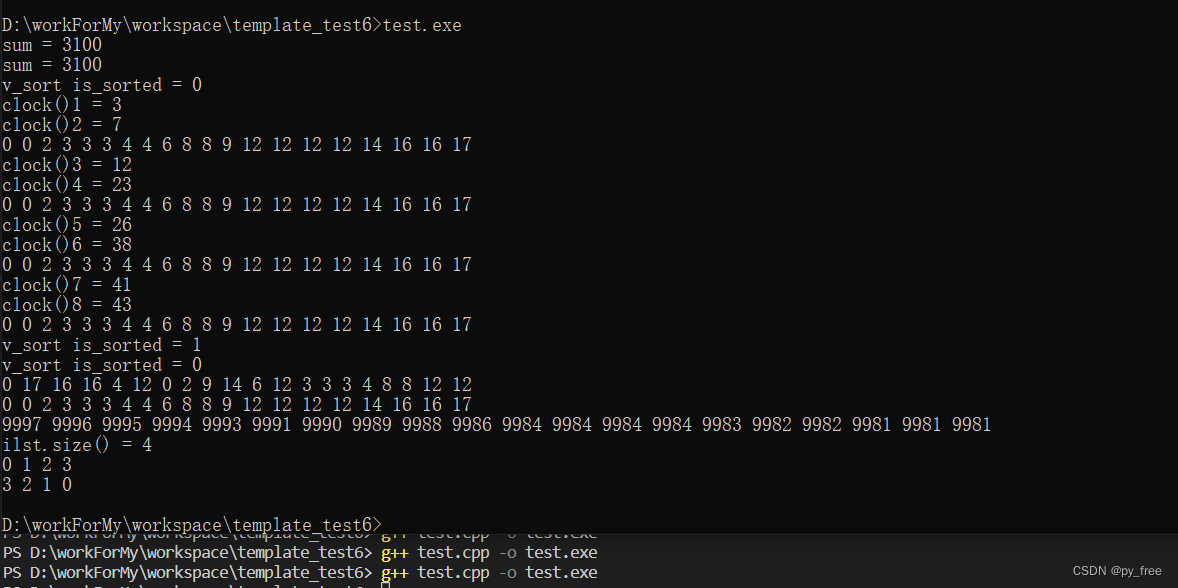
3.2 源代码
test.h
#ifndef _TEST_H_
#define _TEST_H_
#include <iostream>
#include <vector>
#include <list>
#include <set>
#include <numeric>
#include <algorithm>
#include <time.h>
#include <random>
#include <iterator>
#include <fstream>
#include <cstring>
#endif //_TEST_H_
test.cpp
#include "test.h"
using namespace std;
bool compare(int a,int b)
{
return a>b;
};
//
random_device rd;
mt19937 g {rd()};
int main(int argc, char* argv[])
{
vector<int> v{100, 400, 200, 300, 200, 500, 100, 400, 600, 300 };
int sum = 0;
for (auto &&i : v)
{
sum += i;
}
cout << "sum = " << sum << endl;
//
cout << "sum = " << accumulate(begin(v), end(v), 0) << endl;
//创建一个大数组vector
vector<int> v_sort;
const int v_size = 10000;
const int read_size = 20;
for(int i=0; i<v_size;i++)
{
v_sort.push_back(rand()%v_size);
}
cout << "v_sort is_sorted = "<< is_sorted(v_sort.begin(), v_sort.end()) << endl;
//构造一个新的vertor,为了公平测试后面容器,调用sort算法排序vector
vector<int> v_sort_new(v_sort.begin(),v_sort.end());
cout << "clock()1 = " << clock() <<endl;
sort(v_sort_new.begin(),v_sort_new.end());
cout << "clock()2 = " << clock() <<endl;
//输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort_new[i] << " ";
}
cout << "\n";
//将vector拷贝构造list,调用list的sort函数排序
list<int> l_sort(v_sort.begin(),v_sort.end());
cout << "clock()3 = " << clock() <<endl;
l_sort.sort();
cout << "clock()4 = " << clock() <<endl;
//输出已排序的list前一段数据
list<int>::iterator it_list=l_sort.begin();
for (int i=0; i<read_size;i++)
{
/* code */
cout << *(it_list++) << " ";
}
cout << "\n";
//将vector拷贝构造multiset,multiset在构造时就自动排序
cout << "clock()5 = " << clock() <<endl;
multiset<int> set_sort(v_sort.begin(),v_sort.end());
cout << "clock()6 = " << clock() <<endl;
//输出已排序的multiset前一段数据
multiset<int>::iterator it_mset = set_sort.begin();
for (int i=0; i<read_size;i++)
{
/* code */
cout << *(it_mset++) << " ";
}
cout << "\n";
//将multiset拷贝回vector,multiset在构造时就自动排序,vector同样得到已排序结构
cout << "clock()7 = " << clock() <<endl;
v_sort.clear();
v_sort.assign(set_sort.begin(),set_sort.end());
cout << "clock()8 = " << clock() <<endl;
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
cout << "v_sort is_sorted = "<< is_sorted(v_sort.begin(), v_sort.end()) << endl;
//
shuffle(v_sort.begin(),v_sort.end(),g);
cout << "v_sort is_sorted = "<< is_sorted(v_sort.begin(), v_sort.end()) << endl; //=0
//
partition(v_sort.begin(),v_sort.end(), [] (int i) { return i < 20; });
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
//
shuffle(v_sort.begin(),v_sort.end(),g);
auto middle (next(begin(v_sort), 100));
partial_sort(begin(v_sort), middle, end(v_sort));
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
//
shuffle(v_sort.begin(),v_sort.end(),g);
sort(v_sort.begin(),v_sort.end(),compare);
//重新输出已排序的vector前一段数据
for(int i=0; i<read_size;i++)
{
cout << v_sort[i] << " ";
}
cout << "\n";
//算法与容器类型无关
vector<int>::const_iterator result_vec = find(v_sort.begin(),v_sort.end(),99);//vector查找
list<int>::const_iterator result_list = find(l_sort.begin(),l_sort.end(),99); //list查找
multiset<int>::iterator result_mset = find(set_sort.begin(),set_sort.end(),99);//multiset 查找
int vg[12] = {71,73,29,34,40,23,84,99,21,78,18,58};
int *result_vg = find(vg,vg+12,99); //数组查找
//算法修改容器值
fill(v_sort.begin(),v_sort.begin()+2, 0); //前两个值设为0
fill(vg,vg+2, 0); //前两个值设为0
//算法会移动容器内的数据位置
sort(vg,vg+12,compare);
fill(vg,vg+sizeof(vg), 10); //前每个值设为10
//
list<int> ilst, ilst2, ilst3, ilst4; // empty lists
for (list<int>::size_type i = 0; i != 4; ++i)
ilst.push_front(i);
copy (ilst.begin(), ilst.end(), front_inserter(ilst2)); // after copy ilst2 contains: 0 1 2 3
copy (ilst.begin(), ilst.end(), back_inserter(ilst3)); // after copy, ilst3 contains: 3 2 1 0
copy (ilst.begin(), ilst.end(), inserter (ilst4, ilst4.begin()));// after copy, ilst4 contains: 3 2 1 0
//
/*//注释,编译后面代码测试
istream_iterator<string> cin_it(cin),eof; // reads int from cin,
ofstream outfile("test.txt");
ostream_iterator<string> outputf(outfile, " ");// writes string from the ofstream named outfile
ostream_iterator<string> output(cout, "\n");
string end_str = "quit";
while (cin_it != eof)
{
if(0==strcmp((*cin_it).c_str(),end_str.c_str()))
{
break;
}
*outputf++ = *cin_it;
*output++ = *cin_it++;
flush(cout);
}
flush(outfile);
*/
//
cout << "ilst.size() = " << ilst.size() << endl;
list<int>::reverse_iterator it_rvec = ilst.rbegin();
for (size_t i = 0; i < ilst.size(); i++)
{
cout << *it_rvec << " ";
/* code */
it_rvec++;
}
cout << "\n";
it_rvec = ilst.rend();
it_rvec--;
for (size_t i = 0; i < ilst.size(); i++)
{
cout << *it_rvec << " ";
/* code */
it_rvec--;
}
cout << "\n";
//
list<int>::const_iterator it_const = ilst.begin();
it_const++;
//*it_const = 10; //error
list<int>::iterator it_val= ilst.begin();
*it_val = 10;
return 0;
};